Às vezes você dar-lhe um ano para combater o telefone, você sabe? Eu não fiz muita pesquisa neste ano. Passei muito tempo no Twitter. Jogar por um tempo GAN. No ano passado, [12] [1] deixou um pouco de impulso, eu YOLO fez algumas melhorias. Mas, para ser honesto, não há nada de super interessante, apenas algumas pequenas mudanças para torná-lo melhor. Eu também ajudar os outros a fazer alguma pesquisa.
Na verdade, esta é a razão por que veio aqui hoje. Temos um pronto para atirar o prazo [4], é preciso referir-se a alguns dos YOLO de atualizações aleatórias, mas não temos uma fonte. Então, estar preparado um relatório técnico agora!
A grande coisa é que eles não precisam de relatório técnico descreve, você todos sabemos por que estamos aqui. Por isso, o resto do papel será o fim desta apresentação especificada direção. Em primeiro lugar, queremos dizer-lhe YOLOv3 como é. Então, vamos dizer-lhe como nós fazemos. Nós dizemos-lhe alguns de nós tentou, mas não conseguiu fazer. Finalmente, vamos considerar o que isso significa.
De acordo com YOLO9000, nossos usos sistema de cluster de dimensões como as caixas de ancoragem [15] para prever a caixa delimitadora. A previsão de rede de cada caixa delimitadora coordenadas dos quatro, ou seja, t X , T Y , T W , T H . Se a célula correspondente (coordenadas do canto superior esquerdo) é deslocada a partir das coordenadas do canto superior esquerdo da imagem inteira (C X , C Y ), a caixa delimitadora tendo uma largura e uma altura da priori P W , P H , correspondente à previsão:
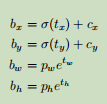
No treinamento, usamos o erro quadrado e perda. Se um valor verdadeiro do previsto a coordenar t ^ *, o nosso valor verdadeiro gradiente ( o valor do bloco real, calculado em conformidade com as fórmulas acima em ordem reversa ), subtraindo o valor de predição nos T * : t * - t * . O valor real pode facilmente reverter pela equação acima calculado.
YOLOv3 meio de regressão logística para prever a caixa delimitadora de cada pontuação objetiva. Se a caixa delimitadora de um priori a priori com a caixa de objetos real sobreposição mais do que qualquer outra caixa delimitadora, a pontuação deve ser 1. Se a caixa delimitadora não é a melhor, a priori, mas sobreposição de blocos verdadeiro alvo excede um certo limite, que irá ignorar a previsão , como [17] fez. Nós usamos um limiar de 0,5. E [17] diferente, o nosso sistema de cada objeto real quadro é atribuído apenas uma caixa delimitadora . Se não a priori delimitadora caixa atribuído a um objeto de caixa real, ele não gera perda de coordenadas ou previsão de classe, só levar a uma perda de confiança.
Cada caixa utilizada para prever caixa delimitadora classe pode conter o uso de classificação multi-rótulo. Nós não usamos softmax, porque descobrimos que não é necessário para o bom desempenho, pelo contrário, só usamos um classificador lógica separada. Durante o treinamento, nós usar a perda Mutual entropia (perda de cross-entropia binária) foram previstos classe .
Esta fórmula vai nos ajudar a mover-se para uma áreas mais complexas, tais como Abrir imagens Dataset [7]. Neste conjunto de dados há muitos rótulo sobreposição (ou seja, a mulher e homem). Usando um softmax impõe uma hipótese, isto é, exactamente uma classe para cada quadro, mas geralmente não é o caso. método multi-etiqueta pode ser melhor para os dados do modelo.
YOLOv3 previu três escalas diferentes característicos da FIG. Os nossos extractos sistema apresenta desta escala, uma característica semelhante à rede de pirâmide (FPN) [8] O conceito (isto é, a saída do gráfico característico de três tamanhos diferentes, mais ricas campos receptivos).
Do nosso início básica recurso exaustor, nós adicionamos várias camada de convolução. Finalmente, uma camada de convolução tridimensional foi um tensor que codifica a predição caixa, objecto e classe delimitadora. Nas experiências utilizou-se COCO [10] realizada, temos três característica quadro de predição para cada posição no mapa para cada tamanho, cada recurso de tensor de saída é, portanto, Fig N X N × [3 * (4 + 1 + 80)], 4 caixa delimitadora para offset, uma predição alvo e predição 80 classes. (Este é o primeiro tamanho característica do gráfico, e os resultados tensor 13 * 13 * [3 * (1 + 4 + 80)] = 13 * 13 * 255 com base no código)
Subsequentemente, a convolução de duas camadas antes da nossa acima transmitido a partir de extracção de características figura, e os tempos de amostragem na camada de convolução 2, para se obter uma camada de convolução. Nós também obter um diagrama característico B (A acima amostrada de saída do mesmo tamanho W * H) a partir da frente da camada de rede de convolução, e usando-o em série com o mapa de características de amostragem B Uma combinados para dar-nos um diagrama característico C. Este método permite a amostra adquiridos a partir da característica Uma informação semântica mais significativo, obter mais informações a partir do início de granulados B, em que a FIG. Em seguida, adicionar processamento convolução várias camadas desta combinação de características da FIG C, e, finalmente, um tensor previu semelhante, agora tensor 2 vezes o tamanho original (porque a amostra duas vezes, de 2N × 2N × [3 * (4 + 1 + 80)] = 26 * 26 * 255).
Foi realizada a mesma segundo passo concebido para prever o tamanho final da caixa de novo, o resultado é obtido 4N × 4N × [3 * ( 4 + 1 + 80)] = 52 * 52 * 255. Assim, beneficiar de todas as calculados uma características a priori ea rede do granulado-fino previsão inicial da terceira dimensão.
Nós ainda usamos os k-means clustering para determinar a caixa delimitadora do nosso a priori. Nós apenas temos que escolher os nove grupos e três dimensões e depois dividir uniformemente em cada escala de cluster. No conjunto de dados COCO, nove grupos, respectivamente (10 × 13), (16 x 30), (33 × 23), (30 × 61), (62 × 45), (59 x 119), (116 × 90), (156 x 198), (373 x 326).
Nós usamos uma nova rede para extração de características. A nossa nova rede é YOLOv2, uma abordagem de híbrido entre a rede Darknet-19 usadas no novo e a rede residual. A nossa rede contínua camada uma convolução 3 × 3 e um 1 × 1, e existem agora alguns conector rápido, e uma rede maior. Tem 53 camada de convolução. Espera ..... Darknet-53!
Esta nova rede de Darknet-19 é muito mais poderoso e mais eficiente do que ResNet-101 ou ResNet-152.
Aqui estão os resultados de alguns dos IMAGEnet:
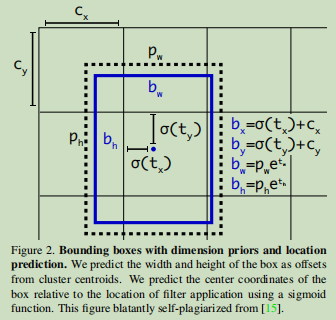
Cada rede é treinado usando as mesmas configurações, e testado em uma precisão de corte único de 256 × 256. tempo de execução foi em Titã X a uma velocidade de 256 × 256 medido. Portanto, Darknet-53 desempenho e a classificação mais avançada é comparável, mas menos operações de vírgula flutuante, mais rápido. Darknet-53 melhor do que ResNet-101, 1,5 vezes mais rápido. Darknet-53 e desempenho semelhante ResNet-152, e 2 vezes a velocidade deste último.
Darknet-53 também alcançado as operações mais elevados de ponto flutuante por segundo. Isto significa que a estrutura da rede melhor utilização do GPU, para torná-lo uma avaliação mais eficaz e, portanto, mais rápido. Isto é principalmente porque camada muitas ResNets, a eficiência não é alta.
Ainda estamos treinando a imagem completa, não um disco (mineração negativo duro) negativo ou qualquer outra escavação amostra método. Usamos formação multi-escala, um monte de expansão de dados, padronização de lotes e todas as outras coisas padrão. Usamos Darknet quadro rede neural para treinar e testar [14].
Tabela 3 YOLOv3 muito boa !:

Em termos de média métrica Cocos AP, que é bastante variante com SSD, mas três vezes mais rápido. No entanto, sobre este indicador, ele ainda está muito aquém de outros modelos RetinaNet e assim por diante.
Mas quando vemos o IOU = 0,5 (ou figura do AP 50 quando MAP métrica detecção de "velho") Departamento, conhecido YOLOv3 muito poderoso. É quase RetinaNet equivalente e muito maior do que o SS D variantes. Isso indica YOLOv3 é uma sonda muito poderoso, bom para a geração de caixa decente para o objeto. No entanto, com o aumento do limiar da IOU, o desempenho será significativamente reduzida, o que sugere que YOLOv3 difícil quadro perfeitamente alinhada com o objecto .
No passado, YOLO lutar com pequenos objetos. Agora, no entanto, vemos uma inversão desta tendência. Através de uma nova previsão multi-escala, vemos uma relativamente alta YOLOv3 a AP S desempenho. No entanto, o desempenho no objeto grande é relativamente pobre . Para averiguar a verdade da questão, precisam de mais investigação.
Quando o AP em 50 (ver Fig. 3) é apresentada no gráfico na precisão e velocidade de medição, vemos YOLOv3 têm vantagens significativas sobre outros sistemas de detecção. Em outras palavras, é mais rápido e melhor.

YOLOv3 quando tentamos fazer um monte de outras maneiras. Muitos inútil. Este é o método utilizado pode lembrar:
Anchor Box deslocamento x, y Predictions . Tentamos usar comum mecanismo de previsão caixas de ancoragem, em que você prever o deslocamento x, y como a utilização de uma largura de caixa de activação linear ou altura de um múltiplos. Encontramos esta receita reduz a estabilidade do modelo, o efeito não é muito bom.
X linear, Y, em vez Previsões de logística . Tentámos usando uma função de activação linear de predição x directos, Y de deslocamento, em vez do que a função de activação lógica. Isso levou a um declínio no número de pontos no mapa.
Perda Focal . Nós tentamos perda focal. Nosso mapa perdeu dois pontos. Para a perda focal para tentar resolver o problema, YOLOv3 pode ter sido o suficiente robusta, porque tem uma previsão de classe de objeto separado e condições de previsão. Assim, para a maioria dos casos, não há nenhuma perda de previsão de classe? Ou o quê? Não podemos completamente certo.
Limiares e Verdade Assignment IOU dupla . Faster RCNN IOU usando dois limiares durante o treinamento. Se um quadro predito se sobrepõe com a caixa verdadeiro 0,7, em seguida é um exemplo positivo, se a sobreposição [0,3 0,7] este intervalo de tempo, então o resultado é ignorado. Para todo objeto real, se a sobreposição é inferior a 0,3, então é um exemplo negativo. Nós tentamos uma estratégia semelhante, mas não obteve bons resultados.
Nós amamos nossa fórmula atual, pelo menos, parece ser localmente ideal. Algumas destas técnicas podem, eventualmente, produzir bons resultados, talvez eles só precisam de alguns ajustes para estabilizar o treinamento.
YOLOv3 é um detector de bom. É rápido e preciso. Entre 0,5 e 0,95 IOU, sua média COCO AP não é alto. Mas é muito bom no velho 0,5 índice de detecção de IOU.
Por que devemos alterar a métrica que Coco artigos originais única maneira de uma frase enigmática :? "Uma vez que a avaliação é servidor completa, adicione a discussão completa dos indicadores de avaliação." Russakovsky et al relatou que humana IOU difícil distinguir entre 0,3 e 0,5! "Treinado verificação visual humana no IOU como uma caixa delimitadora 0,3 e 0,5 área caixa delimitadora separadamente com IOU, é muito difícil. ? [18] Se o ser humano é difícil dizer a diferença entre os dois, em seguida, que serve para distinguir entre eles
, mas talvez a melhor pergunta é: "Agora que temos esses detectores, como podemos obtê-los" " muitas pessoas estão fazendo essa pesquisa no Google e Facebook. Eu acho que, pelo menos sabemos que uma boa compreensão da tecnologia, e certamente não vai ser usado para coletar suas informações pessoais e vender ...... Espere, você está dizendo que esta é a sua finalidade? Oh.
Outros fortemente subsidiada exército da Vision Research, eles nunca fizeram nada terrível coisas, como o uso de novas tecnologias para matar um monte de gente, e assim
espero sinceramente que a maioria das pessoas pode usar a visão de computador para fazer algo felizes, coisas boas como o Parque nacional [13] no número do número de zebra, ou acompanhar o seu gato [19] uma caminhada em sua casa. No entanto, visão computacional começou a ser questionada, como pesquisadores, temos a responsabilidade de considerar o menos possível dano ao nosso trabalho e para encontrar formas de atenuar isso. Afinal, devemos muito neste mundo.
Gostaríamos de agradecer aos meus colegas revisores Reddit, laboratórios, remetente do e-mail, e os aplausos vindos do corredor. Se você é como eu, então estamos avaliando ICCV sei que você provavelmente têm 37 outros arquivos que você pode ler, mas você vai sempre, sempre adiado para a última semana, e então há algumas lendas mail para dizer como você deve completar estas observações, a essas mensagens não são articular completamente o que eles querem dizer, talvez eles vêm do futuro? em qualquer caso, se você não tem todo o trabalho feito no próprio passado no passado, o presente trabalho não acabará por se tornar o que é hoje, ele só poderia ir em frente um pouco, mas não até agora tem estado à frente.
Avaliador # 2 aka Dan Grossman (lol autor ofuscante) insistem que estou aqui para apontar a origem do nosso gráfico tem dois não-zero. Você está absolutamente certo, Dan, parece melhor do que é, porque estamos todos aqui para confessar 2-3% luta mAPA muito melhor. No entanto, esse padrão é solicitada. Eu também acrescentou um FPS, porque quando nós desenhar no FPS, nós olhamos como super. .
Em Reddit comentarista # 4, também conhecido como JudasAdventus, escreveu :. "É interessante para ler, mas os argumentos contra indicadores MSCOCO parecer um pouco insustentável" Eu sabia que você ia me trair, Judas. Sabe quando você está fazendo um projeto, o resultado será bom, então você tem que encontrar alguma maneira de provar que você realmente legal? Eu estou basicamente tentando fazer, então eu indicadores COCO de algumas críticas. Mas desde que eu colocar as apostas sobre esta montanha, assim como eu poderia morrer nele.
Do jeito que está, mapa foi quebrado, então atualizá-lo pode resolver alguns dos problemas, ou pelo menos explicar por que a versão mais recente de alguma forma melhor. Minha pelo menos favorito é a falta de legitimidade. Ele foi "intencionalmente muito baixo para refletir as imprecisões de dados reais em caixa delimitadora" para PASCAL VOC, o limiar de IOU. etiqueta COCO de VOC ok? Isto é absolutamente possível porque há máscara COCO segmentação, talvez rótulo mais confiável, por isso não se preocupe com impreciso. No entanto, o meu problema é a falta de justificação.
COCO enfatizar melhor medida da caixa delimitadora, mas isso significa que ele enfatiza a necessidade de enfatizar outras coisas, neste caso, é a precisão da classificação. Se há motivos suficientes para crer que uma caixa delimitadora mais precisa é mais importante que uma melhor classificação? Exemplo Unclassified é mais óbvio do que a caixa delimitadora ligeiramente deslocado.
Mapa já errei, porque tudo o que importa é a classificação de cada classe. Por exemplo, se definir o seu teste de apenas duas imagens, em seguida, de acordo com mapa, dois detectores de produzir esses resultados são tão bons:
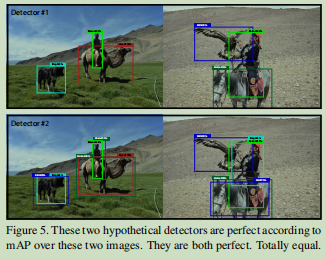
Mapear este problema é exagerado claramente, mas eu acho que o meu novo ponto retconned é uma diferença significativa entre as pessoas deste coisas "mundo real" de interesse e nossos indicadores atuais, acredito que se queremos um novo os indicadores que devem estar preocupados com essas diferenças. Além disso, tem uma precisão média (precisão média média), e mesmo chamado COCO medir a precisão média média (média de precisão média média)?
Aqui vai uma sugestão de que as pessoas realmente se preocupam é dada uma imagem e um detector, como encontrar o detector de objetos e imagens classificar. AP remover cada classe, como sobre apenas uma precisão média global? AP ou ser calculado para cada imagem e média?
Enfim, b caixas são estúpidos, eu provavelmente verdadeiros máscaras crente, mas não posso deixe YOLO aprendê-las.