기사 디렉토리
사전 가져오기
우리가 알고 있는 NoSQL은 비관계형 데이터베이스입니다. 10가지 관련 기술의 통합 솔루션은 공식 springboot 문서에서 제공됩니다. 이 기사에서는 국내 시장에서 가장 인기 있는 몇 가지 NoSQL 데이터베이스 통합 솔루션, 즉 다음을 다룹니다.
- 레디스
- 몽고DB
- 그것은이다
위의 기술에 대한 최상의 사용 사례는 모두 Linux 서버에 배포되지만 이 기사에서는 여전히 Windows 플랫폼을 사용합니다.
SpringBoot는 Redis를 통합합니다.
Redis 기본 소개 및 설치
Redis는 키-값 저장 구조를 가진 인메모리 NoSQL 데이터베이스입니다.
- 여러 데이터 저장 형식 지원
- 고집
- 클러스터 지원
키-값 형식인 데이터 저장 형식, 즉 키-값 쌍의 저장 형식에 중점을 둡니다. MySQL 데이터베이스는 MySQL 데이터베이스와 달리 테이블, 필드, 레코드가 있지만 Redis는 이러한 항목이 없으며 이름은 값에 해당하며 데이터는 주로 메모리에 저장되어 사용됩니다. 메모리에 주로 저장되는 것은 무엇입니까? 사실 Redis는 RDB와 AOF라는 데이터 영속성 솔루션을 가지고 있지만 Redis 자체는 데이터 영속성을 위해 태어난 것이 아니라 주로 메모리에 데이터를 저장하고 데이터 액세스를 가속화하므로 메모리 수준의 데이터베이스입니다.
Redis는 다양한 데이터 저장 형식을 지원합니다. 예를 들어 문자열을 직접 저장할 수 있거나 지도 컬렉션, 목록 컬렉션을 저장할 수 있으며 다른 형식의 일부 데이터 작업은 나중에 관련됩니다.
Windows 버전 설치 패키지 다운로드 주소: https://github.com/tporadowski/redis/releases
다운로드 받은 설치 패키지는 원클릭 설치를 위한 msi 파일과 압축 해제 후 사용할 수 있는 zip 파일의 두 가지 형태가 있습니다.
msi란 사실 소프트웨어를 설치할 뿐만 아니라 소프트웨어 설치 및 패키지 작업에 필요한 기능을 연결하는 데 도움이 되는 파일 설치 패키지입니다. 설치 순서, 설치 경로 생성 및 설정, 시스템 종속성 설정, 기본적으로 설치 옵션 설정, 설치 프로세스를 제어하는 속성 등. 쉽게 말해서 원스톱 서비스로 설치 과정이 원스톱 작업으로 초보 사용자를 위한 소프트웨어 설치 프로그램입니다.
설치가 완료되면 Redis를 시작하기 위한 핵심 명령어로 CMD 명령줄 모드에서 실행해야 하는 두 개의 명령어에 해당하는 두 개의 파일이 있습니다.
서버 시작
redis-server.exe redis.windows.conf
여기서는 기본 포트 6379를 사용하고 있습니다.
클라이언트를 시작
redis-cli.exe
레디스 서버 시작에 실패하면 클라이언트를 먼저 시작한 다음 종료 작업을 수행한 다음 종료할 수 있으며 이 때 레디스 서버는 정상적으로 실행될 수 있습니다.
보여줍시다:
먼저 서버를 시작하고 시작이 실패했는지 확인합니다.
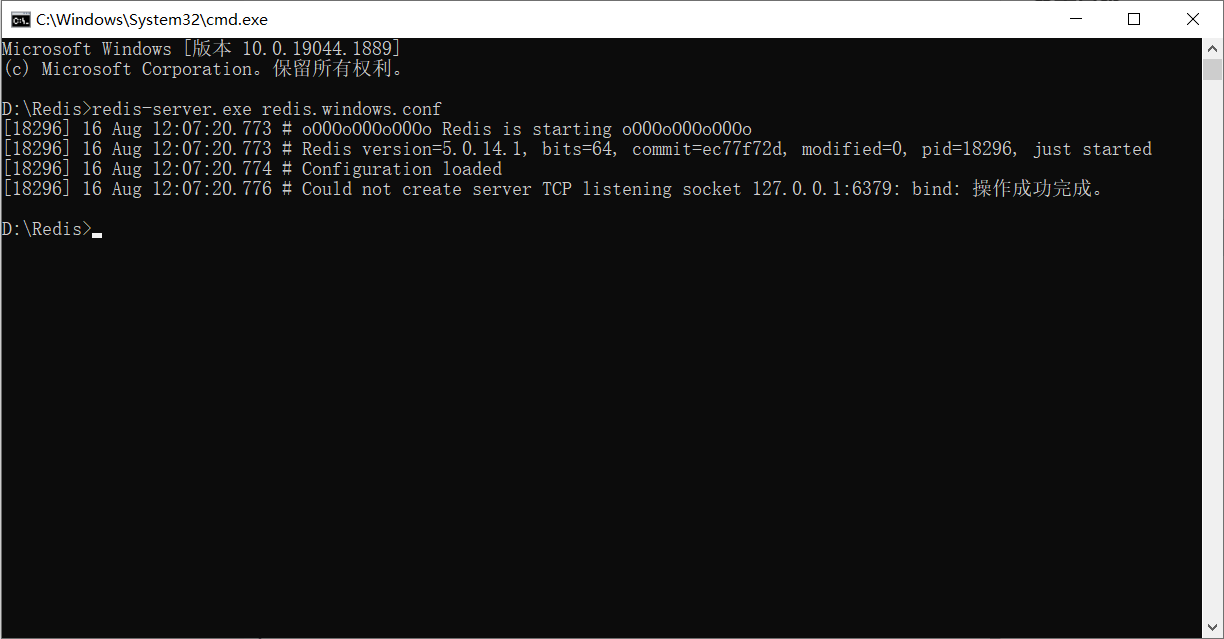
그런 다음 계속 진행 합니다.
다시 서버를 엽니다.
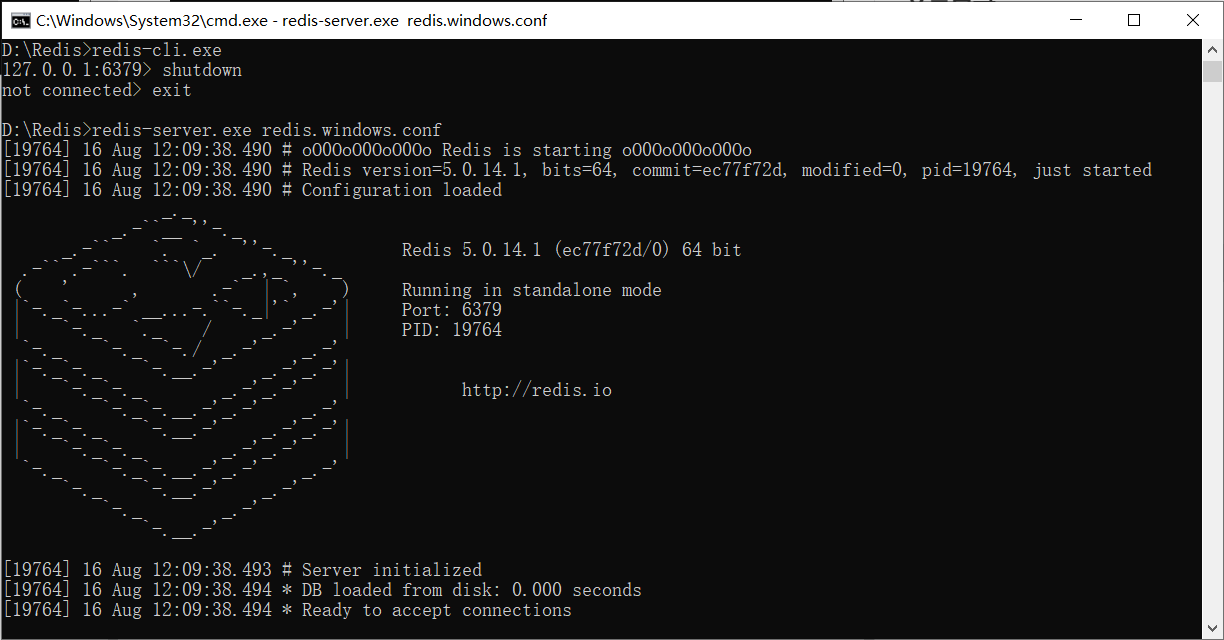
확인: 이 이미지가 나타나면 서버가 성공적으로 열렸음을 의미합니다!
기본 동작
서버가 시작된 후 MySQL 데이터베이스를 시작한 다음 SQL 명령줄을 시작하여 데이터베이스를 작동하는 것과 유사하게 클라이언트를 사용하여 서버에 연결할 수 있습니다.
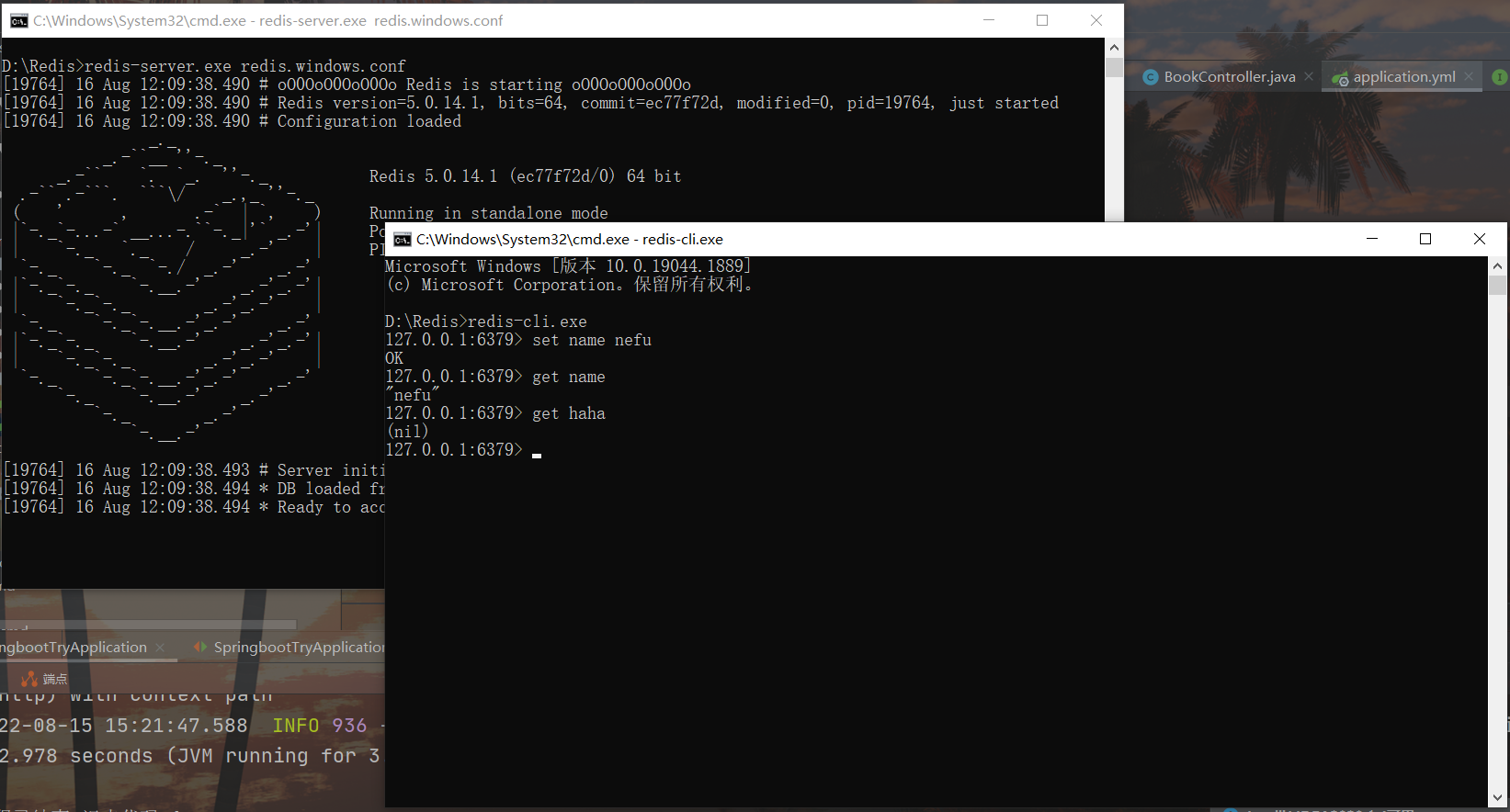
데이터 문자열을 redis에 넣고 먼저 이름, 나이 등의 데이터 이름을 정의한 다음 set 명령을 사용하여 데이터를 redis 서버에 설정합니다.
set name nefu
set age 12
redis에서 넣은 데이터를 꺼내서 이름에 따라 해당 데이터를 가져옵니다. 해당 데이터가 없으면 (nil)
get name
get age
예:
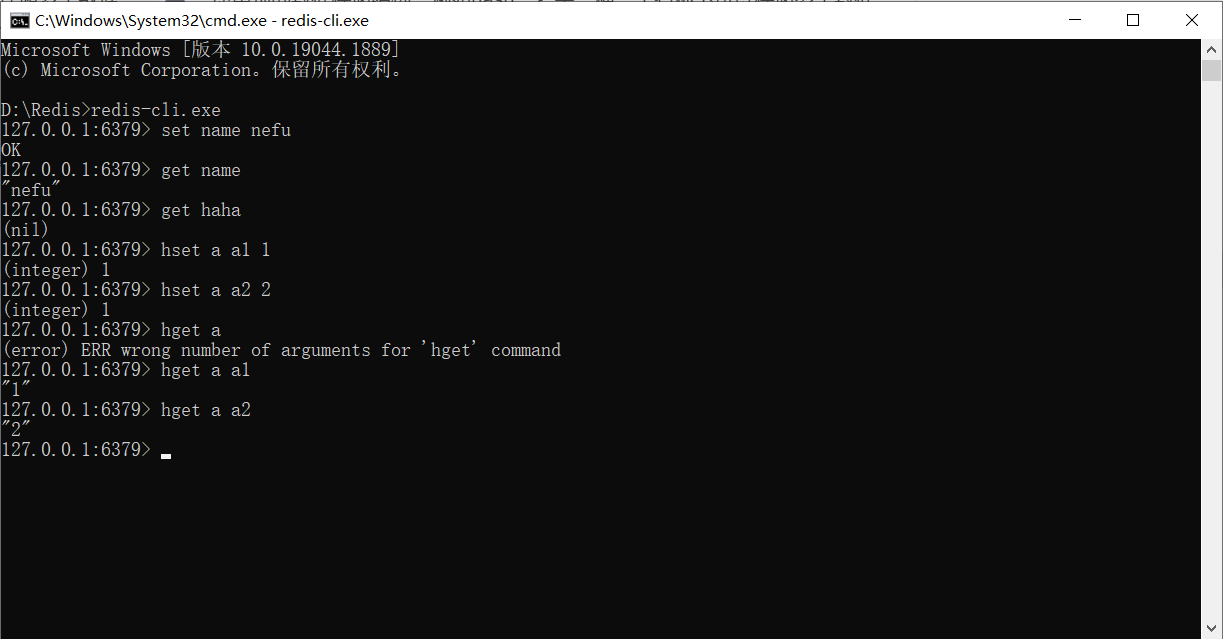
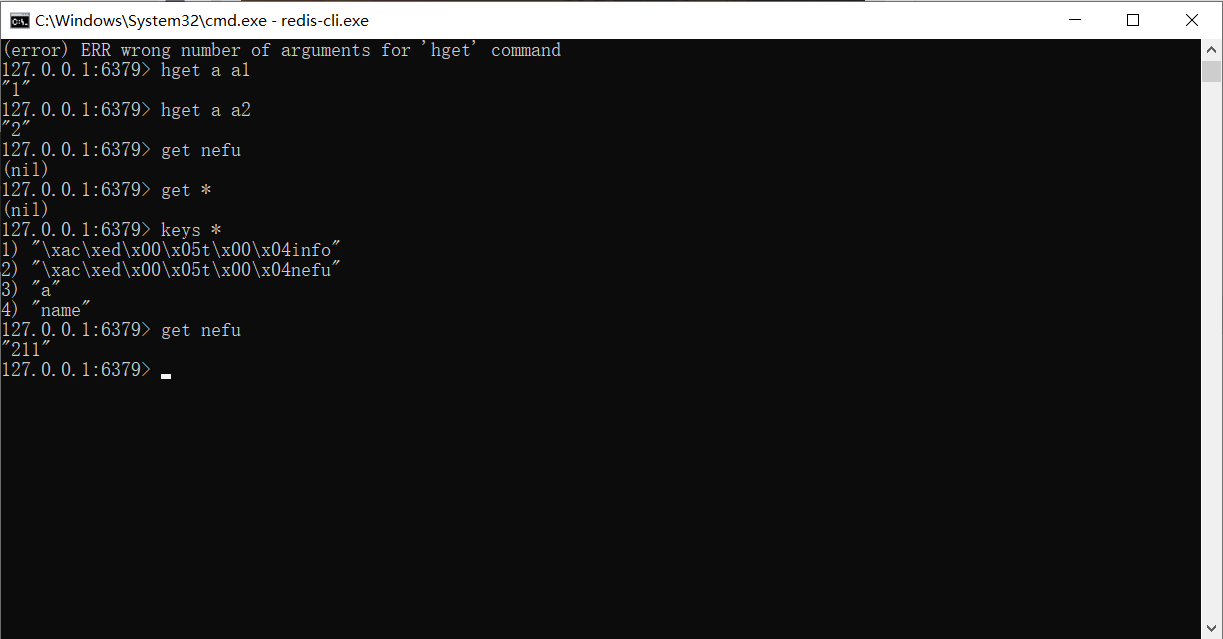
위에서 사용된 데이터 저장소는 값에 해당하는 이름이며 유지해야 할 데이터가 너무 많을 경우 다른 데이터 저장소 구조를 사용할 수 있습니다. 예를 들어 해시는 하나의 이름으로 여러 데이터를 저장할 수 있는 저장소 모델이며 각 데이터에는 고유한 보조 저장소 이름이 있을 수도 있습니다. 해시 구조에 데이터를 저장하는 형식은 다음과 같습니다.
hset a a1 aa1 #对外key名称是a,在名称为a的存储模型中,a1这个key中保存了数据aa1
hset a a2 aa2
해시 구조의 데이터를 가져오는 명령은 다음과 같습니다.
hget a a1 #得到aa1
hget a a2 #得到aa2
직접 받을 수 없으니 참고하세요.
예:
여기에서는 Redis에 대한 몇 가지 간단한 작업만 다룹니다.
통합
통합하기 전에 통합에 대한 아이디어를 정리하자 Springboot는 springboot에서 해당 기술의 API를 사용하기 위해 모든 기술을 통합합니다. 두 기술이 교차하지 않으면 통합 개념이 없습니다. 소위 통합은 실제로 다른 기술을 관리하기 위해 springboot 기술을 사용하는 것입니다.몇 가지 문제는 피할 수 없습니다.
-
먼저 해당 기술의 좌표를 먼저 가져와야 하며 통합 후 이러한 좌표에 약간의 변경이 있습니다.
-
둘째, 모든 기술에는 일반적으로 관련 설정 정보가 있습니다.
-
셋째, 통합 전 작업이 모드 A인 경우 통합 후 개발자에게 몇 가지 편리한 작업을 제공하지 않으면 통합은 의미가 없으므로 통합 후 작업을 단순화해야 하며 해당 작동 모드가 자연스럽게 달라집니다. 다른
위의 세 가지 질문에 따라 springboot의 모든 기술의 통합에 대해 생각하는 것이 일반적입니다. 기본적으로 고정된 사고의 집합을 요약할 수 있습니다.
redis와 springboot의 연동을 시작해 보겠습니다. 동작 단계는 다음과 같습니다.
1단계 : redis 통합을 위한 springboot의 시작 좌표 가져오기
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
위의 좌표는 모듈 생성 시 확인하여 선택할 수 있으며 NoSQL 범주에 속합니다.

2단계 : 기본 구성 수행
spring:
redis:
host: localhost
port: 6379
redis를 운용하기 위해서는 어떤 redis 서버를 운용할 것인가가 가장 기본적인 정보이므로 서버 주소는 기본 설정 정보에 속하며 필수 불가결한 정보입니다. 그러나 구성하지 않더라도 지금은 계속 사용할 수 있습니다. 위의 두 정보 집합에는 정확히 위의 구성 값인 기본 구성이 있기 때문입니다.
3단계 : redis의 전용 클라이언트 인터페이스 작업을 통합하기 위해 springboot를 사용합니다. 여기 RedisTemplate이 있습니다.
@SpringBootTest
class Springboot16RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void set() {
//首先决定要操作哪种数据类型
ValueOperations ops = redisTemplate.opsForValue();
ops.set("age",41);
}
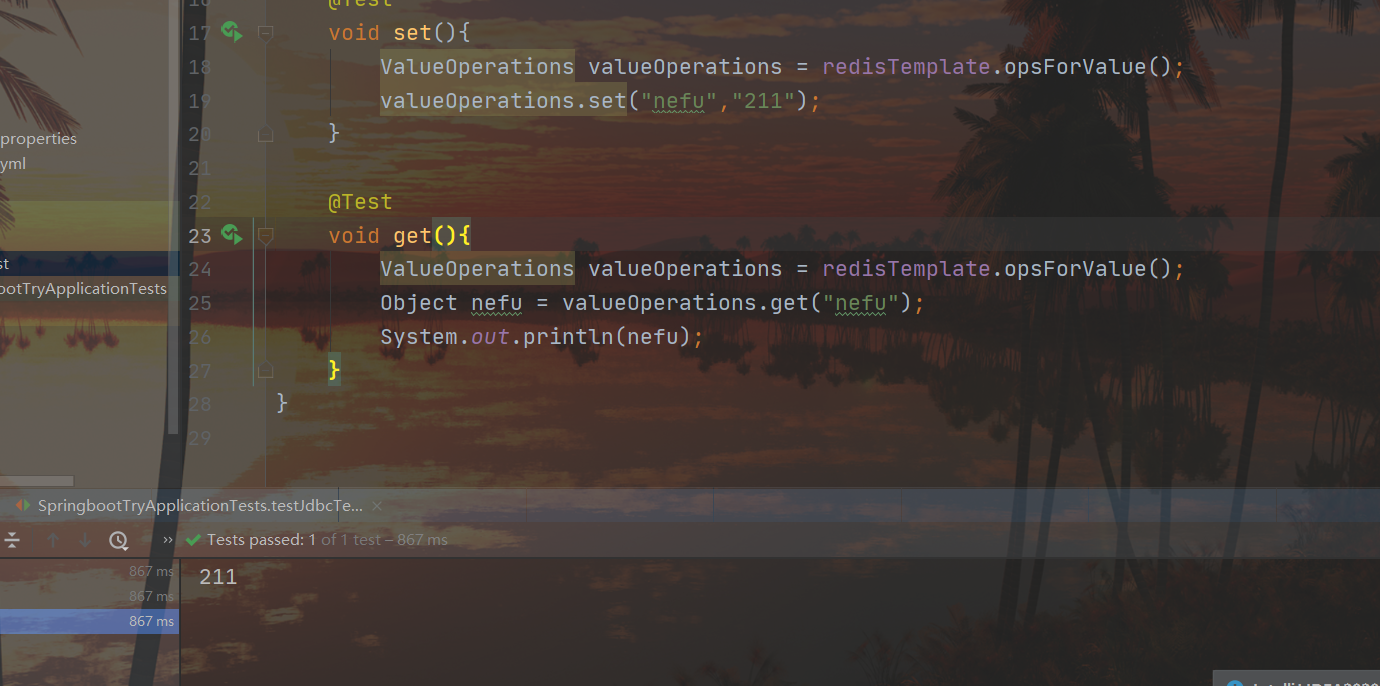
@Test
void get() {
ValueOperations ops = redisTemplate.opsForValue();
Object age = ops.get("name");
System.out.println(age);
}
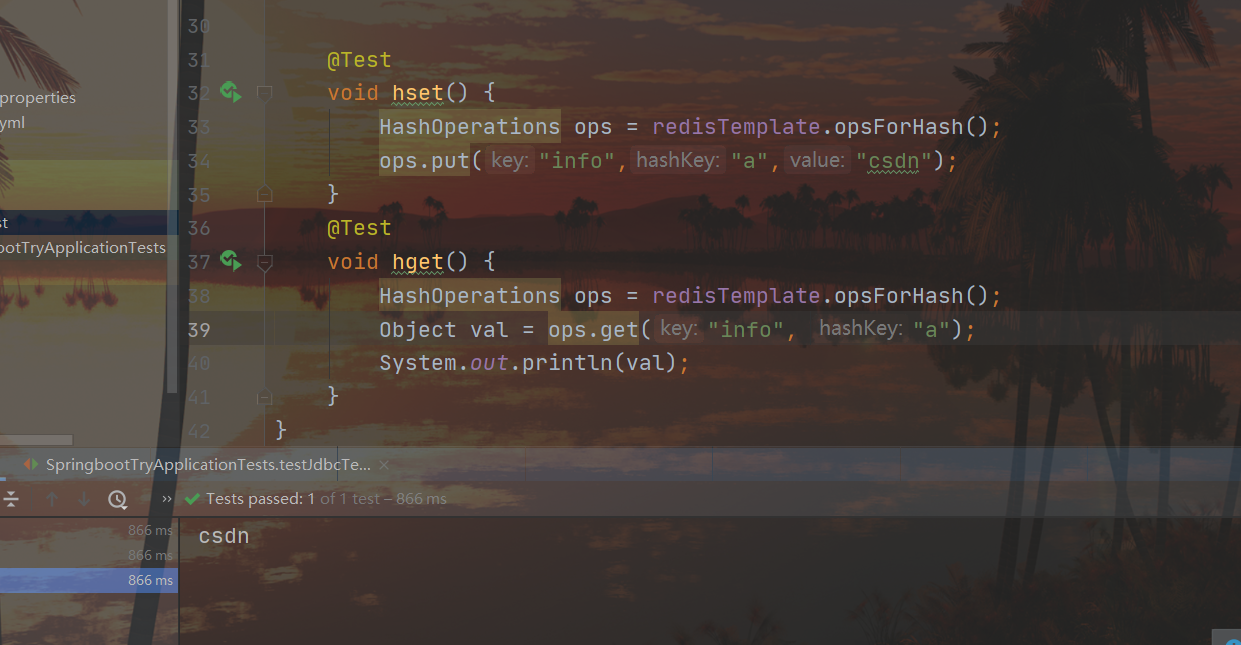
@Test
void hset() {
HashOperations ops = redisTemplate.opsForHash();
ops.put("info","a","csdn");
}
@Test
void hget() {
HashOperations ops = redisTemplate.opsForHash();
Object val = ops.get("info", "a");
System.out.println(val);
}
}
두 세트의 get/set 결과:
redis를 운용할 때 어떤 종류의 데이터를 운용할 것인지 확인하고 데이터의 종류에 따른 운용 인터페이스를 얻어야 합니다.. 예를 들어, opsForValue()를 사용하여 문자열 유형의 데이터 조작 인터페이스를 얻고 opsForHash()를 사용하여 해시 유형의 데이터 조작 인터페이스를 얻으며 나머지는 해당 api 조작을 호출하는 것입니다. 다양한 유형의 데이터 조작 인터페이스는 다음과 같습니다.
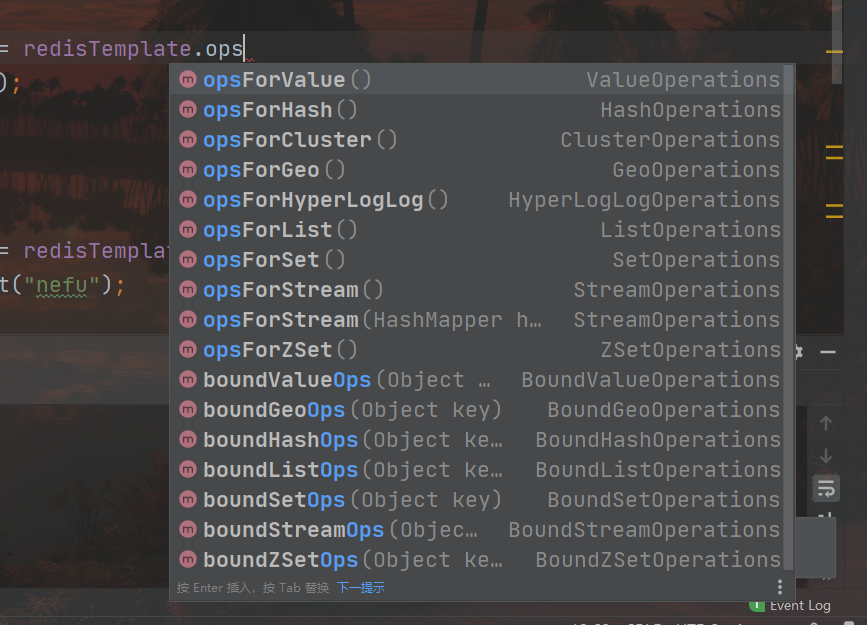
요약하다
- Springboot는 redis 단계를 통합합니다.
- redis를 통합하기 위해 springboot의 시작 좌표를 가져옵니다.
- 기본 구성 수행
- springboot를 사용하여 redis의 전용 클라이언트 인터페이스 RedisTemplate 작업 통합
여기서 주의할 점이 있는데 Redis 클라이언트에서 테스트에서 추가한 키-값 쌍을 찾을 때 찾을 수 없습니다. 추가되지 않았기 때문이 아니라 데이터 유형 문제 때문입니다. 이 때 명령을 사용하여 저장된 모든 키를 볼
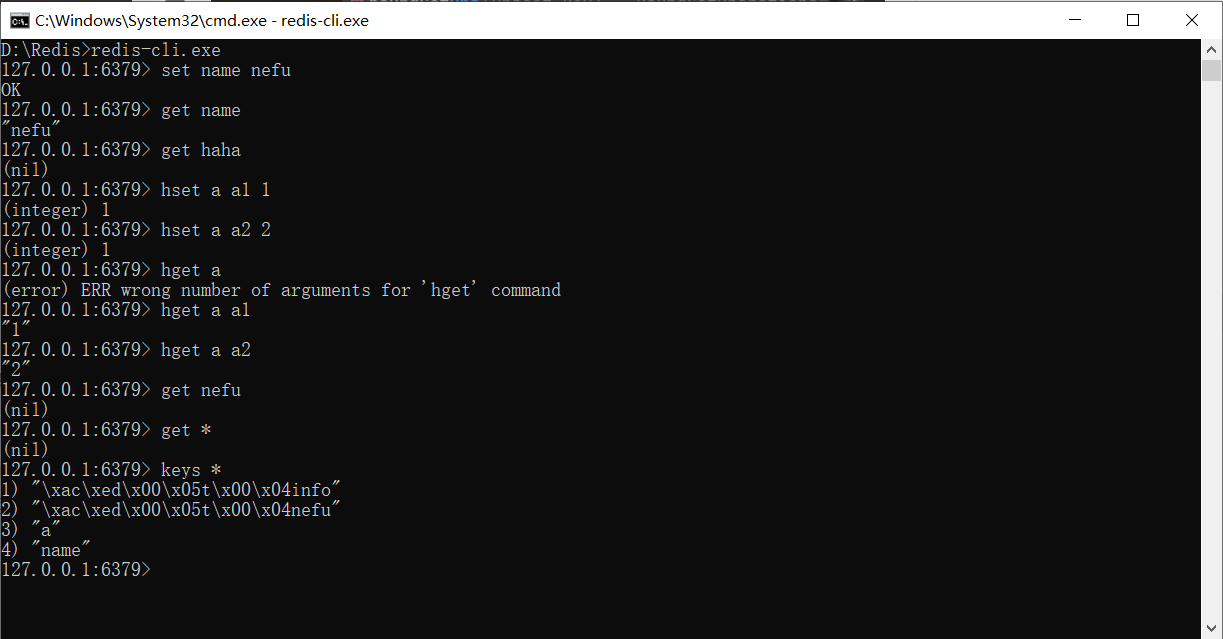
수 있습니다. 찾을 수 없는 것이 아니라 개체의 형태로 저장되고 특별한 방법을 사용하여 Redis에 의해 직렬화되기 때문에 직접 입력합니다. 문자 문자열을 찾을 수 없습니다.
RedisTemplate에서도 볼 수 있습니다.
여기서 제네릭이 사용되며 아무 것도 작성하지 않으면 Object 객체로 처리됩니다.
이를 피하기 위해 다음을 사용할 수 있습니다 StringRedisTemplate.
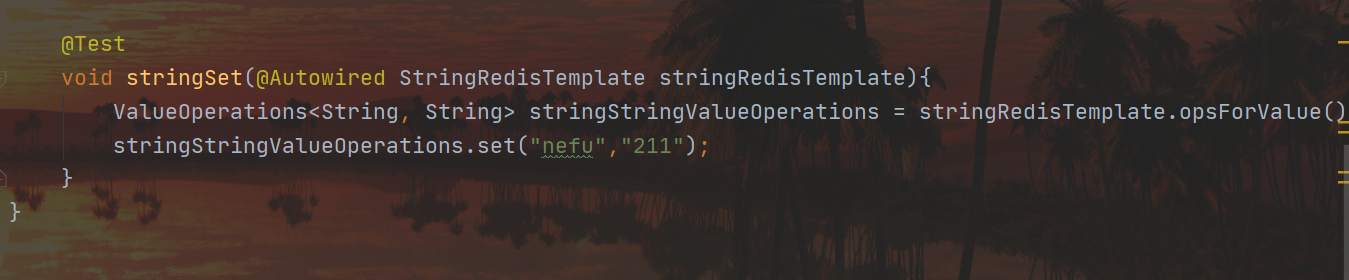
그러면 다음을 찾을 수 있습니다.
SpringBoot는 MongoDB를 통합합니다.
MongoDB 기본 소개 및 설치
Redis 기술을 사용하면 데이터 액세스 속도를 효과적으로 향상시킬 수 있지만 Redis의 단일 데이터 형식으로 인해 구조화된 데이터를 운영할 수 없습니다 . 접근 속도를 보장하는 경우 구조화된 데이터를 운용하고자 한다면 Redis가 요구 사항을 충족하지 못하는 것으로 보이며, 이때 이 문제를 해결하기 위해 새로운 데이터 저장 구조를 사용해야 합니다.
MongoDB는 NoSQL 데이터베이스 제품 중 하나인 오픈 소스, 고성능, 스키마 없는 문서 데이터베이스입니다.관계형 데이터베이스와 가장 유사한 비관계형 데이터베이스입니다..
위의 설명에 있는 몇 개의 단어 중 우리에게 가장 생소한 단어는 패턴이 없습니다. 모덜리스란? 간단히 말해서 데이터베이스로서 고정된 데이터 저장 구조는 없으며, 첫 번째 데이터는 A, B, C의 3개의 필드를 가질 수 있고, 두 번째 데이터는 D, E, F의 3개의 필드를 가질 수 있으며, 세 번째 데이터는 3개의 필드를 가질 수 있으며, 데이터는 A, C, E3 필드일 수 있습니다. 즉, 데이터의 구조가 고정되어 있지 않고 스키마가 없습니다 . 어떤 사람들은 이것이 무슨 소용이 있다고 말할 것입니다. 유연하고 언제든지 변경 가능하며 제약이 없습니다. 위의 특징을 바탕으로 MongoDB의 애플리케이션 측면도 약간의 변화를 겪을 것입니다. 다음은 MongoDB를 데이터 저장소로 사용할 수 있는 몇 가지 시나리오를 나열하지만 MongoDB를 사용할 필요는 없습니다.
-
타오바오 사용자 데이터
- 저장 위치: 데이터베이스
- 특징: 영구 저장, 매우 낮은 수정 빈도
-
게임 장비 데이터, 게임 소품 데이터
- 저장 위치: 데이터베이스, Mongodb
- 특징: 영구저장과 임시저장의 조합, 높은 수정 빈도
-
생방송 데이터, 리워드 데이터, 팬 데이터
- 저장 위치: 데이터베이스, Mongodb
- 특징: 영구 저장과 임시 저장의 조합으로 수정 빈도가 매우 높음
-
사물인터넷 데이터
- 저장 위치: Mongodb
- 특징: 임시 저장, 빠른 수정 빈도

MongoDB에 대해 간단히 이해한 후 설치에 대해 이야기해 보겠습니다.
Windows 버전 설치 패키지 다운로드 주소: https://www.mongodb.com/try/download
다운로드 받은 설치 패키지도 원클릭 설치를 위한 msi 파일과 압축 해제 후 사용할 수 있는 zip 파일의 두 가지 형식이 있습니다.
압축을 풀면 bin 디렉토리에 mongodb의 모든 실행 가능한 명령이 포함된 다음 파일이 표시됩니다.

mongodb는 런타임에 데이터 저장 디렉토리를 지정해야 하므로 일반적으로 설치 디렉토리에 위치하는 데이터 저장 디렉토리를 생성합니다. 여기서 데이터 디렉토리는 데이터를 저장하기 위해 생성됩니다(우리는 또한 데이터 폴더에 db 폴더를 생성합니다. 데이터를 저장하기 위해), 다음과 같이

설치 과정에서 다음과 같은 경고 메시지가 나타나면 현재 운영 체제에 일부 시스템 파일이 누락되어 있다는 것이므로 걱정하지 마십시오.

해결 방법은 다음 해결 방법에 따라 해결할 수 있습니다. 브라우저에서 누락된 이름에 해당하는 파일을 검색하여 다운로드하고 다운로드한 파일을 Windows 설치 디렉터리의 system32 디렉터리에 복사한 다음 명령줄에서 regsvr32 명령을 실행합니다. 파일을 등록합니다. 다운로드한 파일 이름에 따라 해당 이름을 변경한 후 명령을 실행하십시오.
regsvr32 vcruntime140_1.dll
서버 시작
mongod --dbpath=..\data\db
서버를 시작할 때 데이터 저장 위치를 지정해야 하며, 이는 –dbpath 매개변수를 통해 설정할 수 있으며, 필요에 따라 데이터 저장 경로를 설정할 수 있습니다.기본 서비스 포트 27017.
그런 다음 데이터의 db 폴더에 들어가면 더 많은 것을 찾을 수 있습니다.
이 파일은 초기화를 위해 한 번만 생성되고 나중에 서버가 시작될 때 다시 생성되지 않습니다.
그런 다음 클라이언트를 다시 시작합니다.
클라이언트를 시작
mongo --host=127.0.0.1 --port=27017
mongo우리의 설정은 모두 기본값 이기 때문에 실행할 때 직접
성공을 나타내는 다음 인터페이스가 나타납니다.
서버가 꺼지지 않도록 주의하십시오. 두 개의 cmd 창이 동시에 존재해야 합니다.
기본 동작
MongoDB는 데이터베이스지만 SQL문으로 연산을 하지 않기 때문에 운용방법이 낯설 수 있습니다. 다행히도 Navicat과 유사한 MongoDB를 쉽게 운용할 수 있는 몇몇 데이터베이스 클라이언트 소프트웨어가 있습니다.클라이언트를 설치한 후 몽고DB를 운영합니다.
같은 종류의 소프트웨어가 많이 있는데 이번에 설치할 소프트웨어는 Robo3t입니다. Robot3t는 설치 없이 압축을 풀 수 있는 그린 소프트웨어입니다. 압축 해제 후 설치 디렉토리로 들어가 robot3t.exe를 더블 클릭하여 사용합니다.
소프트웨어를 열려면 먼저 MongoDB 서버에 연결하고 [파일] 메뉴를 선택한 다음 [연결…]을 선택해야 합니다.

연결 관리 인터페이스에 진입한 후 왼쪽 상단의 [만들기] 링크를 선택하여 새 연결 설정을 만듭니다.

설정 값을 입력하면 접속 가능 (로컬 머신의 27017 포트는 기본적으로 수정 없이 접속 가능)

연결이 성공하면 명령 입력 영역에 명령을 입력하여 MongoDB를 구동합니다.
데이터베이스 생성: 왼쪽 메뉴에서 생성하려면 마우스 오른쪽 버튼을 클릭하고 데이터베이스 이름을 입력합니다.
컬렉션 만들기: 컬렉션에서 오른쪽 버튼을 사용하여 컬렉션을 만들고 컬렉션 이름을 입력합니다. 컬렉션은 데이터베이스에서 테이블의 역할과 동일합니다.
新增文档: (문서는 일종의 json 형식의 데이터이지만 실제로는 json 데이터가 아님)
db.集合名称.insert/save/insertOne(文档)
예:
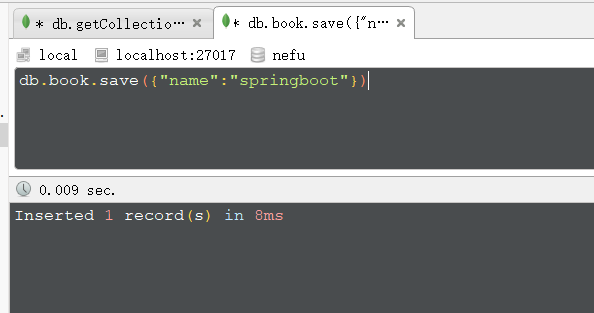
결과:
删除文档:
db.集合名称.remove(条件)
修改文档:
db.集合名称.update(条件,{操作种类:{文档}})
查询文档:
基础查询
查询全部: db.集合.find();
查第一条: db.集合.findOne()
查询指定数量文档: db.集合.find().limit(10) //查10条文档
跳过指定数量文档: db.集合.find().skip(20) //跳过20条文档
统计: db.集合.count()
排序: db.集合.sort({age:1}) //按age升序排序
投影: db.集合名称.find(条件,{name:1,age:1}) //仅保留name与age域
条件查询
基本格式: db.集合.find({条件})
模糊查询: db.集合.find({域名:/正则表达式/}) //等同SQL中的like,比like强大,可以执行正则所有规则
条件比较运算: db.集合.find({域名:{$gt:值}}) //等同SQL中的数值比较操作,例如:name>18
包含查询: db.集合.find({域名:{$in:[值1,值2]}}) //等同于SQL中的in
条件连接查询: db.集合.find({$and:[{条件1},{条件2}]}) //等同于SQL中的and、or
여기에는 몇 가지 기본적인 MongoDB 작업만 포함됩니다.
통합
springboot를 사용하여 MongDB를 통합하는 방법은 무엇입니까? 사실, springboot가 많은 개발자를 사용하는 이유는 그의 루틴이 거의 똑같기 때문입니다. 좌표를 가져오고 구성을 수행하고 API 인터페이스를 사용하여 작동합니다. Redis 통합도 마찬가지고 MongoDB 통합도 마찬가지입니다.
먼저 해당 기술의 통합 스타터 좌표를 먼저 가져옵니다.
둘째, 필요한 정보 구성
셋째, 제공된 API를 사용하여
MongoDB와 springboot의 통합을 시작해 보겠습니다. 단계는 다음과 같습니다.
1단계 : Springboot를 가져와 MongoDB의 시작 좌표를 통합합니다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
위 좌표도 NoSQL 카테고리에 속하는 모듈을 생성할 때 확인하여 선택할 수 있습니다.
2단계 : 기본 구성 수행
spring:
data:
mongodb:
uri: mongodb://localhost/nefu #我们对nefu集合进行操作
MongoDB 운용에 필요한 설정은 redis 운용과 동일하며 가장 기본적인 정보는 어떤 서버를 운용할 것인가 하는 점이며 차이점은 연결된 서버의 IP 주소와 포트가 다르고 쓰기 형식이 다르다는 점이다.
3단계 : springboot를 사용하여 MongoDB의 전용 클라이언트 인터페이스 MongoTemplate을 통합하여 운영
@SpringBootTest
class Springboot17MongodbApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void contextLoads() {
Book book = new Book();
book.setId(2);
book.setName("springboot2");
book.setType("springboot2");
book.setDescription("springboot2");
mongoTemplate.save(book);
}
@Test
void find(){
List<Book> all = mongoTemplate.findAll(Book.class);
System.out.println(all);
}
}
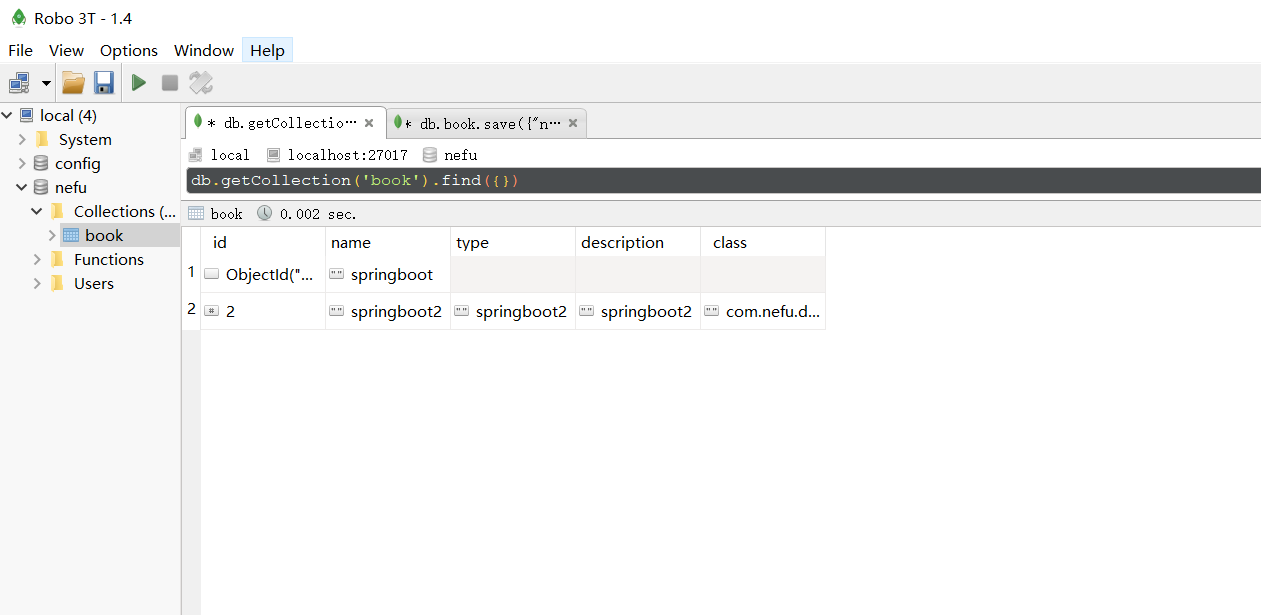
저장 작업을 실행한 후 데이터베이스에서 새 데이터를 볼 수 있습니다.
통합 작업은 여기에서 이루어지며 낯익기도 하고 낯설기도 합니다. 나는 이 루틴, 3개의 축, API 작업을 구성하는 좌표를 안내하는 이 3가지 트릭에 익숙합니다. 내가 익숙하지 않은 것은 이 기술이고 특정 작동 API는 낯설 수 있습니다. 여기서 MongoDB를 통합하는 springboot에 대해 이야기하겠습니다.
요약하다
- Springboot는 MongoDB 단계를 통합합니다.
- MongoDB의 시작 좌표를 통합하기 위해 springboot 가져오기
- 기본 구성 수행
- Springboot를 사용하여 MongoDB의 전용 클라이언트 인터페이스 MongoTemplate 작업 통합
SpringBoot는 ES를 통합합니다.
ES 기본 소개 및 설치
NoSQL 솔루션은 두 기술의 통합을 완료했습니다.Redis는 메모리를 사용하여 데이터를 로드하고 빠른 데이터 액세스를 달성할 수 있으며, MongoDB는 메모리에 객체와 유사한 데이터를 저장하고 빠른 데이터 액세스를 달성할 수 있습니다.엔터프라이즈 수준 개발에서 속도 추적은 끝이 없습니다. 아래에서 논의할 내용도 NoSQL 솔루션 이지만 그 역할은 데이터의 읽기와 쓰기를 직접적으로 가속화하는 것이 아니라 ES 기술이라고 하는 데이터 쿼리를 가속화하는 것이다 .
ES(Elasticsearch)는 전체 텍스트 검색에 중점을 둔 분산 전체 텍스트 검색 엔진입니다.
그렇다면 전체 텍스트 검색이란 무엇입니까? 예를 들어 사용자가 책을 구매하고 싶어 키워드로 Java를 검색하면 책 제목이든 책 서두든 책의 저자 이름이든 상관없다. 그것은 자바를 포함하고, 그것은 쿼리 결과로 사용자에게 반환됩니다.위의 프로세스가 사용됩니다.전체 텍스트 검색 기술. 검색 조건은 더 이상 특정 필드를 비교하는 데만 사용되는 것이 아니라 데이터 조각에서 검색 조건을 사용하여 더 많은 필드를 비교하는 데 사용 되며, 일치하는 한 쿼리 결과에 포함됩니다. 이것이 전체의 목적입니다. -텍스트 검색. . ES 기술은 위와 같은 효과를 얻을 수 있는 기술입니다.
전체 텍스트 검색의 효과를 얻으려면 비교를 위해 데이터베이스에서 like 연산을 사용할 수 없으므로 너무 비효율적입니다. ES는 전체 텍스트 검색을 실현하기 위해 새로운 아이디어를 고안했습니다. 구체적인 운영 과정은 다음과 같습니다.
-
조회하고자 하는 필드의 데이터에 대한 모든 텍스트 정보를 확인하고 점수를 매기고, 이를 여러 단어로 나눕니다.
- 예를 들어 "Spring Actual 5th Edition"은 "Spring", "Actual Combat" 및 "5th Edition"의 세 단어로 나뉩니다. 이 과정을 전문 용어로 부릅니다
分词. 서로 다른 단어 분할 전략은 서로 다른 분리 효과를 가지며, 서로 다른 단어 분할 전략을 토크나이저(tokenizer)라고 합니다.
- 예를 들어 "Spring Actual 5th Edition"은 "Spring", "Actual Combat" 및 "5th Edition"의 세 단어로 나뉩니다. 이 과정을 전문 용어로 부릅니다
-
각 데이터 조각의 ID에 해당하는 단어 분할 결과를 저장합니다.

-
예를 들어 id가 1인 데이터에서 name item의 값은 "Spring Actual 5th Edition"이고 단어 분할이 끝나면 "Spring"이 id 1에 해당하고 "actual battle"에 해당하는 것으로 나타납니다. id 1, "버전 5" "해당 id는 1입니다.
-
예를 들어, id가 3인 데이터에서 name item의 값은 "Spring5 design mode"이고 단어 분할이 끝난 후 "Spring"은 id 3에 해당하고 "design mode"는 id 3에 해당합니다.
-
이 때 다음과 같은 해당 결과가 나타납니다.선적 서류 비치단어 분할을 수행합니다. 주의할 점은 단어 분할 과정은 하나의 필드에서 뿐만 아니라 쿼리에 참여하는 각 필드에서 수행되며 최종 결과는 표에 요약되어 있다는 점이다.
이러한 데이터 조각을 문서라고 부를 수 있습니다.
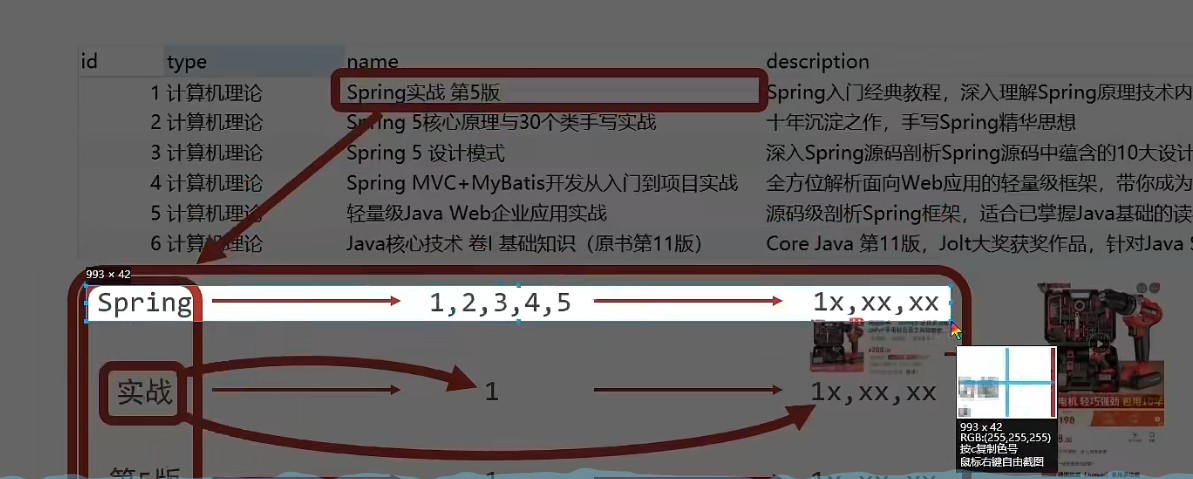
단어 세분화 결과 키워드 해당 아이디 봄 1, 2, 3, 4, 5 실제 전투 1 5판 1 -
-
쿼리 시 쿼리 조건으로 '실전'을 입력하면 위의 표 데이터를 비교하여 id 값이 1이 되도록 하고, id 값에 따라 쿼리 결과 데이터를 얻을 수 있다.

위의 과정에서 단어 분할 결과에서 각 키워드의 내용은 다르며, 그 기능은 데이터 쿼리 속도를 높이는 데 사용되는 데이터베이스의 인덱스와 다소 유사합니다. 그러나 데이터베이스의 인덱스는 특정 필드에 인덱스를 추가하기 위한 것으로, 여기서 단어 분할 결과 키워드는 완전한 필드 값이 아니라 필드 내용의 일부일 뿐입니다. 그리고 인덱스는 인덱스 내용에 따라 전체 데이터를 찾는 데 사용되며, 전체 텍스트 검색에서 단어 분할 결과 전체 데이터가 아닌 데이터의 id가 나옵니다. 특정 데이터를 얻고 싶다면, 다시 쿼리해야하므로 여기에서 이러한 종류의 단어 세분화 결과 키워드에 새로운 이름이 부여되었습니다. 이를 역 색인 이라고 합니다.
다음으로 설치에 대해 이야기합시다
. Windows 버전 설치 패키지의 다운로드 주소 : https://www.elastic.co/cn/downloads/elasticsearch
다운로드 받은 설치 패키지는 압축 해제 후 사용할 수 있는 zip 파일로 압축 해제 후 아래와 같은 파일을 얻게 됩니다.

- bin 디렉토리: 모든 실행 가능한 명령을 포함합니다.
- config 디렉토리: ES 서버에서 사용하는 구성 파일을 포함합니다.
- jdk 디렉토리: 이 디렉토리에는 완전한 jdk 툴킷 버전 17이 포함되어 있습니다. ES가 업그레이드되면 최신 버전의 jdk를 사용하여 버전 지원 부족 문제가 없는지 확인하십시오.
- lib 디렉토리: ES가 실행하는 종속 jar 파일을 포함합니다.
- logs 디렉토리: ES 실행 후 생성된 모든 로그 파일 포함
- 모듈 디렉토리: ES 소프트웨어의 모든 기능 모듈을 포함하며 하나씩 jar 패키지입니다. jar 디렉토리와 달리 jar 디렉토리는 런타임 동안 ES가 의존하는 jar 패키지이고 모듈은 ES 소프트웨어 자체의 기능적 jar 패키지입니다.
- plugins 디렉토리: ES 소프트웨어에서 설치한 플러그인을 포함하며 기본적으로 비어 있습니다.
서버 시작
elasticsearch.bat
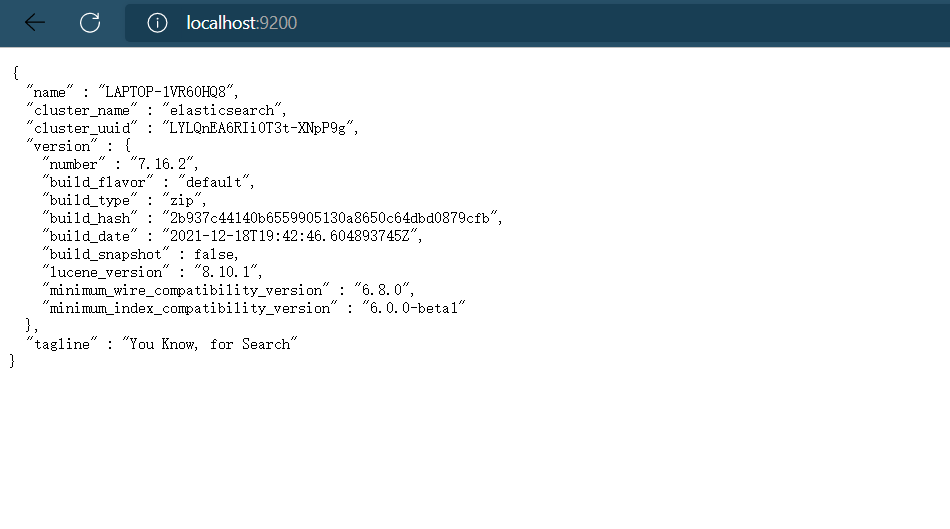
Elasticsearch.bat 파일을 더블 클릭하여 ES 서버를 시작하며, 기본 서비스 포트는 9200입니다. 브라우저를 통해 http://localhost:9200에 접속하여 ES 서버가 정상적으로 시작되면 다음과 같은 정보를 볼 수 있다.
실행 과정에서 기억해야 할 두 개의 포트 번호가 있습니다.
포트 9300: elasticsearch 클러스터웨어 구성 요소의 통신 포트로, 단순히 elasticsearch의 내부 통신을 위한 포트입니다.
포트 9200: 브라우저의 액세스 포트입니다.
때때로 작업에서 다음 오류가 보고됩니다:
GeoIP 보고 오류, GeoIP 프로세서 | Elasticsearch Guide [7.14] | Elastic
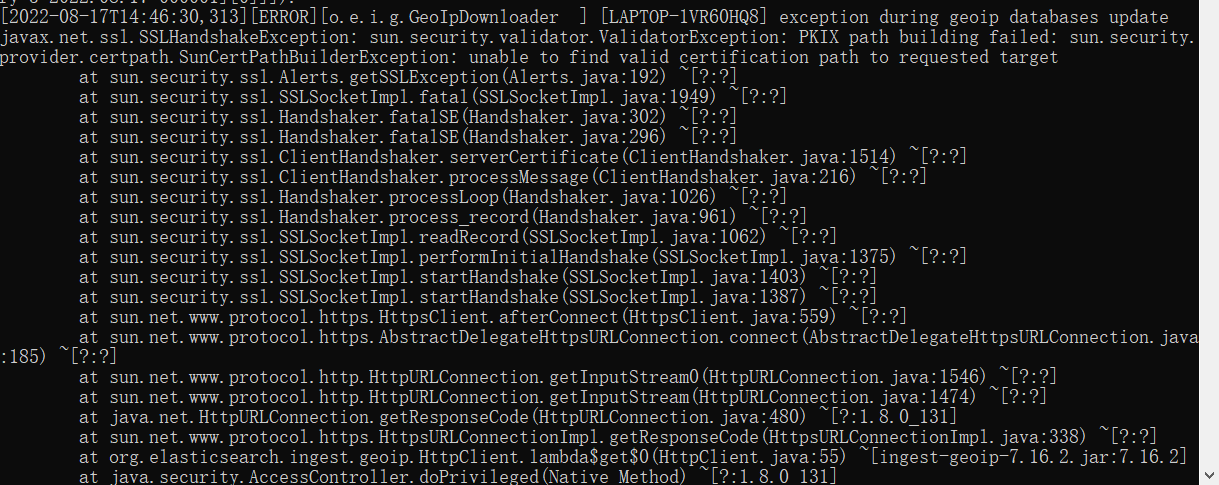
오류 메시지는 대부분
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX 경로 구축 실패: sun.security.provider.certpath.SunCertPathBuilderException: 요청된 대상에 대한 유효한 인증 경로를 찾을 수 없음
해결 방법은 ssh 보안 인증서를 다운로드한 jre의 보안 디렉토리에 추가하는 것입니다. 단, 동작에 영향을 미치지 않으므로 해결할 수 없습니다.
PKIX 해결: 솔루션
일부 사용자는 elasticsearch.bat 파일을 클릭하면 몇 줄의 텍스트를 표시한 후 cmd 팝업 창이 자동으로 닫히는데 이 경우 정상 실행될 때까지 몇 번 열어야 합니다.
기본 동작
쿼리하려는 데이터는 ES에 저장되어 있지만 데이터베이스에 저장된 데이터의 형식과 형식이 다릅니다. ES에서는 데이터베이스 테이블과 기능면에서 유사한 역색인을 먼저 생성한 다음 역색인에 데이터를 추가해야 하며, 추가된 데이터를 문서라고 합니다. 따라서 ES 작업을 수행하려면 먼저 인덱스를 생성한 후 문서를 추가해야 후속 쿼리 작업을 수행할 수 있습니다.
ES를 운영하려면 Rest-style 요청을 통해 수행할 수 있습니다. 즉, 요청을 보내면 작업을 수행할 수 있습니다. 예를 들어, 인덱스 생성 및 삭제는 요청을 보내는 형태로 수행될 수 있습니다.
-
색인 생성, books는 색인 이름, 아래 동일
PUT请求 http://localhost:9200/books요청을 보낸 후 인덱스가 성공적으로 생성되었다는 다음 정보가 표시됩니다.
{ "acknowledged": true, "shards_acknowledged": true, "index": "books" }기존 인덱스를 반복적으로 생성하면 오류 메시지가 표시됩니다. 오류 이유는 reason 속성에 설명되어 있습니다.
{ "error": { "root_cause": [ { "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "books" } ], "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", # books索引已经存在 "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "book" }, "status": 400 } -
쿼리 인덱스
GET请求 http://localhost:9200/books다음과 같이 인덱스 관련 정보를 얻기 위해 인덱스를 쿼리합니다.
{ "book": { "aliases": { }, "mappings": { }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645768584849", "number_of_replicas": "1", "uuid": "VgC_XMVAQmedaiBNSgO2-w", "version": { "created": "7160299" } } } } }존재하지 않는 인덱스를 조회하면 오류 메시지가 반환되며, 예를 들어 book이라는 인덱스를 조회한 후의 정보는 다음과 같다.
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [book]", "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" } ], "type": "index_not_found_exception", "reason": "no such index [book]", # 没有book索引 "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" }, "status": 404 } -
드롭 인덱스
DELETE请求 http://localhost:9200/books모두 삭제 후 삭제 결과 제공
{ "acknowledged": true }중복이 삭제되면 오류 메시지가 표시되고 특정 오류 이유도 reason 속성에 설명됩니다.
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [books]", "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" } ], "type": "index_not_found_exception", "reason": "no such index [books]", # 没有books索引 "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" }, "status": 404 } -
인덱스 생성 및 토크나이저 지정
앞서 생성한 인덱스는 토크나이저를 지정하지 않고, 인덱스 생성 시 토크나이저를 설정하는 요청 파라미터를 추가할 수 있습니다. 현재 중국에서 가장 인기 있는 토크나이저는 IK 토크나이저이며, 사용하기 전에 해당 토크나이저를 다운로드하여 사용하십시오.
IK 토크나이저 다운로드 주소: https://github.com/medcl/elasticsearch-analysis-ik/releases 토크나이저 다운로드 후 ES 설치 디렉터리의 plugins 디렉터리에 압축을 풀고, 토크나이저 설치 후 ES 서버를 재시작해야 합니다. IK 토크나이저를 사용하여 인덱스 형식을 만듭니다.
PUT请求 http://localhost:9200/books 请求参数如下(注意是json格式的参数) { "mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性 "properties":{ #定义索引中包含的属性设置 "id":{ #设置索引中包含id属性 "type":"keyword" #当前属性可以被直接搜索 }, "name":{ #设置索引中包含name属性 "type":"text", #当前属性是文本信息,参与分词 "analyzer":"ik_max_word", #使用IK分词器进行分词 "copy_to":"all" #分词结果拷贝到all属性中 }, "type":{ "type":"keyword" }, "description":{ "type":"text", "analyzer":"ik_max_word", "copy_to":"all" }, "all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询 "type":"text", "analyzer":"ik_max_word" } } } } 생성이 완료된 후 반환되는 결과는 토크나이저를 사용하지 않고 인덱스를 생성한 결과와 같으며, 이때 추가된 요청 파라미터 매핑이 인덱스 속성에 입력되었음을 인덱스 정보를 통해 확인할 수 있습니다.
{ "books": { "aliases": { }, "mappings": { #mappings属性已经被替换 "properties": { "all": { "type": "text", "analyzer": "ik_max_word" }, "description": { "type": "text", "copy_to": [ "all" ], "analyzer": "ik_max_word" }, "id": { "type": "keyword" }, "name": { "type": "text", "copy_to": [ "all" ], "analyzer": "ik_max_word" }, "type": { "type": "keyword" } } }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645769809521", "number_of_replicas": "1", "uuid": "DohYKvr_SZO4KRGmbZYmTQ", "version": { "created": "7160299" } } } } }
현재 인덱스는 있지만 인덱스에 데이터가 없으므로 먼저 데이터를 추가해야 하는데, ES에서는 해당 데이터를 문서라고 하며, 아래에서 문서 작업을 수행한다.
-
문서를 추가하는 세 가지 방법이 있습니다
POST请求 http://localhost:9200/books/_doc #使用系统生成id POST请求 http://localhost:9200/books/_create/1 #使用指定id POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增) 文档通过请求参数传递,数据格式json { "name":"springboot", "type":"springboot", "description":"springboot" } -
쿼리 문서
GET请求 http://localhost:9200/books/_doc/1 #查询单个文档 GET请求 http://localhost:9200/books/_search #查询全部文档 -
조건부 쿼리
GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值 -
문서 삭제
DELETE请求 http://localhost:9200/books/_doc/1 -
문서 수정(전체 업데이트)
PUT请求 http://localhost:9200/books/_doc/1 文档通过请求参数传递,数据格式json { "name":"springboot", "type":"springboot", "description":"springboot" } -
개정된 문서(부분적으로 업데이트됨)
POST请求 http://localhost:9200/books/_update/1 文档通过请求参数传递,数据格式json { "doc":{ #部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新 "name":"springboot" #仅更新提供的属性值,未提供的属性值不参与更新操作 } }
통합
springboot를 사용하여 ES를 통합하는 방법은 무엇입니까? 이전 규칙은 좌표를 가져오고 구성을 수행하고 API 인터페이스를 사용하여 작동합니다. Redis의 통합은 동일하고 MongoDB의 통합은 동일하며 ES의 통합은 여전히 동일합니다. 새롭지는 않지만 새롭지 않은 것도 아니다 이것이 스프링부트의 힘이다 모든 것이 같은 규칙으로 만들어져 개발자들에게 매우 친숙하다.
ES와 springboot의 통합을 시작해 보겠습니다. 단계는 다음과 같습니다.
1단계 : ES 통합을 위해 springboot의 시작 좌표를 가져옵니다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2단계 : 기본 구성 수행
spring:
elasticsearch:
rest:
uris: http://localhost:9200
ES 서버 주소, 포트 9200 구성
3단계 : springboot를 사용하여 ES의 전용 클라이언트 인터페이스 ElasticsearchRestTemplate을 통합하여 작동
@SpringBootTest
class Springboot18EsApplicationTests {
@Autowired
private ElasticsearchRestTemplate template;
}
위의 동작 형태는 ES의 초기 동작 방식이며, 사용하는 클라이언트를 Low Level Client라고 하며, 이 클라이언트 동작 방식의 성능이 다소 미흡하여 ES는 High Level Client라는 새로운 클라이언트 동작 방식을 개발하였습니다. 상위 클라이언트는 ES 버전과 동기적으로 업데이트되지만, springboot는 처음 ES 통합 시 하위 클라이언트를 사용했기 때문에 엔터프라이즈 개발은 상위 클라이언트 모드로 교체해야 합니다.
다음은 고수준 클라이언트 방식을 사용하여 ES와 springboot를 통합하는 작업 단계는 다음과 같습니다.
1단계 : ES 고급 클라이언트의 좌표를 통합하기 위해 springboot 가져오기 현재 이 양식에 해당하는 스타터가 없습니다.
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2단계 : 연결된 ES 서버를 프로그래밍 방식으로 설정하고 클라이언트 개체 가져오기
@SpringBootTest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateClient() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
client.close();
}
}
ES 서버 주소와 포트 9200을 설정합니다. 사용 후에는 클라이언트를 수동으로 닫아야 합니다. 현재 클라이언트는 수동으로 유지 관리되므로 자동 연결을 통해 개체를 로드할 수 없습니다.
3단계 : 인덱스 생성과 같은 ES 운영을 위해 클라이언트 객체를 사용
@SpringBootTest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
client.close();
}
}
High-level 클라이언트 작업은 요청을 전송하여 모든 작업을 완료합니다. ES는 다양한 작업에 대한 다양한 요청 개체를 설정합니다. 위의 예에서 인덱스를 생성하는 개체는 CreateIndexRequest이고 다른 작업에도 전용 Request 개체가 있습니다.
현재 오퍼레이션에서는 어떠한 ES 오퍼레이션을 하든, 첫 번째 단계는 항상 RestHighLevelClient 객체를 획득하는 것이고, 마지막 단계는 항상 객체의 연결을 닫는다는 것을 알게 되었습니다. 테스트에서는 테스트 클래스의 기능을 사용하여 개발자가 위의 작업을 한 번에 완료할 수 있지만 비즈니스를 작성할 때 스스로 관리해야 합니다. 클라이언트 객체를 유지하기 위해 테스트 클래스의 초기화 메소드와 파괴 메소드를 사용하도록 위의 코드 형식을 변환합니다.
@SpringBootTest
class Springboot18EsApplicationTests {
@BeforeEach //在测试类中每个操作运行前运行的方法
void setUp() {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
}
@AfterEach //在测试类中每个操作运行后运行的方法
void tearDown() throws IOException {
client.close();
}
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
}
}
이제 글쓰기가 훨씬 간소화되고 합리적입니다. 그런 다음 위의 모드를 사용하여 모든 ES 작업을 한 번 실행하고 결과를 테스트합니다.
인덱스 생성(IK 토크나이저) :
@Test
void testCreateIndexByIK() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
String json = "{\n" +
" \"mappings\":{\n" +
" \"properties\":{\n" +
" \"id\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"copy_to\":\"all\"\n" +
" },\n" +
" \"type\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"copy_to\":\"all\"\n" +
" },\n" +
" \"all\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
//设置请求中的参数
request.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
IK 토크나이저는 요청 매개변수 형태로 설정되며, 요청 매개변수는 요청 객체의 소스 메소드를 사용하여 설정됩니다. 매개변수는 작업 유형에 따라 다릅니다. 요청에 매개변수가 필요한 경우 현재 형식으로 매개변수를 설정할 수 있습니다.
문서 추가 :
@Test
//添加文档
void testCreateDoc() throws IOException {
Book book = bookDao.selectById(1);
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
}
문서를 추가할 때 사용하는 요청 객체는 IndexRequest로, 인덱스를 생성할 때 사용하는 요청 객체와 다릅니다.
일괄 문서 추가 :
@Test
//批量添加文档
void testCreateDocAll() throws IOException {
List<Book> bookList = bookDao.selectList(null);
BulkRequest bulk = new BulkRequest();
for (Book book : bookList) {
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
bulk.add(request);
}
client.bulk(bulk,RequestOptions.DEFAULT);
}
Batch를 할 때 먼저 BulkRequest 객체를 생성하여 요청객체를 저장하는 컨테이너로 이해할 수 있으며 모든 요청이 초기화된 후 BulkRequest 객체에 추가한 후 BulkRequest 객체의 bulk 메소드를 사용한다. 완료되었습니다.
id로 문서 쿼리 :
@Test
//按id查询
void testGet() throws IOException {
GetRequest request = new GetRequest("books","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
System.out.println(json);
}
id로 문서를 조회하는 데 사용되는 요청 객체는 GetRequest입니다.
기준에 따라 문서 쿼리 :
@Test
//按条件查询
void testSearch() throws IOException {
SearchRequest request = new SearchRequest("books");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termQuery("all","spring"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsString();
//System.out.println(source);
Book book = JSON.parseObject(source, Book.class);
System.out.println(book);
}
}
조건별로 문서를 조회하기 위해 사용하는 요청 객체는 SearchRequest 입니다. 조회 시 SearchRequest 객체의 termQuery 메소드를 호출하고 조회 속성 이름을 부여해야 합니다. 여기서 merge 필드를 지원합니다. 즉, all 속성이 추가됩니다 인덱스 속성이 이전에 정의되었을 때.
springboot ES 통합 작업은 여기에서 완료되었습니다. 이전 단계에서 redis와 mongodb를 통합하는 springboot의 차이는 여전히 큽니다. 주된 이유는 ES 클라이언트 개체를 통합하기 위해 springboot를 사용하지 않았기 때문입니다. 오퍼레이션은 ES 오퍼레이션의 종류가 너무 많아서 오퍼레이션이 조금 복잡해 보입니다.
요약하다
- springboot는 ES 단계를 통합합니다
- ES의 고급 클라이언트 좌표를 통합하기 위해 springboot 가져오기
- 초기화 및 종료 작업을 포함한 클라이언트 개체의 수동 관리
- 다른 유형의 작업에 따라 해당 작업을 완료하기 위해 다른 요청 개체를 선택하기 위해 고급 클라이언트를 사용합니다.