Почему бы не хэш (он же хэш )
- Хэш-таблица — это хеш-таблица.Принцип состоит в том, чтобы использовать хеш-функцию для преобразования данных, которые мы храним, в хэш-значение в форме ключевого слова, а затем сохранять данные в памяти в соответствии с хеш-значением.
- Независимо от того, читаете ли вы или записываете, хэш выполняется быстрее, чем дерево, так зачем выбирать древовидную структуру в качестве структуры индекса? Потому что для группировки, сортировки и сравнения временная сложность хэш-индекса вырождается до O(n), а в практических приложениях время относительно велико, поскольку объем данных составляет миллионы уровней.
- В хеш-алгоритме будут хеш-конфликты.Хотя используется функция возмущения, после большого объема данных все равно будет неравномерное распределение ( функция возмущения 1 , функция возмущения 2 ).
Почему бы не использовать двоичное дерево
- Каждый узел двоичного дерева разделен только на две вилки, и каждый узел может хранить только одну запись.По мере увеличения объема данных высота дерева будет значительно увеличиваться, и чем выше высота, тем медленнее скорость запроса.
- После увеличения высоты число становится списком, а временная сложность приближается к O (n).
Почему бы не использовать B-деревья
- Количество узлов в каждом слое B-дерева очень велико, а количество слоев очень мало.По сравнению с бинарным деревом количество дисковых операций ввода-вывода уменьшено, но каждый узел хранит данные, и запрос требует обход порядка, что не является лучшим способом быстрого поиска данных.
АВЛ-дерево
-
При условии баланса: абсолютное значение (коэффициент баланса) разницы высот между левым и правым поддеревьями каждого узла не превышает 1. Другими словами, дерево AVL по сути представляет собой двоичное дерево поиска с функцией баланса. Хотя число сбалансировано и запрос выполняется быстрее, при вставке данных для достижения баланса требуется несколько вращений. Когда объем данных велик, ротация занимает особенно много времени.
красное черное дерево
- Несбалансированное двоичное дерево, но данные большие, и запрос будет трудоемким.
B-дерево
- Во время ввода-вывода компьютерных данных данные запроса не используют непрерывное чтение и запись. Используйте 4k или N*4k для чтения и записи. Преимущество этого в том, что запрос выполняется быстрее.
- В этом блоке данных 4к. Листовые узлы B-дерева хранят ключи и данные. Таким образом, чем больше объем данных, тем больше данных содержится в этом блоке данных. Если данные + ключ достигают 2к. Тогда каждый узел может поместить только 2 данных.
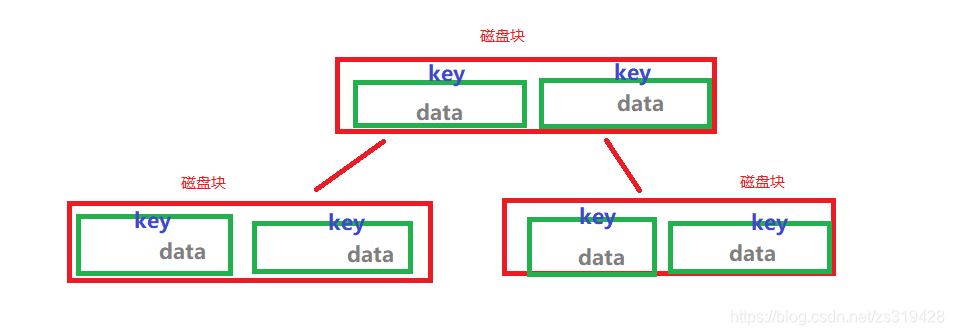
Зачем использовать дерево B+ вместо дерева B?
- Дерево B+ усовершенствовано на основе дерева B. Данные сохраняются только на листовых узлах, а между листовыми узлами добавляется связанный список. Таким образом, при получении узлов не требуется обход по порядку, Это удобно для быстрого поиска данных и является лучшим способом уменьшить количество операций ввода-вывода на диске.
