
Na era digital, os dados são um dos ativos mais valiosos de uma empresa. No entanto, à medida que a quantidade de dados aumenta, aumenta também a complexidade do gerenciamento de banco de dados. Uma falha no banco de dados pode causar interrupções nos negócios e causar enormes perdas financeiras e de reputação à empresa. Neste blog, compartilharemos como o KaiwuDB projeta ferramentas de diagnóstico de falhas e exemplos específicos de demonstrações
01 ideias de design
Siga os princípios básicos
- Fácil de usar: Mesmo usuários com diferentes níveis de habilidade podem usar facilmente nossas ferramentas;
- Monitoramento abrangente: Monitoramento abrangente de todos os aspectos do sistema de banco de dados, incluindo indicadores de desempenho, recursos do sistema e eficiência de consulta;
- Diagnóstico Inteligente: Utiliza algoritmos avançados para identificar a causa raiz dos problemas;
- Reparos automatizados: Fornece sugestões de reparo com um clique e, sempre que possível, aplica automaticamente esses reparos;
- Extensibilidade: permite que os usuários ampliem e personalizem a funcionalidade da ferramenta de acordo com suas necessidades específicas.
Apoiar a coleta de indicadores-chave
Para garantir um diagnóstico abrangente, a ferramenta irá recolher uma série de indicadores-chave, incluindo, mas não se limitando a:
- Configuração do sistema: versão do banco de dados, sistema operacional, arquitetura e número da CPU, capacidade de memória, tipo e capacidade do disco, ponto de montagem, tipo de sistema de arquivos;
- Situação de implantação: se é implantação bare metal ou contêiner, o modo de implantação e número de nós da instância de banco de dados organização de dados: a estrutura do diretório de dados, configuração local e de cluster, tabelas e parâmetros do sistema;
- Estatísticas de banco de dados: número de bancos de dados comerciais, número de tabelas em cada banco de dados e estrutura da tabela;
- Características da coluna: características estatísticas de colunas numéricas e colunas de enumeração, comprimento e detecção de caracteres especiais de colunas de string;
- Arquivos de log: log de relacionamento, log de tempo, log de erros, log de auditoria;
- Informações PID: número de identificadores abertos pelo processo de banco de dados, número de MMAPs abertos, estatísticas e outras informações;
- Dados de desempenho: plano de execução SQL, dados de monitoramento do sistema (CPU, memória, E/S), uso e eficiência do índice, padrões de acesso a dados, bloqueios (conflitos de transação e eventos de espera), eventos do sistema, etc.
Suporta diferentes modos de operação
A ferramenta fornecerá dois modos de operação para atender às necessidades de diferentes cenários:
- Coleta única: capture rapidamente o status atual do sistema e os dados de desempenho, adequados para diagnóstico imediato de problemas;
- Coleta programada: Colete dados periodicamente de acordo com um plano predefinido para monitoramento de desempenho de longo prazo e análise de tendências.
Adapte-se a várias análises de tendências
Os dados coletados serão usados para realizar análises de tendências, com recursos que incluem:
- Tendências de desempenho: identifique tendências no desempenho do banco de dados ao longo do tempo e preveja possíveis gargalos de desempenho;
- Uso de recursos: rastreie o uso de recursos do sistema e ajude a otimizar a alocação de recursos;
- Análise de log: Analise arquivos de log para identificar padrões anormais e erros frequentes;
- Otimização de consultas: Forneça sugestões de otimização de consultas analisando planos de execução SQL;
- Melhores práticas: Forneça recomendações de configuração ideais por meio de análise abrangente de distribuição de dados e recursos de hardware.
02 Arquitetura geral
A ferramenta de diagnóstico de falhas é dividida em duas partes: coleta e análise:
- A parte da coleção é conectada ao sistema operacional/banco de dados/servidor de monitoramento de destino, suporta análise simplificada de regras locais e gera relatórios de texto simples;
- A parte de análise lê e formata os dados coletados e os carrega no servidor de análise para persistência. Ele suporta análise detalhada e previsão de regras online e gera relatórios detalhados por meio da IU.
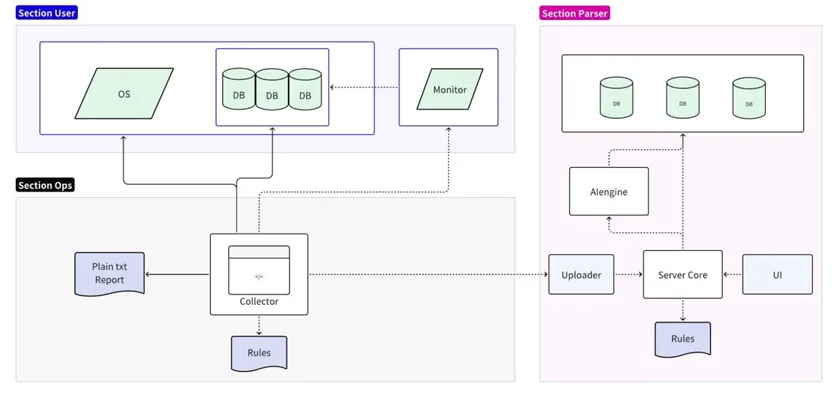
Implementação do coletor
O coletor é uma ferramenta utilizada diretamente pelo pessoal de operação e manutenção no local. Obtém diversas informações originais no local por meio do sistema operacional, banco de dados e serviços de monitoramento. Por padrão, há suporte para compactação e exportação direta após a coleta. Você também pode usar regras locais para fazer análises mais básicas, como localizar e imprimir todas as mensagens de erro.

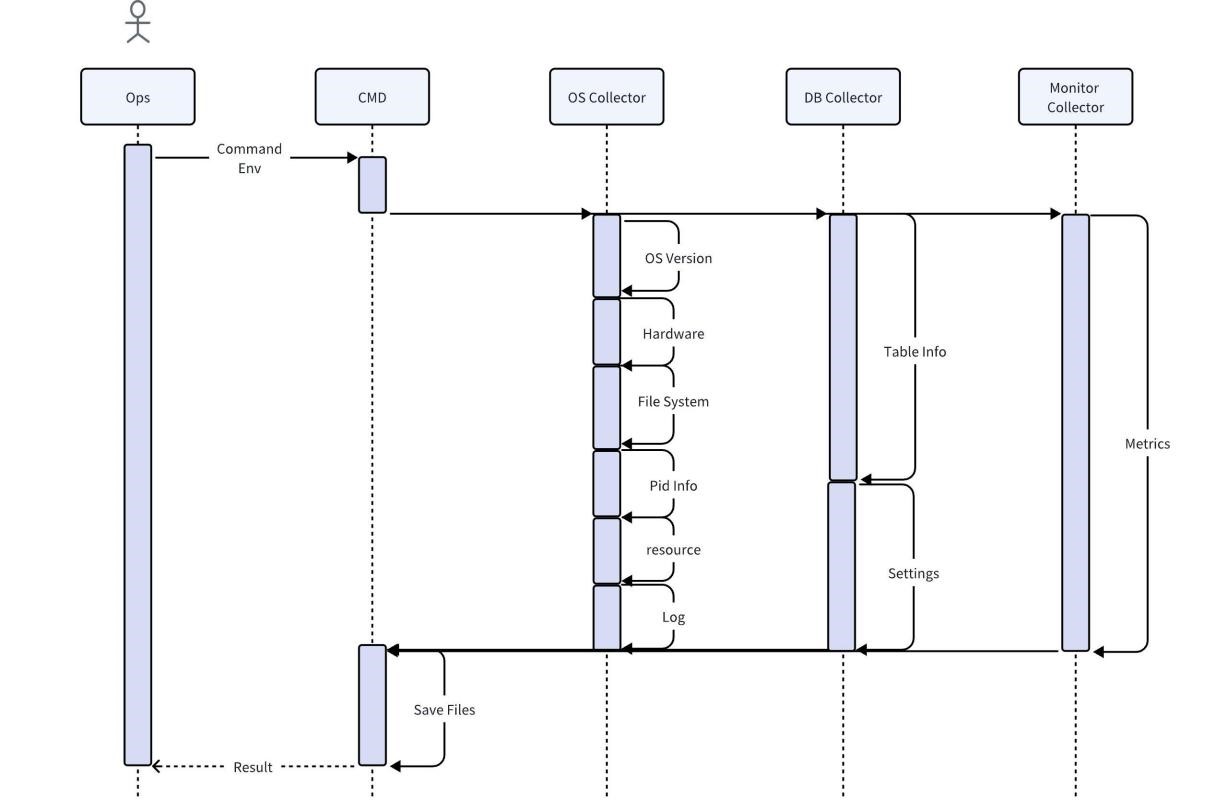
Considerando que a coleta direta de dados comerciais do usuário pode levar ao risco de exposição de informações do usuário, durante o processo de coleta do coletor de banco de dados, apenas as características dos dados do usuário serão capturadas e nenhum dado será copiado. A fim de garantir a integridade e precisão de outros dados, os dados recolhidos não serão processados de forma alguma antes da análise, e os dados necessários serão mantidos para fornecer informações completas. Para economizar espaço, os dados coletados devem ser compactados. Ao mesmo tempo, o coletor deve ser compatível com a maioria dos sistemas operacionais e não exigir dependências adicionais.
Implementação do mecanismo de regras
Para análise de dados subsequente, o mecanismo de regras precisa ser compatível com o coletor de dados para fornecer saída de dados padronizada e ter certa escalabilidade. Por exemplo, para analisar o aumento no uso da CPU quando um SQL específico é executado, é necessário gerar os metadados da consulta SQL (como texto SQL, tempo de execução, etc.) e indicadores de desempenho (como uso da CPU) em o formato do mecanismo de cronometragem para analisar gargalos de desempenho.
Para fornecer escalabilidade suficiente e ser capaz de cobrir um conjunto de regras em constante expansão, incluindo questões funcionais como verificação de código de erro, o mecanismo de regras lê regras de arquivos externos e depois aplica essas regras para analisar os dados. A seguir estão alguns exemplos de código:
Python
import pandas as pd
import json
# 加载规则
def load\_rules(rule\_file):
with open(rule_file, 'r') as file:
return json.load(file)
# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold):
# 比较当前行的CPU使用率是否超过阈值
return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold
# 应用规则
def apply\_rules(data, rules\_config, custom_rules):
for rule in rules_config:
data\[rule\['name'\]\] = data.eval(rule\['expression'\])
for rule\_name, custom\_rule in custom_rules.items():
data\[rule\_name\] = data.apply(custom\_rule, axis=1)
return data
# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')
# 加载规则
rules\_config = load\_rules('rules.json')
# 定义自定义规则
custom_rules = {
'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}
# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)
# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
Os arquivos de regras devem ser continuamente expandidos com iterações de versão e oferecer suporte a atualizações importantes. A seguir está um exemplo de arquivo de configuração de regras no formato JSON. As regras são definidas como objetos JSON, cada um contendo um nome e uma expressão compreendida pelo Pandas DataFrame.
JSON
\[
{
"name": "high\_execution\_time",
"expression": "execution_time > 5"
},
{
"name": "general\_high\_cpu_usage",
"expression": "cpu_usage > 80"
},
{
"name": "slow_query",
"expression": "query_time > 5"
},
{
"name": "error\_code\_check",
"expression": "error_code not in \[0, 200, 404\]"
}
// 其他规则可以在此添加
\]
Previsão realizada
As ferramentas de diagnóstico podem ser ligadas a motores de previsão para detectar antecipadamente riscos potenciais. O exemplo a seguir usa o classificador de árvore de decisão scikit-learn para treinar um modelo e usa o modelo para fazer previsões:
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score
# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')
# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到
# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]
# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X\_train, y\_train)
# 预测测试集
y\_pred = model.predict(X\_test)
# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')
# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')
# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time):
model = joblib.load('performance\_predictor\_model.joblib')
prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\])
return 'Issue' if prediction\[0\] == 1 else 'No issue'
# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 Exemplo de Demonstração
Cenário hipotético: você é um especialista em TI em uma empresa de Internet das Coisas. Você descobre que o tempo de resposta da consulta do banco de dados de série temporal para processar dados de status do dispositivo é muito lento em determinados períodos.
coleção de dados
A ferramenta de diagnóstico de banco de dados que você usa começa a coletar os seguintes dados:
1. Log de consulta: é encontrada uma consulta que aparece com frequência e o tempo de execução é muito maior do que outras consultas.
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2. Plano de execução: O plano de execução desta consulta mostra que este SQL irá verificar toda a tabela e então filtrar o device_id.
3. Uso do índice: O device_id na tabela device_readings não possui um índice TAG.
4. Uso de recursos: pico de CPU e E/S ao executar esta consulta.
5. Eventos de bloqueio e espera: Nenhum evento de bloqueio anormal foi encontrado.
Análise e reconhecimento de padrões
As ferramentas de diagnóstico analisam consultas e planos de execução para identificar os seguintes padrões:
- Varreduras completas frequentes da tabela levam ao aumento de cargas de E/S e CPU;
- Sem índices apropriados, as consultas não conseguem localizar os dados de forma eficiente.
Diagnóstico de problemas
A ferramenta utiliza regras integradas que correspondem ao seguinte diagnóstico: A ineficiência da consulta é causada pela falta de índices apropriados.
Geração de sugestões
Com base nesse padrão, a ferramenta de diagnóstico gera a seguinte recomendação: Crie um índice TAG no campo device_id da tabela device_readings.
Implementar recomendações
O administrador do banco de dados executa a seguinte instrução SQL para criar o índice:
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
Resultados de validação
Após a criação do índice, a ferramenta de diagnóstico do banco de dados coletou os dados novamente e descobriu:
- O tempo de execução desta consulta específica caiu significativamente;
- As cargas de CPU e E/S caem para níveis normais durante a execução da consulta;
- O tempo de carregamento da página do catálogo de produtos do site voltou ao normal.
Descrição do algoritmo
Neste exemplo, a ferramenta de diagnóstico utiliza o seguinte algoritmo e lógica:
- Reconhecimento de padrões: detecta frequência de consulta e tempo de execução;
- Análise de correlação: Correlacione consultas de longo tempo de execução com planos de execução e uso de índice;
- Árvore de decisão ou mecanismo de regras: Se for encontrada uma varredura completa da tabela e o campo correspondente não possuir índice, é recomendável criar um índice;
- Monitoramento de mudanças de desempenho: Após criar o índice, monitore a melhoria de desempenho para determinar a eficácia das recomendações.