Строки и кортежи очень похожи и не могут быть легко изменены после того, как они определены.
Если вам нужно изменить его, вы можете использовать срезы и конкатенации,
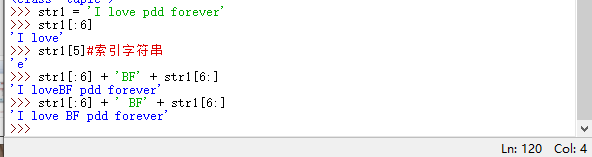
чтобы старая строка str1 все еще существовала, и она будет перезаписана после присвоения.Механизм сборки мусора Python удалит строки без тегов.

Встроенные методы для строк
| метод | смысл |
|---|---|
| капитализировать () | Измените первый символ строки на верхний регистр, а все остальные символы на строчные |
| футляр () | Все буквы новой строки становятся строчными |
| центр (ширина, fillchar = '') | Возвращает новую символьную строку с центрированием (ширина <= длина строки, новая строка = исходная строка; ширина> ширина строки, все символы центрированы, левый и правый заполнены символами, указанными параметром fillchar) |
| count (sub [, начало [, конец]]) | Возвращает количество неперекрывающихся вхождений sub в строке. Необязательные параметры start и end используются для указания начальной и конечной позиций. |
| заканчивается (суффикс [, начало [, конец]]) | Если строка заканчивается подстрокой, указанной суффиксом, то верните True, иначе верните False; необязательные параметры start и end используются для указания начальной и конечной позиций |
| expandtabs ([tabsize = 8]) | Возвращает новую строку, используя пробелы для замены табуляции. Если параметр tabsize не указан, то по умолчанию 1 табуляция = 8 пробелов. |
| find (sub [, начало [, конец]]) | Найдите подстроку в строке и верните наименьшее значение индекса совпадения; необязательные параметры start и end используются для указания начальной и конечной позиций; если подстрока не соответствует, верните -1 |
| присоединиться (повторяемый) | Объедините несколько строк и верните новую строку; используйте строку, вызывающую этот метод, в качестве разделителя и вставьте ее в середину каждой строки, указанной параметром итерации; |
| кодировать (кодировка = 'utf-8', ошибки = 'строгий') | Закодируйте строку в формате кодировки, заданном параметром кодирования. Параметр errors указывает решение при возникновении ошибки кодирования: значение по умолчанию «strict» означает, что в случае возникновения ошибки будет выдано UnicodeEncodeError. Другие доступные значения параметров: 'игнорировать', 'заменить' и 'xmlcharrefreplace'. |
| формат (* args, ** kwargs) | Вернуть новую отформатированную строку; используйте позиционные параметры (args) и аргументы ключевого слова (kwargs) для замены |
| format_map (отображение) | Вернуть новую отформатированную строку; использовать параметры сопоставления (сопоставление) для замены |
| index (sub [, начало [, конец]]) | Найдите подстроку в строке и верните наименьшее значение индекса для совпадения; необязательные параметры start и end используются для указания начальной и конечной позиций; если подстрока не соответствует, генерируется исключение ValueError |
| isalnum () | Если в строке есть хотя бы один символ и все символы являются буквами или цифрами, он возвращает True, в противном случае - False. |
| isalpha () | Если в строке есть хотя бы один символ и все символы являются буквами, он возвращает True, в противном случае - False. |
| isascii () | Если все символы в строке являются ASCII, он возвращает True, в противном случае он возвращает False; диапазон кодирования символов ASCII - U + 0000 ~ U + 007F, а пустая строка также является ASCII |
| isdecimal () | Если в строке есть хотя бы один символ и все символы являются десятичными числами, он возвращает True, в противном случае - False. |
| isdigit () | Если в строке есть хотя бы один символ и все символы являются числами, он возвращает True, в противном случае - False. |
| Идентификатор () | Если строка является допустимым идентификатором Python, она возвращает True, в противном случае она возвращает False; вызовите keyword.iskeyword (s), чтобы проверить, является ли строка зарезервированным идентификатором (например, «если» или «для») |
| islower () | Если строка содержит хотя бы одну английскую букву с учетом регистра, и все эти буквы строчные, верните True, в противном случае верните False |
| isnumeric () | Если в строке есть хотя бы один символ и все символы являются числами, он возвращает True, в противном случае - False. |
| для печати () | Если строка пригодна для печати, она возвращает True, в противном случае возвращает False. |
| isspace () | Если в строке есть хотя бы один символ и все символы являются пробелами, верните True, в противном случае верните False |
| список () | Если строка представляет собой строку с заголовком (все слова начинаются с верхнего регистра, остальные буквы в нижнем регистре), тогда верните True, иначе верните False |
| isupper () | Если строка содержит хотя бы одну английскую букву с учетом регистра, и все эти буквы являются прописными, вернуть True, иначе вернуть False |
| присоединиться (повторяемый) | Объедините несколько строк и верните новую строку; используйте строку, вызывающую этот метод, в качестве разделителя и вставьте ее в середину каждой строки, указанной параметром итерации; |
| яркий (ширина) | Вернуть новую строку с символами, выровненными по левому краю (ширина <= длина строки, новая строка = исходная строка; ширина> ширина строки, все символы выровнены по левому краю, а правая сторона заполнена символами, указанными параметром fillchar) |
| нижний () | Вернуть новую строку, в которой все английские буквы преобразованы в нижний регистр |
| lstrip (символы = Нет) | Вернуть новую строку с удаленными оставшимися пустыми символами; параметр chars можно использовать для указания удаляемой строки. |
| перегородка (сеп) | Найдите разделитель, указанный параметром sep в строке. Если он найден, верните кортеж из трех частей ('часть до sep', 'sep', 'часть после sep'); если не найден, верните ('Исходная строка ',' ',' ') |
| removeprefix (префикс) | Если подстрока префикса, указанная параметром префикса, существует, она возвращает новую строку с удаленным префиксом; если она не существует, она возвращает копию исходной строки |
| удаляет суффикс (суффикс) | Если существует подстрока суффикса, заданная параметром суффикса, он возвращает новую строку с удаленным суффиксом; если он не существует, он возвращает копию исходной строки |
| заменить (старый, новый, счетчик = -1) | 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部 |
| rfind(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1 |
| rindex(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常 |
| rjust(width, fillchar=’ ') | 返回一个字符右对齐的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 fillchar 参数指定的字符填充) |
| rpartition(sep) | 在字符串中自右向左搜索sep参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (’’, ‘’, ‘原字符串’) |
| rsplit(sep=None, maxsplit=-1) | 将字符串自右向左进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit 参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| rstrip(chars=None) | 返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| split(sep=None, maxsplit=-1) | 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| splitlines(keepends=False) | 将字符串按行分割,并将结果以列表的形式返回;keepends 参数指定是否包含换行符,True 是包含,False 是不包含 |
| startswith(prefix[, start[, end]]) | 如果存在 prefix 参数指定的前缀子字符串,则返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置;prefix 参数允许以元组的形式提供多个子字符串 |
| strip(chars=None) | 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| swapcase() | 返回一个大小写字母翻转的新字符串 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’) |
| upper() | 返回一个所有英文字母都转换成大写后的新字符串 |
| zfill(width) | 返回一个左侧用 0 填充的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 0 进行填充) |
capitalize():将字符串的第一个字符修改为大写,其他字符全部改为小写

casefold() :新字符串的所有字母变为小写

center(width, fillchar=’ ') : 返回一个字符居中的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符居中,左右使用 fillchar 参数指定的字符填充)

count(sub[, start[, end]]): 返回 sub 在字符串中不重叠的出现次数,可选参数 start 和 end 用于指定起始和结束位置

endswith(suffix[, start[, end]]): 如果字符串是以 suffix 指定的子字符串为结尾,那么返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置

expandtabs([tabsize=8]) :返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格

find(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1

index(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常
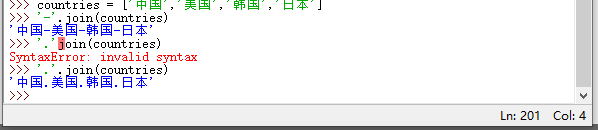
join(iterable) :连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到 iterable 参数指定的每个字符串的中间;
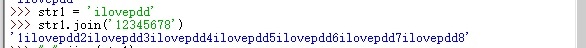
join()方法代替加号来拼接字符串
istitle():如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回 True,否则返回 False

lstrip(chars=None):返回一个去除左侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串
rstrip(chars=None):返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串

partition(sep) 在字符串中搜索 sep 参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (‘原字符串’, ‘’, ‘’)
replace(old, new, count=-1) 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部

split(sep=None, maxsplit=-1) 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制

strip(chars=None) 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串


swapcase() 返回一个大小写字母翻转的新字符串

translate(table) 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’)

Task
0. 还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
【1】三重引号字符串
【2】转义字符\n

【3】
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
1. 三引号字符串通常我们用于做什么使用?
三引号字符串不赋值的情况下,通常当作跨行注释使用
2. file1 = open ('C: \ windows \ temp \ readme.txt', 'r') означает открыть текстовый файл «C: \ windows \ temp \ readme.txt» в режиме только для чтения, но на самом деле это заявление будет сообщать об ошибке, вы знаете почему? Как бы вы его изменили?
"\ T" и "\ r" обозначают "горизонтальную табуляцию (TAB)" и "возврат каретки" соответственно.
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
3. Есть строка: str1 = '<a href="http://www.fishc.com/dvd" target="_blank"> Упаковка ресурсов Fish C', как извлечь подстроку: 'www.fishc. com '
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[16:29]

4. Если вы используете отрицательное число в качестве значения индекса для операции нарезки, сможете ли вы правильно визуально определить результат в соответствии с третьим вопросом?
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[-45:-32]

5. Это строка, о которой идет речь. 3. Что будет отображаться в предложении ниже?
>>> str1[20:-36]
'fishc'
6. Говорят, что только рыбий жир с IQ выше 150 может разблокировать эту строку (преобразованную в значимую строку): str1 = 'i2sl54ovvvb4e3bferi32s56h; $ c43.sfc67o0cm99'

(Я мало что знаю, ?????)
7. Напишите, пожалуйста, код для проверки безопасности пароля: check.py (в раздумьях ...)
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
