fundointroduzir
Atualmente, as GPUs são amplamente utilizadas na plataforma de aprendizado profundo iQiyi. A GPU possui centenas ou milhares de núcleos de processamento e pode executar um grande número de instruções em paralelo, tornando-a muito adequada para cálculos relacionados ao aprendizado profundo. As GPUs têm sido amplamente utilizadas em modelos de CV (visão computacional) e PNL (processamento de linguagem natural). Em comparação com as CPUs, elas geralmente podem concluir o treinamento e a inferência do modelo de maneira mais rápida e econômica.
O modelo CTR (Click Trough Rate) é amplamente utilizado em cenários de recomendação, publicidade, pesquisa e outros para estimar a probabilidade de um usuário clicar em um anúncio ou vídeo. As GPUs têm sido amplamente utilizadas no cenário de treinamento do modelo CTR, o que melhora a velocidade de treinamento e reduz os custos de servidor necessários.
Mas no cenário de inferência, quando implantamos diretamente o modelo treinado na GPU por meio do serviço Tensorflow, descobrimos que o efeito de inferência não é ideal. aparece em:
-
A latência de inferência é alta. Os modelos do tipo CTR são geralmente orientados ao usuário final e são muito sensíveis à latência de inferência.
-
A utilização da GPU é baixa e o poder de computação não é totalmente utilizado.
Análise de causa
ferramenta de análise
-
O Tensorflow Board, ferramenta fornecida oficialmente pela tensorflow, pode visualizar visualmente o tempo consumido em cada etapa do gráfico do fluxo de cálculo e resumir o tempo total consumido pelos operadores.
-
Nsight é um conjunto de ferramentas de desenvolvimento fornecido pela NVIDIA para desenvolvedores CUDA. Ele pode realizar rastreamento, depuração e análise de desempenho de programas CUDA de nível relativamente baixo.
Conclusão da análise
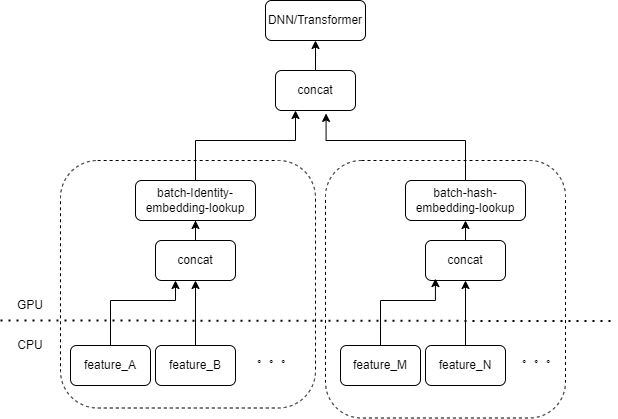
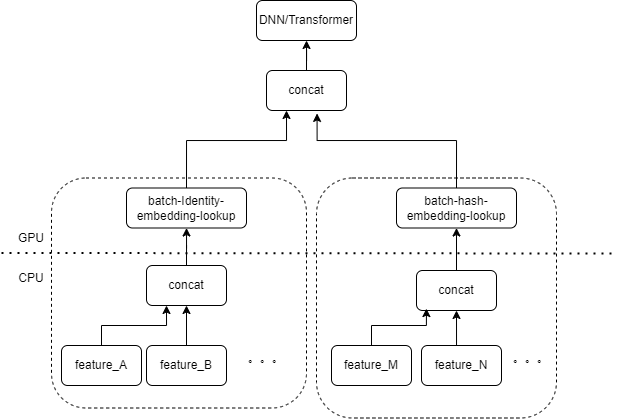
A entrada típica do modelo CTR contém um grande número de recursos esparsos (como ID do dispositivo, ID do vídeo visualizado recentemente, etc.). O FeatureColumn do Tensorflow processará esses recursos. Primeiro, as operações de identidade/hash são executadas para obter o índice da tabela de incorporação. Após incorporar as operações de pesquisa e média, o tensor de incorporação correspondente é obtido. Depois de emendar os tensores de incorporação correspondentes a vários recursos, um novo tensor é obtido e, em seguida, entra no DNN/Transformador subsequente e outras estruturas.
Portanto, cada recurso esparso ativará vários operadores na camada de entrada do modelo. Cada operador corresponderá a um ou vários cálculos de GPU, ou seja, kernel cuda. Cada kernel cuda inclui dois estágios, lançamento do kernel cuda (a sobrecarga necessária para iniciar o kernel) e execução do kernel (realmente realizando cálculos de matriz no núcleo cuda). O operador correspondente à pesquisa de identidade/hash/incorporação de recurso esparso tem uma pequena quantidade de cálculo e o kernel de inicialização geralmente leva mais tempo do que o tempo de execução do kernel. De modo geral, o modelo CTR contém dezenas a centenas de recursos esparsos e, teoricamente, haverá centenas de kernels de lançamento, que é o principal gargalo de desempenho atual.
Este problema não foi encontrado ao usar GPU para treinar o modelo CTR. Como o treinamento em si é uma tarefa off-line e não leva em consideração atrasos, o tamanho do lote durante o treinamento pode ser muito grande. Embora o kernel de lançamento ainda seja executado várias vezes, desde que o número de amostras calculadas durante a execução do kernel seja grande o suficiente, o tempo médio gasto em cada amostra do kernel de lançamento será muito pequeno. Para cenários de inferência online, se o Tensorflow Serving for necessário para receber solicitações de inferência suficientes e mesclar lotes antes de realizar cálculos, a latência de inferência será muito alta.
Otimização
Nosso objetivo é otimizar o desempenho sem alterar basicamente o código de treinamento ou a estrutura de serviço. Naturalmente pensamos em dois métodos: reduzir o número de kernels iniciados e melhorar a velocidade de inicialização do kernel.
Fusão de operadores
A operação básica é mesclar várias operações ou operadores consecutivos em um único operador. Por um lado, pode reduzir o número de inicializações do kernel cuda. Por outro lado, alguns resultados intermediários durante o processo de cálculo podem ser armazenados em registros ou compartilhados. memória, e somente no cálculo. No final da subseção, os resultados do cálculo são gravados na memória cuda global.
Existem dois métodos principais
-
Fusão automática baseada em compilador de aprendizado profundo
-
Fusão manual de operadores para empresas
fusão automática
Tentamos uma variedade de compiladores de aprendizado profundo, como TVM/TensorRT/XLA, e testes reais podem alcançar a fusão de um pequeno número de operadores em DNN, como MatrixMat/ADD/Relu contínuo. Como o TVM/TensorRT precisa exportar formatos intermediários como onnx, o processo online do modelo original precisa ser modificado. Portanto, usamos tf.ConfigProto() para habilitar o XLA integrado do tensorflow para fusão.
No entanto, a fusão automática não tem um bom efeito de fusão em operadores relacionados a recursos esparsos.
Fusão manual do operador
Naturalmente pensamos que se houver vários recursos processados pelo mesmo tipo de combinação FeatureColumn na camada de entrada, então podemos implementar um operador para dividir a entrada de vários recursos em uma matriz como a entrada do operador. A saída do operador é um tensor, e a forma desse tensor é consistente com a forma do tensor obtida calculando os recursos originais separadamente e depois concatenando-os.
Tomando a combinação original IdentityCategoricalColumn + EmbeddingColumn como exemplo, implementamos o operador BatchIdentiyEmbeddingLookup para obter a mesma lógica de cálculo.
Para facilitar o uso dos alunos de algoritmo, encapsulamos um novo FusedFeatureLayer para substituir o FeatureLayer nativo, além de incluir o operador de fusão, a seguinte lógica também é implementada:
-
A lógica fundida entra em vigor durante a inferência e a lógica original é usada durante o treinamento.
-
Os recursos precisam ser classificados para garantir que recursos do mesmo tipo possam ser organizados juntos.
-
Como a entrada de cada recurso tem comprimento variável, aqui geramos uma matriz de índice adicional para marcar a qual recurso cada elemento da matriz de entrada pertence.
Para empresas, apenas o FeatureLayer original precisa ser substituído para obter o efeito de integração.
O kernel de lançamento que foi originalmente testado centenas de vezes foi reduzido para menos de 10 vezes após a fusão manual. A sobrecarga de inicialização do kernel é bastante reduzida.
MultiStream melhora a eficiência de lançamento
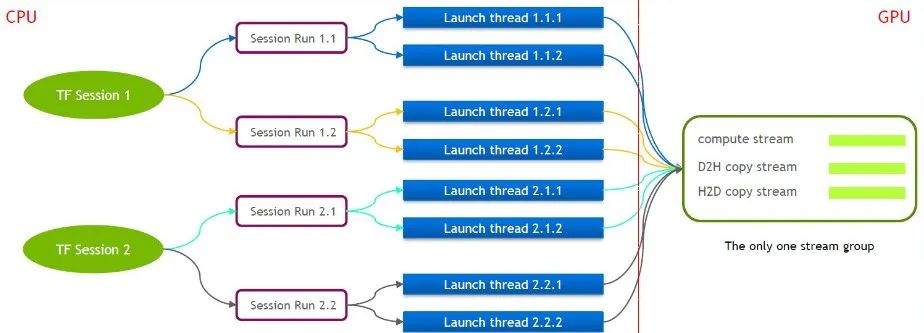
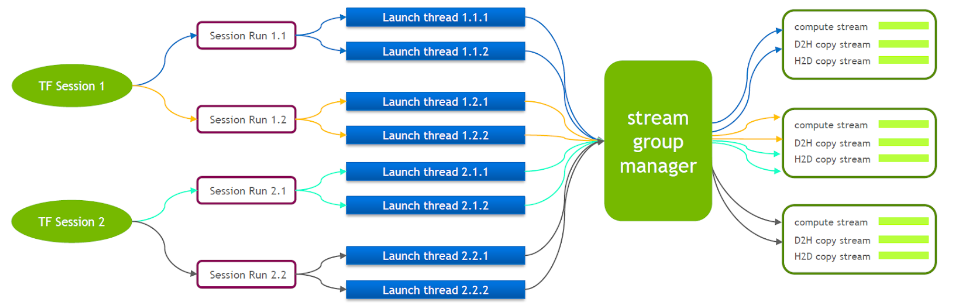
O próprio TensorFlow é um modelo de fluxo único, contendo apenas um Cuda Stream Group (composto por Compute Stream, H2D Stream, D2H Stream e D2D Stream. Vários kernels só podem ser executados em série no mesmo Compute Stream, o que é ineficiente). Mesmo que o kernel cuda seja iniciado por meio de várias sessões de tensorflow, o enfileiramento ainda é necessário no lado da GPU.
Por esse motivo, a equipe técnica da NVIDIA mantém uma ramificação própria do Tensorflow para suportar a execução simultânea de múltiplos Stream Groups. Isso é usado para melhorar a eficiência de inicialização do kernel cuda. Transferimos esse recurso para nosso Tensorflow Serving.
Quando o Tensorflow Serving está em execução, o Nvidia MPS precisa ser ativado para reduzir a interferência mútua entre vários contextos CUDA.
Otimização de pequenas cópias de dados
Com base na otimização anterior, otimizamos ainda mais a pequena cópia de dados. Depois que o Tensorflow Serving desserializa os valores de cada recurso da solicitação, ele chama cudamemcpy várias vezes para copiar os dados do host para o dispositivo. O número de chamadas depende do número de recursos.
Para a maioria dos serviços CTR, na verdade, é medido que, quando o tamanho do lote é pequeno, será mais eficiente dividir os dados primeiro no lado do host e, em seguida, chamar cudamemcpy todos de uma vez.
Mesclar lotes
No cenário de GPU, a mesclagem em lote precisa ser habilitada. Por padrão, o Tensorflow Serving não mescla solicitações. Para utilizar melhor os recursos de computação paralela da GPU, mais amostras podem ser incluídas em um cálculo direto. Ativamos a opção enable_batching do Tensorflow Serving em tempo de execução para mesclar em lote várias solicitações. Ao mesmo tempo, você precisa fornecer um arquivo de configuração em lote, com foco na configuração dos seguintes parâmetros. A seguir estão algumas de nossas experiências.
-
max_batch_size: O número máximo de solicitações permitidas em um lote, que pode ser um pouco maior.
-
batch_timeout_micros: O tempo máximo de espera para mesclar um lote Mesmo que o número do lote não atinja max_batch_size, ele será calculado imediatamente (a unidade é microssegundos). É melhor definir menos de 5 milissegundos.
-
num_batch_threads: Máximo de threads de inferência simultâneos Depois de ativar o MPS, pode ser definido como 1 a 4. Qualquer valor a mais aumentará o atraso.
Deve-se notar aqui que a maioria dos recursos esparsos inseridos no modelo de classe CTR são recursos de comprimento variável. Se o cliente não fizer um acordo especial, a duração de um determinado recurso pode ser inconsistente em múltiplas solicitações. O Tensorflow Serving possui uma lógica de preenchimento padrão, que preenche os recursos correspondentes com zeros para solicitações mais curtas. Para recursos de comprimento variável, -1 é usado para representar nulo. O preenchimento padrão de 0 realmente alterará o significado da solicitação original.
Por exemplo, o ID do vídeo assistido mais recentemente pelo usuário A é [3,5] e o ID do vídeo assistido mais recentemente pelo usuário B é [7,9,10]. Se for concluída por padrão, a solicitação se tornará [[3,5,0], [7,9,10]]. No processamento subsequente, o modelo pensará que A assistiu recentemente a 3 vídeos com IDs 3, 5, 0. .
Portanto, modificamos a lógica de conclusão da resposta do Tensorflow Serving. Nesse caso, a lógica de conclusão será [[3,5,-1], [7,9,10]]. O significado da primeira linha ainda é que os vídeos 3 e 5 foram assistidos.
efeito final
Após várias otimizações mencionadas acima, a latência e a taxa de transferência atenderam às nossas necessidades e foram implementadas em serviços personalizados recomendados de push e streaming em cascata. Os resultados do negócio são os seguintes:
-
A taxa de transferência é aumentada em mais de 6 vezes em comparação com o contêiner GPU Tensorflow nativo.
-
A latência é basicamente a mesma da CPU, atendendo às necessidades do negócio
-
Ao suportar o mesmo QPS, o custo é reduzido em mais de 40%
Talvez você também queira ver
Este artigo é compartilhado pela conta pública do WeChat - iQIYI Technology Product Team (iQIYI-TP).
Se houver alguma violação, entre em contato com [email protected] para exclusão.
Este artigo participa do “ Plano de Criação da Fonte OSC ”. Você que está lendo é bem-vindo para participar e compartilhar juntos.