Implantação de cluster Elasticsearch
- 1. Arquitetura de cluster Elasticsearch
- 2. Implantação de cluster Elasticsearch
-
- 2.1 Modificação da configuração do sistema
- 2.2 Baixe o banco de dados es e carregue-o no servidor
- 2.3 Modificar arquivo de configuração de cluster
- 2.4 Criar usuários e grupos do Elasticsearch
- 2.5 Definir permissões de diretório
- 2.6. Inicie o serviço Elasticsearch
- 2.7 Abrir portas de firewall
- 2.8 Ver o status de inicialização
1. Arquitetura de cluster Elasticsearch
O cluster Elasticsearch é um poderoso mecanismo de pesquisa e análise que consiste em vários nós, cada nó é uma instância independente do Elasticsearch. Esses nós trabalham juntos para construir um mecanismo de pesquisa altamente disponível e escalonável. Este artigo se aprofundará na arquitetura e implantação do cluster Elasticsearch, incluindo nós mestres, nós de dados, nós clientes, fragmentos e métodos de comunicação entre nós.
nó mestre
Em um cluster Elasticsearch, há um nó designado como nó mestre. A principal tarefa do nó mestre é o gerenciamento e coordenação do cluster. Aqui estão algumas das principais responsabilidades do masternode:
-
Manter o status do cluster: O nó mestre é responsável por manter o status de todo o cluster, incluindo
节点列表、索引元数据和分片状态etc. -
Responsável pelo rebalanceamento do cluster: Quando novos nós ingressam ou nós antigos saem do cluster, o nó mestre será o responsável
重新平衡集群,确保分片被适当地重新分配给节点,以保持负载均衡. -
Execute operações em nível de cluster: o nó mestre pode realizar operações em nível de cluster, como criar ou excluir índices, definir configurações em nível de índice, etc.
-
Monitorar o status do nó: o nó mestre monitora o status de cada nó no cluster e detecta se o nó está funcionando corretamente em tempo hábil.
Em um cluster, só pode haver um nó mestre. Se o nó mestre falhar, o Elasticsearch criará 自动选举um novo nó mestre para assumir o trabalho e garantir a operação estável do cluster.
nó de dados
A principal responsabilidade do nó de dados é 存储和处理数据. Quando um cliente inicia uma solicitação de pesquisa para o cluster, o nó de dados consulta os dados locais de acordo com a solicitação e retorna os resultados. Cada nó de dados é responsável por armazenar uma parte dos dados no cluster. Quando novos dados são indexados, os nós de dados atribuem os dados aos fragmentos correspondentes e armazenam os fragmentos em discos locais. Se um nó de dados falhar, outros nós do cluster assumirão o trabalho do nó, garantindo a disponibilidade dos dados e backup redundante.
nó cliente
Os nós clientes não armazenam dados; sua função principal é fornecer dados ao cliente 集群发送查询请求,并将查询结果返回给客户端应用程序.
Os nós clientes têm as duas funções principais a seguir:
-
Balanceamento de carga: os nós clientes podem alocar solicitações de consulta a diferentes nós de dados para obter balanceamento de carga e melhorar o desempenho da consulta.
-
Failover: se um nó de dados falhar, o nó cliente poderá alternar automaticamente as solicitações de consulta para outros nós íntegros para garantir a disponibilidade do serviço.
Fragmentação
Em um cluster Elasticsearch, os dados são divididos em vários fragmentos para armazenamento e gerenciamento. Cada fragmento é um índice Lucene independente, contendo 一部分数据和索引信息. A fragmentação pode ser distribuída e replicada em diferentes nós do cluster para conseguir isso 高可用性和数据冗余.
Cada índice pode ser dividido em vários fragmentos primários e vários fragmentos de réplica. O fragmento primário é a unidade básica do índice e contém parte dos dados e informações do índice. Cada fragmento primário é um índice Lucene independente que pode ser armazenado em qualquer nó do cluster. Os fragmentos de réplica são cópias de fragmentos primários e são usados para melhorar a eficiência e a disponibilidade da consulta.
O número de fragmentos é especificado quando o índice é criado e não pode ser alterado depois de criado. Normalmente, 主分片的数量应该与集群中的数据节点数量相匹配, para garantir que cada nó possa armazenar um certo número de fragmentos.
Comunicação entre nós
Em um cluster Elasticsearch, os nós se comunicam entre si pela rede. Cada nó possui um nome de nó exclusivo, que é gerado automaticamente pelo Elasticsearch. Os nomes dos nós geralmente assumem o seguinte formato:
<host>-<uuid>
Entre eles, host é o nome do host onde o nó está localizado e uuid é um identificador exclusivo usado para garantir a exclusividade do nome do nó.
A comunicação entre os nós pode ocorrer de duas maneiras: protocolo HTTP e protocolo de transporte. O protocolo HTTP é o protocolo padrão do Elasticsearch e é usado para lidar com solicitações de API RESTful. O protocolo Transport é um protocolo usado internamente pelo cluster Elasticsearch para comunicação direta entre nós.
Status do cluster
O status do cluster Elasticsearch pode ser dividido nos três tipos a seguir:
-
Verde: o cluster está normal e todos os fragmentos primários e de réplica estão disponíveis.
-
Amarelo: o cluster está parcialmente disponível, todos os fragmentos primários estão disponíveis, mas alguns fragmentos de réplica estão indisponíveis.
-
Vermelho: o cluster não está disponível e pelo menos um fragmento primário está indisponível.
Quando um nó em um cluster Elasticsearch falha, o nó mestre remove automaticamente o nó com falha do cluster e redistribui os fragmentos atribuídos ao nó para outros nós. Assim que o nó com falha retornar ao normal
, ele se juntará novamente ao cluster e redistribuirá os fragmentos para garantir a integridade e a disponibilidade dos dados.
A arquitetura de cluster do Elasticsearch oferece alta escalabilidade e disponibilidade para armazenamento e pesquisa de dados em grande escala, tornando-o ideal para lidar com necessidades complexas de pesquisa e análise. Ao compreender os diferentes componentes e funções da arquitetura do cluster, você pode planejar e gerenciar melhor seu cluster Elasticsearch para atender às necessidades de negócios.
2. Implantação de cluster Elasticsearch
2.1 Modificação da configuração do sistema
2.1.1 Modifique o número de identificadores de arquivo e threads
Para evitar erros causados por permissões baixas em descritores de arquivos criáveis pertencentes ao usuário do Elasticsearch, é necessário modificar o número de identificadores de arquivo e threads. Edite /etc/security/limits.confo arquivo e adicione o seguinte conteúdo:
# 文件句柄
es soft nofile 65536
es hard nofile 65536
# 线程
es soft nproc 4096
es hard nproc 4096
保存退出后,需要重新启动系统
A configuração acima é para resolver:
Relatório de erros: o máximo de descritores de arquivo [4096] para o processo elasticsearch é muito baixo, aumente para pelo menos [65535]
Descrição do problema: O usuário do elasticsearch tem permissões muito baixas para criar descrições de arquivo, pelo menos 65536 é necessário;
2.1.2 Modificar memória virtual
Edite /etc/sysctl.confo arquivo e adicione o seguinte conteúdo:
vm.max_map_count=262144
Após salvar e sair, atualize o arquivo de configuração:
sysctl -p
Verifique se a modificação foi bem-sucedida:
sysctl vm.max_map_count
A configuração acima é para resolver
o problema de erro: o máximo de áreas de memória virtual vm.max_map_count [65530] é muito baixo, aumente para pelo menos [262144]
2.1.3 Fechar espaço de troca (Swap)
Recomendação oficial: Dê metade da memória para Lucene + e não exceda 32G + desligue a troca.
ES recomenda desligar o espaço de troca da memória swap e desabilitar a troca. Porque quando a memória é trocada para o disco, uma operação de 100 microssegundos pode se tornar 10 milissegundos e, em seguida, o atraso da operação de 100 microssegundos aumenta. Pode-se ver que a troca tem um impacto fatal no desempenho.
vim /etc/fstab
O comentário contém a linha de troca.
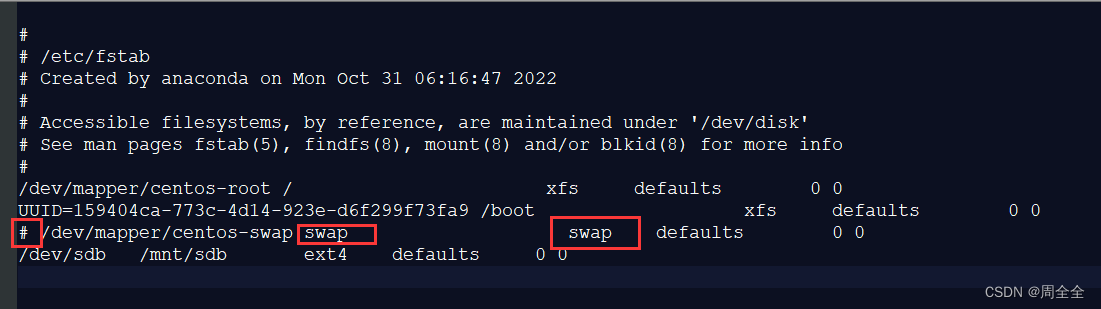
Antes do comentário:

保存退出后需要系统重启!
Após comentário:

2.2 Baixe o banco de dados es e carregue-o no servidor
Baixe o Elasticsearch 7.17.11 , faça upload para o servidor e use o seguinte comando para descompactar o Elasticsearch:
cd /mnt/data/es-cluster
tar -zxvf elasticsearch-7.17.11-linux-x86_64.tar.gz
Faça 3 cópias e nomeie-as da seguinte forma:

2.3 Modificar arquivo de configuração de cluster
2.3.1 descrição do item de configuração elasticsearch.yml
| Itens de configuração | Instruções de configuração | Exemplo de configuração |
|---|---|---|
| cluster.nome | Nome do cluster | es-cluster |
| nó.nome | Nome do nó | nó1 |
| caminho.dados | diretório de dados | /home/es/caminho/nó/dados |
| caminho.logs | Diretório de registros | /home/es/caminho/nó/logs |
| nó.nome | Nome do nó | nó1 |
| rede.host | Vincular endereço IP | 127.0.0.1 |
| http.porta | Especifique a porta de acesso ao serviço | 9201 |
| transporte.tcp.port | Especifique a porta de chamada do cliente API | 9301 |
| descoberta.seed_hosts | Endereço de comunicação do cluster | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| cluster.initial_master_nodes | Informações do nó que podem ser selecionadas para inicialização do cluster | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| http.cors.enabled | Habilitar suporte de acesso entre domínios | verdadeiro |
| http.cors.allow-origin | Nomes de domínio permitidos para acesso entre domínios | “*” |
As atribuições da porta são as seguintes:
| Hospedar | Nome do nó | Porta HTTP | Porto de transporte |
|---|---|---|---|
| 192.168.0.119 | nó1 | 9201 | 9301 |
| 192.168.0.119 | nó2 | 9202 | 9302 |
| 192.168.0.119 | nó3 | 9203 | 9303 |
2.3.2 Modificar informações de configuração do nó node1
vim /mnt/data/es-cluster/elasticsearch-7.17.11-node1/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node1
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/logs
# 指定服务访问端口
http.port: 9201
# 指定API端户端调用端口
transport.tcp.port: 9301
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.2 Modificar informações de configuração do nó node2
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node2
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/logs
# 指定服务访问端口
http.port: 9202
# 指定API端户端调用端口
transport.tcp.port: 9302
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.3 Modificar informações de configuração do nó node3
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node3/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node3
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/logs
# 指定服务访问端口
http.port: 9203
# 指定API端户端调用端口
transport.tcp.port: 9303
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.4 Criar usuários e grupos do Elasticsearch
Crie um usuário chamado "es" e um grupo chamado "es" e adicione o usuário ao grupo:
# 新建群组es
groupadd es
# 新建用户es并指定群组为es
useradd -g es es
# 设置用户密码
passwd es
# usermod 将用户添加到某个组group
usermod -aG root es
2.5 Definir permissões de diretório
Defina o usuário e o grupo ao qual o diretório de cluster do Elasticsearch pertence:
chown -R es:es /mnt/data/es-cluster
2.6. Inicie o serviço Elasticsearch
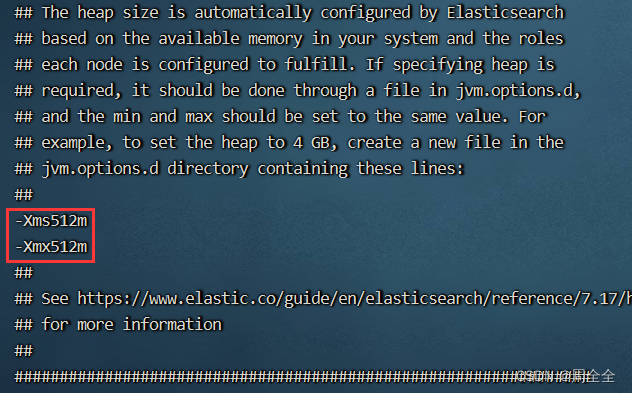
2.6.1 Configurar memória de inicialização (opcional)
Se o tamanho da memória de uma única máquina for limitado, você poderá definir o tamanho da memória de inicialização como es. Insira o diretório /config dos três nós respectivamente, execute vim jvm.optionse modifique a configuração.
-Xms512m
-Xmx512m
2.6.2 Criar scripts para iniciar e parar serviços
Crie 三个es节点um script para iniciar e parar o serviço Elasticsearch
( 注意当前目录是在 ../elasticsearch-7.17.11-node1)
-
começa-single.sh
#!/bin/bash cd "$(dirname "$0")" # -d:后台(daemon)方式运行 Elasticsearch ./bin/elasticsearch -d -p pid -
stopes-single.sh
#!/bin/bash cd "$(dirname "$0")" if [ -f "pid" ]; then pkill -F pid fi -
Conceda permissões de execução:
chmod 755 startes-single.sh stopes-single.sh chown es:es startes-single.sh stopes-single.sh -
Inicie o serviço Elasticsearch como usuário do Elasticsearch:
su es cd /mnt/sdb/es-cluster/elasticsearch-7.17.11-node1 ./startes-single.sh
Possíveis erros:
- falha ao obter bloqueios de nó, tentei [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] com ID de bloqueio [0]; talvez esses locais não sejam graváveis ou vários nós tenham sido iniciados sem aumentar
][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [node2] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:173) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.main(Command.java:77) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80) ~[elasticsearch-7.17.11.jar:7.17.11]
Caused by: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:429) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:309) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169) ~[elasticsearch-7.17.11.jar:7.17.11]
... 6 more
uncaught exception in thread [main]
java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328)
at org.elasticsearch.node.Node.<init>(Node.java:429)
at org.elasticsearch.node.Node.<init>(Node.java:309)
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112)
at org.elasticsearch.cli.Command.main(Command.java:77)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80)
Solução: Adicione: node.max_local_storage_nodes: 3 ao arquivo de configuração.
Esta configuração limita o número de instâncias de armazenamento ES que podem ser abertas em um único nó. Se precisar iniciar várias instâncias em uma única máquina, você precisará gravar essa configuração no arquivo de configuração e atribuir um valor 2 ou superior a essa configuração.
2.7 Abrir portas de firewall
CentOS
# 查看防火墙状态
systemctl status firewalld
# 查看开放的端口
firewall-cmd --query-port=9200/tcp
# 添加端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 重载防火墙
firewall-cmd --reload
# 再次查看端口是否已经开放
firewall-cmd --query-port=9200/tcp
Ubuntu
# 查看防火墙状态
sudo ufw status
# 开放端口 9200
sudo ufw allow 9200/tcp
# 查看已添加的规则
sudo ufw status numbered
# 查看防火墙状态
sudo ufw status
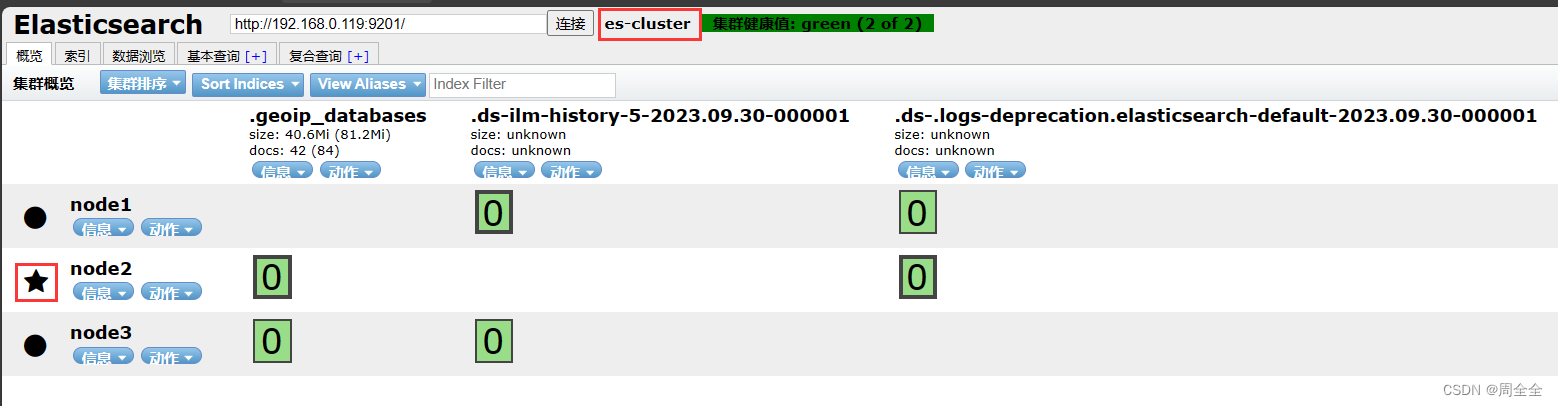
2.8 Ver o status de inicialização
- Acesse as portas http de três nós, respectivamente
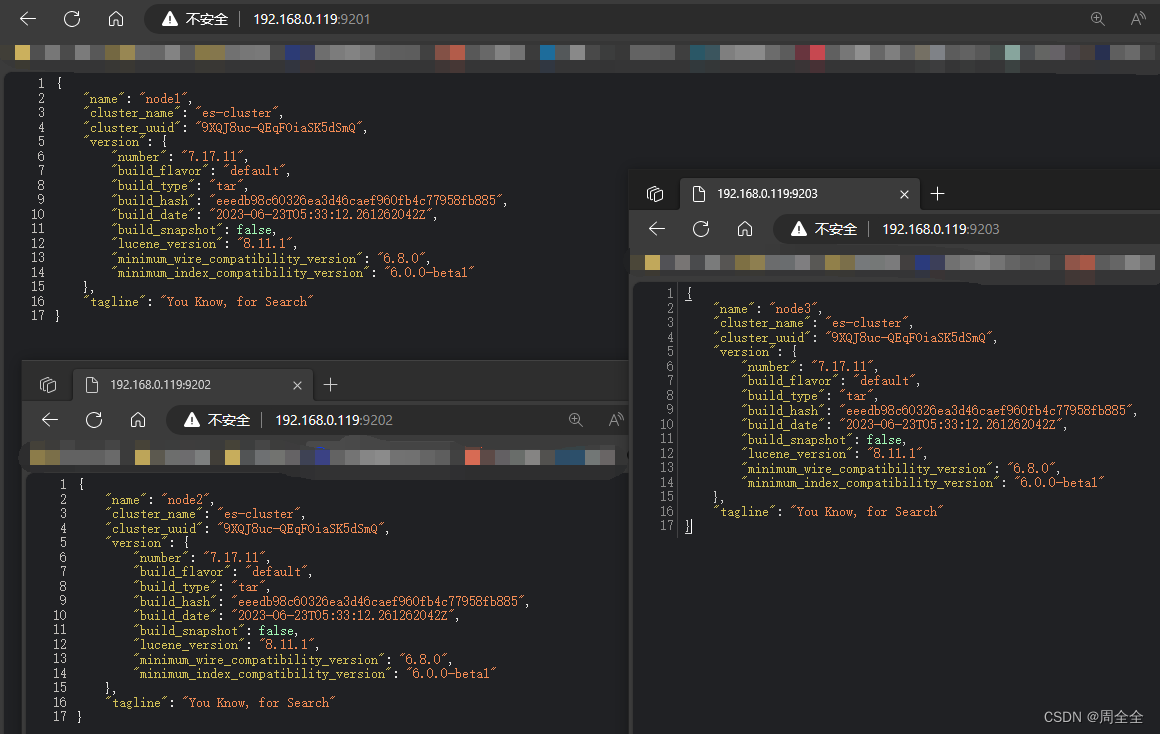
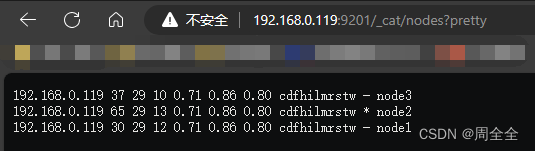
- Ver status do nó
http://192.168.0.119:9201/_cat/nodes?pretty
Você pode ver as informações de três nós, e os três nós elegerão o nó mestre por conta própria (ES é uma implementação aprimorada baseada no algoritmo de eleição Bully)
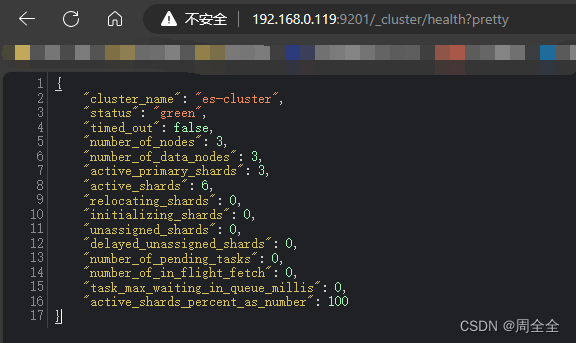
- Ver o status de integridade do cluster
http://192.168.0.119:9201/_cluster/health?pretty
4. Visualização do cabeçalho do Elasticsearch