Требования к теме:
Все числа в массиве длины n находятся в диапазоне от 0 до n-1. Некоторые числа в массиве повторяются, но я не знаю, сколько чисел повторяется. Я не знаю, сколько раз каждое число повторяется. Пожалуйста, найдите любой дубликат числа в массиве. Например, если входной массив длины 7 равен {2,3,1,0,2,5,3}, то соответствующим выходным значением является первое повторное число 2.
Разрешение:
Способ 1:
сначала отсортировать массив, найти повторяющиеся числа из отсортированного массива - простая задача, но временная сложность O (nlogn) очень высока
Способ 2:
Поскольку все числа в массиве длины n находятся в диапазоне 0 ~ n-1, если нет повторяющихся чисел, то число i появится в позиции нижнего индекса i после сортировки массива. Однако из-за повторяющихся номеров в некоторых местах может быть несколько номеров, а в некоторых местах номеров может не быть.
Давайте рассмотрим конкретный пример для описания нашего метода,
такого как массив {2 , 3, 1, 0, 2, 5, 3}. Первое число 2! = Индекс 0, поэтому поменяйте местами 2 на позицию индекса 2.
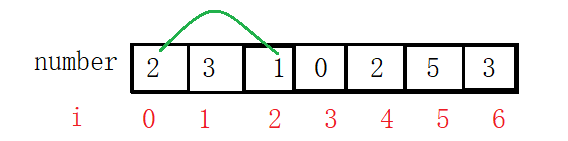
i ++, продолжайте сравнивать, второе число 3! = индекс 1, поэтому обмен 3 на позицию индекса 3 с
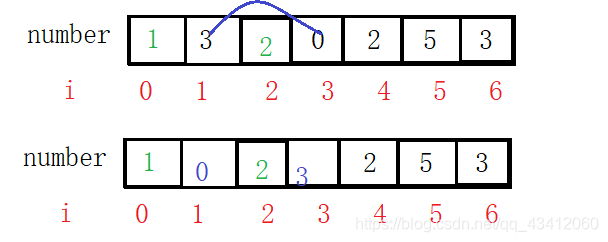
i ++, продолжайте сравнение, третье число 2 == индекс 2 не меняйте.
i ++, продолжайте сравнивать, четвертое число 3 == индекс 3, не обмениваться. ,
I ++, продолжить сравнение, пятое число 2! = Подстрочный индекс 4, сравнить число [4] == число [numver [4]]. Таким образом, была найдена двойная реализация кода значения
:
bool duplicate(int number[], int length, int* duplicate)
{
if (number == nullptr || length <= 0)
{
return false;
}
for (int i = 0; i < length; i++)
{
if (number[i]<0 || number[i]>length - 1)
{
return false;
}
}
for (int i = 0; i < length; i++)
{
while (i != number[i])
{
if (number[i] == number[number[i]])
{
*duplicate = number[i];
return true;
}
int tmp = number[i];
number[i] = number[tmp];
number[tmp] = tmp;
}
}
return false;
}
Улучшение темы:
Массивы, которые не могут быть введены на основе вышеуказанных вопросов
Разрешение:
Метод 1:
Мы создаем вспомогательный массив длиной n + 1, а затем копируем каждое число исходного массива во вспомогательный массив по одному и копируем число со значением m в позицию, отмеченную m. Но сложность пространства при этом составляет O (n). Итак, мы придумали другой метод
Способ 2: Это
все еще объясняется конкретным массивом, таким как массив {2,3,5,4,3,2,6,7}. Всего 8 номеров. Средняя 4 делит массив на две части, одна секция - 1-4, а другая секция - 5-7.

Число в 1-4 больше, чем последнее, поэтому повторяющееся число должно быть в диапазоне 1-4.
Затем разделите середину 2 на две группы,
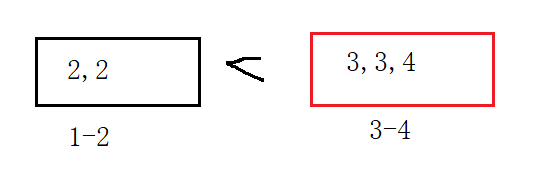
число в 1-2, 3-4 3-4 больше, чем в первой, поэтому число повторов должно быть в пределах 3-4.
Затем посчитайте, сколько раз эти два числа появляются в массиве.
Код реализован следующим образом:
int getcount(int* number, int length, int start, int end)
{
if (number == nullptr)
return 0;
int count = 0;
for (int i = 0; i < length; i++)
{
if (number[i] >= start && number[i] <= end)
{
count++;
}
}
return count;
}
int getduplicate(int* number, int length)
{
if (number == nullptr || length <= 0)
return -1;
int end = length - 1;//7
int start = 1;//1
while (end >= start)
{
int middle = ((end - start) >> 1) + start;//4
int count = getcount(number, length, start, middle);
if (end == start)
{
if (count > 1)
return start;
break;
}
if (count > (middle - start + 1))//5>4 所以在1-4里面再划分
end = middle;
else
start = middle;
}
return -1;
}
Этот метод аналогичен бинарному поиску, функция getcount называется O (logn) раз, каждый раз требуется O (n) время, поэтому сложность времени равна O (nlogn), но сложность пространства равна O (1). Это алгоритм пространства-времени.
