
Introdução ao histórico
Num sistema empresarial recente, a base de dados secundária está num estado atrasado e não consegue acompanhar a base de dados principal, resultando em maiores riscos empresariais. Do ponto de vista dos recursos, o uso de CPU, E/S e rede da biblioteca escrava é baixo e não há situação em que a reprodução seja retardada por pressão excessiva do servidor. A reprodução paralela está habilitada na biblioteca escrava. biblioteca mostra que não há threads de reprodução Bloqueio, a reprodução continua; analisando o arquivo de log de retransmissão, verifica-se que não há reprodução de transações grandes.
análise de processo
Confirmação do fenômeno
Recebi feedback de meus colegas de operação e manutenção de que um conjunto de bibliotecas escravas estava muito atrasado. Forneci show slave statusinformações de captura de tela sobre o atraso.
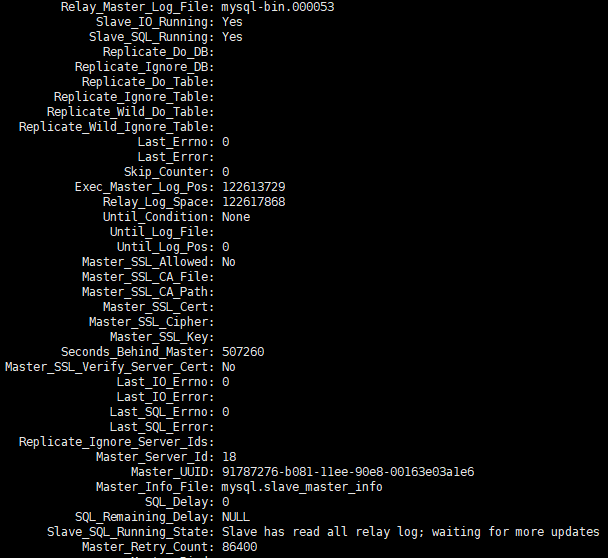
Depois de continuar observando show slave statusas mudanças por um tempo, descobri que as informações do ponto POS mudavam constantemente, Seconds_Behind_master também mudava constantemente e a tendência geral continuava a crescer.
Uso de recursos
Depois de observar o uso de recursos do servidor, podemos perceber que o uso é muito baixo.

Observando o processo escravo, você basicamente pode ver apenas um thread reproduzindo o trabalho.
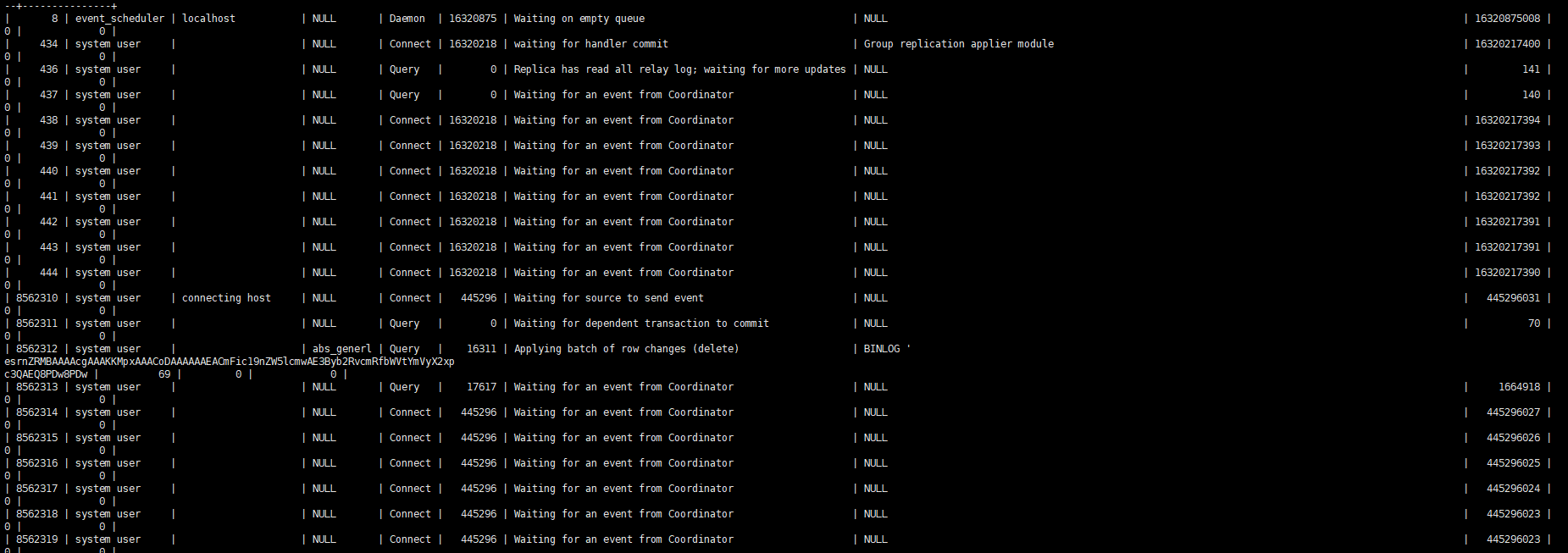
Descrição do parâmetro de reprodução paralela
Situado na biblioteca principalbinlog_transaction_dependency_tracking=WRITESET
Na biblioteca de escravos, slave_parallel_type=LOGICAL_CLOCKo eslave_parallel_workers=64
comparação de log de erros
Obtenha o log de reprodução paralela do log de erros para análise
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
Para obter uma explicação detalhada das informações acima, consulte Monitoramento de desempenho do MTS Quanto você sabe?
Removidas as estatísticas que ocorriam com menos frequência e mostramos a comparação de alguns dados importantes.
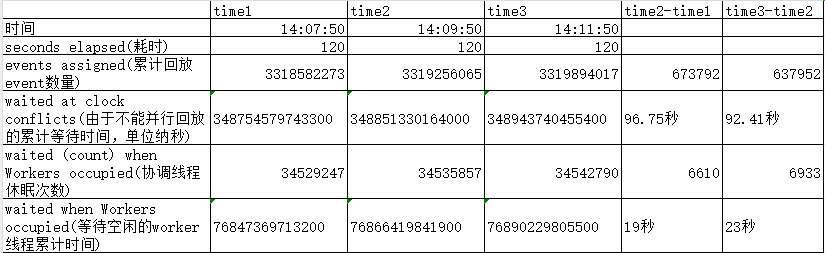
Pode-se descobrir que no tempo natural de 120, o encadeamento de coordenação de reprodução espera mais de 90 segundos porque não pode reproduzir em paralelo e quase 20 segundos porque não há encadeamentos de trabalho ociosos para esperar. Isso se traduz em apenas cerca de 10 segundos. para que o thread de coordenação funcione.
Estatísticas de paralelismo
Como todos sabemos, a reprodução paralela do MySQL da biblioteca depende principalmente do last_committed no binlog para fazer julgamentos. Se o last_committed da transação for o mesmo, pode-se basicamente considerar que essas transações podem ser reproduzidas em paralelo. as estatísticas aproximadas de obtenção de um log de retransmissão do ambiente para reprodução paralela.
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
O primeiro comando acima conta o número de transações com o mesmo last_commit entre 1 e 10, ou seja, o grau de reprodução paralela é baixo ou não pode ser reproduzido em paralelo. O número total dessas transações é 235703, representando 43%. Análise detalhada das transações com um grau relativamente baixo de reprodução paralela A partir da distribuição da transação, pode-se ver que esta parte do last_committed é basicamente uma única transação. Eles precisam aguardar a conclusão da reprodução da transação pré-encomendada antes de poderem reproduzi-lo. Isso fará com que a espera do encadeamento de coordenação observada no log anterior seja incapaz de reproduzir em paralelo e entre no estado de espera. Quando o tempo for relativamente longo
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
O segundo comando conta o número total de transações com mais de 10 transações last_committed iguais. O número é 314694, representando 57%. Ele analisa essas transações com um grau relativamente alto de reprodução paralela em detalhes. entre 6.500 e 9.000. número de transações
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
Introdução ao mecanismo last_commited
Os parâmetros da biblioteca principal binlog_transaction_dependency_trackingsão usados para especificar como gerar as informações de dependência gravadas no log binário para ajudar a biblioteca escrava a determinar quais transações podem ser executadas em paralelo. Ou seja, este parâmetro é usado para controlar o mecanismo de geração de last_committed. Os valores opcionais do parâmetro são COMMIT_ORDER, WRITESET e SESSION_WRITESET. No código a seguir, é fácil ver os três relacionamentos de parâmetros:
- O algoritmo básico é COMMIT_ORDER
- O algoritmo WRITESET é calculado novamente com base em COMMIT_ORDER
- O algoritmo SESSION_WRITESET é calculado novamente com base em WRITESET
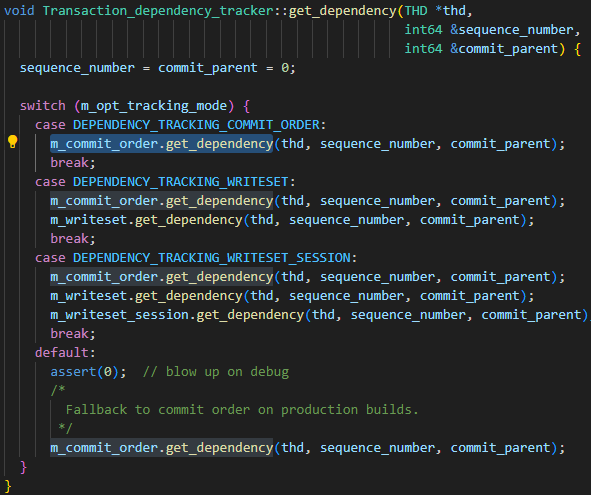
Como minha instância está definida como WRITESET, concentre-se apenas no algoritmo COMMIT_ORDER e no algoritmo WRITESET.
COMMIT_ORDER
Regra de cálculo COMMIT_ORDER: Se duas transações forem enviadas ao mesmo tempo no nó mestre, significa que não há conflito entre os dados das duas transações, então elas também podem ser executadas em paralelo no nó escravo. Um caso típico ideal. é o seguinte.
| sessão 1 | sessão-2 |
|---|---|
| COMEÇAR | COMEÇAR |
| INSERIR valores t1 (1) | |
| INSERIR valores t2 (2) | |
| confirmar (grupo_commit) | confirmar (grupo_commit) |
Mas para o MySQL, group_commit é um comportamento interno, desde que a sessão 1 e a sessão 2 executem o commit ao mesmo tempo, independentemente de serem mescladas internamente no group_commit, os dados das duas transações são essencialmente livres de conflitos; um passo atrás, contanto que a sessão 1 execute o commit e nenhum dado novo seja gravado na sessão 2, as duas transações ainda não terão conflitos de dados e ainda poderão ser replicadas em paralelo.
| sessão 1 | sessão-2 |
|---|---|
| COMEÇAR | COMEÇAR |
| INSERIR valores t1 (1) | |
| INSERIR valores t2 (2) | |
| comprometer-se | |
| comprometer-se |
Para cenários com mais threads simultâneos, esses threads podem não conseguir replicar em paralelo ao mesmo tempo, mas algumas transações podem. Tomando a sequência de execução a seguir como exemplo, após a confirmação da sessão 3, a sessão 2 não tem novas gravações, portanto as duas transações podem ser replicadas em paralelo; após a confirmação da sessão 3, a sessão 1 insere novos dados, o conflito de dados não pode ser determinado neste momento, portanto, as transações da sessão 3 e da sessão 1 não podem ser replicadas em paralelo; mas após o envio da sessão 2, nenhum dado novo é gravado após a sessão 1, portanto, a sessão 2 e a sessão 1 são novamente Podem ser replicados em paralelo. Portanto, neste cenário, a sessão 2 pode ser replicada em paralelo com a sessão 1 e a sessão 3 respectivamente, mas as três transações não podem ser replicadas em paralelo ao mesmo tempo.
| sessão 1 | sessão-2 | sessão-3 |
|---|---|---|
| COMEÇAR | COMEÇAR | COMEÇAR |
| INSERIR valores t1 (1) | INSERIR valores t2 (1) | INSERIR valores t3 (1) |
| INSERIR valores t1 (2) | INSERIR valores t2 (2) | |
| comprometer-se | ||
| INSERIR valores t1 (3) | ||
| comprometer-se | ||
| comprometer-se |
ESCREVER
Na verdade, é uma combinação de commit_order + writeset. Ele primeiro calculará um valor last_committed por meio de commit_order, depois calculará um novo valor por meio de writeset e, finalmente, tomará o valor menor entre os dois como o valor last_committed da transação final gtid.
No MySQL, writeset é essencialmente um valor hash calculado para schema_name + table_name + Primary_key/unique_key Durante a execução da instrução DML, antes de gerar row_event por meio de binlog_log_row, todas as chaves primárias/chaves exclusivas na instrução DML terão valores de hash calculados. separadamente e adicionado à lista writeset da própria transação. E se houver uma tabela sem chave primária/índice exclusivo, has_missing_keys=true também será definido para a transação.
O parâmetro está definido como WRITESET, mas não pode ser usado. As restrições são as seguintes.
- Instruções ou tabelas não DDL com chaves primárias ou chaves exclusivas ou transações vazias
- O algoritmo hash usado pela sessão atual é consistente com o do mapa hash.
- Nenhuma chave estrangeira usada
- A capacidade do mapa hash não excede a configuração de binlog_transaction_dependency_history_size Quando as quatro condições acima forem atendidas, o algoritmo WRITESET pode ser usado. Se alguma das condições não for atendida, ele degenerará para o método de cálculo COMMIT_ORDER.
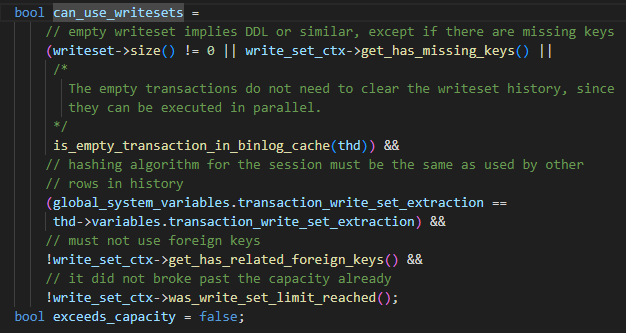
O algoritmo WRITESET específico é o seguinte, quando a transação é enviada:
-
last_committed está definido como m_writeset_history_start, este valor é o menor número_sequencial na lista m_writeset_history
-
Percorra a lista de transações do writeset
a Se um writeset não existir no m_writeset_history global, construa um objeto pair<writeset, sequence_number> da transação atual e insira-o na lista global m_writeset_history
b. Se existir, last_committed=max(last_committed, o valor de sequence_number do writeset histórico) e, ao mesmo tempo, atualize o sequence_number correspondente ao writeset em m_writeset_history para o valor da transação atual
-
Se has_missing_keys=false, ou seja, todas as tabelas de dados da transação contêm chaves primárias ou índices exclusivos, então o valor mínimo calculado por commit_order e writeset será usado como o valor final last_committed.
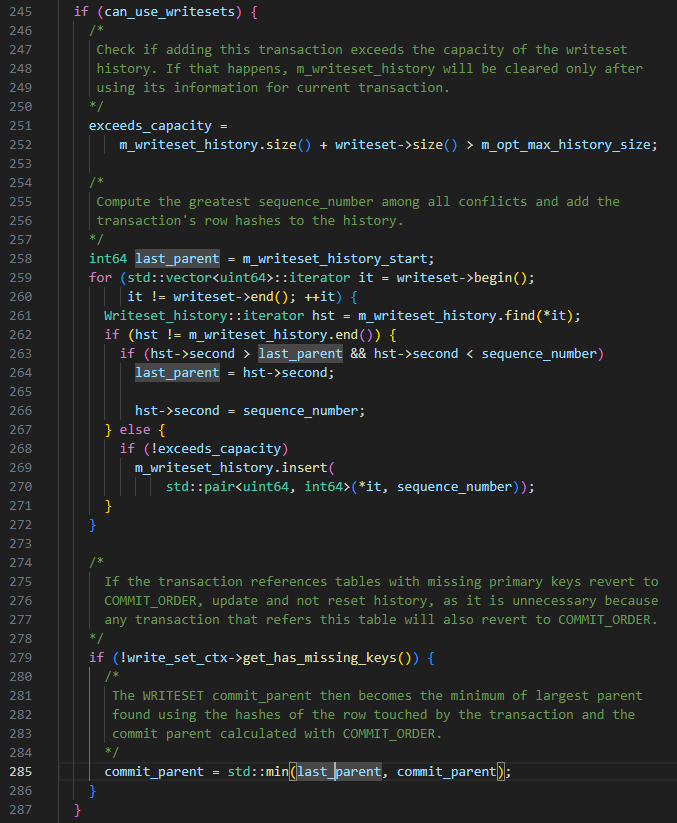
DICAS: Com base nas regras WRITESET acima, haverá uma situação em que o last_committed da transação enviada posteriormente será menor do que a transação enviada primeiro.
Análise de conclusão
Descrição da conclusão
De acordo com as restrições de uso do WRITESET, comparamos o log de retransmissão e as estruturas da tabela envolvidas na transação, analisamos a composição da transação do único last_committed e encontramos as duas situações a seguir:
- Há um conflito de dados entre os dados envolvidos na única transação last_committed e no sequence_number.
- A tabela envolvida em uma única transação last_committed não possui chave primária e existem muitas dessas transações.
A partir da análise acima, pode-se concluir que há muitas transações na tabela sem uma chave primária, fazendo com que WRITESET degenere em COMMIT_ORDER.Como o banco de dados é um aplicativo TP, as transações são enviadas rapidamente e o envio de múltiplas transações não pode ser garantido estar dentro de um ciclo de confirmação, resultando em COMMIT_ORDER As leituras repetidas last_committed geradas pelo mecanismo são muito baixas. A biblioteca escrava só pode reproduzir essas transações em série, causando atrasos na reprodução.
Medidas de otimização
- Modifique as tabelas do lado comercial e adicione chaves primárias às tabelas relacionadas sempre que possível.
- Tente aumentar os parâmetros binlog_group_commit_sync_delay e binlog_group_commit_sync_no_delay_count de 0 a 10.000. Devido a restrições ambientais especiais, esse ajuste não entra em vigor. Cenários diferentes podem ter desempenhos diferentes.
Aproveite o GreatSQL :)
Sobre GreatSQL
GreatSQL é um banco de dados doméstico independente de código aberto adequado para aplicativos de nível financeiro. Possui muitos recursos básicos, como alto desempenho, alta confiabilidade, alta facilidade de uso e alta segurança. Ele pode ser usado como um substituto opcional para MySQL ou Percona Server e é utilizado em ambientes de produção online, totalmente gratuito e compatível com MySQL ou Percona Server.
Links relacionados: Guia da comunidade GreatSQL GitHub Bilibili
Comunidade GreatSQL:

Sugestões e feedback de recompensas da comunidade: https://greatsql.cn/thread-54-1-1.html
Detalhes do envio do prêmio do blog da comunidade: https://greatsql.cn/thread-100-1-1.html
(Se você tiver alguma dúvida sobre o artigo ou tiver ideias exclusivas, você pode acessar o site oficial da comunidade para perguntar ou compartilhá-las ~)
Grupo de intercâmbio técnico:
Grupo WeChat e QQ:
Grupo QQ: 533341697
Grupo WeChat: Adicione o GreatSQL Community Assistant (WeChat ID:) wanlidbccomo amigo e espere que o assistente da comunidade adicione você ao grupo.