[1] Concepts et calculs associés de l'IOU dans la détection de cibles
IoU (Intersection over Union) est un module important dans la tâche de détection de cible. C'est la zone d'intersection de GT bbox et pred bbox / la zone d'union des deux .
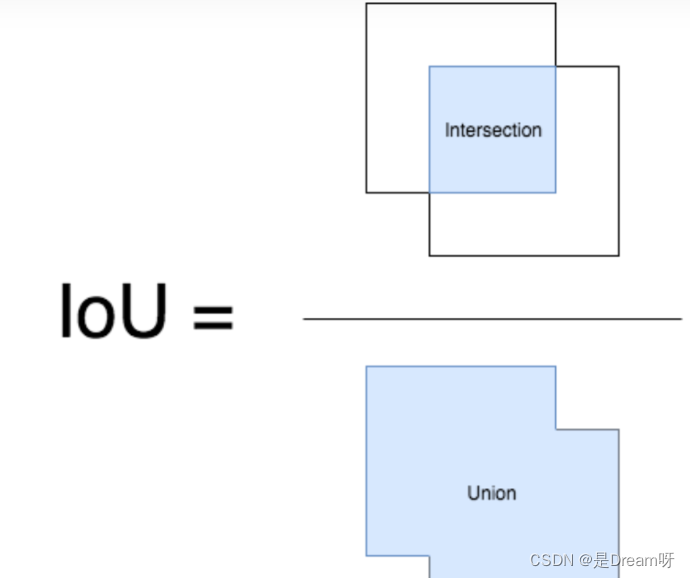
Ci-dessous, nous utilisons les coordonnées (haut, gauche, bas, droite), c'est-à-dire les coordonnées du coin supérieur gauche et les coordonnées du coin inférieur droit. Ainsi, la valeur IOU peut être calculée dans les deux rectangles donnés.
def compute_iou(rect1,rect2):
# (y0,x0,y1,x1) = (top,left,bottom,right)
S_rect1 = (rect1[2] - rect1[0]) * (rect1[3] - rect1[1])
S_rect2 = (rect2[2] - rect2[0]) * (rect2[3] - rect1[1])
sum_all = S_rect1 + S_rect2
left_line = max(rect1[1],rect2[1])
right_line = min(rect1[3],rect2[3])
top_line = max(rect1[0],rect2[0])
bottom_line = min(rect1[2],rect2[2])
if left_line >= right_line or top_line >= bottom_line:
return 0
else:
intersect = (right_line - left_line) * (bottom_line - top_line)
return (intersect / (sum_area - intersect)) * 1.0
[2] Concepts et calculs associés du NMS dans la détection de cibles
Dans la détection de cible, nous pouvons utiliser la suppression non maximale (NMS) pour post-traiter un grand nombre de trames candidates générées, supprimer les trames candidates redondantes et obtenir les résultats les plus représentatifs pour accélérer l'efficacité de la détection de cible.
Comme le montre la figure ci-dessous, éliminez les cases candidates redondantes et trouvez la meilleure bbox :

Processus de suppression non maximale (NMS) :
-
Nous devons d’abord définir deux valeurs : un seuil de score et un seuil d’IOU.
-
Pour chaque type d'objet, parcourez toutes les cases candidates de cette classe, filtrez les cases candidates dont la valeur de score est inférieure au seuil de score et triez les cases candidates en fonction de leur probabilité de classification de catégorie : A < B < C < D < E < FA < B < C < D < E < FUN<B<C<D<E<F .
-
Marquez d’abord la boîte rectangulaire de probabilité maximale F comme boîte candidate que nous souhaitons conserver.
-
À partir du cadre rectangulaire de probabilité maximale F, il est jugé si le rapport d'intersection et d'union (IOU) de A à E et F est supérieur au seuil d'IOU. En supposant que le chevauchement entre B, D et F dépasse le seuil d'IOU, alors B et D sont supprimés.
-
Parmi les cadres rectangulaires restants A, C et E, sélectionnez le E avec la probabilité la plus élevée et marquez-le comme cadre candidat à conserver. Déterminez ensuite le chevauchement entre E et A et C et supprimez les cadres rectangulaires dont le chevauchement dépasse le définir le seuil.
-
Répétez cette opération jusqu'à ce qu'il ne reste plus de cases rectangulaires et marquez toutes les cases rectangulaires que vous souhaitez conserver.
-
Une fois chaque catégorie traitée, revenez à l'étape 2 pour traiter à nouveau la catégorie d'objets suivante.
import numpy as np
def py_cpu_nms(dets, thresh):
#x1、y1(左下角坐标)、x2、y2(右上角坐标)以及score的值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个候选框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score降序排序(保存的是索引)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
#计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到向量
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算重叠度IOU:重叠面积 / (面积1 + 面积2 - 重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#找到重叠度不高于阈值的矩形框索引
inds = np.where(ovr < thresh)[0]
# 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要加1操作
order = order[inds + 1]
return keep
[3] Quelle est la différence entre la détection de cible en une étape et la détection de cible en deux étapes ?
Algorithme de détection de cible en deux étapes : générer d'abord une proposition de région (RP) (une boîte présélectionnée pouvant contenir l'objet à détecter), puis classer l'échantillon via un réseau neuronal convolutif. Sa précision est plus élevée et sa vitesse est plus lente.
Logique principale : Extraction de fonctionnalités -> Générer RP -> Régression de classification/positionnement.
Les algorithmes courants de détection de cible en deux étapes incluent : les séries R-CNN et R-FCN plus rapides, etc.
Algorithme de détection de cible en une étape : sans RP, les caractéristiques sont extraites directement du réseau pour prédire la classification et l'emplacement des objets. Il est plus rapide et a une précision légèrement inférieure à celle de l'algorithme en deux étapes.
Logique principale : extraction de fonctionnalités -> régression de classification/positionnement.
Les algorithmes courants de détection de cible en une étape incluent : la série YOLO, SSD et RetinaNet, etc.
【4】Quelles méthodes peuvent améliorer l'effet de la détection de petites cibles ?
-
Améliorer la résolution de l'image. Les petits objets ne peuvent contenir que quelques pixels dans le cadre de délimitation, de sorte que la richesse des fonctionnalités des petits objets peut être augmentée en augmentant la résolution de l'image.
-
Augmentez la résolution d'entrée du modèle. Il s'agit d'une méthode générale avec un meilleur effet, mais elle posera le problème d'une vitesse d'inférence plus lente du modèle.
-
Images de tuiles.

-
Augmentation des données. L'amélioration de la détection des petites cibles comprend le recadrage aléatoire, la rotation aléatoire et l'amélioration de la mosaïque.
-
Apprenez automatiquement l'ancre.
-
Optimisation des catégories.
[5] Quelles sont les caractéristiques du modèle ResNet et les problèmes qu'il résout ?
Chaque fois que je répondrai à cette question, j'inclurai mon égoïsme. J'aime l'expliquer du point de vue de l'automatisation électrique plutôt que du point de vue de l'informatique, car cela me rappelle mes années vertes à l'université.
ResNet est un amplificateur différentiel . La conception structurelle et la logique idéologique de ResNet consistent à faire abstraction d'un amplificateur différentiel dans l'apprentissage automatique, qui peut améliorer la corrélation des gradients du réseau profond et mettre en évidence de petits changements lors de la rétropropagation des gradients.
La caractéristique du modèle est la structure résiduelle conçue, qui est très sensible aux petits changements dans les résultats du modèle.
Pourquoi l'ajout du module résiduel a-t-il un effet ?
Hypothèse : si le module résiduel n'est pas utilisé, la sortie est F 1 ( x ) = 5,1 F_{1} (x) = 5,1F1( X )=5.1 , le résultat attendu estH 1 ( x ) = 5 H_{1} (x)= 5H1( X )=5 , si vous souhaitez apprendre la fonction H telle queF 1 ( x ) = H 1 ( x ) = 5 F_{1} (x) = H_{1} (x) = 5F1( X )=H1( X )=5. Ce taux de changement est relativement faible et difficile à apprendre.
Mais si le plan est H 1 ( x ) = F 1 ( x ) + 5 = 5,1 H_{1} (x) = F_{1} (x) + 5 = 5,1H1( X )=F1( X )+5=5.1 , effectuez une division telle queF 1 ( x ) = 0,1 F_{1} (x)= 0,1F1( X )=0.1 , alors l'objectif d'apprentissage devient de laisserF 1 (x) = 0 F_{1} (x)= 0F1( X )=0 , une fonction de mappage est apprise pour que sa sortie passe de 0,1 à 0. C'est relativement simple. En d’autres termes, le mappage après introduction du module résiduel est plus sensible aux changements de sortie.
Compréhension approfondie : Si F 1 ( x ) = 5,1 F_{1} (x) = 5,1F1( X )=5.1 , continuez maintenant à entraîner le modèle pour que la fonction de cartographieF 1 ( x ) = 5 F_{1} (x) = 5F1( X )=5 . Taux de variation :(5,1 − 5) / 5,1 = 0,02 (5,1 - 5) / 5,1 = 0,02( 5.1−5 ) /5.1=0,02 . Si le module résiduel n'est pas utilisé, le taux d'apprentissage peut être réglé de 0,01 à 0,0000001. Il peut toujours être traité si le nombre de couches est faible, mais une fois le nombre de couches approfondi, il peut ne pas être facile à utiliser.
Si le module résiduel est utilisé à ce moment, c'est-à-dire F 1 ( x ) = 0,1 F_{1} (x) = 0,1F1( X )=0,1 devientF 1 ( x ) = 0 F_{1} (x) = 0F1( X )=0 . Ce taux de changement a augmenté de 100 %. Évidemment, cela aura un effet plus important sur l’ajustement des pondérations des paramètres.
[6] Quelles sont la structure et les caractéristiques du modèle ResNeXt ?
Le modèle ResNeXt est optimisé sur la base du modèle ResNet. Son objectif principal est d'introduire l'idée d'Inception dans ResNeXt. Comme le montre la figure ci-dessous, le côté gauche est la structure classique ResNet et le côté droit est la structure ResNeXt, qui convertit la convolution monocanal en convolution multicanal multicanal pour une convolution groupée .
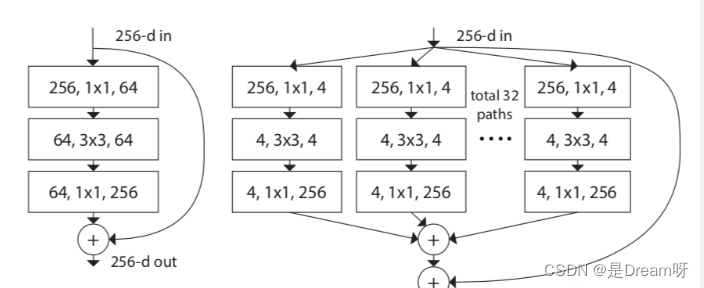
L'auteur a en outre proposé trois structures équivalentes de ResNeXt, parmi lesquelles l'idée de convolution groupée dans la structure c est venue à l'esprit.
Enfin, jetons un œil au tableau comparatif des différences structurelles entre ResNeXt50 et ResNet50 :
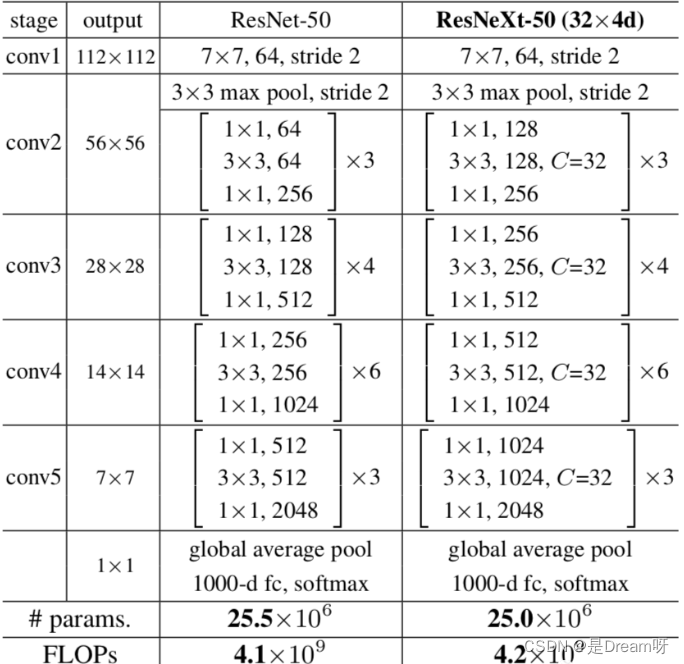
ResNeXt论文:《Transformations résiduelles agrégées pour les réseaux de neurones profonds》
[7] Quelles sont les structures et les caractéristiques des modèles de la série MobileNet ?
MobileNet est une structure de réseau légère principalement conçue pour les appareils embarqués tels que les téléphones mobiles. La structure du réseau MobileNetv1 utilise une convolution séparable en profondeur sur la base de VGG, ce qui réduit considérablement le nombre de paramètres du modèle tout en garantissant de ne pas perdre trop de précision.
La convolution séparable en profondeur est composée d'une convolution en profondeur et d'une convolution ponctuelle.
La convolution en profondeur (DW) peut réduire efficacement le nombre de paramètres et améliorer la vitesse de fonctionnement. Cependant, étant donné que chaque carte de caractéristiques est convoluée par un seul noyau de convolution, la carte de caractéristiques produite par DW ne contient que toutes les informations de la carte de caractéristiques d'entrée, et les informations entre les entités ne peuvent pas être communiquées, ce qui entraîne un « mauvais flux d'informations ». La convolution ponctuelle (PW) réalise l'échange d'informations sur les caractéristiques du canal et résout le problème du « mauvais flux d'informations » provoqué par la convolution DW.
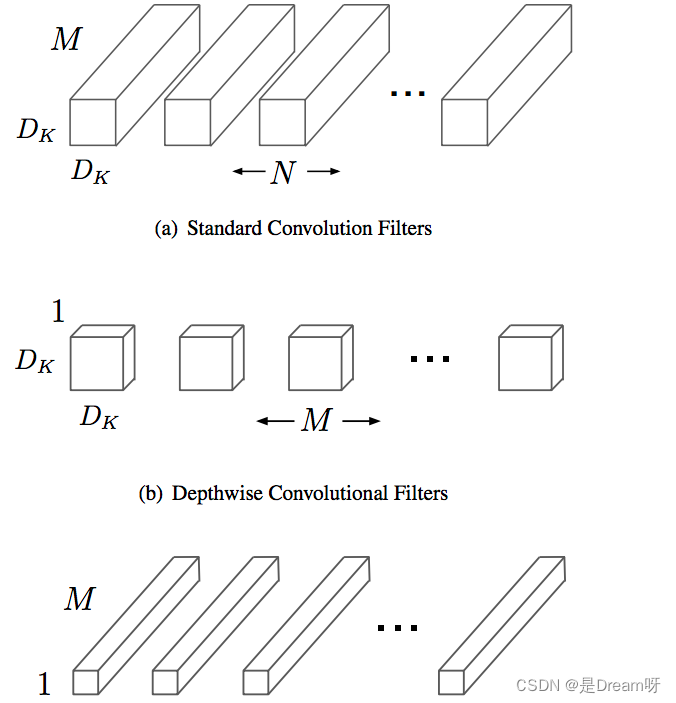
Comparaison de la quantité de calcul de la convolution séparable en profondeur et de la convolution standard :
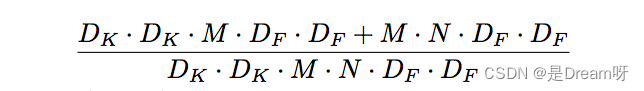
Par rapport à la convolution standard, la convolution Depthwise Separable peut réduire considérablement la quantité de calcul. Et à mesure que le nombre de canaux de convolution augmente, l’effet devient plus évident.
De plus, Mobilenetv1 utilise la convolution stride=2 pour remplacer l'opération de pooling et utilise directement stride=2 pour terminer le sous-échantillonnage pendant la convolution, économisant ainsi le temps d'utilisation de l'opération de pooling pour effectuer le sous-échantillonnage après la convolution, ce qui peut améliorer la vitesse de calcul.
MobileNetv1论文 :《MobileNets : réseaux neuronaux convolutifs efficaces pour les applications de vision mobile》
[8] Quelles sont les structures et les caractéristiques des modèles de la série MobileNet ? (deux)
MobileNetV2 introduit le goulot d'étranglement linéaire et les résidus inversés basés sur MobileNetV1 .
MobileNetV2 utilise le goulot d'étranglement linéaire (transformation linéaire) au lieu de la fonction d'activation non linéaire d'origine pour capturer la variété d'intérêt. Des expériences ont prouvé que l'utilisation du goulot d'étranglement linéaire peut mieux conserver les informations utiles sur les fonctionnalités dans les petits réseaux.
Les résidus inversés sont exactement le contraire du fonctionnement inter-canal du module résiduel ResNet classique. Étant donné que MobileNetV2 utilise une structure de goulot d'étranglement linéaire, les dimensions des fonctionnalités extraites sont généralement faibles. Si vous utilisez simplement une carte de fonctionnalités de faible dimension, l'effet ne sera pas bon. Si les couches convolutives utilisent toutes des cartes de caractéristiques de faible dimension pour extraire des caractéristiques, il n'y aura alors aucun moyen d'extraire suffisamment d'informations globales. Si nous souhaitons extraire des informations complètes sur les fonctionnalités, nous devons les compléter avec une carte de fonctionnalités de grande dimension pour atteindre l'équilibre.
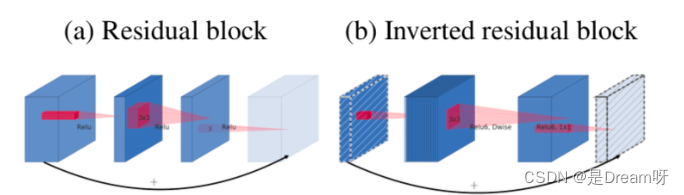
MobileNetV2的论文:《MobileNetV2 : résidus inversés et goulots d'étranglement linéaires》
MobileNetV3 présente globalement deux innovations majeures :
1. Combinaison technologique de recherche complémentaire : le NAS aux ressources limitées effectue une recherche au niveau du module, NetAdapt effectue une recherche locale et affine la couche réseau après avoir déterminé chaque module.
2. Amélioration de la structure du réseau : réduisez davantage le nombre de couches de réseau et introduisez la fonction d'activation h-swish.
L'auteur a découvert que la fonction d'activation swish peut améliorer efficacement la précision du réseau. Cependant, swish nécessite trop de calculs. L'auteur a proposé h-swish (version dure de swish) comme suit :
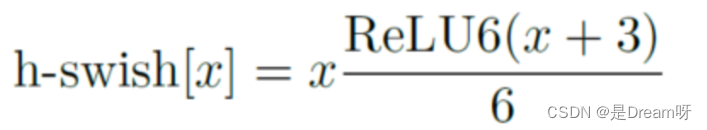
Cette non-linéarité apporte de nombreux avantages tout en conservant la précision. Premièrement, ReLU6 peut être implémenté dans de nombreux frameworks logiciels et matériels. Deuxièmement, il évite la perte de précision numérique lors de la quantification et s'exécute rapidement.
Optimisation de la structure du modèle MobileNetV3 :
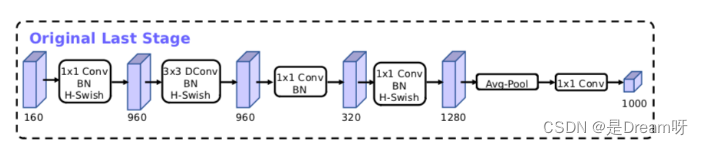
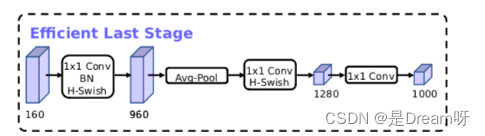
Article MobileNetV3 : « Recherche de MobileNetV3 »
[9] Quelles sont les structures et caractéristiques du modèle ViT (Vision Transformer) ?
Caractéristiques du modèle ViT :
1. ViT utilise directement la structure standard Transformer pour la classification des images, et sa structure de modèle ne contient pas de CNN.
2. Afin de répondre aux exigences de structure d'entrée du transformateur, l'extrémité d'entrée divise l'image entière en petits blocs d'image, puis entre la séquence d'intégration linéaire de ces petits blocs d'image dans le réseau. À la sortie finale, le formulaire Class Token est utilisé pour la prédiction de classification.
3. Le transformateur a moins d'invariance de traduction et de perceptibilité locale que la structure CNN. Lorsque la quantité de données est petite, l'effet peut ne pas être aussi bon que le modèle CNN. Cependant, après un pré-entraînement sur un ensemble de données à grande échelle, puis un transfert apprenant, il peut atteindre des performances SOTA sur des tâches spécifiques.
La structure globale du modèle de ViT :
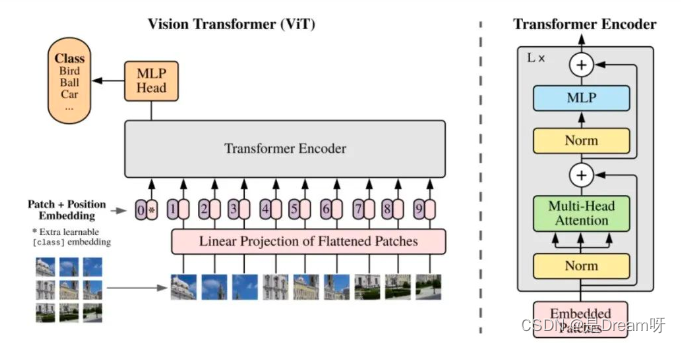
Il peut être spécifiquement divisé en les parties suivantes :
-
Incorporation de blocs d'images
-
structure d'attention à plusieurs têtes
-
Structure perceptron multicouche (MLP)
-
Utilisez des opérations telles que DropPath, Class Token, Positional Encoding, etc.
[10] Quelles sont les structures et les caractéristiques des modèles de la série EfficientNet ?
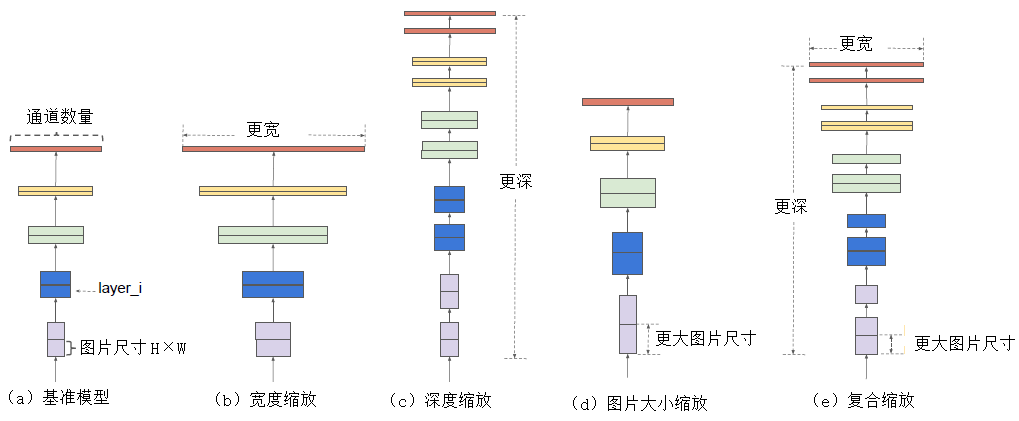
Le modèle de la série Efficientnet est un modèle obtenu en ajustant la recherche sous trois perspectives : profondeur, largeur et résolution de l'image d'entrée via une recherche par grille. De la version EfficientNet-B0 à la version EfficientNet-L2, la précision du modèle est de plus en plus élevée, tout comme le nombre de paramètres et les besoins en mémoire.
L'échelle du modèle de profondeur est principalement déterminée par les paramètres de mise à l'échelle des trois dimensions que sont la largeur, la profondeur et la résolution. Ces trois dimensions ne sont pas indépendantes les unes des autres : dans le cas où la résolution de l'image d'entrée est plus élevée, un réseau plus profond est nécessaire pour obtenir un champ de vision plus large. De même, pour les images à plus haute résolution, davantage de canaux sont nécessaires pour obtenir des caractéristiques plus précises .
L'intérieur du modèle EfficientNet est implémenté via plusieurs modules de convolution MBConv. La structure spécifique de chaque module de convolution MBConv est illustrée dans la figure ci-dessous. Il a été prouvé expérimentalement que la convolution Depthwise Separable est toujours très efficace dans les grands modèles ; la convolution Depthwise Separable a de meilleures capacités d'extraction et d'expression de caractéristiques que la convolution standard .
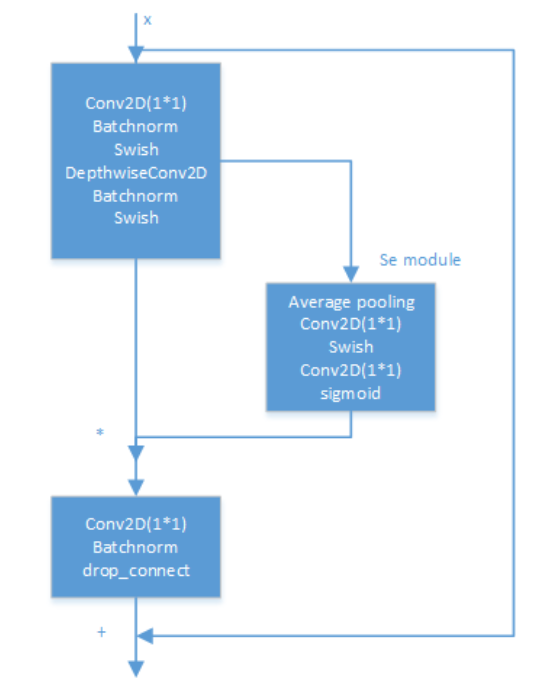
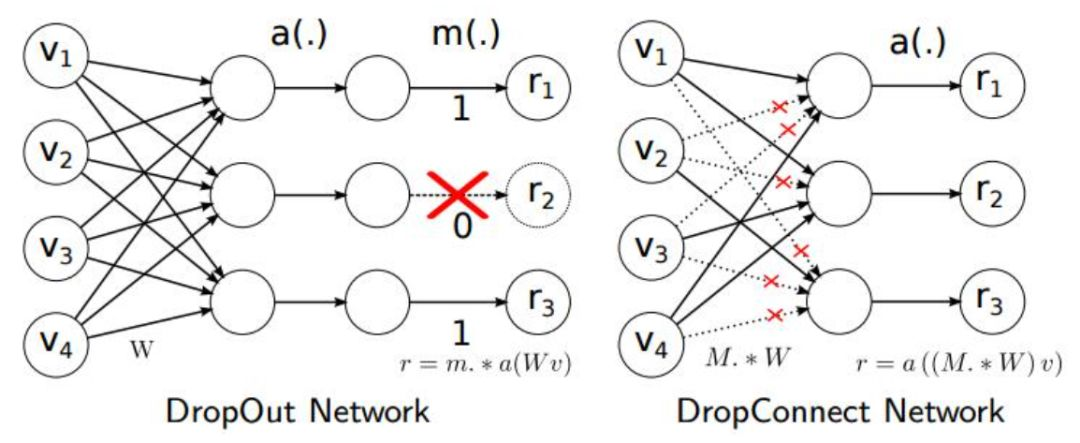
De plus, la méthode Drop_Connect est utilisée dans l'article pour remplacer la méthode Dropout traditionnelle afin d'éviter le surajustement du modèle. La différence entre DropConnect et Dropout est que lors du processus de formation du modèle de réseau neuronal, il ne supprime pas de manière aléatoire la sortie des nœuds de couche cachés, mais supprime de manière aléatoire l'entrée des nœuds de couche cachés.
EfficientNet论文:《EfficientNet : Repenser la mise à l'échelle du modèle pour les réseaux de neurones convolutifs》
Pour faire une parenthèse, vous pouvez voir le processus étouffant d'ajustement des paramètres de l'auteur à travers l'article. . .
[11] Modèle classique de questions fréquemment posées en entretien ?
Des questions sur les modèles sont souvent posées lors des entretiens. C'est également une question qui n'est pas facile à quantifier car les modèles sont complexes et divers. Il est possible à l'enquêteur de poser n'importe quelle question. Dans le schéma logique ci-dessous, j'ai listé quelques questions qui sont utiles dans les domaines académiques. Le monde et l’industrie sont des modèles de grande valeur pour la référence de tous.
Il est préférable de peaufiner votre CV avec davantage de projets, de concours, de recherches scientifiques, etc., et d'orienter les questions liées aux modèles pendant le processus d'entretien vers des modèles familiers utilisés dans ces emplois.
【12】Quel est le rôle de la perte focale ?
Focal Loss est une fonction de perte qui résout le déséquilibre des catégories et les différences de difficulté de classification dans les problèmes de classification, permettant au modèle de se concentrer davantage sur les échantillons difficiles pendant le processus de formation.
La perte focale part de problèmes à deux classifications, et la même idée peut être transférée à des problèmes multi-classifications.
Nous savons que la perte standard pour les problèmes de classification binaire est l'entropie croisée :
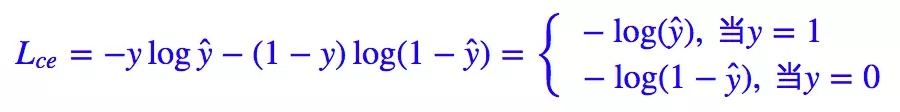
Pour les problèmes de classification binaire, nous appliquons presque la fonction d'activation sigmoïde y ^ = σ ( x ) \hat{y} = \sigma(x)oui^=σ ( x ) , donc la formule ci-dessus peut être transformée en :
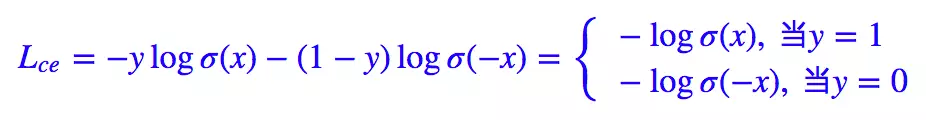
Ici nous avons 1 − σ ( x ) = σ ( − x ) 1 - \sigma(x) = \sigma(-x)1−σ ( X )=σ ( − X ) .
La formule donnée dans l'article Focal Loss est la suivante :

où y ∈ { 1 , − 1 } y\in \{ 1,-1\}oui∈{ 1 ,− 1 } est la vraie étiquette,p ∈ [ 0 , 1 ] p\in[0,1]p∈[ 0 ,1 ] est la probabilité prédite.
On définit alors pt: p_{t} :pt:

Ensuite, la formule d'entropie croisée ci-dessus peut être convertie en :

Sur la base des fondations ci-dessus, l'article initial sur la perte focale a ensuite introduit la fonction d'entropie croisée équilibrée :

Pour résoudre le problème du déséquilibre des catégories, un poids de contrôle est ajouté à la perte. Pour les échantillons appartenant à la catégorie minoritaire, α t \alpha_{t} est augmenté.untC'est ça. Mais il y a un problème avec cela : cela résout uniquement le problème d'équilibre entre les échantillons positifs et négatifs, et ne fait pas de distinction entre les échantillons faciles/difficiles .
Pourquoi la formule ci-dessus ne résout-elle que le problème du déséquilibre entre les échantillons positifs et négatifs ?
Parce qu'un coefficient α t \alpha_{t} est ajoutéunt, suivi du pt p_{t}ptLa définition est similaire, lorsque label = 1 label=1étiquette _ _ _=Quand 1 , α t = α \alpha_{t}=\alphaunt=α ;当étiquette = − 1 étiquette=-1étiquette _ _ _=Lorsque − 1 , α t = 1 − α \alpha_{t}= 1 - \alphaunt=1−α ,α \alphaLa plage de α est également [0, 1] [0,1][ 0 ,1 ] . Par conséquent, nous pouvons poserα \alphavaleur de α (si1 11Le nombre d'échantillons dans cette catégorie est comparé à− 1 -1− 1Le nombre d’échantillons dans cette catégorie est beaucoup plus petit, alorsα \alphaα peut être pris comme0,5 0,50,5 à1 11 pour augmenter1 11Le poids des échantillons de cette classe) pour contrôler la contribution des échantillons positifs et négatifs à la perte globale.
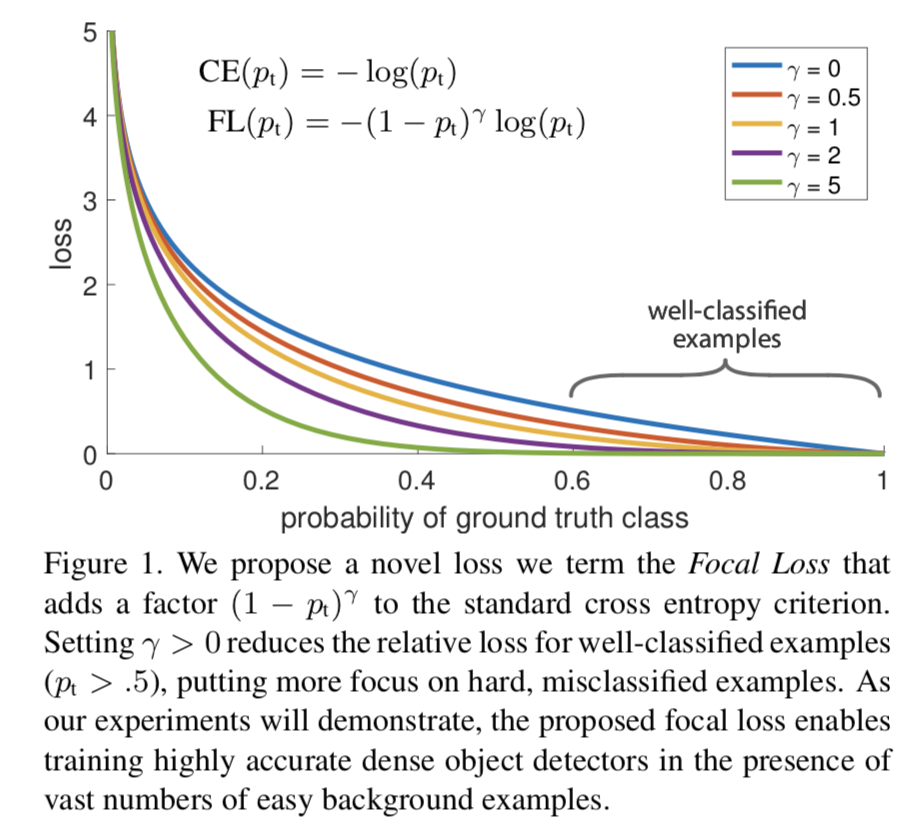
Perte focale
Afin de distinguer les échantillons difficiles/faciles, le prototype de Focal Loss est apparu :

( 1 − pt ) γ (1 - p_{t})^{\gamma}( 1−pt)γ est utilisé pour équilibrer la proportion inégale d'échantillons difficiles et faciles,γ > 0 \gamma >0c>0 joue le rôle de(1 − pt) (1 - p_{t})( 1−pt) effet d'amplification. γ > 0 \gamma >0c>0 réduit la perte d'échantillons faciles à classer, permettant au modèle de se concentrer davantage sur les échantillons difficiles à classer et facilement mal classés. Par exemple, lorsqueγ = 2 \gamma =2c=2 , le modèle prédit la confiancept p_{t}ptest 0,9 0,90,9 , alors( 1 − 0,9 ) γ = 0,01 (1 - 0,9)^{\gamma} = 0,01( 1−0,9 )c=0,01 , c'est-à-dire que la valeur FL devient très petite ; et lorsque le modèle prédit le niveau de confiancept p_{t}ptLorsque 0,3, ( 1 − 0,3 ) γ = 0,49 (1 - 0,3)^{\gamma} = 0,49( 1−0,3 )c=0,49 , sa contribution à la perte devient alors plus importante. Quandγ = 0 \gamma = 0c=Lorsque 0 , cela devient une perte d'entropie croisée.
Afin de résoudre le problème du déséquilibre entre les échantillons positifs et négatifs, α t \alpha_{t} d'entropie croisée équilibrée est ajouté à la formule ci-dessus.untFacteur, utilisé pour équilibrer la proportion inégale d'échantillons positifs et négatifs, et finalement obtenir la perte focale :
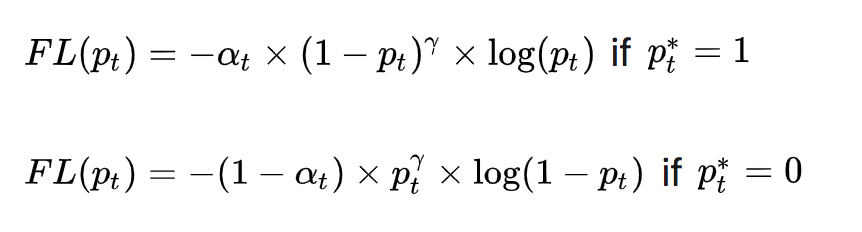
La valeur expérimentale optimale donnée dans l'article Focal Loss est à = 0,25 a_{t}= 0,25unt=0,25,γ = 2 \gamma = 2c=2 .
[14] Quels sont les modèles classiques de détection de visage légers ?
La détection des visages est une sous-tâche par rapport à la détection générale des cibles. Par rapport à la tâche générale de détection de cibles qui détecte 1 000 catégories à chaque tour, la tâche de détection de visages se concentre principalement sur la détection de cibles d'un seul type de visages. L' utilisation d'un modèle général de détection de cibles est trop extravagante et ressemble un peu à « tuer un poulet avec un sledgehammer" et possède un grand nombre de paramètres. La redondance affectera l'aspect pratique du côté déploiement . Par conséquent, pour les tâches de détection de visage, la communauté universitaire a proposé de nombreux modèles légers de détection de visage. Rocky en présentera ici quelques-uns représentatifs :
- libfacedetection
- Ultra-léger-rapide-générique-Face-Detector-1MB
- Un détecteur de visage léger et rapide pour les appareils Edge
- CentreVisage
- DBFace
- RétineVisage
- MTCNN
[15] Quelles sont les structures et les caractéristiques du modèle de détection de visage LFFD ?
Rocky a été interrogé à plusieurs reprises sur le modèle LFFD lors des entretiens de recrutement sur les stages/campus et sur la situation dans laquelle l'intervieweur voulait extraire des solutions algorithmiques liées au LFFD, ce qui montre que le modèle LFFD est toujours très précieux dans l'industrie . Maintenant, Rocky amènera tout le monde à découvrez le modèle LFFD.
LFFD (A-Light-and-Fast-Face-Detector-for-Edge-Devices) convient aux tâches de détection de cibles uniques telles que les visages, les piétons et les véhicules. Il présente les caractéristiques d'une vitesse rapide, d'un petit modèle et d'un bon effet. . LFFD est une méthode sans ancre. Elle utilise des champs récepteurs au lieu d'ancres et extrait des cartes de caractéristiques à 8 voies sur la structure de base pour détecter les visages de petite à grande. Le module de détection est divisé en deux catégories et une régression de boîte englobante .
Structure du modèle LFFD
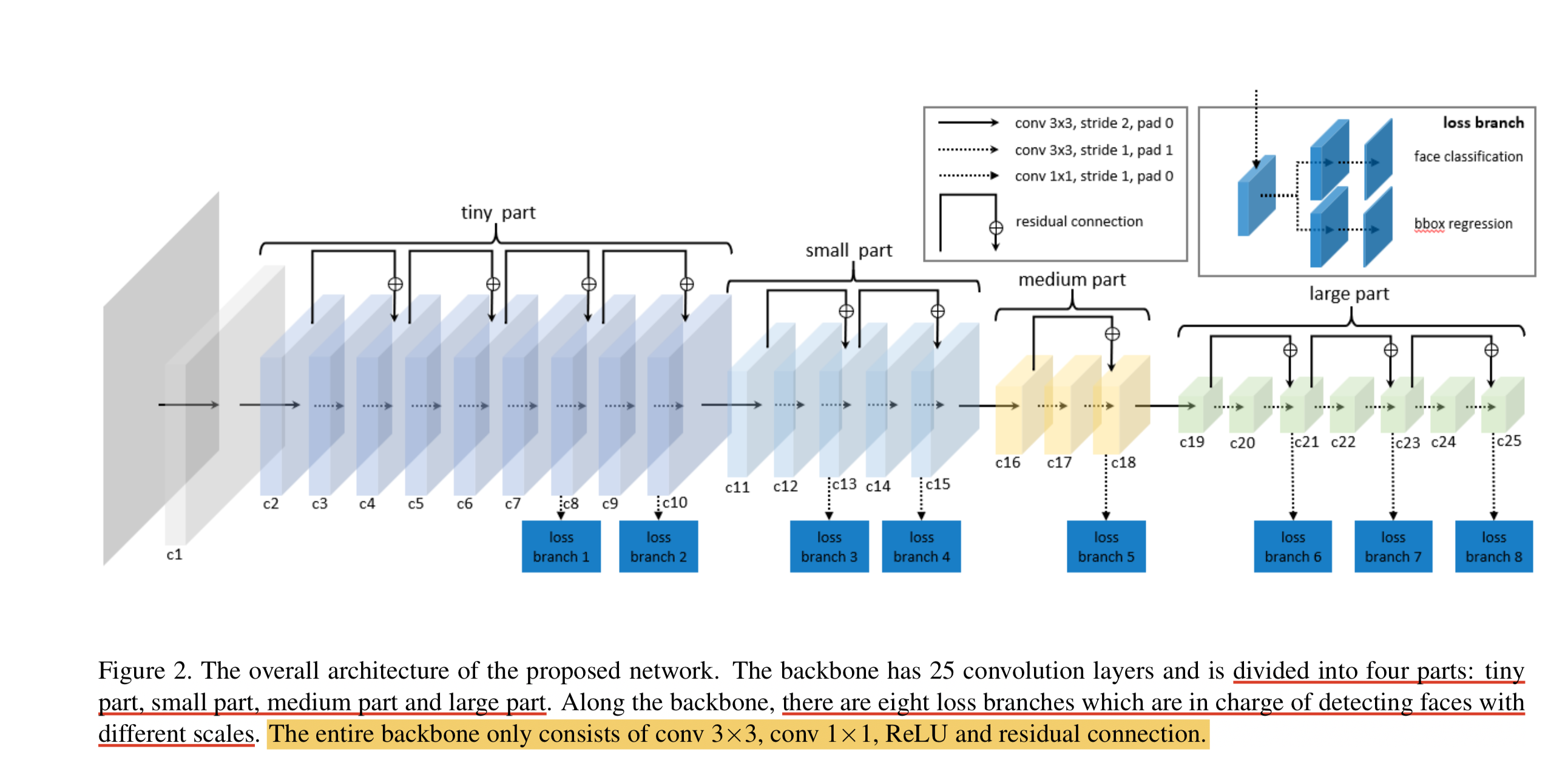
Nous pouvons voir que le modèle LFFD se compose principalement de quatre parties : une petite partie, une petite partie, une partie moyenne et une grande partie.
La couche BN n'est pas utilisée dans le modèle car elle ralentira la vitesse d'inférence de 17 %. Il utilise principalement un sous-échantillonnage aussi rapide que possible pour maintenir une couverture du visage à 100 %.
Principales caractéristiques du LFFD :
-
La structure est simple et directe, et elle est facile à déployer dans les appareils finaux d’IA grand public.
-
La capacité de détection de petites cibles est exceptionnelle : dans les images à très haute résolution (telles que 8K ou plus), il peut détecter des cibles aussi grandes que 10 pixels entre les deux ;
Fonction de perte LFFD
La fonction de perte LFFD est la somme pondérée de la perte de régression et de la perte de classification.
La perte de classification utilise la perte d'entropie croisée.
La perte de régression utilise la fonction de perte L2.
Adresse papier du LFFD : LFFD : Un détecteur de visage léger et rapide pour les appareils Edge
【16】La structure et les caractéristiques du modèle U-Net ?
La structure du réseau U-Net est la suivante :
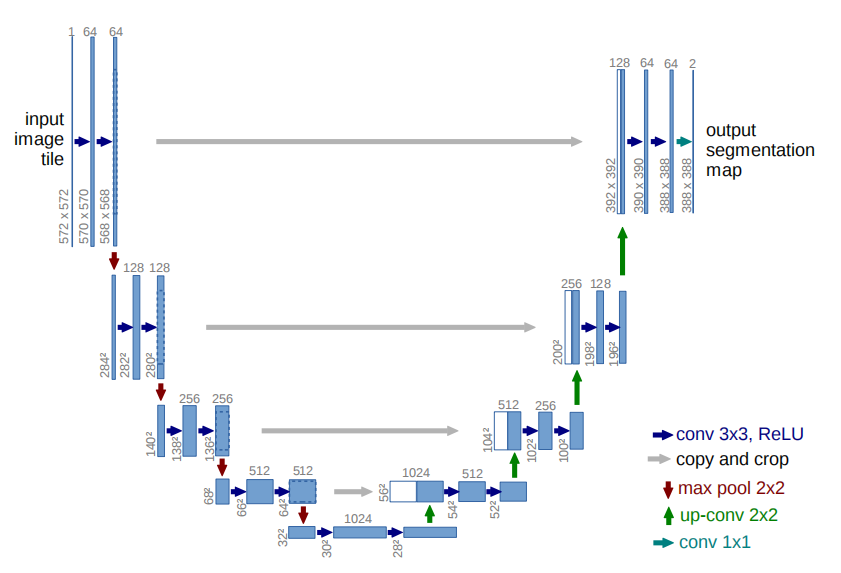
Caractéristiques du réseau U-Net :
- Réseau neuronal entièrement convolutif : utilisez 1 × 1 1\times11×1 convolution remplace complètement la couche entièrement connectée, ce qui rend la taille d'entrée du modèle illimitée.
- La moitié gauche du réseau est le chemin de contraction : utiliser des couches de convolution et de pooling maximum pour sous-échantillonner la carte des caractéristiques.
- La moitié droite du réseau est le chemin d'expansion : utilisez la convolution transposée pour suréchantillonner la carte de caractéristiques et concaténez-la avec la carte de caractéristiques générée par la couche correspondante du chemin de contraction. Le suréchantillonnage peut compléter les informations sur les caractéristiques et se concaténer avec la carte caractéristique du chemin de retrait de la moitié gauche du réseau (ce qui donne aux deux cartes caractéristiques la même taille tout au long de l'opération de culture), ce qui équivaut à une fusion entre haute résolution et haute résolution. caractéristiques dimensionnelles, compromis .
- U-Net propose une structure globale d'encodeur-décodeur rafraîchissante, qui rend U-Net plein de vitalité et d'adaptabilité forte.
U-Net a des applications très riches dans les images médicales, la détection de défauts et les scènes de trafic. On peut dire que dans les scénarios réels de segmentation d'images, U-Net est une référence universelle.
Adresse papier d'U-Net : U-Net
[17] Quelle est la structure et les caractéristiques du modèle RepVGG ?
L'architecture de base du modèle RepVGG se compose de 20 multicouches 3 × 3 3\times33×Il se compose de 3 convolutions et est divisé en étapes 5. La première couche de chaque étape est un sous-échantillonnage avec stride=2, et chaque couche de convolution utilise ReLU comme fonction d'activation.
Principales caractéristiques de RepVGG :
- 3 × 3 3 fois33×La densité de calcul de 3 convolutions sur le GPU (opérations théoriques divisées par le temps utilisé) peut être jusqu'à quatre fois supérieure à celle des convolutions 1x1 et 5x5.
- L'efficacité de calcul de la structure droite monocanal est supérieure à celle de la structure multicanal.
- La structure monocanal droite occupe moins de mémoire que la structure multicanal.
- L'architecture monocanal offre une meilleure flexibilité et permet d'effectuer plus facilement d'autres opérations telles que la compression de modèle.
- RepVGG ne contient qu'un seul opérateur, ce qui permet aux fabricants de puces de concevoir des puces spéciales pour améliorer l'efficacité de l'IA côté extrémité.
Alors, qu’est-ce qui permet à RepVGG d’obtenir l’effet SOTA dans la situation ci-dessus ?
La réponse est le reparamétrage structurel .
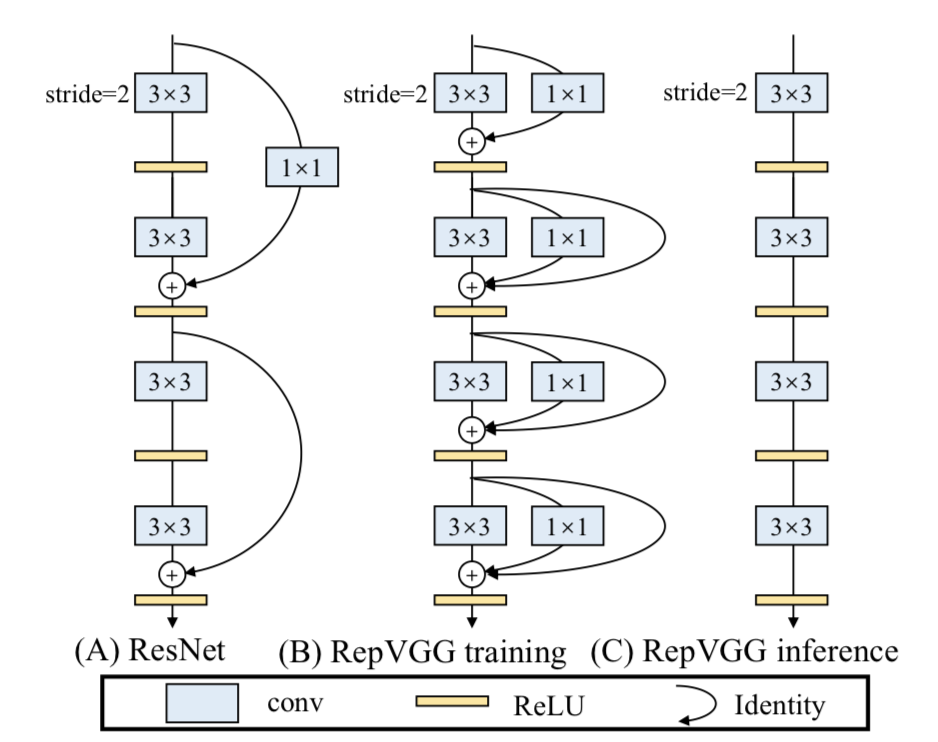
Au cours de la phase de formation, un modèle multi-branches est formé et converti de manière équivalente en un modèle mono-branche. Lors de la phase de déploiement, déployez un modèle monocanal. De cette façon, vous pouvez profiter des avantages de la formation de modèles multibranches (hautes performances) et des avantages de l'inférence de modèles monocanal (vitesse rapide, économie de mémoire).
Des connaissances plus détaillées sur le reparamétrage structurel seront introduites dans les chapitres suivants, donc tout le monde l'attend avec impatience !
【18】L'idée centrale du GAN ?
En 2014, Ian Goodfellow a proposé pour la première fois le concept de GAN. Yann LeCun a dit un jour : « Les réseaux adverses génératifs et leurs variantes sont devenus l'une des idées les plus importantes dans le domaine de l'apprentissage automatique au cours des 10 dernières années . » La proposition du GAN a permis au modèle génératif de se retrouver à nouveau sur la scène brillante de la vague d'apprentissage profond et a commencé à discuter et à rire avec le modèle discriminatif.
GAN se compose du générateur GGG et discriminateurDDComposition D. Parmi eux, le générateur est principalement responsable de la génération des données d'échantillon correspondantes, et l'entrée est généralement du bruit ZZéchantillonné aléatoirement à partir d'une distribution gaussienne.Z. _ La responsabilité principale du discriminateur est de distinguer les échantillons générés par le générateur degt (G round Truth) gt (GroundTruth)gt ( G ro u n d Truth ) , l' entrée est généralement gtgtg t échantillons et échantillons générés correspondants, ce que nous voulons, c'est associergt gtPlus le niveau de confiance de la sortie de l'échantillon g t est proche de1 11 est meilleur et la confiance dans la sortie de l'échantillon généré est plus proche de0 00 c'est mieux. Contrairement aux réseaux neuronaux généraux, le GAN doit entraîner le générateur et le discriminateur en même temps pendant la formation, sa formation est donc relativement difficile.
Dans le premier article proposant le GAN, le générateur était comparé à un criminel qui imprime de la fausse monnaie, et le discriminateur était traité comme un policier. Les criminels travaillent dur pour rendre réaliste la monnaie contrefaite qu’ils impriment, et la police améliore constamment sa capacité à détecter la monnaie contrefaite. Les deux se font concurrence et, au fil du temps, ils deviendront de plus en plus forts. Il en va de même dans les tâches de génération d’images, où le générateur génère en permanence de fausses images aussi réalistes que possible. Le discriminateur détermine que l'image est gt gtg t image, ou image générée. Les deux continuent d'optimiser le jeu, et finalement l'image générée par le générateur rend totalement impossible au discriminateur de distinguer le vrai du faux.
L'idée contradictoire du GAN se réalise principalement par sa fonction objective . La formule spécifique est la suivante :
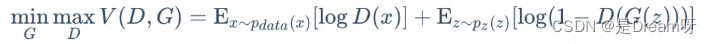
La formule ci-dessus semble compliquée, mais elle ne l’est pas. Au-delà des détails, la logique fondamentale de la formule entière est en fait un problème min-max. Lorsque les limites des applications mathématiques de l'apprentissage profond s'étendent ici, le GAN commence à briller .
Ensuite, nous entrons dans les détails. Nous pouvons examiner cette formule en deux parties, à savoir l'angle de minimisation du discriminateur et l'angle de maximisation du générateur. Du point de vue du discriminateur, nous voulons maximiser cette fonction objective, car dans la première partie de la publicité, cela signifie gt gtg t échantillon(x ~ P données) (x ~ Pdata)( x ~ P d a t a ) La confiance dans la sortie après la saisie du discriminateur est bien sûr plus proche de1 11 c'est mieux. La deuxième partie de la formule représente l'échantillon généré (G (z))en sortie du générateur( G ( z ) ) est ensuite entré dans le discriminateur pour la classification binaire. Bien entendu, le niveau de confiance de sa sortie est plus proche de0 00 est meilleur, donc1 − D ( G ( z ) ) 1 - D(G(z))1−Plus D ( G ( z )) est proche de 1 11 c'est mieux.
Du point de vue du générateur, nous voulons minimiser la valeur maximale de la fonction objectif discriminatrice . La valeur maximale de la fonction objectif du discriminateur représente la divergence JS entre la distribution des données réelles et la distribution des données générées. La divergence JS peut mesurer la similarité de la distribution. Plus les deux distributions sont proches, plus la divergence JS est petite (la divergence JS est la valeur initiale). Elle a été proposée dans l'article du GAN, mais des lacunes seront trouvées dans les applications pratiques. Des articles ultérieurs ont successivement proposé de nombreuses nouvelles fonctions de perte pour l'optimisation.)
[19] Modèle GAN classique souvent demandé lors des entretiens ?
- GAN original et sa logique de formation
- DCGAN
- CGAN
- FAUX
- LSGAN
- Série PixPix
- CysleGAN
- Série SRGAN
【20】Connaissance connexe du FPN (Feature Pyramid Network)
Points d'innovation du FPN
- Structure pyramidale des caractéristiques de conception
- Extraire des fonctionnalités multicouches (de bas en haut, de haut en bas)
- Fusion de fonctionnalités multicouches (connexion latérale)
La structure de la pyramide des fonctionnalités est conçue pour résoudre le problème multi-échelle de la détection de cibles et améliorer considérablement les performances de détection de petits objets sans augmenter fondamentalement la quantité de calcul du modèle d'origine.
Il s'avère que de nombreux algorithmes de détection de cibles utilisent uniquement des fonctionnalités de haut niveau pour la prédiction. Les fonctionnalités de haut niveau ont des informations sémantiques riches, mais ont une faible résolution et des emplacements de cibles approximatifs. Supposons que dans un réseau profond, un pixel de la carte finale des caractéristiques de haut niveau puisse correspondre à l'image de sortie 20 × 20 20 \times 2020×Zone de 20 pixels, donc moins de20 × 20 20 \times 2020×Les caractéristiques d'un petit objet de 20 pixels ont très probablement été perdues. Dans le même temps, les informations sémantiques des fonctionnalités de bas niveau sont relativement petites, mais la position de la cible est précise, ce qui est utile pour la détection de petites cibles. FPN fusionne des fonctionnalités de haut niveau avec des fonctionnalités de bas niveau, utilisant ainsi simultanément la haute résolution des fonctionnalités de bas niveau et les riches informations sémantiques des fonctionnalités de haut niveau, et effectue une prédiction indépendante des fonctionnalités multi-échelles, améliorant considérablement l'effet de détection de petits objets.
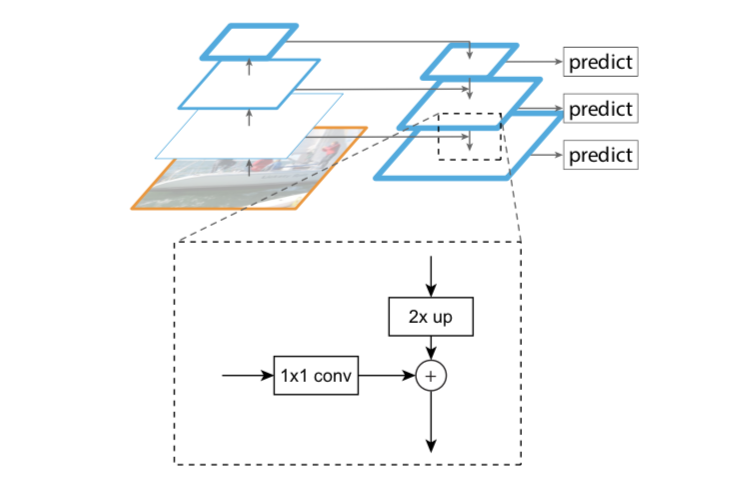
Les idées traditionnelles pour résoudre ce problème incluent :
- Pyramide d'images, c'est-à-dire formation et tests multi-échelles. Cependant, cette méthode est gourmande en calculs et prend du temps.
- Superposition de fonctionnalités, c'est-à-dire que chaque couche génère les résultats de détection de la résolution d'échelle correspondante, telle que l'algorithme SSD. Mais en fait, différentes profondeurs correspondent à différents niveaux de caractéristiques sémantiques. Le réseau superficiel a une haute résolution et apprend des caractéristiques plus détaillées. Le réseau profond a une faible résolution et apprend plus de caractéristiques sémantiques. Différentes caractéristiques seules ne suffisent pas.
Principaux modules de FPN
- Voie ascendante
- Chemin descendant
- Connexions latérales
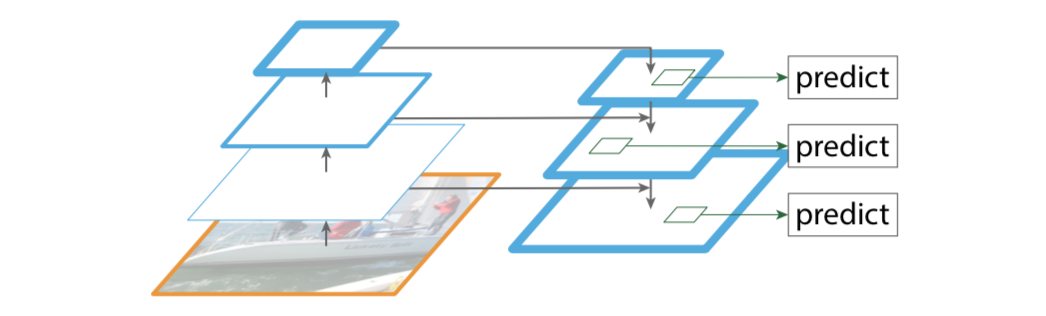
Voie ascendante
La ligne ascendante est le processus de propagation vers l’avant du réseau convolutif. Lors de la propagation vers l'avant, la taille de la carte de caractéristiques peut changer au niveau de certaines couches.
Chemin descendant (ligne descendante) et connexions latérales (liens horizontaux)
La ligne descendante est un processus de suréchantillonnage, tandis que le lien horizontal fusionne les résultats de la ligne descendante avec la structure de la ligne ascendante.
La carte de caractéristiques suréchantillonnée et la carte de caractéristiques sous-échantillonnée de même taille sont ajoutées et fusionnées pixel par pixel (addition élément par élément), où la caractéristique ascendante passe d'abord par 1 × 1 1\times 11×1 couche de convolution, le but est de réduire la dimension du canal.
Demande FPN
Dans l'article, FPN est directement amélioré sur Faster R-CNN et son épine dorsale est ResNet101. FPN est principalement utilisé dans les deux modules RPN et Fast R-CNN dans Faster R-CNN.
FPN+RPN :
En combinant FPN et RPN, l'entrée de RPN deviendra une carte de caractéristiques multi-échelles, et plusieurs couches de tête RPN seront connectées à la sortie de RPN pour satisfaire la classification et la régression des ancres.
FPN + R-CNN rapide :
La logique structurelle globale de Fast R-CNN reste inchangée et l'idée FPN est introduite dans la partie principale de la transformation.
【21】Connaissance connexe du SPP (Spatial Pyramid Pooling)
Dans le domaine de la détection de cibles, de nombreux algorithmes de détection utilisent finalement des couches entièrement connectées, ce qui aboutit à une taille d'entrée fixe. Lorsque vous rencontrez une entrée d'image avec des tailles incompatibles, vous devez utiliser des opérations telles que le recadrage ou la déformation pour faire correspondre la taille de l'image et l'entrée de l'algorithme. Ces deux méthodes peuvent poser des problèmes différents : la zone recadrée peut ne pas contenir la totalité de l'objet ; l'opération de déformation provoque une distorsion géométrique inutile de la cible, etc.
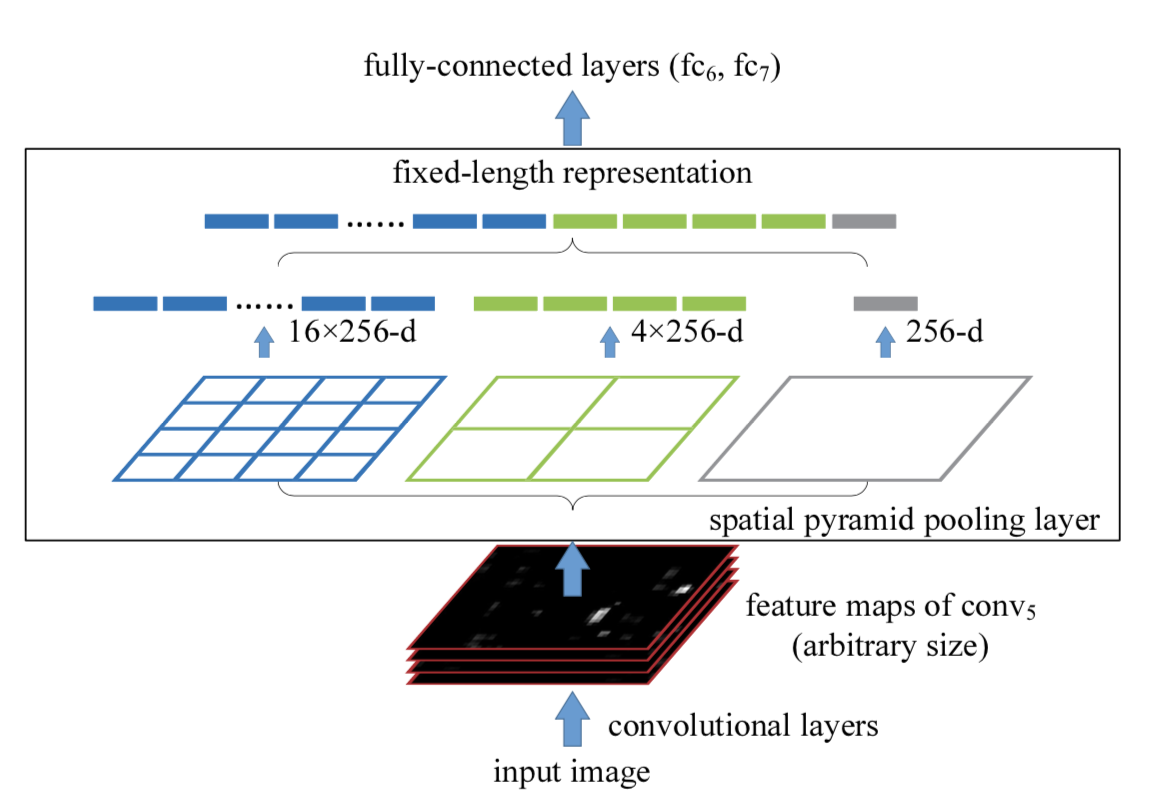
Ce que fait SPP, c'est ajouter une couche SPP après la couche convolutive pour extraire la carte des caractéristiques dans un vecteur de caractéristiques de longueur fixe. Ensuite, le vecteur de caractéristiques est entré dans la couche entièrement connectée . Cela résoudra le problème embarrassant ci-dessus.
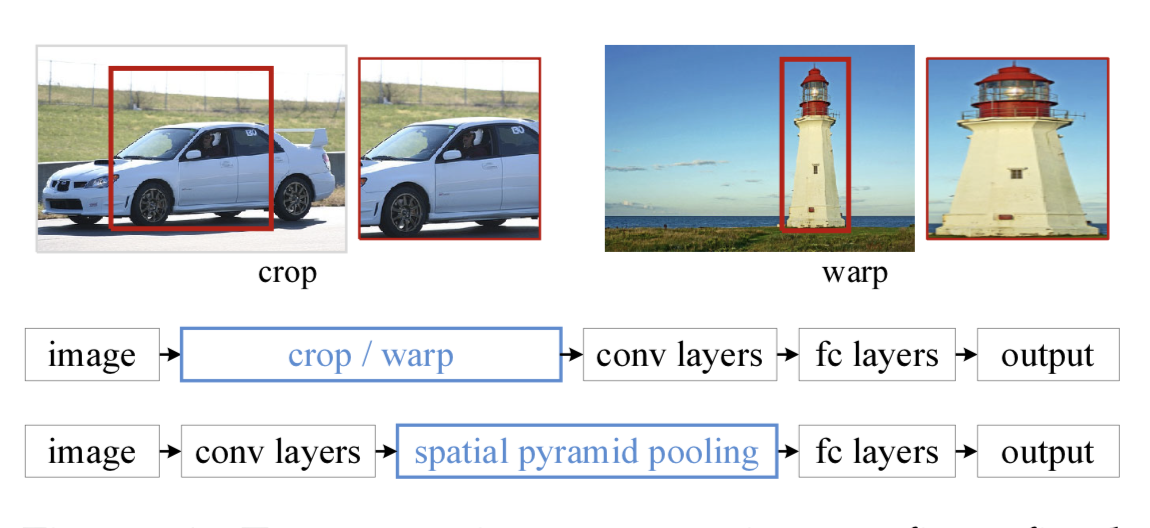
Avantages du SPP :
- SPP peut ignorer les dimensions d'entrée et produire une sortie de longueur fixe.
- SPP utilise des noyaux glissants à plusieurs échelles au lieu d'une seule fenêtre glissante de taille pour la mise en commun.
- SPP extrait les fonctionnalités sur des cartes de fonctionnalités de différentes tailles, augmentant ainsi la richesse des fonctionnalités extraites.
[22] La signification de AP, AP50, AP75, mAP et autres indicateurs dans la détection de cibles
AP : Aire sous la courbe PR.
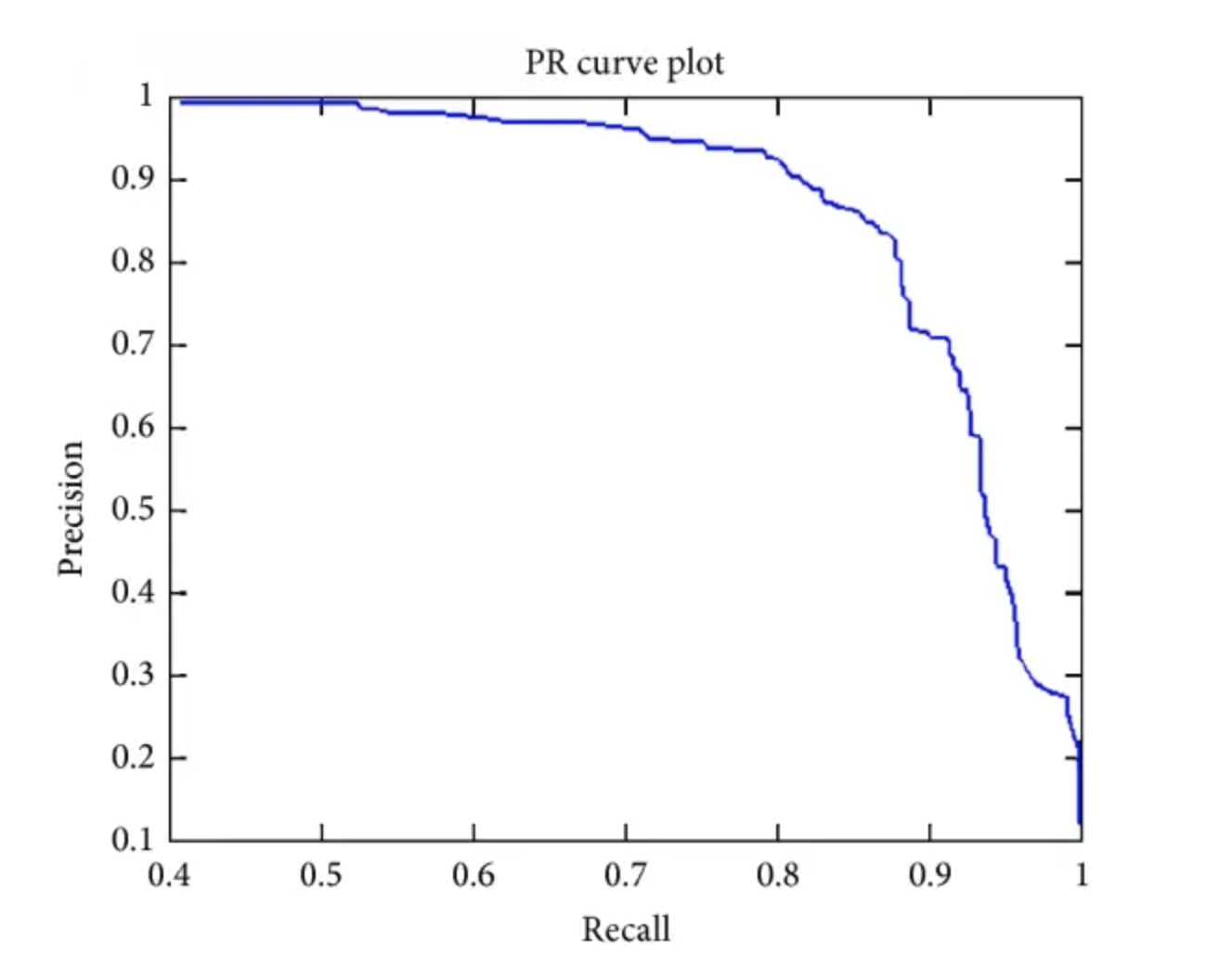
AP50 : la valeur AP lorsque l'IoU fixe est de 50 %.
AP75 : la valeur AP lorsque l'IoU fixe est de 75 %.
AP@[0,5:0,95] : divisez la valeur IoU tous les 5 % de 50 % à 95 % et faites la moyenne de ces 10 ensembles de valeurs AP.
mAP : calculez AP pour toutes les catégories, puis prenez la moyenne.
mAP@[.5:.95] (c'est-à-dire mAP@[.5,.95]) : indique qu'à différents seuils IoU (de 0,5 à 0,95, pas de 0,05) (0,5, 0,55, 0,6, 0,65, 0,7, 0,75 , 0,8, 0,85, 0,9, 0,95).
【23】Comment générer une ancre dans YOLOv2 ?
L'algorithme K-means est introduit dans YOLOv2 pour générer des ancres , qui peuvent automatiquement trouver de meilleures valeurs de largeur et de hauteur d'ancre pour l'initialisation de la formation du modèle.
Cependant, si la distance euclidienne dans les K-means classiques est utilisée comme métrique, cela signifie qu'une ancre plus grande produira une erreur plus importante qu'une ancre plus petite, et les résultats du regroupement peuvent dévier.
Étant donné que la détection de cible se soucie principalement de l'IOU de l'ancre et de la véritable boîte au sol (gt box), elle ne se soucie pas de la taille des deux. Par conséquent, il est plus approprié d'utiliser l'IOU comme métrique, c'est-à-dire d'augmenter la valeur de l'IOU. Par conséquent, YOLOv2 utilise la valeur IOU comme critère :
d ( gtbox , ancre ) = 1 − IOU ( gtbox , ancre ) d (gt box,anchor) = 1 - IOU (gt box,anchor)d ( gtbox , _ _ _ _ancre ) _ _ _=1−I O U ( g t box , _ _ancre ) _ _ _
Les étapes spécifiques de génération d’ancres sont à peu près les mêmes que celles des K-means classiques, qui seront présentées en détail dans le chapitre suivant. La principale différence est que la métrique utilisée est d ( gtbox , Anchor ) d(gt box, Anchor)d ( gtbox , _ _ _ _an c h or ) , et utilisez l’ancre comme centre du cluster.