
Na mente do autor, fila de mensagens , cache e subbanco de dados e subtabela são os três espadachins das soluções de alta simultaneidade.
Em minha carreira, usei filas de mensagens conhecidas, como ActiveMQ, RabbitMQ, Kafka e RocketMQ.
Neste artigo, o autor combina sua própria experiência real para compartilhar com vocês sete cenários clássicos de aplicação de filas de mensagens.
1 Assíncrono e desacoplamento
O autor já foi responsável pelo atendimento ao usuário de uma empresa de comércio eletrônico, que fornecia funções básicas como cadastro, consulta e modificação de usuários. Depois que o usuário se registrar com sucesso, uma mensagem de texto precisará ser enviada ao usuário.
Na imagem, adicionar novos usuários e enviar mensagens de texto estão incluídos no serviço da central do usuário. As desvantagens deste método são muito óbvias:
-
O canal SMS não é estável o suficiente e leva cerca de 5 segundos para enviar uma mensagem de texto. Isso torna a interface de registro do usuário muito demorada e afeta a experiência do usuário front-end;
-
Se a interface do canal SMS for alterada, o código da central de usuário deverá ser modificado. Mas o User Center é o sistema central. Você precisa ser cauteloso sempre que estiver online. Isso parece muito estranho, pois funções não essenciais afetam o sistema central.
Para resolver este problema, o autor utilizou a fila de mensagens para reconstruí-lo.

-
assíncrono
Depois que o serviço da central do usuário salva com sucesso as informações do usuário, ele envia uma mensagem para a fila de mensagens e retorna imediatamente o resultado para o front end. Isso pode evitar o problema de demorar muito e afetar a experiência do usuário.
-
dissociação
Quando o serviço de tarefa recebe a mensagem, ele chama o serviço SMS para enviar o SMS, o que separa os serviços principais das funções não essenciais e reduz significativamente o acoplamento entre os sistemas.
2 Eliminação de pico
Em cenários de alta simultaneidade, picos repentinos de solicitações podem facilmente tornar o sistema instável. Por exemplo, um grande número de solicitações para acessar o banco de dados colocará grande pressão no banco de dados ou os recursos do sistema, CPU e E/S, poderão ficar com gargalos. .
Certa vez, o autor atendeu a equipe de pedidos de carros particulares de Shenzhou. Durante o ciclo de vida do pedido do passageiro, a operação de modificação do pedido primeiro modifica o cache do pedido e, em seguida, envia a mensagem para MetaQ. O serviço de colocação de pedido consome a mensagem e determina se o pedido as informações forem normais (como se há fora de serviço), se os dados do pedido estiverem corretos, eles serão armazenados no banco de dados.

Ao enfrentar um pico de solicitações, como a simultaneidade de consumidores está dentro de uma faixa limite e a velocidade de consumo é relativamente uniforme, não terá um grande impacto no banco de dados. Ao mesmo tempo, os produtores do sistema de pedidos que realmente enfrentam o pico. o front-end também se tornará mais estável.
3 barramento de mensagens
O chamado barramento é como o barramento de dados da placa-mãe, com capacidade de transmitir e interagir dados. As partes não se comunicam diretamente e usam o barramento como interface de comunicação padrão .
O autor já atuou na equipe de pedidos de uma empresa lotérica, durante o ciclo de vida de um pedido de loteria, ele passou por diversas etapas, como criação, divisão de subpedidos, emissão de bilhetes e cálculo de prêmios. Cada link requer processamento de serviço diferente, cada sistema possui sua própria tabela independente e as funções de negócios são relativamente independentes. Se cada aplicação tivesse que modificar as informações na tabela mestre de pedidos, seria bastante confuso.
Portanto, o arquiteto da empresa projetou o serviço de <font color="red"> Central de Despacho </font>. A Central de Despacho mantém informações de pedidos, mas não se comunica com subserviços, mas sim através de filas de mensagens e gateways de tickets. como serviços de cálculo de prêmios, transmitem e trocam informações.
O projeto arquitetônico do barramento de mensagens pode tornar o sistema mais desacoplado e permitir que cada sistema desempenhe suas próprias funções.
4 tarefas atrasadas
Quando um usuário faz um pedido no APP Meituan e não paga imediatamente, uma contagem regressiva será exibida ao inserir os dados do pedido. Caso o prazo de pagamento seja ultrapassado, o pedido será automaticamente cancelado.
Uma maneira muito elegante é usar mensagens atrasadas da fila de mensagens .
Depois que o serviço de pedidos gera o pedido, ele envia uma mensagem atrasada para a fila de mensagens. A fila de mensagens entrega a mensagem ao consumidor quando a mensagem atinge o prazo de vencimento do pagamento. Após o consumidor receber a mensagem, ela determina se o status do pedido é pago. Caso não seja pago, a lógica de cancelamento do pedido é executada.

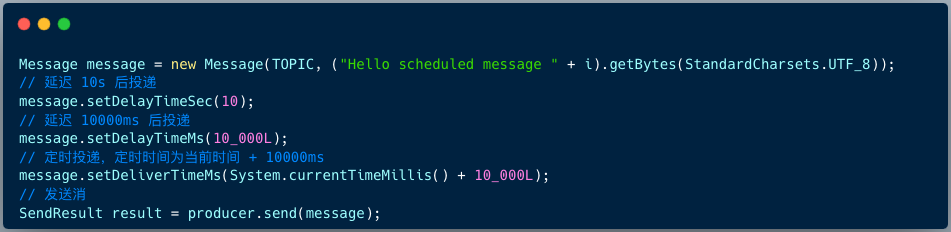
O código para o produtor RocketMQ 4.X enviar mensagens atrasadas é o seguinte:
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
A versão RocketMQ 4.X suporta 18 níveis de mensagens atrasadas por padrão, que são determinados pelo item de configuração messageDelayLevel no lado do corretor.

A versão RocketMQ 5.X suporta atraso de mensagens a qualquer momento. O cliente fornece 3 APIs para especificar o tempo de atraso ou tempo ao construir a mensagem.
5 Consumo de rádio
Consumo de broadcast : Ao usar o modo de consumo de broadcast, cada mensagem é enviada para todos os consumidores do cluster, garantindo que a mensagem seja consumida por cada consumidor pelo menos uma vez.
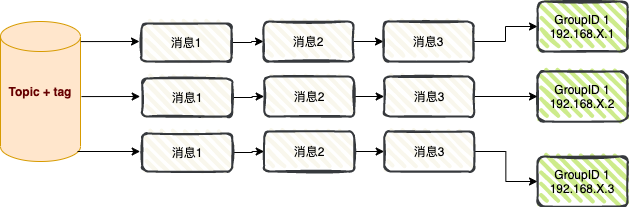
O consumo de broadcast é usado principalmente em dois cenários: envio de mensagens e sincronização de cache .
01 Envio de mensagem
A figura abaixo mostra o mecanismo push do lado do motorista de um carro particular. Depois que o usuário faz um pedido, o sistema de pedidos gera um pedido de carro especial. O sistema de despacho despachará o pedido para um motorista com base no algoritmo relevante, e o motorista. -end receberá a mensagem push de despacho.
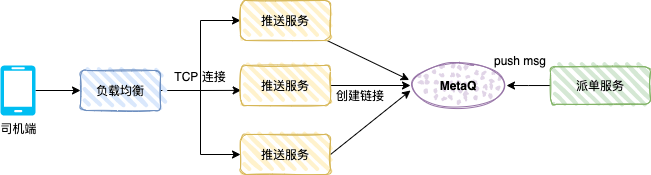
O serviço push é um serviço TCP (protocolo personalizado) e um serviço de consumidor. O modo de mensagem é o consumo de transmissão.
Depois que o driver abrir o APP do driver, o APP criará uma conexão longa por meio de balanceamento de carga e serviço push, e o serviço push salvará a referência de conexão TCP (como número do driver e referência do canal TCP).
O serviço de despacho é o produtor e envia os dados de despacho para MetaQ. Cada serviço push consumirá a mensagem. O serviço push determina se o canal TCP do driver existe na memória local. através da conexão TCP do lado do driver.
02 Sincronização de cache
Em cenários de alta simultaneidade, muitos aplicativos usam cache local para melhorar o desempenho do sistema.
O cache local pode ser HashMap, ConcurrentHashMap ou a estrutura de cache Guava Cache ou Caffeine cache.

Conforme mostrado na figura acima, após o aplicativo A ser iniciado, como consumidor RocketMQ, o modo de mensagem é configurado para consumo de transmissão. Para melhorar o desempenho da interface, cada nó do aplicativo carrega a tabela do dicionário no cache local.
Quando os dados da tabela do dicionário mudam, uma mensagem pode ser enviada ao RocketMQ por meio do sistema de negócios, e cada nó do aplicativo consumirá a mensagem e atualizará o cache local.
6 transações distribuídas
Tomando o cenário de transação de comércio eletrônico como exemplo, a operação principal de pagamento de pedidos pelo usuário também envolverá mudanças em vários subsistemas, como entrega logística downstream, alterações de pontos e compensação de status do carrinho de compras.
![]()
1. Solução tradicional de transação XA: desempenho insuficiente
Para garantir a consistência dos resultados de execução das quatro ramificações acima, uma solução típica é implementada por um sistema de transações distribuídas baseado no protocolo XA. Encapsule as quatro ramificações de chamada em uma grande transação contendo quatro ramificações de transação independentes. A solução baseada em transações distribuídas XA pode atender à correção dos resultados do processamento de negócios, mas a maior desvantagem é que em um ambiente multi-filial, o intervalo de bloqueio de recursos é grande e a simultaneidade é baixa. À medida que o número de filiais downstream aumenta, o o desempenho do sistema ficará cada vez pior.
2. Baseado no esquema de mensagens comuns: dificuldade em garantir consistência
![]()
Nesta solução, o ramo downstream da mensagem e o ramo principal da mudança do sistema de pedidos estão sujeitos a inconsistências, por exemplo:
- A mensagem foi enviada com sucesso, mas o pedido não foi executado com sucesso e toda a transação precisa ser revertida.
- A ordem foi executada com sucesso, mas a mensagem não foi enviada com sucesso e foi necessária uma compensação adicional para descobrir a inconsistência.
- O tempo limite de envio da mensagem é desconhecido e é impossível determinar se o pedido precisa ser revertido ou se as alterações do pedido devem ser enviadas.
3. Baseado em mensagens de transação distribuídas RocketMQ: suporta consistência eventual
Na solução de mensagens comuns mencionada acima, a razão pela qual as mensagens comuns e as transações de pedidos não podem ser garantidas como consistentes é essencialmente porque as mensagens comuns não podem ter a capacidade de confirmação, reversão e coordenação unificada como transações de banco de dados independentes.
A função de mensagem de transação distribuída implementada com base no RocketMQ oferece suporte a recursos de envio em dois estágios com base em mensagens comuns. Vincule o envio em duas fases às transações locais para obter consistência nos resultados do envio global.
As mensagens de transação RocketMQ oferecem suporte para garantir a consistência eventual da produção de mensagens e transações locais em cenários distribuídos . O processo de interação é mostrado na figura abaixo:
![]()
1. O produtor envia a mensagem ao Corretor.
2. Depois que o Broker persiste a mensagem com sucesso, ele retorna um Ack ao produtor para confirmar que a mensagem foi enviada com sucesso. Neste momento, a mensagem é marcada como " temporariamente não entregue " . mensagem de transação .
3. O produtor começa a executar a lógica de transação local .
4. O produtor envia um resultado de confirmação secundário (Commit ou Rollback) ao servidor com base no resultado da execução da transação local. Após o Broker receber o resultado da confirmação, a lógica de processamento é a seguinte:
- O resultado secundário da confirmação é Commit: o Broker marca a mensagem da semitransação como entregável e a entrega ao consumidor.
- O resultado secundário da confirmação é Rollback: o Broker reverterá a transação e não entregará a mensagem da semitransação ao consumidor.
5. Em circunstâncias especiais onde a rede é desconectada ou a aplicação do produtor é reiniciada, se o Broker não receber o resultado da confirmação secundária enviado pelo remetente, ou o resultado da confirmação secundária recebido pelo Broker estiver no status Desconhecido, após um período fixo período de tempo, o serviço O terminal iniciará uma revisão da mensagem .
- Após o produtor receber a revisão da mensagem, ele precisa verificar o resultado final da execução da transação local correspondente à mensagem.
- O produtor envia novamente uma confirmação secundária com base no status final da transação local que está sendo verificada , e o servidor ainda processa a mensagem de meia transação de acordo com a etapa 4.
7 Centro de transferência de dados
Nos últimos 10 anos, surgiram sistemas especiais como armazenamento KV (HBase), pesquisa (ElasticSearch), processamento de streaming (Storm, Spark, Samza), banco de dados de série temporal (OpenTSDB) e outros sistemas especiais. Esses sistemas foram criados com um único objetivo em mente e sua simplicidade torna mais fácil e econômico construir sistemas distribuídos em hardware comum.
Freqüentemente, o mesmo conjunto de dados precisa ser injetado em vários sistemas especializados.
Por exemplo, quando os logs do aplicativo são usados para análise de log offline, a pesquisa de registros de log individuais também é indispensável. Obviamente, é impraticável construir fluxos de trabalho independentes para coletar cada tipo de dados e depois importá-los para seus próprios sistemas dedicados. serve como um hub de transferência de dados e os mesmos dados podem ser importados para diferentes sistemas dedicados.
A sincronização de logs tem principalmente três partes principais: cliente de coleta de logs, fila de mensagens Kafka e aplicativo de processamento de log de back-end.
- O cliente de coleta de logs é responsável por coletar dados de log de vários serviços de aplicativos do usuário e enviar os logs "em lotes" e "de forma assíncrona" para o cliente Kafka na forma de mensagens. O cliente Kafka envia e compacta mensagens em lotes, o que tem muito pouco impacto no desempenho dos serviços de aplicação.
- Kafka armazena logs em arquivos de mensagens, fornecendo persistência.
- Os aplicativos de processamento de log, como o Logstash, assinam e consomem mensagens de log no Kafka e, eventualmente, o serviço de pesquisa de arquivos recupera os logs ou o Kafka passa as mensagens para outros aplicativos de big data, como o Hadoop, para armazenamento e análise sistemáticos.

Se meu artigo for útil para você, curta , leia e encaminhe . Seu apoio me incentivará a produzir artigos de melhor qualidade.
