
Autor: Bruce
fundo
O case hoje compartilhado vem das melhores práticas na aplicação do MSE-ZooKeeper pela equipe técnica da Dewu. O SLA original do Dewu ZooKeeper também pode ser 99,99% |
ZooKeeper (ZK) é um serviço distribuído de coordenação de aplicativos nascido em 2007. Embora por algumas razões históricas especiais, muitos cenários de negócios ainda dependam dele. Por exemplo, Kafka, agendamento de tarefas, etc. Especialmente quando a implantação mista do Flink e o desacoplamento do ETCD, o lado comercial exigia estabilidade absoluta e recomendava fortemente não usar o ZooKeeper autoconstruído. Por questões de estabilidade, é usado o MSE-ZK do Alibaba. Desde a sua utilização em setembro de 2022, a equipa técnica do Dewu não encontrou quaisquer problemas de estabilidade e a fiabilidade do SLA atingiu de facto 99,99%.
Em 2023, algumas empresas usaram clusters ZooKeeper (ZK) autoconstruídos e, em seguida, o ZK experimentou várias flutuações durante o uso. Então, Dewu SRE começou a assumir o controle de alguns clusters autoconstruídos e fez várias rodadas de tentativas de reforço de estabilidade. Durante o processo de controle, descobriu-se que após um período de execução do ZooKeeper, o uso de memória continuará a aumentar, o que pode facilmente levar a problemas de falta de memória (OOM). A equipa técnica da Dewu ficou muito curiosa com este fenómeno e por isso participou no processo de exploração para resolver este problema.
Explorar e analisar
determinar a direção
Ao solucionar o problema, tive muita sorte de encontrar um local de falha em um ambiente de teste. Dois nós no cluster estavam em um estado extremo de OOM.

Com a cena da falha, normalmente resta apenas 50% antes do ponto final bem-sucedido. A memória está alta. De acordo com a experiência anterior, ela não é heap ou há um problema no heap. Pode ser confirmado pelo gráfico em degradê e pelo jstat que é um problema no heap.

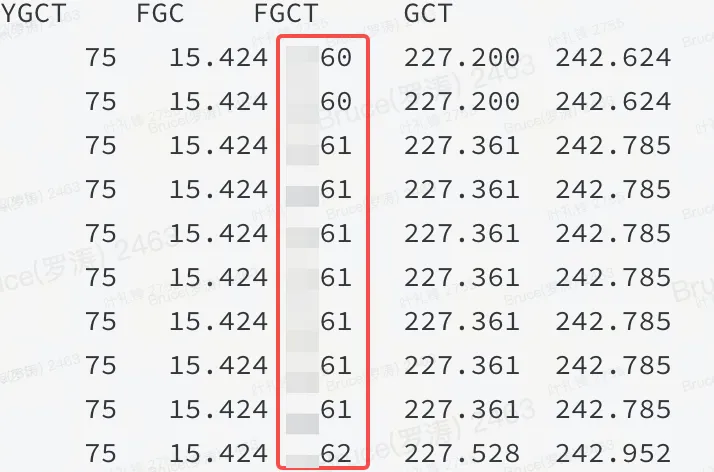
Conforme mostrado na figura: Isso significa que um determinado recurso no heap da JVM ocupa uma grande quantidade de memória e o FGC não pode liberá-lo.
Análise de memória
Para explorar a distribuição do uso de memória no heap da JVM, a equipe técnica da Dewu imediatamente fez um despejo de heap da JVM. A análise descobriu que a memória JVM está fortemente ocupada por childWatches e dataWatches.
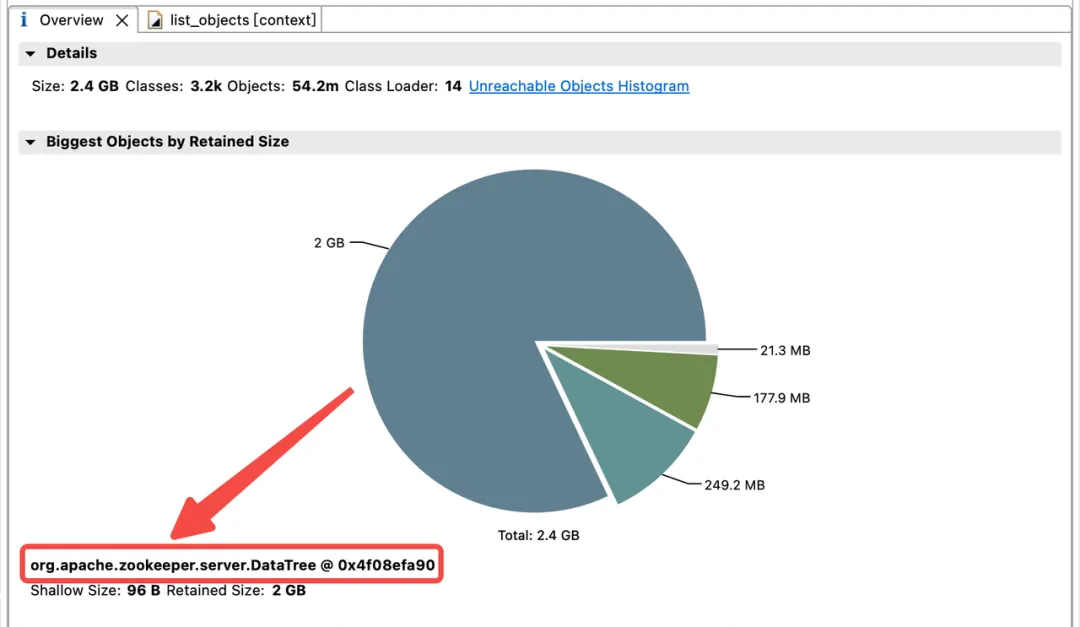
dataWatches: rastreie alterações nos dados do nó znode.
childWatches: rastreie alterações na estrutura do nó znode (árvore).
childWatches e dataWatches são originados do WatcherManager.
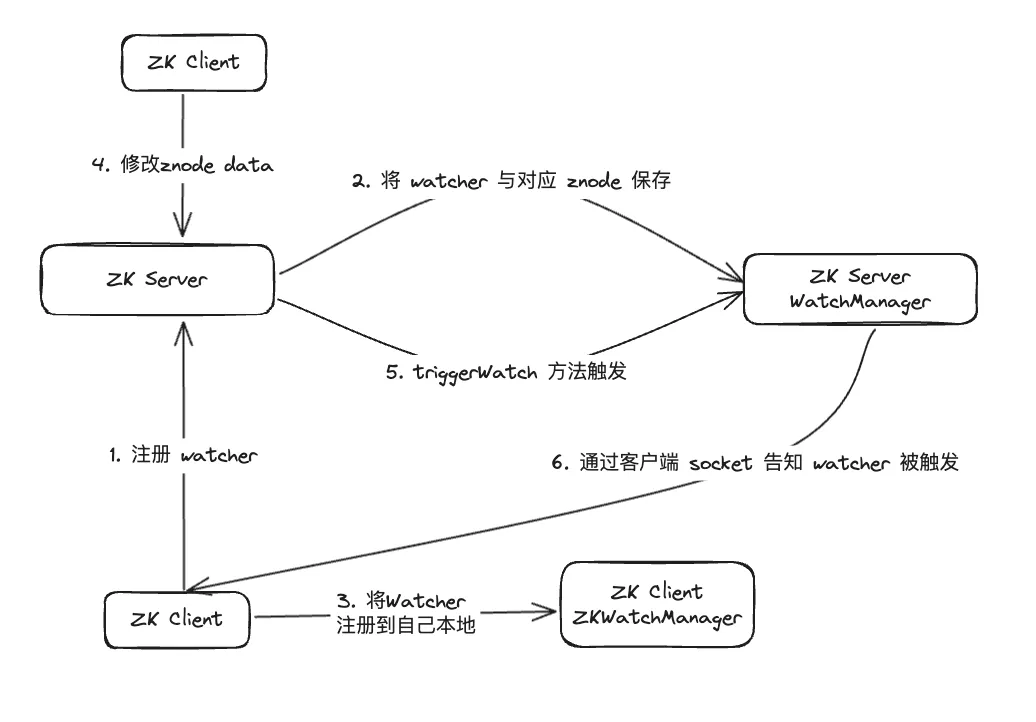
Após investigação dos dados, constatou-se que o WatcherManager é o principal responsável pelo gerenciamento dos Watchers. O cliente ZooKeeper (ZK) primeiro registra os Inspetores no servidor ZooKeeper e, em seguida, o servidor ZooKeeper usa o WatcherManager para gerenciar todos os Inspetores. Quando os dados de um Znode mudam, o WatchManager acionará o Watcher correspondente e se comunicará com o soquete do cliente ZooKeeper inscrito no Znode. Posteriormente, o gerenciador Watch do cliente acionará o retorno de chamada do Watcher relevante para executar a lógica de processamento correspondente, completando assim todo o processo de publicação/assinatura de dados.
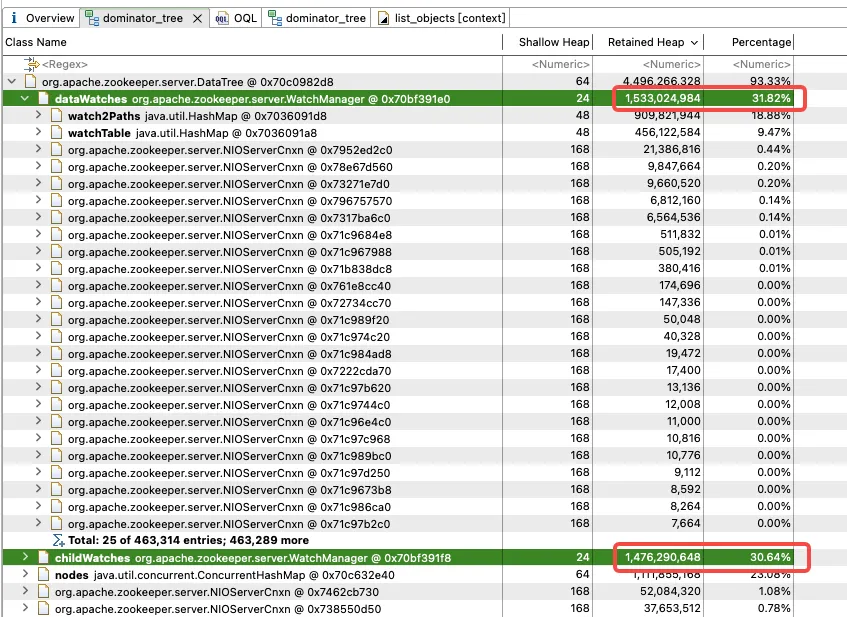
Uma análise mais aprofundada do WatchManager mostra que a proporção de memória das variáveis-membro Watch2Path e WatchTables é tão alta quanto (18,88+9,47)/31,82 = 90%.
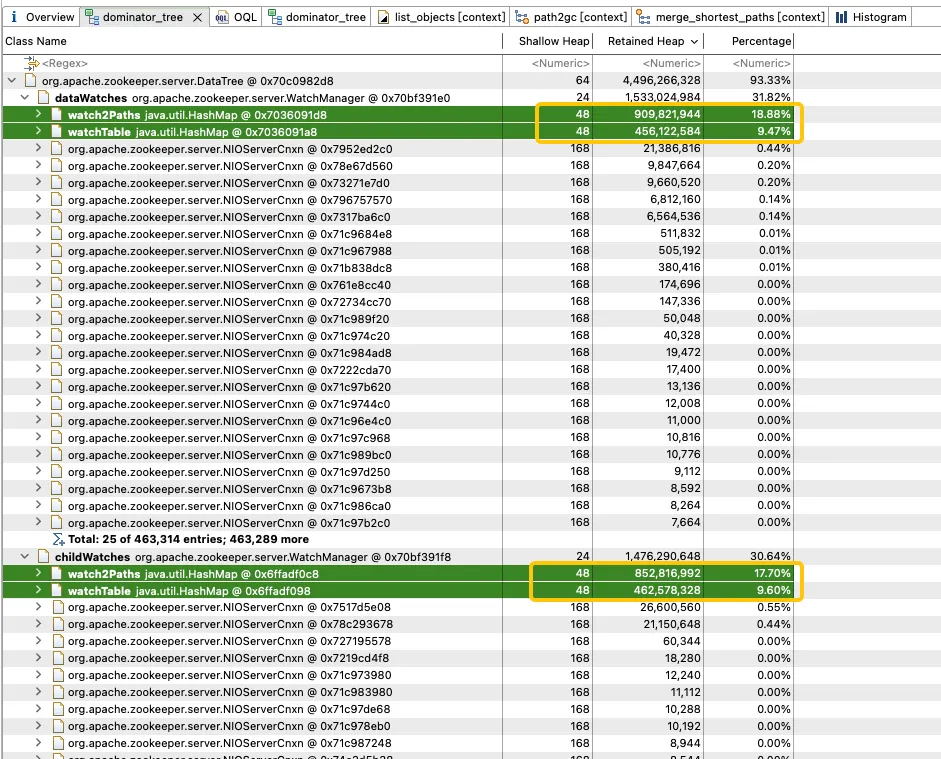
WatchTables e Watch2Path armazenam o relacionamento de mapeamento exato entre ZNode e Watcher, conforme mostrado no diagrama da estrutura de armazenamento:
WatchTables [tabela de pesquisa direta]
HashMap<ZNode, HashSet<Watcher>>
Cenário: Quando um ZNode muda, o Watcher inscrito no ZNode receberá uma notificação.
Lógica: Use este ZNode para encontrar todas as listas de Watchers correspondentes através de WatchTables e, em seguida, enviar notificações uma por uma.
Watch2Paths [tabela de pesquisa reversa]
HashMap<Observador, HashSet>
Cenário: Contar quais ZNodes um determinado Watcher assinou.
Lógica: Use este Watcher para encontrar todas as listas ZNode correspondentes através de Watch2Paths.
Watcher é essencialmente NIOServerCnxn, que pode ser entendido como uma sessão de conexão.
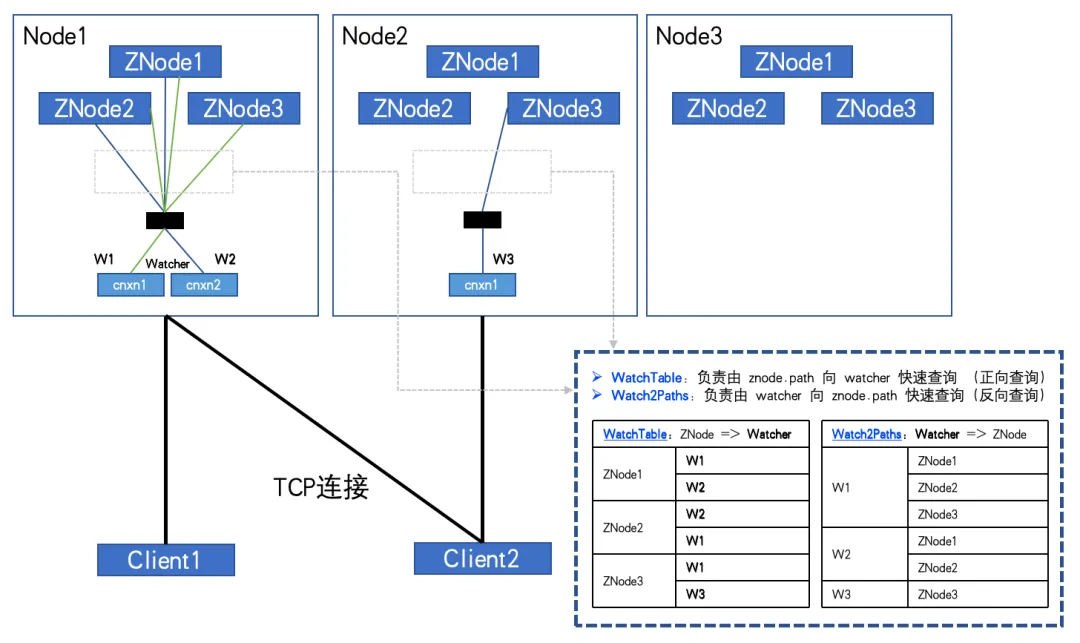
Se houver um grande número de ZNodes e Watchers, e o cliente assinar um grande número de ZNodes, ele poderá até ser totalmente inscrito. O relacionamento registrado nessas duas tabelas Hash crescerá exponencialmente e, eventualmente, atingirá um volume altíssimo!
Quando totalmente inscrito, conforme mostrado na figura:
Quando o número de ZNodes: 3, o número de Watchers: 2, WatchTables e Watch2Paths terão 6 relacionamentos cada.
Quando o número de ZNodes: 4, o número de Watchers: 3, WatchTables e Watch2Paths terão 12 relacionamentos cada.
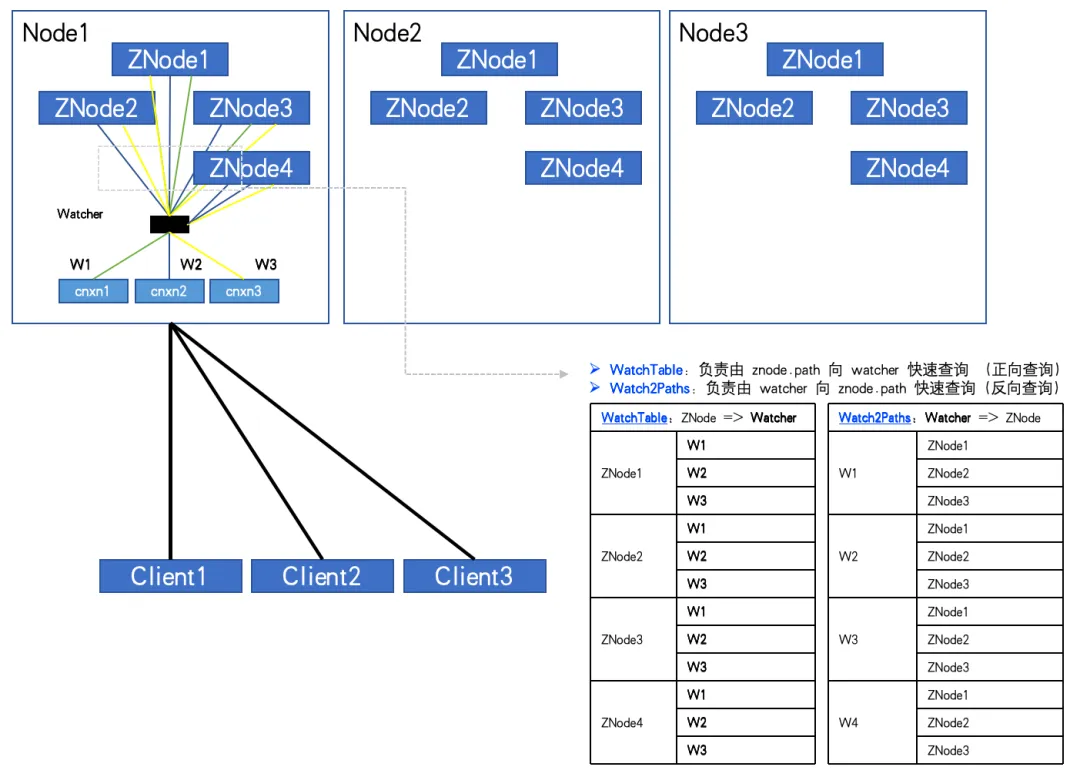
Um ZK-Node anormal foi descoberto através do monitoramento. O número de ZNodes é de cerca de 20W e o número de Watchers é de 5.000. O número de relacionamentos entre Watcher e ZNode atingiu 100 milhões.
Se for necessário um HashMap&Node (32Byte) para armazenar cada relacionamento, já que existem duas tabelas de relacionamento, dobre-o. Então não calcule mais nada. Este "shell" sozinho requer 2 10000 ^ 2 32/1024 ^ 3 = 5,9 GB de sobrecarga de memória inválida.
descoberta inesperada
Pela análise acima, podemos saber que é necessário evitar que o cliente assine integralmente todos os ZNodes. No entanto, a realidade é que muitos códigos de negócios possuem essa lógica para percorrer todos os ZNodes começando no nó raiz do ZTree e assiná-los totalmente.
Pode ser possível persuadir algumas partes empresariais a fazer melhorias, mas não pode ser forçado a restringir o uso de todas as partes empresariais. Portanto, a solução para este problema está no monitoramento e na prevenção. No entanto, infelizmente, o próprio ZK não suporta tal função, o que requer modificação do código-fonte do ZK.
Através do rastreamento e análise do código-fonte, constatou-se que a raiz do problema apontava para o WatchManager, e os detalhes lógicos desta classe foram cuidadosamente estudados. Após um entendimento profundo, descobri que a qualidade desse código parecia ter sido escrita por um recém-formado e havia muito uso inadequado de threads e bloqueios. Observando os registros do Git, descobrimos que esse problema remonta a 2007. No entanto, o que é interessante é que durante este período apareceu WatchManagerOptimized (2018). Ao pesquisar as informações da comunidade ZK, [ZOOKEEPER-1177] foi descoberto. Os relógios causaram problemas de consumo de memória e finalmente forneceram uma solução em 2018. É justamente por causa deste WatchManagerOptimized que parece que a comunidade ZK já o otimizou.
Curiosamente, o ZK não habilita esta classe por padrão, mesmo na versão 3.9.X mais recente, o WatchManager ainda é usado por padrão. Talvez porque ZK seja tão antigo, as pessoas gradualmente prestam menos atenção a ele. Ao perguntar aos colegas do Alibaba, foi confirmado que o MSE-ZK também habilitou o WatchManagerOptimized, o que confirmou ainda que o foco da equipe técnica da Dewu estava na direção certa.
Otimize a exploração
Otimização de bloqueio
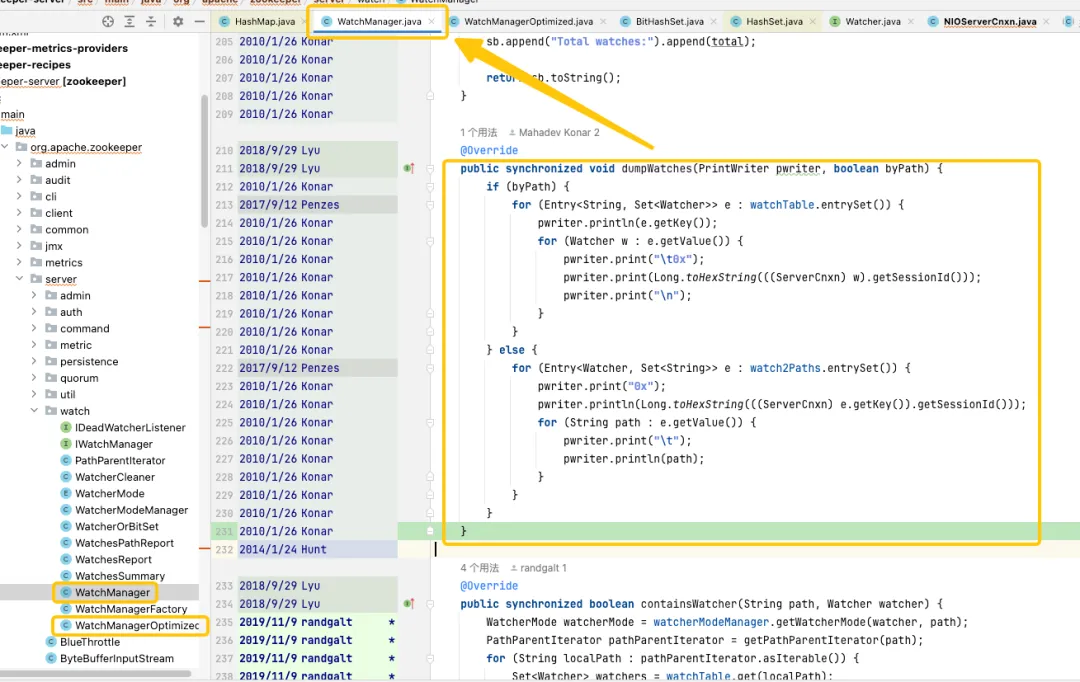
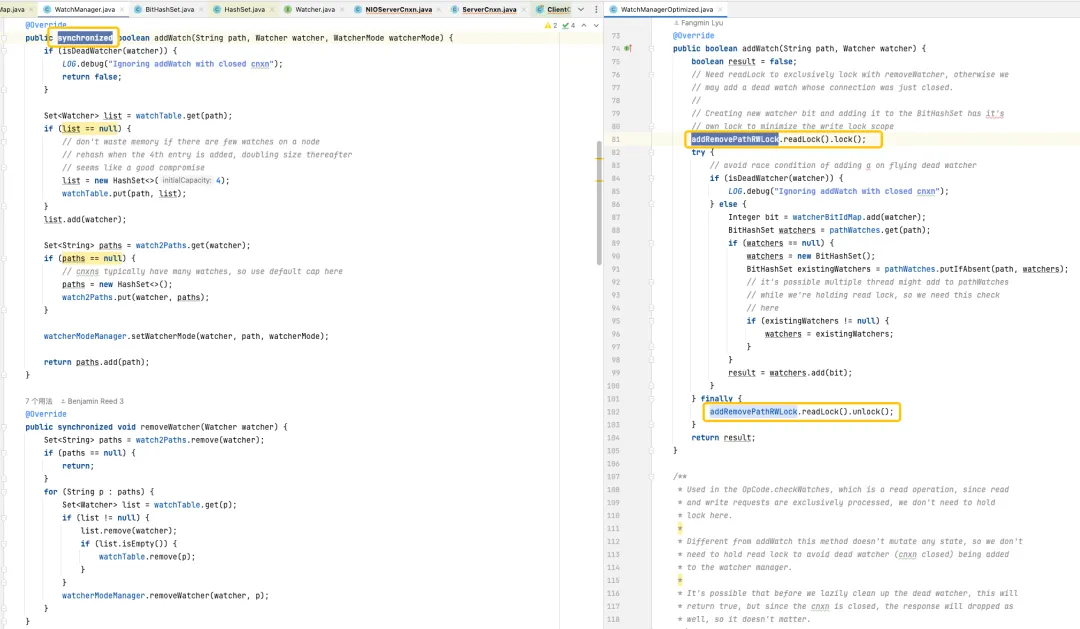
Na versão padrão, o HashSet usado não é seguro para threads. Nesta versão, métodos de operação relacionados como addWatch, removeWatcher e triggerWatch são todos implementados adicionando bloqueios pesados sincronizados aos métodos. Na versão otimizada, uma combinação de ConcurrentHashMap e ReadWriteLock é usada para usar o mecanismo de bloqueio de maneira mais refinada. Desta forma, operações mais eficientes podem ser alcançadas durante o processo de adição do Watch e acionamento do Watch.
Otimização de armazenamento
Este é o foco. A partir da análise do WatchManager, podemos ver que a eficiência de armazenamento do uso de WatchTables e Watch2Paths não é alta. Se o ZNode tiver muitos relacionamentos de assinatura, uma grande quantidade de memória inválida adicional será consumida.
Surpreendentemente, WatchManagerOptimized usa "tecnologia preta" -> bitmap aqui.
O armazenamento relacional é fortemente compactado usando bitmaps para obter otimização de redução de dimensionalidade.
Principais recursos do Java BitSet:
- Eficiente em termos de espaço: BitSet usa matrizes de bits para armazenar dados, exigindo menos espaço do que matrizes booleanas padrão.
- O processamento é rápido: operações de bits como AND, OR, XOR e inversão são geralmente mais rápidas do que as operações lógicas booleanas correspondentes.
- Expansão dinâmica: O tamanho de um BitSet pode crescer dinamicamente conforme necessário para acomodar mais bits.
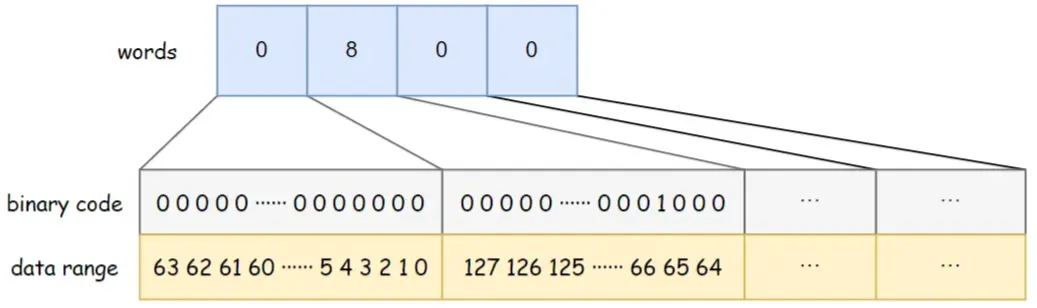
BitSet usa palavras long[] para armazenar dados. O tipo long ocupa 8 bytes e tem 64 bits . Cada elemento da matriz pode armazenar 64 dados. A ordem de armazenamento dos dados na matriz é da esquerda para a direita, do menor para o maior.
Por exemplo, a capacidade de palavras do BitSet na figura abaixo é 4. Palavras[0] de baixo a alto indicam se os dados 0 ~ 63 existem, palavras[1] de baixo a alto indicam se os dados 64 ~ 127 existem e assim sobre. Entre eles, palavras[1] = 8, e o bit binário correspondente 8 é 1, indicando que há dados {67} armazenados no BitSet neste momento.
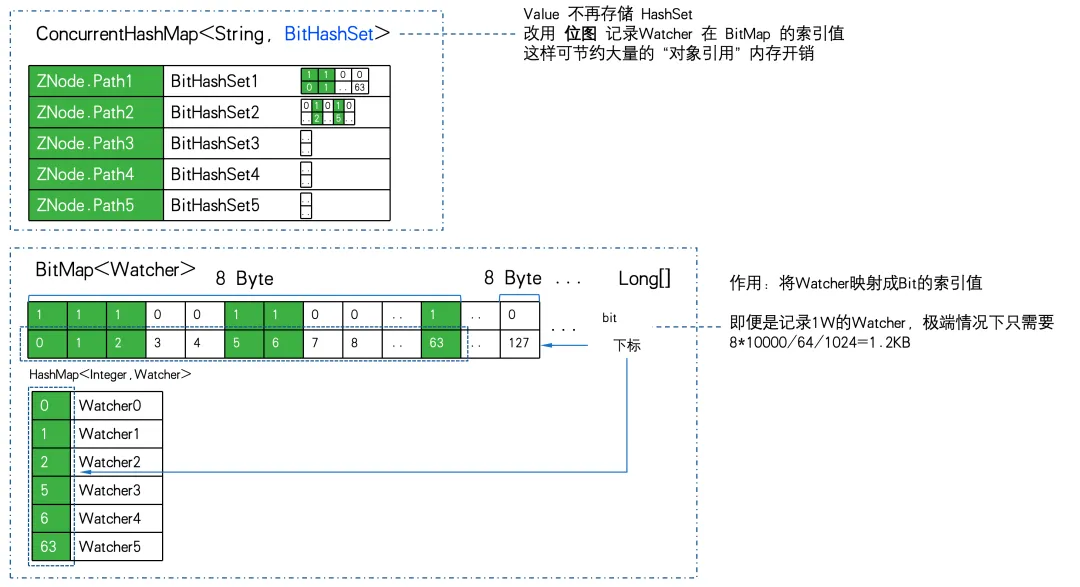
WatchManagerOptimized usa BitMap para armazenar todos os Watchers. Desta forma, mesmo que exista um 1W Watcher. O consumo de memória do bitmap é de apenas 8Byte 1W/64/1024= 1,2KB . Se substituído por HashSet, serão necessários pelo menos 32 bytes 10000/1024 = 305 KB e a eficiência de armazenamento será quase 300 vezes diferente.
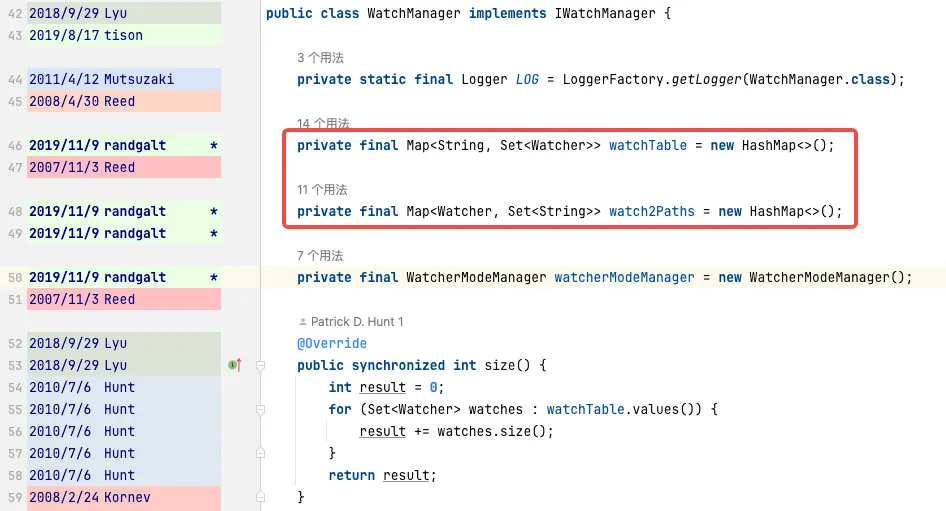
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
O armazenamento de mapeamento do ZNode para o Watcher é alterado de Map<string, set> para ConcurrentHashMap<string, BitHashSet >. Ou seja, o conjunto não é mais armazenado, mas o bitmap é usado para armazenar o valor do índice do bitmap.
Use 1W ZNode, 1W Watcher e vá até o ponto extremo da assinatura completa (todos os Watchers assinam todos os ZNodes) para fazer PK de eficiência de armazenamento:

Você pode ver que 11,7 MB PK 5,9 GB , a diferença de eficiência de armazenamento de memória é: 516 vezes .
Otimização lógica
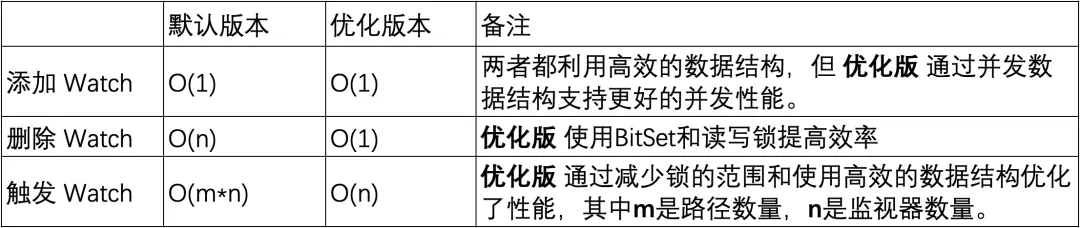
Adicionando um monitor: ambas as versões são capazes de concluir operações em tempo constante, mas a versão otimizada oferece melhor desempenho de simultaneidade usando ConcurrentHashMap .
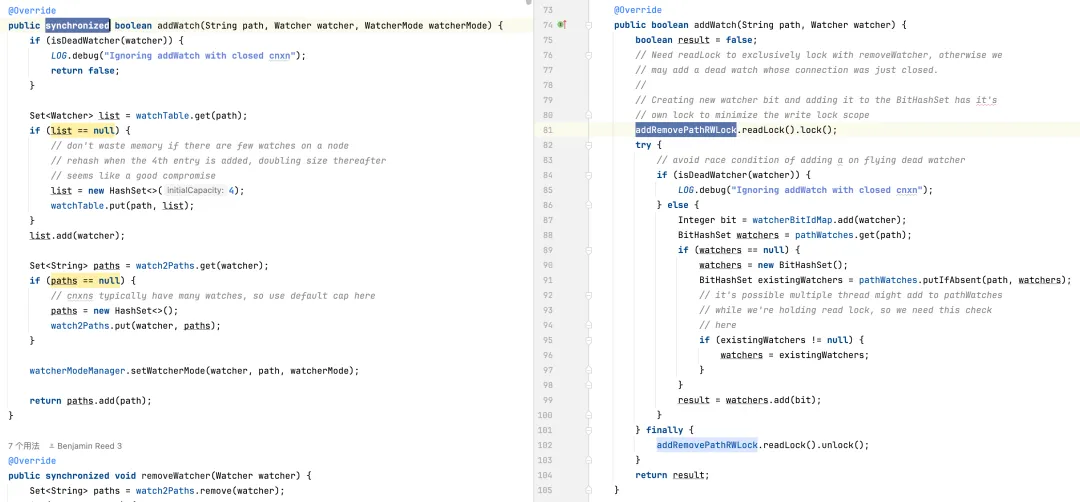
Excluindo um monitor: A versão padrão pode precisar percorrer toda a coleção de monitores para localizar e excluir o monitor, resultando em uma complexidade de tempo de O(n). A versão otimizada usa BitSet e ConcurrentHashMap para localizar e excluir rapidamente monitores em O(1) na maioria dos casos.
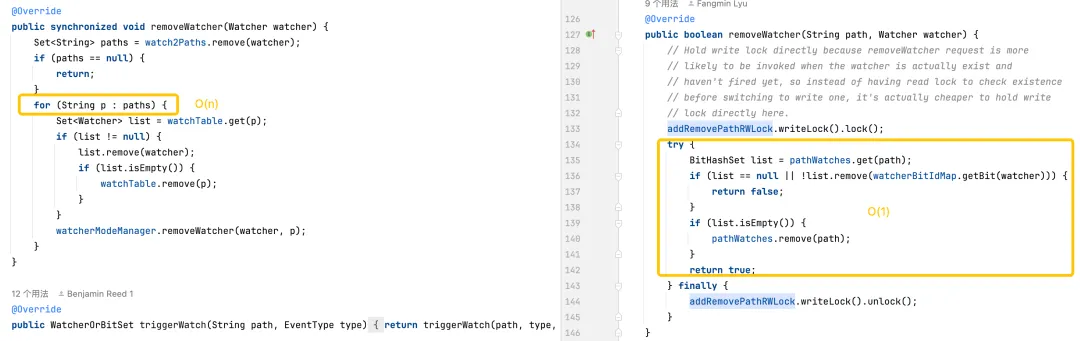
Acionamento de monitores: a versão padrão é mais complexa porque requer operações em todos os monitores e em todos os caminhos. A versão otimizada otimiza o desempenho dos monitores de disparo por meio de estruturas de dados mais eficientes e redução do uso de bloqueios.
Teste de estresse de desempenho
Microbenchmark JMH
Compilação do código-fonte do ZooKeeper 3.6.4, teste de estresse JMH micor WatchBench.
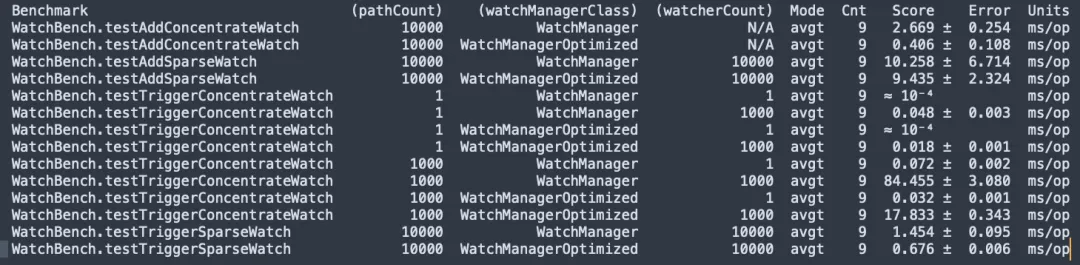
pathCount: Indica o número de caminhos ZNode usados no teste.
watchManagerClass: Representa a classe de implementação WatchManager usada no teste.
watcherCount: Indica a quantidade de observadores (Watchers) utilizados no teste.
Modo: Indica o modo de teste, aqui está avgt, que indica o tempo médio de execução.
Cnt: Indica o número de execuções de teste.
Pontuação: Indica a pontuação da prova, ou seja, o tempo médio de execução.
Erro: Indica a faixa de erro da pontuação.
Unidades: A unidade que representa a pontuação, aqui é milissegundos/operação (ms/op).
- Existem 1 milhão de assinaturas entre ZNode e Watcher. A versão padrão usa 50 MB e a versão otimizada requer apenas 0,2 MB e não aumentará linearmente.
- Adicionando Watch, a versão otimizada (0,406 ms/op) é 6,5 vezes mais rápida que a versão padrão (2,669 ms/op).
- Um grande número de relógios é acionado, e a versão otimizada (17,833 ms/op) é 5 vezes mais rápida que a versão padrão (84,455 ms/op).
Teste de estresse de desempenho
Em seguida, um conjunto de ZooKeeper 3.6.4 de 3 nós foi construído em uma máquina (32C 60G) e a versão otimizada e a versão padrão foram usadas para comparação do teste de estresse de capacidade.
Cenário 1: caminho curto do znode de 20 W
Caminho curto do Znode: /demo/znode1

Cenário 2: caminho longo do nó znode de 20 W
Caminho longo do Znode: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- O uso da memória do relógio está relacionado ao comprimento do caminho do ZNode.
- O número de relógios aumenta linearmente na versão padrão e funciona muito bem na versão otimizada, o que é uma melhoria muito óbvia para otimização do uso de memória.
Teste em escala de cinza
Com base no teste de benchmark e teste de capacidade anteriores, a versão otimizada tem otimização de memória óbvia em um grande número de cenários de observação. Em seguida, começamos a realizar observações de teste de atualização em escala de cinza no cluster ZK no ambiente de teste.
O primeiro cluster e benefícios do ZooKeeper
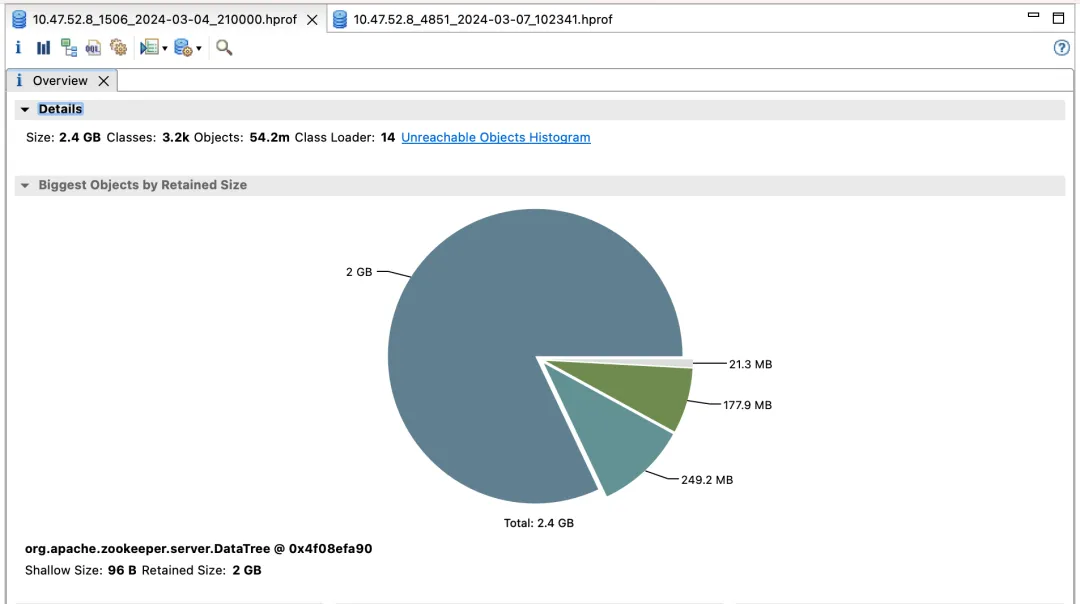
Versão padrão
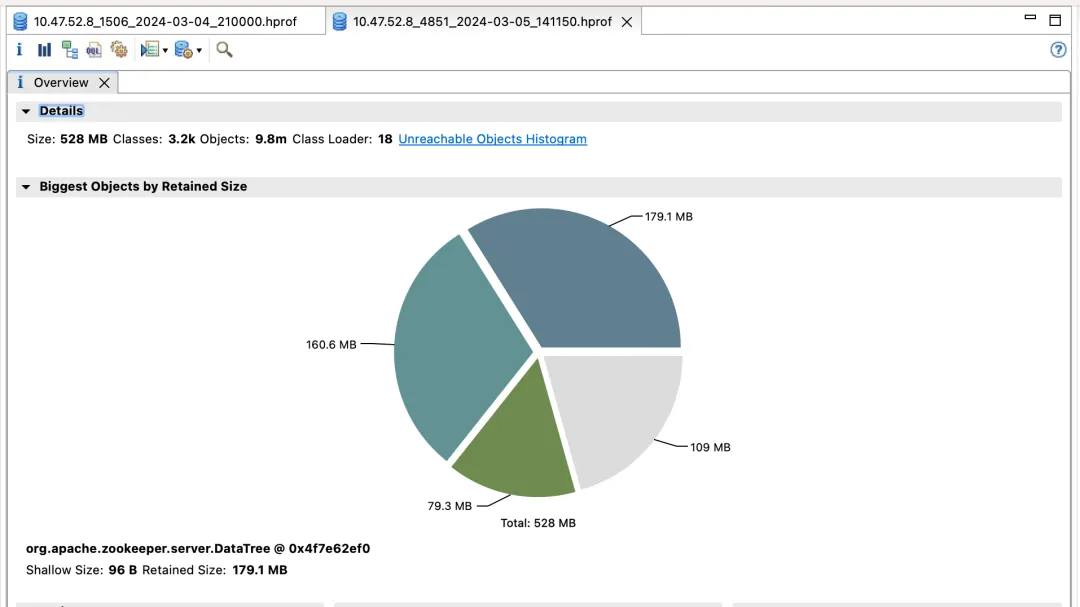
Versão otimizada


Renda de efeito:
- lection_time (horário da eleição): reduzido em 60%
- fsync_time (tempo de sincronização da transação): reduzido em 75%
- Uso de memória: reduzido em 91%
Segundo cluster e benefícios do ZooKeeper
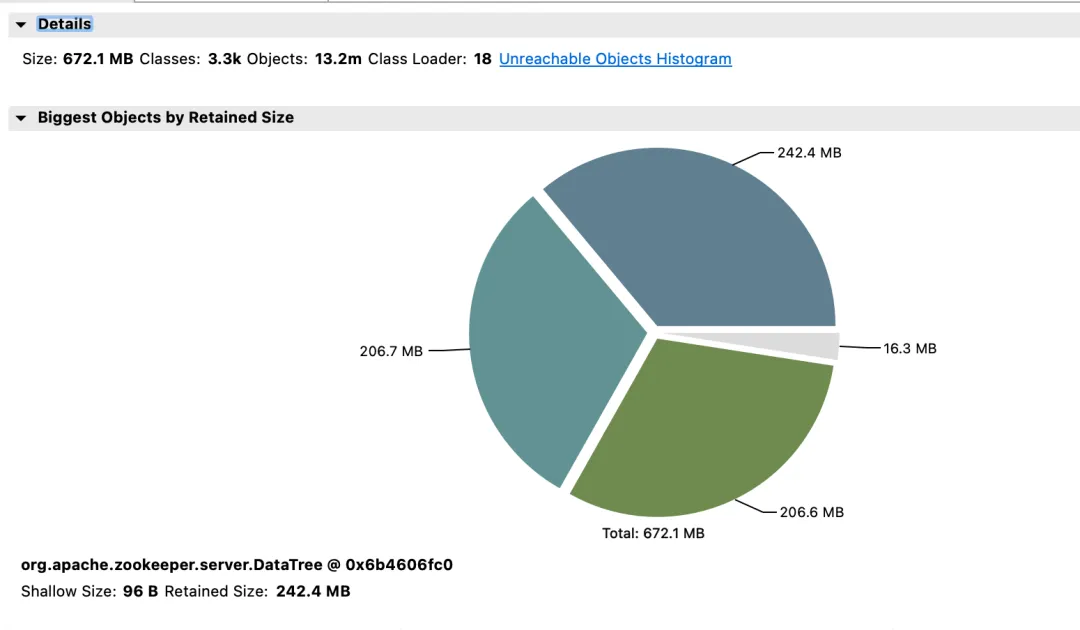



Renda de efeito:
- Memória: Antes da mudança, a resposta JVM Attach falhou em responder e a coleta de dados falhou.
- lection_time (horário eleitoral): reduzido em 64%.
- max_latency (latência de leitura): reduzido em 53%.
- proposta_latency (atraso da proposta no processamento eleitoral): 1400000 ms --> 43 ms.
- propagation_latency (atraso de propagação de dados): 1400000 ms --> 43 ms.
O terceiro conjunto de cluster e benefícios do ZooKeeper
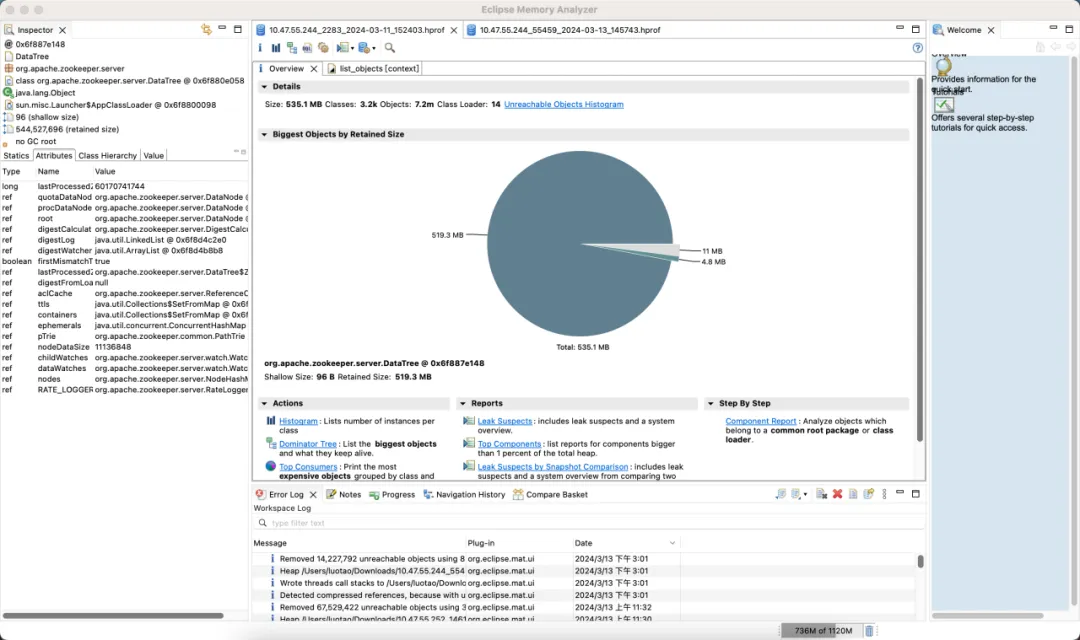
Versão padrão
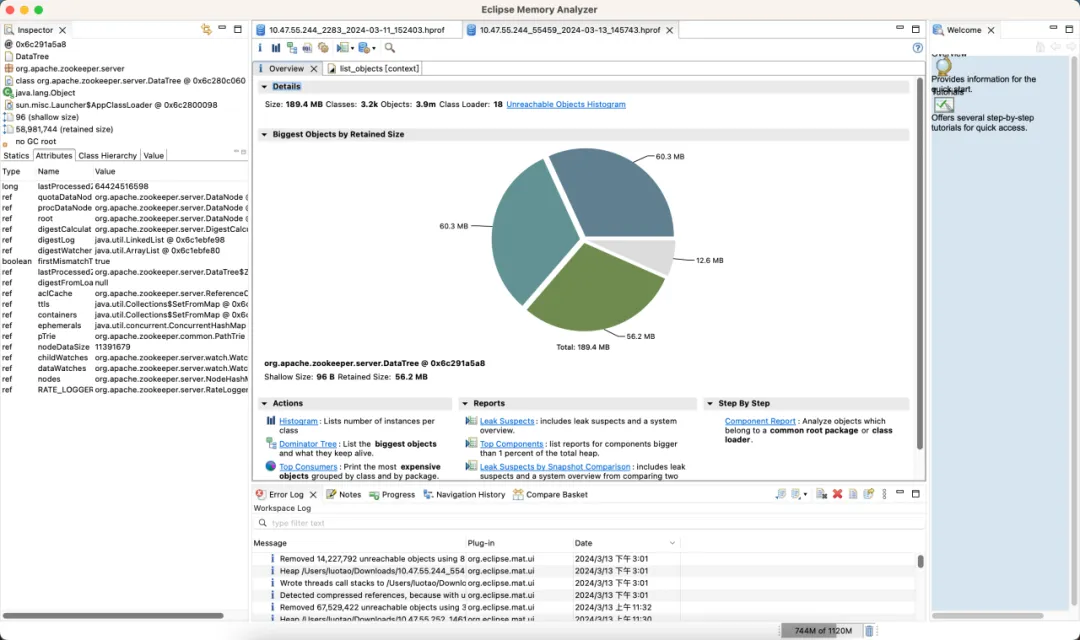
Versão otimizada
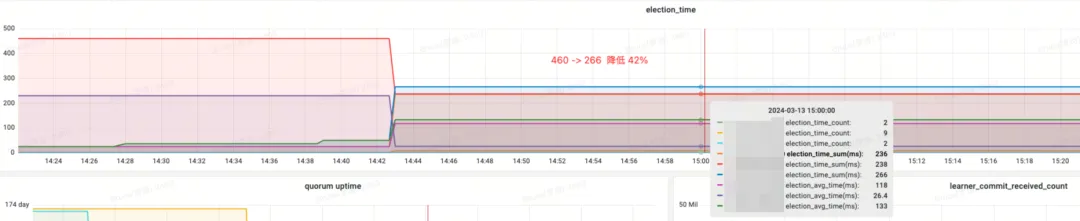

Renda de efeito:
- Memória: Economize 89%
- lection_time (horário da eleição): reduzido em 42%
- max_latency (latência de leitura): reduzido em 95%
- proposta_latency (atraso da proposta no processamento eleitoral): 679999 ms --> 0,3 ms
- propagation_latency (atraso de propagação de dados): 928.000 ms -> 5 ms
Resumir
Por meio de testes de benchmark anteriores, testes de estresse de desempenho e testes em escala de cinza, o WatchManagerOptimized do ZooKeeper foi descoberto. Essa otimização não apenas economiza memória, mas também melhora significativamente indicadores como eleição e sincronização de dados entre nós por meio da otimização de bloqueio, melhorando assim a consistência do ZooKeeper. Também tivemos intercâmbios aprofundados com alunos do Alibaba MSE, cada um simulando testes de estresse em cenários extremos, e chegamos a um consenso: WatchManagerOptimized melhora significativamente a estabilidade do ZooKeeper. No geral, essa otimização melhora o SLA do ZooKeeper em uma ordem de grandeza.
O ZooKeeper tem muitas opções de configuração, mas na maioria dos casos nenhum ajuste é necessário. Para melhorar a estabilidade do sistema, recomenda-se realizar as seguintes otimizações de configuração:
- Monte dataDir (diretório de dados) e dataLogDir (diretório de log de transações) em discos diferentes, respectivamente, e use armazenamento em bloco de alto desempenho.
- Para o ZooKeeper versão 3.8, é recomendado usar o JDK 17 e habilitar o coletor de lixo ZGC; para as versões 3.5 e 3.6, é recomendado usar o JDK 8 e habilitar o coletor de lixo G1; Para essas versões, basta configurar -Xms e -Xmx.
- Ajuste o valor padrão do parâmetro SnapshotCount de 100.000 a 500.000, o que pode reduzir significativamente a pressão do disco quando o ZNode muda em altas frequências.
- Use a versão otimizada do Watch Manager WatchManagerOptimized.
Referência:
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
Linus assumiu a responsabilidade de evitar que os desenvolvedores do kernel substituíssem tabulações por espaços. Seu pai é um dos poucos líderes que sabe escrever código, seu segundo filho é o diretor do departamento de tecnologia de código aberto e seu filho mais novo é um núcleo de código aberto. contribuidor Robin Li: A linguagem natural se tornará uma nova linguagem de programação universal. O modelo de código aberto ficará cada vez mais atrás da Huawei: levará 1 ano para migrar totalmente 5.000 aplicativos móveis comumente usados para Hongmeng. vulnerabilidades de terceiros. O editor de rich text Quill 2.0 foi lançado com recursos, confiabilidade e desenvolvedores. A experiência foi bastante melhorada. fonte de Laoxiangji não é o código, as razões por trás disso são muito comoventes. O Google anunciou uma reestruturação em grande escala.