파일 저장 형식
Hive 공식 웹사이트에서 Apache Hive는 Apache Hadoop에서 사용되는 여러 친숙한 파일 형식(예: , TextFile(文本格式), RCFile(行列式文件), SequenceFile(二进制序列化文件)및 현재 사용 중인 AVRO, 및 .ORC(优化的行列式文件)ParquetTextFileSequenceFileORCParquet
이 두 가지 결정적 저장소에 대해 자세히 살펴보겠습니다.
1, 오크
1.1 ORC 저장 구조
먼저 공식 웹 사이트에서 ORC 스토리지 모델 다이어그램을 얻습니다.
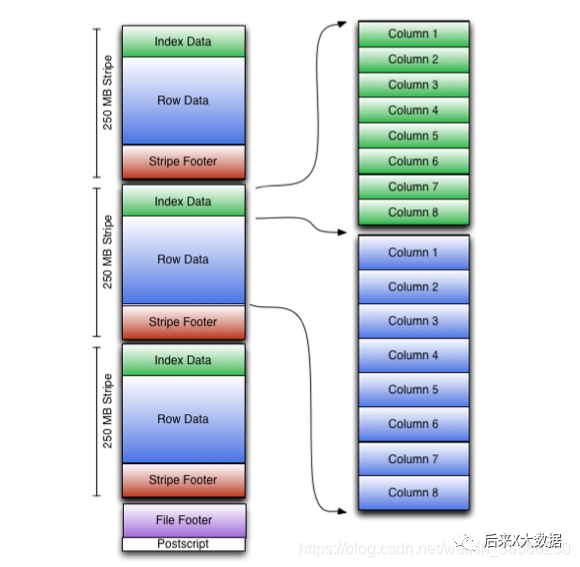
조금 복잡해 보여서 조금 단순화 시켜 보겠습니다.
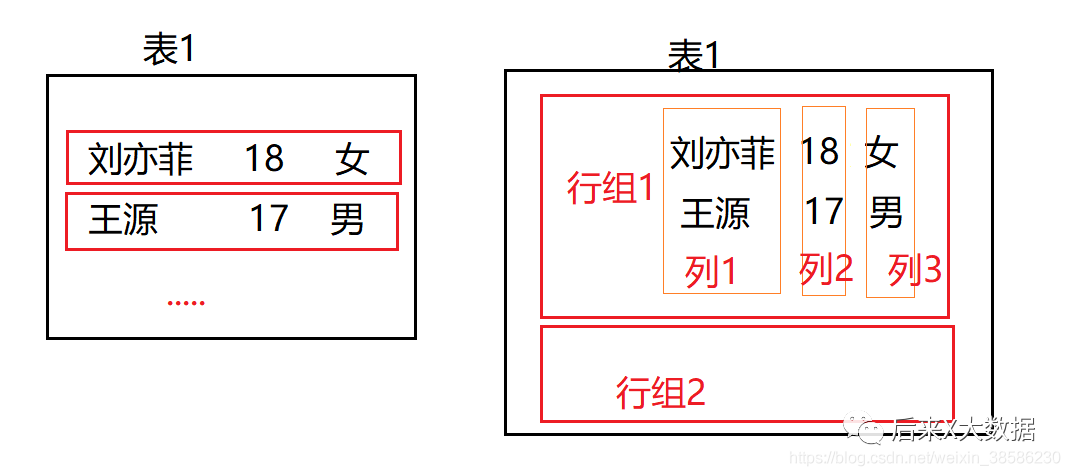
왼쪽 그림은 기존의 행 기반 데이터베이스 저장 방식을 보여주며, 저장 인덱스가 없는 경우 필드를 쿼리해야 하는 경우 전체 행의 데이터를 찾아 필터링해야 합니다. 더 많은 IO 리소스를 소모하므로 초기에 Hive에서 이 문제를 해결하기 위해 인덱스 방식을 사용했습니다.
하지만 인덱스의 높은 비용으로 인해 " 현재 Hive 3.X에서는 인덱스가 폐지되었다" 는 점 은 물론, 컬럼형 스토리지가 도입된 지 오래다.
컬럼형 스토리지의 저장 방식은 위 그림의 오른쪽 그림과 같이 한 번에 한 컬럼씩 저장되는데, 이 경우 필드의 데이터를 쿼리하면 인덱스 쿼리와 동일하므로 매우 효율적입니다. . 그러나 전체 테이블을 조회해야 하는 경우 모든 열을 가져와 별도로 요약해야 하므로 더 많은 리소스를 차지합니다. 그래서 ORC 결정적 저장소가 나타났습니다.
-
전체 테이블 스캔이 필요한 경우 행 그룹별로 읽을 수 있습니다.
-
열 데이터를 가져와야 하는 경우 모든 행 그룹의 모든 행 데이터와 한 행의 모든 필드 데이터가 아닌 행 그룹을 기준으로 지정된 열을 읽습니다.
ORC 스토리지의 기본 논리를 이해한 후 스토리지 모델 다이어그램을 살펴보겠습니다.
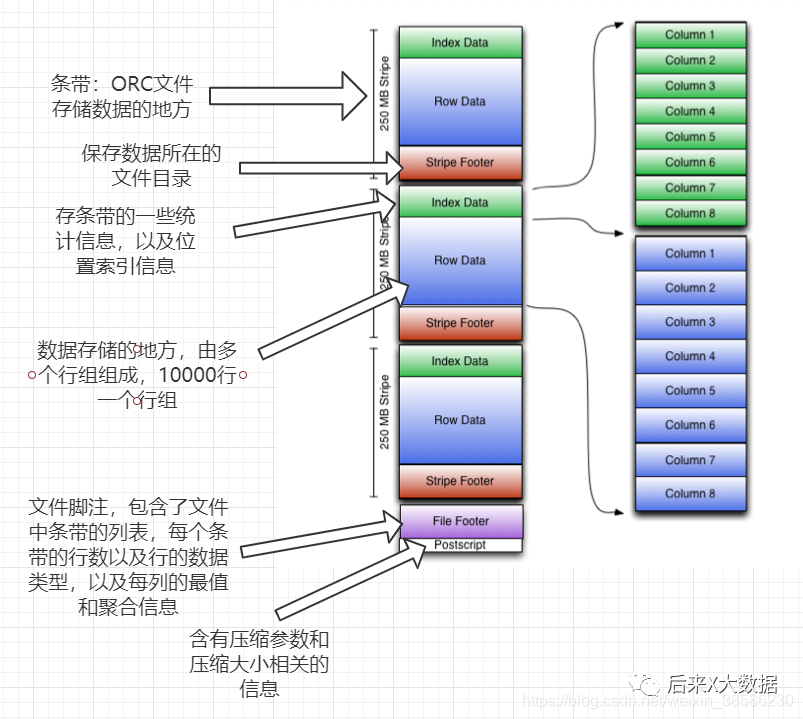
동시에 아래에 자세한 내용도 첨부하였으니 확인하실 수 있습니다.
-
스트라이프: ORC 파일이 데이터를 저장하는 곳에서 각 스트라이프는 일반적으로 HDFS의 블록 크기입니다. (다음 3개 파트 포함)
index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息。
rows data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流( stream)的形式进行存储。
stripe footer:保存数据所在的文件目录
-
파일 바닥글: 파일의 sipe 목록, 각 스트라이프의 줄 수 및 각 열의 데이터 유형이 포함됩니다. 또한 각 열에 대한 최소, 최대, 행 수, 합계 등과 같은 집계된 정보를 포함합니다.
-
포스트스크립트: 압축 매개변수 및 압축 크기에 대한 정보가 들어 있습니다.
그래서 실제로 ORC는 파일 레벨, 스트립 레벨, 행 그룹 레벨의 3가지 레벨의 인덱스를 제공하므로 쿼리 시 이러한 인덱스를 사용하여 쿼리 조건에 맞지 않는 대부분의 파일 및 데이터 블록을 피할 수 있음을 알 수 있습니다. .
단, ORC의 모든 데이터에 대한 설명 정보는 저장된 데이터와 함께 통합되며 외부 데이터베이스를 사용하지 않는다는 점에 유의하십시오.
"특별 참고 사항: ORC 형식 테이블도 트랜잭션 ACID를 지원하지만 트랜잭션을 지원하는 테이블은 버킷 테이블이어야 하므로 대규모 데이터 배치 업데이트에 적합합니다. 트랜잭션으로 작은 데이터 배치를 자주 업데이트하지 않는 것이 좋습니다."
#开启并发支持,支持插入、删除和更新的事务
set hive. support concurrency=truei
#支持ACID事务的表必须为分桶表
set hive. enforce bucketing=truei
#开启事物需要开启动态分区非严格模式
set hive.exec,dynamicpartition.mode-nonstrict
#设置事务所管理类型为 org. apache.hive.q1. lockage. DbTxnManager
#原有的org. apache. hadoop.hive.q1.1 eckmar. DummyTxnManager不支持事务
set hive. txn. manager=org. apache. hadoop. hive. q1. lockmgr DbTxnManageri
#开启在相同的一个 meatore实例运行初始化和清理的线程
set hive. compactor initiator on=true:
#设置每个 metastore实例运行的线程数 hadoop
set hive. compactor. worker threads=l
#(2)创建表
create table student_txn
(id int,
name string
)
#必须支持分桶
clustered by (id) into 2 buckets
#在表属性中添加支持事务
stored as orc
TBLPROPERTIES('transactional'='true‘);
#(3)插入数据
#插入id为1001,名字为student 1001
insert into table student_txn values('1001','student 1001');
#(4)更新数据
#更新数据
update student_txn set name= 'student 1zh' where id='1001';
# (5)查看表的数据,最终会发现id为1001被改为 sutdent_1zh
1.2 ORC에 대한 하이브 구성
테이블 구성 속성(예: 테이블 생성 시 구성 tblproperties ('orc.compress'='snappy');)
-
orc.compress: ORC 파일의 압축 유형을 나타냅니다. "선택적 유형은 NONE, ZLB 및 SNAPPY입니다. 기본값은 ZLIB입니다(Snappy는 슬라이스를 지원하지 않음)" --- 이 구성이 가장 중요합니다.
-
orc.compress.Slze: 압축된 블록(청크)의 크기를 나타내며 기본값은 262144(256KB)입니다.
-
orc.stripe.size: 쓰기 스트라이프, 사용할 수 있는 메모리 버퍼 풀의 크기, 기본값은 67108864(64MB)입니다.
-
orc.row.index.stride: 행 그룹 수준 인덱스의 데이터 크기, 기본값은 10000, 10000 이상의 숫자로 설정해야 합니다.
-
orc.create index: 행 그룹 레벨 인덱스 생성 여부, 기본값은 true
-
orc.bloom filter.columns: 블룸 필터를 생성해야 하는 그룹입니다.
-
orc.bloom 필터 fpp: 블룸 필터를 사용한 거짓 긍정(False Positive) 확률, 기본값은 0입니다.
확장: Hive에서 블룸 필터를 사용하면 파일 공간이 적은 테이블에 데이터가 저장되어 있는지 여부를 빠르게 확인할 수 있지만 이 테이블에 속하지 않는 데이터가 이 테이블에 속하는 것으로 판단되는 상황도 있습니다. 가양성 확률이라고 하는 개발자는 확률을 조정할 수 있지만 확률이 낮을수록 블룸 필터가 필요합니다.
2, 쪽모이 세공 마루
위의 ORC에 대해 이야기하고 나면 행-열 스토리지에 대한 기본적인 이해도 갖게 되었으며 Parquet은 또 다른 고성능 행-열 스토리지 구조입니다.
2.1 Parquet의 보관 구조
ORC는 매우 효율적이기 때문에 다른 Parquet이 있어야 하는 이유는 "Parquet은 Hadoop 에코시스템의 모든 프로젝트에서 사용할 수 있는 압축되고 효율적인 열 데이터 표현을 만드는 것" 이기 때문입니다.
❝Parquet은 언어 독립적이며 데이터 처리 프레임워크에 구속되지 않으며 다양한 언어 및 구성 요소에 적합합니다. Parquet과 함께 작동할 수 있는 구성 요소는 다음과 같습니다.
쿼리 엔진: Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL
컴퓨팅 프레임워크: MapReduce, Spark, Cascading, Crunch, Scalding, Kite
데이터 모델: Avro, Thrift, 프로토콜 버퍼, POJO
❞
먼저 공식 홈페이지에서 파르케의 수납 구조를 살펴볼까요?

음 좀 크긴 한데 단순화해서 그려볼게
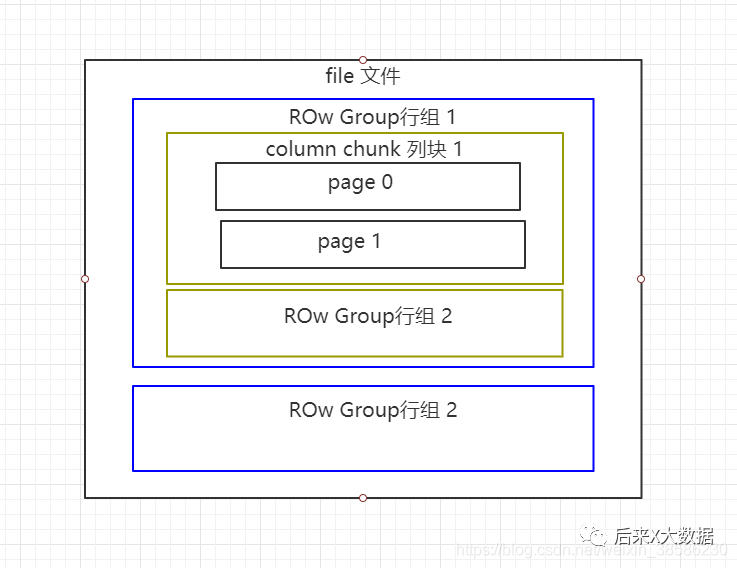
Parquet 파일은 바이너리 형식으로 저장되어 직접 읽을 수 없으며, ORC와 마찬가지로 파일의 메타데이터가 데이터와 함께 저장되므로 Parquet 형식 파일은 자체 파싱됩니다.
-
행 그룹: 각 행 그룹에는 특정 수의 행이 포함되며, 오크의 스트라이프 개념과 유사하게 HDFS 파일에 하나 이상의 행 그룹이 저장됩니다.
-
열 청크: 행 그룹의 각 열은 열 블록에 저장되고 행 그룹의 모든 열은 이 행 그룹 파일에 연속적으로 저장됩니다. 열 블록의 값은 모두 동일한 유형이며 다른 열 블록은 다른 알고리즘을 사용하여 압축될 수 있습니다.
-
페이지: 각 열 블록은 여러 페이지로 나뉩니다. 페이지는 가장 작은 코딩 단위입니다. 동일한 열 블록의 다른 페이지는 다른 코딩 방법을 사용할 수 있습니다.
2.2Parquet 테이블 구성 속성
-
parquet.block 크기: 기본값은 134217728byte로 메모리에 있는 Row Group의 블록 크기를 나타내는 128MB입니다. 이 값을 크게 설정하면 Parquet 파일의 읽기 효율을 높일 수 있지만 그에 따라 쓰기 시 더 많은 메모리를 소모하게 된다.
-
parquet.page:size: 기본값은 1048576byte로 각 페이지(페이지)의 크기를 나타내는 1MB이다. 이것은 특히 압축된 페이지 크기를 나타내며 읽을 때 페이지의 데이터가 먼저 압축 해제됩니다. 페이지는 Parquet 운영 데이터의 가장 작은 단위이며 데이터에 액세스하려면 매번 전체 데이터 페이지를 읽어야 합니다. 이 값을 너무 작게 설정하면 압축할 때 성능 문제가 발생합니다.
-
parquet.compression: 기본값은 페이지의 압축 방식을 나타내는 UNCOMPRESSED입니다. "사용 가능한 압축 방법은 UNCOMPRESSED, SNAPPY, GZP 및 LZO입니다." .
-
Parquet enable 사전: 기본값은 사전 인코딩이 활성화되었는지 여부를 나타내는 tue입니다.
-
parquet.dictionary page.size: 기본값은 1048576byte로 1MB입니다. 사전 인코딩을 사용하면 Parquet의 각 행과 열에 사전 페이지가 생성됩니다. 사전 인코딩을 사용하면 저장된 데이터 페이지에 반복되는 데이터가 많을 경우 압축 효과가 좋고 각 페이지의 메모리 점유율을 줄일 수 있습니다.
3. ORC와 Parquet의 비교
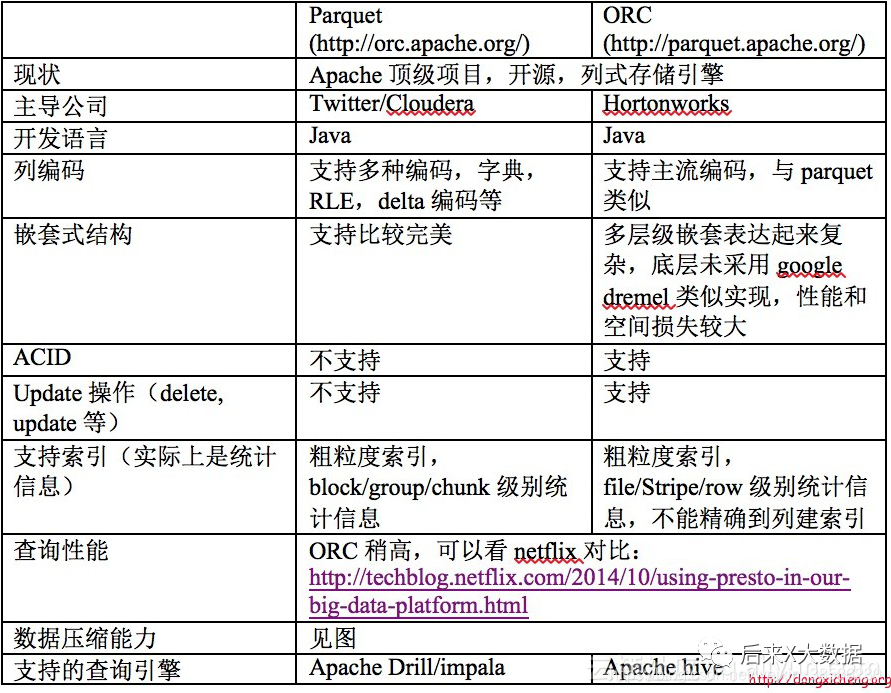
동시에 "Hive Performance Tuning in Practice" 저자의 사례에서 ORC와 Parquet 스토리지 포맷을 각각 사용하는 2개의 테이블에서 동일한 데이터를 임포트하고 sql 쿼리를 수행하면서 "ORC를 사용하여 읽은 행이 발견됨을 알 수 있다. Parquet보다 훨씬 작기 때문에 ORC를 스토리지로 사용하면 메타데이터의 도움으로 더 많은 불필요한 데이터를 필터링할 수 있으며 쿼리는 Parquet보다 적은 클러스터 리소스를 필요로 합니다. (자세한 성능 분석은 https://blog.csdn.net/yu616568/article/details/51188479로 이동)
"그래서 ORC는 여전히 스토리지 측면에서 더 좋아 보입니다."
압축 방법
| 체재 | 나눌 수 있는 | 평균 압축 속도 | 텍스트 파일 압축 효율성 | 하둡 압축 코덱 | 순수 자바 구현 | 토종의 | 주목 |
|---|---|---|---|---|---|---|---|
| gzip | 아니요 | 빠른 | 높은 | org.apache.hadoop.io.compress.GzipCodec | 예 | 예 | |
| 이조 | 예(사용된 라이브러리에 따라 다름) | 매우 빠르게 | 중간 | com.hadoop.compression.lzo.LzoCodec | 예 | 예 | 각 노드에 LZO를 설치해야 합니다. |
| bzip2 | 예 | 느린 | 매우 높은 | org.apache.hadoop.io.compress.Bzip2Codec | 예 | 예 | 분할 가능한 버전에 순수 Java 사용 |
| 즐리브 | 아니요 | 느린 | 중간 | org.apache.hadoop.io.compress.DefaultCodec | 예 | 예 | Hadoop의 기본 압축 코덱 |
| 팔팔한 | 아니요 | 매우 빠르게 | 낮은 | org.apache.hadoop.io.compress.SnappyCodec | 아니요 | 예 | Snappy에는 순수한 Java 포트가 있지만 Spark/Hadoop에서는 작동하지 않습니다. |
저장과 압축의 조합을 선택하는 방법은 무엇입니까?
ORC 및 쪽모이 세공의 요구 사항에 따르면 일반적으로
1. ORC 포맷 저장, Snappy 압축
create table stu_orc(id int,name string)
stored as orc
tblproperties ('orc.compress'='snappy');
2, 쪽모이 세공 마루 형식 저장, Lzo 압축
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='lzo');
3, 쪽모이 세공 마루 형식 저장, Snappy 압축
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='snappy');
Hive의 SQL은 MR 작업 으로 변환되기 때문에 파일이 ORC에 저장되어 있으면 Snappy가 압축합니다 . 그러면 파일의 맵을 처리하는 데 필요한 시간이 일반 파일의 맵을 읽는 시간보다 훨씬 더 길어지며, 이를 종종 "파일을 읽는 맵의 데이터 왜곡"이라고 합니다.
이러한 상황을 피하기 위해서는 데이터를 압축할 때 bzip2, Zip과 같은 파일 분할을 지원하는 압축 알고리즘을 사용해야 합니다. 그러나 ORC는 방금 언급한 이러한 압축 방법을 지원하지 않으므로 사람들이 데이터 왜곡을 피하기 위해 대용량 파일을 접할 때 ORC를 선택하지 않는 이유입니다.
Hve on Spark 접근 방식에서도 마찬가지입니다.분산 아키텍처인 Spark는 일반적으로 여러 다른 시스템의 데이터를 함께 읽으려고 합니다. 이를 달성하기 위해 각 작업자 노드는 파일을 분할해야 하는 새 레코드의 시작을 찾을 수 있어야 하지만 분할할 수 없는 압축 형식의 일부 파일은 모든 데이터를 읽기 위해 단일 노드가 필요합니다. 성능 병목 현상을 만듭니다.