zookeeper - estrutura de coordenação de serviços distribuídos
- 1. Visão geral do Zookeeper
- 2. Instalação e implantação do Zookeeper
- 3. O princípio de implementação interna do zookeeper
- 4. Operação de linha de comando do cliente Zookeeper
- 5. Construção de cluster HA-Hadoop de alta disponibilidade
- 6. Configuração YARN-HA
- 7. Como usar o programa MR para contar palavras em um ambiente de alta disponibilidade
1. Visão geral do Zookeeper
1. Conceitos básicos do Zookeeper
- Zookeeper é um projeto Apache distribuído de código aberto que fornece serviços de coordenação para aplicativos distribuídos.
- Zookeeper é entendido sob a perspectiva do padrão de design: é uma estrutura de gerenciamento de serviços distribuídos projetada com base no padrão observador. É responsável por armazenar e gerenciar dados que interessam a todos e, em seguida, aceita o registro de observadores. Uma vez que o status destes alterações de dados, Zookeeper Será responsável por notificar os observadores registrados no Zookeeper para responderem adequadamente, alcançando assim um modelo de gerenciamento Mestre/Escravo semelhante no cluster.
- Zookeeper = sistema de arquivos + mecanismo de notificação
2. Recursos do Zookeeper
- Zookeeper: um líder e um grupo de seguidores.
- O Líder é responsável por iniciar e tomar decisões sobre votação e atualizar o status do sistema.
- O Seguidor é utilizado para receber solicitações do cliente e retornar resultados ao cliente, além de participar da votação durante a eleição do Líder.
- Contanto que mais da metade dos nós do grupo sobrevivam, o cluster Zookeeper pode servir normalmente.
- Consistência global de dados: Cada servidor salva uma cópia dos mesmos dados. Não importa a qual servidor o cliente se conecte, os dados são consistentes.
- As solicitações de atualização são executadas sequencialmente e as solicitações de atualização do mesmo cliente são executadas sequencialmente na ordem em que são enviadas.
- A atualização de dados é atômica, uma atualização de dados é bem-sucedida ou falha.
- Em tempo real, dentro de um determinado intervalo de tempo, o cliente pode ler os dados mais recentes.
3. Estrutura de dados do Zookeeper
- A estrutura do modelo de dados ZooKeeper é muito semelhante ao sistema de arquivos Unix, pode ser considerada como uma árvore como um todo, e cada nó é chamado de ZNode.

- O próprio cluster Zookeeper mantém um conjunto de estruturas de dados. Esta estrutura de armazenamento é uma estrutura de árvore, e cada nó nela é chamado de "znode".Diferente dos nós da árvore, o método de referência Znode é uma referência de caminho, semelhante ao caminho do arquivo: /znode1/leaf1
- Essa estrutura hierárquica permite que cada nó Znode tenha um caminho único, que isola claramente diferentes informações, assim como um namespace.
- Os nós do ZooKeeper são mantidos por meio de uma estrutura semelhante a uma árvore, e cada nó é marcado e acessado por meio de um caminho.
- Além disso, cada nó também possui algumas informações próprias, incluindo: dados, comprimento dos dados, hora de criação, hora de modificação, etc.
- A partir das características de um nó que contém dados e é marcado como uma tabela de caminhos, pode-se observar que um nó ZooKeeper pode ser considerado um arquivo ou um diretório e possui as características de ambos. Para facilitar a expressão, usaremos Znode para representar o nó ZooKeeper em questão no futuro.
- Cada znode pode armazenar 1 MB de dados por padrão
- Um znode é criado pelo cliente. Seu relacionamento intrínseco com o cliente que o criou determina sua existência. Geralmente, existem quatro tipos de nós:
- PERSISTENTE - Nó persistente : Após o cliente que criou este nó se desconectar do serviço zookeeper, este nó não será excluído (a menos que seja forçado a ser excluído usando a API)
- PERSISTENT_SEQUENTIAL - Nó de número sequencial persistente : quando o cliente solicita a criação deste nó A, o zookeeper escreverá um número exclusivo para todo o diretório para este nó A com base no status zxid do pai-znode (esse número continuará crescendo). Quando o cliente for desconectado do serviço zookeeper, o nó não será excluído.
- Nó de diretório temporário EPHEMERAL : depois que o cliente que criou esse nó se desconectar do serviço zookeeper, esse nó (e os nós filhos envolvidos) serão excluídos.
- EPHEMERAL_SEQUENTIAL - Nó de diretório de número sequencial temporário : Quando o cliente solicita a criação deste nó A, o zookeeper escreverá um número exclusivo para todo o diretório para este nó A com base no status zxid do pai-znode (esse número continuará crescendo). Quando o cliente que criou o nó se desconecta do serviço zookeeper, o nó é excluído.
- [Nota] : Não importa se é um tipo de nó EPHEMERAL ou EPHEMERAL_SEQUENTIAL, o nó também será excluído após o cliente zookeeper terminar de forma anormal.
2. Instalação e implantação do Zookeeper
1. Baixe o Zookeeper
No site oficial do Zookeeper , selecione a versão que deseja baixar. A seguir está a versão que baixei.
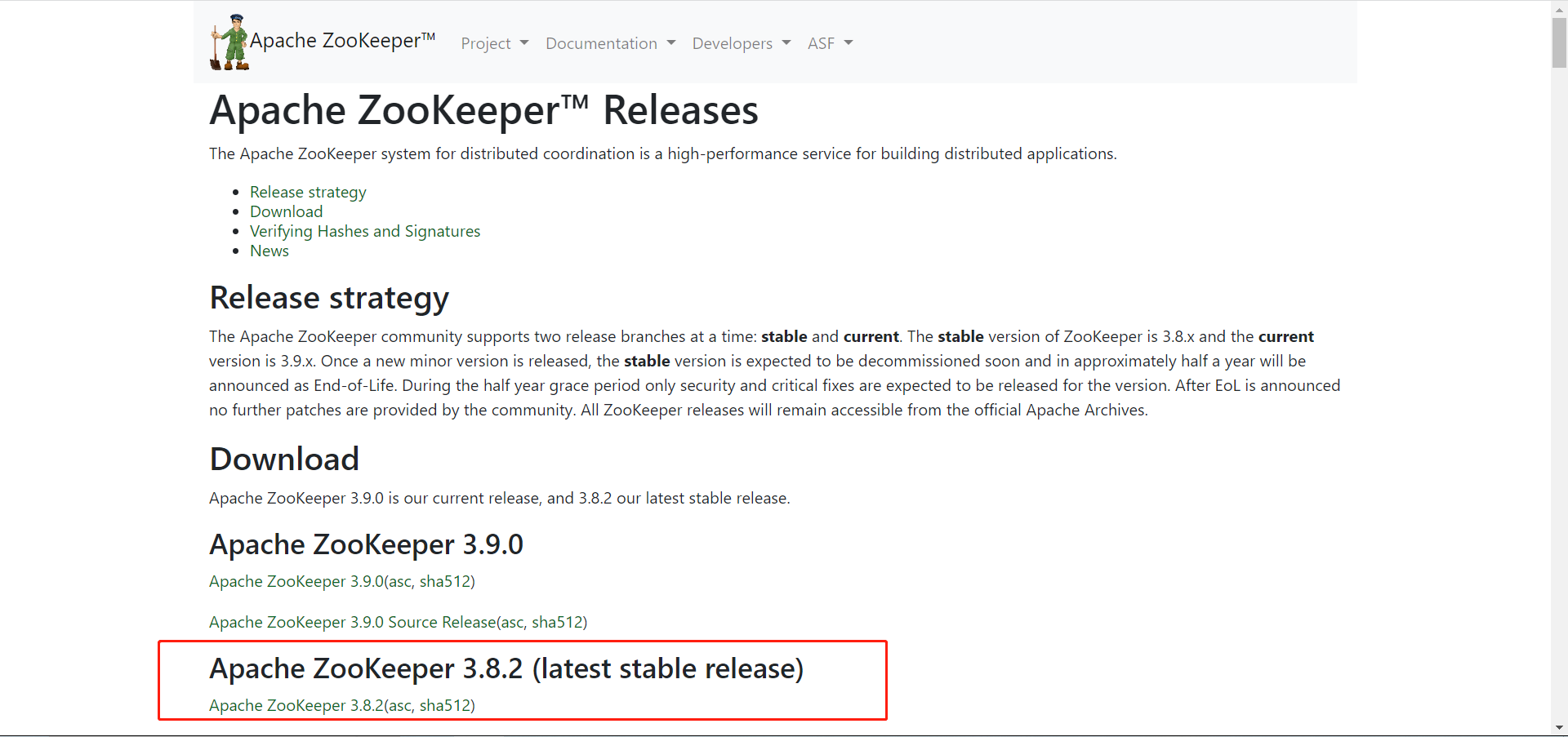
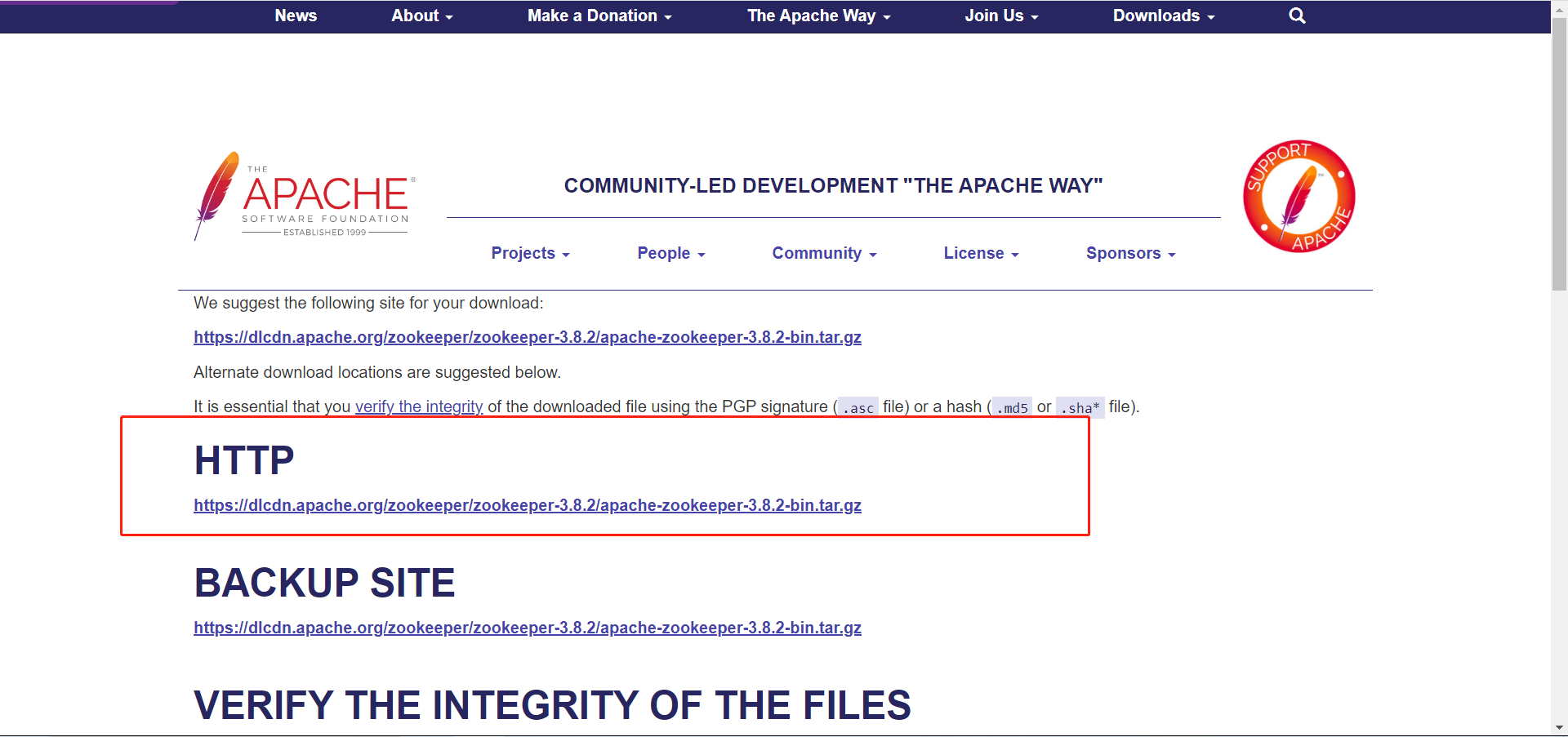
2. Instalação do Zookeeper
Instalação e implantação em modo local (modo autônomo)
Passo 1: Carregue o pacote compactado baixado no diretório especificado da máquina virtual. Eu carreguei-o em /opt/software/
Passo 2: Descompacte o pacote compactado no diretório especificado. Descompactei-o em /opt/app/
tar -zxvf apache-zookeeper-3.8.2-bin.tar.gz -C /opt/app/
Passo 3: Renomeie a pasta zookeeper
mv apache-zookeeper-3.8.2-bin/ zookeeper-3.8.2
Etapa 4: configurar variáveis de ambiente e fornecer o arquivo de configuração para entrar em vigor
vim /etc/profile source /etc/profile

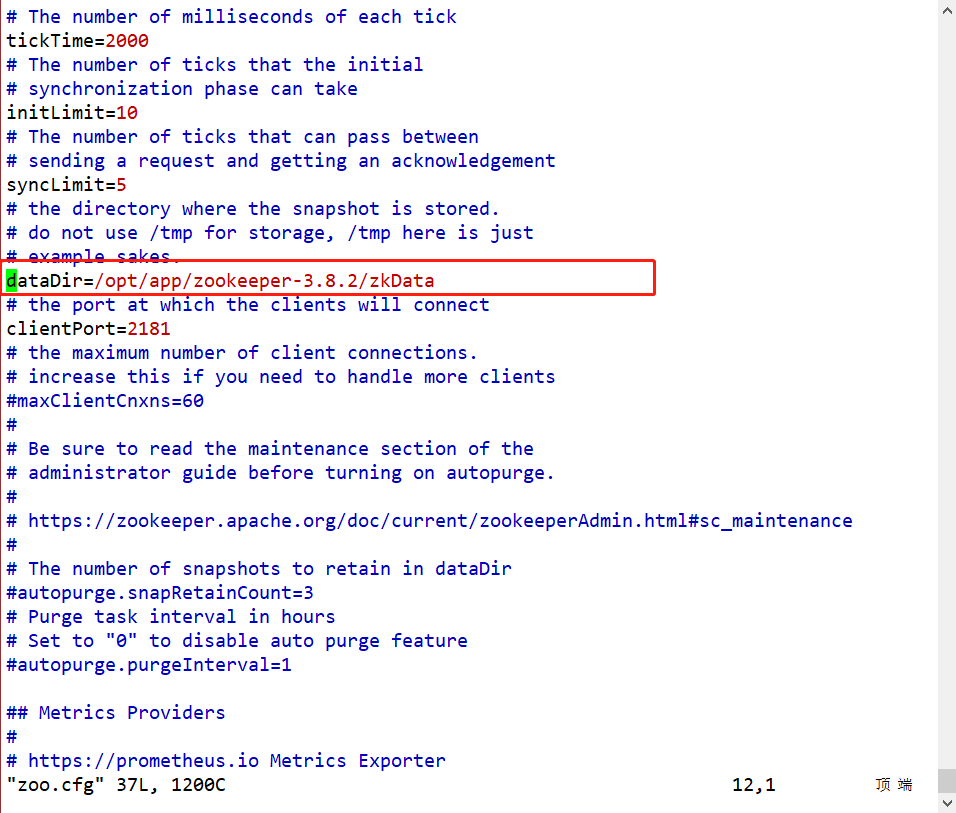
Passo 5: Insira /opt/app/zookeeper-3.8.2/confo diretório, renomeie o arquivo de configuração mv zoo_sample.cfg zoo.cfge edite-o. e /opt/app/zookeeper-3.8.2/crie um novo diretóriotouch zkData
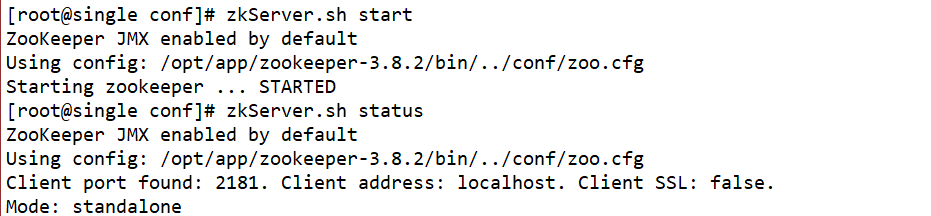
Passo 6: Use o comando zkServer.sh startpara iniciar o zookeeper, use o comando zkServer.sh statuspara verificar o status do zookeeper e use o comando netstat -untlppara verificar o número da porta.
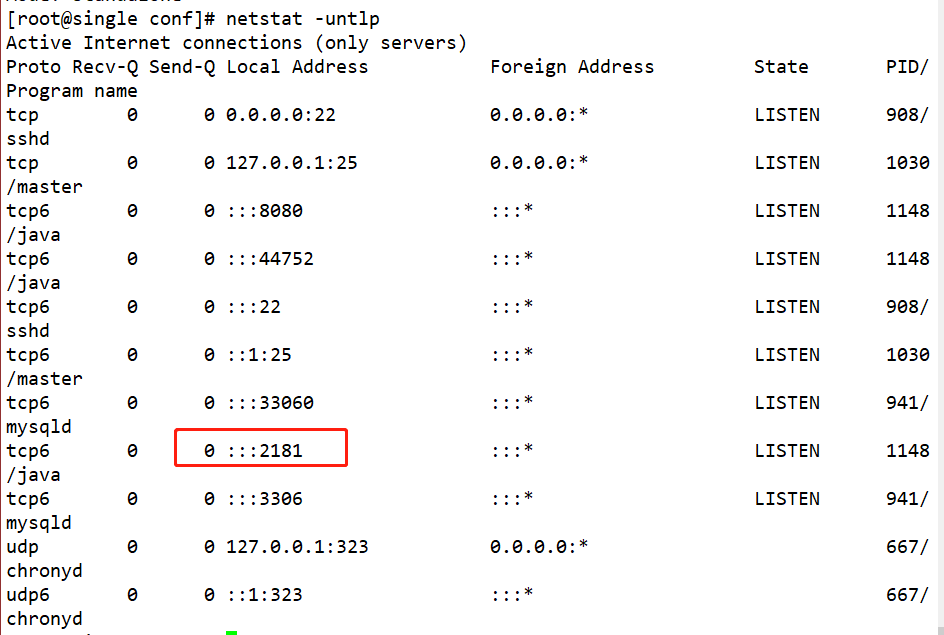
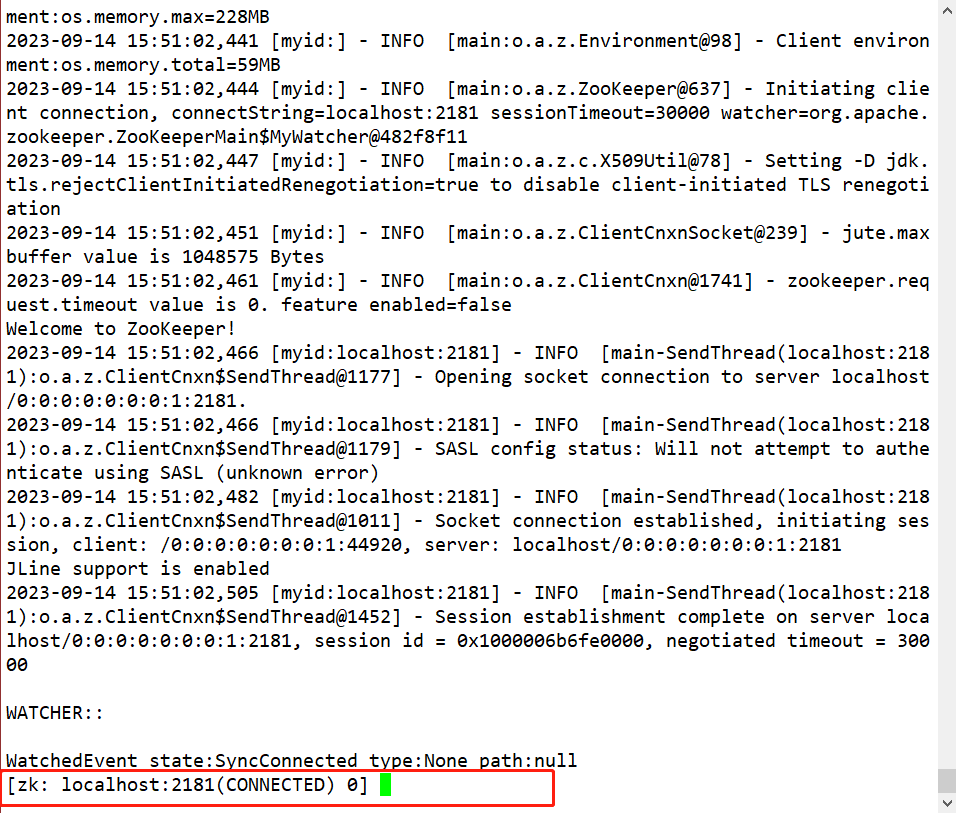
Passo 7: Use o comando zkCli.sh -server localhost:2181para entrar no cliente
zkServer.sh stopPasso 8: Saia usando o comando

Instalação e implantação distribuída (cluster em modo cluster)
-
Planejamento de cluster
-
在node1、node2、node3三个节点上部署Zookeeper。
-
-
Primeiro selecione o nó node1 para descompactar e instalar. As etapas são as mesmas da instalação e implantação no modo local.
-
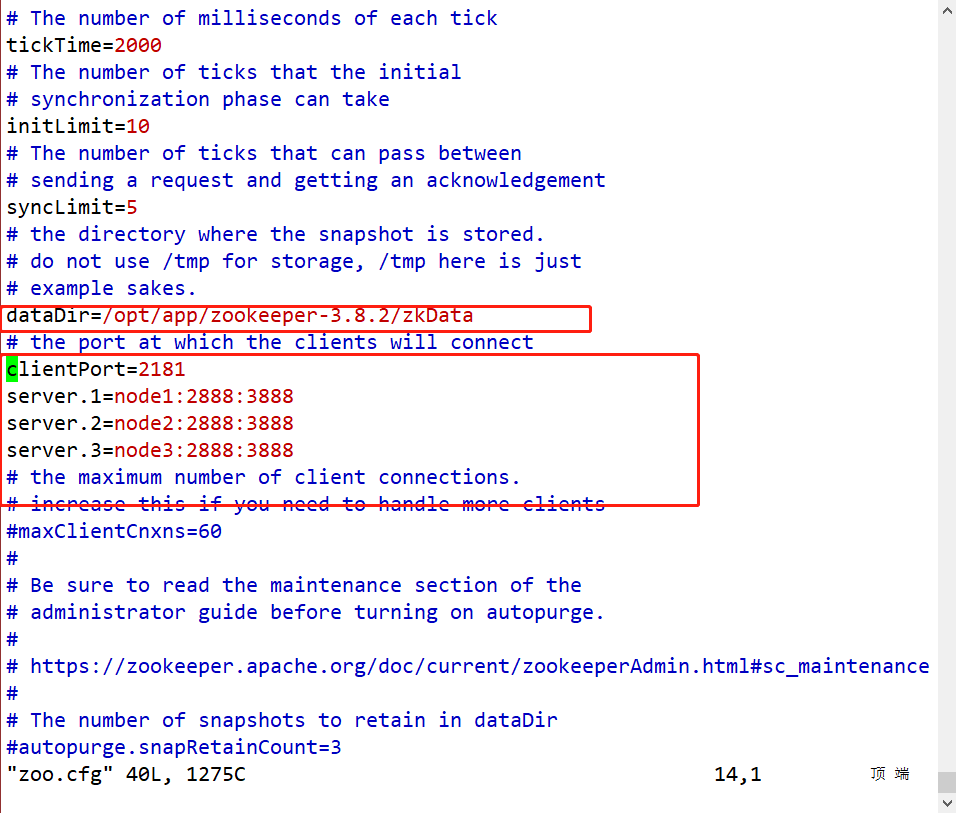
Modifique o arquivo de configuração zoo.cfg
[root@node1 software]# vim /opt/app/zookeeper/conf/zoo.cfg
#修改dataDir数据目录
dataDir=/opt/module/zookeeper-3.8.2/zkData
#在文件最后增加如下配置
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
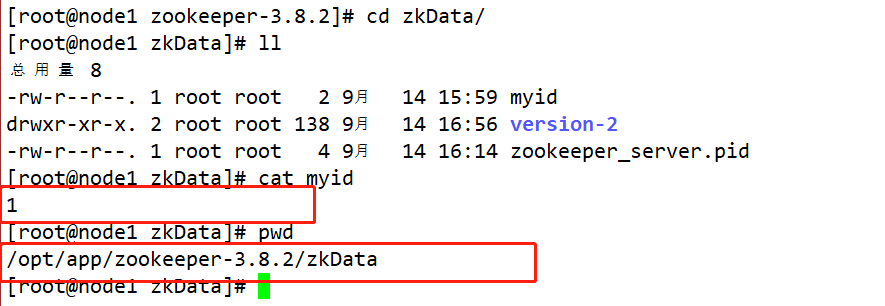
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
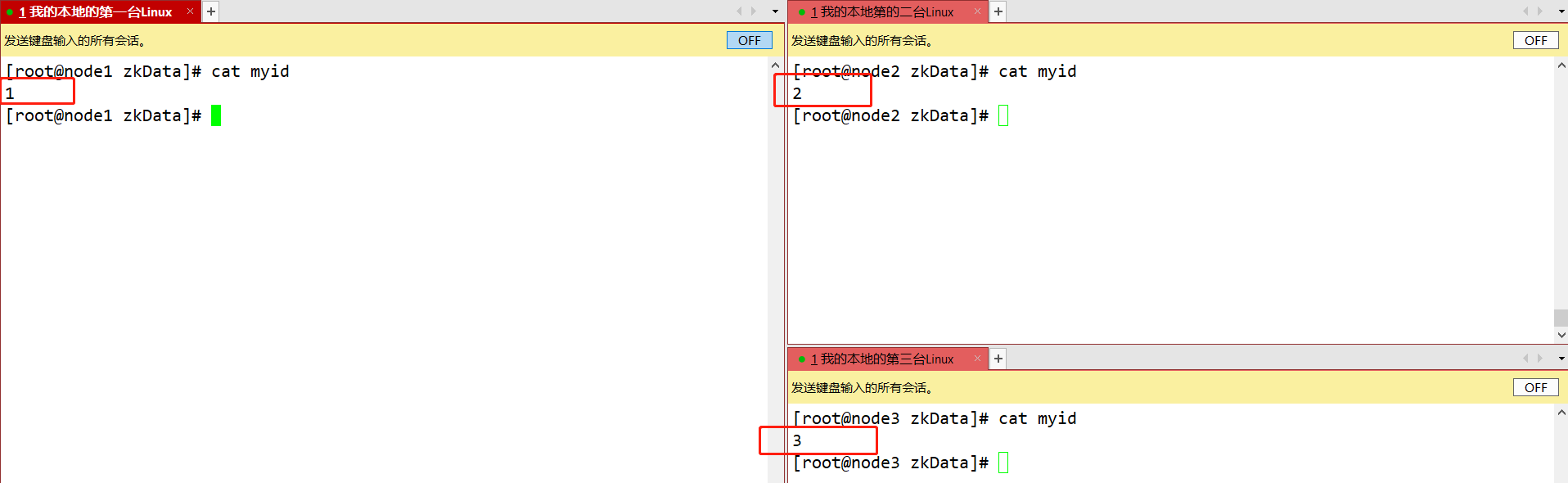
/opt/app/zookeeper-3.8.2Crie uma pasta emmkdir zkDatae entre neste diretório para criar um arquivotouch myiddefinindo o número do host atual.
#在配置zoo.cfg的时候配置了server.1/2/3这个配置项中 数字123代表的就是第几号服务器
#其中这个数字必须在zookeeper的zkData的myid文件中定义 并且定义的时候必须和配置项对应的IP相互匹配
[root@node1 zookeeper]# touch /opt/app/zookeeper/zkData/myid
[root@node1 zookeeper]# vim /opt/app/zookeeper/zkData/myid
#文件中写入当前主机对应的数字 然后保存退出即可 例 node1节点的myid写入1 node2节点的myid写入:2 node3节点的myid写入:3
-
Copie o zookeeper configurado para outras máquinas
scp -r /opt/app/zookeeper-3.8.2/ root@node2:/opt/app/ scp -r /opt/app/zookeeper-3.8.2/ root@node3:/opt/app/ 并分别修改myid文件中内容为2、3
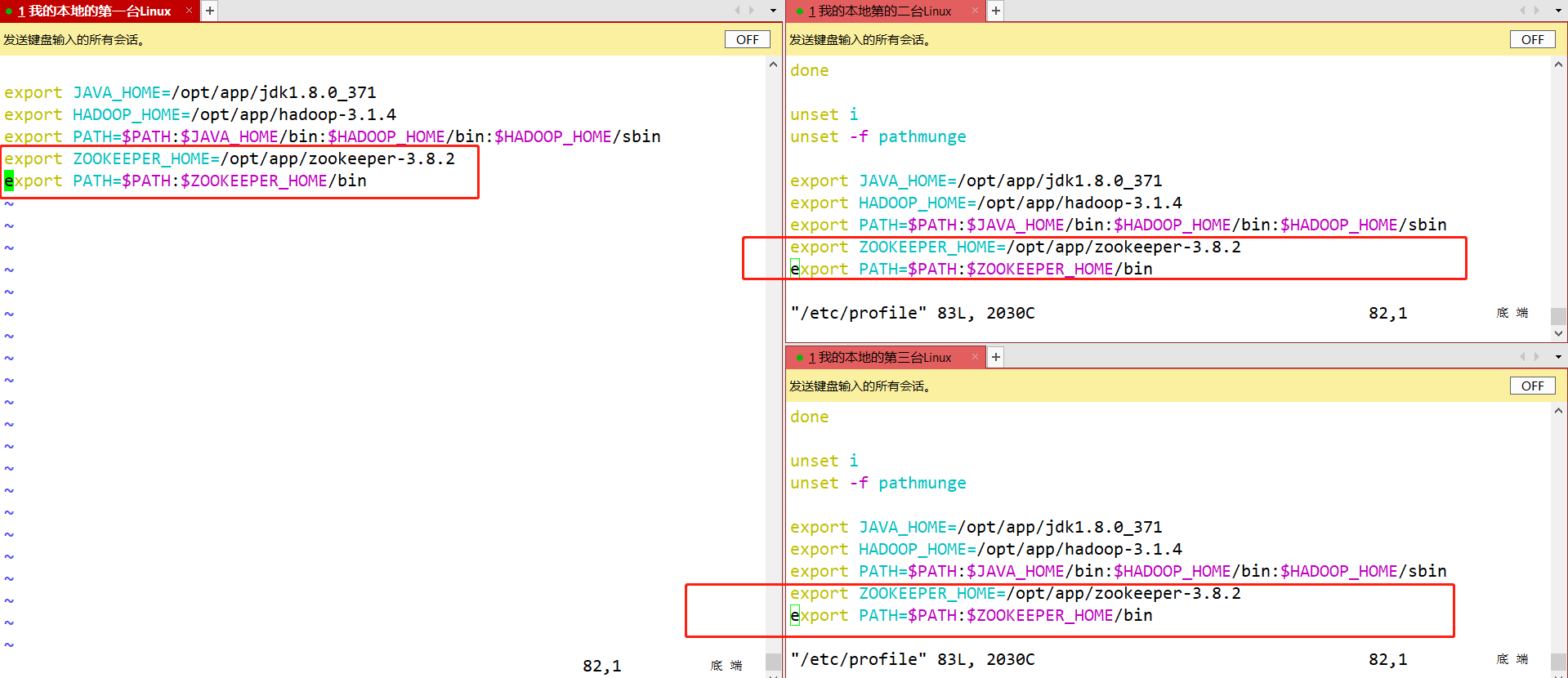
- Configure as variáveis de ambiente exigidas pelo zookeeper nos nós node2 e node3.
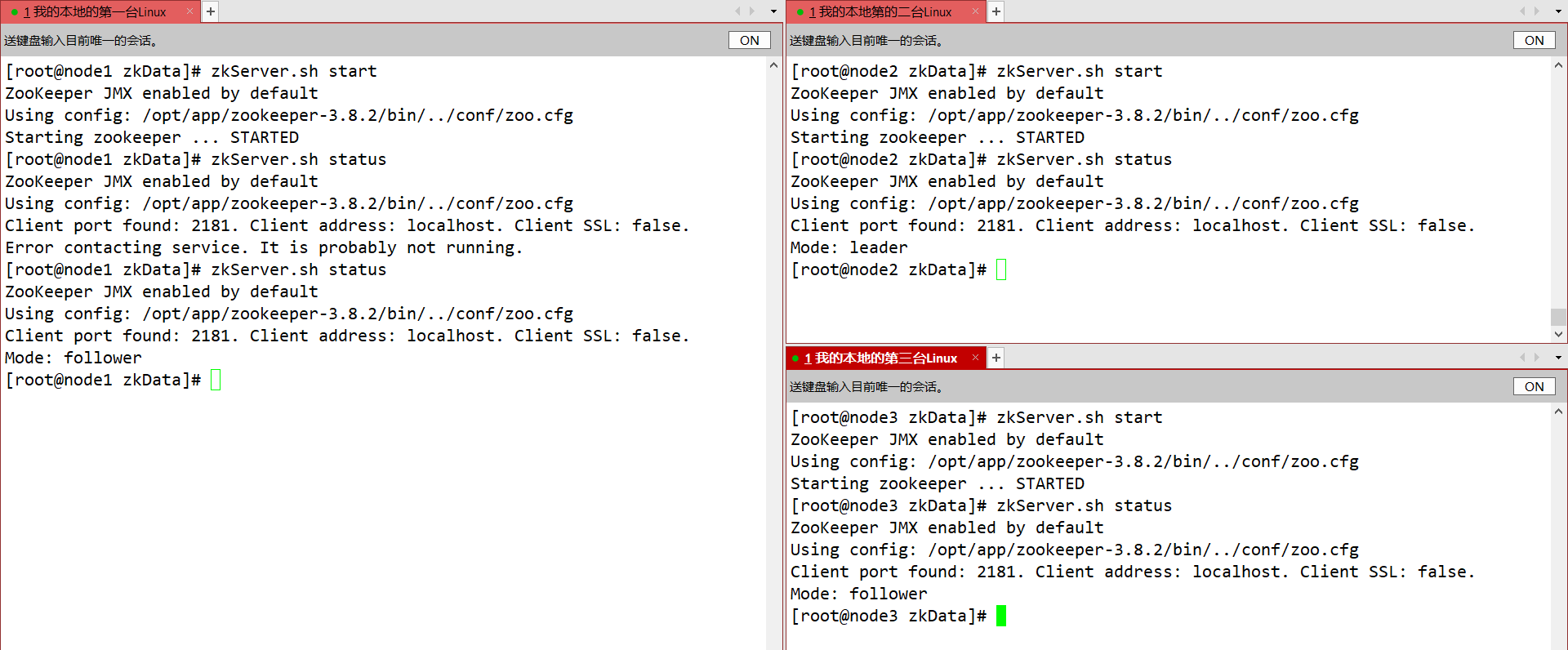
- Inicie o zookeeper separadamente e verifique o status
3. O princípio de implementação interna do zookeeper
1. Mecanismo eleitoral
- Meio mecanismo (protocolo Paxos): Mais da metade das máquinas do cluster sobrevivem e o cluster está disponível. Portanto, o zookeeper é adequado para instalação em um número ímpar de máquinas.
- Embora o Zookeeper não especifique mestre e escravo no arquivo de configuração. Porém, quando o zookeeper trabalha, um nó é o líder e os outros são os seguidores.O líder é gerado temporariamente através do mecanismo de eleição interno.
1. O mecanismo de eleição quando o Zookeeper é iniciado pela primeira vez
-
Mecanismo eleitoral interno do Zookeeper
-
Suponha que haja um cluster de zookeeper composto por cinco servidores, seus IDs variam de 1 a 5. Ao mesmo tempo, todos são recém-iniciados, ou seja, não há dados históricos. A quantidade de dados armazenados é a mesma. Supondo que esses servidores sejam iniciados sequencialmente, seu processo de implementação interna é mostrado na figura
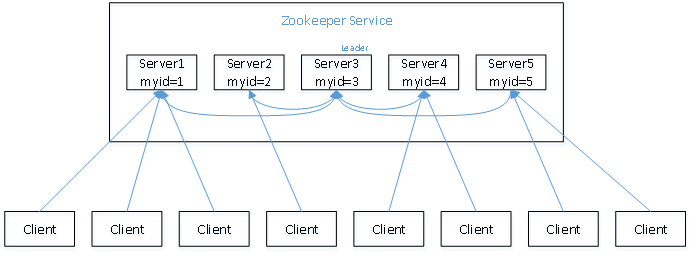
- O servidor 1 é iniciado. Neste momento apenas um servidor está iniciado. Não há resposta aos relatórios que ele envia, portanto seu status de eleição está sempre no estado LOOKING.
- O Servidor 2 inicia. Ele se comunica com o Servidor 1, que foi iniciado no início, e troca seus próprios resultados eleitorais entre si. Como ambos não possuem dados históricos, o Servidor 2 com um valor de ID maior vence, mas como mais da metade do os servidores não chegaram a Concordo para elegê-lo (mais da metade deles são 3 neste exemplo), então os servidores 1 e 2 continuam a manter o estado LOOKING.
- Inicia o servidor 3. De acordo com a análise teórica anterior, o servidor 3 passa a ser o líder entre os servidores 1, 2 e 3. A diferença do anterior é que três servidores o elegeram neste momento, então ele se torna o líder desta eleição.
- É iniciado o servidor 4. De acordo com a análise anterior, teoricamente o servidor 4 deveria ser o maior entre os servidores 1, 2, 3 e 4. Porém, como mais da metade dos servidores anteriores elegeram o servidor 3, ele só poderá receber o pedido de ser o irmão mais novo.
- O servidor 5 inicia e atua como o irmão mais novo, como o 4.
-
2. O mecanismo de eleição do tratador quando não é iniciado pela primeira vez
- SID: ID do servidor. Usado para identificar exclusivamente uma máquina no cluster ZooKeeper. Cada máquina não pode ser repetida e é consistente com myid.
- ZXID: ID da transação. ZXID é um ID de transação usado para identificar uma alteração no status do servidor. Em determinado momento, o valor ZXID de cada máquina do cluster pode não ser exatamente o mesmo, isso está relacionado à lógica de processamento do servidor ZooKeeper para a "solicitação de atualização" do cliente.
- Época: O codinome de cada termo do Líder. Quando não há líder, o valor do relógio lógico na mesma rodada de votação é o mesmo. Esses dados aumentarão cada vez que um voto for lançado.

2. Processo de gravação de dados do Zookeeper
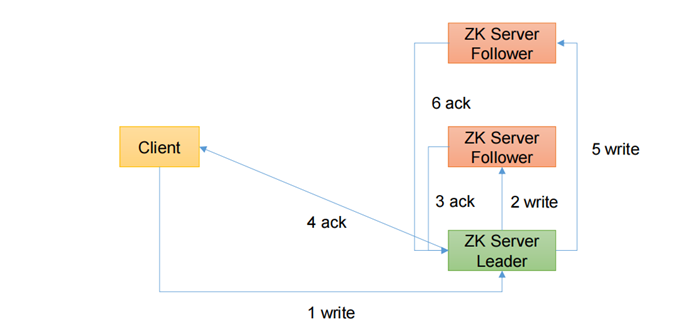
1. O processo de escrever o nó Líder diretamente
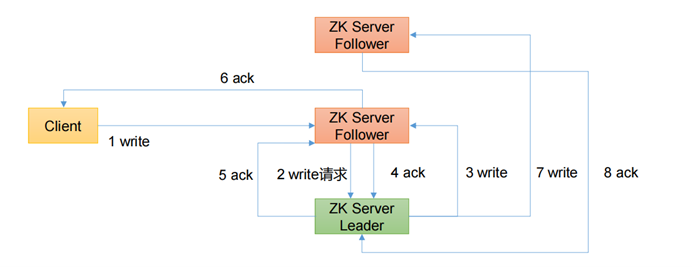
2. Escreva diretamente o processo do Seguidor
3. Visão geral detalhada do processo de gravação de dados
- Por exemplo, o Cliente grava dados no Servidor1 do ZooKeeper e envia uma solicitação de gravação.
- Se o Servidor1 não for o Líder, o Servidor1 encaminhará a solicitação recebida ao Líder, porque um de cada Servidor ZooKeeper é o Líder. O Líder transmitirá a solicitação de gravação para cada Servidor, como Servidor1 e Servidor2. Depois que cada Servidor gravar com sucesso O Líder será notificado.
- Quando o Líder recebe a maior parte dos dados do Servidor e os grava com sucesso, significa que os dados foram gravados com sucesso. Se houver três nós aqui, desde que os dados de dois nós sejam gravados com sucesso, os dados serão considerados gravados com sucesso. Depois que a gravação for bem-sucedida, o Líder informará ao Servidor1 que os dados foram gravados com sucesso.
- O Servidor1 notificará ainda o Cliente de que os dados foram gravados com sucesso e, então, toda a operação de gravação será considerada bem-sucedida. Todo o processo de gravação de dados do ZooKeeper é assim.
4. Operação de linha de comando do cliente Zookeeper
- Use o comando para se conectar ao cluster zookeeper
zkCli.sh -server node:2181,node2:2181,node3:2181
1. Sintaxe da linha de comando
| Sintaxe básica de comando | Descrição da função |
|---|---|
| ajuda | Mostrar todos os comandos de operação |
| caminho [assistir] | Use o comando ls para visualizar o conteúdo contido no znode atual |
| ls -s caminho [assistir] | Ver informações do nó atual |
| criar [-e] [-s] | Crie node -s com sequência -e temporária (reinicie ou desapareça após o tempo limite) |
| obter caminho [assistir] | Obtenha o valor de um nó |
| definir | Defina o valor específico do nó |
| Estado | Ver status do nó |
| excluir | Excluir nó |
| rmr/excluir tudo | Excluir nós recursivamente |
2. Operações básicas de linha de comando
-
Inicie o cliente de linha de comando
zkCli.sh -server node1:2181,node2:2181,node3:2181
-
Mostrar todos os comandos de operação
help

-
Ver informações do nó znode
ls /
-
Veja informações detalhadas sobre um nó no znode
[zk: node1:2181(CONNECTED) 5] ls -s / [zookeeper]cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x0 cversion = -1 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 1 (1)czxid:创建节点的事务 zxid 每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所 有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。 (2)ctime:znode 被创建的毫秒数(从 1970 年开始) (3)mzxid:znode 最后更新的事务 zxid (4)mtime:znode 最后修改的毫秒数(从 1970 年开始) (5)pZxid:znode 最后更新的子节点 zxid (6)cversion:znode 子节点变化号,znode 子节点修改次数 (7)dataversion:znode 数据变化号 (8)aclVersion:znode 访问控制列表的变化号 (9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是 临时节点则是 0。 (10)dataLength:znode 的数据长度 (11)numChildren:znode 子节点数量 -
Crie um nó normal (nó permanente + sem número de série)
create /sanguo "weishuwu"
-
Obtenha o valor de um nó
get -s /test -
Crie um nó com número de série (nó permanente + com número de série)
create -s /a create -s /a create /a 如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排序时从 2 开始,以此类推。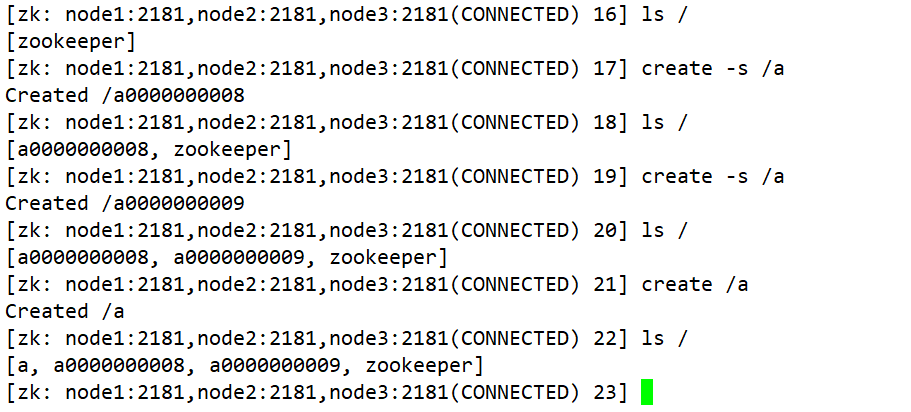
-
Crie um nó transitório (nó efêmero + sem número de série ou com número de série)
(1)创建短暂的不带序号的节点 create -e /b (2)创建短暂的带序号的节点 create -e -s /b (3)在当前客户端是能查看到的 ls / (4)退出当前客户端然后再重启客户端 [zk: node1:2181(CONNECTED) 12] quit [root@node1 zookeeper-3.5.7]$ bin/zkCli.sh (5)再次查看根目录下短暂节点已经删除 ls /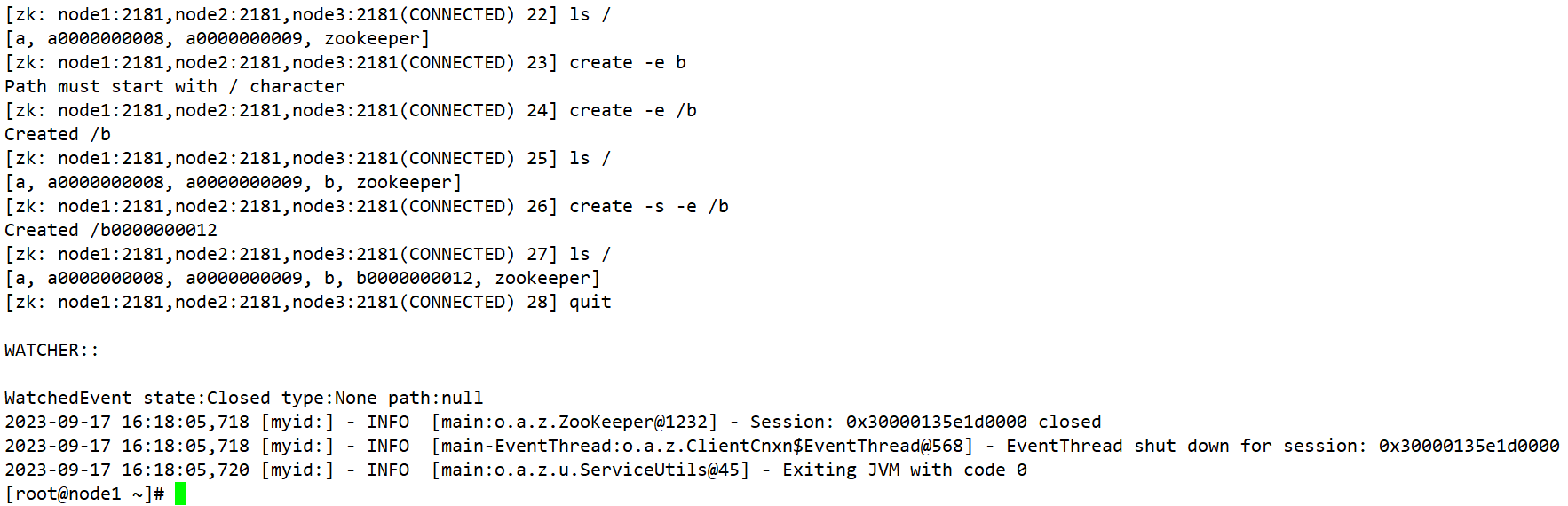
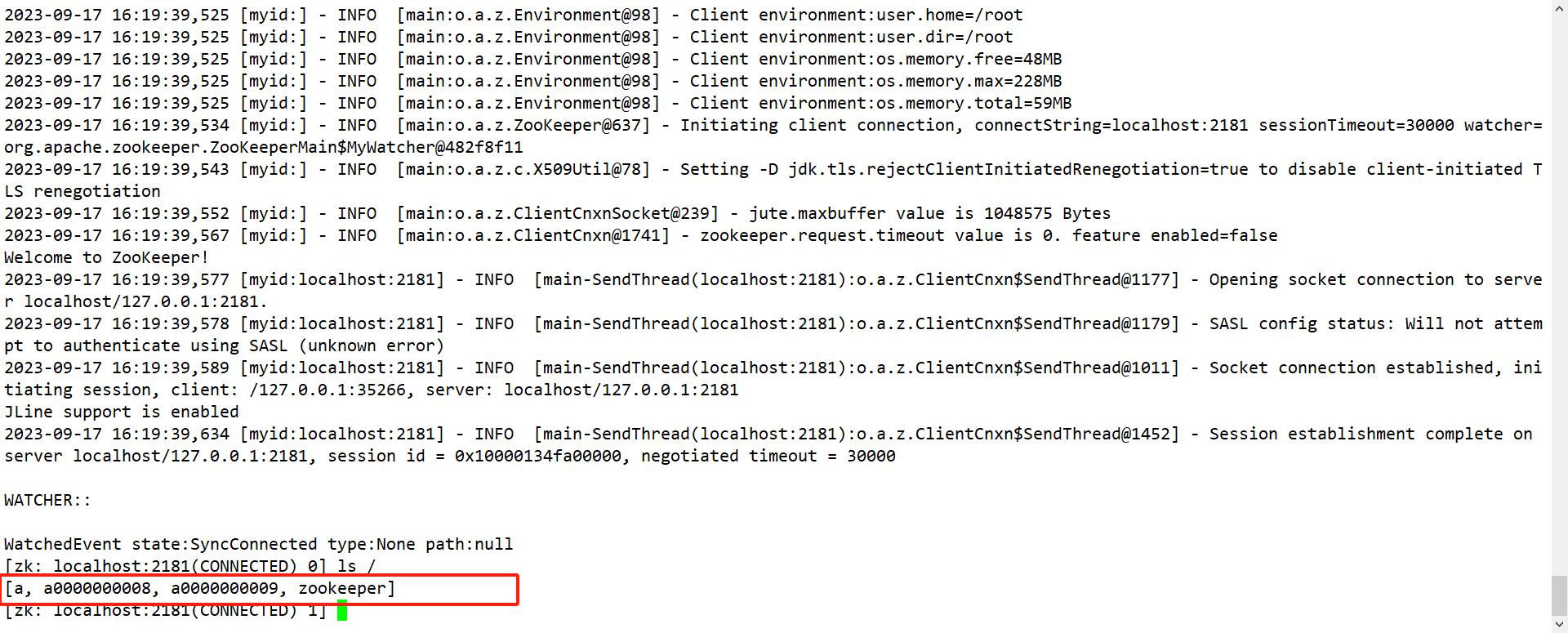
-
Modificar o valor dos dados do nó
[zk: node1:2181(CONNECTED) 6] set /sanguo/weiguo "simayi" -
Excluir nó
delete /test -
Excluir nós recursivamente
deleteall /test
-
Ver status do nó
stat /sanguo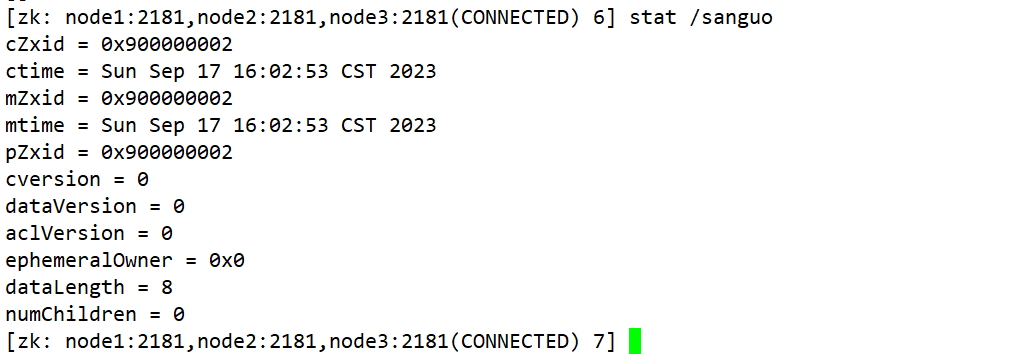
13. Monitore alterações de dados de nós
get -w /sanguo
14. Ouça as mudanças nos nós filhos de um nó
ls -w /sanguo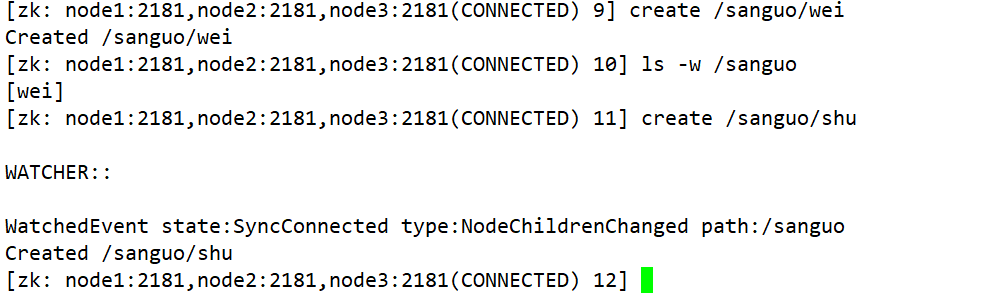
5. Construção de cluster HA-Hadoop de alta disponibilidade
1. Visão geral de HA de alta disponibilidade
- O chamado HA (alta disponibilidade) significa alta disponibilidade (serviço ininterrupto 7*24 horas).
- A estratégia mais crítica para alcançar alta disponibilidade é eliminar pontos únicos de falha. A rigor, o HA deve ser dividido em mecanismos de HA para cada componente: HDFS HA e YARN HA.
- Antes do Hadoop2.0, NameNode tinha um ponto único de falha (SPOF) no cluster HDFS.
- NameNode afeta principalmente o cluster HDFS nos dois aspectos a seguir:
- Se ocorrer um acidente na máquina NameNode, como tempo de inatividade, o cluster ficará inutilizável até que o administrador o reinicie.
- A máquina NameNode precisa ser atualizada, incluindo atualizações de software e hardware, e o cluster não poderá ser usado no momento.
- A função HDFS HA resolve os problemas acima configurando dois nameNodes, Active/Standby, para implementar backup a quente do NameNode no cluster. Se ocorrer uma falha, como uma falha na máquina ou se a máquina precisar ser atualizada e mantida, o NameNode poderá ser rapidamente alternado para outra máquina dessa maneira.
2. Mecanismo de funcionamento do HDFS-HA: elimine pontos únicos de falha por meio de namenodes duplos
-
Pontos de trabalho HDFS-HA
-
Os métodos de gerenciamento de metadados precisam ser alterados (SecondaryNameNode não é obrigatório)
内存中各自保存一份元数据; Edits日志只有Active状态的namenode节点可以做写操作; 两个namenode都可以读取edits; 共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现); -
É necessário um módulo de função de gerenciamento de status
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。 -
Deve ser garantido que o login sem senha SSH seja possível entre os dois NameNodes.
-
Isolamento (Fence) significa que apenas um NameNode fornece serviços externos ao mesmo tempo.
-
3. Configuração de cluster HDFS-HA
-
Preparação do ambiente:
-
Modificar IP
-
Modifique o nome do host e o mapeamento entre o nome do host e o endereço IP
-
Desativar firewall
-
login sem senha ssh
-
Instale o JDK, configure variáveis de ambiente, etc.
-
-
Planejando um cluster
| nó1 | nó2 | nó3 |
|---|---|---|
| NomeNode | NomeNode | - |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| Gerente de Recursos | ||
| NodeManager | NodeManager | NodeManager |
-
Configurando o cluster Zookeeper: Já registrado nas notas acima!
-
Configure o cluster HDFS-HA:
-
Configurar hadoop-env.sh
export JAVA_HOME=/opt/app/jdk -
Configurar core-site.xml
<configuration> <!-- 把两个NameNode的地址组装成一个集群HadoopCluster --> <property> <name>fs.defaultFS</name> <value>hdfs://HC</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/app/hadoop-3.1.4/metaData</value> </property> <!--配置连接的zookeeper的地址--> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> </configuration>

-
Configurar hdfs-site.xml
<configuration> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>HC</value> </property> <!-- 集群中NameNode节点都有哪些 --> <property> <name>dfs.ha.namenodes.HC</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HC.nn1</name> <value>node1:9000</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.HC.nn2</name> <value>node2:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.HC.nn1</name> <value>node1:9870</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.HC.nn2</name> <value>node2:9870</value> </property> <!-- 指定NameNode元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/HadoopCluster</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/app/hadoop-3.1.4/journalnodeData</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 访问代理类:client,HadoopCluster,active配置失败自动切换实现方式--> <property> <name>dfs.client.failover.proxy.provider.HC</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>true</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration> -
Copie o ambiente hadoop configurado para outros nós
scp /opt/app/hadoop-3.1.4/etc/hadoop/core-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/core-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/hdfs-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/hdfs-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ -
-
Iniciar cluster HDFS-HA
- Instale o software psmisc
O failover automático do zkfc precisa ser concluído com a ajuda do software psmisc, portanto, este software precisa ser instalado em três nós.
yum install -y psmisc
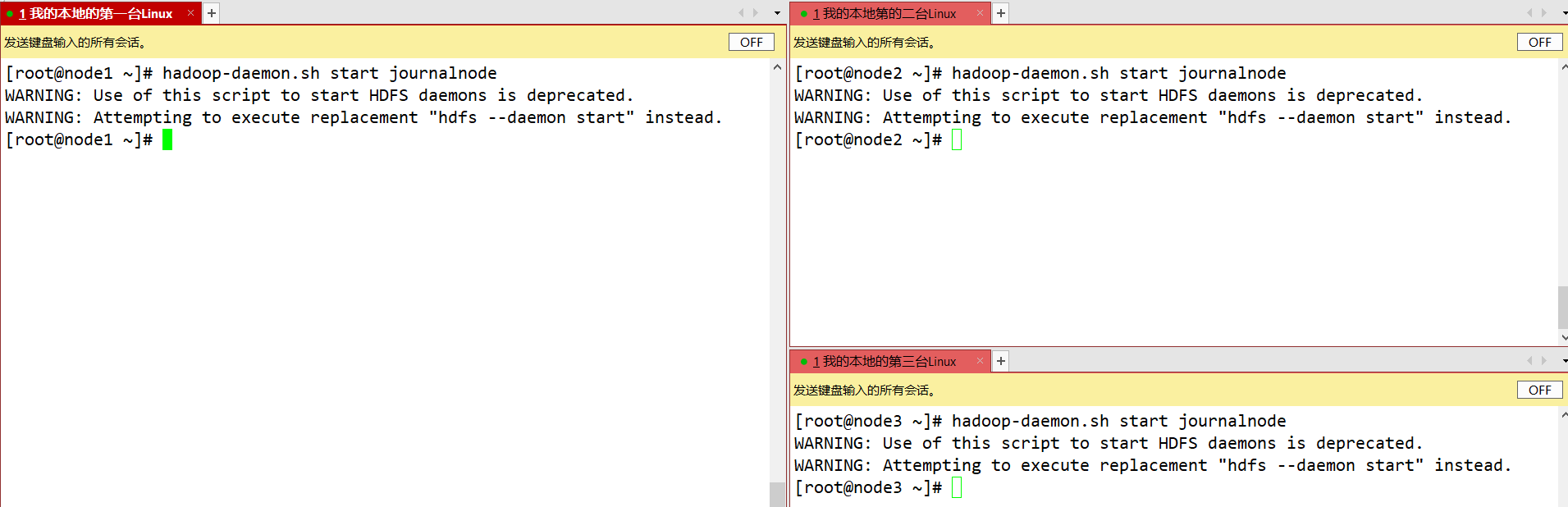
- Em cada nó JournalNode, insira o seguinte comando para iniciar o serviço journalnode:
sbin/hadoop-daemon.sh start journalnode
- Em [nn1], formate-o e inicie:
rm -rf metaData/ journalnodeData/ 删除三台节点 /opt/app/hadoop-3.1.4 hdfs namenode -format 只需要在第一台节点格式化 hadoop-daemon.sh start namenode 只需要执行一次即可,之后就不需要再执行-
Encontrou um erro, conforme mostrado na figura
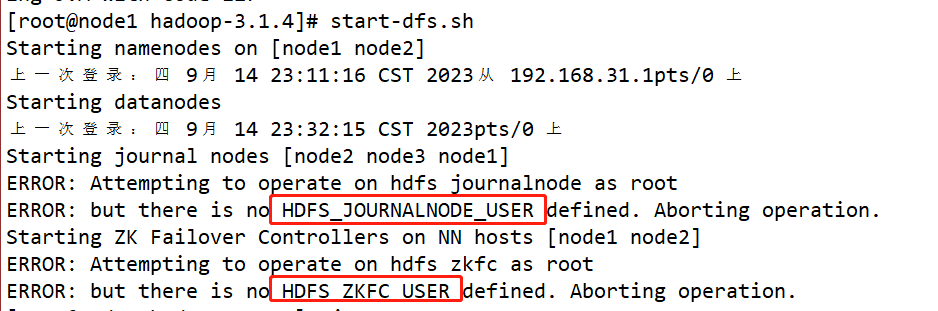
- vim /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh
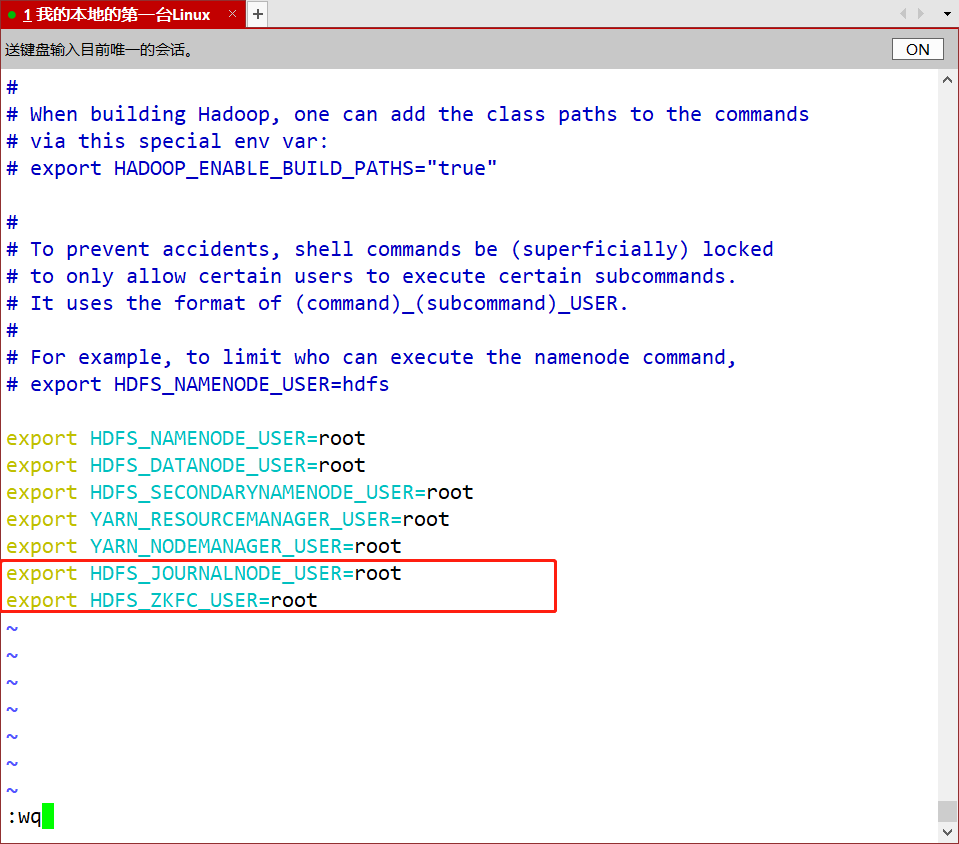
- scp /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/
- scp /opt/app/hadoop-3.1.4/etc/hadoop/hadoop-env.sh root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/

- comece
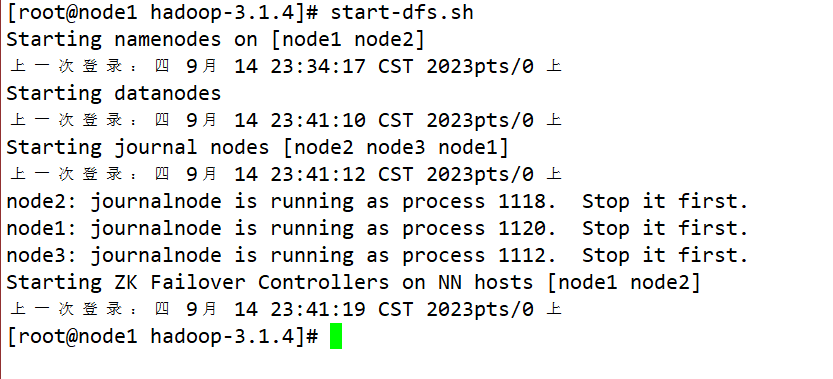
start-dfs.sh
-
Em [nn2], sincronize as informações de metadados de nn1:
bin/hdfs namenode -bootstrapStandbyele só precisa ser executado uma vez e não há necessidade de executá-lo novamente;hadoop-daemon.sh start namenodee inicie o namenode no segundo nó -
Inicie o datanode em três nós
hadoop-daemon.sh start datanode -
Reinicie o HDFS
- Encerre todos os serviços HDFS: sbin/stop-dfs.sh
- Inicie o cluster Zookeeper: bin/zkServer.sh start
- Inicialize o status do HA no Zookeeper: bin/hdfs zkfc -formatZK
- Inicie o serviço HDFS: sbin/start-dfs.sh
- Inicie o controlador de failover DFSZK em cada nó NameNode. Qual máquina é iniciada primeiro? O NameNode de qual máquina é o NameNode ativo: sbin/hadoop-daemin.sh start zkfc
-
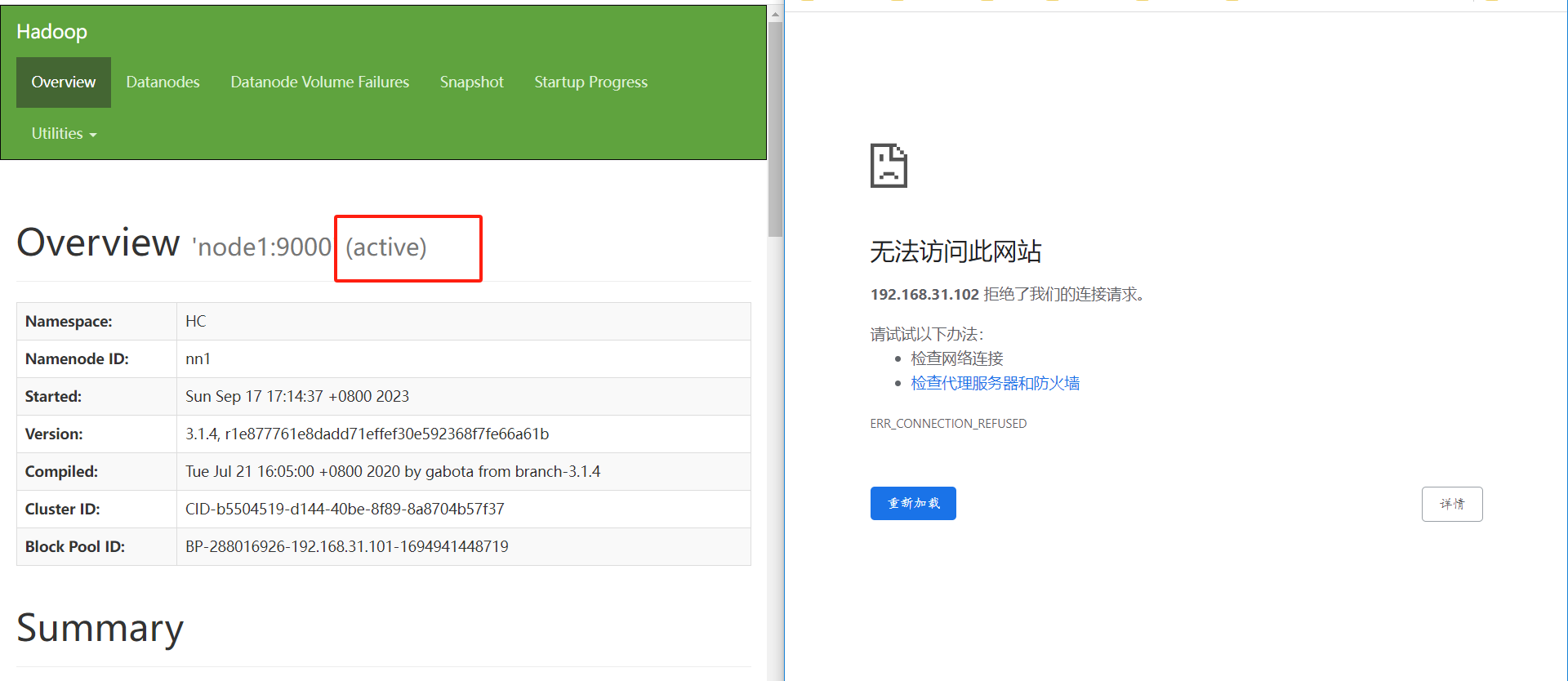
verificar
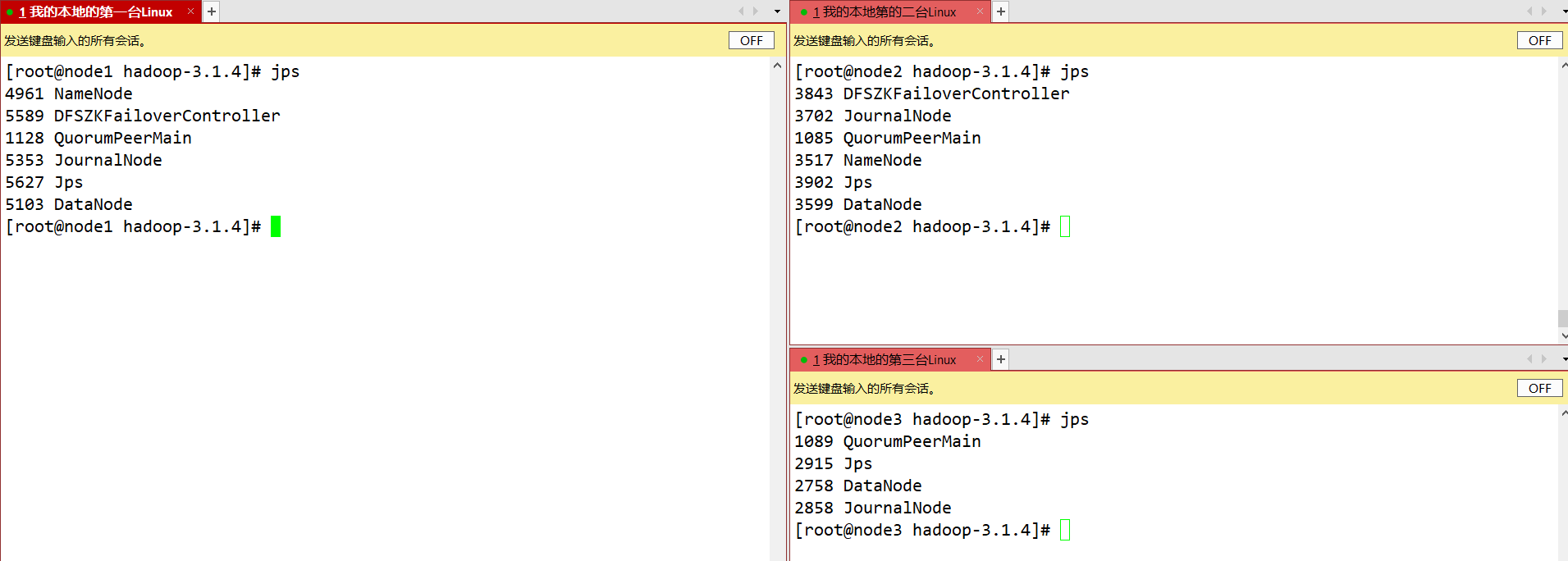
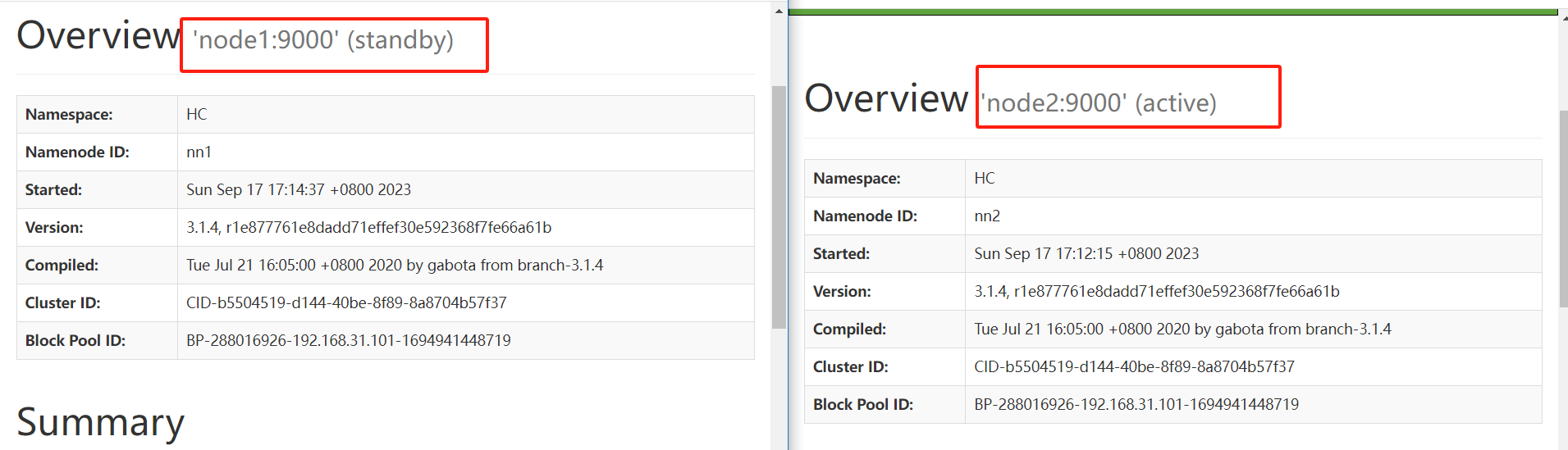
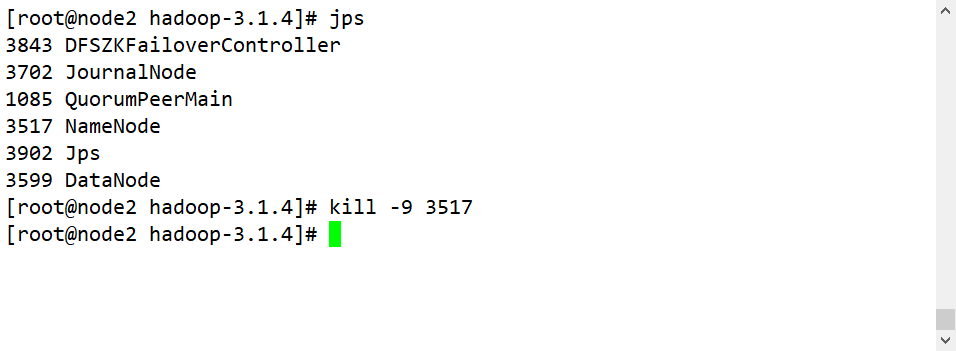
- Elimine o processo Active NameNode: kill -9 o ID do processo do namenode
- Desconecte a máquina Active NameNode da rede: serviço de parada de rede
6. Configuração YARN-HA
Configurar cluster YARN-HA
- Preparação ambiental
- Modificar IP
- Modifique o nome do host e o mapeamento entre o nome do host e o endereço IP
- Desativar firewall
- login sem senha ssh
- Instale o JDK, configure variáveis de ambiente, etc.
- Configurar cluster Zookeeper
- Planejando um cluster
| nó1 | nó2 | nó3 |
|---|---|---|
| NomeNode | NomeNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| ZK | ZK | ZK |
| Gerente de Recursos | Gerente de Recursos | |
| NodeManager | NodeManager | NodeManager |
-
Configuração específica – configure em cada nó
-
fio-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration> -
Atualizar de forma síncrona as informações de configuração de outros nós
-
scp /opt/app/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node2:/opt/app/hadoop-3.1.4/etc/hadoop/ scp /opt/app/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node3:/opt/app/hadoop-3.1.4/etc/hadoop/
-
-
-
Inicie o hdfs (você não precisa executar esta etapa se tiver criado um cluster HA-Hadoop)
-
Em cada nó JournalNode, insira o seguinte comando para iniciar o serviço journalnode: sbin/hadoop-daemon.sh start journalnode
-
Em [nn1], formate-o e inicie:
bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode -
Em [nn2], sincronize as informações de metadados de nn1: bin/hdfs namenode -bootstrapStandby
-
Iniciar [nn2]: sbin/hadoop-daemon.sh iniciar namenode
-
Inicie todos os datanodes: sbin/hadoop-daemons.sh inicie datanode
-
Mude [nn1] para ativo: bin/hdfs haadmin -transitionToActive nn1
-
-
Começar o fio
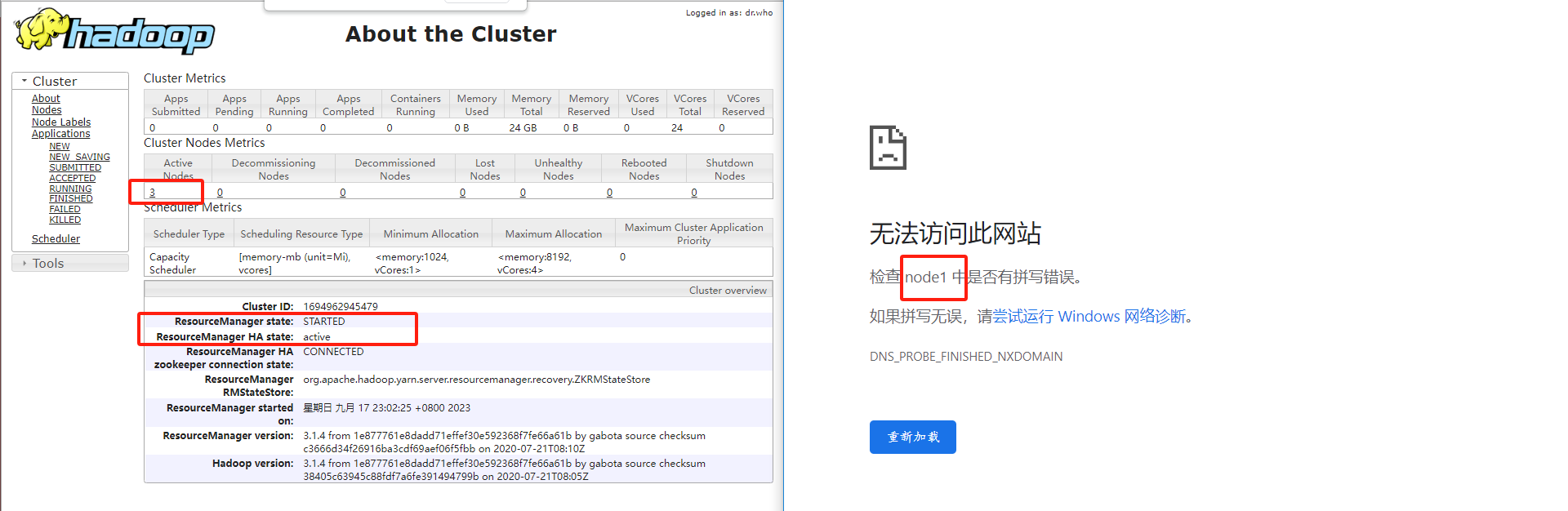
- Execute em node1: sbin/start-yarn.sh
- Execute em node2: sbin/yarn-daemon.sh start resourcemanager
- Verifique o status do serviço: bin/yarn rmadmin -getServiceState rm1

7. Como usar o programa MR para contar palavras em um ambiente de alta disponibilidade
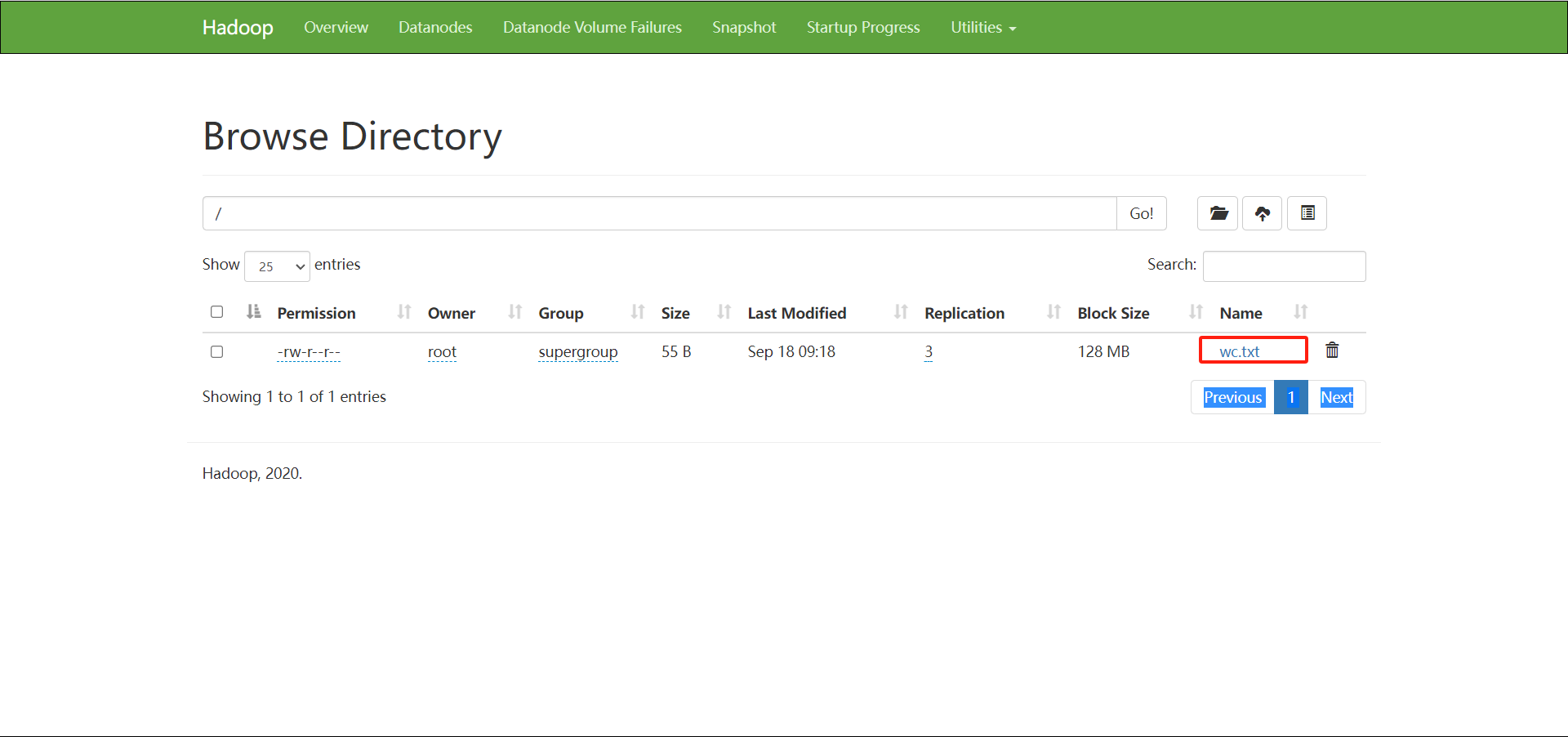
Edite wc.txt e carregue-o em hdfs

Abra a ideia, crie um projeto maven e introduza dependências de programação em pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kang</groupId>
<artifactId>ha-test</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>ha-test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
</dependency>
</dependencies>
</project>
Escrevendo código MapReduce
package com.kang;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word),new LongWritable(1L));
}
}
}
package com.kang;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReduce extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key,new LongWritable(sum));
}
}
package com.kang;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.xml.soap.Text;
import java.io.IOException;
public class WCDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://HC");
Job job = Job.getInstance(conf);
job.setJarByClass(WCDriver.class);
FileInputFormat.setInputPaths(job,new Path("/wc.txt"));
job.setMapperClass(WCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(WCReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setNumReduceTasks(0);
FileOutputFormat.setOutputPath(job,new Path("/output"));
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
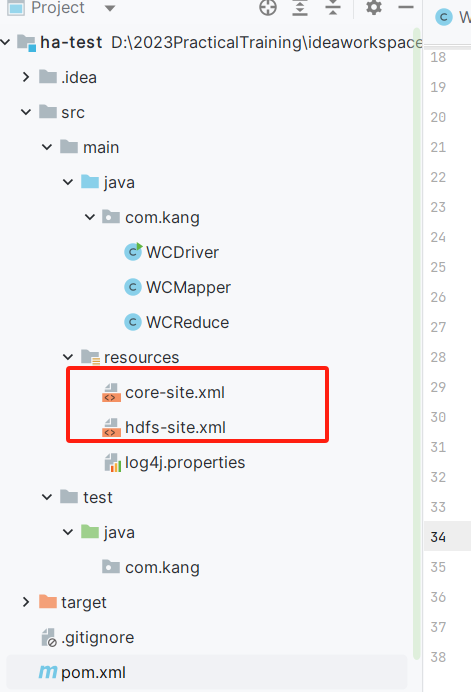
Exporte hdfs-site.xml e core-site.xml da máquina virtual para o diretório do projeto Java
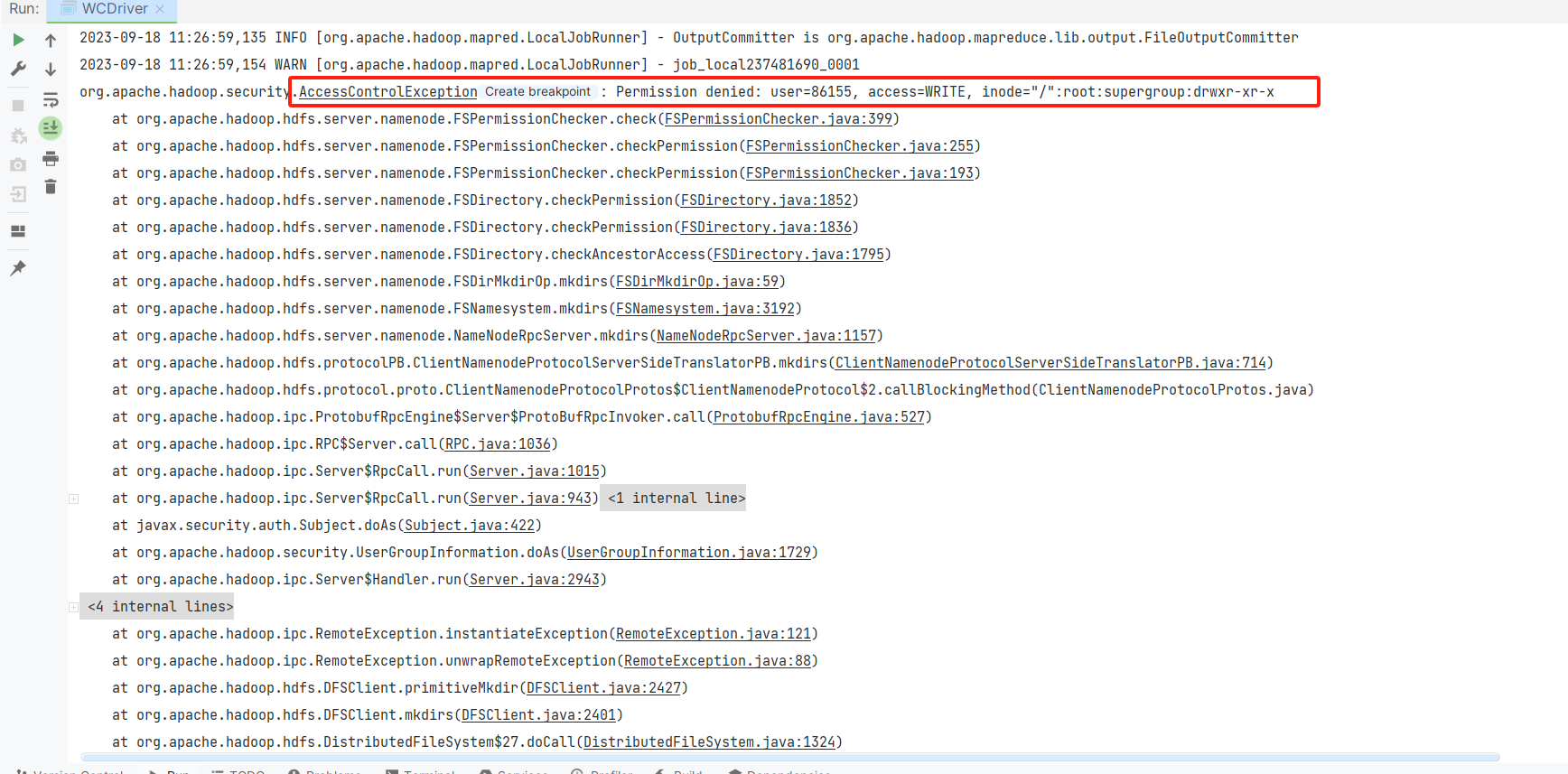
Em seguida, execute WCDriver, você receberá uma mensagem de erro e mostrará permissões insuficientes. Então, para realizar esta tarefa, modificamos as permissões.

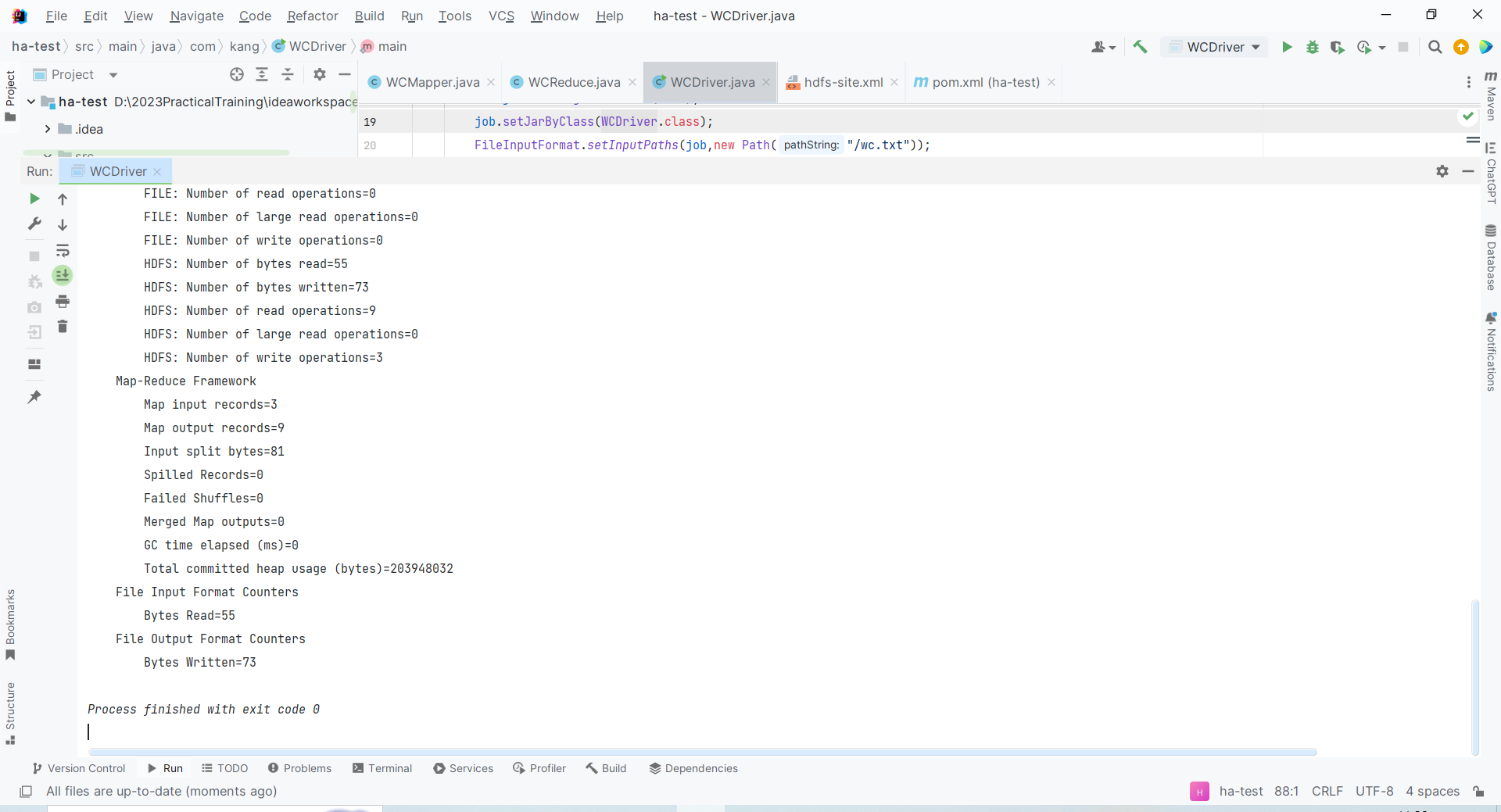
Execute o programa novamente e retorne o código 0, o que significa que a operação foi bem-sucedida.
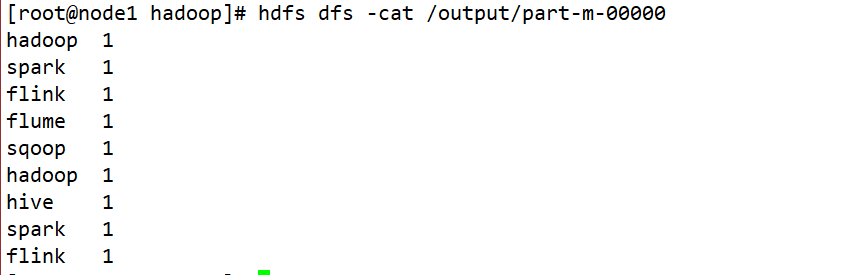
Por fim, restauramos as permissões padrão de arquivos e diretórios no Hadoop Distributed File System (HDFS) para os tipos de permissão padrão
