1. Visão Geral
Quando consideramos a arquitetura de banco de dados MySQL altamente disponível, principalmente para considerar os seguintes aspectos:
- Se o banco de dados falha ou interrupção paradas inesperadas, para retomar o mais rapidamente disponibilidade de banco de dados, reduzir o tempo de inatividade, tanto quanto possível, para garantir que o serviço não seja interrompido devido a uma falha do banco de dados.
- Como um backup, os dados somente leitura cópia do non-master funções de nó deve ser o nó mestre e os dados em tempo real ou sempre o mesmo.
- comutação de serviço ocorre quando o banco de dados, o conteúdo do banco de dados antes e depois da comutação deve ser consistente, os dados não serão faltando ou que afetem o tráfego de dados inconsistentes.
Sobre Aqui não fazemos uma discussão detalhada sobre a classificação de altamente disponível, aqui apenas discutir as vantagens e desvantagens da alta disponibilidade e selecção de programas comumente usados em soluções de alta disponibilidade.
2. High Availability Programa
2,1. A partir do mestre ou mestre primário semi-sincronização
Usando base de dados de dois nós, construir a replicação semi-síncrono unidirecional ou bidirecional. Em uma versão futura 5,7, sem perdas devido a replicação, a introdução de novas características de replicação de rosca de multi-lógica e alguma outra coluna, fazendo a MySQL nativa replicação semi-síncrono é mais fiável.
arquitetura comum é a seguinte:
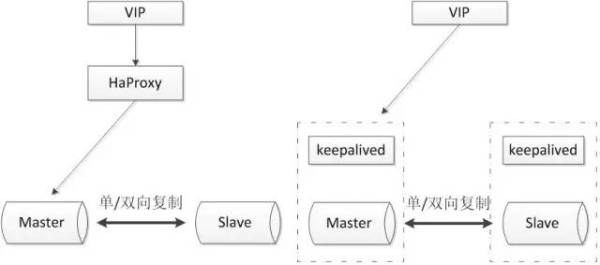
Muitas vezes, e proxy, keepalived ao usar outro software de terceiros que podem ser usados para monitorar a saúde do banco de dados, e pode executar uma série de comandos administrativos. Se o banco de dados primário falhar para o banco de dados standby pode continuar a usar o banco de dados.
vantagens:
- A arquitectura é simples, usando a replicação semi-síncrono nativa como a base para a sincronização de dados;
- Dois nós, não há nenhum problema após o anfitrião principal selecionada é baixo, você pode alternar diretamente;
- Dois Nós, menor demanda de recursos, implementação simples;
desvantagens:
- Totalmente dependente de replicação semi-síncrono, se semi-síncrono degenerada replicação para replicação assíncrona, a consistência dos dados não pode ser garantida;
- E exigem haproxy considerações adicionais, o mecanismo de alta disponibilidade de keepalived.
2.2. Optimização de replicação semi-síncrono
mecanismo de replicação semi-síncrono é fiável. Se a replicação semi-síncrono está em vigor, então pode-se considerar os dados são consistentes. No entanto, devido a algumas razões objectivas produzir, conduzindo a replicação semi-síncrono ocorre de tempo limite e comutada para a replicação assíncrona, em seguida, o tempo não é possível garantir a consistência dos dados. Assim, tanto quanto possível, para assegurar a replicação semi-síncrono, ele pode melhorar a consistência dos dados.
O programa também utiliza uma arquitectura de dois nós, mas na cópia funcional meio optimizado original na mesma base, o mecanismo de replicação semi-síncrono torna-se mais fiável.
Consulte o esquema de otimização é a seguinte:
2.2.1 replicação Dual Channel.

Desde a replicação semi-síncrona ocorre após o tempo limite, cópia desconectada, quando configurar a replicação de novo, ao estabelecer dois canais, um dos canais de replicação semi-síncrona começa a copiar a partir da posição atual para garantir que o escravo saber o progresso da implementação do host atual. Além disso, um canal de catch-up inicia a replicação assíncrona de dados a partir da máquina para trás. Quando o canal de replicação assíncrona para a posição de partida que trava o semi-sincronização, recuperação semi-sincronização.
2.2.2. Servidor de arquivos Binlog
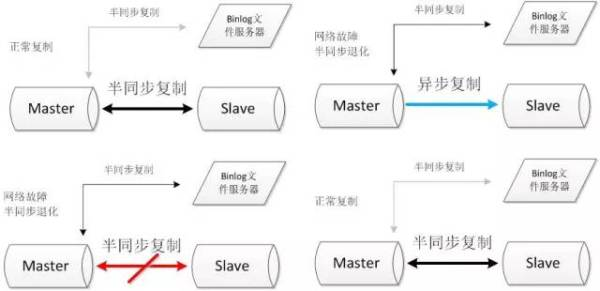
Duas estruturas de canal semi-sincronização, em que a metade inferior-SCH normalmente ligadas ao servidor de ficheiros não é activado, quando a rede mestre-escravo de semi-sincronização problemas degradação metade iniciar a replicação síncrono com o canal de servidor de ficheiros. Quando a recuperação semi-sincronização do mestre, a meia-fim replicação síncrono do canal servidor de ficheiros.
vantagens:
- Dois Nós, menor demanda de recursos, implementação simples;
- estrutura simples, o principal problema não é selecionado, você pode alternar diretamente;
- Em comparação com a cópia do original, a replicação semi-síncrono optimizado para assegurar uma melhor consistência dos dados.
desvantagens:
- Modificações para a fonte do kernel usando o MySQL ou protocolo de comunicação. Precisamos ter algum conhecimento do código-fonte, e pode fazer algum grau de desenvolvimento secundário.
- Ainda depende de replicação semi-síncrona, a consistência dos dados não resolve o problema fundamental.
2.3. High Availability arquitetura otimização
A base de dados estendido de dois nós de um banco de dados multi-nó, ou um agrupamento do banco de dados multi-nó. Você pode escolher dois de um mestre de acordo com as suas necessidades, a partir de um multi-mestre ou multi-mestre do multi-cluster.
Uma vez que a replicação semi-síncrono, a presença de um transponder é recebido a partir de uma máquina que é semi-sincronização sucesso consideradas características bem sucedidos, a replicação multi-síncrono de um único semi-fiabilidade fiabilidade superior replicado a partir da metade. E a probabilidade de vários nós simultaneamente o tempo de inatividade deve ser menor do que a probabilidade de um único nó vai para baixo, de modo a arquitetura multi-nó até certo ponto pode ser considerado de alta disponibilidade é melhor do que uma arquitetura de dois nós.
No entanto, porque o número de bancos de dados, software de gerenciamento de banco de dados, por isso é necessário para garantir a manutenção do banco de dados. Você pode escolher MMM, MHA ou várias versões do proxy, e assim por diante. esquema comum é a seguinte:
2.3.1. MHA + cluster de vários nós
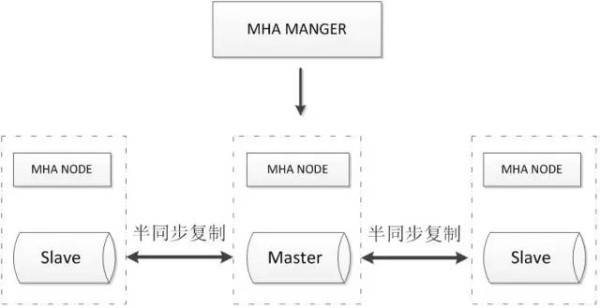
MHA Manager detectará regularmente nó master do cluster quando o mestre falhar, ele pode automaticamente escravo atualizar com os últimos dados para o novo mestre, e depois todos os outros escravos redirecionado para o novo mestre, toda a aplicações de processo failover completamente transparente.
MHA Nó em execução em cada servidor MySQL, o papel principal é processar o log binário quando mudar, certifique-se de mudar para minimizar a perda de dados.
MHA pode ser estendida a um conjunto multi-nó como se segue:
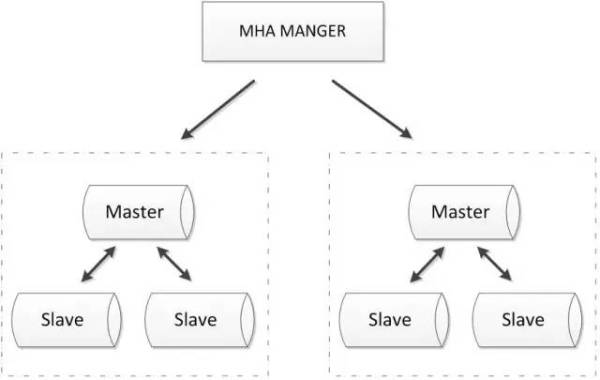
vantagens:
- Ele pode detectar e falhas de transferência automaticamente;
- Melhor escalabilidade, pode precisar expandir o número de nós e estrutura MySQL;
- Uma probabilidade inferior como comparado com uma replicação MySQL de dois nós, de três nós / multi-nó não disponível com MySQL
desvantagens:
- Pelo menos três nós, com relação aos dois-nó requer mais recursos;
- lógica mais complexa, falha resolução de problemas ocorre, o problema de posicionamento é mais difícil;
- A consistência dos dados está ainda por garantia de replicação semi-síncrono nativo, risco de inconsistência de dados continua a existir;
- Provavelmente por causa da ocorrência de rede fenómeno partição cérebro dividido;
2.3.2. tratador + procuração
Tratador usando algoritmo de agrupamento distribuído para garantir a consistência dos dados, a utilização tratador pode eficazmente garantir a elevada disponibilidade de proxy, podem melhor evitar o fenómeno partição rede.
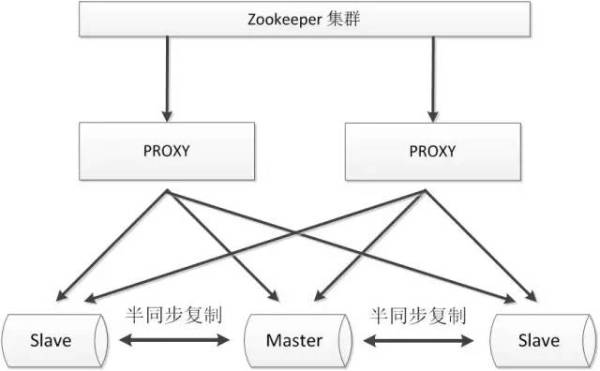
vantagens:
- Melhor garantir a alta disponibilidade de todo o sistema, incluindo o proxy, MySQL;
- Melhor escalabilidade, pode ser estendido para grandes clusters;
desvantagens:
- A consistência dos dados está ainda dependente de replicação semi-síncrono nativo mysql;
- Apresentando zk, a lógica do sistema torna-se mais complicado;
2.4. Shared Storage
O armazenamento partilhado para alcançar uma dissociação de servidores de bases de dados e dispositivos de armazenamento, a sincronização de dados entre diferentes bases de dados já não dependem de capacidades de replicação nativas da MySQL, mas por meio de sincronização de dados do disco para garantir a consistência dos dados.
2.4.1. SAN armazenamento compartilhado
SAN conceito é para permitir que o processador e o dispositivo de armazenamento da rede de alta velocidade entre um directa (servidor) (em comparação com as ligações LAN), que são ligados através de uma aplicação de armazenamento de dados centralizada. arquitetura comum é a seguinte:
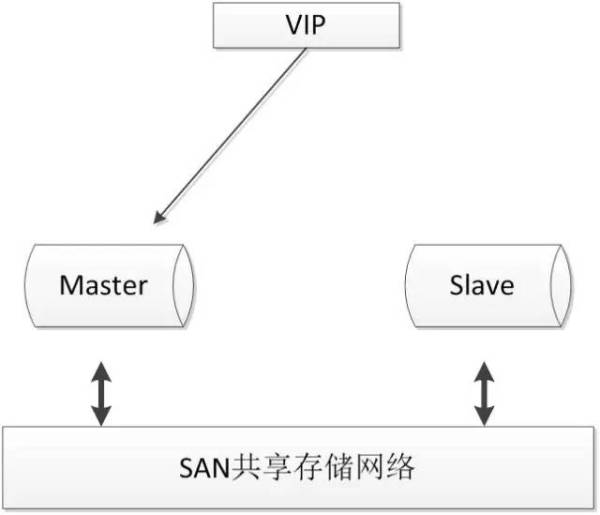
Quando uma memória compartilhada, servidor MySQL pode montar um sistema de arquivos e operando normalmente, se o tempo de inatividade do banco de dados primário ocorre, o banco de dados standby pode montar o mesmo sistema de arquivos, certifique-se de que a biblioteca do banco de dados principal e de backup usando os mesmos dados.
vantagens:
- Dois nós pode ser simples de implementar, lógica de comutação simples;
- Boa forte consistência dos dados de garantia;
- Não por causa de dados erros lógicos inconsistências MySQL ocorrer;
desvantagens:
- Você precisa considerar o armazenamento compartilhado de alta disponibilidade;
- caro;
2.4.2. Duplicação de disco DRBD
DRBD é um software baseado em soluções de armazenamento baseados em blocos cópia de rede, servidores usado principalmente entre os discos, partições e outros dados espelhamento de volume lógico, quando os dados do usuário foi escrito para o disco local, os dados são também transmitidos rede para outro host no disco, de modo que o host local (master) eo (aparelho de nó) host remoto pode garantir a sincronização de dados em tempo real. arquitetura comum é a seguinte:
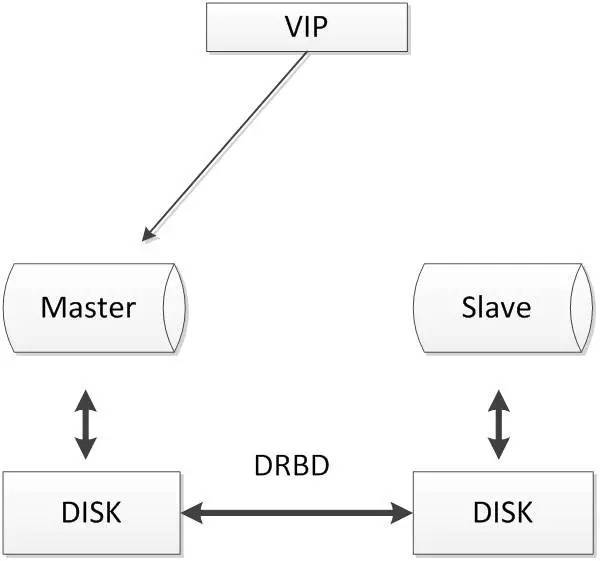
Quando há um problema na máquina local, um host remoto mantém os mesmos dados, podem continuar a ser utilizados para garantir a segurança dos dados.
DRBD nível de replicação rápida síncrona Linux Kernel módulo implementado com um SAN pode conseguir o mesmo efeito memória compartilhada.
vantagens:
- Dois nós pode ser simples de implementar, lógica de comutação simples;
- Em comparação com a rede de armazenamento SAN, preços baixos;
- Assegurar forte a consistência dos dados;
desvantagens:
- maior impacto Io no desempenho;
- não fornece uma operação de leitura da biblioteca;
2.5. Protocolo Distributed
Distributed protocolo problema a consistência dos dados pode ser resolvido. Os cenários mais comuns são as seguintes:
2.5.1. MySQL cluster
MySQL cluster é um aglomerado de implantação oficial usando o mecanismo de armazenamento em tempo real redundância de dados de backup NDB, alta disponibilidade e consistência dos dados do banco de dados.
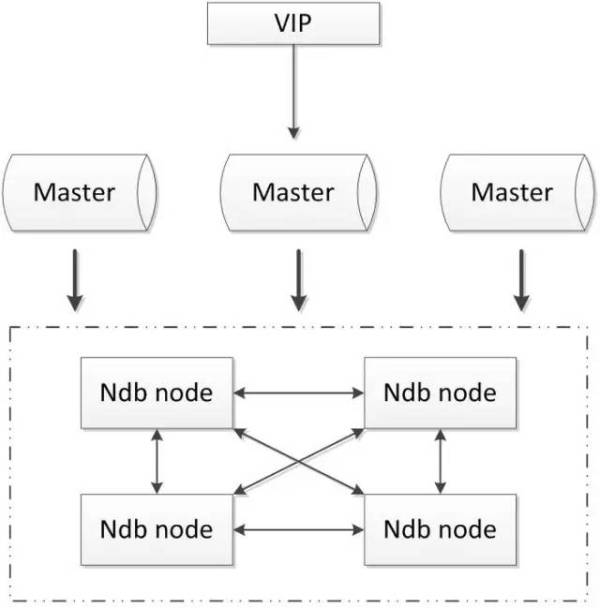
vantagens:
- Todos os componentes usando o oficial, não depende de software de terceiros;
- a consistência dos dados pode ser conseguida forte;
desvantagens:
- Menos uso doméstico;
- configuração mais complexa é necessária mecanismo de armazenamento NDB, existem algumas diferenças com MySQL motor convencional;
- Pelo menos três nós;
2.5.2. Galera
Baseada em MySQL aglomerados de alta disponibilidade de Galera, é uma sincronização de solução MySQL Cluster de dados multi-mestre, fácil de usar, não existe um único ponto de falha, alta disponibilidade. arquitetura comum é a seguinte:
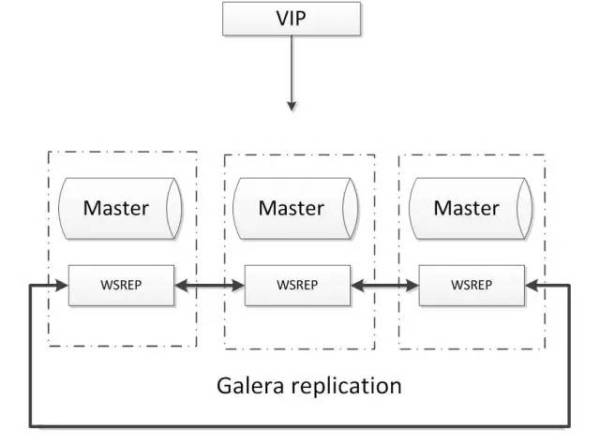
vantagens:
- Multi-mestre escrever, copiar, sem demora, para garantir a forte consistência dos dados;
- Existem comunidade madura, existem empresas de Internet na utilização em larga escala;
- failover automático, automaticamente adicionar, remover o nó;
desvantagens:
- Wsrep necessidade patch para lutar pelo nó MySQL nativa
- Apenas mecanismo de armazenamento InnoDB apoio
- Pelo menos três nós;
2.5.3. POAXS
Paxos algoritmo para resolver a questão de como um sistema distribuído de acordo sobre um valor (resolução). Este algoritmo é considerado o tipo mais eficaz de algoritmo. Paxos e MySQL combinado com forte consistência pode ser alcançada em um MySQL dados distribuída. arquitetura comum é a seguinte

vantagens:
- Multi-mestre escrever, copiar, sem demora, para garantir a forte consistência dos dados;
- Amadureça a base teórica;
- failover automático, automaticamente adicionar, remover o nó;
desvantagens:
- Apenas mecanismo de armazenamento InnoDB apoio
- Pelo menos três nós;
3. Resumo
Como as pessoas continuam a melhorar os requisitos de consistência de dados, mais e mais métodos são utilizados para tentar resolver os problemas de consistência de dados distribuídos, como a própria otimização, otimização da arquitetura MySQL Cluster MySQL, Paxos, Raft, algoritmo 2PC introdução e assim por diante.
Mas usar um algoritmo distribuído para resolver a consistência de dados do banco de dados MySQL problema de abordagem, mais e mais aceito pelas pessoas, uma série de produtos maduros, como PhxSQL, MariaDB Galera Cluster, Percona XtraDB Cluster e assim mais e mais por grande utilização escala.
Com o oficial Grupo de Replicação MySQL de GA, usando um protocolo distribuído para resolver o problema da consistência dos dados tornou-se uma direção mainstream. Esperar soluções cada vez mais proeminentes têm sido propostas, MySQL questões de alta disponibilidade podem ser melhor abordados.
Referências
[2015 OTN] Pengli Xun -DoubleBinlog .pdf programa
referência:
https://zhuanlan.zhihu.com/p/25960208 (acima transferido a partir deste artigo)
