Prefácio
Organize alguns parâmetros de linha de comando comumente usados em documentos oficiais yolov8, documentos oficiais YOLOv8 Docs
O formato de execução unificado da linha de comando yolov8 é:
yolo TASK MODE ARGS
Existem três partes principais na transferência de parâmetros:
- TAREFA (opcional) é [detectar, segmentar, classificar]. Se não for passado explicitamente, YOLOv8 tentará adivinhar TASK a partir do tipo de modelo.
- MODO (obrigatório) é um dos seguintes: [treinar, val, prever, exportar]
- ARGS (opcional) é qualquer número de pares arg=valor personalizados, como imgsz=320, substituindo o valor padrão.
1. Parâmetros de treinamento
Exemplo de linha de comando de treinamento:
# 从YAML中构建一个新模型,并从头开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
# 从预先训练的*.pt模型开始训练
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
# 从YAML中构建一个新的模型,将预训练的权重传递给它,并开始训练
yolo detect train data=coco128.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 imgsz=640
Exemplo de código python correspondente:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # 从YAML中构建一个新模型
model = YOLO('yolov8n.pt') #加载预训练的模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML构建并传递权重
# Train the model
model.train(data='coco128.yaml', epochs=100, imgsz=640)
Alguns dos parâmetros mais comumente usados:
| chave | explicar |
|---|---|
| modelo | O arquivo model.yaml ou arquivo model.pt passado é usado para construir a rede e inicializar. A diferença é que se apenas o arquivo yaml for passado, os parâmetros serão inicializados aleatoriamente. |
| dados | Arquivo yaml de configuração do conjunto de dados de treinamento |
| épocas | Rodadas de treinamento, padrão 100 |
| paciência | O número de rodadas para treinamento e observação de parada antecipada por padrão é 50. Se não houver melhoria na precisão em 50 rodadas, o modelo interromperá o treinamento diretamente. |
| lote | Lote de treinamento, padrão 16 |
| imagens | Tamanho da imagem de treinamento, padrão 640 |
| salvar | Salve o processo de treinamento e os pesos de treinamento, habilitados por padrão |
| período_salvar | Durante o processo de treinamento, o modelo de treinamento é salvo a cada x rodadas, o padrão é -1 (não habilitado) |
| esconderijo | Se deve usar memória RAM para carregamento de dados. Definir True irá acelerar o treinamento, mas este parâmetro consome muita memória e geralmente é definido pelos servidores. |
| dispositivo | O dispositivo para execução, ou seja, cuda device =0 ou Device =0,1,2,3 ou device=cpu |
| trabalhadores | O número de threads para carregar dados. O Windows geralmente é 4 e o servidor pode ser maior. Este parâmetro no Windows pode causar erros de thread. Se você descobrir que erros de thread são relatados, você pode tentar reduzir esse parâmetro. Este parâmetro é padronizado como 8, e a maioria deles precisa ser reduzido. |
| projeto | O nome da pasta do projeto, o padrão é execuções |
| nome | Usado para salvar o nome da pasta de treinamento, exp padrão, acumulado em sequência |
| existe_ok | Se deve substituir a pasta salva existente, o padrão é False |
| pré-treinado | Se deseja carregar pesos pré-treinados, o padrão é Flase |
| otimizador | Seleção de otimizador, SGD padrão, opcional [SGD, Adam, AdamW, RMSProP] |
| detalhado | Se deve imprimir resultados detalhados |
| semente | Semente aleatória, usada para reproduzir o modelo, padrão 0 |
| determinístico | Defina como True para garantir a reprodutibilidade dos experimentos |
| single_cls | Treine dados de múltiplas categorias em uma única categoria e trate todos os dados como uma única categoria para treinamento. O padrão é Flase. |
| pesos_imagem | Use seleção de imagem ponderada para treinamento, o padrão é Flase |
| correto | Use treinamento de retângulo, que é o mesmo que inferência de retângulo. O padrão é Falso. |
| cos_lr | Use agendamento de taxa de aprendizagem de cosseno, o padrão é Flase |
| fechar_mosaico | O aprimoramento do mosaico está desativado nas últimas x rodadas, padrão 10 |
| retomar | Treinamento de breakpoint, o padrão é Flase |
| lr0 | Taxa de aprendizado de inicialização, padrão 0,01 |
| lrf | Taxa de aprendizagem final, padrão 0,01 |
| etiqueta_suavização | Parâmetro de suavização de rótulo, padrão 0,0 |
| cair fora | Use regularização de abandono (classificação apenas para treinamento), padrão 0,0 |
Parâmetros de aumento de dados:
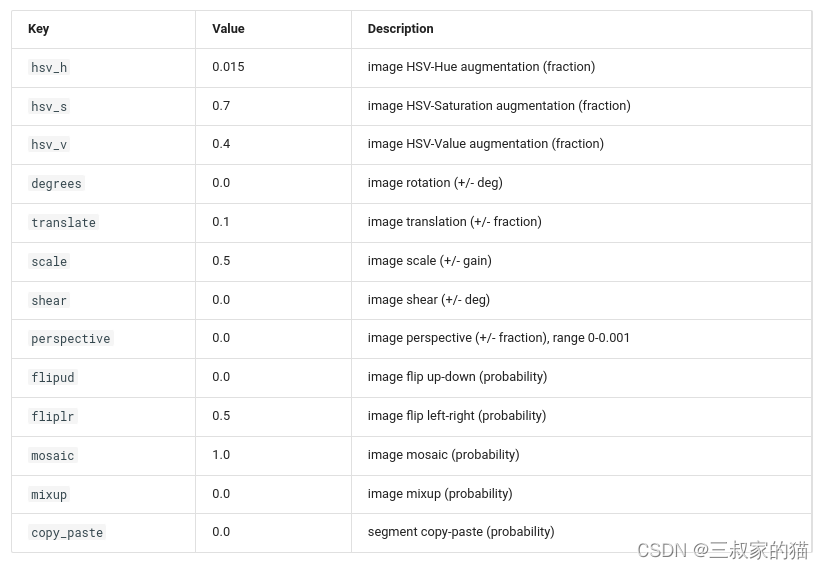
Para mais parâmetros, consulte: modos/trem
2. Parâmetros de Avaliação
Avalie o exemplo de código da linha de comando:
yolo detect val model=yolov8n.pt # val 官方模型
yolo detect val model=path/to/best.pt # val 自己训练的模型
Código python correspondente:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') #加载官方模型
model = YOLO('path/to/best.pt') # 加载自己训练的模型
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
Alguns dos parâmetros mais comumente usados:
| chave | explicar |
|---|---|
| modelo | O caminho para o arquivo do modelo pt que precisa ser avaliado |
| dados | Arquivo yaml do conjunto de dados que precisa ser avaliado |
| imagens | Avalie o tamanho da inferência da imagem, padrão 640 |
| lote | Avaliar lotes de inferência, padrão 16 |
| salvar_json | Se deseja salvar os resultados da avaliação como saída json, o padrão é False |
| salvar_híbrido | Se deseja salvar versões mistas de rótulos (rótulos + previsões extras) |
| conf | Limite de confiança de avaliação do modelo, padrão 0,001 |
| você | Limite de avaliação do modelo, padrão 0,6 |
| max_it | Número máximo de alvos detectados em uma única imagem, padrão 300 |
| metade | Se deve usar a inferência fp16, padrão True |
| dispositivo | O dispositivo para execução, ou seja, cuda device =0 ou Device =0,1,2,3 ou device=cpu |
| dnn | 是否使用use OpenCV DNN for ONNX inference,默认Flase |
| rect | 是否使用矩形推理,默认False |
| split | 数据集分割用于验证,即val、 test、train,默认val |
三、推理参数
推理命令行示例:
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
对应python代码示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model
# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
# 目标检测后处理
boxes = results[0].boxes
boxes.xyxy # box with xyxy format, (N, 4)
boxes.xywh # box with xywh format, (N, 4)
boxes.xyxyn # box with xyxy format but normalized, (N, 4)
boxes.xywhn # box with xywh format but normalized, (N, 4)
boxes.conf # confidence score, (N, 1)
boxes.cls # cls, (N, 1)
boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
# 实例分割后处理
masks = results[0].masks # Masks object
masks.segments # bounding coordinates of masks, List[segment] * N
masks.data # raw masks tensor, (N, H, W) or masks.masks
# 目标分类后处理
results = model(inputs)
results[0].probs # cls prob, (num_class, )
一些常用传参解释:
| key | 解释 |
|---|---|
| source | 跟之前的yolov5一致,可以输入图片路径,图片文件夹路径,视频路径 |
| save | 保存检测后输出的图像,默认False |
| conf | 用于检测的对象置信阈值,默认0.25 |
| iou | 用于nms的IOU阈值,默认0.7 |
| half | FP16推理,默认False |
| device | 要运行的设备,即cuda设备=0/1/2/3或设备=cpu |
| show | 用于推理视频过程中展示推理结果,默认False |
| save_txt | 是否把识别结果保存为txt,默认False |
| save_conf | 保存带有置信度分数的结果 ,默认False |
| save_crop | 保存带有结果的裁剪图像,默认False |
| hide_label | 保存识别的图像时候是否隐藏label ,默认False |
| hide_conf | 保存识别的图像时候是否隐藏置信度,默认False |
| vid_stride | 视频检测中的跳帧帧数,默认1 |
| classes | 展示特定类别的,根据类过滤结果,即class=0,或class=[0,2,3] |
| line_thickness | 目标框中的线条粗细大小 ,默认3 |
| visualize | 可视化模型特征 ,默认False |
| augment | 是否使用数据增强,默认False |
| agnostic_nms | 是否采用class-agnostic NMS,默认False |
| retina_masks | 使用高分辨率分割掩码,默认False |
| max_det | 单张图最大检测目标,默认300 |
| box | 在分割人物中展示box信息,默认True |
yolov8支持各种输入源推理:
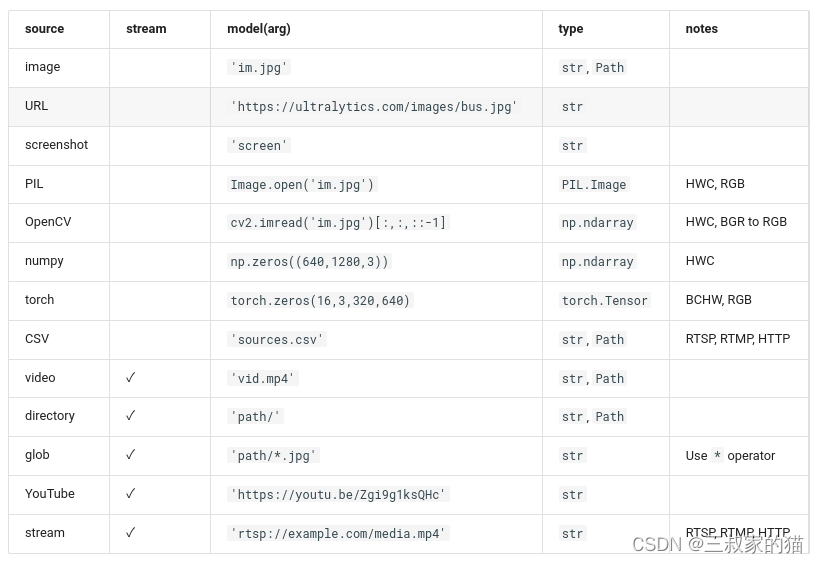
对于图片还支持以下保存格式的输入图片:
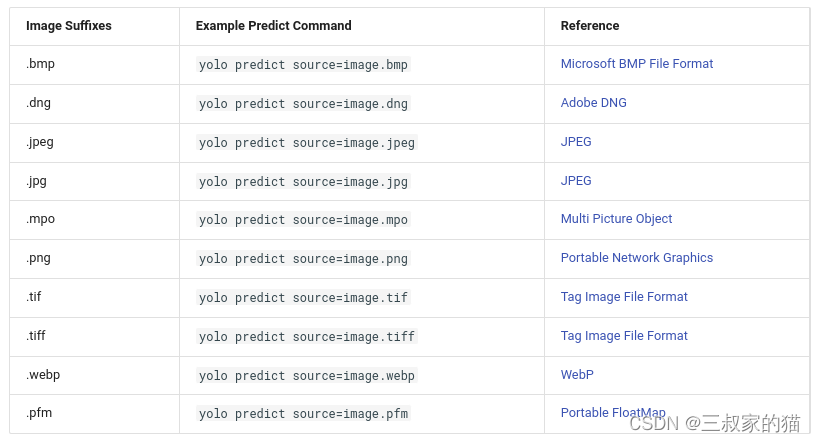
对于视频支持以下视频格式输入:
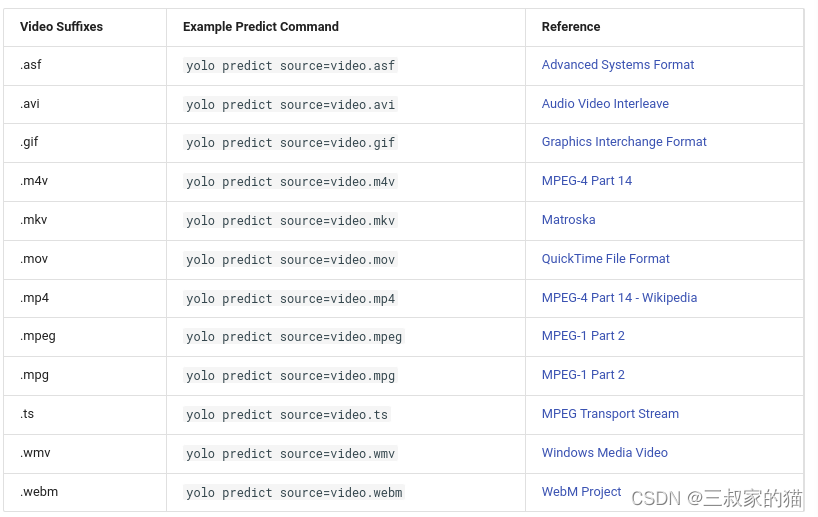
返回的result结果解析:
- Results.boxes: 目标检测返回的boxes信息
- Results.masks: 返回的分割mask坐标信息
- Results.probs: 分类输出的类概率
- Results.orig_img: 原始图像
- Results.path: 输入图像的路径
result可以使用如下方法在加载到cpu或者gpu设备中:
- results = results.cuda()
- results = results.cpu()
- results = results.to(“cpu”)
- results = results.numpy()
更多细节:modes/predict
四、模型导出
yolov8支持一键导出多种部署模型,支持如下格式的模型导出:
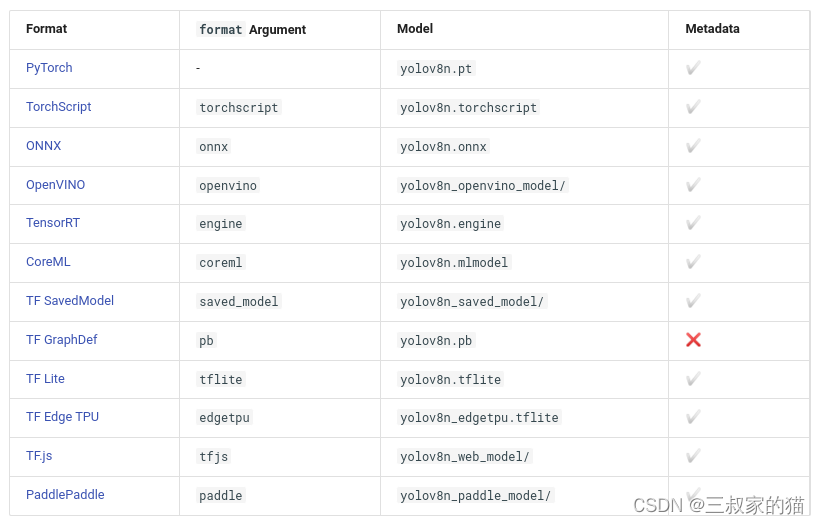
命令行运行示例:
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained model
python代码示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')
一些常用参数解释:
| key | 解释 |
|---|---|
| format | 导出的格式,默认’torchscript’,可选如上支持的格式 onnx、engine、openvino等 |
| imgsz | 导出时固定的图片推理大小,为标量或(h, w)列表,即(640,480) ,默认640 |
| keras | 使用Keras导出TF SavedModel ,用于部署tensorflow模型,默认False |
| optimize | 是否针对移动端对TorchScript进行优化 |
| half | fp16量化导出,默认False |
| int8 | int8量化导出,默认False |
| dynamic | 针对ONNX/TF/TensorRT:动态推理,默认False |
| simplify | onnx simplify简化,默认False |
| opset | onnx的Opset版本(可选,默认为最新) |
| workspace | TensorRT:工作空间大小(GB),默认4 |
| nms | 导出CoreML,添加NMS |
更多参考:modes/export
五、跟踪参数
yolov8目前支持:BoT-SORT、ByteTrack两种目标跟踪,默认使用BoT-SORT
命令行使用示例:
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
yolo track model=yolov8n-seg.pt source=... # official segmentation model
yolo track model=path/to/best.pt source=... # custom model
yolo track model=path/to/best.pt tracker="bytetrack.yaml" # bytetrack tracker
python代码使用示例:
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official detection model
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
model = YOLO('path/to/best.pt') # load a custom model
# Track with the model
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
Ele suporta modelos de detecção e segmentação, e você só precisa carregar os pesos correspondentes.
Os parâmetros passados para rastreamento são os mesmos usados para inferência. Existem três parâmetros principais: conf, iou e show.
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
# or
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
Você também pode personalizar e modificar o arquivo de configuração de rastreamento. Você precisa modificar o arquivo yaml em ultralytics/tracker/cfg e modificar a configuração necessária (exceto o tipo de rastreador). O mesmo método de operação:
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
# or
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
6. Parâmetros de teste de referência
O modo Benchmark é usado para analisar a velocidade e a precisão dos vários formatos de exportação do YOLOv8. Os benchmarks fornecem informações sobre o tamanho do formato de exportação, sua métrica mAP50-95 (para detecção e segmentação de objetos) ou métrica top5 de precisão (para classificação), bem como sobre o desempenho de vários formatos de exportação (como ONNX, OpenVINO, TensorRT , etc.), tempo de inferência por imagem em milissegundos. Essas informações ajudam os usuários a escolher o melhor formato de exportação para seus casos de uso específicos, com base nas necessidades de velocidade e precisão.
Exemplo de código de linha de comando:
yolo benchmark model=yolov8n.pt imgsz=640 half=False device=0
exemplo de código python:
from ultralytics.yolo.utils.benchmarks import benchmark
# Benchmark
benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
Alguns parâmetros comuns para testes de benchmark:
| chave | explicar |
|---|---|
| modelo | Caminho do arquivo do modelo, yoloV8v.pt, etc. |
| imagens | Tamanho da imagem de referência, padrão 640 |
| metade | Se deve ativar o fp16 para testes de benchmark, padrão False |
| dispositivo | Em quais dispositivos são testados em cuda device=0 ou device=0,1,2,3 ou device=cpu |
| falha_dura | Pare de continuar em caso de erro (bool) ou limite inferior do valor (float), padrão False |
Os benchmarks podem suportar a execução de testes nos seguintes formatos exportados:

Mais referências: modos/benchmark
7. Outras tarefas
Referência de segmentação: segmento
Referência de classificação: classificar