
Os alunos que precisam de servidores em nuvem e outros produtos em nuvem para aprender Linux podem migrar para / --> Tencent Cloud <-- / --> Alibaba Cloud <-- / --> Huawei Cloud <-- / site oficial, servidores em nuvem leves são baixo custo para 112 yuans/ano, e novos usuários podem desfrutar de descontos ultrabaixos em seu primeiro pedido.
Índice
1.1 Inserção de dados de linha única
1.2 Inserção de dados de múltiplas linhas
1.3 Inserir ou substituir atualizações
1.1 Consulta de coluna completa
1.2 Especifique a consulta de coluna + use selsct para calcular expressões
1.3 Elimine duplicatas dos resultados da triagem
2.2 Encontre alunos cuja pontuação em inglês seja inferior a 60 e suas pontuações em inglês
2.3 Alunos cujas pontuações em chinês são [80, 90] e suas pontuações em chinês
2.4 Alunos cujas notas em matemática são 58 ou 59 ou 98 ou 99 e suas notas em matemática
2.5 Filtrar colegas chamados Sun e colegas chamados Sun (pesquisa difusa)
2.6 Alunos cujas pontuações em chinês são superiores às pontuações em inglês
2.7 Alunos cuja pontuação total seja inferior a 200 pontos
2.8 Alunos cujas pontuações em chinês são >80 e cujo sobrenome não é Sun
3. ordenar por asc/desc (ordem crescente/decrescente dos resultados)
3.3 Consultar colegas e pontuações totais, de alto a baixo
4. limite (exibir um pequeno número de resultados)
1. Altere a pontuação matemática de Sun Wukong para 80 pontos
2. Altere a pontuação matemática de Cao Mengde para 60 pontos e sua pontuação chinesa para 70 pontos
3. Adicione 30 pontos às notas de matemática dos três alunos com as notas totais mais baixas.
4. Atualize as pontuações em chinês de todos os alunos para o dobro do valor original
1. Exclua os resultados do teste de Sun Wukong
2. Exclua os dados dos alunos com maior pontuação total
3. Exclua todos os dados da tabela
3.2 Truncar tabela (use com cuidado)
5. Insira os dados filtrados no banco de dados (inserir+selecionar)
1. Exclua registros duplicados da tabela. Só pode haver uma cópia dos dados duplicados.
1. COUNT([DISTINCT] expr) retorna o número de dados consultados
2. SUM([DISTINCT] expr) retorna a soma dos dados consultados. Não tem sentido se não for um número.
7. Cláusula Group by: consulta de grupo na coluna especificada
1. Importar tabela de informações de funcionários
2. Exiba o salário médio e o salário máximo de cada departamento
3. Exiba o salário médio e o salário mínimo de cada departamento e cada cargo
4. Exiba os departamentos com salário médio abaixo de 2.000 e seu salário médio
5.1A diferença entre ter e onde
CRUD: Criar, Recuperar, Atualizar, Excluir
1. Crie
gramática:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...Primeiro crie uma tabela de alunos:
--创建学生表
mysql> create table if not exists students(
-> id int unsigned primary key auto_increment,
-> sn int unsigned unique key,
-> name varchar(20) not null,
-> qq varchar(32) unique key
-> );
Query OK, 0 rows affected (0.31 sec)1. inserir(inserir)
1.1 Inserção de dados de linha única
Insira uma única linha de uma coluna especificada:
mysql> insert into students (sn,name,qq) values (100,'张三','123456');
Query OK, 1 row affected (0.04 sec)Inserção de linha única e coluna completa:
mysql> insert into students values (2,101,'李四','222222');
Query OK, 1 row affected (0.05 sec)1.2 Inserção de dados de múltiplas linhas
mysql> insert into students (sn,name,qq) values (102,'王五','333333'),(103,'赵六',444444);
Query OK, 2 rows affected (0.04 sec)
Records: 2 Duplicates: 0 Warnings: 0Cada dado inserido é separado por vírgulas para obter o efeito de inserir várias linhas de uma vez.
1.3 Inserir ou substituir atualizações
--打印当前学生表数据
mysql> select* from students;
+----+------+--------+--------+
| id | sn | name | qq |
+----+------+--------+--------+
| 1 | 100 | 张三 | 123456 |
| 2 | 101 | 李四 | 222222 |
| 3 | 102 | 王五 | 333333 |
| 4 | 103 | 赵六 | 444444 |
+----+------+--------+--------+
4 rows in set (0.00 sec)
--重复插入主键为2的值,主键冲突,插入失败
mysql> insert into students values (2,104,'小明','111111');
ERROR 1062 (23000): Duplicate entry '2' for key 'PRIMARY'
--插入变更新,注意作为更新的值可以和插入的值不一样
mysql> insert into students values (2,104,'小明',111111) on duplicate key update sn=104,name='小明',qq='111111';
Query OK, 2 rows affected (0.04 sec)
--打印当前学生表数据,发现id=2的数据被更新
mysql> select* from students;
+----+------+--------+--------+
| id | sn | name | qq |
+----+------+--------+--------+
| 1 | 100 | 张三 | 123456 |
| 2 | 104 | 小明 | 111111 |
| 3 | 102 | 王五 | 333333 |
| 4 | 103 | 赵六 | 444444 |
+----+------+--------+--------+
4 rows in set (0.01 sec)Para inserir dados, primeiro os dados devem ser legais (os campos relevantes não são limitados por chaves exclusivas, chaves primárias, chaves estrangeiras, etc.) Em segundo lugar, se o id dos dados inseridos já existir, sn, name e qq serão atualizado em vez da falha de inserção.
2. substituir(substituir)
--如果替代的数据在表中无冲突,replace将被当成插入
mysql> replace into students (sn,name,qq) values (105,'小红','555555');
Query OK, 1 row affected (0.46 sec)
--打印当前学生表数据,可以看到表中多了一行小红的信息
mysql> select* from students;
+----+------+--------+--------+
| id | sn | name | qq |
+----+------+--------+--------+
| 1 | 100 | 张三 | 123456 |
| 2 | 104 | 小明 | 111111 |
| 3 | 102 | 王五 | 333333 |
| 4 | 103 | 赵六 | 444444 |
| 5 | 105 | 小红 | 555555 |
+----+------+--------+--------+
5 rows in set (0.00 sec)
--再次replace,唯一键存在冲突,小红1的数据将替换小红的数据
mysql> replace into students (sn,name,qq) values (105,'小红1','555555');
Query OK, 2 rows affected (0.02 sec)
--打印当前学生表数据,发现小红1的id变为6
mysql> select* from students;
+----+------+---------+--------+
| id | sn | name | qq |
+----+------+---------+--------+
| 1 | 100 | 张三 | 123456 |
| 2 | 104 | 小明 | 111111 |
| 3 | 102 | 王五 | 333333 |
| 4 | 103 | 赵六 | 444444 |
| 6 | 105 | 小红1 | 555555 |
+----+------+---------+--------+
5 rows in set (0.00 sec)Se não houver conflito na chave primária ou na chave exclusiva, insira-a diretamente;
Se a chave primária ou a chave exclusiva entrar em conflito, exclua-a e insira-a.
Há um detalhe: quando ocorre uma substituição, porque a chave primária será incrementada automaticamente e a substituição será excluída e depois substituída, o ID da linha usado para substituição usará o próximo ID de incremento automático. Por exemplo, na instrução SQL acima, o ID original de Xiaohong é 5. Após ser substituído por Xiaohong1, o ID passa a ser 6.
2. Recuperar (ler)
gramática:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...Primeiro crie uma planilha de pontuação:
--创建成绩表
mysql> CREATE TABLE exam_result (
-> id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20) NOT NULL COMMENT '同学姓名',
-> chinese float DEFAULT 0.0 COMMENT '语文成绩',
-> math float DEFAULT 0.0 COMMENT '数学成绩',
-> english float DEFAULT 0.0 COMMENT '英语成绩'
-> );
Query OK, 0 rows affected (0.14 sec)
--插入测试数据
mysql> INSERT INTO exam_result (name, chinese, math, english) VALUES
-> ('A', 67, 98, 56),
-> ('B', 87, 78, 77),
-> ('C', 88, 98, 90),
-> ('D', 82, 84, 67),
-> ('E', 55, 85, 45),
-> ('F', 70, 73, 78),
-> ('G', 75, 65, 30);
ds: 7 Duplicates: 0 Warnings: 0Query OK, 7 rows affected (0.03 sec)
Records: 7 Duplicates: 0 Warnings: 01、selecione
1.1 Consulta de coluna completa
mysql> select* from exam_result;
+----+------+---------+------+---------+
| id | name | chinese | math | english |
+----+------+---------+------+---------+
| 1 | A | 67 | 98 | 56 |
| 2 | B | 87 | 78 | 77 |
| 3 | C | 88 | 98 | 90 |
| 4 | D | 82 | 84 | 67 |
| 5 | E | 55 | 85 | 45 |
| 6 | F | 70 | 73 | 78 |
| 7 | G | 75 | 65 | 30 |
+----+------+---------+------+---------+
7 rows in set (0.00 sec)Geralmente não é recomendado usar * para consulta de coluna completa
1. Quanto mais colunas consultadas, maior será a quantidade de dados que precisam ser transmitidos;
2. Pode afetar o uso de índices.
1.2 Especifique a consulta de coluna + use selsct para calcular expressões
--指定姓名和数学成绩列进行查询
mysql> select name,math from exam_result;
+------+------+
| name | math |
+------+------+
| A | 98 |
| B | 78 |
| C | 98 |
| D | 84 |
| E | 85 |
| F | 73 |
| G | 65 |
+------+------+
7 rows in set (0.00 sec)--利用selsct计算平均分
mysql> select name,math,(chinese+math+english)/3 from exam_result;
+------+------+--------------------------+
| name | math | (chinese+math+english)/3 |
+------+------+--------------------------+
| A | 98 | 73.66666666666667 |
| B | 78 | 80.66666666666667 |
| C | 98 | 92 |
| D | 84 | 77.66666666666667 |
| E | 85 | 61.666666666666664 |
| F | 73 | 73.66666666666667 |
| G | 65 | 56.666666666666664 |
+------+------+--------------------------+
--觉得计算式太长,可以用as给它重命名为average
mysql> select name,math,(chinese+math+english)/3 as average from exam_result;
+------+------+--------------------+
| name | math | average |
+------+------+--------------------+
| A | 98 | 73.66666666666667 |
| B | 78 | 80.66666666666667 |
| C | 98 | 92 |
| D | 84 | 77.66666666666667 |
| E | 85 | 61.666666666666664 |
| F | 73 | 73.66666666666667 |
| G | 65 | 56.666666666666664 |
+------+------+--------------------+
7 rows in set (0.02 sec)
--当然这个as可以省略
mysql> select name 姓名,math 数学,(chinese+math+english)/3 平均分 from exam_result;
+--------+--------+--------------------+
| 姓名 | 数学 | 平均分 |
+--------+--------+--------------------+
| A | 98 | 73.66666666666667 |
| B | 78 | 80.66666666666667 |
| C | 98 | 92 |
| D | 84 | 77.66666666666667 |
| E | 85 | 61.666666666666664 |
| F | 73 | 73.66666666666667 |
| G | 65 | 56.666666666666664 |
+--------+--------+--------------------+
7 rows in set (0.01 sec)1.3 Elimine duplicatas dos resultados da triagem
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
6 rows in set (0.00 sec)2、onde
2.1 Operadores
Operadores de comparação:
| operador |
ilustrar |
| >, >=, <, <= |
Maior que, maior ou igual a, menor que, menor ou igual a |
| = |
Igual a, NULL é inseguro , por exemplo, o resultado de NULL = NULL é NULL |
| <=> |
Igual a, NULL é seguro, por exemplo, o resultado de NULL <=> NULL é TRUE(1) |
| !=, <> |
Diferente de (ambos os símbolos são NULL inseguros) |
| ENTRE a0 E a1 |
Correspondência de intervalo, [a0, a1], se a0 <= valor <= a1, retorne TRUE(1) |
| DENTRO (opção, ...) |
Se for qualquer uma das opções, retorne TRUE(1) |
| É NULO |
é nulo |
| NÃO É NULO |
Não nulo |
| COMO |
Correspondência difusa. como um%'. % representa qualquer número (incluindo 0) de qualquer caractere; como 'A_'. _ representa qualquer caractere |
Operadores lógicos:
| operador |
ilustrar |
| E |
Várias condições devem ser todas TRUE(1) e o resultado é TRUE(1) |
| OU |
Se qualquer condição for TRUE(1), o resultado será TRUE(1) |
| NÃO |
A condição é TRUE(1), o resultado é FALSE(0) |
2.2 Encontre alunos cuja pontuação em inglês seja inferior a 60 e suas pontuações em inglês
mysql> select name,english from exam_result where english<60;
+------+---------+
| name | english |
+------+---------+
| A | 56 |
| E | 45 |
| G | 30 |
+------+---------+
3 rows in set (0.00 sec)2.3 Alunos cujas pontuações em chinês são [80, 90] e suas pontuações em chinês
-- >=和<=
mysql> select name,chinese from exam_result where chinese>=80 and chinese <=90;
+------+---------+
| name | chinese |
+------+---------+
| B | 87 |
| C | 88 |
| D | 82 |
+------+---------+
3 rows in set (0.01 sec)
--between a0 and a1
mysql> select name,chinese from exam_result where chinese between 80 and 90;
+------+---------+
| name | chinese |
+------+---------+
| B | 87 |
| C | 88 |
| D | 82 |
+------+---------+
3 rows in set (0.00 sec)2.4 Alunos cujas notas em matemática são 58 ou 59 ou 98 ou 99 e suas notas em matemática
--可以采用多个or
mysql> select name,math from exam_result where math=58 or math=59 or math=98 or math=99;
+------+------+
| name | math |
+------+------+
| A | 98 |
| C | 98 |
+------+------+
2 rows in set (0.02 sec)
--可以用in(......)
mysql> select name,math from exam_result where math in(58,59,98,99);
+------+------+
| name | math |
+------+------+
| A | 98 |
| C | 98 |
+------+------+
2 rows in set (0.00 sec)2.5 Filtrar colegas chamados Sun e colegas chamados Sun (pesquisa difusa)
--对新表插入数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);-- like '孙%'找到所有孙姓同学,%代表后面模糊匹配0-n个字符
mysql> select name from exam_result where name like '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.00 sec)
--like '孙_'找到所有孙某同学,_代表模糊匹配1个字符
mysql> select name from exam_result where name like '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)2.6 Alunos cujas pontuações em chinês são superiores às pontuações em inglês
mysql> select name,chinese,english from exam_result where chinese>english;
+-----------+---------+---------+
| name | chinese | english |
+-----------+---------+---------+
| 唐三藏 | 67 | 56 |
| 孙悟空 | 87 | 77 |
| 曹孟德 | 82 | 67 |
| 刘玄德 | 55 | 45 |
| 宋公明 | 75 | 30 |
+-----------+---------+---------+
5 rows in set (0.00 sec)2.7 Alunos cuja pontuação total seja inferior a 200 pontos
mysql> select name,chinese,math,english,chinese+math+english 总分 from exam_result where chinese+math+english<200;
+-----------+---------+------+---------+--------+
| name | chinese | math | english | 总分 |
+-----------+---------+------+---------+--------+
| 刘玄德 | 55 | 85 | 45 | 185 |
| 宋公明 | 75 | 65 | 30 | 170 |
+-----------+---------+------+---------+--------+
2 rows in set (0.00 sec)
A sequência de execução deste SQL é mostrada na figura acima. Portanto, não é possível usar diretamente a pontuação total depois de expressar chinês+matemática+inglês. (Vá para a tabela exam_result para encontrar alunos cujo chinês + matemática + inglês seja inferior a 200 e imprima-o)
2.8 Alunos cujas pontuações em chinês são >80 e cujo sobrenome não é Sun
mysql> select name,chinese from exam_result where chinese>80 and name not like '孙%';
+-----------+---------+
| name | chinese |
+-----------+---------+
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
2 rows in set (0.00 sec)2.9 Aluno Sun, caso contrário, a pontuação total deverá ser> 200 e pontuação em chinês <pontuação em matemática e pontuação em inglês> 80
mysql> select name,chinese,math,english,chinese+math+english 总分 from exam_result where name like '孙_' or (chinese+math+english>200 and chinese<math and english>80);
+-----------+---------+------+---------+--------+
| name | chinese | math | english | 总分 |
+-----------+---------+------+---------+--------+
| 猪悟能 | 88 | 98 | 90 | 276 |
| 孙权 | 70 | 73 | 78 | 221 |
+-----------+---------+------+---------+--------+
2 rows in set (0.00 sec)2.10 Consulta NULA
--创建一个新表
mysql> create table test(
-> id int,
-> name varchar(20)
-> );
Query OK, 0 rows affected (0.09 sec)
--插入数据
mysql> insert into test (id,name) values (1,'张三');
Query OK, 1 row affected (0.04 sec)
mysql> insert into test (id,name) values (null,'张三');
Query OK, 1 row affected (0.05 sec)
mysql> insert into test (id,name) values (1,null);
Query OK, 1 row affected (0.05 sec)
mysql> insert into test (id,name) values (null,null);
Query OK, 1 row affected (0.02 sec)
mysql> insert into test (id,name) values (1,'');
Query OK, 1 row affected (0.01 sec)
--打印表结构
mysql> select* from test;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| NULL | 张三 |
| 1 | NULL |
| NULL | NULL |
| 1 | |
+------+--------+
5 rows in set (0.02 sec)consulta nula:
mysql> select* from test where name is null;
+------+------+
| id | name |
+------+------+
| 1 | NULL |
| NULL | NULL |
+------+------+
2 rows in set (0.01 sec)
mysql> select* from test where name is not null;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| NULL | 张三 |
| 1 | |
+------+--------+
3 rows in set (0.01 sec)Nota: null é nulo e uma string vazia é uma string vazia, o que é diferente.
mysql> SELECT NULL = NULL, NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
1 row in set (0.00 sec)
mysql> SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
1 row in set (0.01 sec)Comparação entre nulos não pode usar =, você deve usar <=> ou é nulo ou não é nulo
3. ordenar por asc/desc (ordem crescente/decrescente dos resultados)
3.1 Os alunos e as pontuações em matemática são exibidos em ordem crescente/decrescente de acordo com as pontuações em matemática.
mysql> select name,math from exam_result order by math asc;
+-----------+------+
| name | math |
+-----------+------+
| 张三 | NULL |
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
8 rows in set (0.00 sec)
mysql> select name,math from exam_result order by math desc;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
| 刘玄德 | 85 |
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
| 宋公明 | 65 |
| 张三 | NULL |
+-----------+------+
8 rows in set (0.00 sec)- ASC está em ordem crescente (de pequeno para grande)
-- DESC está em ordem decrescente (de grande para pequeno)
-- O padrão é ASC
-- NULL é tratado como menor que qualquer valor
3.2 Consulte as pontuações dos alunos em cada disciplina e exiba-as em ordem decrescente de matemática, ordem decrescente de inglês e ordem crescente de chinês.
mysql> select name,math,english,chinese from exam_result order by math desc,english desc,chinese asc;
+-----------+------+---------+---------+
| name | math | english | chinese |
+-----------+------+---------+---------+
| 猪悟能 | 98 | 90 | 88 |
| 唐三藏 | 98 | 56 | 67 |
| 刘玄德 | 85 | 45 | 55 |
| 曹孟德 | 84 | 67 | 82 |
| 孙悟空 | 78 | 77 | 87 |
| 孙权 | 73 | 78 | 70 |
| 宋公明 | 65 | 30 | 75 |
| 张三 | NULL | NULL | NULL |
+-----------+------+---------+---------+
8 rows in set (0.00 sec)3.3 Consultar colegas e pontuações totais, de alto a baixo
mysql> select name,chinese,math,english,chinese+math+english 总分 from exam_result order by 总分 desc;
+-----------+---------+------+---------+--------+
| name | chinese | math | english | 总分 |
+-----------+---------+------+---------+--------+
| 猪悟能 | 88 | 98 | 90 | 276 |
| 孙悟空 | 87 | 78 | 77 | 242 |
| 曹孟德 | 82 | 84 | 67 | 233 |
| 唐三藏 | 67 | 98 | 56 | 221 |
| 孙权 | 70 | 73 | 78 | 221 |
| 刘玄德 | 55 | 85 | 45 | 185 |
| 宋公明 | 75 | 65 | 30 | 170 |
| 张三 | NULL | NULL | NULL | NULL |
+-----------+---------+------+---------+--------+
8 rows in set (0.00 sec)
mysql> A instrução where acima não pode usar aliases. Mas aliases podem ser usados aqui devido ao problema do pedido.
Primeira prioridade: deixe claro qual tabela exam_result você está procurando
Segunda prioridade: cláusula where
Terceira prioridade: pontuação total em chinês+matemática+inglês
Quarta prioridade: ordenar por pontuação total (por favor, tenha os dados apropriados antes de classificar)
Quinta prioridade: limite (os dados serão exibidos somente quando estiverem prontos)
3.4 Consulte as notas de matemática dos alunos de sobrenome Sun ou dos alunos de sobrenome Cao. Os resultados serão exibidos na ordem das notas de matemática, de maior para menor.
mysql> select name,math from exam_result where name like '孙%' or name like '曹%' order by math desc limit 3 offset 0;
+-----------+------+
| name | math |
+-----------+------+
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
+-----------+------+
3 rows in set (0.00 sec)4. limite (exibir um pequeno número de resultados)
--从表开始连续读取5行
mysql> select* from exam_result limit 5;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
+----+-----------+---------+------+---------+
5 rows in set (0.01 sec)
--limit 1,3;开始位置1是下标,3是步长
mysql> select* from exam_result limit 1,3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
+----+-----------+---------+------+---------+
3 rows in set (0.01 sec)
--limit s offset n其中s代表步长,n代表下标
mysql> select* from exam_result limit 3 offset 5;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 8 | 张三 | NULL | NULL | NULL |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)Ao consultar uma tabela desconhecida, é melhor adicionar um LIMIT 1 para evitar que o banco de dados fique travado devido à consulta de todos os dados da tabela porque os dados na tabela são muito grandes.
selecione* do limite de resultado_exame 0,3;
selecione* do limite de resultado_exame 3,3;
selecione* do limite de resultado_exame 6,3;
......
selecione* do limite de resultado_exame 3 deslocamento 0;
selecione* do limite de resultado_exame 3 deslocamento 3;
selecione* do limite de resultado_exame 3 deslocamento 6;
Execute a exibição paginada.
3. Atualização
gramática:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]1. Altere a pontuação matemática de Sun Wukong para 80 pontos
mysql> update exam_result set math=80 where name ='孙悟空';
Query OK, 1 row affected (0.07 sec)2. Altere a pontuação matemática de Cao Mengde para 60 pontos e sua pontuação chinesa para 70 pontos
mysql> update exam_result set math=60,chinese=70 where name ='曹孟德';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 03. Adicione 30 pontos às notas de matemática dos três alunos com as notas totais mais baixas.
mysql> update exam_result set math=math+30 order by chinese+math+english asc limit 3;
Query OK, 2 rows affected (0.05 sec)
Rows matched: 3 Changed: 2 Warnings: 04. Atualize as pontuações em chinês de todos os alunos para o dobro do valor original
mysql> update exam_result set chinese=chinese*2;
Query OK, 7 rows affected (0.04 sec)
Rows matched: 8 Changed: 7 Warnings: 0
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 2 | 孙悟空 | 174 | 80 | 77 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 60 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
| 8 | 张三 | NULL | NULL | NULL |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)Tenha cuidado ao atualizar diretamente a tabela inteira sem uma cláusula where! Uma atualização errada é tão prejudicial quanto uma exclusão.
4. Excluir
gramática:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]1. Exclua os resultados do teste de Sun Wukong
mysql> delete from exam_result where name='孙悟空';
Query OK, 1 row affected (0.04 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 60 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
| 8 | 张三 | NULL | NULL | NULL |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)2. Exclua os dados dos alunos com maior pontuação total
mysql> delete from exam_result order by chinese+math+english desc limit 1;
Query OK, 1 row affected (0.02 sec)3. Exclua todos os dados da tabela
3.1excluir de
--准备测试表
mysql> CREATE TABLE for_delete (
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20)
-> );
Query OK, 0 rows affected (0.15 sec)
--插入测试数据
mysql> INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.04 sec)
Records: 3 Duplicates: 0 Warnings: 0
--查看表结构
mysql> select* from for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)
--查看创建表时的SQL,可以发现,下一次自增的id值是4
mysql> show create table for_delete\G;
*************************** 1. row ***************************
Table: for_delete
Create Table: CREATE TABLE `for_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=gbk
1 row in set (0.00 sec)
--删除表
mysql> delete from for_delete;
Query OK, 3 rows affected (0.04 sec)
--查看创建表的SQL,发现自增值仍为4
mysql> show create table for_delete\G;
*************************** 1. row ***************************
Table: for_delete
Create Table: CREATE TABLE `for_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=gbk
1 row in set (0.02 sec)Usar deselect from para limpar o conteúdo da tabela não alterará o valor do incremento automático.
3.2 Truncar tabela (use com cuidado)
gramática:
TRUNCATE [TABLE] table_name--准备测试表
mysql> CREATE TABLE for_truncate (
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20)
-> );
Query OK, 0 rows affected (0.14 sec)
--插入测试数据
mysql> INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.04 sec)
Records: 3 Duplicates: 0 Warnings: 0
--查看表结构
mysql> select* from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.01 sec)
--查看创建表时的SQL,可以发现,下一次自增的id值是4
5mysql> show create table for_truncate\G;
*************************** 1. row ***************************
Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=gbk
1 row in set (0.01 sec)
--删除表中数据
mysql> truncate for_truncate;
Query OK, 0 rows affected (0.21 sec)
--查看创建表时的SQL,发现AUTO_INCREMENT字段没了
mysql> show create table for_truncate\G;
*************************** 1. row ***************************
Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk
1 row in set (0.01 sec)
--新插入一条数据
mysql> insert into for_truncate (name) values ('E');
Query OK, 1 row affected (0.04 sec)
--查看表结构,发现id从1开始
mysql> select* from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | E |
+----+------+
1 row in set (0.00 sec)
--查看创建表的SQL,出现自增字段,下一次自增值是2
mysql> show create table for_truncate\G;
*************************** 1. row ***************************
Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=gbk
1 row in set (0.00 sec)Use a operação truncada com cuidado
1. Ele só pode operar em toda a tabela e não pode operar em dados parciais como DELETE;
2. O MySQL não registra registros de operações truncadas no log (DELETE faz), por isso é mais rápido que DELETE. No entanto, quando TRUNCATE exclui dados, ele não passa pela transação real, portanto não pode ser revertido.
3. Quando truncar limpa a tabela, ele inicializa o valor de incremento automático.
5. Insira os dados filtrados no banco de dados (inserir+selecionar)
INSERT INTO table_name [(column [, column ...])] SELECT ...1. Exclua registros duplicados da tabela. Só pode haver uma cópia dos dados duplicados.
Crie uma cópia dos dados brutos:
--创建表结构
mysql> CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.26 sec)
--插入测试数据
mysql> INSERT INTO duplicate_table VALUES
-> (100, 'aaa'),
-> (100, 'aaa'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (300, 'ccc');
Query OK, 6 rows affected (0.03 sec)
Records: 6 Duplicates: 0 Warnings: 0Ideias para desduplicação: 1. Crie uma tabela vazia com os mesmos atributos da tabela original
--创建一张属性和duplicate_table一样的表no_duplicate_table(空表)
mysql> create table no_duplicate_table like duplicate_table;
Query OK, 0 rows affected (0.23 sec)
--它是空表
mysql> select* from no_duplicate_table;
Empty set (0.01 sec)
--但是属性和duplicate_table一样
mysql> desc no_duplicate_table;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.02 sec)2. Use distinto para filtrar os dados deduplicados na tabela original.
--对原表select出来的结果insert进新表中
mysql> insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 3 rows affected (0.05 sec)
Records: 3 Duplicates: 0 Warnings: 0
--查看新表数据
mysql> select* from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.01 sec)3. Altere o nome da tabela original para outro nome e altere os dados da nova tabela para o nome da tabela original (o gato-guaxinim é substituído pelo príncipe).
--改名
mysql> rename table duplicate_table to old_duplicate_table,no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.17 sec)
--查看表
mysql> select* from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.02 sec)Preparamos a nova tabela antes de renomeá-la. Ao renomear a tabela, podemos realizar a operação de desduplicação atômica.
A renomeação aqui é simplesmente uma mudança de nome, que na verdade é uma mudança no relacionamento de mapeamento entre o nome do arquivo e o inode.
6. Função de agregação
| função |
ilustrar |
| CONTAGEM([DISTINCT] expr) |
Retorna o número de dados consultados |
| SOMA([DISTINTO] expr) |
Retorna a soma dos dados consultados.Não tem sentido se não for um número. |
| AVG([DISTINTO] expr) |
Retorna o valor médio dos dados consultados.Não tem sentido se não for um número. |
| MAX([DISTINTO] expr) |
Retorna o valor máximo dos dados consultados.Não tem sentido se não for um número. |
| MIN([DISTINTO] expr) |
Retorna o valor mínimo dos dados consultados.Não tem sentido se não for um número. |
1. COUNT([DISTINCT] expr) retorna o número de dados consultados
mysql> select* from old_duplicate_table;;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 100 | aaa |
| 200 | bbb |
| 200 | bbb |
| 200 | bbb |
| 300 | ccc |
+------+------+
6 rows in set (0.01 sec)
--统计去重的名字有几个
mysql> select count(distinct name) 总数 from old_duplicate_table;
+--------+
| 总数 |
+--------+
| 3 |
+--------+
1 row in set (0.00 sec)
--统计共有几行
mysql> select count(*) from old_duplicate_table;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
--统计共有几行
mysql> select count(2) from old_duplicate_table;
+----------+
| count(2) |
+----------+
| 6 |
+----------+
1 row in set (0.00 sec)
--统计id小于200的行数
mysql> select count(*) from old_duplicate_table where id<200;
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.01 sec)2. SUM([DISTINCT] expr) retorna a soma dos dados consultados. Não tem sentido se não for um número.
--统计id和
mysql> select sum(id) from old_duplicate_table;
+---------+
| sum(id) |
+---------+
| 1100 |
+---------+
1 row in set (0.00 sec)
--统计id的平均值
mysql> select sum(id)/count(*) from old_duplicate_table;
+------------------+
| sum(id)/count(*) |
+------------------+
| 183.3333 |
+------------------+
1 row in set (0.00 sec)3. AVG([DISTINCT] expr) retorna o valor médio dos dados consultados. Não tem sentido se não for um número.
--统计id的平均值
mysql> select avg(id) from old_duplicate_table;
+----------+
| avg(id) |
+----------+
| 183.3333 |
+----------+
1 row in set (0.00 sec)4. MAX([DISTINCT] expr) retorna o valor máximo dos dados consultados. Não tem sentido se não for um número.
4、MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义5. MIN([DISTINCT] expr) retorna o valor mínimo dos dados consultados. Não tem sentido se não for um número.
--查找最小的id
mysql> select min(id) from old_duplicate_table;
+---------+
| min(id) |
+---------+
| 100 |
+---------+
1 row in set (0.01 sec)
--查找id大于150的最小值
mysql> select min(id) from old_duplicate_table where id>150;
+---------+
| min(id) |
+---------+
| 200 |
+---------+
1 row in set (0.00 sec)7. Cláusula Group by: consulta de grupo na coluna especificada
O objetivo do agrupamento é agregar estatísticas.
select column1, column2, .. from table group by column;1. Importar tabela de informações de funcionários
--将linux目录下的sql表导入MySQL
mysql> source /home/jly/scott_data.sql;
mysql> use scott;
Database changed
mysql> show tables;
+-----------------+
| Tables_in_scott |
+-----------------+
| dept |
| emp |
| salgrade |
+-----------------+Crie uma tabela de informações de funcionários (tabela de teste clássica do Oracle 9i)
Lista de funcionários do EMP
Tabela de departamento DEPT
Escala salarial SALGRADE
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);2. Exiba o salário médio e o salário máximo de cada departamento
mysql> select* from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)--按部门对各部门的平均工资和最高工资进行统计
mysql> select deptno,avg(sal),max(sal) from emp group by deptno;
+--------+-------------+----------+
| deptno | avg(sal) | max(sal) |
+--------+-------------+----------+
| 10 | 2916.666667 | 5000.00 |
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
+--------+-------------+----------+
3 rows in set (0.01 sec)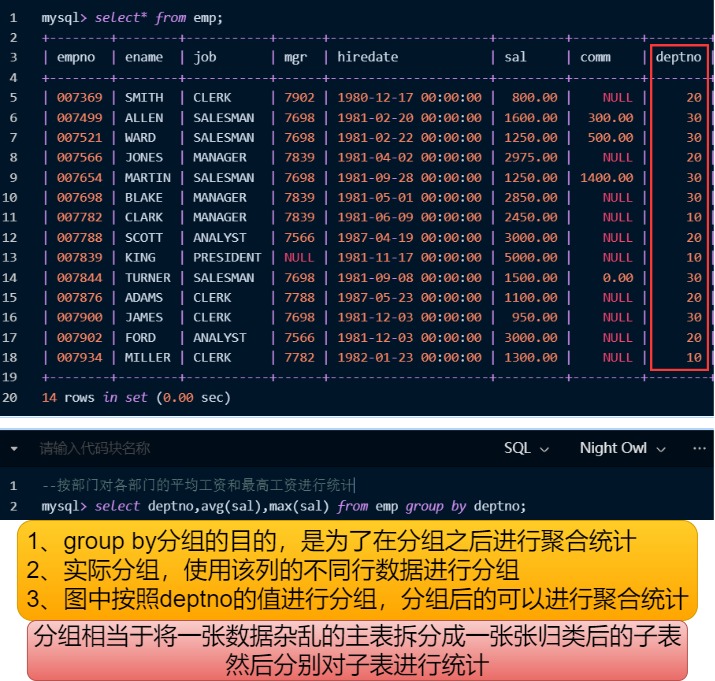
3. Exiba o salário médio e o salário mínimo de cada departamento e cada cargo
Consulta de grupo com múltiplas condições de agrupamento:
mysql> select deptno,job,avg(sal),max(sal) from emp group by deptno,job;
+--------+-----------+-------------+----------+
| deptno | job | avg(sal) | max(sal) |
+--------+-----------+-------------+----------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 1100.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1600.00 |
+--------+-----------+-------------+----------+
9 rows in set (0.00 sec)Se você adicionar um campo de filtro de nome após o filtro de seleção, um erro será relatado:

4. Exiba os departamentos com salário médio abaixo de 2.000 e seu salário médio
1. Primeiro, conte o salário médio de cada departamento (primeiro grupo e agregue o salário médio por departamento)
2. Em seguida, use o julgamento condicional dos resultados da agregação.
mysql> select deptno,avg(sal) as 平均工资 from emp group by deptno having 平均工资<2000;
+--------+--------------+
| deptno | 平均工资 |
+--------+--------------+
| 30 | 1566.666667 |
+--------+--------------+5. 'Smith' não participa das estatísticas, que mostram os tipos de trabalho com salário médio inferior a 2.000 para cada departamento e cada cargo.
mysql> select deptno,job,avg(sal) 平均工资 from emp where ename!='SMITH' group by deptno,job having 平均工资<2000;
+--------+----------+--------------+
| deptno | job | 平均工资 |
+--------+----------+--------------+
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 30 | SALESMAN | 1400.000000 |
+--------+----------+--------------+
4 rows in set (0.01 sec)5.1A diferença entre ter e onde
1. Ter e onde podem ser usados para filtragem condicional. A agregação de grupo só pode usar tendo e não onde. No entanto, para filtrar com apenas uma tabela, ambos tendo e onde podem ser usados. No entanto, não é recomendado usar tendo em este cenário (para distinguir não é recomendado usar tendo).Recomenda-se misturá-los e deixar onde fazer o trabalho de onde)
2. Os objetos de triagem são diferentes, conforme abaixo:
3. A ordem de filtragem de condições é diferente, conforme mostrado abaixo:

