
Autor: Equipe técnica do SelectDB
Hoje em dia, as necessidades de consulta de dados das empresas estão aumentando constantemente. Ao compartilhar o mesmo cluster, elas muitas vezes precisam enfrentar consultas simultâneas de múltiplas linhas de negócios ou múltiplas cargas de análise ao mesmo tempo. Sob condições de recursos limitados, a preempção de recursos entre tarefas de consulta levará à degradação do desempenho e até mesmo à instabilidade do cluster. Portanto, a importância do gerenciamento de carga é evidente.
A partir de cenários de negócios, os requisitos para gerenciamento de carga de usuários vêm principalmente dos seguintes aspectos:
- Quando vários departamentos de negócios ou locatários podem compartilhar o mesmo cluster, para evitar interação de carga entre diferentes locatários, é necessário garantir a independência de uso de recursos e a estabilidade de desempenho de cada locatário.
- Diferentes empresas têm diferentes requisitos para a capacidade de resposta e prioridade das tarefas de consulta. Para empresas-chave ou tarefas de alta prioridade, como análise de dados em tempo real, transações on-line, etc., é necessário garantir que essas tarefas possam obter recursos e recursos suficientes. ser executado com prioridade para evitar competição de recursos. Ter impacto no desempenho da consulta.
- Os usuários não se preocupam apenas com a alocação e gerenciamento de recursos, mas também prestam atenção ao controle de custos e à utilização de recursos. A solução de gerenciamento de carga precisa atender aos requisitos de isolamento e, ao mesmo tempo, atender às demandas do usuário por baixo custo de uso e alta utilização de recursos.
Nas primeiras versões, Apache Doris lançou uma solução de isolamento baseada em tags de recursos, incluindo divisão de grupos de recursos em nível de nó dentro do cluster e limites de recursos para consultas individuais, alcançando isolamento físico de recursos entre diferentes usuários. A fim de fornecer aos usuários uma solução de gerenciamento de carga mais completa, Apache Doris lançou uma solução de gerenciamento baseada em Workload Group desde a versão 2.0, que realiza o limite flexível de recursos da CPU e fornece aos usuários maior utilização de recursos. A versão 2.1 recém-lançada é baseada na tecnologia CGroup fornecida pelo kernel Linux, que implementa limites rígidos nos recursos da CPU e fornece aos usuários melhor estabilidade de consulta.
Solução de isolamento físico baseada em Resource Tag
Existem dois tipos de nós no Apache Doris, FE e BE. O nó FE é responsável pelo armazenamento de metadados, gerenciamento de cluster, acesso a solicitações de usuários, análise do plano de consulta, etc., enquanto o nó BE é responsável pelo armazenamento e cálculo de dados. O principal consumo de recursos envolvido no processo de execução da consulta é o nó BE, portanto a solução de isolamento de carga Apache Doris foi projetada para o nó BE.
Na solução de isolamento físico de recursos de tags de recursos, você pode definir tags em nós BE no mesmo cluster. Os nós BE com as mesmas tags formarão um grupo de recursos (grupo de recursos), e o grupo de recursos pode ser considerado uma unidade de armazenamento de dados. e computação. Quando os dados são inseridos no banco de dados, cópias dos dados serão gravadas em diferentes grupos de recursos de acordo com a configuração do grupo de recursos. Durante a consulta, os recursos de computação no grupo de recursos correspondente serão usados para cálculo de acordo com a divisão dos grupos de recursos.
Documentação de referência: https://doris.apache.org/zh-CN/docs/2.0/admin-manual/resource-admin/multi-tenant
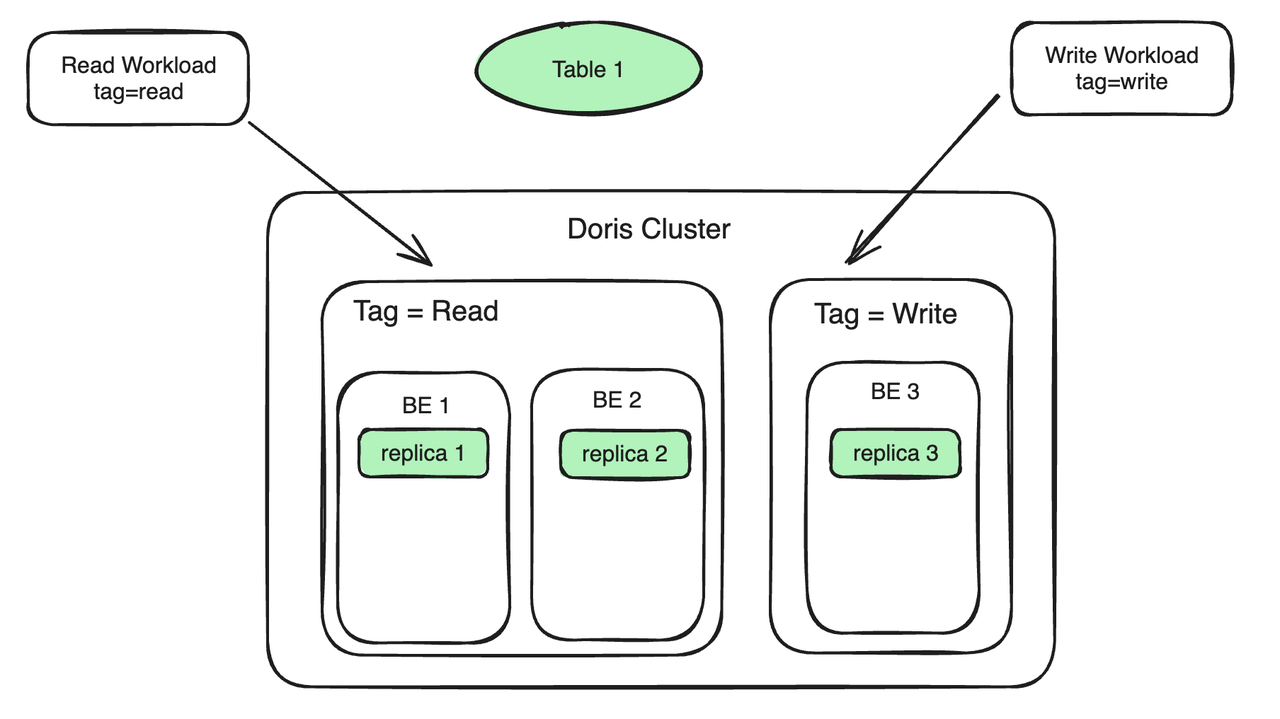
Tomemos como exemplo um cenário comum de análise de leitura e gravação. Suponha que haja 3 BEs no cluster. As etapas de uso específicas são as seguintes:
- Tag de recurso de ligação do nó BE: Vincule dois BEs à Tag Read para atender à carga de leitura; vincule um BE à Tag Write para atender à carga de gravação. As cargas de trabalho de leitura e de gravação estão localizadas em máquinas diferentes para obter isolamento de leitura e gravação.
- As cópias de dados estão vinculadas ao Tag de Recurso: A Tabela 1 possui três cópias, duas cópias estão vinculadas ao Tag Read e uma cópia está vinculada ao Tag Write. Os dados gravados na réplica 3 serão automaticamente sincronizados com a réplica 1 e a réplica 2. O processo de sincronização não ocupará muitos recursos computacionais de BE 1 e BE 2.
- A carga de trabalho está vinculada ao Tag Resource: Se o Tag transportado pela consulta SQL for Read, a consulta será automaticamente roteada para a máquina (BE 1, BE 2) com o Tag como Read para execução caso o Stream Load seja importado; na carga e o Tag especificado for Write , então o Stream Load será roteado para a máquina cujo Tag é Write (BE 3). Nesse processo, além do overhead gerado durante a sincronização das réplicas, não há mais competição por recursos entre consulta e importação.
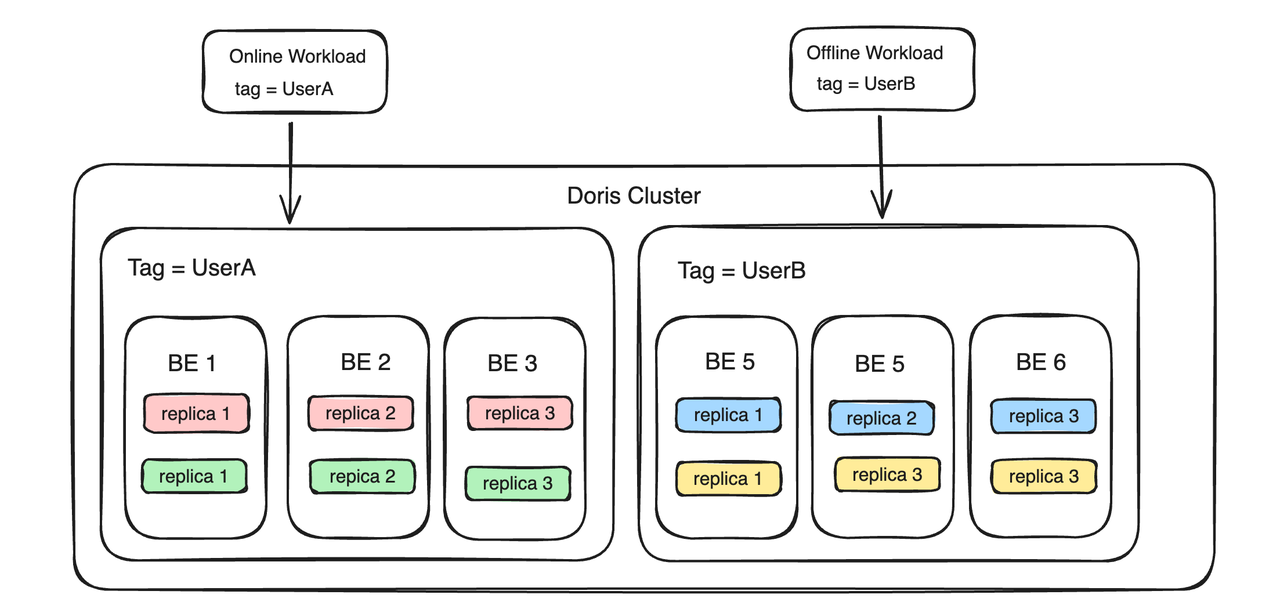
A Resource Tag também pode implementar funções multilocatários. Por exemplo, há dois usuários, UserA e UserB, que desejam criar locatários independentes para evitar influência mútua. Em seguida, você pode vincular os recursos de computação e armazenamento do UserA a uma tag chamada UserA e vincular os recursos de computação e armazenamento do UserB a uma tag chamada UserA. . é a tag do usuário B, então os dois usuários alcançam o isolamento de recursos entre os locatários no lado BE.
A essência do Resource Tag é obter o isolamento de recursos agrupando nós BE. As vantagens desta solução são:
- Bom isolamento, vários locatários são isolados por meio de máquinas físicas e o isolamento completo de CPU, memória e IO é alcançado;
- Isolamento de falhas, quando ocorre um problema em um inquilino (como uma falha no processo), o outro inquilino não é afetado de forma alguma;
Com base nesta tecnologia, alguns usuários colocam diferentes grupos de recursos em diferentes salas físicas de computadores para obter operação ativa-ativa de duas salas de computadores na mesma cidade.
Mas também existem certas limitações:
- No cenário de isolamento de leitura e gravação, quando a carga de gravação parar, a máquina com a tag Write ficará em estado ocioso, reduzindo assim a utilização de recursos de todo o cluster, o que obviamente não pode atender às expectativas do usuário de utilização total dos recursos.
- Num cenário multi-inquilino, as cargas de várias partes comerciais dentro do mesmo inquilino também afectarão umas às outras. Mesmo que o isolamento possa ser alcançado através da configuração de máquinas físicas separadas para cada parte da empresa, isso trará problemas como custos elevados e baixa utilização de recursos.
- A flexibilidade é baixa. O número de locatários está, na verdade, vinculado ao número de réplicas. Se você deseja estabelecer 5 locatários, precisará de pelo menos 5 réplicas, o que causa um certo desperdício de espaço de armazenamento.
Solução de gerenciamento de carga baseada em Workload Group
Para resolver os problemas acima, Apache Doris lançou uma solução de gerenciamento baseada em Workload Group, que suporta um mecanismo de isolamento de recursos mais refinado - isolamento de recursos intra-processo, o que significa que várias salas de consulta no mesmo BE também podem alcançar um até certo ponto. O isolamento evita efetivamente a competição de recursos dentro do processo e melhora a utilização dos recursos.
O Workload Group gerencia cargas de trabalho em grupos para obter gerenciamento e controle refinados de memória e recursos de CPU. Limite a porcentagem de recursos de CPU e memória de uma única consulta em um único nó BE associando a consulta executada pelo usuário ao grupo de carga de trabalho. Ao mesmo tempo, você pode configurar e ativar limites de recursos de memória. Quando os recursos do cluster estão limitados, as consultas com alto uso de memória no grupo serão encerradas automaticamente para aliviar a pressão. Quando os recursos estão ociosos, vários grupos de carga de trabalho compartilham recursos ociosos e ultrapassam automaticamente os limites para garantir a execução estável da consulta.
Os limites de recursos da CPU podem ser subdivididos em limites flexíveis e limites rígidos. Os limites flexíveis da CPU têm as características de maior utilização de recursos e permitem a alocação flexível de recursos quando os recursos estão ociosos, enquanto os limites rígidos da CPU se concentram mais em garantir a estabilidade do desempenho e garantir a segurança dos grupos; não interfiram entre si devido a alterações de carga.
( Os dois métodos de isolamento de limite rígido e limite flexível da CPU podem corresponder a diferentes cenários de uso, mas não podem ser aplicados ao mesmo tempo. Os usuários podem escolher com flexibilidade de acordo com suas próprias necessidades)
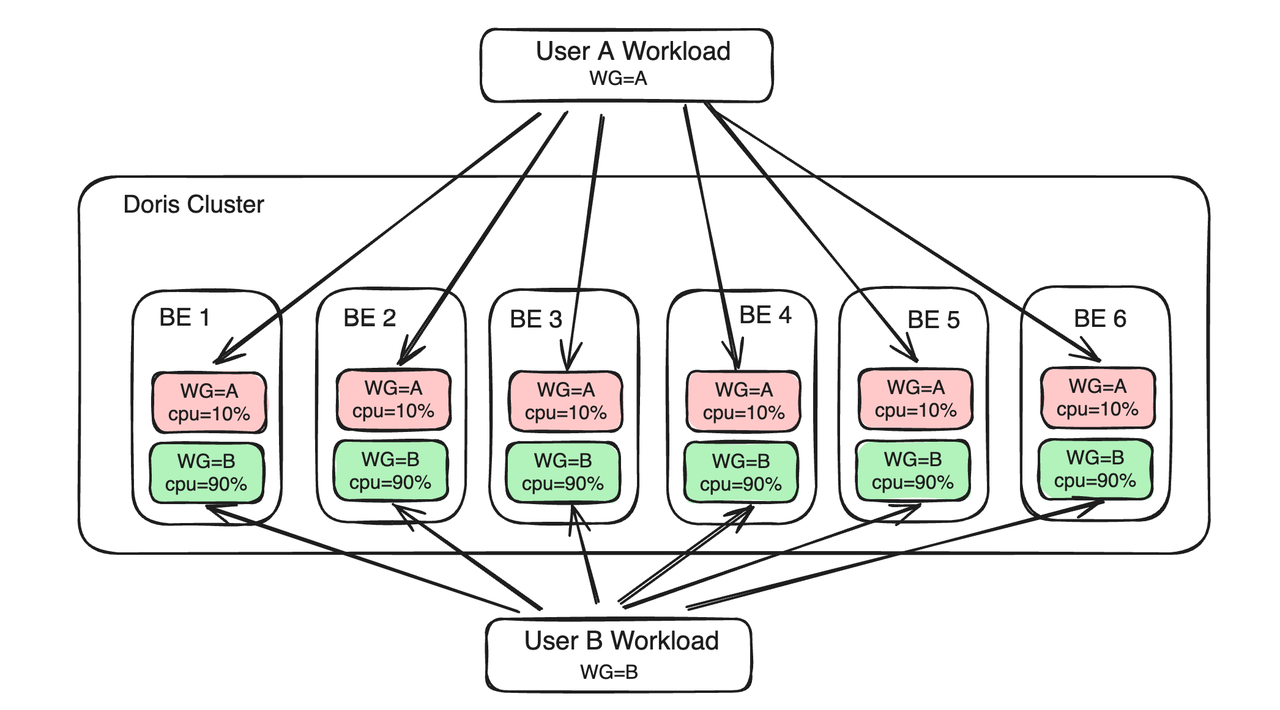
As principais diferenças entre as soluções Workload Group e Resource Tag são as seguintes:
- Do ponto de vista dos recursos de computação, o Grupo de Carga de Trabalho divide ainda mais os recursos de CPU e memória dentro do processo BE. Vários Grupos de Carga de Trabalho precisam competir por recursos no mesmo BE. A tag de recurso agrupa nós BE e as cargas de diferentes partes de negócios são enviadas para BEs em grupos diferentes para obter o isolamento de recursos. Não haverá competição direta de recursos entre cargas de negócios em diferentes grupos de BE.
- Do ponto de vista dos recursos de armazenamento, o Workload Group não precisa prestar atenção aos recursos de armazenamento, mas concentra-se apenas na alocação de recursos computacionais dentro de um único BE. A Tag de Recursos exige o agrupamento de cópias de dados para garantir que os dados do lado comercial que precisam ser isolados sejam distribuídos em diferentes BEs.
01 limite suave da CPU
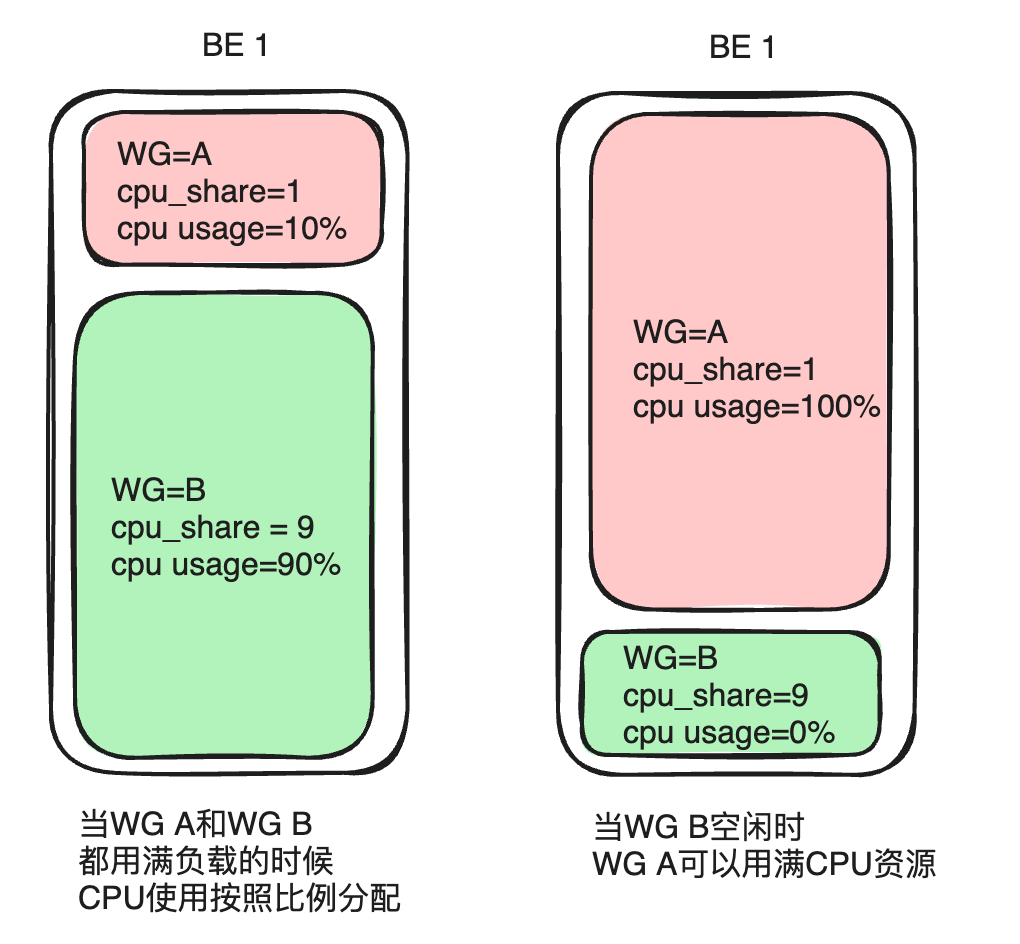
A prioridade da CPU é refletida principalmente cpu_shareatravés de parâmetros, que podem ser comparados ao conceito de peso. No mesmo período, um grupo com peso maior pode obter mais tempo de CPU.
Tomemos como exemplo o Grupo A e o Grupo B. Se o Grupo A estiver configurado cpu_sharecomo 1 e o Grupo B cpu_sharecomo 9, será fornecido um período de tempo de 10 segundos. Quando ambas as cargas estão saturadas, o Grupo B com peso maior pode obter tempo de CPU por 9 segundos (90% de todos os recursos) e o Grupo A pode obter tempo de CPU por 1 segundo (10% de todos os recursos). No uso real, nem todos os serviços estão sendo executados com carga total. Se a carga do Grupo B for baixa ou nenhuma carga, o Grupo A poderá monopolizar o tempo da CPU por 10 segundos. Este método pode fornecer maior flexibilidade de alocação de recursos, melhorando assim a utilização geral dos recursos de CPU do cluster.
02 Limite rígido da CPU
Usar o limite de tempo flexível da CPU pode causar flutuações no desempenho da consulta se a carga do sistema for alta ou se os recursos da CPU estiverem escassos. Para atender aos altos requisitos dos usuários para desempenho de consulta estável, Apache Doris implementou o limite rígido de CPU do grupo de carga de trabalho na versão 2.1 mais recente - independentemente de a CPU geral da máquina física atual estar ociosa, o uso máximo da CPU de o grupo configurado com o limite rígido não pode exceder o valor do limite pré-configurado.
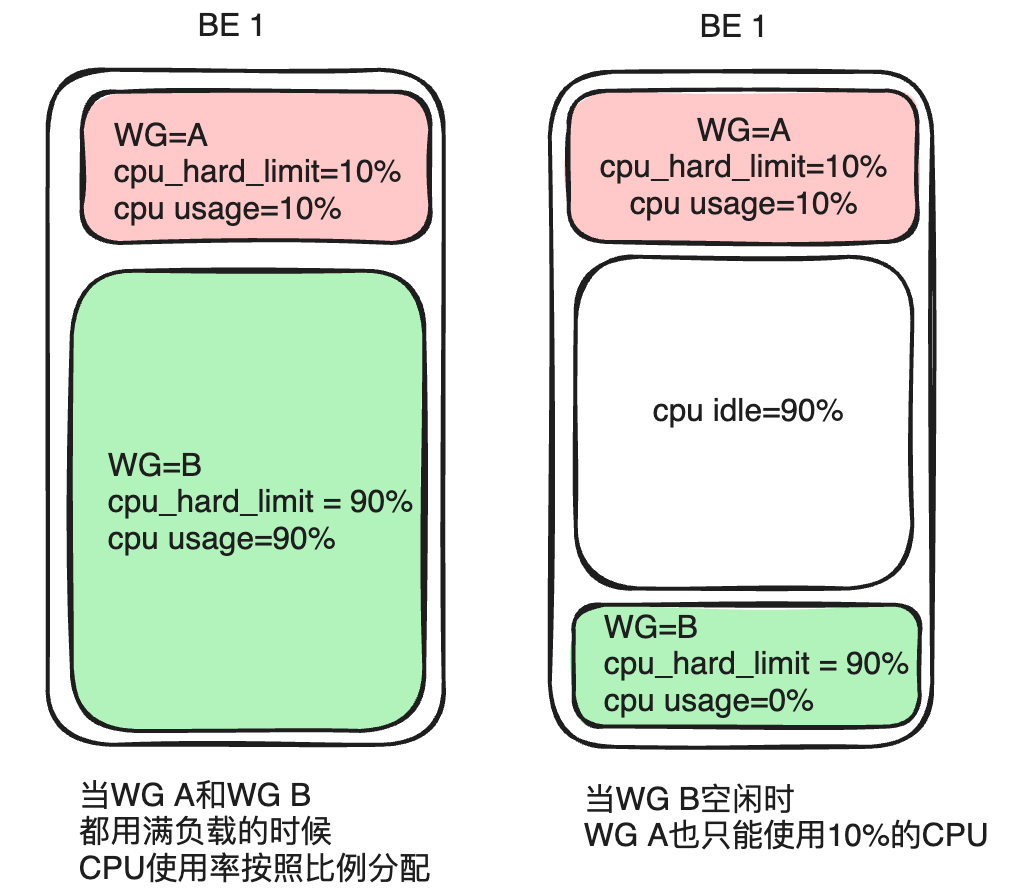
Tomemos como exemplo o Grupo A e o Grupo B. Se você configurar o Grupo A cpu_hard_limit=10%, Grupo B. cpu_hard_limit=90%Quando os recursos da CPU de ambas as máquinas atingem a saturação, a utilização da CPU do Grupo A é de 10% e a utilização da CPU do Grupo B é de 90%, que é igual ao limite flexível da CPU. Porém, quando a carga do Grupo B diminui ou não há carga, mesmo que o Grupo A aumente a carga de consulta, sua utilização máxima da CPU ainda é estritamente limitada a 10% e não pode obter mais recursos. Embora esta abordagem sacrifique a flexibilidade da alocação de recursos, ela também garante a estabilidade do desempenho da consulta.
03 Limitações de recursos de memória
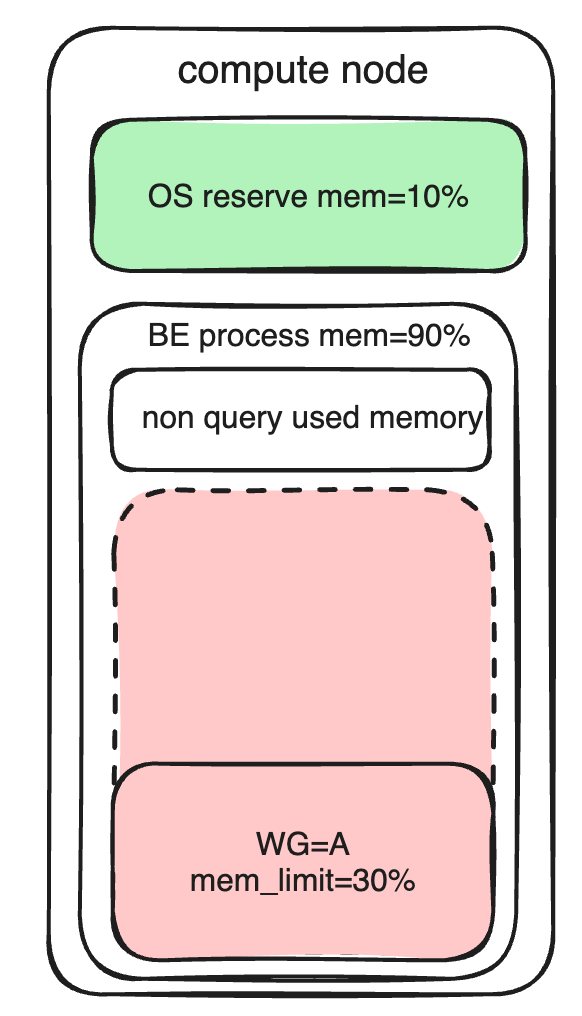
Instruções de uso: A memória do nó BE é dividida principalmente nas seguintes partes:
- Sistema operacional reserva memória
- A parte da memória que não é de consulta no processo BE não pode ser contada pelo Grupo de Carga de Trabalho por enquanto.
- A memória da parte de consulta dentro do processo BE (incluindo operações de importação) pode ser contada e gerenciada pelo Grupo de Carga de Trabalho.
Os limites de recursos de memória são limitados principalmente memory_limitpor parâmetros (definindo a porcentagem de memória BE que pode ser usada). Você não apenas pode definir o uso de memória pré-configurado, mas também pode afetar a prioridade de retorno da memória após superalocação.
No estado inicial, os grupos de recursos de alta prioridade receberão mais memória e os grupos de recursos de baixa prioridade receberão menos memória. Para melhorar a utilização da memória, você pode enable_memory_overcommitativar o limite flexível de memória do grupo de recursos. Se o sistema tiver recursos de memória livres, ele poderá ser usado além do limite.
Para garantir a operação estável do sistema, quando os recursos gerais de memória do sistema forem insuficientes, o sistema dará prioridade ao cancelamento de tarefas que ocupam grandes quantidades de memória para recuperar recursos de memória excessivamente comprometidos. Durante esse processo, o sistema tentará reservar os recursos de memória dos grupos de recursos de alta prioridade e o excesso de memória dos grupos de recursos de baixa prioridade será recuperado mais rapidamente.
04 Fila de consulta
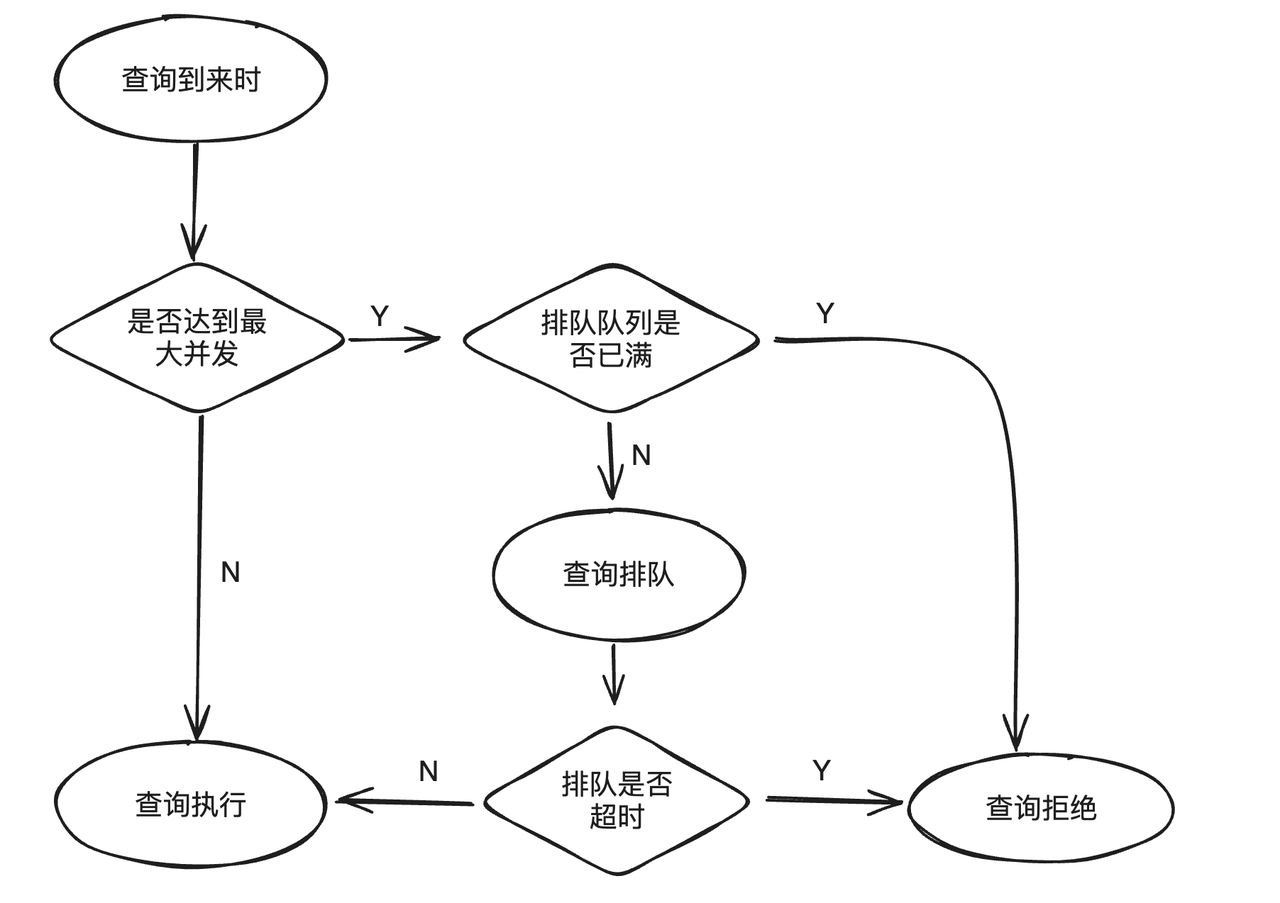
Quando a carga de negócios excede o limite superior do sistema, continuar a enviar novas consultas não apenas deixará de ser executado de forma eficaz, mas também afetará a execução de consultas. Para evitar esse problema, o Workload Group oferece suporte ao enfileiramento de consultas. Quando a consulta atingir a simultaneidade máxima predefinida, o novo plano de envio entrará na lógica de fila. Quando a fila estiver cheia ou o tempo de espera expirar, a consulta será rejeitada para aliviar a pressão do sistema sob alta carga.
A função de enfileiramento de consultas possui principalmente três atributos:
max_concurrency: o número máximo de instruções SQL permitidas para execução simultânea no grupo atual. Se o número máximo for excedido, a lógica de enfileiramento será inserida.max_queue_size: o número máximo de consultas permitidas na fila. Se a fila estiver cheia, a consulta será rejeitada e a execução falhará.queue_timeout: O limite de tempo para enfileiramento na fila. Se atingir o tempo limite, a unidade falhará diretamente.
Documentação de referência: https://doris.apache.org/zh-CN/docs/admin-manual/workload-group
Teste de uso do grupo de carga de trabalho
A seguir, realizamos testes detalhados no limite flexível e no limite rígido da CPU do grupo de carga de trabalho para demonstrar claramente aos usuários o efeito do gerenciamento de carga e o desempenho desses dois limites sob as mesmas condições de hardware.
- Ambiente de teste: máquina física única de memória 64G de 16 núcleos
- Método de implantação: 1 FE, 1 BE
- Conjunto de dados de teste: Clickbench, TPCH
- Ferramenta de medição de estresse: JMeter
01 teste de limite suave da CPU
Inicie dois clientes (1, 2) para testar o efeito do limite flexível da CPU no gerenciamento de carga sem usar/usar o limite flexível da CPU, respectivamente. Deve-se observar que, neste teste, o Page Cache afetará os resultados do teste e o Page Cache precisa ser desligado para obter os resultados de teste ideais.
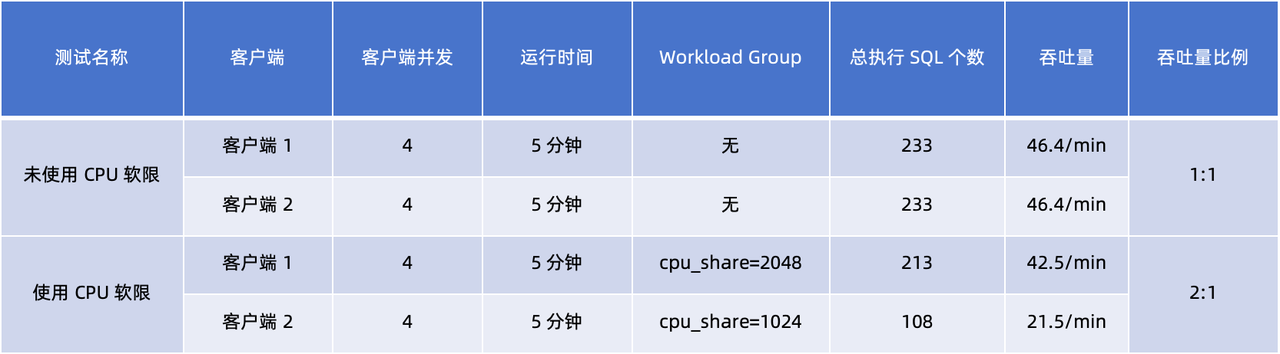
Ao comparar e analisar os dados de rendimento do cliente nos dois testes, podemos tirar as seguintes conclusões:
- Sem Workload Group , a taxa de rendimento dos dois clientes é 1:1, indicando que eles recebem os mesmos recursos de CPU durante o mesmo tempo de execução.
- Depois de usar o Grupo de carga de trabalho e
cpu_shareconfigurá-los para 2.048 e 1.024 respectivamente , os resultados mostram que a taxa de transferência se torna 2:1. Isso mostra quecpu_shareo cliente 1 com parâmetros maiores obtém uma proporção maior de recursos de CPU no mesmo tempo de execução .
02 Teste de limite rígido da CPU
Como pode ser visto na introdução acima, o limite rígido da CPU pode garantir um bom isolamento quando a carga é alta. Portanto, usamos um limite rígido para limitar o uso da CPU a 50% ( cpu_hard_limit=50%) e usamos o mesmo cliente para executar o teste de consulta q23 quando o número de simultaneidades for 1, 2 e 4 (simulando cargas diferentes). Por 5 minutos. .

A partir dos resultados do teste acima, podemos ver que à medida que o número de consultas simultâneas aumenta, a utilização da CPU é sempre estável em torno de 800% (em uma máquina de 16 núcleos, 800% significa usar 8 núcleos e a utilização real da CPU é 50 % ). Como os recursos da CPU são limitados, espera-se que a latência do tp99 aumente à medida que a simultaneidade aumenta.
03 Simular testes de ambiente de produção
Em ambientes de produção reais, os usuários geralmente prestam mais atenção ao desempenho da latência de consulta do que ao rendimento puro. Para estar mais próximo dos cenários reais de aplicação e avaliar com precisão o desempenho, selecionamos uma série de SQLs de consulta com latência de cerca de 1 segundo (incluindo q15, q17, q23 do CKBench e q3, q7, q19 do TPCH) para formar um conjunto SQL. Essas consultas cobrem vários recursos, como agregação de tabela única e cálculo de junção, e o tamanho do conjunto de dados TPCH usado é 100G.
Projetamos dois conjuntos de testes para simular cenários sem Grupo de Carga de Trabalho e com Grupo de Carga de Trabalho respectivamente. Foram realizados quatro testes no Cliente 1 e Cliente 2, com foco na latência do tp90 e tp99.
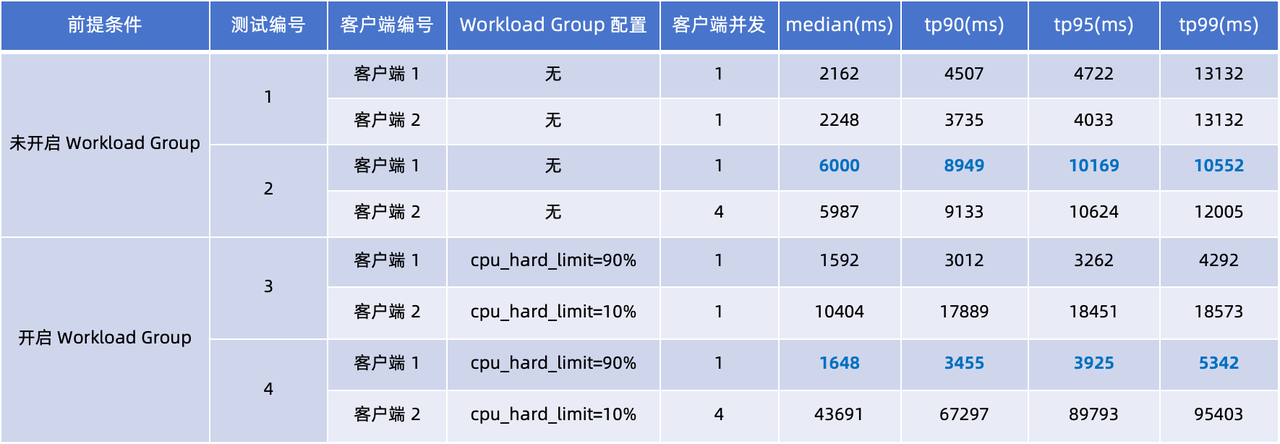
Observando os atrasos nas consultas nos quatro testes da tabela acima, podemos tirar as seguintes conclusões:
- Grupo de carga de trabalho não é usado (testes 1 e 2) : Quando a simultaneidade do cliente 2 aumenta de 1 para 4, os atrasos de consulta dos clientes 1 e 2 aumentam significativamente. Comparando o desempenho do cliente 1, a mediana dos tempos de resposta da consulta tp90 e tp95 aumentou 2 a 3 vezes.
- Usando Grupo de Carga de Trabalho (Teste 3, 4): Limites rígidos de CPU foram aplicados nestes dois testes: Definir Cliente 1
cpu_hard_limit=90%, Cliente 2cpu_hard_limit=90%. Pode-se observar pelos resultados do teste que mesmo que a simultaneidade do cliente 2 aumente, o atraso da consulta do cliente 1 aumenta apenas ligeiramente, o que é significativamente melhor do que o desempenho no teste 2. Este resultado demonstra totalmente a eficácia do Workload Group no isolamento de carga e garantia de estabilidade de desempenho.
Conclusão
Atualmente, as funções Resource Tag e Workload Group foram lançadas nos serviços de produção de vários usuários da comunidade e foram verificadas em larga escala. São recomendadas para usuários com necessidades de isolamento de recursos.
Quer se trate de etiqueta de recurso ou grupo de carga de trabalho, o objetivo é equilibrar a independência do isolamento e utilização de recursos . O primeiro adota uma solução de isolamento mais completa, enquanto o último alcança o isolamento, garantindo a utilização total dos recursos e garantindo ainda mais a estabilidade do sistema. cenários de alta carga de trabalho por meio de mecanismos de fila de consultas e enfileiramento de tarefas.
Na utilização real do isolamento de recursos, recomendamos que as duas soluções possam ser combinadas e aplicadas de acordo com os cenários de negócio:
- Se o mesmo cluster for compartilhado entre sistemas/departamentos entre negócios e você quiser obter isolamento físico de recursos e dados, poderá adotar a solução Resource Tag;
- Se você estiver enfrentando vários tipos de cargas de consulta ao mesmo tempo no mesmo cluster, poderá distinguir diferentes cargas por meio do Grupo de carga de trabalho e garantir que várias cargas de consulta possam obter recursos apropriados por meio de alocação flexível de recursos;
Ainda temos muitos planos para melhorias funcionais subsequentes:
- O limite de memória atual é usado para liberar memória por meio do Cancel Query. No futuro, o posicionamento do operador pode melhorar ainda mais a estabilidade de consultas grandes e evitar falhas nas tarefas de consulta quando os recursos são escassos.
- Atualmente, no modelo de memória do processo BE, alguma memória que não seja de consulta não é contabilizada, o que pode levar a diferenças entre a memória do processo BE e a memória utilizada pelo Grupo de Carga de Trabalho vista pelos usuários. problema em versões futuras.
- A função de enfileiramento de consultas suporta apenas o enfileiramento com base no número máximo de consultas simultâneas. No futuro, o número máximo de consultas simultâneas será restringido pelo uso de recursos do BE, formando assim uma contrapressão automática no cliente e melhorando a disponibilidade de Doris. quando o cliente continua a enviar cargas altas.
- A função Resource Tag serve para dividir os recursos da máquina BE, e o Grupo de carga de trabalho serve para dividir os recursos em um único processo de máquina. Ambos os métodos de divisão de recursos expõem o conceito de nós BE aos usuários. Quando os usuários usam a função de gerenciamento de recursos, eles basicamente só precisam prestar atenção à quantidade de recursos disponíveis e à prioridade de alocação de recursos para suas próprias cargas de trabalho em todo o conjunto. No futuro, serão exploradas novas formas de divisão de recursos para reduzir a compreensão dos utilizadores e os custos de utilização.
Agradecimentos
A função Workload Group é um projeto desenvolvido em conjunto pela comunidade de código aberto. Agradecemos aos seguintes alunos por suas contribuições: Luo Zenglin (luozenglin), Liu Lijia (liutang123), Zhao Liwei (levy5307).
Decidi desistir do código aberto Hongmeng Wang Chenglu, o pai do código aberto Hongmeng: Hongmeng de código aberto é o único evento de software industrial de inovação arquitetônica na área de software básico na China - o OGG 1.0 é lançado, a Huawei contribui com todo o código-fonte. Google Reader é morto pela "montanha de merda de código" Fedora Linux 40 é lançado oficialmente Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" Ma Huateng e Zhou Hongyi apertam as mãos para "eliminar rancores" Empresas de jogos conhecidas emitiram novos regulamentos : os presentes de casamento dos funcionários não devem exceder 100.000 yuans Ubuntu 24.04 LTS lançado oficialmente Pinduoduo foi condenado por concorrência desleal Compensação de 5 milhões de yuans