CeresDB는 Rust로 작성된 고성능 분산 클라우드 네이티브 시계열 데이터베이스입니다. 개발팀은 최근 거의 1년 간의 오픈 소스 연구 및 개발 끝에 시계열 데이터베이스 CeresDB 1.0이 공식적으로 출시되어 생산 가용성 표준에 도달했다고 발표했습니다 .
CeresDB 1.0 공식 중국어 문서: https://docs.ceresdb.io/cn/
CeresDB 1.0의 핵심 기능 소개
스토리지 엔진
-
컬럼형 하이브리드 스토리지 지원
-
효율적인 XOR 필터
클라우드 네이티브 분산
-
컴퓨팅과 스토리지의 분리 실현(데이터 스토리지로 OSS 지원, WAL 구현은 OBKV, Kafka 지원)
-
HASH 파티션 테이블 지원
배포 및 O&M
-
독립 실행형 배포 지원
-
분산 클러스터 배포 지원
-
자체 모니터링 구축을 위해 Prometheus + Grafana 지원
읽기-쓰기 프로토콜
-
SQL 쿼리 및 쓰기 지원
-
CeresDB의 고성능 읽기 및 쓰기 프로토콜 내장 구현 및 다국어 SDK 제공
-
Prometheus 지원, Prometheus의 원격 저장소로 사용 가능
다국어 읽기 및 쓰기 SDK
- Java, Python, Go, Rust의 4개 언어로 클라이언트 SDK 구현
CeresDB 아키텍처 소개
CeresDB는 시계열 데이터베이스입니다. 고전적인 시계열 데이터베이스와 비교할 때 CeresDB의 목표는 시계열 및 분석 모드에서 동시에 데이터를 처리하고 효율적인 읽기 및 쓰기를 제공하는 것입니다.
고전적인 시계열 데이터베이스에서 Tag열( , InfluxDB호출 됨 )은 일반적으로 그에 대한 역 인덱스를 생성하지만 실제 사용에서는 시나리오에 따라 열의 카디널리티가 다릅니다——— 일부 시나리오에서 카디널리티는 매우 높으며(이 시나리오의 데이터를 분석 데이터라고 함) 역지수를 기반으로 한 읽기 및 쓰기는 이에 대한 높은 대가를 지불하게 됩니다. 반면에 분석 데이터베이스에서 일반적으로 사용되는 스캐닝 + 프루닝 방법은 이러한 분석 데이터를 보다 효율적으로 처리할 수 있습니다.TagPrometheusLabelTagTag
따라서 CeresDB의 기본 설계 개념은 시계열 데이터와 분석 데이터를 동시에 효율적으로 처리하기 위해 하이브리드 저장 형식과 해당 쿼리 방법을 채택하는 것입니다.
아래 그림은 CeresDB 독립형 버전의 아키텍처를 보여줍니다.
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
성능 최적화 및 실험 결과
CeresDB는 막대한 타임라인(높은 카디널리티) 하에서 쓰기 쿼리 성능 저하 문제를 해결하기 위해 컬럼형 하이브리드 스토리지, 데이터 파티셔닝, 프루닝 및 효율적인 스캐닝의 조합을 사용합니다.
쓰기 최적화
CeresDB는 LSM과 같은(Log-structured merge-tree) 쓰기 모델을 채택하여 쓰기 시 복잡한 역 인덱스를 처리할 필요가 없으므로 쓰기 성능이 더 좋습니다.
쿼리 최적화
다음 기술 수단은 주로 쿼리 성능을 향상시키는 데 사용됩니다.
전정:
-
최소/최대 가지치기: 건설 비용이 상대적으로 낮고 특정 시나리오에서 성능이 더 좋습니다.
-
XOR 필터: parquet 파일에서 행 그룹의 필터링 정확도 향상
효율적인 스캔:
-
여러 SST 간의 동시성: 여러 SST 파일을 동시에 스캔
-
단일 SST의 내부 동시성: Parquet 계층을 지원하여 여러 행 그룹을 병렬로 가져옵니다.
-
작은 IO 병합: OSS에 있는 파일의 경우 작은 IO 요청을 병합하여 풀 효율성을 개선합니다.
-
로컬 캐시: OSS에서 가져온 캐시 파일, 메모리 및 디스크 캐시 지원
성능 테스트 결과
성능 테스트는 TSBS를 사용하여 수행되었습니다. 압력 측정 매개변수는 다음과 같습니다.
-
10 태그
-
10 필드
-
타임라인(태그조합번호) 100w급
압력 테스트 기계 구성: 24c90g
InfluxDB 버전: 1.8.5
CeresDB 버전: 1.0.0
쓰기 성능 비교
InfluxDB 쓰기 성능은 시간이 지남에 따라 더 저하됩니다. CeresDB의 쓰기가 안정되면 쓰기 속도가 안정되는 경향이 있으며, 전반적인 쓰기 성능은 InfluxDB의 1.5배 이상입니다.
아래 그림에서 단일 행에는 10개의 필드가 포함되어 있습니다.
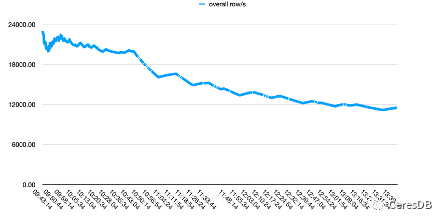
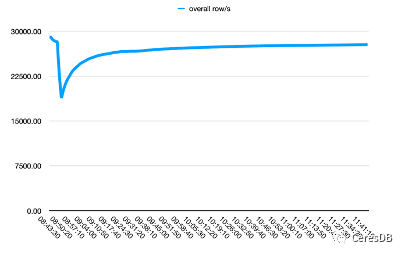
위의 사진은 Influxdb이고, 아래의 사진은 CeresDB입니다.
쿼리 성능 비교
낮은 스크리닝 조건(조건: os=Ubuntu15.10), CeresDB는 InfluxDB보다 26배 빠르며 구체적인 데이터는 다음과 같습니다.
-
CeresDB 쿼리 시간: 15초
-
InfluxDB 쿼리 시간: 6분 43초
높은 스크리닝 조건(더 적은 데이터 적중, 조건: hostname=[8], 이 때 전통적인 반전 인덱스가 이론상 더 효과적일 것임), 이것은 InfluxDB가 더 많은 이점을 갖는 시나리오이며, 현재로서는 워밍업이 완료되면 CeresDB는 InfluxDB보다 5배 느립니다.
-
CeresDB: 85ms
-
인플럭스DB:15ms
2023 로드맵
개발팀은 CeresDB 1.0이 출시된 2023년에는 대부분의 작업이 성능, 배포 및 주변 생태계에 집중될 것이라고 말했습니다. 특히 주변 생태계의 도킹 지원으로 다양한 사용자가 CeresDB를 보다 쉽게 사용할 수 있기를 바랍니다.
주변 생태
-
PromQL, InfluxdbQL 및 OpenTSDB와 같은 일반적인 시계열 데이터베이스 프로토콜과의 호환성을 포함한 생태학적 호환성
-
k8s 지원, CeresDB 운영 및 유지 관리 시스템, 자체 모니터링 등을 포함한 운영 및 유지 관리 도구 지원
-
데이터 가져오기 및 내보내기 등을 포함한 개발자 도구
성능
-
새로운 스토리지 형식 살펴보기
-
다양한 워크로드에서 CeresDB의 성능을 향상시키기 위해 다양한 유형의 인덱스를 향상시킵니다.
분산
-
자동 로드 밸런싱
-
가용성, 안정성 향상