Desde a configuração do ambiente até a compreensão do conhecimento básico e o combate real ao rastreador, iremos guiá-lo passo a passo para começar a usar os rastreadores Python.
Este artigo é principalmente para começar. Se você deseja avançar ou ir mais longe no rastreamento, a ajuda fornecida por este artigo é mínima. O objetivo principal deste artigo é ajudar os alunos interessados em rastreamento da Web de uma maneira simples e linguagem simples.
Atualmente, existem muitas orientações sobre web crawlers na Internet, mas as rotinas são todas iguais e giram basicamente em torno do seguinte conteúdo:
Conhecimento de páginas da web como
solicitações CSS/html ou urllib
BeautifulSoup ou expressões regulares
Selenium ou Scrapy
Para mim, aprender o conhecimento do crawler é uma ferramenta de obtenção de dados, não o conteúdo principal do meu trabalho, portanto não tenho muito tempo para gastar no aprendizado sistemático do conhecimento acima. Cada peça mencionada acima envolve uma grande quantidade de conhecimento. Após um período de estudo, é fácil as pessoas caírem em "nuvens e neblina" e perderem o interesse em aprender. Não há visão geral nem foco, o que acaba fazendo com que a eficiência de aprendizagem é muito baixa.
Este artigo não explica em detalhes o que é CSS/html e como usar solicitações ou urllib. O objetivo principal deste artigo é apresentar como rastrear um site e rastrear os recursos necessários. O conhecimento em um ou vários dos itens acima módulos podem ser usados. Basta entender as funções que usamos. Não há necessidade de aprender do começo ao fim. Espero que este método possa dar aos alunos interessados em rastreadores uma compreensão geral desta tecnologia e possam atender às suas necessidades diárias de aquisição de dados.Se você deseja estudar esta tecnologia em profundidade, pode acompanhar outros cursos sistemáticos e estudar os módulos acima com atenção e detalhes.
Preparação
Muitas ferramentas são usadas ou mencionadas em muitos tutoriais de rastreadores da Web. Este artigo seleciona as seguintes ferramentas:
1 navegador da Web (Google Chrome)
2 BeautifulSoup4
3 solicitações
O navegador da Web é usado principalmente para visualizar o código-fonte HTML da página da Web e verificar o uso da unidade da página da Web, navegar Existem muitos navegadores, como Google, Firefox, IE, etc. Cada um tem preferências diferentes e pode escolher de acordo com seus hábitos diários. Este artigo usa o Google Chrome como exemplo para explicar.
BeautifulSoup4 é um analisador HTML e XML. Ele pode facilmente analisar páginas da web e obter as unidades e informações que desejamos. Ele pode evitar o problema de filtrar informações. Ele pode fornecer uso para iterar, pesquisar e modificar árvores de análise. No processo de correspondência de páginas da web, o BeautifulSoup não é mais rápido que as expressões regulares, nem mesmo mais lento, mas sua maior vantagem é a simplicidade e conveniência, por isso é uma das ferramentas obrigatórias em muitos projetos de rastreadores da web.
Instalar
$ pip install beautifulsoup4

Requests é a obra-prima do mestre Python Kenneth Reitz. É uma biblioteca de terceiros para solicitações de rede. Python incluiu o módulo urllib para acessar recursos de rede, mas é relativamente problemático de usar. Requests é muito mais conveniente e rápido em comparação, então Este artigo opta por usar solicitações para solicitações de rede.
Instalar
$ pip install requests
Mãos
Muitos tutoriais optam por rastrear a Enciclopédia de Histórias Embaraçosas e imagens de páginas da Web. Este artigo escolherá outra direção e rastreará a Enciclopédia Baidu comumente usada, que é mais intuitiva e fácil de entender.

Aqueles que navegam frequentemente na web, prestam atenção aos detalhes ou são bons em resumir, descobrirão que o endereço de um site consiste principalmente em duas partes, a parte básica e o sufixo da entrada correspondente. Por exemplo, a entrada da enciclopédia acima mencionada consiste da parte básica https://baike.baidu.com, o sufixo é item/Lin Chiling/172898?fr=aladdin, portanto, se quisermos rastrear um site, devemos primeiro obter um URL.
A primeira etapa é determinar uma meta: quais dados você deseja rastrear? Muitas pessoas vão pensar: isso não é um absurdo? Pessoalmente, acho que isso é muito importante. Somente com um propósito podemos ser mais eficientes. Sem algum tipo de situação orientada por objetivos, é difícil fazer algo com problemas e pressão. Isso se tornará sem objetivo e levará a A eficiência é muito baixa , então acho que o mais importante é primeiro saber quais dados você deseja rastrear?
Materiais de imagens musicais na web
...
Este artigo explicará o objetivo de rastrear os links internos das entradas da Enciclopédia Baidu e baixar imagens.
Na segunda etapa, precisamos obter um URL básico, o URL básico da Enciclopédia Baidu`
https://baike.baidu.com/`
A terceira etapa é abrir a página inicial e começar a rastrear com a entrada Baidu de Lin Chiling como página inicial.
A quarta etapa é visualizar o código-fonte. Muitas pessoas sabem que a tecla de atalho para visualizar o código-fonte é F12, seja o navegador Google Chrome ou IE, mas depois de pressionar F12, você não pode deixar de se perguntar: "O que é isso?", o que faz com que as pessoas não tenham ideia.
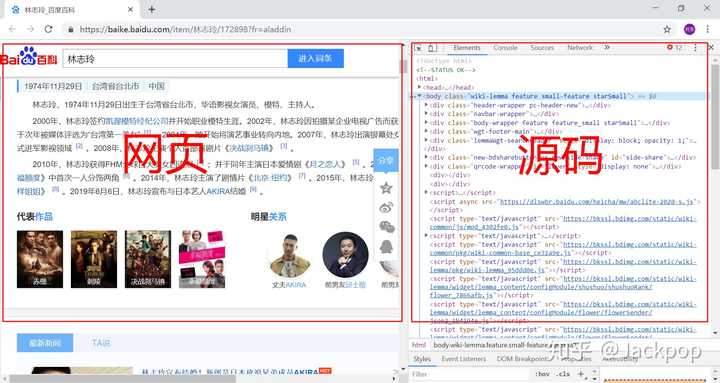
Claro, podemos entender o código-fonte passo a passo, aprender o conhecimento de html e, em seguida, usar expressões regulares para combinar as informações que queremos passo a passo, unidade por unidade, mas isso é muito complicado. Eu pessoalmente recomendo o uso de ferramentas de inspeção .
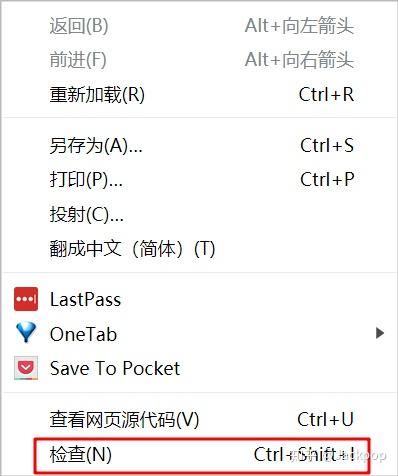
Rastreie links internos apontando para os elementos que queremos conhecer,
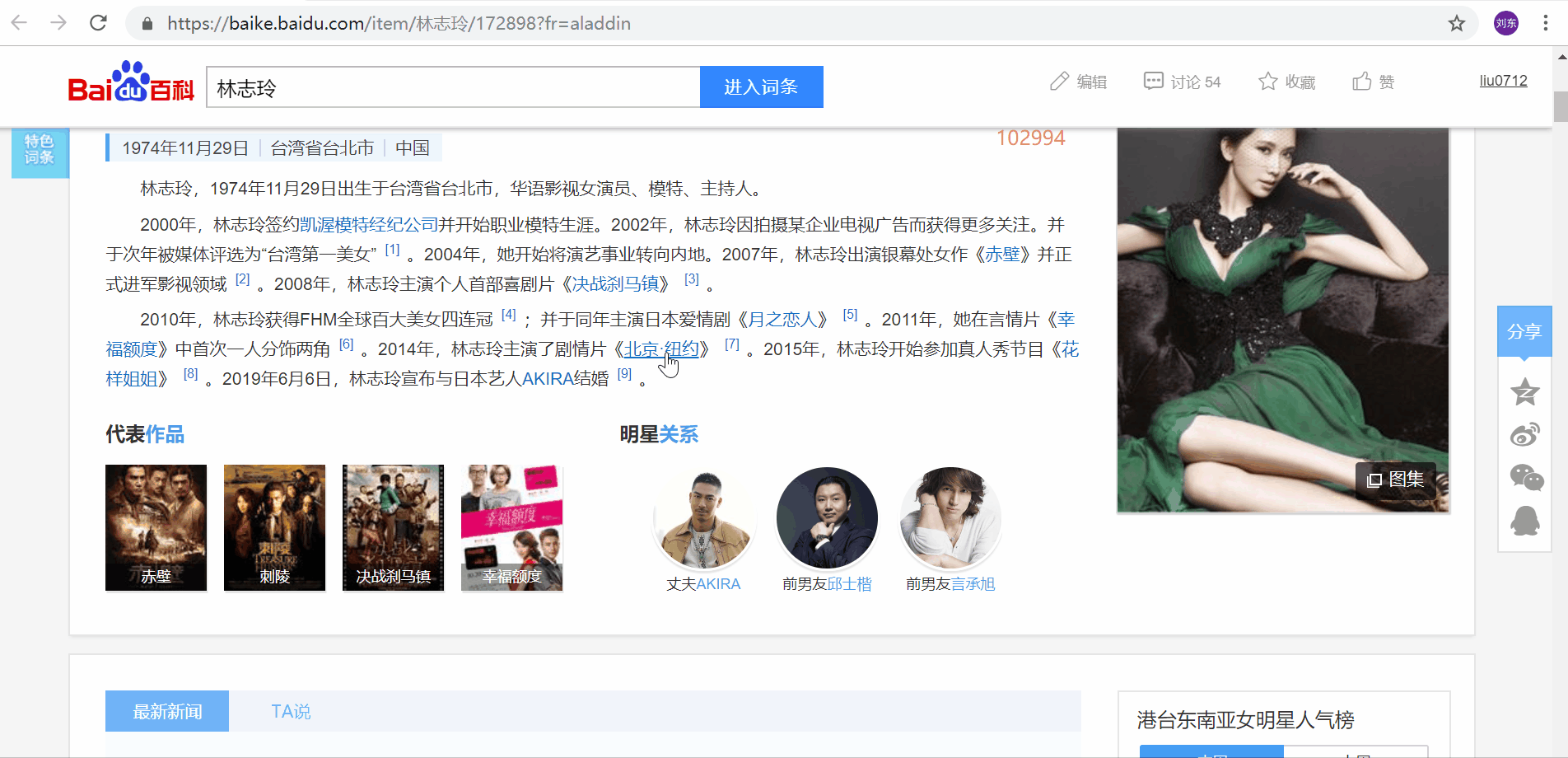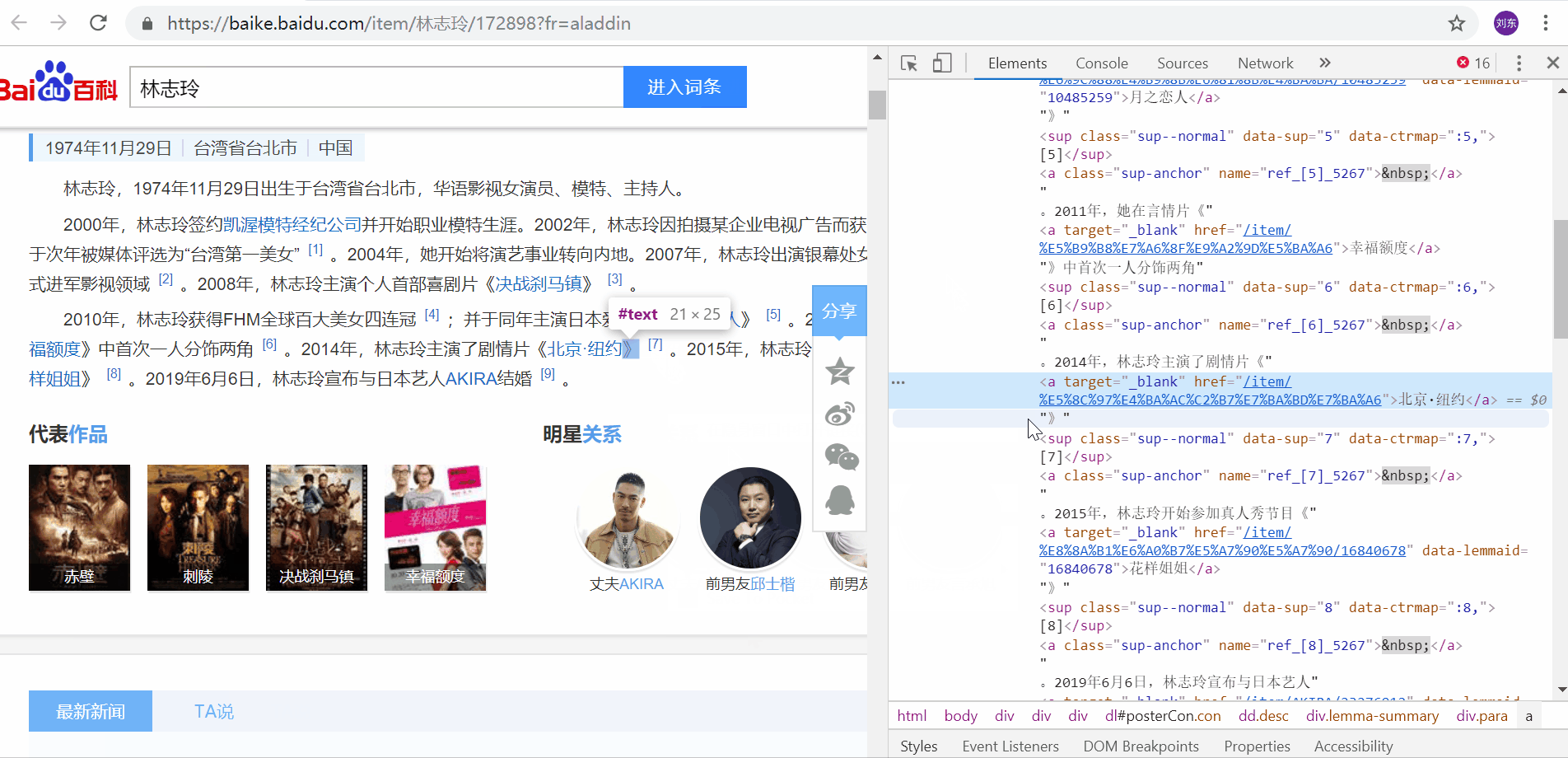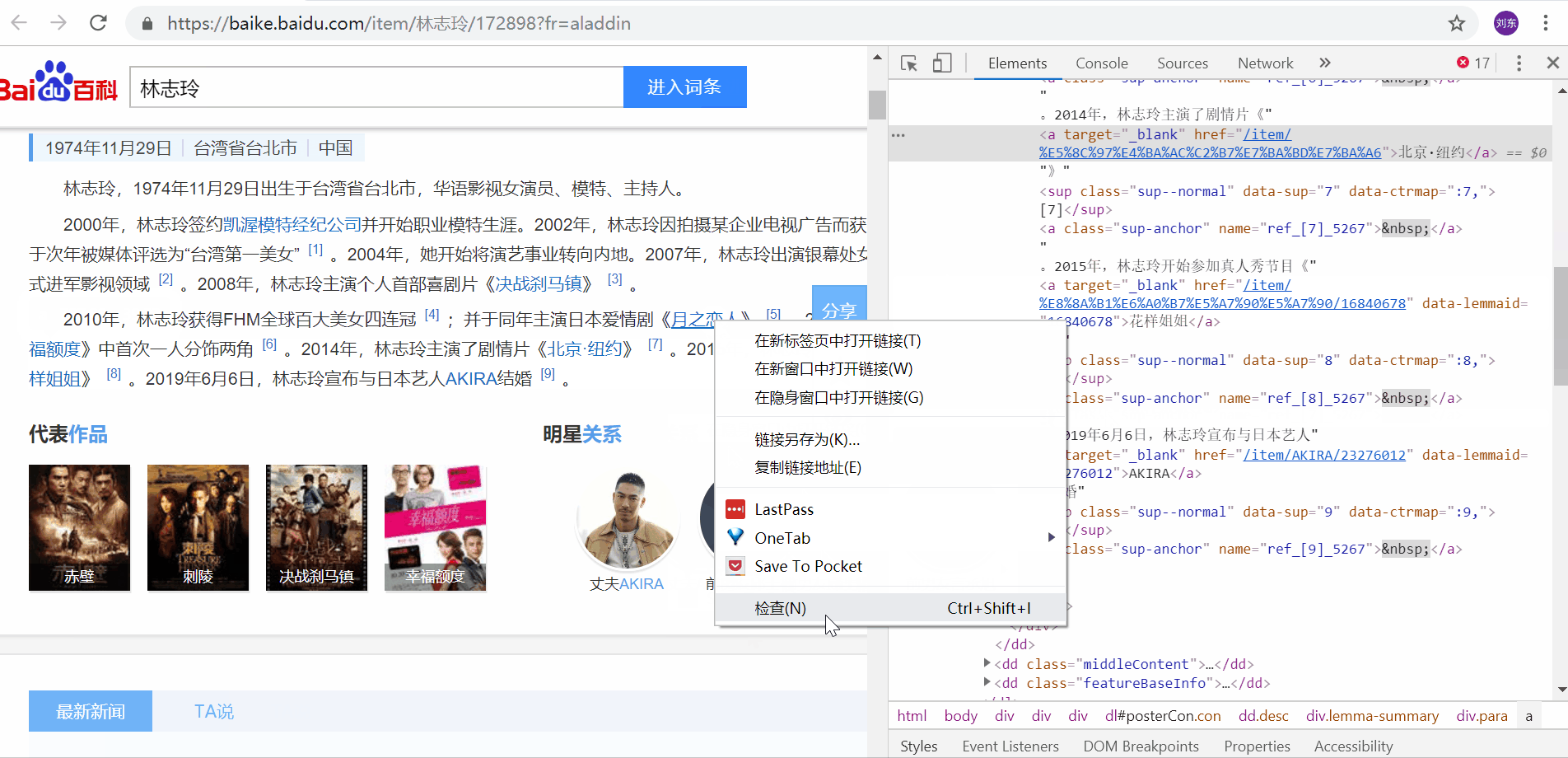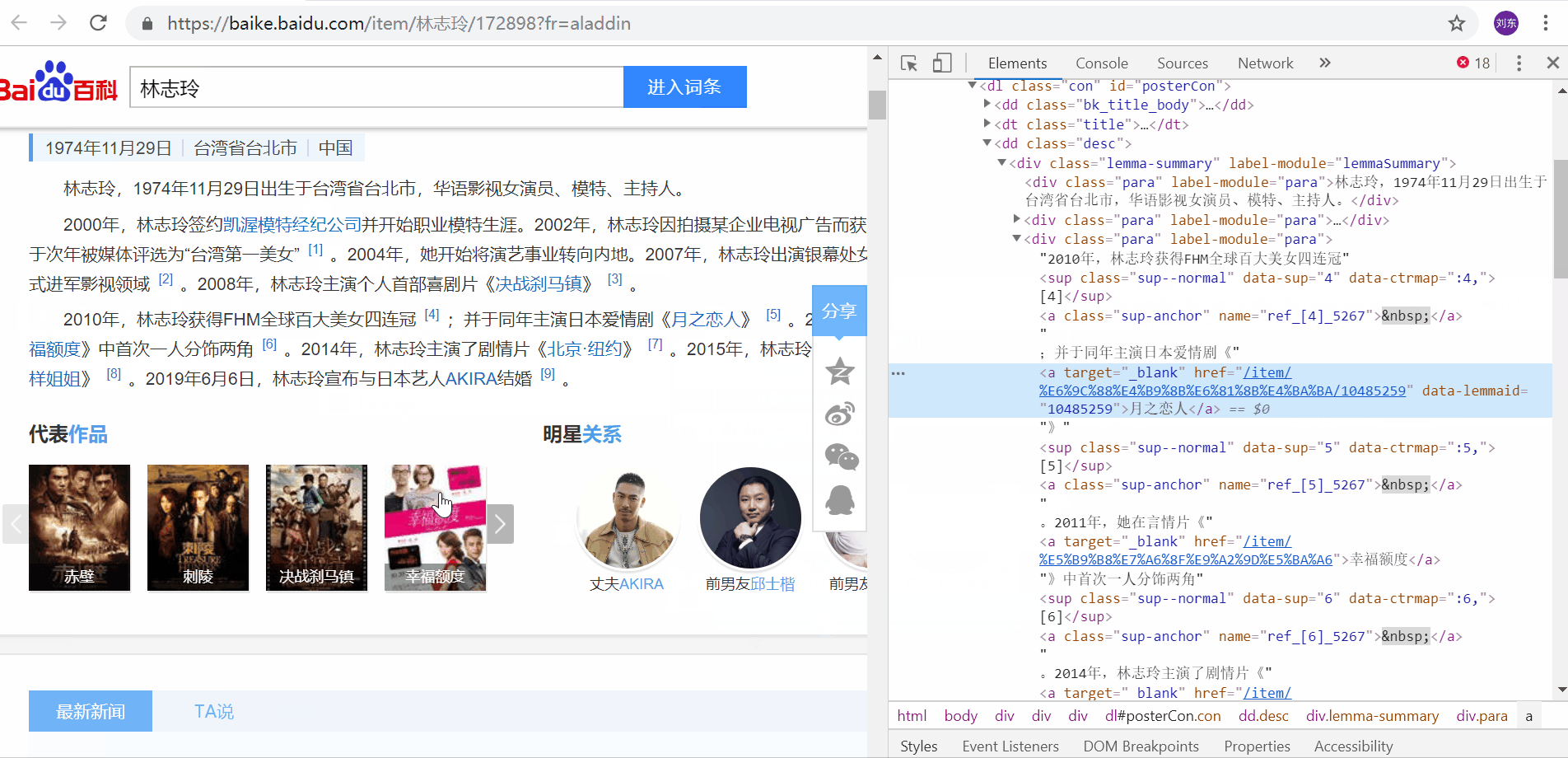
Botão direito do mouse->Inspecionar pode localizar rapidamente o elemento que nos preocupa.
Acho que esta etapa é suficiente. O rastreador da web mais simples é repetir as duas etapas a seguir continuamente: 1.
Verifique e localize os elementos e atributos que desejamos.
2. BeautifulSoup4 corresponde à informação que desejamos.
Através da função de inspeção, você pode ver que o código-fonte da parte do link interno da entrada da enciclopédia é assim,
elemento 1:
<a target="_blank" href="/item/%E5%87%AF%E6%B8%A5%E6%A8%A1%E7%89%B9%E7%BB%8F%E7%BA%AA%E5%85%AC%E5%8F%B8/5666862" data-lemmaid="5666862">凯渥模特经纪公司</a>
Elemento 2:
<a target="_blank" href="/item/%E5%86%B3%E6%88%98%E5%88%B9%E9%A9%AC%E9%95%87/1542991" data-lemmaid="1542991">决战刹马镇</a>
Elemento 3:
<a target="_blank" href="/item/%E6%9C%88%E4%B9%8B%E6%81%8B%E4%BA%BA/10485259" data-lemmaid="10485259">月之恋人</a>
元素4:
<a target="_blank" href="/item/AKIRA/23276012" data-lemmaid="23276012">AKIRA</a>
Como pode ser visto nos quatro elementos acima, o link interno da entrada de informação que desejamos está na tag, e a tag possui os seguintes atributos:
target: Este atributo indica onde o documento vinculado é aberto. _blank indica que o navegador sempre carrega o documento de destino em uma nova aba, que é o documento apontado pelo link href.
href: Como já mencionado várias vezes, o atributo href é usado para especificar o link do destino do hiperlink. Se o usuário selecionar o conteúdo da tag, ele tentará abrir e exibir o documento com o link especificado por href.
data-*: Este é um novo recurso do HTML que pode armazenar atributos definidos pelo usuário.
Percebe-se que a informação que desejamos está no href, que é o link interno da entrada. Portanto, o objetivo do nosso rastreador é muito claro, que é analisar o hiperlink href. Neste ponto, a função de inspeção do navegador desempenhou seu papel. A próxima questão é como analisamos o link href na tag? Neste momento, BeautifulSoup4 é útil. Use BeautifulSoup4 para analisar o html que pegamos da página da web,
soup = BeautifulSoup(response.text, 'html.parser')
Você pode estar se perguntando ao ver isso, o que é html.parser?
Este é um analisador de HTML. Vários analisadores de HTML são fornecidos em Python. Seus principais recursos são:

Resumindo, escolhemos o analisador html.parser. Após selecionar o analisador, começamos a combinar os elementos que desejamos. Porém, olhando para o HTML, descobrimos que existem muitas tags na página web. Qual tipo devemos combinar ?
<a target="_blank" href="/item/AKIRA/23276012" data-lemmaid="23276012">AKIRA</a>
Se você olhar com atenção, encontrará as características, target="_blank", o atributo href começa com /item, então temos nossas condições de correspondência,
{"target": "_blank", "href": re.compile("/item/(%.{2})+$")}
Use essas condições de correspondência para combinar tags que atendam aos requisitos de destino e href.
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
O código completo é,
def main():
url = BASE_URL + START_PAGE
response = sessions.post(url)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
for sub_url in sub_urls:
print(sub_url)
`
输出结果为,<a href="/item/%E5%B9%B8%E7%A6%8F%E9%A2%9D%E5%BA%A6" target="_blank">幸福额度</a>
<a href="/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6" target="_blank">北京·纽约</a>
<a href="/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6" target="_blank">多伦多大学</a>
<a href="/item/%E5%88%BA%E9%99%B5" target="_blank">刺陵</a>
<a href="/item/%E5%86%B3%E6%88%98%E5%88%B9%E9%A9%AC%E9%95%87" target="_blank">决战刹马镇</a>
<a href="/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6" target="_blank">北京·纽约</a>
<a href="/item/%E5%BC%A0%E5%9B%BD%E8%8D%A3" target="_blank">张国荣</a>
<a href="/item/%E5%A5%A5%E9%BB%9B%E4%B8%BD%C2%B7%E8%B5%AB%E6%9C%AC" target="_blank">奥黛丽·赫本</a>
<a href="/item/%E6%9E%97%E5%81%A5%E5%AF%B0" target="_blank">林健寰</a>
<a href="/item/%E6%96%AF%E7%89%B9%E7%BD%97%E6%81%A9%E4%B8%AD%E5%AD%A6" target="_blank">斯特罗恩中学</a>
<a href="/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6" target="_blank">多伦多大学</a>
<a href="/item/%E5%8D%8E%E5%86%88%E8%89%BA%E6%A0%A1" target="_blank">华冈艺校</a>
<a href="/item/%E5%94%90%E5%AE%89%E9%BA%92" target="_blank">唐安麒</a>
<a href="/item/%E6%97%A5%E6%9C%AC%E5%86%8D%E5%8F%91%E7%8E%B0" target="_blank">日本再发现</a>
<a href="/item/%E4%BA%9A%E5%A4%AA%E5%BD%B1%E5%B1%95" target="_blank">亚太影展</a>
<a href="/item/%E6%A2%81%E6%9C%9D%E4%BC%9F" target="_blank">梁朝伟</a>
<a href="/item/%E9%87%91%E5%9F%8E%E6%AD%A6" target="_blank">金城武</a>
......在用属性字段sub_url["href"]过滤一下即可,/item/%E5%B9%B8%E7%A6%8F%E9%A2%9D%E5%BA%A6
/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6
/item/%E5%A4%9A%E4%BC%A6%E5%A4%9A%E5%A4%A7%E5%AD%A6
/item/%E5%88%BA%E9%99%B5
/item/%E5%86%B3%E6%88%98%E5%88%B9%E9%A9%AC%E9%95%87
/item/%E5%8C%97%E4%BA%AC%C2%B7%E7%BA%BD%E7%BA%A6
/item/%E5%BC%A0%E5%9B%BD%E8%8D%A3
......
A parte do sufixo do link interno da entrada é obtida e, em seguida, unida ao URL básico para obter o endereço completo do link interno.
Da mesma forma, você pode usar o mesmo método para rastrear outros conteúdos, como piadas da Enciclopédia de Coisas Embaraçosas, materiais de sites profissionais e entradas da Enciclopédia Baidu.É claro que algumas informações de texto são relativamente confusas e esse processo requer algum processo de triagem de informações, como o uso de expressões regulares para combinar informações valiosas em um trecho de texto, o método é semelhante ao acima.
Baixar fotos
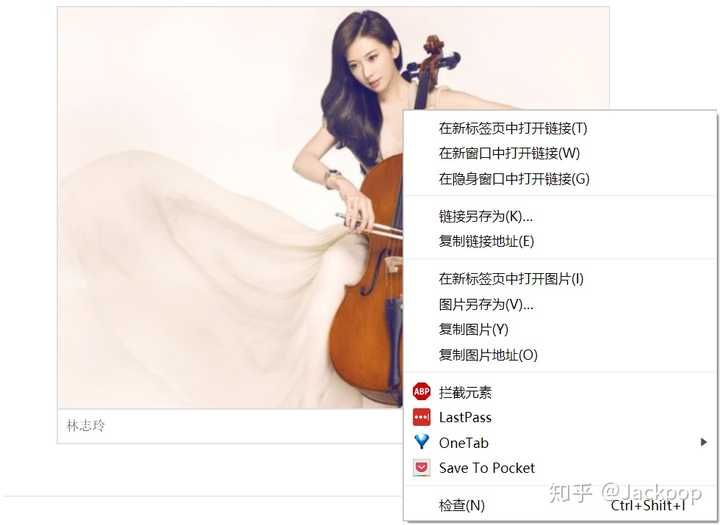
Assim como no rastreamento de links internos, você deve usar a função de verificação do navegador para verificar os links para as imagens dentro da entrada.
<img class="picture" alt="活动照" src="https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=85844ee8de0735fa95f049bbae500f9f/dbb44aed2e738bd49d805ec2ab8b87d6267ff9a4.jpg" style="width:198px;height:220px;">
Verificou-se que o link da imagem está armazenado dentro da tag, e o link completo para a imagem pode ser correspondido usando o método acima.
url = BASE_URL + START_PAGE
response = sessions.post(url)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, "html.parser")
image_urls = soup.find_all("img", {"class": "picture"})
for image_url in image_urls:
print(image_url["src"])
A saída é a seguinte,
https://gss2.bdstatic.com/9fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=36dbb0f7e1f81a4c2232ebcbe7286029/a2cc7cd98d1001e903e9168cb20e7bec55e7975f.jpg
https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=85844ee8de0735fa95f049bbae500f9f/dbb44aed2e738bd49d805ec2ab8b87d6267ff9a4.jpg
Em seguida, use solicitações para enviar uma solicitação para obter os dados da imagem e, em seguida, armazene-os localmente lendo e gravando arquivos.
for image_url in image_urls:
url = image_url["src"]
response = requests.get(url, headers=headers)
with open(url[-10:], 'wb') as f:
f.write(response.content)
Além das solicitações, você também pode usar urllib.request.urlretrieve para baixar imagens. urlretrieve é relativamente mais conveniente, mas para arquivos grandes, as solicitações podem ser lidas e escritas em segmentos, o que é mais vantajoso.
O método apresentado acima é relativamente simples. Se você tem energia limitada, também pode tentar Selenium ou Scrapy. Essas duas ferramentas são realmente muito poderosas, especialmente Selenium. É originalmente uma ferramenta de teste automatizada, mas mais tarde descobri que pode também pode ser usado. Como um rastreador da Web, é uma ferramenta que permite ao navegador ajudá-lo a rastrear dados automaticamente. Ele pode navegar em páginas da Web e capturar dados da mesma forma que os usuários visitam páginas da Web. É muito eficiente. Se você estiver interessado, você pode tentar.
Reservas técnicas sobre Python
Aqui eu gostaria de compartilhar com vocês alguns cursos gratuitos para que todos possam aprender. Abaixo estão as capturas de tela dos cursos. Digitalize o código QR na parte inferior para obter todos eles.
1. Rotas de aprendizagem Python em todas as direções
2. Software de aprendizagem
Se um trabalhador quiser fazer bem o seu trabalho, ele deve primeiro afiar as suas ferramentas. O software de desenvolvimento comumente usado para aprender Python está aqui, economizando muito tempo de todos.
3. Materiais de estudo

4. Informações práticas
A prática é o único critério para testar a verdade. Os pacotes compactados aqui podem ajudá-lo a melhorar suas habilidades pessoais em seu tempo livre.

5. Cursos em vídeo

Bem, o compartilhamento de hoje termina aqui. O tempo feliz é sempre curto. Amigos que querem aprender mais cursos, não se preocupem, há mais surpresas~