Каталог статей
- примечания
-
- Функция активации и градиент потерь
- Задача 5 на распознавание рукописных цифр урока 5
- урок6: основные типы данных
- урок7 Создание тензора
- урок8 Индексирование и нарезка
- урок9 Преобразование измерений
- урок 10 трансляция
- урок 11 Разделить и объединить
- урок12 Математические операции
- урок 13 Тензорная статистика
- урок 14 Тензор продвинутый
- урок 16 Что такое градиент
- урок17 Градиент общих функций
- урок18 Функция активации и градиент потерь
- урок 19 Градиентный вывод перцептрона
- Процесс получения обратного распространения ошибки MLP
- урок22 Оптимизация небольших примеров
- Логистическая регрессия урок24
- урок25 Перекрестная энтропия
- урок26 Практическое решение проблемы мультиклассификации LR
- урок28 Функция активации и ускорение графического процессора
- урок29 МНИСТ
- урок30 Визуализация мудрости
- урок32 Train-Val-Test-Cross Validation
- урок32 Регуляризация
- урок 34 Динамика и снижение скорости обучения
- урок35 с ранней остановкой и amp; выбывать
- урок38 Сверточная нейронная сеть
- Пакетная нормализация
- так называемый Мудл
- увеличение данных
- Классическая нейронная сеть
- РНН
- ЛСТМ
- Как понять встраивание
- Дивергенция КЛ
примечания
- Классификация подходит для дискретных данных, а регрессия — для непрерывных данных.
- Эпоха — это итерация по набору данных, а шаг — это итерация по пакету.
- Тип решения:
a = torch.tensor(2.2)
# 判断类型的两种方法:
# 1
a.type()
type(a) # 这是调用的python自带的方法,返回 torch.Tensor
# 2
isinstance(a, torch.FloatTensor) # 判断a的类型是否为torch.FloatTensor
- Скаляр имеет только 0 измерений. означает, что это скалярная величина.
- Одномерный вектор называется вектором в математике и тензором в pytorch.
Что означает норма в глубоком обучении?
В глубоком обучении «норма» обычно представляет собой концепцию нормы. Норма — это мера размера вектора или матрицы. Ее можно использовать для измерения длины вектора или размера матрицы.
В глубоком обучении общими нормами являются следующие:
Норма L1 (L1 Norm) : также называется Манхэттенской нормой , он вычисляет сумму абсолютных значений каждого элемента вектора. Для вектора x=(x₁, x₂, …, xn) норма L1 определяется как ||x||₁ = |x₁| + |x₂| + … + |xn|.
L2 Norm (L2 Norm): также известная как евклидова норма (евклидова норма), она вычисляет квадратный корень из суммы квадратов каждого элемента. вектора. Для вектора x=(x₁, x₂, …, xn) норма L2 определяется как ||x||₂ = √(x₁² + x₂² + … + xn²).
Норма бесконечности: : вычисляет максимальное абсолютное значение каждого элемента вектора. Для вектора x=(x₁, x₂, …, xn) бесконечная норма определяется как ||x||∞ = max(|x₁|, |x₂|, …, |xn|).
Эти нормы часто используются при регуляризации, определении функций потерь, алгоритмах оптимизации и т. д. в глубоком обучении. Например, регуляризация нормы L1 может использоваться для вывода разреженности, а регуляризация нормы L2 может использоваться для распада весов. (затухание веса), бесконечную норму можно использовать для ограничения размера градиента.
При глубоком обучении понятие нормы также можно распространить на матрицы или тензоры для измерения их размера или сложности. Например, норма Фробениуса матрицы используется для измерения размера матрицы, а ядерная норма (ядерная норма) — для измерения низкоранговых свойств матрицы.
Итерируемые объекты можно преобразовать в итераторы с помощью функции iter(). Например:
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list)
print(next(my_iter)) # 输出:1
print(next(my_iter)) # 输出:2
print(next(my_iter)) # 输出:3
функция enumerate()
enumerate возвращает значение индекса и соответствующий элемент
fruits = ['apple', 'banana', 'orange']
for index, fruit in enumerate(fruits):
print(index, fruit)
"""
0 apple
1 banana
2 orange
"""
Как представить строку с помощью pytorch
1. Горячее кодирование:
Горячее кодирование — это широко используемый метод кодирования данных, который преобразует дискретные категориальные признаки в набор двоичных векторов для таких задач, как машинное обучение.
например, если есть мужчины, женщины и нейтральные персонажи, они обозначаются [1, 0, 0], [0, 1, 0], [0, 0, 1] соответственно. Такое представление называется горячим кодированием
2. Встраивание
- Word2vec
- перчатка
# 随机正态分布
torch.randn()
# 随机均匀分布,[0, 1]
Resnet: самая большая функция использует остаточные соединения.
optimizer.zero_grad() :参数梯度的清零
loss.backward() :反向传播,计算梯度
optimizer.step(): 根据梯度更新模型参数
这三行代码分别代表什么意思

Вышеописанное является основой
Функция активации и градиент потерь
为什么要计算梯度w.requires_grad_(requires_grad=True), 有什么用?
Градиент — это вектор, указывающий направление, в котором скорость изменения функции наибольшая в данной точке. Путем расчета градиентов можно добиться обратного распространения ошибки, оптимизации параметров, выбора функций и т. д.
p[1].backward(retain_graph=True)
Вычислить градиент p[1] к тензору a и сохранить градиент в a.grad
mse = F.mse_loss(torch.ones(1), x*w)
Входными параметрами функции F.mse_loss() являются два тензора, представляющие прогнозируемое значение и целевое значение соответственно. Он рассчитает среднеквадратическую ошибку между этими двумя тензорами и вернет в качестве результата скалярный тензор.
torch.autograd.grad(mse, [w])
Функция torch.autograd.grad() используется для вычисления градиента заданного скалярного тензора mse относительно заданного тензора параметра w.
save_graph=True означает сохранение промежуточного графика вычислений, чтобы при обратном вызове не возникало ошибок
import torch
from torch.nn import functional as F
# autograd.grad 自动求导
x = torch.ones(1)
print(x)
w = torch.full([1], 2) # 创建了一个包含一个元素且值为2的PyTorch Tensor
print(w)
w = w.type(torch.float32)
w.requires_grad_(requires_grad=True) # w初始化时设置需要求导信息
mse = F.mse_loss(torch.ones(1), x*w)
# torch.autograd.grad(y,w) 表示y对w求导。
torch.autograd.grad(mse, [w], retain_graph=True) # retain_graph=True 表示保留中间的计算图,以便在第二调用backward时不会引发错误
# mse = F.mse_loss(torch.ones(1), x*w)
print(torch.autograd.grad(mse, [w]))
# F.softmax 放缩到0-1且和为1
a = torch.rand(3) # 生成3个0-1的随机数
print(a)
a.requires_grad_()
p = F.softmax(a, dim=0) # 将给定的数据转化为0-1范围内,且和为1
print(p)
p[1].backward(retain_graph=True) # 计算p[1]对张量a的梯度,并将该梯度存在a.grad中
print(p[1])
p1 = torch.autograd.grad(p[1], [a], retain_graph=True) # 计算p1对张量a的梯度,返回梯度值
print(p1)
print(a.grad)
p[2].backward(retain_graph=True)
print(p[2])
p2 = torch.autograd.grad(p[2], [a], retain_graph=True) # 计算p2对张量a的梯度,返回梯度值
print(p2)
print(a.grad)
"""
tensor([1.])
tensor([2])
(tensor([2.]),)
tensor([0.9741, 0.7026, 0.0407])
tensor([0.4639, 0.3536, 0.1824], grad_fn=<SoftmaxBackward0>)
tensor(0.3536, grad_fn=<SelectBackward0>)
(tensor([-0.1641, 0.2286, -0.0645]),)
tensor([-0.1641, 0.2286, -0.0645])
tensor(0.1824, grad_fn=<SelectBackward0>)
(tensor([-0.0846, -0.0645, 0.1491]),)
tensor([-0.2487, 0.1641, 0.0846])
"""
Задача 5 на распознавание рукописных цифр урока 5
# mnist_train.py
import torch
from torch import nn
from torch.nn import functional as F # 常用函数
from torch import optim # 优化数据包
import torchvision
from matplotlib import pyplot as plt
from utils import plot_image, plot_curve, one_hot # image是图片,curve是曲线
batch_size = 512 # 一次可以处理的图片数
# step1. load dataset 非重点
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True, # train=True表示采用的训练集
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True, # train=False表示采用的测试集
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 下载下的为numpy格式,转为tensor格式
torchvision.transforms.Normalize( # 使数据从0-1之间转为0附近均匀分布,使性能更好
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
x, y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
plot_image(x, y, 'image sample')
# 创建网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# xw+b
self.fc1 = nn.Linear(28*28, 256) # 线性层 256是随机决定的 28*28是图片尺寸
self.fc2 = nn.Linear(256, 64) # 256是fc2的输入,应为fc1的输出。
self.fc3 = nn.Linear(64, 10) # 64是fc3的输入,应为fc2的输出。10是0-9十个数字。
def forward(self, x):
# x: [b, 1, 28, 28]
# h1 = relu(xw1+b1)
x = F.relu(self.fc1(x))
# h2 = relu(h1w2+b2)
x = F.relu(self.fc2(x))
# h3 = h2w3+b3
x = self.fc3(x)
return x
net = Net()
# [w1, b1, w2, b2, w3, b3]
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_loss = []
for epoch in range(3): # 对整个数据集迭代3次
for batch_idx, (x, y) in enumerate(train_loader): # 对一个batch迭代一次
# x: [batch_size, 1, 28, 28], y: [batch_size] x是图像输入,y是输出结果0-9
# [batch_size, 1, 28, 28] => [batch_size, 784]
x = x.view(x.size(0), 28*28)
# => [b, 10]
out = net(x) # net是个全连接层,只能接受dimension=2的输入,即[b, feature]的特征(b=batch_size)。因此要view成新的shape。
# [b, 10]
y_onehot = one_hot(y)
# loss = mse(out, y_onehot)
loss = F.mse_loss(out, y_onehot)
optimizer.zero_grad()
loss.backward()
# w' = w - lr*grad
optimizer.step() # 更新参数信息
train_loss.append(loss.item())
if batch_idx % 10==0:
print(epoch, batch_idx, loss.item())
plot_curve(train_loss)
# we get optimal [w1, b1, w2, b2, w3, b3]
total_correct = 0
for x,y in test_loader:
x = x.view(x.size(0), 28*28)
out = net(x)
# out: [b, 10] => pred: [b]
pred = out.argmax(dim=1)
correct = pred.eq(y).sum().float().item()
total_correct += correct
total_num = len(test_loader.dataset)
acc = total_correct / total_num
print('test acc:', acc)
x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')
# utils.py
# 封装了一些函数
import torch
from matplotlib import pyplot as plt
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'], loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
def plot_image(img, label, name):
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
plt.title("{}: {}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
def one_hot(label, depth=10):
# convert label to one-hot encoding
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out
урок6: основные типы данных
# 判断数据类型方法
a.type() //
type(a) # python自带的
isinstance(a, torch.FloatTensor) # 判断是否为某种类型的
# dimension为0的标量表示方法: (dimension为0的标量常用于表示loss)
a = torch.tensor(1.) # tensor(1.)
# dimension为1的张量表示方法,常用于表示bias偏置
torch.tensor([1.1]) # tensor([1.1000])
torch.tensor([1.1, 2.2]) # tensor([1.1000, 2.2000])
# FloatTensor的参数为张量的长度,而内容为随机初始化的。
torch.FloatTensor(1) # tensor([3.2239e-25])
torch.FloatTensor(2) # tensor([3.2239e-25, 4.59e-41])
# 从numpy转为tensor
data = np.ones(2) # array([1., 1.])
torch.from_numpy(data) # tensor([1., 1.], dtype=torch.float64)
# dimension为2的张量常用于表示多张图片的时候。比如有100张图片,每张图片是28*28=784的,所以可以用[100, 784]表示多张图片
# 求size,shape
a = torch.tensor(2.2)
a.shape # torch.Size([])
len(a.shape) # 0
a.size() # torch.Size([])
# dimension为3适用于RNN,自然语言处理
# dimension为4适用于图片,卷积神经网络。
[b, c, h, w] => [图片数, 通道数, 高度, 宽度]
# 其他
a.numel() #tensor占用的内存的数量
a.dim() # 返回维度dimension
урок7 Создание тензора
import numpy as np
import torch
# import from numpy
a = np.array([2, 3.3])
a = torch.from_numpy(a)
print(a)
# 全1矩阵,[a, b]表示创建a行b列的矩阵
a = np.ones([2, 3])
a = torch.from_numpy(a)
print(a)
# torch.tensor 使用现成的数据, tensor.Tensor接收数据的shape维度
# import from list
a = torch.tensor([2., 3.2]) # a就是tensor类型的[2, 3.2]
print(a)
a = torch.Tensor(2, 3) # 生成2行3列的数据
print(a)
# 如果出现torch.nan 或者torch.inf可能是没有初始化
# 随机初始化
a = torch.rand(3, 3) # 生成一个3行3列的,均匀采样于[0, 1]之间的数
print(a)
# 生成相同shape的tensor
a = torch .rand_like(a)
print(a)
# int的随机初始化
a = torch.randint(1, 10, [3, 3]) # [1, 9] shape:(3,3)
print(a)
# 正态分布 N(0, 1) 作为bias的初始化
a = torch.randn(3, 3) # 生成(3, 3)的,均值为0 方差为1的tensor
print(a)
# full: 全部赋值为1个元素
a = torch.full([2, 3], 7) # 2*3, 用7来填充
print(a)
# [] 表示生成标量 用7来填充
a = torch.full([], 7)
print(a) # tensor(7)
# [1] 表示生成dimension为1的tensor
a = torch.full([1], 7)
print(a) # tensor([7])
# arange
a = torch.arange(0, 10) # 生成0-9的数字,默认步长是1
print(a)
a = torch.arange(0, 10, 2) # 步长是2
print(a)
# linespace /logspace
a = torch.linspace(0, 10, steps=4) # 0,10分别表示第一个和最后一个元素 steps表示元素数量
print(a)
a = torch.linspace(0, 10, steps=11)
print(a)
a = torch.logspace(0, -1, steps=10) # 这个是logspace, 0表示10的0次方,-1表示10的-1次方
print(a) # a的第一个数是1,最后一个数是0
# ones zeros eye
a = torch.ones(3, 3) # 生成3*3的全1矩阵
a = torch.zeros(3, 3) # 生成3*3的全0矩阵
a = torch.eye(3, 4) # 生成主对角全1的矩阵
# randperm随机打散 重新排序 ★★
a = torch.randperm(10) # 0-9之间的所有数随机打散
a = torch.rand(2, 3)
b = torch.rand(2, 2)
idx = torch.randperm(2)
print(idx)
print("a=\n", a)
a = a[idx] # 将a的行按照idx重新排序 (整个行重新换)
print("new_a=\n",a)
print("b=\n", b)
b = b[idx]
print("new_b=\n", b) # 将b的行按照idx重新排序
урок8 Индексирование и нарезка
import numpy
import torch
# index: dim 0 first
a = torch.rand(4, 3, 28, 30)
print(a[0].shape) # torch.Size([3, 28, 30])
print(a[0, 0].shape) # torch.Size([28, 30])
print(a[0, 0, 2, 4]) # 用下标索引元素值
# 隔行采样:
print(a[:, :, 0:28:2, 0:30:2].shape) # torch.Size([4, 3, 14, 14])
# ::2 等价于start:end:2
# index_select
"""
a.index_select(idx, torch.arange(k))
将第idx个维度变为k
"""
print(a.index_select(0, torch.arange(2)).shape)
print(a.index_select(2, torch.arange(13)).shape)
урок9 Преобразование измерений
import numpy as np
import torch
# view / reshape
# view能干的reshape都能干。reshape更强大
a = torch.rand(4, 1, 28, 28)
print(a.shape) # torch.Size([4, 1, 28, 28])
b = a.view(4, 28*28)
print(b.shape) # torch.Size([4, 784])
c = a.reshape(4*28, 28)
print(c.shape)
# squeeze / unsqueeze
# unsqueeze(idx) 将shape在idx维度多插上一维。
# 指定压缩第n位,如果它的维数为1,则压缩,反之不对该维度操作。
# unsqueeze(-1) 使shape从[2] => [2, 1], 再unsqueeze变成[2,1,1] -1表示插到最后面
# unsqueeze(1) 使shape从[4,2] => [4, 1,2]
a = torch.tensor([1.2, 2.3])
print(a.unsqueeze(-1)) # shape变成[2,1]
"""
tensor([[1.2000],
[2.3000]])
"""
print(a.unsqueeze(0)) # 变成[1, 2] tensor([[1.2000, 2.3000]])
# 实在案例
b = torch.rand(32) # b是在channel上的bias。
f = torch.rand(4, 32, 14, 14)
b = b.unsqueeze(0).unsqueeze(2).unsqueeze(3)
print(b.shape) # torch.Size([1, 32, 1, 1])
# squeeze(n)用法
# 指定压缩第n位,如果它的维数为1,则压缩,反之不对该维度操作。
b = torch.Tensor(1, 32, 1, 1)
print(b.shape)
print(b.squeeze().shape) # torch.Size([32]) b.squeeze表示默认将所有维度为1的全部squeeze
print(b.squeeze(0).shape) # torch.Size([32, 1, 1]) 将第0维挤压
# 维度扩展expand / repeat
# expand: boradcasting 不主动复制数据,推荐使用。
a = torch.rand(4, 32, 14, 14)
b = torch.Tensor(1, 32, 1, 1)
print(b.expand(4, 32, 14, 14).shape) # torch.Size([4, 32, 14, 14]) expand从1到n可行,从n到m不太好
# repeat
# repeat: memory copied
# repeat的参数表示倍数,在原来的基础上乘
b = torch.Tensor(1, 32, 1, 1)
print(b.repeat(4, 32, 1, 1).shape) # torch.Size([4, 1024, 1, 1])
# .t 转置
a = torch.randn(3, 4) # 生成3行4列的矩阵
print(a.t().shape, a.t()) # torch.Size([4, 3])
# permute
# 按照参数的顺序交换维度。
b = torch.rand(4, 3, 28, 32)
print(b.permute(0, 2, 3, 1).shape) # torch.Size([4, 28, 32, 3])
урок 10 трансляция
Относительно возможности использования механизма трансляции:
Если текущее измерение dim=1, вы можете напрямую расширить его до того же размера
Если есть нет дима, вставьте его A дим, а затем расширьте до того же дима
иначе трансляция невозможна:

урок 11 Разделить и объединить
import numpy as np
import torch
# cat concat 要求除了拼接外的维度之外都不一样
a1 = torch.rand(4, 3, 32, 32)
a2 = torch.rand(5, 3, 32, 32)
print(torch.cat([a1, a2], dim=0).shape) # torch.Size([9, 3, 32, 32])
a2 = torch.rand(4, 1, 32, 32)
print(torch.cat([a1, a2], dim=1).shape) # torch.Size([4, 4, 32, 32])
a1 = torch.rand(4, 3, 16, 32)
a2 = torch.rand(4, 3, 20, 32)
print(torch.cat([a1, a2], dim=2).shape) # torch.Size([4, 3, 36, 32])
# stack: create new dim 要求a和b的shape完全一样。
a1 = torch.rand(4, 3, 16, 32)
a2 = torch.rand(4, 3, 16, 32)
print(torch.stack([a1, a2], dim=2).shape) # torch.Size([4, 3, 2, 16, 32]) 在dim=2处插一个维度
b = torch.randn(32, 8)
a = torch.randn(32, 8)
c = torch.stack([a, b], dim=0)
print(c.shape) # torch.Size([2, 32, 8])
# split: by len
a = torch.rand([5, 6])
print(a)
aa, bb = torch.split(a, [2, 3], dim=0) # 按行去split,本来是[5,6], split成[2,6]和[3,6]
print(aa.shape, bb.shape) # torch.Size([2, 6]) torch.Size([3, 6])
урок12 Математические операции
import numpy as np
import torch
a = torch.rand(3,4)
b = torch.rand(4)
torch.all(torch.eq(a-b, torch.sub(a,b)))
print(a + b)
print(torch.add(a, b)) # 等价于a+b
# 同理,torch.sub(a,b) 等价于a-b
# 矩阵的乘法
# matmul:
# torch.mm : 只适用于2d
# torch.matmul
# @
a = torch.full([2, 2], 3)
b = torch.ones(2, 2)
# 矩阵乘法的三种表示方法
torch.mm(a, b) # 等价于
torch.matmul(a, b) # 等价于
print(a@b)
a = torch.rand(4, 784)
x = torch.rand(4, 784)
w = torch.rand(512, 784) # w:(channel.out, channel.in)
print(torch.matmul(x, w.t()).shape) # torch.Size([4, 512])
# >>> a = torch.rand(4,3, 28, 64)
# >>> b = torch.rand(4,1,64,32)
# >>> torch.matmul(a,b).shape
# torch.Size([4, 3, 28, 32])
# 次方
# a.pow(k) : a的k次方
# a**k
# a.sqrt(): 开根号
# a.rsqrt(): 取倒数再开方
# e的几次方 & ln
a = torch.exp(torch.ones(2, 2))
print(torch.log(a)) # 对a的所有元素再取ln
# 近似值
a = torch.tensor(3.14)
a.floor() # 取地板
a.ceil() # 取天花板
a.trunc() # 取整数
a.frac() # 取小数
# clamp
# 将值限制在给定参数的范围内
# a.clamp(min, max) : 将a的值限定在min-max之间。a中的值小于min的变成min,大于max的变成max,介于二者之间的不变。
grad = torch.rand(2, 3) * 15
урок 13 Тензорная статистика
import torch
"""
tensor统计:
norm: 求范数
mean : 平均值 sum : 求和
prod : 连乘
max, min, argmin, argmax : 最大最小值,最大最小值的idx(默认先打平,再求第几个数)
kthvalue, topk : 第k大的数的位置及其值
"""
# 1范数表示 |x|求和。 2范数表示平方和再开根号。
a = torch.tensor([1,2,3,4,5,6,7,8], dtype=float)
b = a.view(2, 4)
c = a.view(2, 2, 2)
print(c)
print(c.norm(1, dim=0)) # 参数1表示1范数。 2表示2范数
print(c.norm(1, dim=1))
print(c.norm(1, dim=2))
print(c.norm(2, dim=0))
"""
c: tensor([[[1., 2.],
[3., 4.]],
[[5., 6.],
[7., 8.]]], dtype=torch.float64)
c.norm(1, dim=0):
tensor([[ 6., 8.],
[10., 12.]], dtype=torch.float64)
c.norm(1, dim=1):
tensor([[ 4., 6.],
[12., 14.]], dtype=torch.float64)
c.norm(1, dim=2):
tensor([[ 3., 7.],
[11., 15.]], dtype=torch.float64)
"""
a = torch.randn(4, 10)
print(a.argmax()) # tensor(28)
print(a.argmax(dim=1)) # tensor([1, 0, 8, 2]) 每行10个数,求10个数中的最大值的idx,即按照dim=1求最大值
# dim, keepdim
a = torch.rand(4, 10)
b = a.max(dim=1) # b[0]是value的max, b[1]是value对应的idx
c = a.max(dim=1, keepdim=True)
print(b[0].shape) # torch.Size([4])
print(c[0].shape) # torch.Size([4, 1]) 保持竖着的
a = torch.rand(4, 10)
print(a)
print(a.topk(3, dim=1)) # 共4行,返回每一行前3大的元素及下标
print(a.topk(3, dim=1, largest=False)) # largest=False表示求最小的。
print(a.kthvalue(8, dim=1)) # 默认是第8小的元素
"""
tensor([[0.7841, 0.5202, 0.5160, 0.4788, 0.6427, 0.1049, 0.5161, 0.3836, 0.1677, 0.4653],
[0.4838, 0.4054, 0.4336, 0.1541, 0.4228, 0.4602, 0.5819, 0.3031, 0.0749, 0.7695],
[0.2420, 0.7969, 0.7428, 0.4675, 0.3132, 0.7516, 0.6356, 0.4277, 0.7945, 0.1089],
[0.0475, 0.6876, 0.4313, 0.2479, 0.8423, 0.2280, 0.3918, 0.2062, 0.9654, 0.9479]])
torch.return_types.topk(
values=tensor([[0.7841, 0.6427, 0.5202],
[0.7695, 0.5819, 0.4838],
[0.7969, 0.7945, 0.7516],
[0.9654, 0.9479, 0.8423]]),
indices=tensor([[0, 4, 1],
[9, 6, 0],
[1, 8, 5],
[8, 9, 4]]))
torch.return_types.topk(
values=tensor([[0.1049, 0.1677, 0.3836],
[0.0749, 0.1541, 0.3031],
[0.1089, 0.2420, 0.3132],
[0.0475, 0.2062, 0.2280]]),
indices=tensor([[5, 8, 7],
[8, 3, 7],
[9, 0, 4],
[0, 7, 5]]))
torch.return_types.kthvalue(
values=tensor([0.5202, 0.4838, 0.7516, 0.8423]),
indices=tensor([1, 0, 5, 4]))
"""
# torch.equal() 用的更多一些
# torch.eq(a,b) 返回相同类型的矩阵,相等的位置为1,不等的位置为0
# torch.equal(a,b) 返回True或False
урок 14 Тензор продвинутый
где
собираются
import torch
# where
# torch.where(cond>0.5, a, b) 大于0.5选a,小于0.5选b的值
cond = torch.rand(2, 2)
print(cond)
a = torch.zeros(2, 2)
print(a)
b = torch.ones(2, 2)
print(b)
c = torch.where(cond>0.5, a, b)
print(c)
"""
#### where
tensor([[0.4118, 0.6295],
[0.1647, 0.2860]])
tensor([[0., 0.],
[0., 0.]])
tensor([[1., 1.],
[1., 1.]])
c = torch.where(cond>0.5, a, b) 大于0.5选a,小于0.5选b的值
tensor([[1., 0.],
[1., 1.]])
进程已结束,退出代码0
"""
# gather
prob = torch.randn(4, 10)
topk = prob.topk(dim=1, k=3)
print("idx=\n", topk)
idx = topk[1] # 取到下标。 topk[1]表示
print("idx=\n", idx)
label = torch.arange(10) + 100
# 根据idx索引,在label张量中收集对应 位置的值。
res = torch.gather(label.expand(4, 10), dim=1, index=idx.long()) # idx.long()表示转为长整型
print("res=\n", res)
"""
idx=
torch.return_types.topk(
values=tensor([[1.1974, 0.6872, 0.6593],
[1.5346, 0.4412, 0.4348],
[1.8746, 1.3127, 0.5541],
[1.9470, 0.8821, 0.5151]]),
indices=tensor([[1, 3, 4],
[9, 6, 5],
[0, 9, 2],
[9, 7, 8]]))
idx=
tensor([[1, 3, 4],
[9, 6, 5],
[0, 9, 2],
[9, 7, 8]])
res=
tensor([[101, 103, 104],
[109, 106, 105],
[100, 109, 102],
[109, 107, 108]])
"""
урок 16 Что такое градиент
Длина градиента отражает тенденцию
Направление градиента отражает направление роста.


Какие факторы влияют на процесс поиска?
- начальное состояние
- скорость обучения
- Импульс (как избежать локальных минимумов): можно понимать как инерцию.
урок17 Градиент общих функций
Производные и частные производные являются производными в одном направлении. Градиент — это производная во всех направлениях.
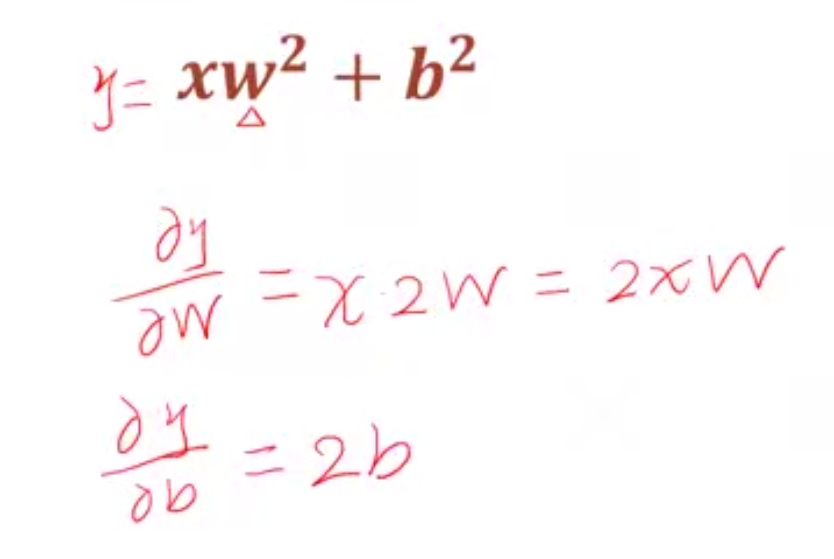
урок18 Функция активации и градиент потерь
Функция активации сигмовидной мышцы
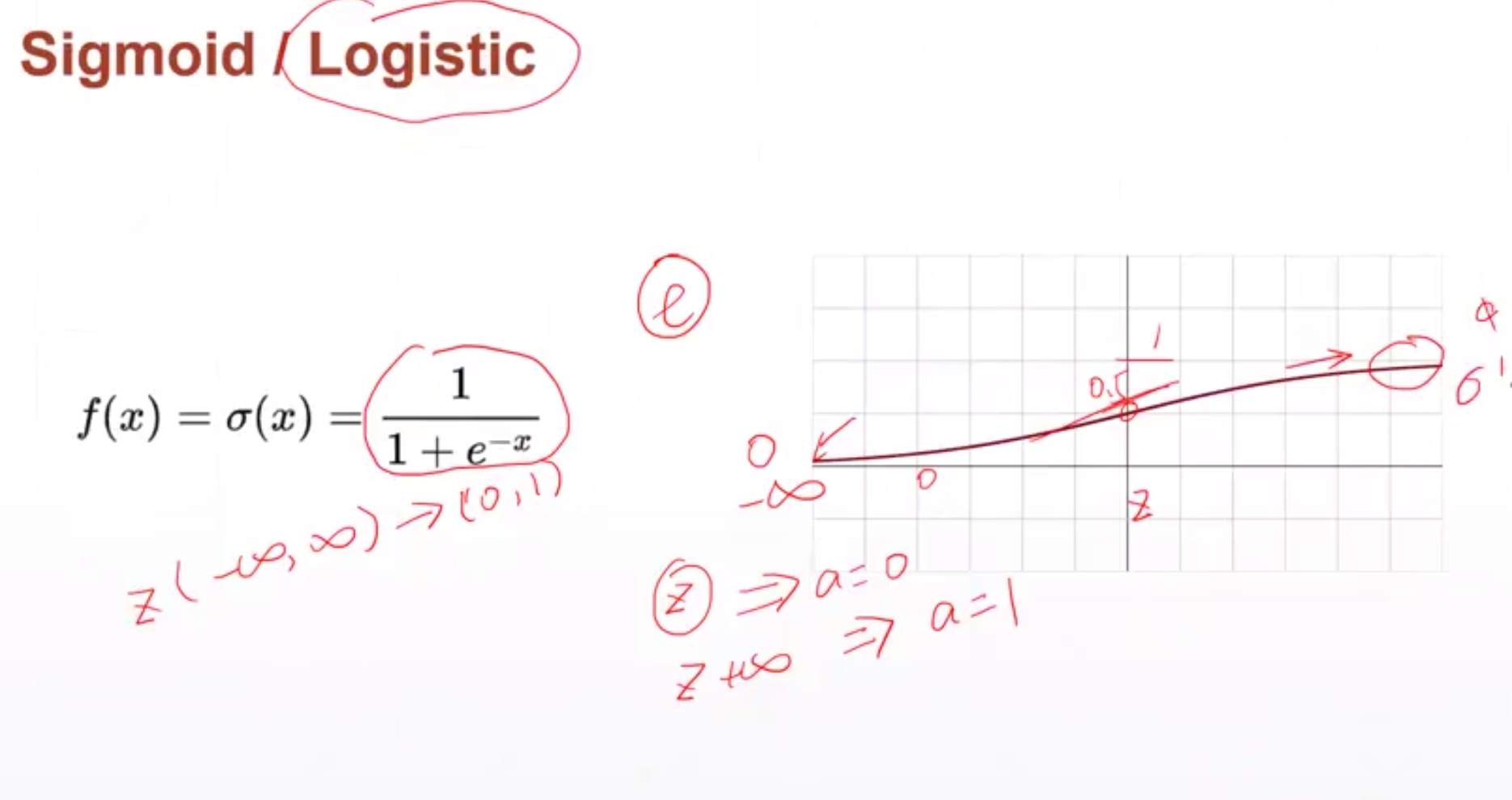
Для функции сигмовидной кишки f' = f * (1-f).
Когда x приближается к положительной или отрицательной бесконечности, значение его производной становится равным 0, и градиент не может быть обновлен.
Функция активации Tanh
подходит для RNN
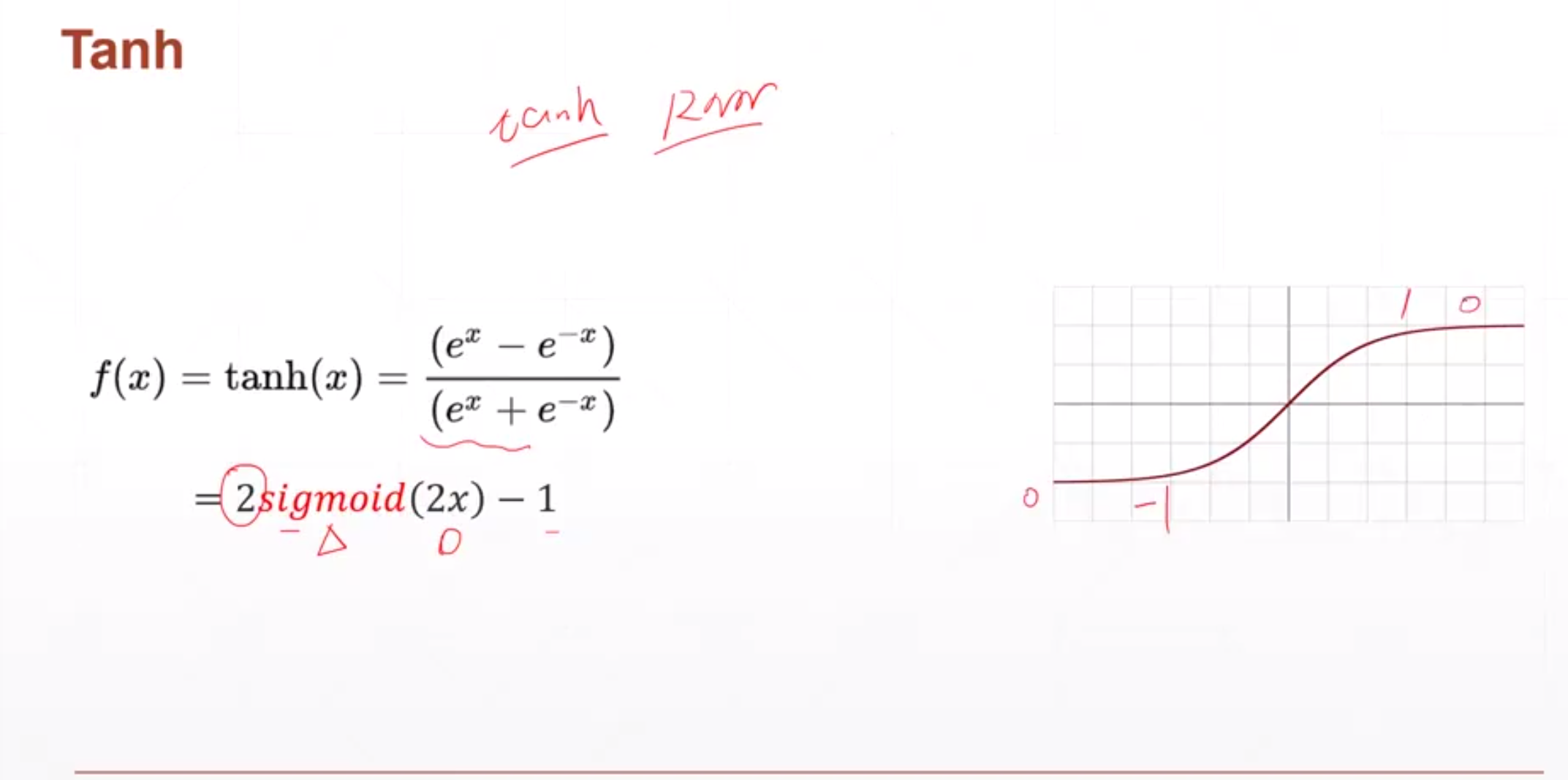
Функция активации ReLU

** API градиента **
Найдите информацию о градиенте функции потерь по параметрам

- torch.autograd.grad(loss, [w1, w2…])
-
Softmax
Преобразуйте данные в вероятность. Используя softmax, вы можете преобразовать все данные в 0–1, а сумма данных равна 1
Также вы можете сделать большие больше, а меньшие меньше.

вывод softmax



import torch
from torch.nn import functional as F
# 常见激活函数
a = torch.randn(10)
print(a)
print(torch.sigmoid(a))
print(torch.tanh(a))
print(torch.relu(a))
# autograd.grad 自动求导
x = torch.ones(1)
print(x)
w = torch.full([1], 2,) # 创建了一个包含一个元素且值为2的PyTorch Tensor
print(w)
w = w.type(torch.float32) # 更改w的类型
w.requires_grad_(requires_grad=True) # w初始化时设置需要求导信息
mse = F.mse_loss(torch.ones(1), x*w) # 求平均绝对误差。 torch.ones()是真实值,x*w是预测值
# torch.autograd.grad(y,[w]) 表示y对w求导。
torch.autograd.grad(mse, [w], retain_graph=True) # retain_graph=True 表示保留中间的计算图,以便在第二调用backward时不会引发错误
print(torch.autograd.grad(mse, [w]))
# loss.backward ?
x = torch.ones(1)
w = torch.full([1], 2)
w = w.type(torch.float32) # 下一行的需要梯度信息需要浮点类型数据才能有梯度信息,所以将w改为浮点类型。
w.requires_grad_()
mse = F.mse_loss(torch.ones(1), x*w)
print(mse)
mse.backward() # 对loss向后传播,把梯度信息存在.grad中。每个参数的梯度信息存储在.grad中
print(w.grad)
# softmax 求导
# F.softmax 放缩到0-1且和为10
a = torch.rand(3) # 生成3个0-1的随机数
print(a)
a.requires_grad_()
p = F.softmax(a, dim=0) # 将给定的数据转化为0-1范围内,且和为1
print(p)
p[1].backward(retain_graph=True) # 计算p[1]对张量a的梯度,并将该梯度存在a.grad中
print(p[1])
p1 = torch.autograd.grad(p[1], [a], retain_graph=True) # 计算p[1]对张量a的梯度,返回梯度值
print(p1) # (tensor([-0.1025, 0.2275, -0.1249]),) 只有p[1]的下标为正
print(a.grad) # tensor([-0.1025, 0.2275, -0.1249])
p[2].backward(retain_graph=True)
print(p[2]) # tensor(0.3571, grad_fn=<SelectBackward0>)
p2 = torch.autograd.grad(p[2], [a], retain_graph=True) # 计算p2对张量a的梯度,返回梯度值 只有p[2]的下标为正
print(p2) # (tensor([-0.1046, -0.1249, 0.2296]),)
print(a.grad) # tensor([-0.2072, 0.1025, 0.1046]) 这里的梯度累加了p[1]的和p[2]的梯度
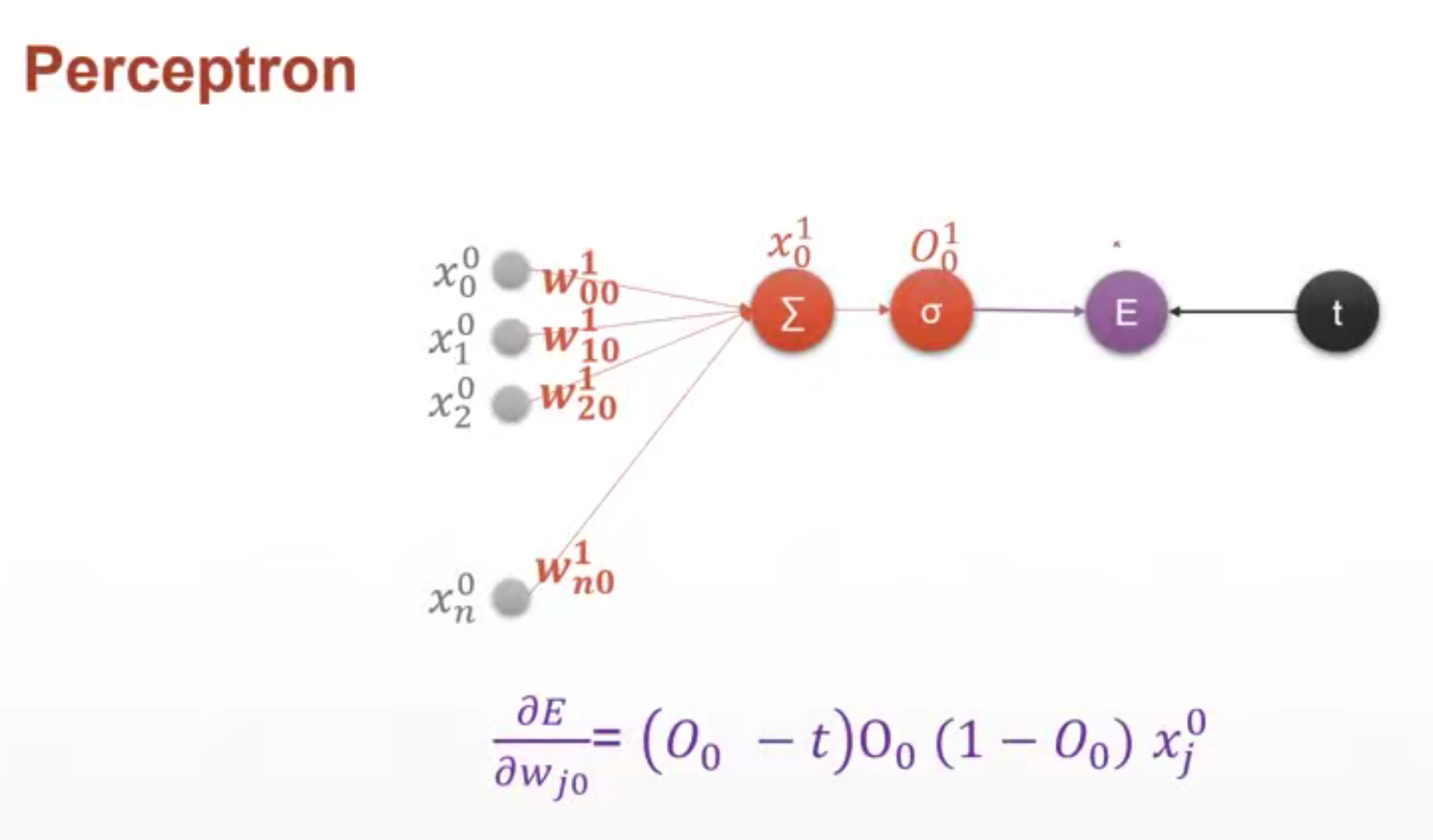
урок 19 Градиентный вывод перцептрона
персептрон с одним выходом

Верхний индекс 1 указывает на первый уровень
Нижний индекс i указывает на то, что узлом верхнего уровня является i , jУказывает, что узел текущего слояj

O должно представлять прогнозируемое выходное значение, а t представляет истинное значение.
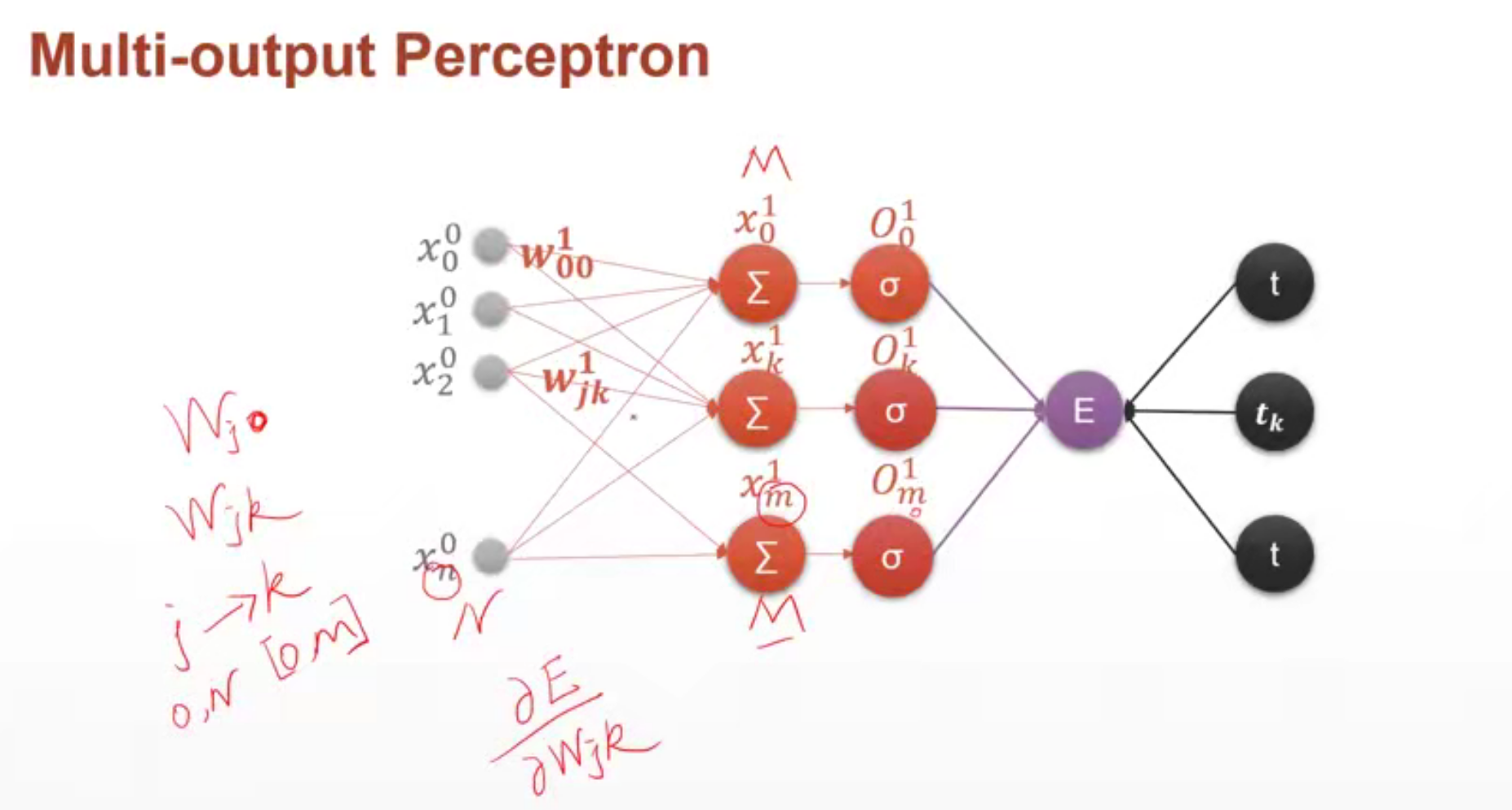
многовыходной перцептрон
import torch
from torch.nn import functional as F
# 单一输出感知机推导
x = torch.randn(1, 10)
w = torch.randn(1, 10, requires_grad=True) # 设置w需要保存梯度信息
o = torch.sigmoid(x@w.t()) # 得到1*1的输出结果
print(o.shape) # torch.Size([1, 1])
loss = F.mse_loss(torch.ones(1, 1), o) # 计算平均绝对误差。 真实值是(1, 1),预测值是o
print(loss.shape) # loss是个标量,所以shape是torch.Size([])
loss.backward() # 计算损失函数对参数的梯度信息
print(w.grad) # 输出损失函数对w的梯度。w是[1, 10]的tensor,所以w的梯度信息也是[1, 10]的。
# 多输出感知机
x = torch.randn(1, 10)
w = torch.randn(2, 10, requires_grad=True)
o = torch.sigmoid(x@w.t()) # 得到[1, 2]的输出
print(o.shape)
loss = F.mse_loss(torch.ones(1, 2), o)
print(loss.shape)
loss.backward() # 可以得到损失函数对所有需要梯度信息的参数的梯度信息
print(w.grad)
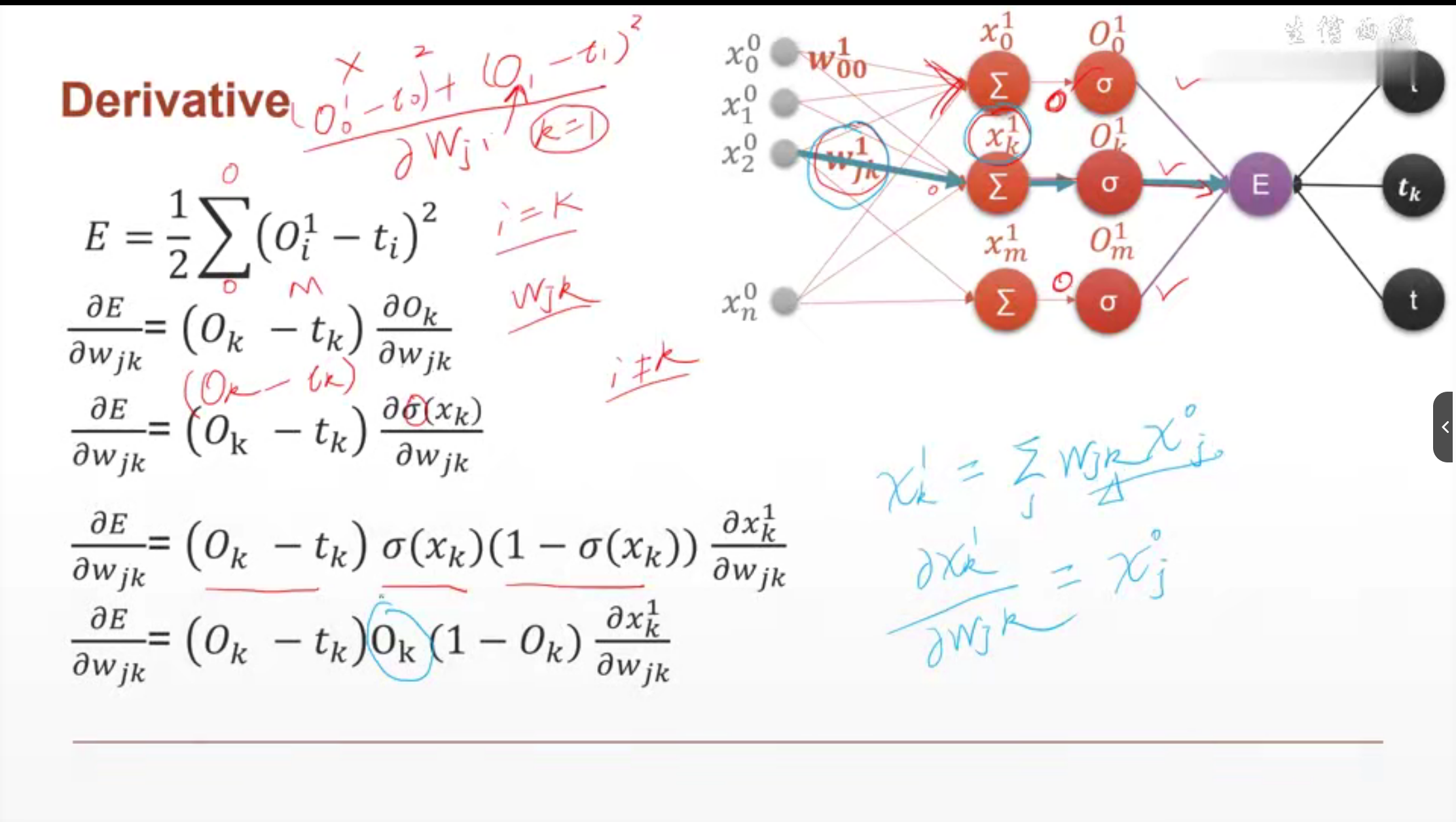
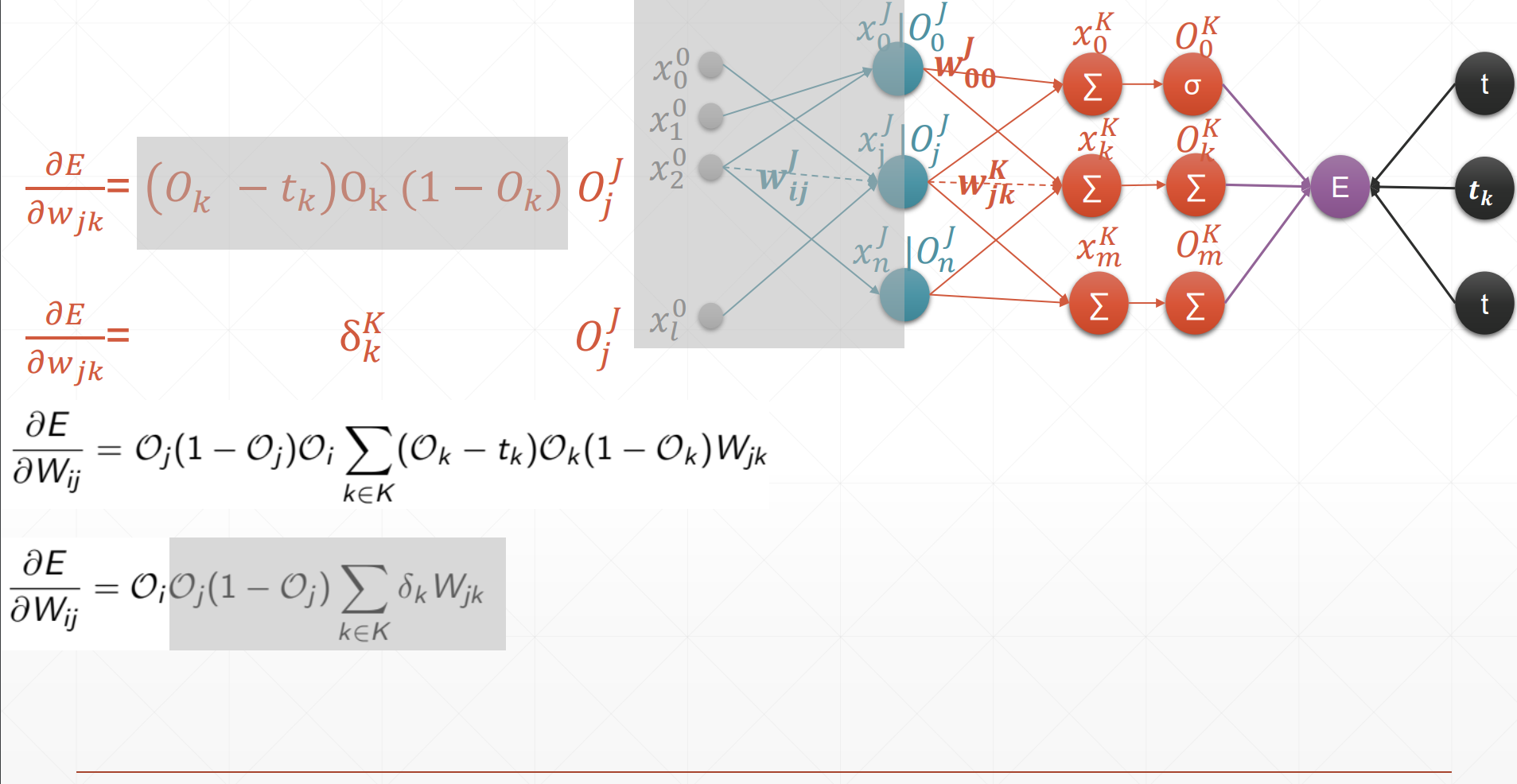
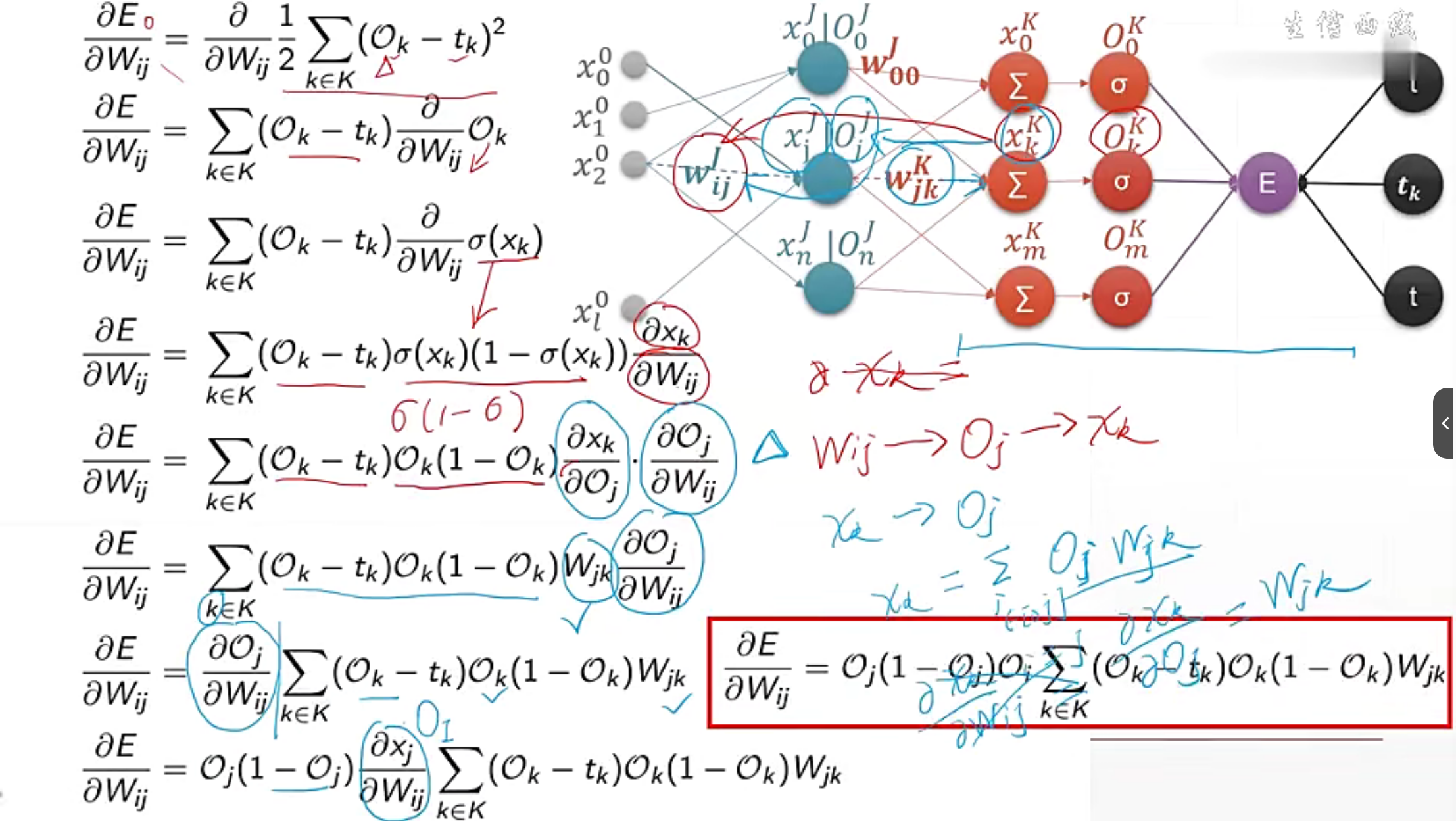
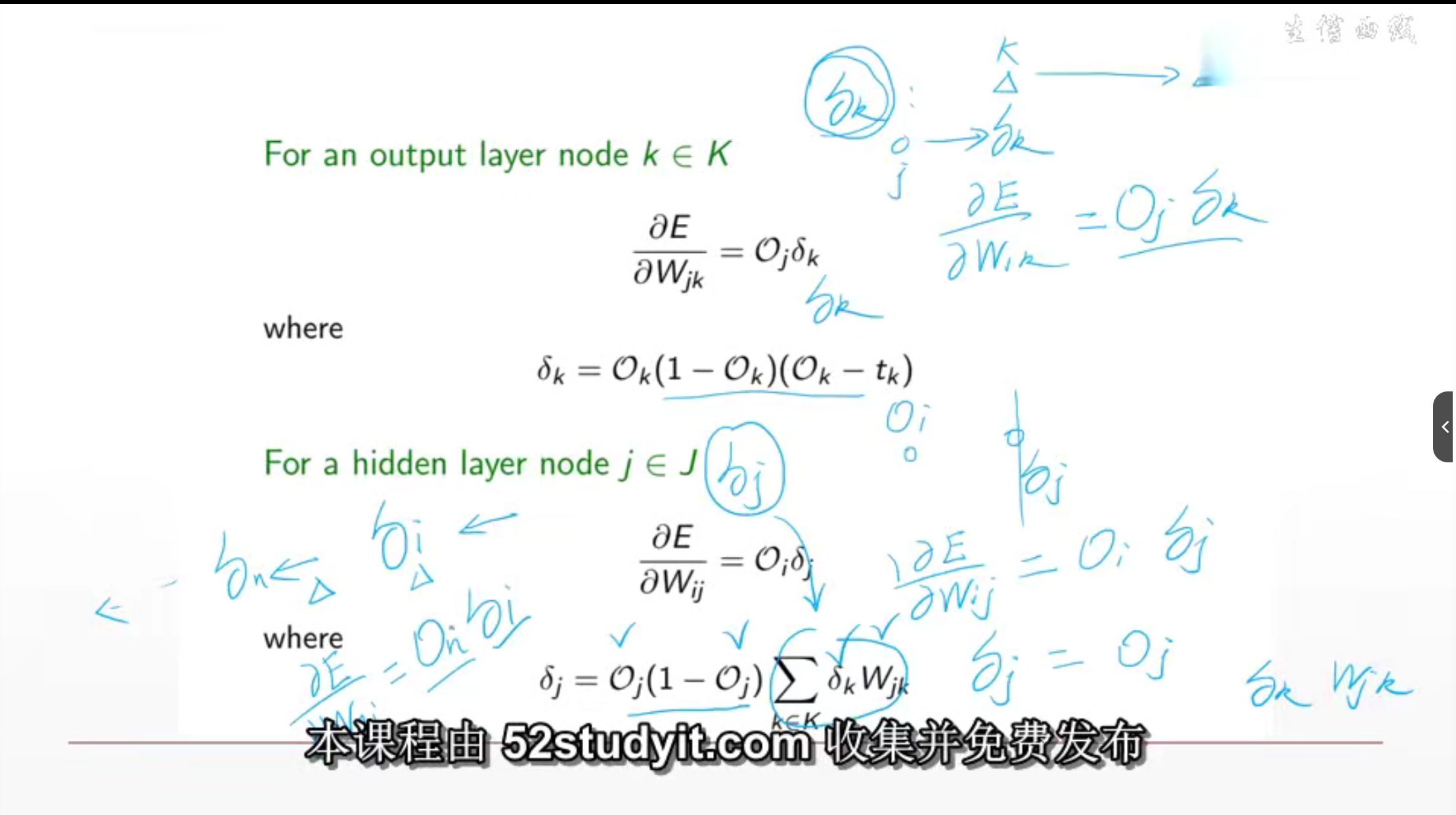
Процесс получения обратного распространения ошибки MLP
Это делается для того, чтобы найти ошибку обратного распространения каждого параметра для обновления параметров.
урок22 Оптимизация небольших примеров
Пример оптимизации 2D-функции
view_init() 用于设置三维坐标轴的视角
x.tolist() 将numpy转为list列表 pred.item返回值而不是tensor
tensor.item() 返回一维张量的数值而非tensor类型。
eg: a = torch.tensor(1.234) a.item()是个数值。a是张量。
# 2D函数优化实例
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import pyplot as plt
import torch
def himmelblau(x):
# f = (x^2 + y - 11)^2 + (x + y^2 - 7)^2
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2 # x[0]是x,x[1]是y
# Plot
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print("x,y range:", x.shape, y.shape)
X, Y = np.meshgrid(x, y)
Z = himmelblau([X, Y])
fig = plt.figure('himmelblau')
ax = fig.add_subplot(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30) # view_init() 用于设置三维坐标轴的视角
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# 梯度下降法求
x = torch.tensor([-4., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3) # Adam优化器,学习率1e-3
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad() # 梯度清零
pred.backward() # 生成x[0], x[1]的梯度信息
optimizer.step() # 更新参数信息
if step % 2000 == 0:
print(f"step={
step}, x = {
x.tolist()}, f(x) = {
pred.item()} ") # x.tolist() 将numpy转为list列表 pred.item返回值而不是tensor
Логистическая регрессия урок24
Логистическая регрессия, как ее называли ранее. Теперь это называется классификацией.
Разница между логистической регрессией и классификацией заключается в том, что логистическая регрессия не может напрямую использовать точность как ошибку.
Если вы используете MSE и делаете разницу между истинным значением и прогнозируемым значением так, что значение между ними становится все меньше и меньше, это интерпретируется как проблема регрессии
Если вы используете перекрестную энтропию, это интерпретируется как классификация.
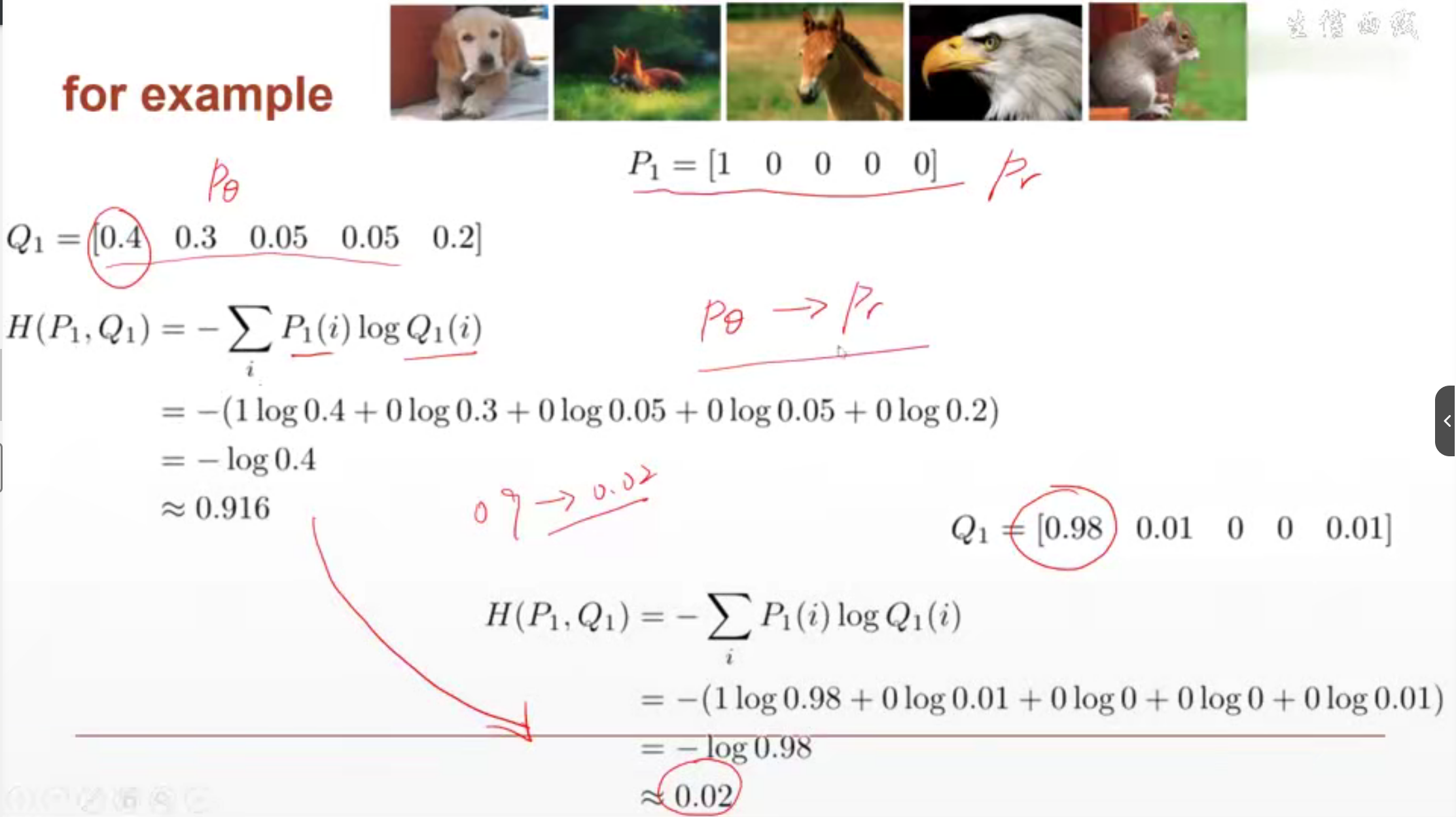
урок25 Перекрестная энтропия
Используется ли потеря для измерения расстояния между двумя объектами. Чем меньше интервал, тем меньше перекрестная энтропия. Чем больше интервал, тем больше перекрестная энтропия.


# practise
import torch
from torch.nn import functional as F
# Cross Entropy = softmax + log + nll_loss
x = torch.randn(1, 784)
w = torch.randn(10, 784)
logits = x@w.t()
pred = F.softmax(logits, dim=1)
pred_log = torch.log(pred)
print(F.cross_entropy(logits, torch.tensor([3])))
print(F.nll_loss(pred_log, torch.tensor([3]))) # 之前的softmax和log都做了,所以只需要nll_loss即可得到与上面一样的结果
урок26 Практическое решение проблемы мультиклассификации LR
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size = 200
learning_rate = 0.01
epochs = 10
# 加载数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 参数信息
# 784是输入,200是输出 前后相反
w1, b1 = torch.randn(200, 784, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\
torch.zeros(10, requires_grad=True)
torch.nn.init.kaiming_normal_(w1) # 用于对张量进行Kaiming正态分布初始化
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
# 向前传播
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x)
return x
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) # SGD: 随机梯度下降
criteon = nn.CrossEntropyLoss() # 交叉熵做loss
for eopch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
logits = forward(data) # 模型得到的预测值logits
loss = criteon(logits, target) # 真实值target和预测值logits之间的交叉熵损失函数
optimizer.zero_grad() # 清零梯度 每次计算前都要清零梯度,不让梯度累计
loss.backward() # 计算交叉熵损失函数对参数的梯度信息 (参数有w1 b1 w2 b2 w3 b3)
optimizer.step() # 更新参数梯度信息
if batch_idx % 100 == 0:
print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}".format(
eopch, batch_idx*len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28*28)
logits = forward(data) # # 模型得到的预测值logits
test_loss += criteon(logits, target).item() # 测试误差累加交叉熵损失函数值
pred = logits.data.max(1)[1] # logits.data 是获取 logits 张量的数据部分,即去除梯度信息,得到一个新的张量。
# .max(1) 是对 logits.data 进行操作,这个操作会返回两个值:最大值和最大值所在的索引。[1] 表示选择返回最大值所在的索引。
correct += pred.eq(target.data).sum() # 判断pred和target.data是否相等(eq),将相等的求和得到预测正确的数量。
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
урок28 Функция активации и ускорение графического процессора
# 使用GPU的code
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
"""
logits是模型的输出,通常是一个包含每个类别的得分张量,通常是[batch_size, num_classes], 分别表示批量大小、类别数量
logits.data是去除梯度信息只保留张量的数值数据。
.max(1)用于在张量的指定维度上找到最大值。多分类问题的得分分布在第二个维度上。 为什么找最大值? 找最大值是每个预测结果都有个值,取最可能的就是取得分值最大的。
[1]用于获取最大值的索引,即得分最高的类别的索引。
"""
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
урок29 МНИСТ
import torch
import torch.nn.functional as F
# 计算Accuracy的流程
logits = torch.rand(4, 10)
print(logits)
pred = F.softmax(logits, dim=1)
pred_label = pred.argmax(dim=1)
print(pred_label)
print(logits.argmax(dim=1))
label = torch.tensor([9, 3, 2, 4]) # 真实值
correct = torch.eq(pred_label, label) # 这是一个类型为byte的tensor
print("Accuracy: {}".format(correct.sum().float().item() / 4)) # 先求和,再将byte转为float,再取值,再/4
# MNIST测试集
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
урок30 Визуализация мудрости
Я буквально плакал «Нарушенный код»! ! !
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size = 200
learning_rate = 0.01
epochs = 10
# 导入数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# print(len(train_loader)) # 返回的是批次数,即总样本数/batch_size
# print(len(train_loader.dataset)) # 返回总样本数
# 创建多层感知机模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True), # inplace=True表示就地操作
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
# 重写了父类的方法
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0') # 使用索引为0的设备
net = MLP().to(device) # 将MLP导入device上计算。
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device) # 将交叉熵Loss导入device上计算。
# 创建visdom可视化
"""
viz.line: 创建一个折线图窗口
[0.] 指定初始x y轴的数据点
win='train_loss':指定窗口名称为train_loss。
opts 用于指定折线图选项。这里设置了标题为train loss
"""
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0 # 步长
# 开始训练
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda() # 将图片数据和真实值挪到GPU(device)上进行运算
logits = net(data) # 预测值 结果
loss = criteon(logits, target) # 损失
optimizer.zero_grad() # 清零梯度
loss.backward() # 保留参数的梯度信息
optimizer.step() # 根据参数的梯度信息以更新参数
global_step += 1
# 画折线。 纵坐标是loss的值。横坐标是步长
viz.line([loss.item()], [global_step], win='train_loss', update='append') # 更新方式为在后面append
# 输出
if batch_idx % 100 == 0:
print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}".format(
epoch, batch_idx*len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试集上的数据
test_loss = 0 # 测试集上的Loss
correct = 0 # 预测正确的个数
for data, target in test_loader:
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item() # 取item取值
pred = logits.argmax(dim=1) # 0-9每个都可能预测到。取概率最大的就是取得分最高的。得到其下标就是该值。dim=1表示求第一个维度。
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x') # images是可视化函数 用于显示图像诗句
# detach是将张量从计算图中分离出来。.cpu是转到cpu上。.numpy是转为numpy格式。
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
урок32 Train-Val-Test-Cross Validation
Обучите параметр обновления θ на обучающем наборе. Посмотрите на набор проверки, чтобы узнать, какая временная метка является лучшей и на какой временной метке она заканчивается. Тестовый набор предназначен для проверки эффективности модели
Проверочный набор отделен от исходного обучающего набора.
pred = logits.data.max(1)[1] # max(1) 表示在第一个维度上找到最大值。[1]用于返回最大值的索引,[0]用于返回最大值的数值。
урок32 Регуляризация


Регуляризация заключается в том, чтобы заставить веса стать равными 0 или приблизиться к 0, что снижает сложность модели.
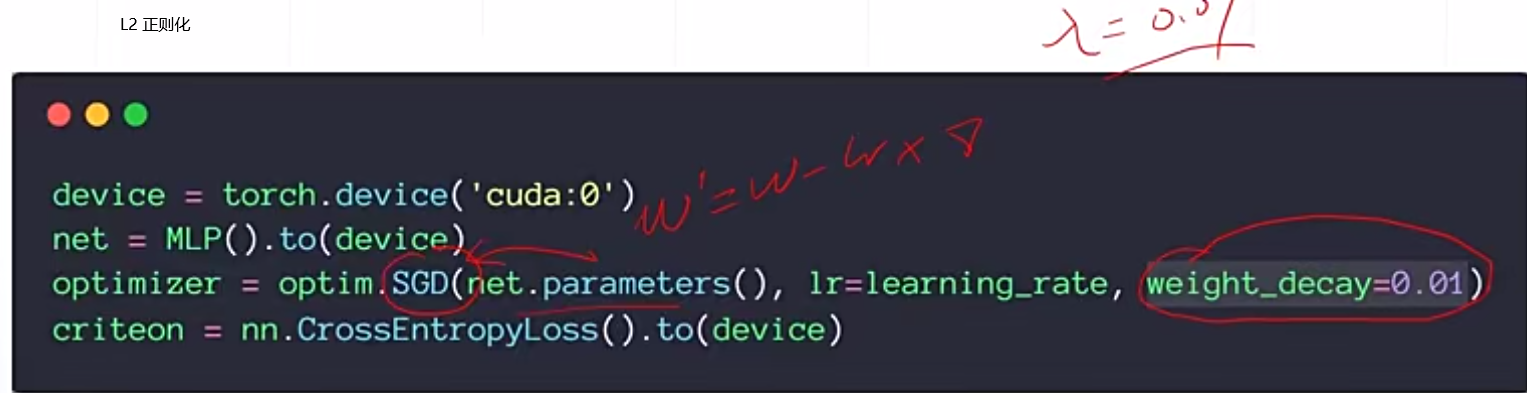
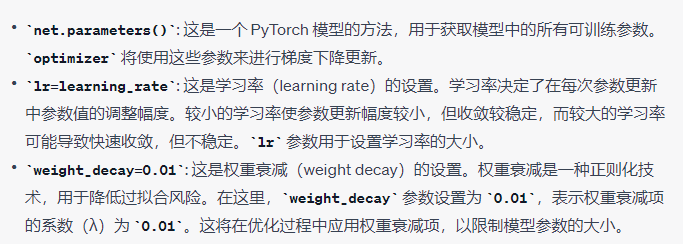

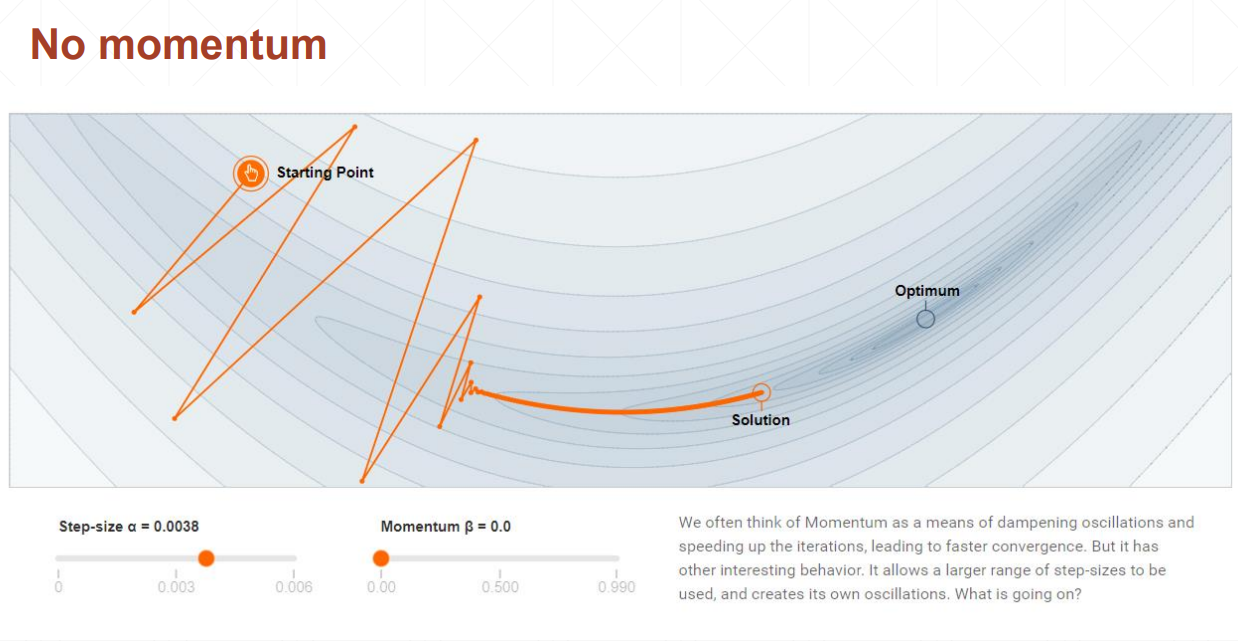
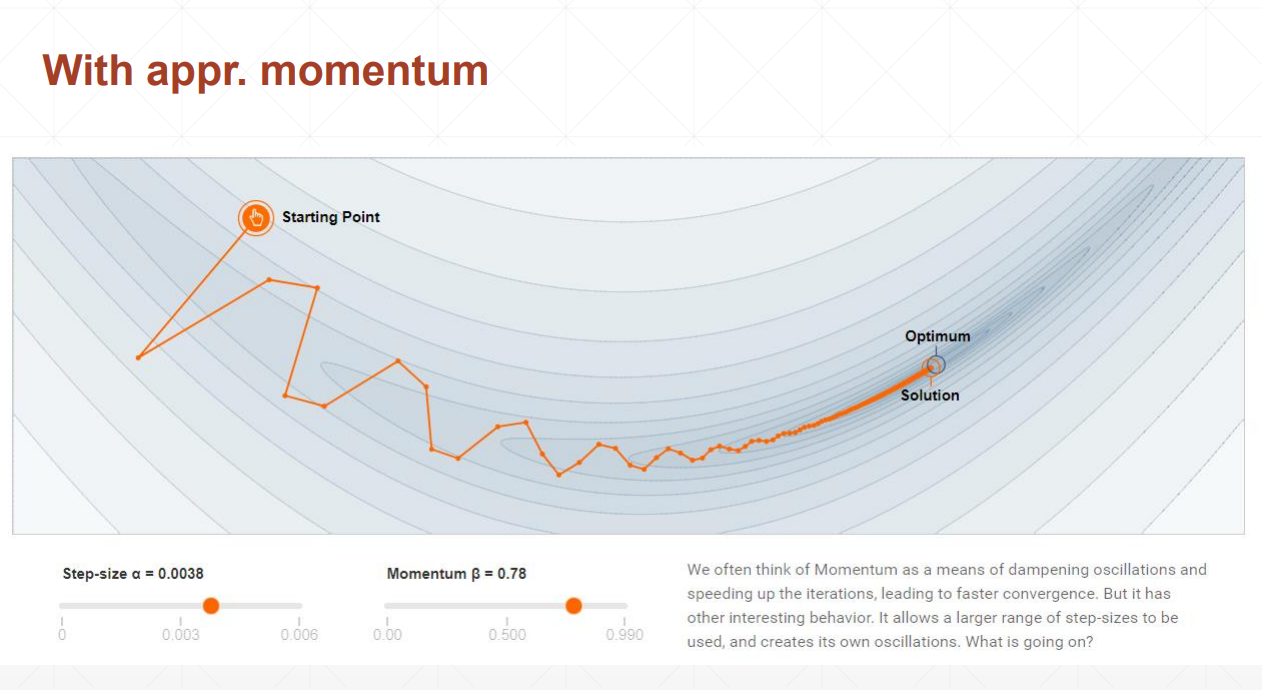
урок 34 Динамика и снижение скорости обучения
Импульс понимается как инерция.
Без импульса градиент сильно меняется, и потери тоже сильно меняются.
При наличии импульса изменение градиента будет небольшим.
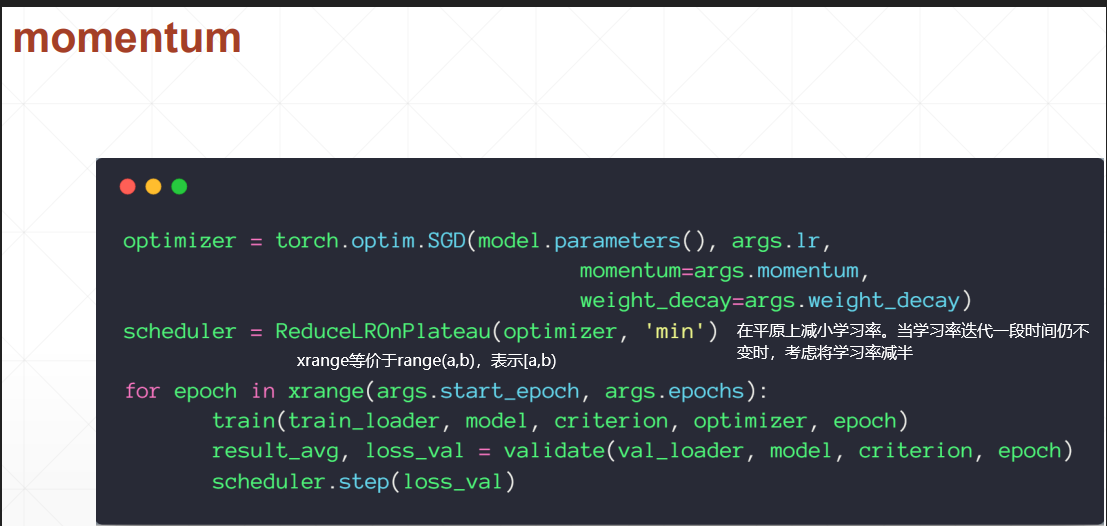
скорость обучения
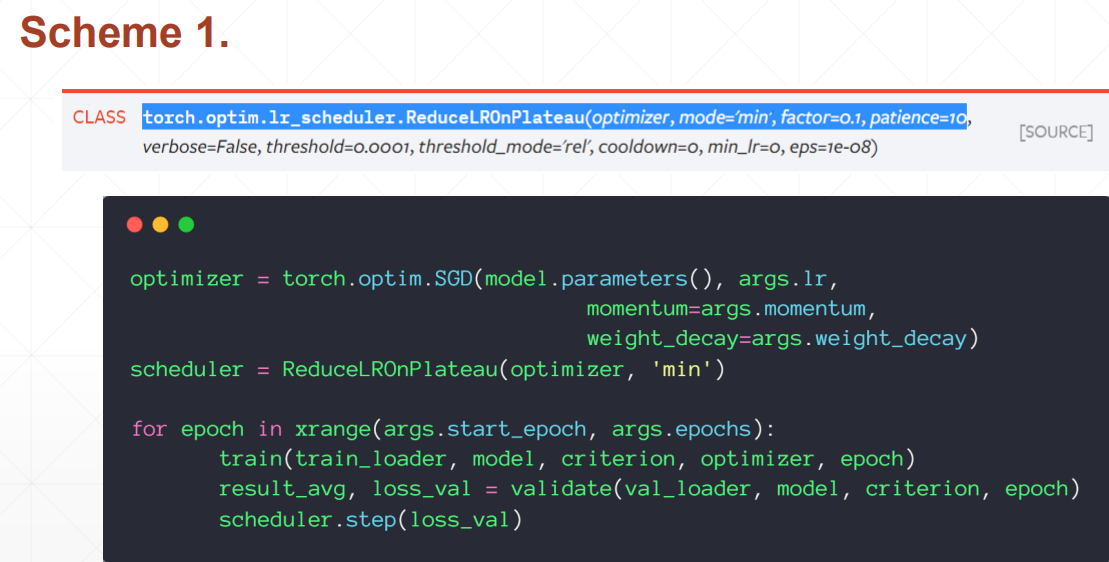
Если скорость обучения не меняется в течение шага, установите скорость обучения, уменьшаемую вдвое (ReduceLROnPlateau).
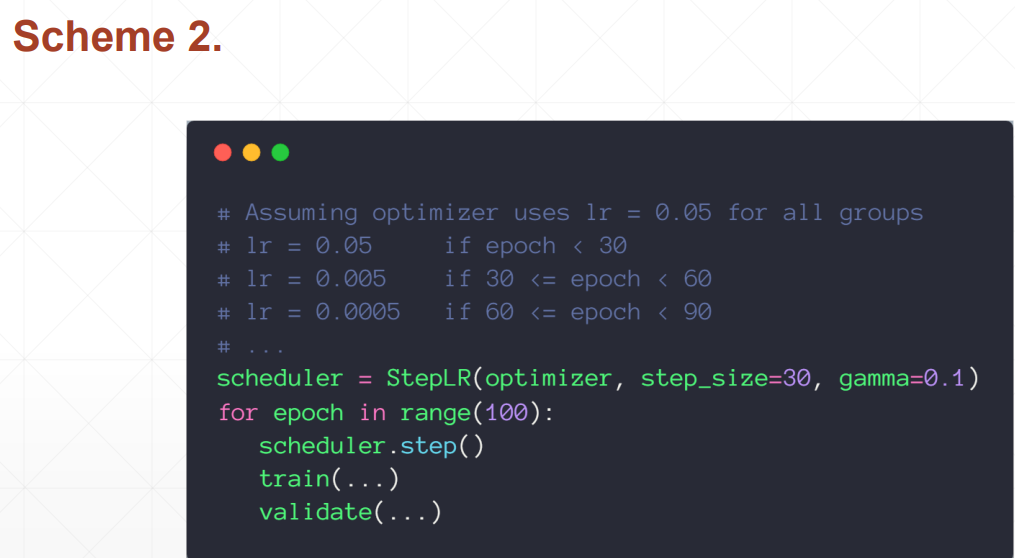
Согласно правилам, пусть скорость обучения становится любой, какой она есть каждый раз. несколько шагов.
урок35 с ранней остановкой и amp; выбывать
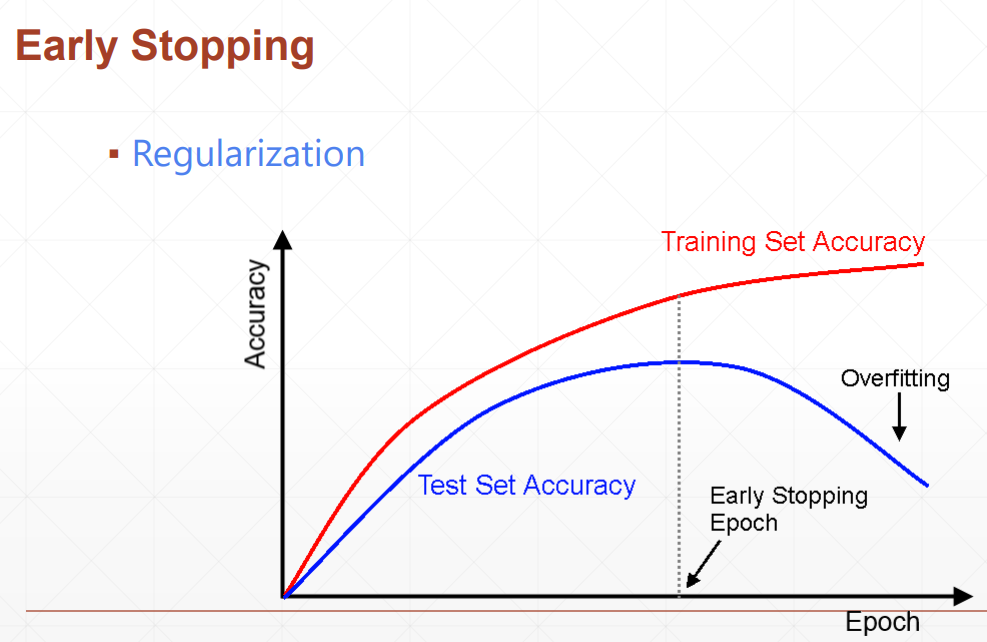

выбывать
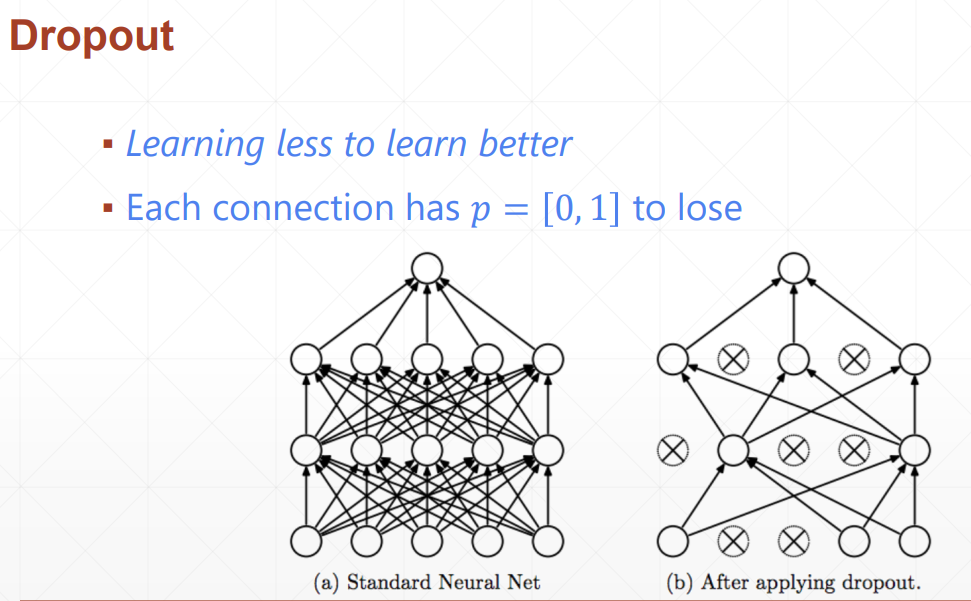



net_dropped.eval() — это метод PyTorch для переключения модели нейронной сети в режим оценки. В режиме оценки поведение модели претерпевает некоторые изменения и обычно используется для вывода или тестирования без обучения модели.
Когда вы вызываете net_dropped.eval(), он делает следующее:
Уровень пакетной нормализации: в режиме обучения уровень пакетной нормализации выполняет пакетную нормализацию на основе статистической информации каждой партии. Но в режиме оценки он использует фиксированную статистику, обычно вычисляемую на обучающем наборе. Это обеспечивает согласованность режима оценки независимо от входных данных.
Dropout: Если в модели используется слой Dropout, Dropout не будет отбрасывать выходные данные любого нейрона в режиме оценки. Это связано с тем, что вам обычно не нужно выполнять случайное отбрасывание при тестировании или выводе.
Параметр tensorflow — это вероятность сохранения узла, а Torch — вероятность удаления узла!
Расчет градиента. В режиме оценки PyTorch не рассчитывает градиенты, поскольку в режиме оценки обычно не выполняется обратное распространение ошибки (т. е. не проводится обучение).
Обычно после обучения модели вы вызываете model.eval(), чтобы убедиться, что модель находится в согласованном состоянии при выполнении вывода или тестирования. Это помогает обеспечить согласованное поведение модели в разных режимах. Если вы хотите вернуться в режим обучения, вызовите model.train().
Стохастический градиентный спуск
Стохастический градиентный спуск предназначен для пакетного получения параметров. Обычно параметры дифференцируются по всему набору данных.
Стохастический градиентный спуск (сокращенно SGD) — один из наиболее часто используемых алгоритмов оптимизации в машинном и глубоком обучении, используемый для обучения весов модели. минимизировать функцию потерь. В отличие от традиционных алгоритмов градиентного спуска, SGD использует небольшую часть обучающих данных вместо всего набора данных при обновлении весов на каждом шаге. Это делает его особенно подходящим для крупномасштабных наборов данных и глубоких нейронных сетей.
Ниже приведены основные особенности и принципы работы SGD:
Стохастичность: SGD является стохастическим в том смысле, что он случайным образом выбирает небольшую партию выборок из обучающих данных на каждой итерации для расчета градиента. Эта случайность помогает избежать застревания в локальных минимумах и позволяет алгоритму выскакивать из локальных оптимальных решений во время обучения.
Эффективность вычислений: поскольку SGD использует только небольшой пакет данных для расчета градиента, он обычно выполняется быстрее, чем пакетный градиентный спуск, который использует весь набор данных. Это особенно важно для крупномасштабных наборов данных.
Скорость обучения: SGD использует гиперпараметр, называемый скоростью обучения, для управления размером шага каждого обновления веса. Меньшая скорость обучения приведет к более медленной, но более стабильной сходимости, тогда как более высокая скорость обучения может привести к нестабильному обучению.
Расчет стохастического градиента: на каждой итерации SGD вычисляет градиент функции потерь относительно небольшого пакета данных и использует этот градиент для обновления весов модели. Этот расчет градиента выполняется с помощью алгоритма обратного распространения ошибки.
Мини-пакет. Небольшие пакеты данных в SGD часто называют мини-пакетами. Размер мини-пакета является важным гиперпараметром, который влияет на производительность и скорость сходимости алгоритма. Меньшие мини-пакеты могут привести к большей случайности, но также и к увеличению вычислительных затрат.
Конвергенция: SGD не гарантирует глобально оптимального решения, но часто способен прийти к разумному решению, особенно при использовании соответствующей стратегии планирования скорости обучения.
Планирование скорости обучения. Чтобы повысить производительность SGD, можно использовать стратегию планирования скорости обучения, то есть постепенное уменьшение размера скорости обучения в процессе обучения.
урок38 Сверточная нейронная сеть


import torch
from torch import nn
layer = nn.Conv2d(1, 3, kernel_size=3, stride=1, padding=1) # 1表示通道数,3表示卷积核数量
x = torch.rand(1, 1, 28, 28)
out = layer.forward(x) # 完成一次前向传播,即计算一次卷积结果
out = layer(x) # 推荐使用这个方法 完成一次前向传播,同时做pytorch自带的一些工作。
print(out)
layer.weight # 权重,需要梯度信息
layer.weight.shape # 权重的shape
Слой объединения и выборка
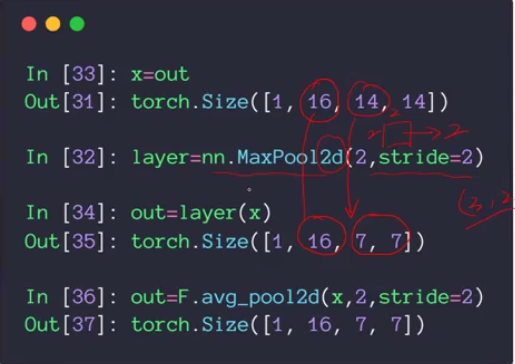
Выборка
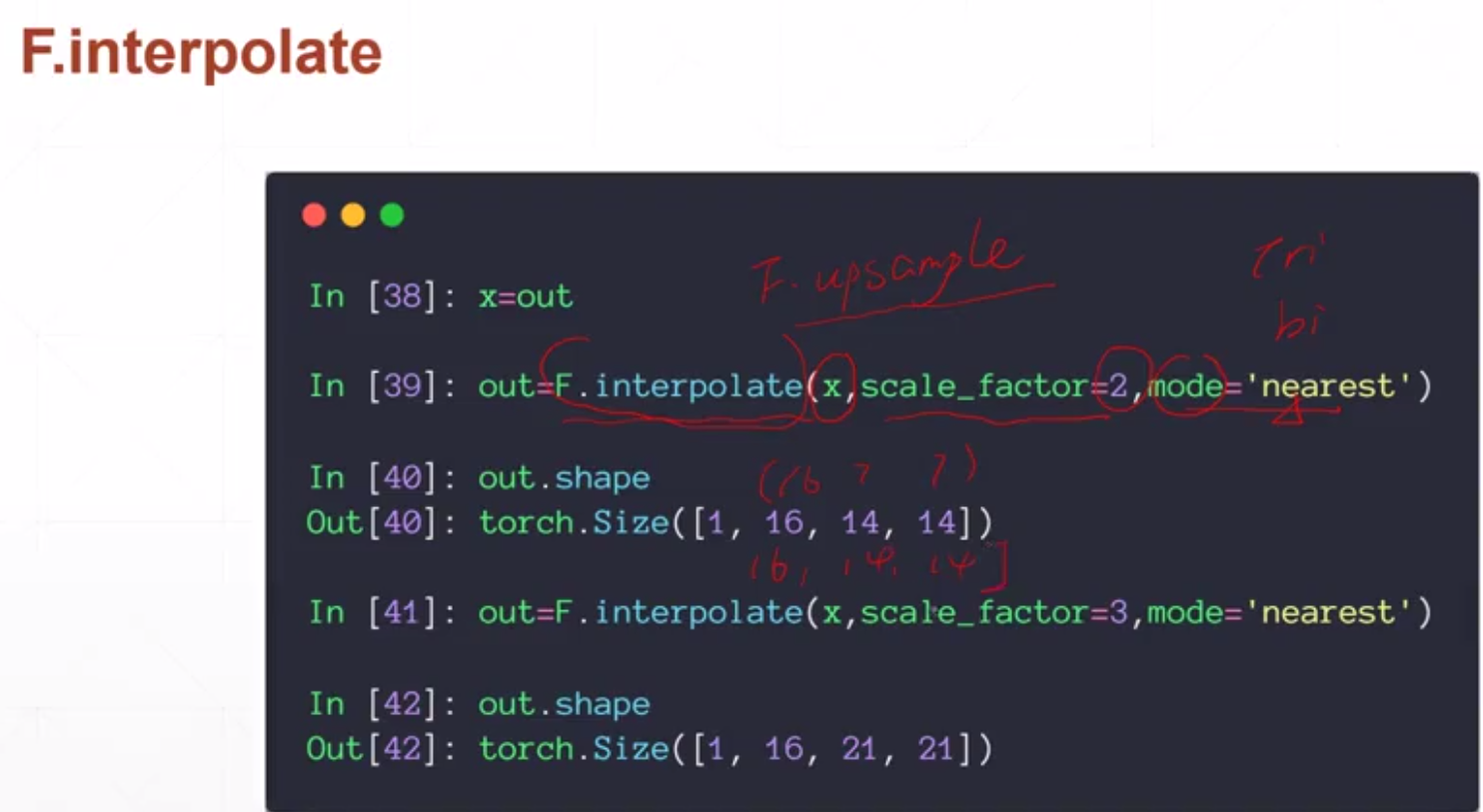
Пакетная нормализация
Зачем использовать пакетную нормализацию?
При использовании мелкой модели по мере обучения модели, когда параметры в каждом слое обновляются, выходные данные, близкие к выходному слою, с меньшей вероятностью будут радикально меняться. Для глубоких нейронных сетей по мере обучения сети настройка параметров предыдущего слоя приводит к изменению распределения входных данных последующего слоя.Каждый слой необходимо постоянно изменять в процессе обучения, чтобы адаптироваться к этому новому обучению. Распределение данных. Таким образом, даже если входные данные были стандартизированы, обновления параметров модели во время обучения все равно могут легко привести к изменениям в распределении входных данных на более поздних уровнях. слои будут накапливаться и усиливаться. В конечном итоге это приводит к резким изменениям выходных данных вблизи выходного слоя. Эта численная нестабильность часто затрудняет обучение эффективных глубоких моделей. Если распределение обучающих данных будет продолжать меняться в процессе обучения, это не только увеличит сложность обучения, повлияет на скорость обучения сети, но и увеличит риск переобучения.
так называемый Мудл
# 常用的flatten操作
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, input):
return input.view(input.size(0), -1)
увеличение данных
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.RandomVerticalFlip(), # 垂直反转
transforms.RandomRotation(15), # 旋转,-15°~ 15°
transforms.RandomRotation([90, 180, 270]), # 旋转
transforms.Resize([32, 32]), # 裁切,变成大小为32*32
transforms.RandomCrop([28, 28]), # 裁剪部分
transforms.ToTensor(), # 转为tensor类型
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 转到一个transform的list中,会对数据进行上面的操作。但是操作是随机的,并不一定会进行该操作。
Классическая нейронная сеть
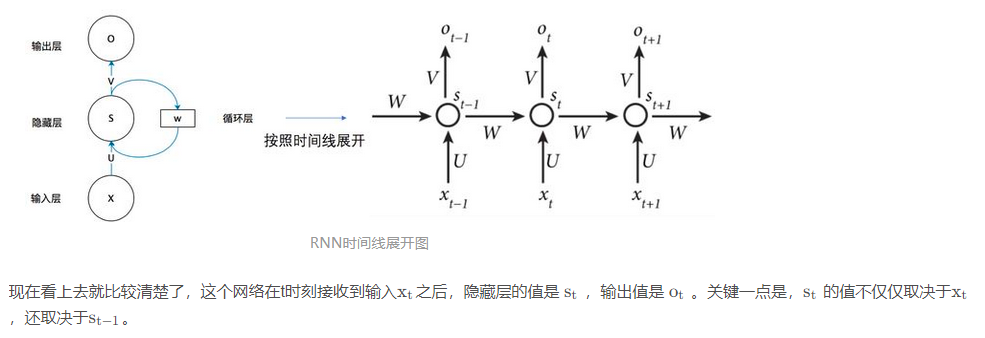
РНН
Самая большая разница между RNN и традиционными нейронными сетями заключается в том, что каждый раз предыдущий выходной результат переносится на следующий скрытый слой и обучается вместе.
ЛСТМ

Как понять встраивание
Дивергенция КЛ
Относительная энтропия может измерять расстояние между двумя случайными распределениями. Когда два случайных распределения одинаковы, их относительная энтропия равна нулю. Когда разница между двумя случайными распределениями увеличивается,
Разница между дивергенцией KL и дивергенцией JS
Среди них KL — асимметричная мера, JS — симметричная, а W — симметричная. Кроме того, мы предполагаем, что «разницей» между двумя распределениями является переменная x(x>0), тогда:
Чем больше x, тем больше KL, и когда он в определенной степени велик, например, когда нет пересечения, он всегда бессмысленен (или считается бесконечным).
Чем больше x, тем больше JS, и когда он в определенной степени велик, например, когда нет пересечения, он не меняется и всегда равен log2.
Чем больше x, тем больше w.