Reading time: 2023-11-6
1 Introduction
Year: 2022
Author: Wang Lei, School of Automation, Beijing University of Information Science and Technology
Journal: Applied Soft Computing
Citations: 12
A self-organizing modular echo state (PDSM-ESN) network based on pseudo-inverse decomposition is proposed. The network is constructed via a grow-pruning approach, using errors and condition numbers to determine the structure of the reservoir. The authors also adopted a pseudo-inverse decomposition method to improve the learning speed of the network. Furthermore, the paper discusses ill-conditioned problems in ESN and proposes solutions such as pruning modular sub-reservoirs with high condition numbers.
2 innovation points
(1) A self-organizing modular echo state network (PDSM-ESN) based on pseudo-inverse decomposition is proposed. This network is constructed using a growing-pruning approach that uses errors and condition numbers to determine the structure of the reservoir. At the same time, a pseudo-inverse decomposition method is used to improve the learning speed of the network.
(2) Solve the ill-posed problem in Echo State Network (ESN). Some solutions are proposed in the paper, such as pruning modular subreservoirs with high condition numbers.
(3) The simulation experimental results show that PDSM-ESN is superior to the traditional ESN model in terms of prediction performance and runtime complexity. This provides implications for improving the design and performance of echo state networks for time series prediction.
3 Related research
summarized that ESN has two main shortcomings:
(1) Due to the black-box nature of the reservoir, many performance attributes are difficult to understand. So it takes a lot of experimentation and even some luck. Network performance is highly dependent on the number of reservoir neurons, thus requiring an appropriate reservoir structure that matches the specific task [26, 27].
In order to design an appropriate reservoir, some models have been proposed, including deterministic reservoir [, Minimum complexity echo state network] [Decoupled echo state networks with lateral inhibition], growth method [Growing echo-state network with multiple subreservoirs], pruning method [Pruning and regularization in reservoir computing] [Improved simple deterministically constructed cycle reservoir network with sensitive iterative pruning algorithm], evolutionary method [Echo state networks with orthogonal pigeon-inspired optimization for image restoration] [PSO-based growing echo state network,] and hybrid ESN [2021- Convolutional multitimescale echo state network] [2021-Echo memory-augmented network for time series classification].
(2) The output weights are learned through the least square error (LSE) method, so ill-conditioned problems may occur. Once this happens, large output weights will be generated, affecting the generalization ability [28, 29].
In order to solve ill-conditioned problems, some regularization methods, such as L1 regularization, L2 regularization and hybrid regularization, have been used to enhance generalization ability. L1 regularization methods, including lasso[38], adaptive lasso[2019-Adaptive lasso echo state network based on modified Bayesian information criterion for nonlinear system modeling] and adaptive elastic network[Adaptive elastic echo state network for multivariate time series prediction] , a sparse prediction model can be obtained. L2 regularization has smooth characteristics and cannot obtain sparse prediction models [32]. Hybrid regularization can take advantage of different regularizations to train ESN [2019-Hybrid regularized echo state network for multivariate chaotic time series prediction].
4 Algorithms
PDSM-ESN has a growth-pruning stage with errors and condition numbers, which can effectively solve structural design and ill-conditioned problems. At the same time, pseudo-inverse decomposition is used to improve the learning speed, so the output weights are learned through an iterative incremental method.
(1) Growing phase: In the growth phase, modular sub-reservoirs are constructed by using the singular value decomposition (SVD) method, and the modular sub-reservoirs are added block by block. into the network until the stopping criterion is met. In the growth phase, the pseudo-inverse decomposition method is also used to train the output weights. The purpose of the growth phase is to optimize structural design and enhance generalization capabilities.
(2) Pruning phase: The pruning phase mainly includes two stages. The first stage is to prune linearly related modular subreservoirs using condition numbers. The second stage is to calculate the pseudo-inverse matrix using an iterative matrix factorization method, which is similar to the growth stage. In the pruning stage, problematic modular subreservoirs that result in large condition numbers are pruned based on the condition number. The purpose of the pruning stage is to prune redundant sub-reservoirs and enhance the generalization ability of ESN.
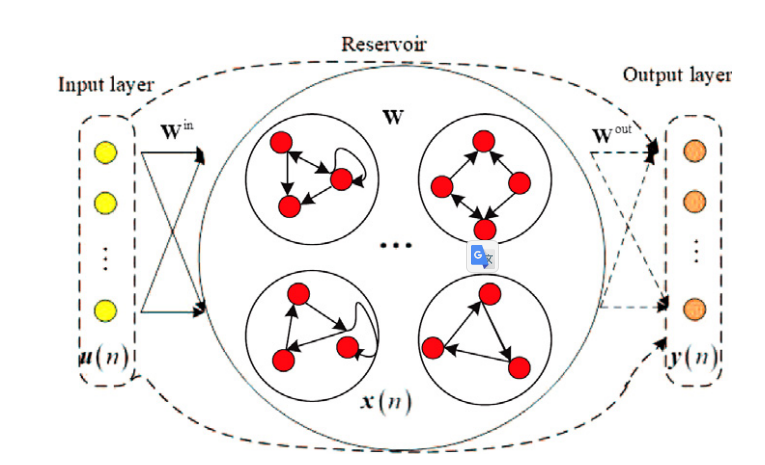
5 Experimental analysis
(1) Tested on Mackey-Glass data set
- PDSM-ESN has better performance in Mackey-Glass time series prediction. Compared with traditional ESN, PDSM-ESN has better prediction accuracy and smaller test error.
- The performance of PDSM-ESN under different sub-reservoir sizes is affected by the sub-reservoir size. Experimental results show that PDSM-ESN has the best performance when the sub-reservoir size is 5.
- PDSM-ESN has high robustness in Mackey-Glass time series forecasting. Experimental results under different thresholds show that when the threshold is about 0.002, the successful design rate of PDSM-ESN is about two times higher than that of ESN.
- PDSM-ESN has a compact network structure, the shortest training time, and good prediction performance and generalization ability.
(2) Test on Henon map data set
In 50 independent experiments, when the threshold η is greater than 0.003, the successful design rate of PDSM-ESN is higher than that of OESN. When the threshold eta reaches 0.007, the successful design rates of PDSM-ESN and OESN are 95% and 50% respectively, which means that PDSM-ESN is more robust than OESN. During the self-organization process of PDSM-ESN (as shown in Figure 14), the size of the reservoir will increase or decrease, so the condition number of the internal state matrix will also change.
(3) Prediction of ammonia nitrogen concentration in water treatment plants
- NH4-N concentration is an important parameter for assessing water quality in wastewater treatment plants. Excessive discharge of NH4-N may lead to eutrophication of water bodies. Due to economic conditions or detection technology limitations, NH4-N concentration is difficult to detect through detection instruments, so soft measurement methods need to be used for prediction.
- By using the proposed DLSBESN method to predict NH4-N concentration, the experimental results show that the prediction error of PDSM-ESN is significantly lower than that of OESN. The prediction error range of PDSM-ESN is [-0.2, 0.2], while that of OESN is [-0.9, 1.4].
- The rendering shows that PDSM-ESN's prediction of wastewater NH4-N concentration is very close to the actual observed value, and the coefficient of determination R2 is 0.9969, indicating that PDSM-ESN has high prediction accuracy.
- The successful design ratio of PDSM-ESN is always higher than that of OESN, which indicates that PDSM-ESN is more robust.
- During the self-organization process (as shown in Figure 24), the condition number of the internal state matrix first increases and then decreases. When the reservoir size is 115, the condition number reaches its maximum value, while when the reservoir size is 40, the condition number is relatively small. Therefore, PDSM-ESN alleviates the pathological problem.
6 thoughts
This paper gives a detailed algorithm reasoning process and proves the feasibility of the generation-pruning theory on ESN. And from three data sets, the effectiveness of the improved ESN is proved. The generation process is to first initialize many reservoir sub-modules, and then delete redundant sub-modules to retain the best reservoir structure.