архитектура
Всем механизмам распределенных вычислений нужны менеджеры ресурсов кластера, например, программы MapReduce и Spark можно запускать в кластерах YARN или Mesos. Flink также является распределенным вычислительным движком.Для запуска программы Flink также требуется менеджер ресурсов. Чтобы изучить каждый распределенный вычислительный движок, первое, что нам нужно выяснить, это то, как разрабатываемое нами распределенное приложение выполняется в кластере, что обязательно потребует взаимодействия с менеджером ресурсов. Фактически управление ресурсами можно рассматривать как абстракцию кластера.
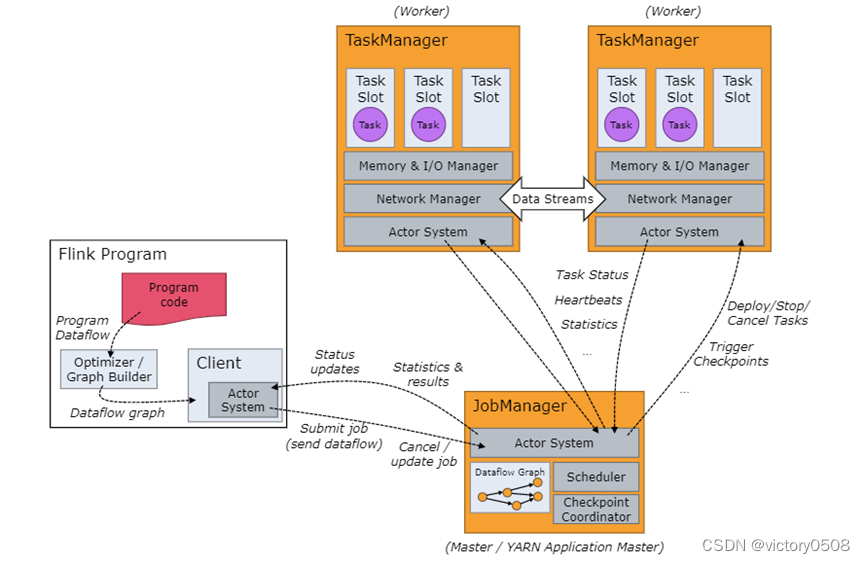
Давайте рассмотрим важные роли, которые будет выполнять кластер Flink.
- клиент
Клиент преобразует написанный код в поток данных программы, оптимизирует поток данных, создает график потока данных, а затем отправляет задание в JobManager. Код Flink, который мы пишем, в основном используется для описания того, как программа Flink должна выполняться в кластере.Конечно, кластер Flink не выполняется последовательно, как запуск написанной автономной программы. Он будет принимать задания только одно за другим, а затем запускать задачи в задании одну за другой.
- Менеджер по работе
Диспетчер заданий фактически является диспетчером заданий кластера Flink, который отвечает за планирование и управление вычислительными ресурсами кластера.
- Диспетчер задач
Кластер часто состоит из множества диспетчеров задач, которые отвечают за управление и выполнение определенных задач. Диспетчер задач и диспетчер задач также могут взаимодействовать друг с другом.
| компоненты |
использовать |
выполнить |
| Флинк-клиент |
Скомпилируйте пакетное или потоковое приложение в граф потока данных, который затем будет отправлен в JobManager. |
|
| JobManager |
Узел управления системы Flink управляет всеми диспетчерами задач и решает, какие диспетчеры задач должны выполнять пользовательские задачи. Существует три режима отправки заданий в JobManager. Режим приложения Режим работы Режим сеанса |
|
| Диспетчер задач |
Узел бизнес-исполнения системы Flink выполняет определенные пользовательские задачи и задания Flink . |
планирование
Flink определяет ресурсы выполнения через слоты задач. Каждый диспетчер задач имеет один или несколько слотов задач, и каждый слот задач может запускать конвейер, состоящий из нескольких параллельных задач. Такой конвейер состоит из нескольких последовательных задач.
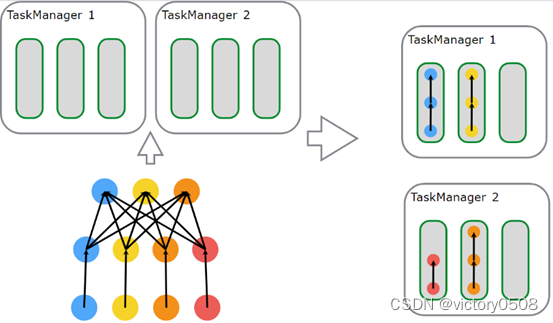
Ресурсы, которые может использовать каждый слот, фиксированы.Например, если три слота настроены в TaskManager, память, которую может использовать каждый слот, составляет 1/3 памяти, управляемой TaskManager. Конкуренция за ресурсы памяти между слотами отсутствует. Flink позволяет пользователям настраивать количество слотов TaskManager.Если количество слотов равно 1, это означает, что каждая задача выполняется в независимой JVM. И если он больше 1, это означает, что в одной JVM выполняется несколько задач.
Каждый запуск слота может запускать одну задачу. Если в задании много операторов и параллелизма, оно будет содержать много задач.В стандартной конфигурации кластера Flink задачи могут разделять слоты. То есть несколько задач могут быть запущены в одном слоте.
Клиент анализирует код Flink в JobGraph и упаковывает некоторые подзадачи в задачу, и каждая задача выполняется в потоке. Каждая задача запускается в слоте в TaskManager. Для потоковой обработки Flink поместит полный конвейер в слот.
Такая программа работает в кластере Flink с двумя диспетчерами задач, каждый из которых имеет 3 слота. Flink не планирует на основе каждого экземпляра выполнения оператора, но отдает приоритет планированию полного конвейера в слот. Мы видим, что для настройки параллелизма здесь есть три слота, в которых запланирован полный конвейер.
Таким образом, производительность программы может быть улучшена. Если параллелизм каждого оператора выполняется с независимым потоком, то при большом количестве потоков потоки нужно переключать и кэшировать непрерывно, что будет иметь определенные накладные расходы.
Структура данных JobManager
Во время выполнения задания JobManager отслеживает каждую задачу, решает, когда запланировать следующую задачу или группу задач, и обрабатывает завершенные задачи или сбои выполнения.
JobManager получает JobGraph, который является представлением потока данных, включая операторы (JobVertex) и промежуточные результаты (IntermediateDataSet). Каждый оператор имеет такие свойства, как степень параллелизма и код для выполнения.
Код, который мы пишем, преобразуется в JobGraph. По сути, это также ориентированный ациклический граф. Поскольку это структура графа, должны быть Vertex (вершина) и Edge (ребро). Вершина JobGraph во Flink — это JobVertex, который на самом деле является оператором во Flink, а ребро JobGraph — это IntermediateDataSet, промежуточный результат, обработанный оператором.
Каждая JobVertex имеет свои собственные свойства. Например: степень параллелизма и код, который должен выполнять Оператор. Более того, для того, чтобы гарантировать корректную работу кода в каждой JobVertex в JVM, каждый JobGraph также должен содержать набор библиотек (кучу jar-пакетов)
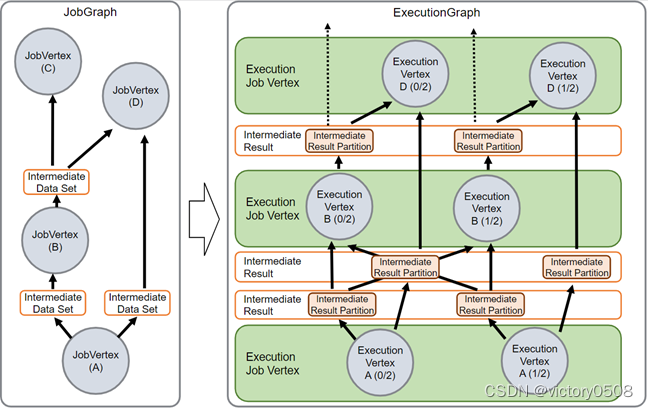
Чтобы запустить программу Flink в кластере, вам нужно преобразовать JobGraph в ExecutionGraph. Фактически ExecutionGraph можно понимать как параллельную версию JobGraph или параллельное расширение JobGraph.
Вершина в ExecutionGraph — это ExecutionVertex. Если JobVertex имеет параллелизм 50, то в ExecutionGraph будет 50 ExecutionVertex (вершин). Каждая ExecutionVertex содержит статус выполнения каждой задачи. Краем в ExecutionGraph является IntermediatePartition. Потому что данные промежуточного результата, соответствующие каждой вершине параллелизма, на самом деле являются разбиением.
рабочий статус
Каждый ExecutionGraph имеет связанную с ним информацию о состоянии задания, которая используется для описания текущего состояния выполнения задания.
- полное исполнение
Задание Flink будет находиться в состоянии создания в начале, а затем переключится в состояние выполнения, когда оно начнет планировать операцию. Переключается в состояние завершения после завершения выполнения задания.

- Не удалось запустить задание
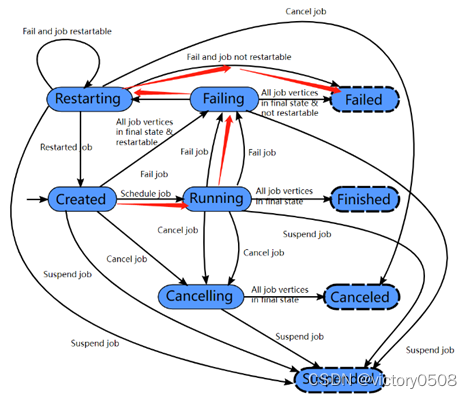
Если в течение этого периода происходит сбой, задание сначала переходит в состояние сбоя , чтобы отменить все запущенные задачи. Если все узлы задания достигают конечного состояния и задание не может быть перезапущено, задание переходит в состояние сбоя .
- перезапуск задания
Если во время выполнения задания произойдет сбой, и задание можно будет перезапустить, задание перейдет в состояние перезапуска и перейдет в состояние создания после полного перезапуска задания .
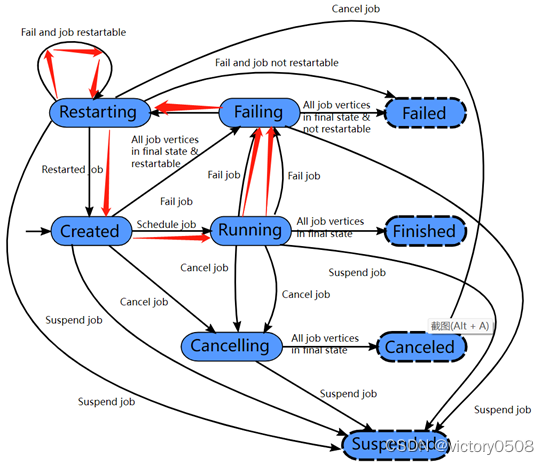
- Пользователь вручную отменяет задание
Если пользователь вручную отменяет задание, оно переходит в состояние отмены и отменяет все запущенные задачи. Когда все запущенные задачи переходят в конечное состояние, задание переходит в отмененное состояние.
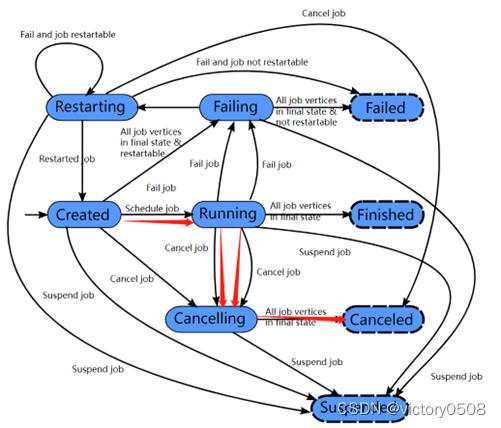
- работа находится на рассмотрении
Завершено, отменено и не удалось привести к глобальному конечному состоянию и вызвать очистку задания. В отличие от этих состояний приостановленное состояние является лишь частичной доработкой. Локальное завершение означает, что выполнение задания было прервано соответствующим диспетчером заданий, но другие диспетчеры заданий в кластере все еще могут получать информацию о задании из хранилища высокой доступности и перезапускаться. Таким образом, задание в приостановленном состоянии не будет полностью очищено.
Состояния Finished, Canceled и Failed — это глобальные состояния терминала, запускающие очистку задания. Приостановленное состояние является локальным терминальным состоянием. Это означает, что если задание было прекращено на одном диспетчере заданий, но если это кластер высокой доступности, другой диспетчер заданий все еще может получить задание из хранилища высокой доступности и перезапустить его. Таким образом, состояние «Приостановлено» не приведет к полной очистке задания.
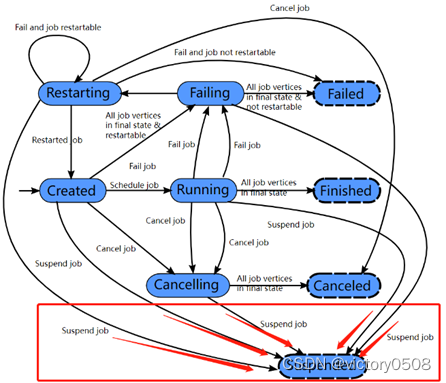
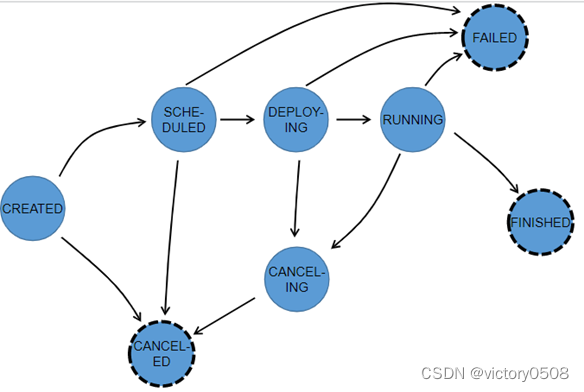
- статус задачи
Во время выполнения всего ExecutionGraph каждая параллельная задача будет проходить несколько этапов, от созданного состояния до завершенного или неудавшегося . На рисунке ниже показаны различные состояния и отношения перехода между ними. Поскольку задача может выполняться несколько раз (например, во время восстановления после исключения), выполнение ExecutionVertex отслеживается Execution, и каждая ExecutionVertex будет записывать текущее выполнение и предыдущее выполнение.