
В этой статье мы глубоко исследуем теоретическую основу, основные концепции и применение алгоритма Априори в практических задачах. В статье не только всесторонне анализируется механизм работы алгоритма, но и демонстрируются конкретные практические применения с помощью фрагментов кода Python. Кроме того, мы также предложили решения по оптимизации и методы расширения ограничений производительности алгоритма в среде больших данных и, наконец, пришли к уникальным техническим выводам.
Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в архитектуре интернет-сервисов, опыт разработки продуктов искусственного интеллекта и опыт управления командой.Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud, Профессионал в области управления проектами, а также исследования и разработки продуктов искусственного интеллекта с доходом в сотни миллионов.

1. Введение
Алгоритм Априори — это алгоритм, используемый для анализа часто встречающихся наборов элементов в наборах данных, а затем используемый для создания правил ассоциации. Этот алгоритм имеет широкое применение во многих областях, таких как интеллектуальный анализ данных, машинное обучение, анализ потребительской корзины и т. д.
Что такое майнинг правил ассоциации?
Анализ ассоциативных правил — это важная отрасль интеллектуального анализа данных, цель которой — обнаружение интересных ассоциаций или закономерностей между переменными в наборе данных.
Пример: предположим, что в данных о транзакциях розничного продавца, если покупатель покупает пиво, он, скорее всего, также купит картофельные чипсы. Здесь «пиво» и «картофельные чипсы» образуют правило ассоциации.
Что такое частый набор элементов?
Часто встречающийся набор элементов — это набор элементов, которые превышают или равны минимальному порогу поддержки в наборе данных.
Пример: если в данных о покупках в супермаркете комбинация «молоко» и «хлеб» часто встречается вместе в одной и той же корзине для покупок, а количество вхождений превышает минимальную поддерживаемую величину, то { «молоко», «хлеб»} является частым набор предметов.
Что такое поддержка и уверенность?
-
Поддержка: это частота появления набора элементов во всех транзакциях. Он используется для измерения общности набора элементов.
Пример: Если у нас 100 транзакций и 30 из них содержат «молоко», то поддержка «молока» составляет 30%.
-
Уверенность: это условная вероятность того, что B появится, когда появится A.
Пример: если 70% всех транзакций, содержащих «молоко», также содержат «хлеб», то уровень достоверности от «молока» к «хлебу» составляет 70%.
Важность алгоритма Априори
Алгоритм Априори широко используется в интеллектуальном анализе данных благодаря своей простоте и эффективности. Его можно использовать не только для выявления скрытых закономерностей в данных, но также в различных сценариях приложений, таких как рекомендации по продуктам, анализ поведения пользователей и сетевая безопасность.
Пример: на веб-сайтах электронной коммерции алгоритм Apriori можно использовать для анализа данных истории покупок пользователей для получения персонализированных рекомендаций и увеличения продаж и удовлетворенности пользователей.
Сценарии применения
Благодаря широкому спектру применения и гибкости алгоритм Apriori имеет широкое применение в следующих основных областях:
-
Анализ рыночной корзины. Поймите, какие продукты часто покупаются вместе, для эффективного размещения продуктов или стратегий продвижения.
-
Медицинская диагностика: анализируйте исторические данные пациентов, чтобы найти корреляцию между состояниями и вариантами лечения.
-
Сетевая безопасность: анализируйте сетевые журналы, чтобы обнаружить аномальные закономерности и предотвратить или обнаружить угрозы безопасности.
Благодаря этим определениям и примерам мы можем получить более полное представление об основных концепциях, важности и сфере применения алгоритма Априори, закладывая прочную основу для последующего технического анализа и практического применения.
2. Теоретическая основа
Прежде чем углубляться в алгоритм Априори, важно понять лежащую в его основе теоретическую основу. В этом разделе будут подробно представлены основные концепции анализа правил ассоциации, включая наборы элементов, поддержку, уверенность и подъем, а также способы использования этих концепций для поиска полезных правил ассоциации.
предметы и наборы предметов
-
Элемент: при интеллектуальном анализе правил ассоциации элемент обычно относится к элементу в наборе данных.
Пример. В корзине покупок супермаркета данные «молоко», «хлеб», «пиво» и т. д. представляют собой отдельные позиции.
-
Набор предметов: это коллекция элементов, которая может содержать один или несколько элементов.
Пример: {"Молоко", "Хлеб"} и {"Пиво", "Картофельные чипсы", "Хлеб"} являются наборами элементов.
Поддерживать
Поддержка — это показатель того, как часто набор элементов появляется во всем наборе данных.
! файл
{kind=link}
Уверенность
Доверие представляет собой вероятность того, что среди всех транзакций, содержащих набор элементов X, есть также транзакция, содержащая набор элементов Y.

Поднимать
Lift используется для измерения того, независимы ли вхождения наборов элементов X и Y друг от друга.

Априорный принцип
Принцип Априори является основой алгоритма Априори и основан на простом, но важном наблюдении: если набор элементов является частым, то и все его подмножества также должны быть частыми.
Пример: если {"Молоко", "Хлеб", "Пиво"} — часто встречающийся набор элементов, то {"Молоко", "Хлеб"}, {"Молоко", "Пиво"} и {"Хлеб", "Пиво" "} также должен быть частым набором элементов.
Благодаря приведенным выше концепциям и примерам мы должны глубже понять основную теорию анализа ассоциативных правил. Это обеспечивает прочную основу для нашего последующего подробного объяснения алгоритма Априори и его практического применения.
3. Обзор алгоритма Априори
Алгоритм Apriori был предложен Агравалом и Шрикантом в 1994 году для эффективного анализа наборов часто встречающихся элементов и создания правил ассоциации. Его название «Априори» происходит от латинского языка, что означает «из априорного знания». Это хорошо отражает основную идею алгоритма: использование известных частых наборов элементов (т. е. предшествующих знаний) для более эффективного поиска более крупных частых наборов элементов.
Шаги алгоритма
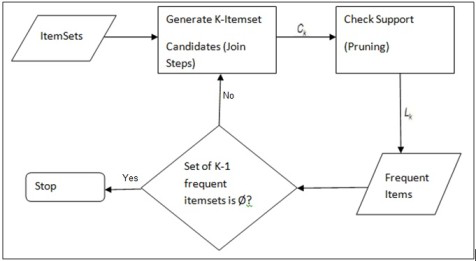
Процесс выполнения алгоритма Априори в основном состоит из двух этапов:
-
Генерация часто встречающихся наборов элементов: найдите все часто встречающиеся наборы элементов, соответствующие минимальному порогу поддержки.
-
Генерация правил ассоциации: создание правил ассоциации с высокой степенью достоверности из часто используемых наборов элементов.
Частое создание набора элементов
- Сканируйте набор данных, чтобы найти поддержку всех отдельных элементов, и отфильтруйте элементы, соответствующие минимальной поддержке.
- Создайте новый набор элементов-кандидатов, используя элементы, удовлетворяющие минимальной поддержке.
- Рассчитайте поддержку вновь созданного набора элементов-кандидатов и снова отфильтруйте.
- Повторяйте вышеуказанные шаги до тех пор, пока не перестанут создаваться новые часто встречающиеся наборы элементов.
Пример: предположим, что имеется набор данных о торговых транзакциях, который включает 5 транзакций. Первый шаг — подсчитать количество вхождений всех отдельных продуктов (таких как «молоко», «хлеб» и т. д.) в этих 5 транзакциях и отфильтровать те продукты, появление которых достигает минимальной поддержки.
Генерация правил ассоциации
- Для каждого часто встречающегося набора элементов сгенерируйте все возможные непустые подмножества.
- Для каждого сгенерированного правила ( A \Rightarrow B ) рассчитайте его достоверность.
- Правило является допустимым правилом ассоциации, если его достоверность соответствует минимальному требованию достоверности.
Пример. Для часто встречающегося набора элементов {"молоко", "хлеб", "масло"} возможные правила включают "молоко, хлеб->масло", "молоко, масло->хлеб" и т. д. Рассчитайте достоверность этих правил и отфильтруйте правила, соответствующие минимальной достоверности.
Преимущества и недостатки
преимущество
- Простой и понятный: алгоритм Apriori основан на интуитивных принципах и имеет простой процесс вычислений.
- Сильная масштабируемость: алгоритм можно применять к крупномасштабным наборам данных.
недостаток
- Интенсивные вычисления: для больших наборов данных может потребоваться создание большого количества наборов кандидатов.
- Многократное сканирование данных. Алгоритму необходимо несколько раз сканировать набор данных, чтобы вычислить поддержку набора элементов, что может быть неэффективно, если набор данных большой.
Пример: на веб-сайте электронной коммерции, содержащем миллионы данных о транзакциях, использование алгоритма Apriori может потребовать много вычислительных ресурсов и времени.
Благодаря приведенному выше подробному описанию и примерам мы должны иметь полное и глубокое понимание алгоритма Априори. Это заложило основу для нашего последующего технического анализа и практического применения.
4. Практическое применение
Поняв теоретическую основу и принцип работы алгоритма Априори, мы продолжим изучение его применения в практических сценариях. Особенно широко используется алгоритм Apriori в системах анализа корзин покупок и рекомендательных системах.
Чтобы лучше это проиллюстрировать, ниже будет показано, как реализовать алгоритм Apriori через Python, и продемонстрируем его на простом наборе данных о покупках.
Анализ корзины покупок
Анализ рыночной корзины — очень популярный метод в сфере розничной торговли, который используется для выявления правил связи между продуктами, приобретенными покупателями.
ввод и вывод
- Входные данные: набор данных о транзакциях, каждая транзакция содержит несколько приобретенных товаров.
- Результат: правила ассоциации, которые удовлетворяют минимальной поддержке и минимальному доверию.
Код реализации Python
Сначала импортируйте необходимые библиотеки:
from itertools import chain, combinations
Затем определите несколько вспомогательных функций:
# 生成候选项集的所有非空子集
def powerset(s):
return chain.from_iterable(combinations(s, r) for r in range(1, len(s)))
# 计算支持度
def calculate_support(itemset, transactions):
return sum(1 for transaction in transactions if itemset.issubset(transaction)) / len(transactions)
Теперь реализуем алгоритм Априори:
def apriori(transactions, min_support, min_confidence):
# 初始化频繁项集和关联规则列表
frequent_itemsets = []
association_rules = []
# 第一步:找出单项频繁项集
singletons = {frozenset([item]) for transaction in transactions for item in transaction}
singletons = {itemset for itemset in singletons if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(singletons)
# 迭代找出所有其他频繁项集
prev_frequent_itemsets = singletons
while prev_frequent_itemsets:
# 生成新的候选项集
candidates = {itemset1 | itemset2 for itemset1 in prev_frequent_itemsets for itemset2 in prev_frequent_itemsets if len(itemset1 | itemset2) == len(itemset1) + 1}
# 计算支持度并筛选
new_frequent_itemsets = {itemset for itemset in candidates if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(new_frequent_itemsets)
# 生成关联规则
for itemset in new_frequent_itemsets:
for subset in powerset(itemset):
subset = frozenset(subset)
diff = itemset - subset
if diff:
confidence = calculate_support(itemset, transactions) / calculate_support(subset, transactions)
if confidence >= min_confidence:
association_rules.append((subset, diff, confidence))
prev_frequent_itemsets = new_frequent_itemsets
return frequent_itemsets, association_rules
Примеры и вывод
Допустим, у нас есть следующий простой набор данных о покупках:
transactions = [
{'牛奶', '面包', '黄油'},
{'啤酒', '面包'},
{'牛奶', '啤酒', '黄油'},
{'牛奶', '鸡蛋'},
{'面包', '鸡蛋', '黄油'}
]
Вызовите алгоритм Априори:
min_support = 0.4
min_confidence = 0.5
frequent_itemsets, association_rules = apriori(transactions, min_support, min_confidence)
print("频繁项集:", frequent_itemsets)
print("关联规则:", association_rules)
Вывод может быть следующим:
频繁项集: [{'牛奶'}, {'面包'}, {'黄油'}, {'啤酒'}, {'鸡蛋'}, {'牛奶', '面包'}, {'牛奶', '黄油'}, {'面包', '黄油'}, {'啤酒', '黄油'}, {'面包', '啤酒'}]
关联规则: [(('牛奶',), ('面包',), 0.6666666666666666), (('面包',), ('牛奶',), 0.6666666666666666), ...]
Благодаря этому практическому применению мы не только узнали, как реализовать алгоритм Apriori на Python, но и узнали о его конкретном применении в анализе потребительской корзины. Это дает полезные рекомендации для дальнейших исследований и практического применения.
5. Оптимизация производительности и расширение
Хотя алгоритм Априори широко используется во многих областях, его производительность на больших наборах данных не является удовлетворительной. Это связано с тем, что требуется многократное сканирование набора данных и создание большого количества наборов кандидатов. В этом разделе мы обсуждаем решения по оптимизации производительности и методы расширения этих проблем.
Стратегия оптимизации
К основным методам оптимизации алгоритма Априори относятся:
Уменьшите количество сканирований данных
Поскольку алгоритму Apriori необходимо сканировать весь набор данных в каждом раунде для расчета поддержки, интуитивно понятный метод оптимизации состоит в уменьшении количества сканирований данных.
Пример. Построив инвертированный индекс элементов транзакций, вы можете найти поддержку любого набора элементов сразу после одного сканирования набора данных.
Использование технологии сжатия данных
Объем вычислений можно уменьшить за счет сжатия данных транзакций, например использования битовых векторов для представления транзакций.
Пример: если в наборе данных 100 элементов, каждая транзакция может быть представлена 100-битным битовым вектором. Такой подход может существенно снизить требования к хранению данных.
Используйте технологию хеширования
Вычисление поддержки можно ускорить, используя хеш-таблицу для хранения наборов кандидатов и их количества.
Пример. При создании набора элементов-кандидатов можно использовать хэш-функцию для сопоставления набора элементов с местоположением в хеш-таблице и увеличения соответствующего счетчика в этом месте.
метод расширения
Распараллеливание
Алгоритм Apriori можно расширить за счет распараллеливания данных или задач, чтобы использовать преимущества мультипроцессоров или распределенных вычислительных сред.
Пример. В распределенной системе набор данных можно разделить на несколько подмножеств, а наборы поддерживаемых и часто встречающихся элементов можно рассчитывать параллельно на каждом узле.
Поддержка приблизительного майнинга
Для некоторых сценариев приложений абсолютно точный анализ частого набора элементов может не потребоваться. В этом случае для ускорения расчета можно использовать аппроксимационные алгоритмы.
Пример. Используйте метод Монте-Карло или другие методы случайной выборки, чтобы оценить часто встречающиеся наборы элементов для всего набора данных с помощью частичных данных.
Интегрируйте другие алгоритмы интеллектуального анализа данных
Алгоритм Apriori можно использовать в сочетании с другими алгоритмами интеллектуального анализа данных или машинного обучения для решения более сложных задач.
Пример. В системе рекомендаций помимо использования алгоритма Apriori для поиска часто встречающихся наборов элементов также можно использовать алгоритм кластеризации для группировки пользователей для получения более персонализированных рекомендаций.
Благодаря этим методам оптимизации и расширения мы можем не только повысить производительность алгоритма Apriori в средах больших данных, но и расширить область его применения. Они дают полезные направления для дальнейших исследований и приложений.
6. Резюме
Благодаря обсуждению в этой статье мы не только получим всестороннее и глубокое понимание алгоритма Априори, но и освоим его применение в практических задачах, особенно в системах анализа корзин покупок и рекомендательных системах. Однако мы также заметили ограничения этого алгоритма при работе с крупномасштабными данными.
технические идеи
-
Баланс между поддержкой и доверием. В практических приложениях выбор подходящих порогов поддержки и доверия — это искусство. Слишком низкий порог может привести к появлению большого количества несущественных правил ассоциации, а слишком высокий порог может привести к пропуску некоторых полезных правил.
-
Проблемы реального времени: Что касается динамически изменяющихся наборов данных, то, как реализовать анализ алгоритма Apriori в реальном времени или почти в реальном времени, также является вопросом, заслуживающим внимания. Это особенно важно в сценариях быстрого реагирования, таких как электронная коммерция.
-
Многомерный и многоуровневый анализ: существующий алгоритм Apriori в основном фокусируется на уровне одного набора элементов. В будущем мы можем рассмотреть, как расширить его до многомерного или многоуровневого анализа правил ассоциации.
-
Интеграция алгоритмов и моделей. Будущие направления исследований могут больше сосредоточиться на интеграции интеллектуального анализа ассоциативных правил с другими моделями машинного обучения (такими как нейронные сети, деревья решений и т. д.) для решения более сложных проблем.
В будущей работе ключевыми направлениями исследований станут изучение актуальности и прикладной ценности этих технических идей, а также более тесная интеграция алгоритма Apriori с современными вычислительными архитектурами (такими как графические процессоры, распределенные вычисления и т. д.).
Короче говоря, алгоритм Apriori имеет широкие перспективы применения в области интеллектуального анализа данных и корреляционного анализа. Однако для того, чтобы он лучше адаптировался к масштабу и сложности современных данных, необходимы дополнительные исследования и исследования в области оптимизации алгоритмов и расширения приложений. Я надеюсь, что эта статья предоставит полезную информацию и вдохновит вас на изучение и применение в этой области.
Microsoft официально запускает новое «приложение для Windows» .NET 8, последняя версия LTS. Xiaomi официально объявила, что Xiaomi Vela имеет полностью открытый исходный код, а базовым ядром является NuttX Alibaba Cloud 11.12. Причина сбоя раскрыта: Служба ключей доступа (Access) Ключевое) исключение Vite 5 официально выпустил отчет GitHub: TypeScript заменяет Java и становится третьим по популярности языком Предлагает вознаграждение в сотни тысяч долларов за переписывание Prettier на Rust Спрашивает автора открытого исходного кода: «Проект еще жив?» Очень грубо и неуважительный Bytedance: использование искусственного интеллекта для автоматической настройки операторов параметров ядра Linux. Магическая операция: отключить сеть в фоновом режиме, деактивировать широкополосную учетную запись и заставить пользователя сменить оптический модем.Следуйте за TechLead и делитесь всесторонними знаниями об искусственном интеллекте. Автор имеет более чем 10-летний опыт работы в архитектуре интернет-сервисов, опыт разработки продуктов искусственного интеллекта и опыт управления командой.Он имеет степень магистра Университета Тунцзи в Университете Фудань, член Лаборатории интеллекта роботов Фудань, старший архитектор, сертифицированный Alibaba Cloud, Профессионал в области управления проектами, а также исследования и разработки продуктов искусственного интеллекта с доходом в сотни миллионов. Если это поможет, обратите больше внимания на TeahLead KrisChang, более 10 лет опыта работы в Интернете и индустрии искусственного интеллекта, более 10 лет опыта управления техническими и бизнес-командами, степень бакалавра в области разработки программного обеспечения от Tongji, степень магистра в области инженерного менеджмента. из Фуданя, сертифицированный Alibaba Cloud старший архитектор облачных сервисов, руководитель подразделения продуктов искусственного интеллекта с доходом более 100 миллионов долларов.