Índice
Editar 2.1 Status do Operador
2.1.2 Estado da Lista de Sindicatos (UnionListState)
2.1.3 Estado de transmissão (BroadcastState)
2.2.3 Estado do mapa (MapState)
2.2.4 Estado Redutor (ReduzindoEstado)
2.2.6 Estado do Tempo de Vida (TTL)
3.1 Classificação do back-end de estado (HashMapStateBackend/RocksDB)
3.1.2 Back-end de estado RocksDB incorporado (EmbeddedRocksDBStateBackend)
3.2 Como escolher o backend de status correto
3.3 Configuração do back-end de status
1. Visão geral do status
1.1 Operador apátrida
O resultado da saída pode ser convertido diretamente de acordo com a entrada atual.Esse tipo de nariz é o operador sem estado, como map, flatMap, filter
1.2 Operadores com estado
Além do processamento atual, é necessário processamento adicional para obter os resultados do cálculo. Como operadores de agregação, operadores de janela, etc.
2. Classificação de status
Flink tem dois estados: Estado Gerenciado e Estado Bruto . O estado gerenciado é gerenciado uniformemente pelo Flink. Uma série de problemas como acesso ao armazenamento de estado, recuperação de falhas e reorganização são todos implementados pelo Flink. Precisamos apenas ajustar a interface; enquanto o estado original é personalizado, o que equivale a abrir um pedaço de memória., precisamos gerenciá-lo nós mesmos para obter serialização de status e recuperação de falhas.
Normalmente usamos o estado gerenciado do Flink para atender às nossas necessidades.
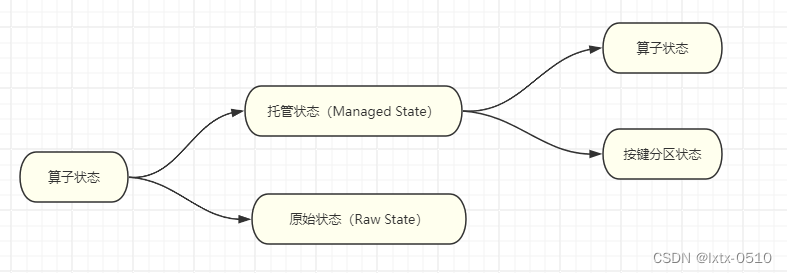
2.1 Situação do operador
Uma tarefa do operador será dividida em múltiplas subtarefas paralelas para execução de acordo com o grau de paralelismo, e diferentes subtarefas ocuparão diferentes slots de tarefas. Como diferentes slots estão fisicamente isolados em termos de recursos computacionais, o estado que o Flink pode gerenciar não pode ser compartilhado entre tarefas paralelas. Cada estado é válido apenas para a instância da subtarefa atual.
Estado do Operador é o estado definido em uma instância paralela do operador e seu escopo é limitado à tarefa atual do operador.
Os cenários reais de aplicação do estado do operador não são tantos quanto o Keyed State . Geralmente é usado em operadores como Source ou Sink que estão conectados a sistemas externos ou em cenários onde não há nenhuma definição de chave. Por exemplo, o conector Kafka do Flink usa status de operador.
O estado do operador também suporta diferentes tipos de estrutura, existem três tipos principais: ListState, UnionListState e BroadcastState.
2.1.1 Estado da lista (ListState)
A diferença do estado de lista no estado chaveado é que no contexto do estado do operador, o estado não é processado separadamente por chave, portanto, apenas uma "lista" (lista) é retida em cada subtarefa paralela, que é a coleção atual. de todos os itens de status em uma subtarefa paralela. Os itens de status na lista são os mais granulares que podem ser reatribuídos e são completamente independentes uns dos outros.
Prática de caso: Calcule o número de dados no operador de mapa.
public class OperatorListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env
.socketTextStream("hadoop102", 7777)
.map(new MyCountMapFunction())
.print();
env.execute();
}
// TODO 1.实现 CheckpointedFunction 接口
public static class MyCountMapFunction implements MapFunction<String, Long>, CheckpointedFunction {
private Long count = 0L;
private ListState<Long> state;
@Override
public Long map(String value) throws Exception {
return ++count;
}
/**
* TODO 2.本地变量持久化:将 本地变量 拷贝到 算子状态中,开启checkpoint时才会调用
*
* @param context
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("snapshotState...");
// 2.1 清空算子状态
state.clear();
// 2.2 将 本地变量 添加到 算子状态 中
state.add(count);
}
/**
* TODO 3.初始化本地变量:程序启动和恢复时, 从状态中 把数据添加到 本地变量,每个子任务调用一次
*
* @param context
* @throws Exception
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("initializeState...");
// 3.1 从 上下文 初始化 算子状态
state = context
.getOperatorStateStore()
.getListState(new ListStateDescriptor<Long>("state", Types.LONG));
// 3.2 从 算子状态中 把数据 拷贝到 本地变量
if (context.isRestored()) {
for (Long c : state.get()) {
count += c;
}
}
}
}
}2.1.2 Estado da Lista de Sindicatos (UnionListState)
Semelhante a ListState, Union ListState também representa o estado como uma lista. A diferença entre ele e o estado de lista regular é que o estado é alocado de forma diferente quando o paralelismo do operador é dimensionado e ajustado.
O foco do UnionListState é “união”. Ao ajustar o paralelismo, os estados de lista regulares são pesquisados para distribuir itens de estado, enquanto os operadores que combinam estados de lista transmitem diretamente a lista completa de estados.
Se houver demasiados itens de estado na lista, geralmente não é recomendado utilizar a reorganização conjunta por razões de recursos e eficiência.
O uso é igual ao ListState, a diferença é: getUnionListState (new ListStateDescriptor<Long>("union-state", Types.LONG));
state = context
.getOperatorStateStore()
.getUnionListState(new ListStateDescriptor<Long>("union-state", Types.LONG));2.1.3 Estado de transmissão (BroadcastState)
Às vezes, queremos que as subtarefas paralelas do operador mantenham o mesmo estado "global" para configuração unificada e definições de regras.
Prática de caso: Um alarme é enviado quando o nível da água excede um limite especificado e o limite pode ser modificado dinamicamente .
public class OperatorBroadcastStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 数据流
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
// 配置流(用来广播配置)
DataStreamSource<String> configDS = env.socketTextStream("hadoop102", 8888);
// TODO 1. 将 配置流 广播
MapStateDescriptor<String, Integer> broadcastMapState = new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT);
BroadcastStream<String> configBS = configDS.broadcast(broadcastMapState);
// TODO 2.把 数据流 和 广播后的配置流 connect
BroadcastConnectedStream<WaterSensor, String> sensorBCS = sensorDS.connect(configBS);
// TODO 3.调用 process
sensorBCS
.process(
new BroadcastProcessFunction<WaterSensor, String, String>() {
/**
* 数据流的处理方法: 数据流 只能 读取 广播状态,不能修改
* @param value
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processElement(WaterSensor value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
// TODO 5.通过上下文获取广播状态,取出里面的值(只读,不能修改)
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
Integer threshold = broadcastState.get("threshold");
// 判断广播状态里是否有数据,因为刚启动时,可能是数据流的第一条数据先来
threshold = (threshold == null ? 0 : threshold);
if (value.getVc() > threshold) {
out.collect(value + ",水位超过指定的阈值:" + threshold + "!!!");
}
}
/**
* 广播后的配置流的处理方法: 只有广播流才能修改 广播状态
* @param value
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception {
// TODO 4. 通过上下文获取广播状态,往里面写数据
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(broadcastMapState);
broadcastState.put("threshold", Integer.valueOf(value));
}
}
)
.print();
env.execute();
}
}2.2 Status da partição chave
Muitas operações com estado (como agregação e janelas) exigem que keyBy seja particionado primeiro por chave. Após o particionamento por chave, todos os cálculos realizados pela tarefa deverão ser válidos apenas para a chave atual, portanto os estados também deverão ser isolados uns dos outros de acordo com a chave.
Sua característica é bastante distinta, ou seja, utiliza a chave como espaço de isolamento.
Deve-se observar que o uso do Keyed State deve ser baseado em KeyedStream. Para um DataStream sem particionamento keyBy, mesmo que o operador de conversão implemente a classe de função rica correspondente, o Keyed State não pode ser acessado por meio do contexto de tempo de execução.
2.2.1 ValueState (ValueState)
public interface ValueState<T> extends State {
T value() throws IOException;
void update(T value) throws IOException;
}- Valor T(): obtém o valor do estado atual;
- update (valor T): atualiza o status. O valor do parâmetro passado é o valor do status a ser substituído.
Em uso específico, para que o contexto de tempo de execução saiba qual é o seu estado, também precisamos criar um "Descritor de Estado" (StateDescriptor) para fornecer informações básicas sobre o estado. Por exemplo, no código-fonte, o método de construção do descritor de estado de ValueState é o seguinte:
public ValueStateDescriptor(String name, Class<T> typeClass) {
super(name, typeClass, null);
}Requisitos do caso: Detectar o valor do nível de água de cada sensor. Se dois valores consecutivos de nível de água excederem 10, um alarme será emitido.
public class KeyedValueStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);
sensorDS.keyBy(r -> r.getId())
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
// TODO 1.定义状态
ValueState<Integer> lastVcState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// TODO 2.在open方法中,初始化状态
// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型
lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState", Types.INT));
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
// lastVcState.value(); // 取出 本组 值状态 的数据
// lastVcState.update(); // 更新 本组 值状态 的数据
// lastVcState.clear(); // 清除 本组 值状态 的数据
// 1. 取出上一条数据的水位值(Integer默认值是null,判断)
int lastVc = lastVcState.value() == null ? 0 : lastVcState.value();
// 2. 求差值的绝对值,判断是否超过10
Integer vc = value.getVc();
if (Math.abs(vc - lastVc) > 10) {
out.collect("传感器=" + value.getId() + "==>当前水位值=" + vc + ",与上一条水位值=" + lastVc + ",相差超过10!!!!");
}
// 3. 更新状态里的水位值
lastVcState.update(vc);
}
}
)
.print();
env.execute();
}2.2.2 Estado da lista (ListState)
Organize os dados que precisam ser salvos em forma de lista. Há também um parâmetro de tipo T na interface ListState<T>, que representa o tipo de dados na lista. ListState também fornece uma série de métodos para manipular o estado, e o uso é muito semelhante a uma lista geral.
- Iterable<T> get(): Obtém o status atual da lista e retorna um tipo iterável Iterable<T>;
- update(List<T> valores): passa uma lista de valores e sobrescreve diretamente o status;
- add(T value): Adiciona um valor de elemento à lista de status;
- addAll(List<T> valores): adiciona vários elementos à lista, passados como valores de lista.
Da mesma forma, o descritor de estado de ListState é chamado ListStateDescriptor e seu uso é exatamente o mesmo que ValueStateDescriptor.
Caso : Produza os 3 valores de nível de água mais altos para cada sensor
public class KeyedListStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);
sensorDS.keyBy(r -> r.getId())
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
ListState<Integer> vcListState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcListState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("vcListState", Types.INT));
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
// 1.来一条,存到list状态里
vcListState.add(value.getVc());
// 2.从list状态拿出来(Iterable), 拷贝到一个List中,排序, 只留3个最大的
Iterable<Integer> vcListIt = vcListState.get();
// 2.1 拷贝到List中
List<Integer> vcList = new ArrayList<>();
for (Integer vc : vcListIt) {
vcList.add(vc);
}
// 2.2 对List进行降序排序
vcList.sort((o1, o2) -> o2 - o1);
// 2.3 只保留最大的3个(list中的个数一定是连续变大,一超过3就立即清理即可)
if (vcList.size() > 3) {
// 将最后一个元素清除(第4个)
vcList.remove(3);
}
out.collect("传感器id为" + value.getId() + ",最大的3个水位值=" + vcList.toString());
// 3.更新list状态
vcListState.update(vcList);
// vcListState.get(); //取出 list状态 本组的数据,是一个Iterable
// vcListState.add(); // 向 list状态 本组 添加一个元素
// vcListState.addAll(); // 向 list状态 本组 添加多个元素
// vcListState.update(); // 更新 list状态 本组数据(覆盖)
// vcListState.clear(); // 清空List状态 本组数据
}
}
)
.print();
env.execute();
}
}2.2.3 Estado do mapa (MapState)
Salvar alguns pares de valores-chave como um estado completo pode ser considerado uma lista de mapeamentos de valores-chave.
MapState fornece métodos para operar o estado de mapeamento, que é muito semelhante ao uso de Map.
- UV get (UK key): passe uma chave como parâmetro e consulte o valor correspondente;
- put (chave do Reino Unido, valor UV): passe um par de valores-chave e atualize o valor correspondente à chave;
- putAll(Map<UK, UV> map): Adiciona todos os pares de valores-chave no mapa de mapeamento recebido ao estado de mapeamento;
- remove (chave do Reino Unido): Exclui o par chave-valor correspondente à chave especificada;
- boolean contém (chave do Reino Unido): Determine se a chave especificada existe e retorne um valor booleano.
Além disso, MapState também fornece métodos para obter informações relacionadas a todo o mapeamento;
- Iterable<Map.Entry<UK, UV>>entries(): obtém todos os pares de valores-chave no estado de mapeamento;
- Iterable<UK> keys(): Obtém todas as chaves no estado de mapeamento e retorna um tipo Iterable iterável;
- Iterable<UV> valores(): Obtém todos os valores (valor) no estado de mapeamento e retorna um tipo Iterable iterável;
- boolean isEmpty(): Determina se o mapeamento está vazio e retorna um valor booleano.
Requisitos do caso: Contar o número de ocorrências de cada valor de nível de água para cada sensor.
public class KeyedMapStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);
sensorDS.keyBy(r -> r.getId())
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
MapState<Integer, Integer> vcCountMapState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcCountMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Integer>("vcCountMapState", Types.INT, Types.INT));
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
// 1.判断是否存在vc对应的key
Integer vc = value.getVc();
if (vcCountMapState.contains(vc)) {
// 1.1 如果包含这个vc的key,直接对value+1
Integer count = vcCountMapState.get(vc);
vcCountMapState.put(vc, ++count);
} else {
// 1.2 如果不包含这个vc的key,初始化put进去
vcCountMapState.put(vc, 1);
}
// 2.遍历Map状态,输出每个k-v的值
StringBuilder outStr = new StringBuilder();
outStr.append("======================================\n");
outStr.append("传感器id为" + value.getId() + "\n");
for (Map.Entry<Integer, Integer> vcCount : vcCountMapState.entries()) {
outStr.append(vcCount.toString() + "\n");
}
outStr.append("======================================\n");
out.collect(outStr.toString());
// vcCountMapState.get(); // 对本组的Map状态,根据key,获取value
// vcCountMapState.contains(); // 对本组的Map状态,判断key是否存在
// vcCountMapState.put(, ); // 对本组的Map状态,添加一个 键值对
// vcCountMapState.putAll(); // 对本组的Map状态,添加多个 键值对
// vcCountMapState.entries(); // 对本组的Map状态,获取所有键值对
// vcCountMapState.keys(); // 对本组的Map状态,获取所有键
// vcCountMapState.values(); // 对本组的Map状态,获取所有值
// vcCountMapState.remove(); // 对本组的Map状态,根据指定key,移除键值对
// vcCountMapState.isEmpty(); // 对本组的Map状态,判断是否为空
// vcCountMapState.iterator(); // 对本组的Map状态,获取迭代器
// vcCountMapState.clear(); // 对本组的Map状态,清空
}
}
)
.print();
env.execute();
}
}2.2.4 Estado Redutor (ReduzindoEstado)
A definição da lógica de redução é implementada passando uma função de redução (ReduceFunction) no descritor de estado de redução (ReduzindoStateDescriptor). A função de redução aqui é a ReduceFunction que mencionamos quando introduzimos o operador de agregação de redução antes, portanto, o tipo de estado é igual ao tipo de dados de entrada.
public ReducingStateDescriptor(
String name, ReduceFunction<T> reduceFunction, Class<T> typeClass) {...}Caso: Calcule a soma dos níveis de água de cada sensor
.process(new KeyedProcessFunction<String, WaterSensor, Integer>() {
private ReducingState<Integer> sumVcState;
@Override
public void open(Configuration parameters) throws Exception {
sumVcState = this
.getRuntimeContext()
.getReducingState(new ReducingStateDescriptor<Integer>("sumVcState",Integer::sum,Integer.class));
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<Integer> out) throws Exception {
sumVcState.add(value.getVc());
out.collect(sumVcState.get());
}
})2.2.5 Estado Agregador (AggregatingState)
Muito semelhante ao estado de redução, o estado de agregação também é um valor que contém o resultado da agregação de todos os dados adicionados. Diferente de ReduceState, sua lógica de agregação é definida passando uma função agregada mais geral (AggregateFunction) no descritor; esta é a AggregateFunction da qual falamos antes, que usa um acumulador (Accumulator) para representar o status, então o tipo de status agregado pode ser completamente diferente do tipo de dados adicionado, tornando-o mais flexível de usar.
Requisitos do caso: Calcule o nível médio de água de cada sensor
public class KeyedAggregatingStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);
sensorDS.keyBy(r -> r.getId())
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
AggregatingState<Integer, Double> vcAvgAggregatingState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcAvgAggregatingState = getRuntimeContext()
.getAggregatingState(
new AggregatingStateDescriptor<Integer, Tuple2<Integer, Integer>, Double>(
"vcAvgAggregatingState",
new AggregateFunction<Integer, Tuple2<Integer, Integer>, Double>() {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
@Override
public Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {
return Tuple2.of(accumulator.f0 + value, accumulator.f1 + 1);
}
@Override
public Double getResult(Tuple2<Integer, Integer> accumulator) {
return accumulator.f0 * 1D / accumulator.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
// return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);
return null;
}
},
Types.TUPLE(Types.INT, Types.INT))
);
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
// 将 水位值 添加到 聚合状态中
vcAvgAggregatingState.add(value.getVc());
// 从 聚合状态中 获取结果
Double vcAvg = vcAvgAggregatingState.get();
out.collect("传感器id为" + value.getId() + ",平均水位值=" + vcAvg);
// vcAvgAggregatingState.get(); // 对 本组的聚合状态 获取结果
// vcAvgAggregatingState.add(); // 对 本组的聚合状态 添加数据,会自动进行聚合
// vcAvgAggregatingState.clear(); // 对 本组的聚合状态 清空数据
}
}
)
.print();
env.execute();
}
}2.2.6 Estado do Tempo de Vida (TTL)
Em aplicações práticas, muitos estados crescerão gradualmente ao longo do tempo e, se não forem restringidos, acabarão por levar ao esgotamento do espaço de armazenamento.
Ao configurar o TTL do estado, você precisa criar um objeto de configuração StateTtlConfig e, em seguida, chamar o método .enableTimeToLive() do descritor de estado para iniciar a função TTL.
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("my state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);Vários itens de configuração são usados aqui:
- .newBuilder()
O método construtor da configuração TTL do estado deve ser chamado. Após retornar um Construtor, chame o método .build() para obter o StateTtlConfig. O método precisa passar um Time como parâmetro, que é o tempo de sobrevivência do estado definido .
- .setUpdateType()
Defina o tipo de atualização. O tipo de atualização especifica quando atualizar o tempo de expiração do estado . OnCreateAndWrite aqui significa que o tempo de expiração só é atualizado ao criar o estado e alterá-lo (operação de gravação). Outro tipo, OnReadAndWrite, indica que o tempo de expiração será atualizado independente das operações de leitura ou gravação, ou seja, enquanto o estado for acessado, indica que ele está ativo, estendendo assim o tempo de sobrevivência. O padrão desta configuração é OnCreateAndWrite.
- .setStateVisibility()
Defina a visibilidade do status. A chamada "visibilidade do estado" significa que porque a operação de compensação não é em tempo real, pode continuar a existir após o estado expirar.Neste momento, se você acessá-lo, se ele pode ser lido normalmente é um problema. O NeverReturnExpired definido aqui é o comportamento padrão, o que significa que o valor expirado nunca é retornado, ou seja, enquanto expirar, é considerado limpo e a aplicação não pode continuar a ler; isso é mais importante ao lidar com sessão ou dados privados. Outra configuração correspondente é ReturnExpireDefNotCleanedUp, que retorna seu valor se o status expirado ainda existir.
public class StateTTLDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
);
sensorDS.keyBy(r -> r.getId())
.process(
new KeyedProcessFunction<String, WaterSensor, String>() {
ValueState<Integer> lastVcState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// TODO 1.创建 StateTtlConfig
StateTtlConfig stateTtlConfig = StateTtlConfig
.newBuilder(Time.seconds(5)) // 过期时间5s
// .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 状态 创建和写入(更新) 更新 过期时间
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite) // 状态 读取、创建和写入(更新) 更新 过期时间
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 不返回过期的状态值
.build();
// TODO 2.状态描述器 启用 TTL
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("lastVcState", Types.INT);
stateDescriptor.enableTimeToLive(stateTtlConfig);
this.lastVcState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {
// 先获取状态值,打印 ==》 读取状态
Integer lastVc = lastVcState.value();
out.collect("key=" + value.getId() + ",状态值=" + lastVc);
// 如果水位大于10,更新状态值 ===》 写入状态
if (value.getVc() > 10) {
lastVcState.update(value.getVc());
}
}
}
)
.print();
env.execute();
}
}3. Back-ends estaduais
No Flink, o armazenamento, o acesso e a manutenção do estado são todos determinados por um componente conectável, chamado back-end de estado. O back-end do estado é o principal responsável por gerenciar o método de armazenamento e a localização do estado local .
3.1 Classificação do back-end de estado ( HashMapStateBackend/RocksDB )
Flink fornece dois tipos diferentes de backends de estado, um é o "HashMapStateBackend" e o outro é o "EmbeddedRocksDBStateBackend".
O back-end de estado padrão do sistema é HashMapStateBackend.
3.1.1 HashMapStateBack-end
HashMapStateBackend armazena o estado na memória . Em termos de implementação específica, o back-end de status da tabela hash tratará internamente o status diretamente como objetos e os salvará no heap JVM do Taskmanager .
O estado comum, bem como os dados e gatilhos coletados na janela, são armazenados na forma de pares de valores-chave, de modo que a camada inferior é uma tabela hash (HashMap) , razão pela qual esse back-end de estado é nomeado.
3.1.2 Back-end de estado RocksDB incorporado (EmbeddedRocksDBStateBackend)
RocksDB é um meio de armazenamento de valor-chave integrado que pode persistir dados no disco rígido local .
Após configurar o EmbeddedRocksDBStateBackend, todos os dados processados serão colocados no banco de dados RocksDB.RocksDB é armazenado no diretório de dados local do TaskManager por padrão .
3.2 Como escolher o backend de status correto
A maior diferença entre os dois back-ends de estado do HashMap e do RocksDB é onde o estado local é armazenado.
HashMapStateBackend é um cálculo na memória com velocidades de leitura e gravação muito rápidas; no entanto, o tamanho do estado será limitado pela memória disponível do cluster. Se o estado do aplicativo continuar a crescer ao longo do tempo, os recursos de memória serão esgotados.
RocksDB é um armazenamento em disco rígido , portanto pode ser expandido de acordo com o espaço em disco disponível, por isso é muito adequado para armazenamento de estado supermassivo . No entanto, uma vez que cada estado de leitura e gravação requer serialização/desserialização, e os dados podem precisar ser lidos diretamente do disco, isso levará a uma redução no desempenho. O desempenho médio de leitura e gravação é uma ordem de magnitude mais lenta que o HashMapStateBackend.
3.3 Configuração do back-end de status
3.3.1 Configurar o back-end de status padrão
#flink-conf.yaml
# 默认状态后端
state.backend: hashmap
# 存放检查点的文件路径
# 这里的state.checkpoints.dir配置项,定义了检查点和元数据写入的目录。
state.checkpoints.dir: hdfs://hadoop102:8020/flink/checkpoints3.3.2 Configurar o back-end de status separadamente para cada trabalho (por trabalho/aplicativo)
Definido executando o ambiente HashMapStateBackend .
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());Definido executando o ambiente, EmbeddedRocksDBStateBackend.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());Deve-se observar que se você quiser usar EmbeddedRocksDBStateBackend no IDE, você precisa adicionar dependências ao projeto Flink:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>