
In diesem Artikel untersuchen wir eingehend die theoretischen Grundlagen, Kernkonzepte und die Anwendung des Apriori-Algorithmus bei praktischen Problemen. Der Artikel analysiert nicht nur umfassend den Funktionsmechanismus des Algorithmus, sondern demonstriert auch spezifische praktische Anwendungen anhand von Python-Codefragmenten. Darüber hinaus haben wir Optimierungslösungen und Erweiterungsmethoden für die Leistungsbeschränkungen des Algorithmus in der Big-Data-Umgebung vorgeschlagen und schließlich einzigartige technische Erkenntnisse gewonnen.
Folgen Sie TechLead und teilen Sie umfassendes Wissen über KI. Der Autor verfügt über mehr als 10 Jahre Erfahrung in der Architektur von Internetdiensten, Erfahrung in der Entwicklung von KI-Produkten und Erfahrung im Teammanagement. Er hat einen Master-Abschluss der Tongji-Universität der Fudan-Universität, ist Mitglied des Fudan Robot Intelligence Laboratory und ein von Alibaba Cloud zertifizierter leitender Architekt Projektmanagementprofi sowie Forschung und Entwicklung von KI-Produkten mit einem Umsatz von Hunderten von Millionen. Auftraggeber.

1. Einleitung
Der Apriori-Algorithmus ist ein Algorithmus, mit dem häufige Elementmengen in Datensätzen ermittelt und anschließend Assoziationsregeln generiert werden. Dieser Algorithmus findet breite Anwendung in vielen Bereichen wie Data Mining, maschinelles Lernen, Warenkorbanalyse usw.
Was ist Association Rule Mining?
Association Rule Mining ist ein wichtiger Zweig des Data Mining, dessen Ziel darin besteht, interessante Assoziationen oder Muster zwischen Variablen in einem Datensatz zu entdecken.
Beispiel: Nehmen wir an, dass in den Transaktionsdaten eines Einzelhändlers ein Kunde, der Bier kauft, wahrscheinlich auch Kartoffelchips kauft. Hier bilden „Bier“ und „Kartoffelchips“ eine Assoziationsregel.
Was ist ein häufiges Itemset?
Ein häufiger Artikelsatz ist ein Satz von Artikeln, die größer oder gleich dem Mindestunterstützungsschwellenwert im Datensatz sind.
Beispiel: Wenn in den Supermarkt-Einkaufsdaten die Kombination „Milch“ und „Brot“ oft zusammen im selben Warenkorb erscheint und die Häufigkeit des Vorkommens die Mindestunterstützung überschreitet, dann ist {„Milch“, „Brot“} eine Häufigkeit Artikelsatz.
Was sind Unterstützung und Vertrauen?
-
Unterstützung: Dies ist die Häufigkeit, mit der ein Artikelsatz in allen Transaktionen erscheint. Es wird verwendet, um die Allgemeingültigkeit einer Artikelmenge zu messen.
Beispiel: Wenn wir 100 Transaktionen haben und 30 davon „Milch“ enthalten, dann beträgt die Unterstützung von „Milch“ 30 %.
-
Vertrauen: Es ist die bedingte Wahrscheinlichkeit, dass B erscheint, wenn A erscheint.
Beispiel: Wenn 70 % aller Transaktionen, die „Milch“ enthalten, auch „Brot“ enthalten, beträgt das Konfidenzniveau von „Milch“ zu „Brot“ 70 %.
Die Bedeutung des Apriori-Algorithmus
Der Apriori-Algorithmus wird aufgrund seiner Einfachheit und Effizienz häufig im Data Mining eingesetzt. Es kann nicht nur zum Aufspüren versteckter Muster in Daten verwendet werden, sondern kann auch in mehreren Anwendungsszenarien wie Produktempfehlungen, Benutzerverhaltensanalysen und Netzwerksicherheit eingesetzt werden.
Beispiel: Auf E-Commerce-Websites kann der Apriori-Algorithmus zur Analyse der Kaufhistoriendaten der Benutzer verwendet werden, um personalisierte Empfehlungen zu erhalten und den Umsatz und die Benutzerzufriedenheit zu steigern.
Anwendungsszenarien
Aufgrund seines breiten Einsatzspektrums und seiner Flexibilität findet der Apriori-Algorithmus breite Anwendungsmöglichkeiten in den folgenden Hauptbereichen:
-
Warenkorbanalyse: Verstehen Sie, welche Produkte häufig zusammen gekauft werden, um effektive Produktplatzierungs- oder Werbestrategien zu erzielen.
-
Medizinische Diagnostik: Analysieren Sie historische Patientendaten, um Zusammenhänge zwischen Erkrankungen und Behandlungsoptionen zu finden.
-
Netzwerksicherheit: Analysieren Sie Netzwerkprotokolle, um ungewöhnliche Muster zu finden und Sicherheitsbedrohungen zu verhindern oder zu erkennen.
Durch diese Definitionen und Beispiele können wir ein umfassenderes Verständnis der Grundkonzepte, der Bedeutung und des Anwendungsbereichs des Apriori-Algorithmus erlangen und so eine solide Grundlage für nachfolgende technische Analysen und praktische Anwendungen legen.
2. Theoretische Grundlage
Bevor wir uns mit dem Apriori-Algorithmus befassen, ist es wichtig, die theoretischen Grundlagen dahinter zu verstehen. In diesem Abschnitt werden die grundlegenden Konzepte des Assoziationsregel-Minings, einschließlich Itemsets, Support, Confidence und Lift, ausführlich vorgestellt und erläutert, wie diese Konzepte zum Mining nützlicher Assoziationsregeln verwendet werden.
Artikel und Artikelsätze
-
Element: Beim Assoziationsregel-Mining bezieht sich ein Element normalerweise auf ein Element im Datensatz.
Beispiel: In einem Supermarkt-Einkaufskorb sind die Daten „Milch“, „Brot“, „Bier“ usw. alles einzelne Artikel.
-
Itemset: Es handelt sich um eine Sammlung von Elementen, die ein oder mehrere Elemente enthalten können.
Beispiel: {"Milch", "Bread"} und {"Beer", "Potato Chips", "Bread"} sind beide Itemsets.
Unterstützung
Die Unterstützung ist ein Maß dafür, wie oft ein Elementsatz im gesamten Datensatz vorkommt.
! Datei
{kind=link}
Vertrauen
Konfidenz stellt die Wahrscheinlichkeit dar, dass es unter allen Transaktionen, die den Artikelsatz X enthalten, auch eine Transaktion gibt, die den Artikelsatz Y enthält.

Aufzug
Lift wird verwendet, um zu messen, ob die Vorkommen der Itemsets X und Y unabhängig voneinander sind.

Apriori-Prinzip
Das Apriori-Prinzip stellt den Kern des Apriori-Algorithmus dar. Es basiert auf einer einfachen, aber wichtigen Beobachtung: Wenn eine Elementmenge häufig ist, müssen auch alle ihre Teilmengen häufig sein.
Beispiel: Wenn {"Milch", "Bread", "Beer"} eine häufige Elementmenge ist, dann {"Milk", "Bread"}, {"Milk", "Beer"} und {"Bread", "Beer" "} muss ebenfalls ein häufiges Itemset sein.
Durch die oben genannten Konzepte und Beispiele sollten wir ein tieferes Verständnis der grundlegenden Theorie des Association Rule Mining erlangen. Dies bildet eine solide Grundlage für unsere anschließende ausführliche Erläuterung des Apriori-Algorithmus und seiner praktischen Anwendung.
3. Überblick über den Apriori-Algorithmus
Der Apriori-Algorithmus wurde 1994 von Agrawal und Srikant vorgeschlagen, um häufige Elementmengen effizient zu durchsuchen und Assoziationsregeln zu generieren. Sein Name „Apriori“ kommt aus dem Lateinischen und bedeutet „aus apriorischem Wissen“. Dies spiegelt gut die Kernidee des Algorithmus wider: die Verwendung bekannter häufiger Itemsets (d. h. Vorwissen), um größere häufige Itemsets effizienter zu finden.
Algorithmusschritte
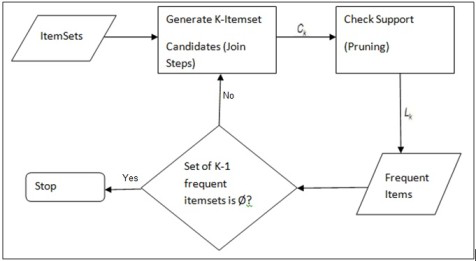
Der Ausführungsprozess des Apriori-Algorithmus besteht hauptsächlich aus zwei Schritten:
-
Häufige Itemset-Generierung: Finden Sie alle häufigen Itemsets, die den Mindestunterstützungsschwellenwert erfüllen.
-
Generierung von Assoziationsregeln: Generieren Sie Assoziationsregeln mit hoher Zuverlässigkeit aus häufigen Elementmengen.
Häufige Itemset-Generierung
- Scannen Sie den Datensatz, um die Unterstützung aller einzelnen Elemente zu ermitteln, und filtern Sie die Elemente heraus, die die Mindestunterstützung erfüllen.
- Generieren Sie einen neuen Satz Kandidatenelemente mit Elementen, die die Mindestunterstützung erfüllen.
- Berechnen Sie die Unterstützung des neu generierten Kandidaten-Itemsets und filtern Sie erneut.
- Wiederholen Sie die obigen Schritte, bis keine neuen häufigen Itemsets generiert werden können.
Beispiel: Angenommen, es gibt einen Einkaufstransaktionsdatensatz, der 5 Transaktionen umfasst. Der erste Schritt besteht darin, die Anzahl der Vorkommen aller einzelnen Produkte (z. B. „Milch“, „Brot“ usw.) in diesen 5 Transaktionen zu zählen und diejenigen Produkte herauszufiltern, deren Vorkommen die Mindestunterstützung erreichen.
Generierung von Assoziationsregeln
- Generieren Sie für jede häufige Elementmenge alle möglichen nicht leeren Teilmengen.
- Berechnen Sie für jede generierte Regel ( A \Rightarrow B ) deren Konfidenz.
- Eine Regel ist eine gültige Assoziationsregel, wenn ihre Konfidenz die Mindestkonfidenzanforderung erfüllt.
Beispiel: Für das häufige Itemset {„Milch“, „Brot“, „Butter“} sind mögliche Regeln „Milch, Brot->Butter“, „Milch, Butter->Brot“ usw. Berechnen Sie die Konfidenz dieser Regeln und filtern Sie die Regeln heraus, die die Mindestkonfidenz erfüllen.
Vorteile und Nachteile
Vorteil
- Einfach und leicht verständlich: Der Apriori-Algorithmus basiert auf intuitiven Prinzipien und verfügt über einen einfachen Berechnungsprozess.
- Starke Skalierbarkeit: Der Algorithmus kann auf große Datensätze angewendet werden.
Mangel
- Rechenintensiv: Bei großen Datensätzen muss möglicherweise eine große Anzahl von Kandidatensätzen generiert werden.
- Mehrmaliges Scannen der Daten: Der Algorithmus muss den Datensatz mehrmals scannen, um die Unterstützung des Itemsets zu berechnen, was bei großen Datensätzen ineffizient sein kann.
Beispiel: Auf einer E-Commerce-Website mit Millionen von Transaktionsdaten kann die Verwendung des Apriori-Algorithmus viel Rechenressourcen und Zeit in Anspruch nehmen.
Durch die obige detaillierte Beschreibung und die Beispiele sollten wir ein umfassendes und tiefgreifendes Verständnis des Apriori-Algorithmus erlangen. Damit wurde der Grundstein für unsere spätere technische Analyse und praktische Anwendung gelegt.
4. Praktische Anwendung
Nachdem wir die theoretischen Grundlagen und das Funktionsprinzip des Apriori-Algorithmus verstanden haben, werden wir nun seine Anwendung in praktischen Szenarien weiter untersuchen. Vor allem in Warenkorbanalyse- und Empfehlungssystemen findet der Apriori-Algorithmus breite Anwendung.
Um dies besser zu veranschaulichen, wird im Folgenden gezeigt, wie der Apriori-Algorithmus mit Python implementiert und anhand eines einfachen Einkaufsdatensatzes demonstriert wird.
Warenkorbanalyse
Die Warenkorbanalyse ist eine sehr beliebte Technik im Einzelhandel, mit der Assoziationsregeln zwischen von Kunden gekauften Produkten ermittelt werden.
Eingabe und Ausgabe
- Eingabe: Eine Reihe von Transaktionsdaten. Jede Transaktion enthält mehrere gekaufte Artikel.
- Ausgabe: Assoziationsregeln, die Mindestunterstützung und Mindestkonfidenz erfüllen.
Python-Implementierungscode
Importieren Sie zunächst die notwendigen Bibliotheken:
from itertools import chain, combinations
Definieren Sie dann mehrere Hilfsfunktionen:
# 生成候选项集的所有非空子集
def powerset(s):
return chain.from_iterable(combinations(s, r) for r in range(1, len(s)))
# 计算支持度
def calculate_support(itemset, transactions):
return sum(1 for transaction in transactions if itemset.issubset(transaction)) / len(transactions)
Jetzt implementieren wir den Apriori-Algorithmus:
def apriori(transactions, min_support, min_confidence):
# 初始化频繁项集和关联规则列表
frequent_itemsets = []
association_rules = []
# 第一步:找出单项频繁项集
singletons = {frozenset([item]) for transaction in transactions for item in transaction}
singletons = {itemset for itemset in singletons if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(singletons)
# 迭代找出所有其他频繁项集
prev_frequent_itemsets = singletons
while prev_frequent_itemsets:
# 生成新的候选项集
candidates = {itemset1 | itemset2 for itemset1 in prev_frequent_itemsets for itemset2 in prev_frequent_itemsets if len(itemset1 | itemset2) == len(itemset1) + 1}
# 计算支持度并筛选
new_frequent_itemsets = {itemset for itemset in candidates if calculate_support(itemset, transactions) >= min_support}
frequent_itemsets.extend(new_frequent_itemsets)
# 生成关联规则
for itemset in new_frequent_itemsets:
for subset in powerset(itemset):
subset = frozenset(subset)
diff = itemset - subset
if diff:
confidence = calculate_support(itemset, transactions) / calculate_support(subset, transactions)
if confidence >= min_confidence:
association_rules.append((subset, diff, confidence))
prev_frequent_itemsets = new_frequent_itemsets
return frequent_itemsets, association_rules
Beispiele und Ausgabe
Nehmen wir an, wir haben den folgenden einfachen Einkaufsdatensatz:
transactions = [
{'牛奶', '面包', '黄油'},
{'啤酒', '面包'},
{'牛奶', '啤酒', '黄油'},
{'牛奶', '鸡蛋'},
{'面包', '鸡蛋', '黄油'}
]
Rufen Sie den Apriori-Algorithmus auf:
min_support = 0.4
min_confidence = 0.5
frequent_itemsets, association_rules = apriori(transactions, min_support, min_confidence)
print("频繁项集:", frequent_itemsets)
print("关联规则:", association_rules)
Die Ausgabe könnte wie folgt aussehen:
频繁项集: [{'牛奶'}, {'面包'}, {'黄油'}, {'啤酒'}, {'鸡蛋'}, {'牛奶', '面包'}, {'牛奶', '黄油'}, {'面包', '黄油'}, {'啤酒', '黄油'}, {'面包', '啤酒'}]
关联规则: [(('牛奶',), ('面包',), 0.6666666666666666), (('面包',), ('牛奶',), 0.6666666666666666), ...]
Durch diese praktische Anwendung haben wir nicht nur gelernt, wie man den Apriori-Algorithmus in Python implementiert, sondern auch seine spezifische Anwendung in der Warenkorbanalyse kennengelernt. Dies bietet nützliche Hinweise für weitere Forschung und praktische Anwendungen.
5. Leistungsoptimierung und -erweiterung
Obwohl der Apriori-Algorithmus in vielen Bereichen weit verbreitet ist, ist seine Leistung bei großen Datenmengen nicht zufriedenstellend. Dies liegt daran, dass mehrere Scans des Datensatzes und die Generierung einer großen Anzahl von Kandidatensätzen erforderlich sind. In diesem Abschnitt diskutieren wir Lösungen zur Leistungsoptimierung und Erweiterungsmethoden für diese Probleme.
Optimierungsstrategie
Zu den wichtigsten Methoden zur Optimierung des Apriori-Algorithmus gehören:
Reduzieren Sie die Anzahl der Datenscans
Da der Apriori-Algorithmus zur Berechnung der Unterstützung in jeder Runde den gesamten Datensatz scannen muss, besteht eine intuitive Optimierungsmethode darin, die Anzahl der Datenscans zu reduzieren.
Beispiel: Durch die Erstellung eines invertierten Transaktions-Element-Index können Sie die Unterstützung jedes Elementsatzes sofort nach einem einzelnen Datensatz-Scan finden.
Verwendung von Datenkomprimierungstechnologie
Der Rechenaufwand kann durch die Komprimierung von Transaktionsdaten reduziert werden, beispielsweise durch die Verwendung von Bitvektoren zur Darstellung von Transaktionen.
Beispiel: Wenn der Datensatz 100 Elemente enthält, kann jede Transaktion durch einen 100-Bit-Bitvektor dargestellt werden. Dieser Ansatz kann den Datenspeicherbedarf erheblich reduzieren.
Nutzen Sie die Hashing-Technologie
Die Berechnung der Unterstützung kann beschleunigt werden, indem eine Hash-Tabelle zum Speichern von Kandidatensätzen und deren Anzahl verwendet wird.
Beispiel: Beim Generieren eines Kandidaten-Itemsets kann eine Hash-Funktion verwendet werden, um das Itemset einer Position in der Hash-Tabelle zuzuordnen und die entsprechende Anzahl an dieser Position zu erhöhen.
Erweiterungsmethode
Parallelisierung
Der Apriori-Algorithmus kann durch Daten- oder Aufgabenparallelisierung erweitert werden, um die Vorteile von Multiprozessoren oder verteilten Computerumgebungen zu nutzen.
Beispiel: In einem verteilten System kann der Datensatz in mehrere Teilmengen unterteilt werden und die Unterstützungs- und häufigen Elementmengen können auf jedem Knoten parallel berechnet werden.
Unterstützen Sie den ungefähren Bergbau
Für einige Anwendungsszenarien ist möglicherweise kein vollständig genaues, häufiges Itemset-Mining erforderlich. In diesem Fall können Näherungsalgorithmen eingesetzt werden, um die Berechnung zu beschleunigen.
Beispiel: Verwenden Sie die Monte-Carlo-Methode oder andere Zufallsstichprobentechniken, um häufige Itemsets für den gesamten Datensatz anhand von Teildaten zu schätzen.
Integrieren Sie andere Data-Mining-Algorithmen
Der Apriori-Algorithmus kann in Verbindung mit anderen Data-Mining- oder Machine-Learning-Algorithmen verwendet werden, um komplexere Probleme zu lösen.
Beispiel: In einem Empfehlungssystem kann zusätzlich zur Verwendung des Apriori-Algorithmus zum Auffinden häufiger Elementmengen auch ein Clustering-Algorithmus zum Gruppieren von Benutzern verwendet werden, um personalisiertere Empfehlungen zu erhalten.
Durch diese Optimierungs- und Erweiterungsmethoden können wir nicht nur die Leistung des Apriori-Algorithmus in Big-Data-Umgebungen verbessern, sondern auch seinen Anwendungsbereich erweitern. Diese bieten nützliche Hinweise für weitere Forschung und Anwendungen.
6. Zusammenfassung
Durch die Diskussion in diesem Artikel verfügen wir nicht nur über ein umfassendes und tiefgreifendes Verständnis des Apriori-Algorithmus, sondern beherrschen auch dessen Anwendung in praktischen Problemen, insbesondere in Warenkorbanalysen und Empfehlungssystemen. Wir haben jedoch auch die Einschränkungen dieses Algorithmus bei großen Datenmengen festgestellt.
technische Einblicke
-
Balance zwischen Unterstützung und Vertrauen: In praktischen Anwendungen ist die Auswahl geeigneter Unterstützungs- und Vertrauensschwellen eine Kunst. Ein zu niedriger Schwellenwert kann zu einer großen Anzahl unbedeutender Assoziationsregeln führen, während bei einem zu hohen Schwellenwert möglicherweise einige nützliche Regeln fehlen.
-
Echtzeitprobleme: Bei sich dynamisch ändernden Datensätzen ist auch die Implementierung einer Echtzeit- oder nahezu Echtzeitanalyse des Apriori-Algorithmus ein Thema, das Aufmerksamkeit verdient. Dies ist besonders wichtig in reaktionsschnellen Szenarien wie dem E-Commerce.
-
Mehrdimensionale und mehrschichtige Analyse: Der bestehende Apriori-Algorithmus konzentriert sich hauptsächlich auf die Ebene einzelner Elementmengen. In Zukunft können wir überlegen, wie wir ihn auf mehrdimensionales oder mehrschichtiges Assoziationsregel-Mining erweitern können.
-
Integration von Algorithmen und Modellen: Zukünftige Forschungstrends könnten sich stärker auf die Integration von Association Rule Mining mit anderen Modellen des maschinellen Lernens (wie neuronalen Netzen, Entscheidungsbäumen usw.) konzentrieren, um komplexere Probleme zu lösen.
In zukünftigen Arbeiten werden die Erforschung der Relevanz und des Anwendungswerts dieser technischen Erkenntnisse sowie eine engere Integration des Apriori-Algorithmus mit modernen Computerarchitekturen (wie GPUs, verteiltes Rechnen usw.) wichtige Forschungsrichtungen sein.
Kurz gesagt, der Apriori-Algorithmus hat breite Anwendungsaussichten in den Bereichen Data Mining und Korrelationsanalyse. Damit es sich jedoch besser an den Umfang und die Komplexität moderner Daten anpassen kann, sind weitere Forschungs- und Forschungsarbeiten zur Algorithmusoptimierung und Anwendungserweiterung erforderlich. Ich hoffe, dass dieser Artikel nützliche Informationen und Inspiration für Ihr Studium und Ihre Bewerbung in diesem Bereich liefern kann.
Microsoft startet neue „Windows App“ .NET 8 offiziell GA, die neueste LTS-Version Xiaomi gab offiziell bekannt, dass Xiaomi Vela vollständig Open Source ist und der zugrunde liegende Kernel NuttX Alibaba Cloud 11.12 ist. Die Ursache des Fehlers wurde offengelegt: Access Key Service (Access Schlüssel) Ausnahme Vite 5 offiziell veröffentlichter GitHub-Bericht: TypeScript ersetzt Java und wird zur drittbeliebtesten Sprache. Bietet eine Belohnung von Hunderttausenden Dollar für das Umschreiben von Prettier in Rust. Den Open-Source-Autor fragen: „Ist das Projekt noch am Leben?“ Sehr unhöflich und respektloses Bytedance: Verwendung von KI zur automatischen Optimierung von Linux-Kernel-Parameteroperatoren. Zauberoperation: Trennen Sie das Netzwerk im Hintergrund, deaktivieren Sie das Breitbandkonto und zwingen Sie den Benutzer, das optische Modem zu wechselnFolgen Sie TechLead und teilen Sie umfassendes Wissen über KI. Der Autor verfügt über mehr als 10 Jahre Erfahrung in der Architektur von Internetdiensten, Erfahrung in der Entwicklung von KI-Produkten und Erfahrung im Teammanagement. Er hat einen Master-Abschluss der Tongji-Universität der Fudan-Universität, ist Mitglied des Fudan Robot Intelligence Laboratory und ein von Alibaba Cloud zertifizierter leitender Architekt Projektmanagementprofi sowie Forschung und Entwicklung von KI-Produkten mit einem Umsatz von Hunderten von Millionen. Auftraggeber. Wenn es hilft, schenken Sie TeahLead KrisChang bitte mehr Aufmerksamkeit, mehr als 10 Jahre Erfahrung in der Internet- und Künstliche-Intelligenz-Branche, mehr als 10 Jahre Erfahrung im technischen und geschäftlichen Teammanagement, Bachelor-Abschluss in Software-Engineering von Tongji, Master-Abschluss in Engineering Management aus Fudan, Alibaba Cloud-zertifizierter Senior-Architekt für Cloud-Dienste, Leiter des KI-Produktgeschäfts mit einem Umsatz von über 100 Millionen.