Índice de artigos da série
代码:https://jumpat.github.io/SAGA.
论文:https://jumpat.github.io/SAGA/SAGA_paper.pdf
来源:上海交大和华为研究院
Diretório de artigos
Resumo
A tecnologia de segmentação 3D interativa é de grande importância na compreensão e manipulação de cenas 3D e é uma tarefa digna de atenção. No entanto, os métodos existentes enfrentam desafios para alcançar segmentação multigranular refinada ou enfrentam sobrecarga computacional substancial, inibindo a interação em tempo real. Neste artigo, apresentamos Segmented Arbitrary 3D Gassin (SAGA), um novo método de segmentação 3D interativo que combina perfeitamente modelos de segmentação 2D com 3D Gaussian Splatting (3DGS). O SAGA incorpora efetivamente os resultados de segmentação 2D multigranularidade gerados pelo modelo de segmentação em recursos de pontos gaussianos 3D por meio de treinamento de contraste bem projetado . A avaliação experimental demonstra o desempenho competitivo. Além disso, o SAGA pode completar a segmentação 3D em milissegundos, também implementa segmentação multigranular e se adapta a vários sinais, incluindo pontos, grafites e máscaras 2D.
I. Introdução
A segmentação interativa tridimensional tem atraído ampla atenção de pesquisadores devido às suas aplicações potenciais em campos como manipulação de cenas, rotulagem automática e realidade virtual. Métodos anteriores [13, 25, 46, 47 Decomposição de nerf, campos de fusão de recursos neurais, etc.] promovem principalmente recursos visuais bidimensionais no espaço tridimensional por meio de campos de recursos de treinamento para simular modelos visuais auto-supervisionados [4, 39] Extraído recursos 2D de visualização múltipla. A similaridade de características tridimensionais é então usada para medir se dois pontos pertencem ao mesmo objeto. Essa abordagem é rápida devido ao seu pipeline de segmentação simples, mas ao custo da granularidade da segmentação grosseira devido à falta de mecanismos para analisar as informações incorporadas nos recursos (por exemplo, decodificadores de segmentação). Em contraste, outro paradigma [5: Segmentar qualquer coisa em 3D com nerfs] melhora o modelo básico de segmentação 2D para um modelo 3D, projetando diretamente resultados de segmentação 2D de granulação fina e multivisualização em uma grade de máscara 3D. Embora esse método possa produzir resultados de segmentação precisos, sua grande sobrecarga de tempo limita a interatividade devido à necessidade de executar o modelo subjacente e renderizar várias vezes.
A discussão acima revela o dilema dos paradigmas existentes em alcançar eficiência e precisão, e aponta dois fatores que limitam o desempenho dos paradigmas existentes. Primeiro, os campos de radiação implícitos empregados pelos métodos anteriores [5, 13] dificultam a segmentação eficaz : o espaço tridimensional deve ser atravessado para recuperar um objeto tridimensional. Em segundo lugar, ao utilizar um descodificador de segmentação bidimensional, a qualidade da segmentação é elevada, mas a eficiência é baixa.
O Splatting gaussiano tridimensional (3DGS) é capaz de renderização de alta qualidade e em tempo real : ele usa um conjunto de distribuições gaussianas de cores tridimensionais para representar uma cena tridimensional. A média dessas distribuições gaussianas representa sua posição no espaço tridimensional, de modo que o 3DGS pode ser visto como uma nuvem de pontos que ajuda a contornar o processamento extensivo de espaços tridimensionais enormes, muitas vezes vazios, e fornece antecedentes tridimensionais explícitos ricos. Com esta estrutura semelhante a uma nuvem de pontos, o 3DGS não apenas alcança uma renderização eficiente, mas também se torna um candidato ideal para tarefas de segmentação.
Com base no 3DGS, propusemos Segment Any 3D GAussians (SAGA) : extrair os recursos de segmentação refinada do modelo de segmentação 2D (ou seja, SAM) em um modelo 3D Gaussiano, com foco na atualização dos recursos visuais 2D para 3D e na obtenção de Fine segmentação 3D granulada . Além disso, evita múltiplas inferências do modelo de segmentação 2D. A destilação é implementada usando SAM para extrair máscaras automaticamente e treinar recursos tridimensionais de distribuição gaussiana. Durante a inferência, uma dica de entrada é usada para gerar um conjunto de consultas, que são então usadas para recuperar a Gaussiana desejada por meio de correspondência eficiente de recursos . O método permite segmentação 3D refinada em milissegundos e oferece suporte a uma variedade de dicas, incluindo pontos, rabiscos e máscaras.
2. Trabalho relacionado
1. Segmentação 2D baseada em dicas
Inspirado nas tarefas de PNL e nos avanços recentes na visão computacional, o SAM é capaz de retornar máscaras de segmentação, dadas dicas de entrada para alvos de segmentação em uma imagem específica. Um modelo semelhante ao SAM é o SEEM [55], que também mostra impressionantes capacidades de segmentação de vocabulário aberto. Antes deles, a tarefa mais intimamente relacionada à segmentação 2D com pistas era a segmentação interativa de imagens, que foi explorada por muitos estudos.
2. Atualize o modelo visual básico 2D para 3D
Recentemente, os modelos fundamentais de visão 2D experimentaram um forte crescimento. Em contraste, os modelos básicos de visão 3D não tiveram um desenvolvimento semelhante, principalmente devido à falta de dados. Obter e anotar dados 3D é significativamente mais desafiador do que outros dados 2D . Para resolver este problema, os pesquisadores tentaram atualizar o modelo básico 2D para 3D [8, 16, 20, 22, 28, 38, 51, 53]. Uma tentativa notável é LERF [22], que treina um modelo de linguagem visual em um campo de recurso (ou seja, CLIP [39]) e um campo radial. Este paradigma é útil para localizar objetos em um campo de radiação com base em pistas linguísticas , mas tem um desempenho fraco na segmentação 3D precisa, especialmente quando confrontado com vários objetos semanticamente semelhantes. Os métodos restantes concentram-se principalmente em nuvens de pontos. Ao usar a pose da câmera para associar a nuvem de pontos 3D à imagem de visualização múltipla 2D, os recursos extraídos do modelo base 2D podem ser projetados na nuvem de pontos 3D. Esta integração é semelhante ao LERF, mas a aquisição de dados é mais cara que os métodos baseados em campo de radiação.
3. Segmentação tridimensional em campos de radiação
Inspirados pelo sucesso do NeRF, muitos estudos exploraram a segmentação tridimensional nele. Zhi et al.[54] propuseram o SemanticNeRF, demonstrando o potencial do NeRF na propagação e refinamento semântico. NVOS [40] apresenta um método interativo para selecionar objetos 3D do NeRF, treinando uma percepção leve de múltiplas camadas usando recursos 3D personalizados (MLP). Ao usar modelos 2D auto-supervisionados, como N3F [47], DFF [25], LERF [22] e ISRF [13], os mapas de recursos 2D são gerados pelo treinamento de campos de recursos adicionais que podem imitar diferentes mapas de recursos 2D, atualização 2D recursos visuais para 3D. NeRF-SOS [9] usa perda de destilação de correspondência [17] para refinar semelhanças de recursos 2D em recursos 3D. Entre esses métodos baseados em recursos visuais 2D, a segmentação 3D pode ser alcançada comparando recursos 3D incorporados no domínio de recursos, o que parece ser eficaz. No entanto, a qualidade de segmentação de tais métodos é limitada porque a informação incorporada em características visuais de alta dimensão não pode ser totalmente explorada quando se baseia apenas na distância euclidiana ou na distância do cosseno. Existem alguns outros métodos de segmentação de instância e segmentação semântica [2, 12, 19, 30, 35, 44, 48, 52] combinados com campos de radiação.
Os dois métodos mais intimamente relacionados ao nosso SAGA são ISRF [13] e SA3D [5]. O primeiro segue o paradigma de treinar um campo de recursos para modelar recursos visuais 2D de múltiplas visualizações. Portanto, é difícil distinguir objetos diferentes (especialmente partes de objetos) com semântica semelhante . Este último consulta iterativamente o SAM para obter os resultados da segmentação bidimensional e os projeta na grade de máscara para segmentação tridimensional. Possui boa qualidade de segmentação, mas o pipeline de segmentação é complexo, resultando em alto consumo de tempo e inibindo a interação com os usuários.
3. Metodologia
1. Respingos Gaussianos 3D (3DGS)
Como o mais recente desenvolvimento de campos de radiação, 3DGS [21] usa distribuição gaussiana tridimensional treinável para representar cenas tridimensionais e propõe um algoritmo de treinamento e renderização de rasterização diferenciável eficaz. Dado um conjunto de dados de treinamento I de imagens 2D multivisualização com poses de câmera, 3DGS aprende um conjunto de Gaussianas de cores 3D G = {g 1 , g 2 ,…, g N }, onde N representa o número de Gaussianas 3D na cena. A média de cada distribuição gaussiana representa sua posição no espaço tridimensional e a covariância representa a escala. Portanto, o 3DGS pode ser considerado uma nuvem de pontos. Dada uma pose de câmera específica, o 3DGS projeta uma Gaussiana tridimensional em duas dimensões e então calcula a cor C de um pixel misturando um conjunto de Gaussianas ordenadas N que se sobrepõem ao pixel:
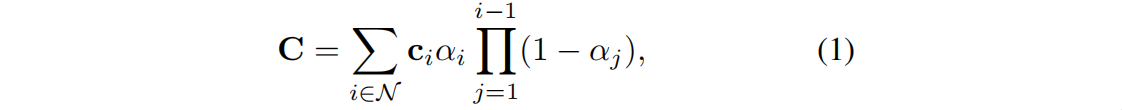
onde ci é a cor de cada distribuição gaussiana, α é obtido calculando uma distribuição gaussiana bidimensional com covariância Σ multiplicada por uma opacidade aprendida por gaussiana. A partir da equação (1) podemos aprender a linearidade do processo de rasterização: a cor renderizada por um pixel é uma soma ponderada das Gaussianas envolvidas . Este recurso garante o alinhamento dos recursos 3D com as propriedades de renderização 2D.
SAM pega uma imagem I e um conjunto de pistas P como entrada e gera a máscara de segmentação bidimensional correspondente M, a saber:
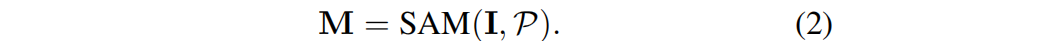
2. Quadro geral
Conforme mostrado na Figura 2, dado um modelo 3DGS G pré-treinado e seu conjunto de treinamento, primeiro usamos o codificador do SAM para extrair os recursos bidimensionais de cada imagem I∈R H×W : F I SAM ∈R Csam× H × W e um conjunto de máscaras multi-granularidade M I SAM ; então, de acordo com a máscara extraída, recursos de baixa dimensão f g ∈ R C de cada Gaussiano G são treinados para agregar informações de segmentação multi-granularidade consistentes de visão cruzada (( C representa a dimensão do recurso, o tamanho padrão é 32. Para melhorar ainda mais a compactação dos recursos, obtemos correspondências pontuais das máscaras extraídas e as extraímos como recursos (ou seja, perda de correlação).
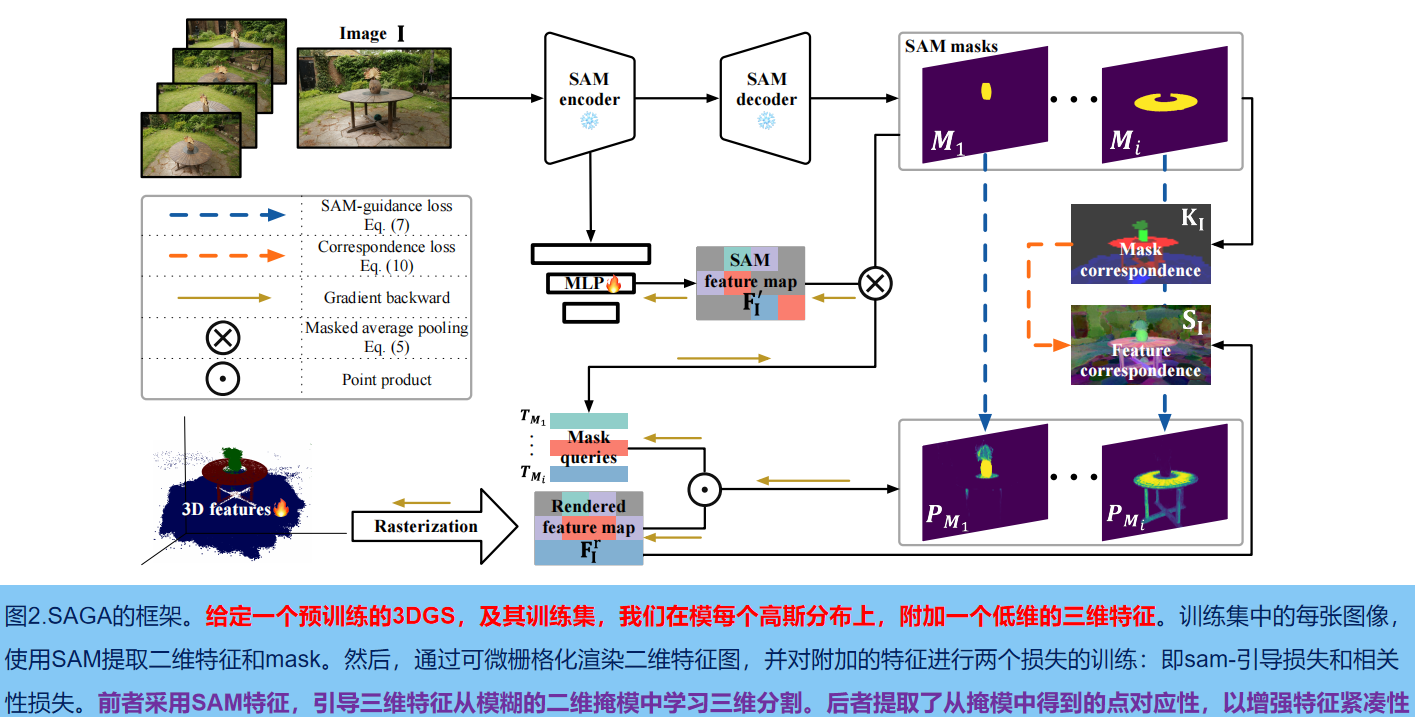
No estágio de inferência, para a visão específica da pose da câmera v 2 , um conjunto de consultas Q é gerado de acordo com o prompt de entrada p e, em seguida, essas consultas são usadas para realizar uma correspondência eficaz de recursos com os recursos aprendidos para recuperar o tridimensional Distribuição gaussiana do alvo correspondente . Além disso, introduzimos uma operação de pós-processamento eficiente para refinar a distribuição gaussiana 3D recuperada, explorando o forte anterior 3D fornecido pela estrutura semelhante a nuvem de pontos do 3DGS .
3. Treinamento de recursos gaussianos
Imagem de treinamento I com pose v, renderize o mapa de recursos correspondente F usando o modelo 3DGS pré-treinado g:
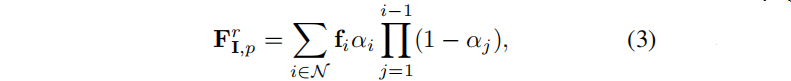
Entre eles, N é um conjunto de distribuições gaussianas ordenadas sobrepostas. Durante a fase de treinamento, exceto os recursos recém-anexados, todas as outras propriedades do Gaussiano G tridimensional (como média, covariância e opacidade) são congeladas.
3.1 Perda de orientação do SAM
A máscara 2D MI extraída automaticamente pelo SAM é complexa e confusa (ou seja, um ponto no espaço 3D pode ser segmentado em diferentes objetos/partes em diferentes visualizações). Este sinal de supervisão ambíguo representa um enorme desafio para o treinamento de recursos 3D do zero. Para resolver este problema , usamos recursos gerados pelo SAM como orientação. Conforme mostrado na Figura 2: Use MLP φ para projetar os recursos SAM no mesmo espaço de baixa dimensão que os recursos tridimensionais :
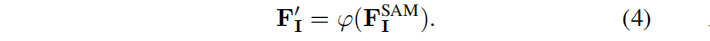
Então, para cada máscara M extraída de M I SAM , após uma operação de pooling médio, uma consulta correspondente T M ∈ R C é obtida :
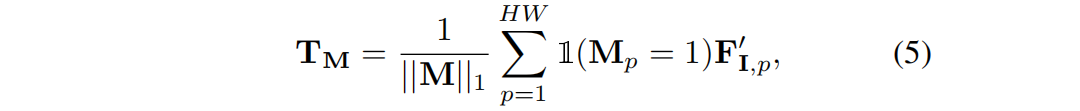
Entre eles, 'oco 1' é a função do indicador. Em seguida, use TM para segmentar o mapa de recursos renderizado F I r por softmaxed :
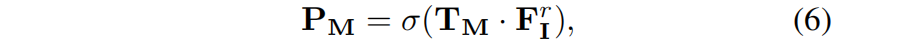
Entre eles, σ representa a função sigmóide em nível de elemento. A perda de orientação do SAM é definida como: a entropia cruzada binária entre o resultado da segmentação P M e a máscara extraída do SAM correspondente M:
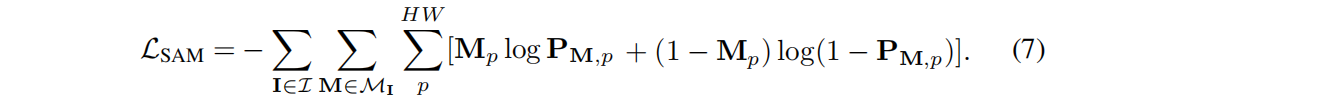
3.2 Perda de Correspondência
Na prática, descobrimos que os recursos aprendidos da perda guiada por SAM não são suficientemente compactos, reduzindo a qualidade da segmentação com base em diferentes sinais (consulte o estudo de ablação na Seção 4). Inspirados nos métodos contrastivos anteriores de destilação por correspondência [9, 17], introduzimos a perda de correspondência para resolver este problema.
Conforme mencionado anteriormente, para cada imagem I de altura H e largura W no conjunto de treinamento I, o SAM é usado para extrair um conjunto de máscaras M I . Considerando dois pixels p1, p2 em I, eles podem pertencer a muitas máscaras em M I. Deixei M I p1 e M I p2 representarem respectivamente as máscaras às quais pertencem os pontos de pixel p 1 e p 2 . Se seu IoU for maior, os recursos de pixel deverão ser semelhantes. Portanto, o coeficiente de correlação K I (p 1 , p 2 ) da máscara :
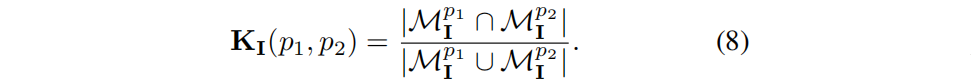
A correlação de recursos SI ( p 1 , p 2 ) entre pixels p 1 , p 2 é definida como a semelhança de cosseno entre seus recursos renderizados:
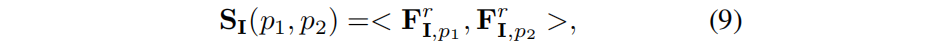
perda de correspondência (se dois pixels nunca pertencerem à mesma parte, reduza a similaridade de recursos definindo o valor 0 em K I como −1.):
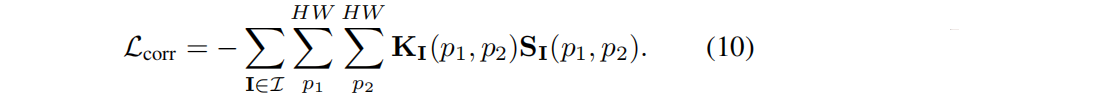
4. Inferência
Embora o treinamento seja realizado em mapas de recursos renderizados , a linearidade da operação de rasterização (Equação 3) garante que os recursos no espaço tridimensional estejam alinhados com os recursos renderizados no plano da imagem . Portanto, recursos de renderização 2D podem ser usados para obter segmentação gaussiana tridimensional. Este recurso oferece compatibilidade ao SAGA com vários prompts. Além disso, também apresentamos um algoritmo eficaz de pós-processamento anterior 3D baseado em 3DGS.
4.1 Prompts baseados em pontos
Para o mapa de recursos renderizado F v r de uma visão específica v , os recursos correspondentes são recuperados diretamente para gerar consultas para pontos de amostra positivos e negativos. Deixe Q v p e Q v n representar N p consultas positivas e consultas negativas respectivamente. Para o gaussiano g tridimensional, sua pontuação positiva S g p é definida como a máxima similaridade de cosseno entre seu recurso e a consulta positiva, ou seja, max{ < f g , Q p > |Q p ∈Q v p } . Da mesma forma, a fração negativa S g n é definida como max{ < f g , Q n > |Q n ∈Q v n } . Somente quando S g p > S g n a Gaussiana tridimensional pertence ao alvo G t . Para filtrar ainda mais a distribuição gaussiana ruidosa, o limite adaptativo τ é definido como uma fração positiva, ou seja, g∈G t somente se S g p > τ . τ é definido como a média das maiores pontuações positivas. Observe que esta filtragem pode resultar em muitas amostras FN (amostras positivas não reconhecidas), mas isso pode ser resolvido pelo pós-processamento na Seção 4.5.
4.2 Dicas baseadas em máscara e rabisco
Simplesmente tratar dicas densas como múltiplos pontos resultará em uma enorme sobrecarga de memória da GPU. Portanto, usamos o algoritmo K-means para extrair consultas positivas e negativas de dicas densas: Q v p e Q v n . Como regra geral, o número de clusters para Kmeans é 5 (pode ser ajustado de acordo com a complexidade do objeto alvo).
4.3 Prompts baseados em SAM
As dicas anteriores serão obtidas do mapa de recursos renderizado. Devido à perda de orientação do SAM, podemos usar diretamente os recursos SAM de baixa dimensão F' v para gerar consultas: primeiro insira o prompt no SAM para gerar resultados precisos de segmentação 2D M v ref . Usando esta máscara 2D, primeiro obtemos uma máscara Q de consulta com pooling médio de máscara e usamos esta consulta para segmentar o mapa de recursos renderizado 2D F v r para obter uma máscara de segmentação 2D temporária M v temp e, em seguida, comparamos com M v ref . Se a interseção dos dois ocupar a maior parte da referência M v (90% por padrão), a máscara Q v será aceita como a consulta. Caso contrário, usamos o algoritmo K-means para extrair outro conjunto de consultas Q v kmeans dos recursos SAM de baixa dimensão F′ v dentro da máscara . Esta estratégia é adotada porque o alvo de segmentação pode conter muitos componentes que não podem ser capturados simplesmente pela aplicação de pooling médio mascarado.
Depois de obter o conjunto de consultas Q v SAM = {Q v mask } ou Q v SAM = Q v kmeans , o processo subsequente é o mesmo do prompt anterior. Usamos produto escalar em vez de similaridade de cosseno como medida de segmentação para acomodar a perda guiada por SAM. Para um gaussiano g tridimensional, sua pontuação positiva S g p é o produto escalar máximo calculado pela seguinte consulta:
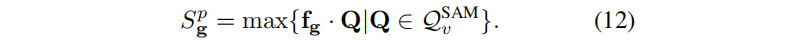
Se a pontuação positiva for maior que outro limiar adaptativo τ SAM , então o Gaussiano g tridimensional pertence ao alvo de segmentação G t , que é a soma da média e do desvio padrão de todas as pontuações.
5. Pós-processamento baseado em anterior tridimensional
Existem dois problemas principais na segmentação inicial G t de Gaussianos 3D : (i) o problema de Gaussianos ruidosos redundantes, (ii) a omissão de alvos . Para resolver este problema, utilizamos técnicas tradicionais de segmentação de nuvens de pontos, incluindo filtragem estatística e crescimento de região. Para segmentação baseada em dicas de pontos e grafites, a filtragem estatística é usada para filtrar a distribuição gaussiana do ruído. Para prompts de máscara e prompts baseados em SAM, a máscara 2D é projetada em G t para obter um conjunto de funções gaussianas validadas, que são projetadas em G para excluir funções gaussianas desnecessárias. A função gaussiana efetiva resultante pode ser usada como semente para o algoritmo de crescimento de região. Finalmente, um método de crescimento de região baseado em consulta de esfera é adotado para recuperar todas as funções gaussianas necessárias para o alvo do modelo original G.
4.1 Filtragem Estatística Filtragem Estatística
A distância entre duas distribuições gaussianas pode indicar se elas pertencem ao mesmo alvo. A filtragem estatística primeiro usa o algoritmo |-vizinho mais próximo (KNN) para calcular o G t \sqrt{Gt} mais próximo de cada distribuição gaussiana no resultado da segmentação GtGtA distância média de uma distribuição gaussiana. Posteriormente, calculamos a média (µ) e o desvio padrão (σ) dessas distâncias médias para todas as gaussianas em G t . Removemos então as distribuições gaussianas cuja distância média excede µ+σ e obtemos G t' .
4.2 Filtragem baseada no crescimento regional
A máscara 2D da sugestão de máscara ou a sugestão baseada em sam pode ser usada como uma prévia para localizar com precisão o alvo : primeiro, a máscara é projetada no resultado gaussiano grosseiro Gt , resultando em um subconjunto gaussiano, denotado como Gc . Posteriormente, para cada g gaussiano dentro de G c , calcula-se a distância euclidiana d g do vizinho mais próximo no subconjunto :
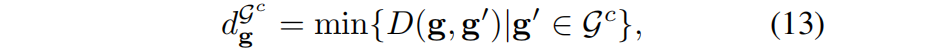
Na fórmula, D() representa a distância euclidiana. Então, gaussianas adjacentes (distâncias menores que a distância máxima do vizinho mais próximo no conjunto G c ) são adicionadas iterativamente ao resultado gaussiano grosseiro G t . Essa distância é formalizada como: Observe que, embora as dicas pontuais e de rabisco também possam localizar aproximadamente o alvo, aumentar a área com base nelas é demorado. Portanto, só usamos quando há máscara.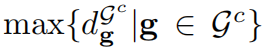
4.3 Crescimento baseado em Ball Query
A saída de segmentação filtrada G′ t pode não ter todas as Gaussianas do alvo. Para resolver este problema, usamos o algoritmo de consulta de bola para recuperar todas as Gaussianas necessárias de todas as Gaussianas G. Especificamente, isto é conseguido examinando uma vizinhança esférica de raio r. As distribuições gaussianas localizadas dentro desses limites esféricos em G são então agregadas no resultado final da segmentação G s . O raio r é definido como a distância máxima do vizinho mais próximo em G' t :

4. Experimente
1.Conjunto de dados
Experimentos quantitativos, usando seleção de objetos volumétricos neurais (NVOS), conjunto de dados SPIn-NeRF [33]. O conjunto de dados NVOS é baseado no conjunto de dados LLFF, que inclui vários cenários futuros. Para cada cena, o conjunto de dados NVOS fornece uma visualização de referência com rabiscos e uma visualização de destino anotada com máscaras de segmentação 2D. Da mesma forma, o conjunto de dados SPIn-NeRF [33] também anota manualmente alguns dados com base no conjunto de dados NeRF amplamente utilizado [11, 24, 26, 31, 32]. Além disso, também anotamos alguns objetos na cena LERF-Figurine usando SA3D para demonstrar o melhor compromisso do SAGA em termos de eficiência e qualidade de segmentação.
Para análise qualitativa foram utilizados o conjunto de dados LLFF, MIP-360, T&T e o conjunto de dados LERF.
2. Experimento quantitativo
NVOS : Segue SA3D [5] para processar graffiti fornecido pelo conjunto de dados NVOS para atender aos requisitos do SAM. Conforme mostrado na Tabela 1, o SAGA é igual ao SOTA SA3D anterior e supera significativamente os métodos anteriores baseados em imitação de recursos (ISRF e SGISRF), o que demonstra suas capacidades de segmentação refinada.
SPIn-NeRF : A avaliação segue o SPIn-NeRF, que especifica uma visualização com uma máscara de verdade 2D e propaga essa máscara para outras visualizações para verificar a precisão da máscara. Esta operação pode ser considerada um prompt de mascaramento. Os resultados são mostrados na Tabela 2. MVSeg usa o método de segmentação de vídeo [4] para segmentar imagens multivisualização, e o SA3D consulta automaticamente o modelo básico de segmentação bidimensional da imagem renderizada na visualização de treinamento. Ambos exigem a proposta muitas vezes de um modelo de segmentação 2D. Notavelmente, SAGA mostra desempenho comparável a eles quase um milésimo das vezes. Observe que a ligeira degradação é causada pela geometria abaixo do ideal aprendida pelo 3DGS.
Comparação com SA3D . Execute o SA3D com base na cena LERF-futtes para obter um conjunto de anotações para muitos objetos. Posteriormente, usamos o SAGA para segmentar os mesmos objetos e verificar o IoU e o custo de tempo de cada objeto. Os resultados são mostrados na Tabela 3, e também fornecemos resultados de visualização comparando com SA3D. É importante notar que a resolução de treinamento do SAGA é muito maior devido ao enorme custo de memória GPU do SA3D. Isso mostra que a SAGA pode obter ativos 3D de maior qualidade em menos tempo. Mesmo levando em consideração o tempo de treinamento (~10 minutos por cena), o tempo médio de segmentação por objeto no SAGA é muito menor que o do SA3D.

3. Experimento qualitativo

4. Casos de falha
Na Tabela 2, o SAGA apresenta desempenho abaixo do ideal em comparação aos métodos anteriores. Isso ocorre porque a segmentação da cena da sala LLFF falha, revelando as limitações do SAGA. Mostramos na Figura 4 a média das funções gaussianas coloridas, que pode ser vista como uma espécie de nuvem de pontos. SAGA é suscetível à reconstrução geométrica insuficiente de modelos 3DGS . Conforme mostrado na caixa vermelha, as Gaussianas da mesa são significativamente esparsas, com as Gaussianas representando a superfície da mesa flutuando abaixo da superfície real. Para piorar a situação, a gaussiana na cadeira está muito próxima da pessoa que está na mesa. Estes problemas não só dificultam a aprendizagem de características 3D discriminativas, mas também afectam a eficácia do pós-processamento. Acreditamos que melhorar a fidelidade geométrica dos modelos 3DGS pode melhorar este problema.

d \sqrt{d}d 1 0,24 \ frac {1}{0,24}0,241 xˉ\bar{x}xˉ x ^ \hat{x}x^ x ~ \tilde{x}x~ ϵ \épsilonϵ
Resumir
提示:这里对文章进行总结:
Por exemplo: Vou falar sobre o que foi dito acima hoje: este artigo apresenta apenas brevemente o uso de pandas, e pandas fornece um grande número de funções e métodos que nos permitem processar dados de forma rápida e conveniente.