содержание
Тема 1: Анализ игрового процесса
Тема 2: Клиенты с наибольшим количеством заказов
Тема 4: Последовательные номера
предисловие
- Просмотрите предыдущие основные моменты
Ежедневная LeetCode (1)базы данныхпрактика 2 )
Тема 1: Анализ игрового процесса
511. Анализ игрового процесса I

- Требования к вопросу: Получить дату первого входа каждого игрока на платформу.
- Идея обработки: Дата входа в платформу в первый раз оказалась датой входа в платформу в первый раз, которая является наименьшей event_date в соответствующем player_id, так что идея вышла, и вы может напрямую запрашивать min(date) с помощью агрегированного запроса.
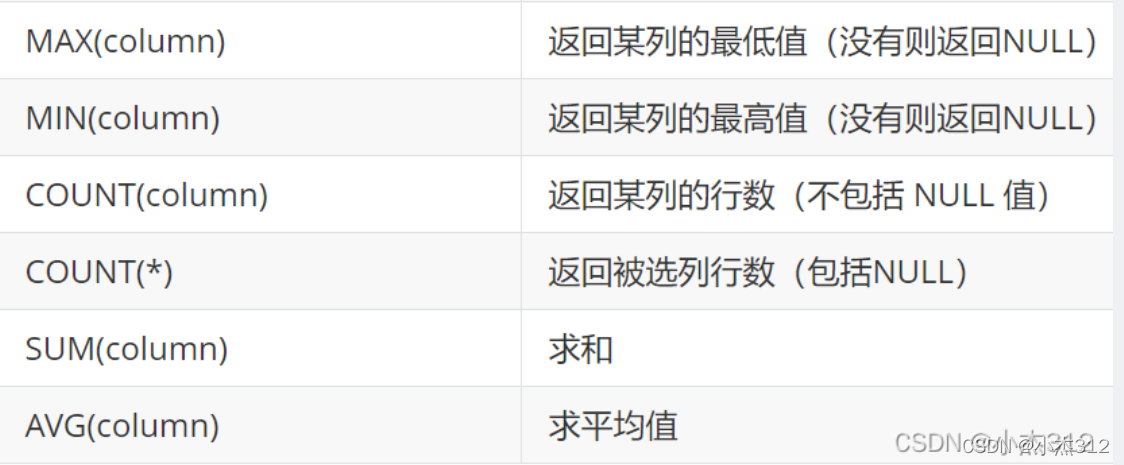
- Как думать об использовании агрегированного запроса, сначала есть несколько дат входа в систему, но нам нужна только самая маленькая, поэтому мы подумали о сжатии с помощью агрегированного запроса, который можно использовать в сочетании с агрегатными функциями.Обычно используемые агрегатные функции прикреплены следующим образом.
select
player_id,
min(event_date) as 'first_login'
from
activity
group by
player_id;Тема 2: Клиенты с наибольшим количеством заказов
586. Клиенты с наибольшим количеством заказов
- Требование к заголовку: Получите клиента с наибольшим количеством заказов
- Направление мышления: нам нужно получить клиента с наибольшим количеством заказов. Первый шаг — подсчитать количество заказов. Чтобы подсчитать количество заказов, нам нужно агрегировать запрос, count(customer_number) или count(*) для получить количество заказов, а затем прямо по количеству заказов от Сортировать от большого к меньшему.Первый пункт - это количество максимальных заказов, необходимых клиентам (чтобы получить самый большой, какой самый большой, а какой самый маленький , вы должны думать о сортировке + ограничении подкачки)
select
customer_number
from
orders
group by customer_number
order by count(*) desc
limit 0, 1; # 获取第一条记录Тема 3: Большие страны
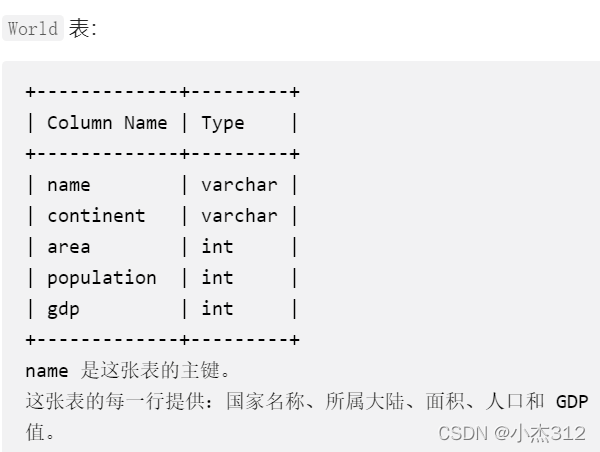
- Требования к названию: нам нужно отфильтровать основные страны в соответствии со следующими правилами.

- Идеи решения проблем: это очень просто, и этого можно достичь, напрямую запросив условие «где» для фильтрации больших стран.
select
name, population, area
from
world
where
area >= 3000000 or population >= 25000000;
-- where 条件筛选大国Тема 4: Последовательные номера

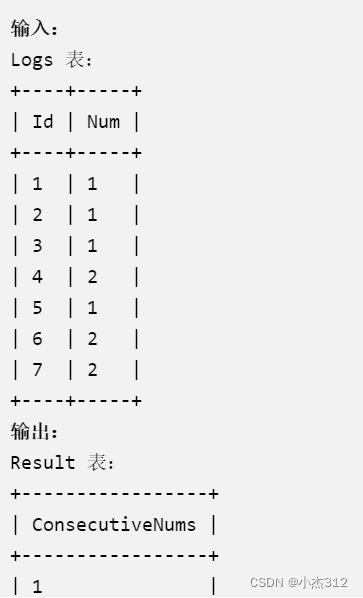
- Требования к предмету: 1. Происходит постоянно 2. Происходит три раза
- Поскольку нам нужно найти из одной и той же таблицы, есть только одна таблица, а отношение — это повторяющиеся записи num, которые появляются три раза подряд в таблице, поэтому легко подумать, что мы можем запрашивать через самосоединение. Тогда в процессе запроса обязательно будут повторы, т.к. это эквивалентно одной и той же таблице дважды подключается сама к себе , поэтому необходимо выполнить различное
select distinct
l1.num as 'ConsecutiveNums' -- 'consecutivenums'题目要求别名
from
logs l1 inner join logs l2 on l1.num = l2.num
inner join logs l3 on l1.num = l3.num
# 子连接关系条件满足同一个num
where
l1.id = l2.id + 1 && l2.id = l3.id + 1;
-- where条件保证连续记录Резюме темы
- Чтобы найти количество повторяющихся записей, нам нужно подумать о запросах агрегации, поскольку запросы агрегации могут сжимать одну и ту же операцию агрегации ключевых слов.
- Чтобы найти самую большую или самую маленькую запись, нам нужно подумать, что мы можем использовать sort + limit paging.
- Операция объединения нескольких таблиц не ограничивается количеством таблиц, и одновременно могут быть соединены даже три таблицы и четыре таблицы, но обычно не рекомендуется писать таким образом после того, как количество слишком велико, и вы нужно найти другой способ, потому что вы не можете записать его