1. Introdução à plataforma
O faturamento autooperado financeiro assume principalmente a função de transferir os dados autooperados de JD da extremidade C para a extremidade B em toda a cadeia de suprimentos. É um estágio posterior em toda a cadeia de suprimentos. A principal função do sistema é o faturamento e agregação para o final B.
2. Descrição do problema
Nos últimos anos, a quantidade de dados de cobrança autooperados aumentou significativamente, com mais de 10 bilhões de volumes de dados, e o resumo representa metade dos recursos do banco de dados por dia.
1. Localize dezenas de milhares de dados de dezenas de milhões de W+ em uma única tabela todos os dias para realizar resumos, ou seja, realizar grupo por operação em todos os bancos de dados e todas as tabelas, 32 bancos de dados * 32 tabelas, que leva 12 horas para processar diariamente.
2. Durante o período de agregação, o sistema basicamente estagnou, resultando em processamento lento de mensagens e tarefas, um grande atraso e a incapacidade de cobrar dados em tempo hábil.
3. O banco de dados está sob grande pressão e corre o risco de travar a qualquer momento.
4. Afeta a experiência do fornecedor.Durante o grande período de promoção, os fornecedores precisam verificar os dados de vendas e os relatórios de batalha em tempo real, e o sistema não consegue responder a tempo.
3. Introdução à tecnologia original
O núcleo do resumo do sistema depende da máquina física MySQL para realizar o agrupamento em cada banco de dados e em cada tabela. O resumo é dividido e conquistado por tipo de despesa. Cada tipo de dimensão de resumo é diferente. Cada vez que uma nova dimensão de resumo é introduzida, ele precisa ser escrito de frente para trás. A nova lógica de resumo serve principalmente para bloquear o intervalo de dados da nova dimensão e determinar o novo grupo por campo. A lógica anterior teve que ser testada em regressão, o que é estúpido, eu acho.
4. Ideias e métodos para resolver problemas
Com base nos antecedentes e nos problemas acima, determine uma solução aproximada para o problema
1. Em primeiro lugar, devemos romper com o resumo do MySQL. O banco de dados é muito frágil. Devemos protegê-lo, caso contrário a magnitude continuará aumentando e um dia o céu cairá.
2. Resolver incidentalmente as desvantagens do desenvolvimento repetido de novos requisitos.
5. Descrição do processo prático
Devido ao grande volume, o processamento T + 1 é permitido no negócio. Como se trata de processamento de dados off-line, geralmente pode-se pensar em spark, spring batch, finlk, etc.. No estágio de pesquisa técnica, a maturidade e a atividade da comunidade são principalmente considerado, e a tecnologia de faísca é usada principalmente. Divida o processo de resumo em 4 etapas. Para facilitar a compreensão, o conteúdo a seguir simplifica a lógica e a descreve resumidamente.
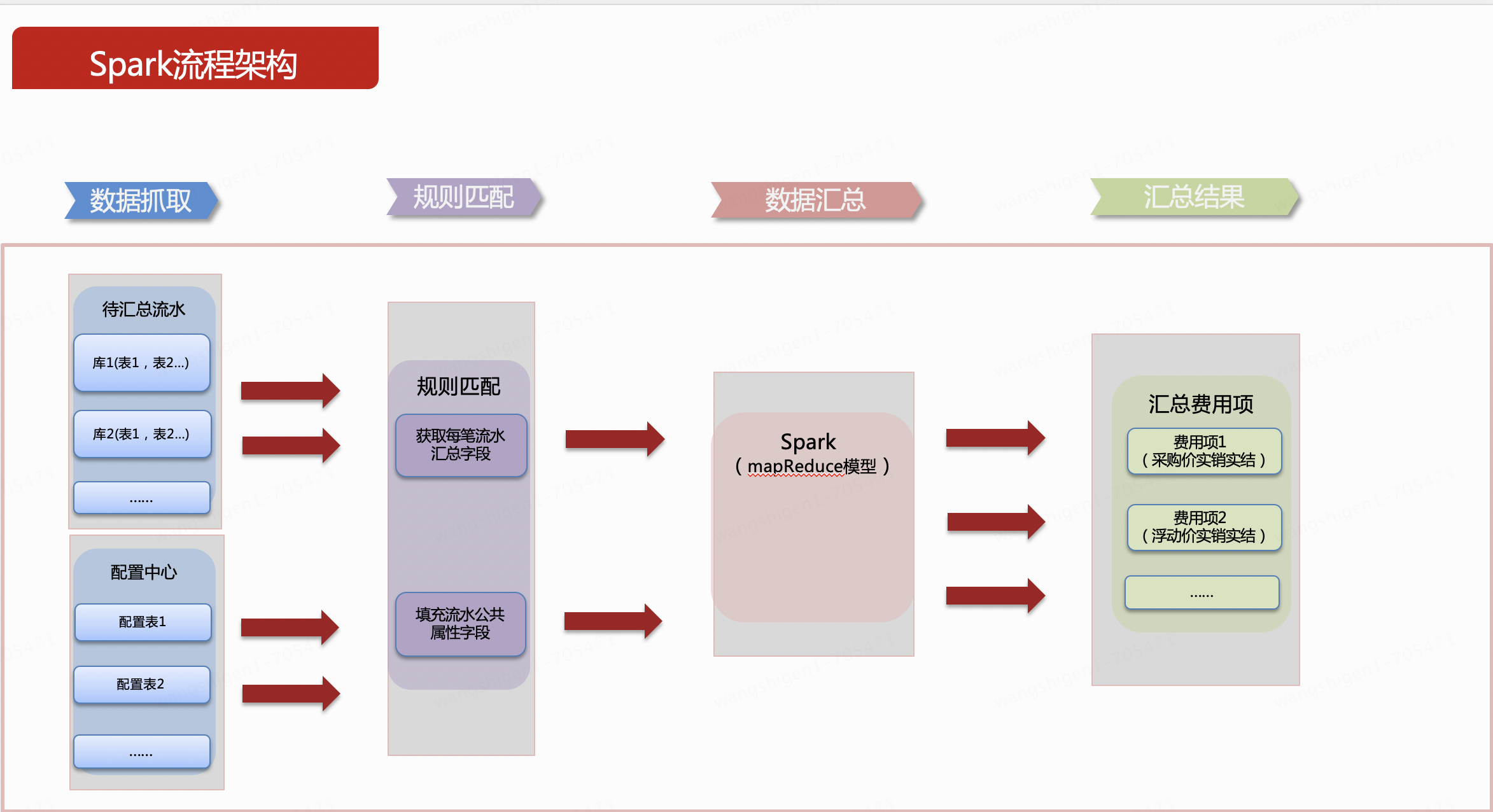
1. Captura de dados
Os dados antes da agregação são dados comerciais. O tipo geralmente se refere ao campo que divide o tipo de custo dos dados nos dados comerciais. ou e departamento geralmente se referem às dimensões dos dados de origem, que podem ser um ou mais campos. Valor é o campo a ser resumido e somado. Aqui é expresso o valor.
A tabela de configuração é derivada dos dados de origem. Pode haver muitos dados de configuração, que é um termo geral. Este sistema usa apenas uma tabela. type indica que o tipo de despesa é usado para associar aos dados de origem. A associação pode ser associada a um ou mais campos. Aqui, um campo é usado como exemplo. merge_key é um campo de resumo e o valor do campo é um ou mais da estrutura da tabela dos dados de origem.Composição do campo. fatura_type representa os campos públicos que precisam ser preenchidos no conjunto de resultados agregados e é geralmente chamado de tipo de fatura aqui. Pode ser expandido de acordo com os campos preenchidos, caso expandido basta adicionar colunas posteriormente na tabela de configuração. O diagrama de exemplo a seguir expressa esse significado em um único campo.
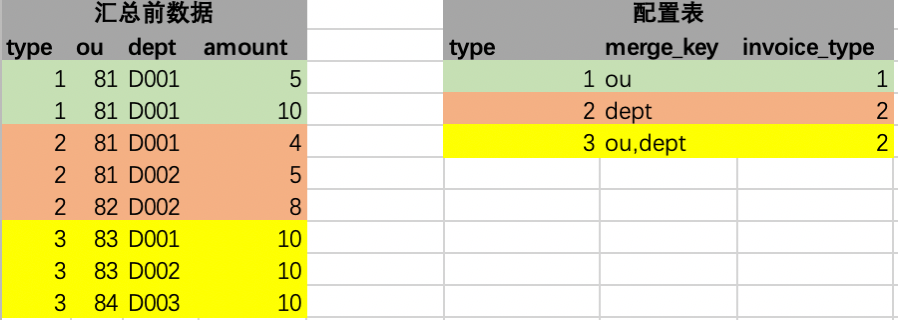
2. Correspondência de regras
O primeiro processamento é realizado, ou seja, cada linha dos dados de origem é associada à única linha da tabela de configuração, conforme mostrado na figura abaixo. Sob instruções especiais, cada linha dos dados de origem pode ser associada a apenas uma linha de configuração na tabela de configuração, ou seja, left join, que não pode ser associado, ou seja, não tem configuração, é filtrado e não está resumido . A primeira etapa da operação de processamento é concluída na memória.

Em seguida, prossiga para a segunda etapa de processamento. Nesta etapa, precisamos analisar ainda mais o campo merge_key retirado da tabela de configuração no valor específico do campo correspondente à linha de junção esquerda atual. O resultado analisado é mostrado abaixo: De acordo com a explicação desta etapa, de acordo com o campo de merge_key, como a primeira linha ou, é obtido o valor do campo da coluna correspondente desta linha, que é 81. O princípio é implementado através da reflexão Java. Existem agora várias ferramentas de código aberto que podem ser usadas diretamente no pacote, como expressões spring e outras ferramentas. Por analogia, os valores de vários campos também podem ser obtidos. Vários campos podem ser emendados de acordo com determinados símbolos de conexão. Esta figura é emendada com _. Os campos preenchidos também são adicionados simultaneamente.
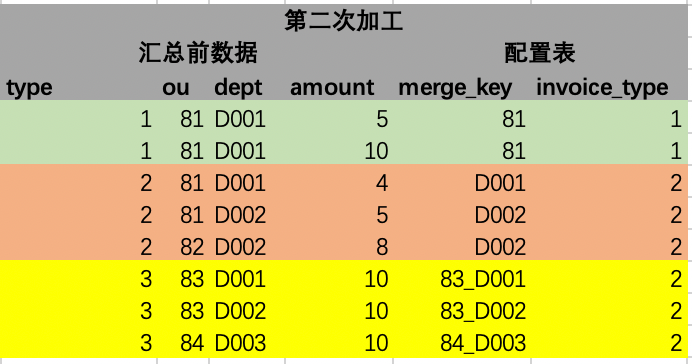
3. Resumo dos dados
Depois que os dados de correspondência de regras são processados, só precisamos resumir o campo merge_key processado. O mecanismo de resumo só precisa seguir o campo de resumo fixo (o exemplo aqui é o campo merge_key após o processamento da segunda etapa), e a lógica de resumo é Ele pode ser solidificado e apenas um SQL geral é necessário para implementar o resumo de todos os tipos de despesas, e o resultado final do resumo é gerado.
4. Resultados resumidos
Os dados agregados podem manter os mesmos resultados que os dados agregados através da tecnologia original e, ao mesmo tempo, alguns campos comuns podem ser preenchidos. Conforme mostrado na figura abaixo, as 2 linhas verdes dos dados de origem são resumidas por ou e se tornam 1 linha na tabela de resultados; as 3 linhas laranja dos dados de origem são resumidas por dept e se tornam 2 linhas na tabela de resultados; a fonte amarela os dados são resumidos pelos campos ou e dept. O resumo passa a ter 3 linhas.

Finalmente, escreva os resultados resumidos de volta no MySQL.
6. Pensamento prático de processos e avaliação de efeitos
1. Durante o processo de verificação do ambiente de teste, a tabela de teste e a tabela online têm níveis numéricos diferentes. Ao entrar online pela primeira vez, a leitura dos dados é extremamente lenta. Como o Spark lê uma única tabela muito rapidamente, a eficiência da leitura de dados de subbancos de dados e subtabelas cai drasticamente.Aqui, um método multithreading é usado para ler os dados não resumidos que atendem às condições e, finalmente, resume um grande conjunto.
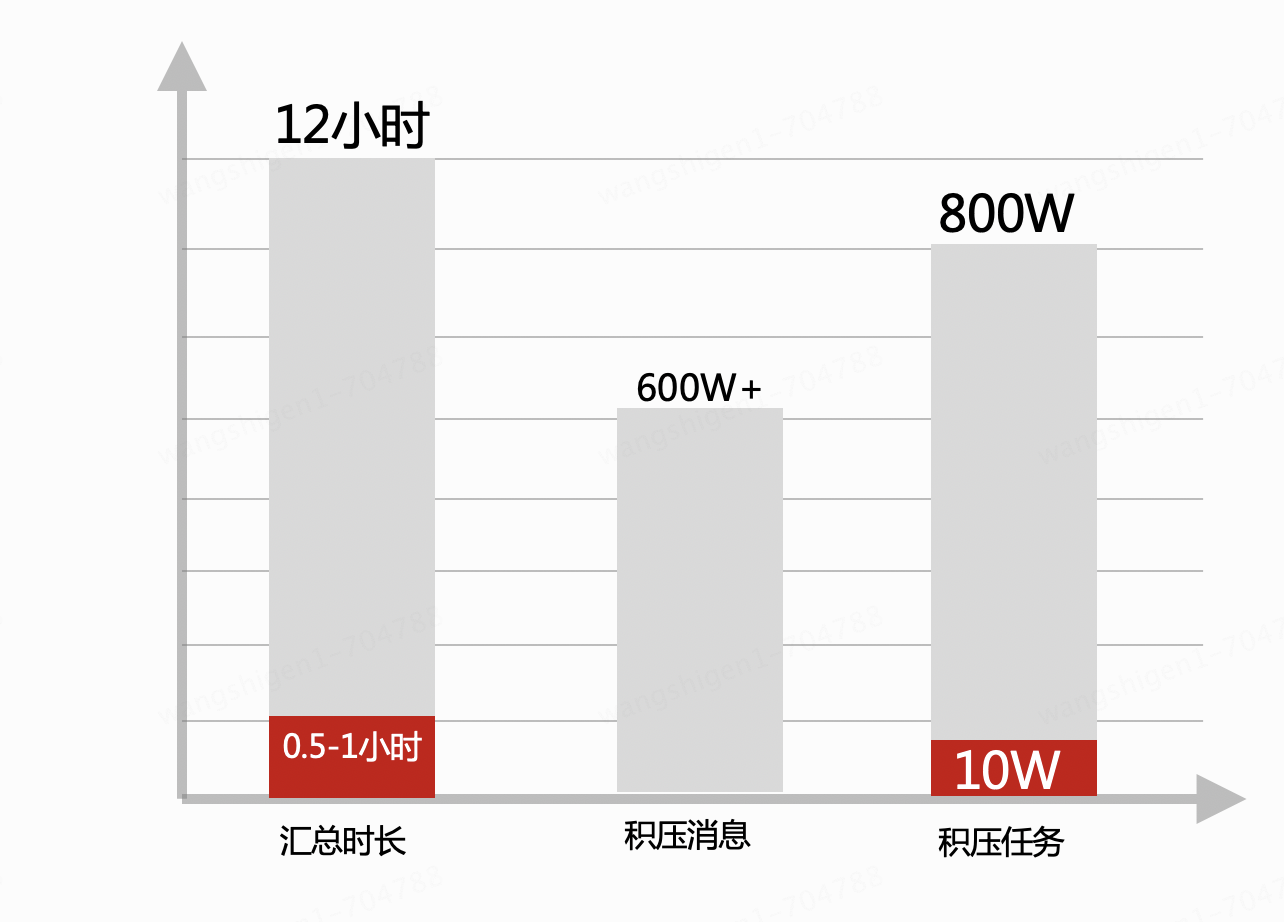
2. Depois de ficar on-line e funcionar de forma estável por um período de tempo, o gráfico de comparação de desempenho mostra que, ao eliminar o grupo por operação no MySQL, o tempo de resumo foi reduzido, o desempenho do banco de dados melhorou e a capacidade de processar mensagens e as tarefas assíncronas também melhoraram e afetaram a situação geral.
3. Quando novos requisitos de resumo estiverem online no futuro, a nova função de resumo de dimensão poderá ser implementada por meio de configuração, o que simplifica o trabalho de pesquisa e desenvolvimento e melhora a pontualidade da entrega da demanda. Há também desvantagens: atualmente, os campos das dimensões de resumo devem ser retirados da tabela principal, pois o Spark só lê a tabela principal ao ler os dados de negócios e não lê a tabela estendida. Se você estiver confiante sobre a qualidade dos dados da tabela Hive no futuro, poderá alterá-la para spark para ler diretamente a tabela Hive ou ler de es, ck e outras bibliotecas.
4. Através da introdução da estrutura Spark, o grande resumo do banco de dados é alterado de online para offline, o que alivia a pressão sobre o banco de dados. Depois que o desempenho do banco de dados é melhorado, a eficácia do faturamento também é melhorada. Também aumenta a estabilidade do o sistema e melhora a experiência do fornecedor.
Autor: Wang Shigen
Fonte: JD Cloud Developer Community Por favor, indique a fonte ao reimprimir
npm é abusado - alguém enviou mais de 700 vídeos de fatias de Wulin Gaiden "Linux China" A comunidade de código aberto anunciou que encerrará as operações A Microsoft formou uma nova equipe para ajudar a reescrever a biblioteca principal do Windows com o assistente de IA incluído Rust JetBrain causou insatisfação do usuário Deutsche Bahn está recrutando pessoas familiarizadas com MS - administradores de TI de DOS e Windows 3.11 VS Code 1.86 fará com que a função de desenvolvimento remoto fique indisponível. FastGateway: um gateway que pode ser usado para substituir o Nginx. Visual Studio Code 1.86 é lançado . Sete departamentos, incluindo o O Ministério da Indústria e Tecnologia da Informação emitiu em conjunto um documento: Desenvolva o sistema operacional da próxima geração e promova a tecnologia de código aberto. , Construindo um ecossistema de código aberto Lançado o Windows Terminal Preview 1.20