参考文章:Modelo de linha de base para "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020).[ papel ] [ conjunto de dados ] [ API ] [ doc ]
1. Baixe o Grapenet
1. Instalação
Obter código
git clone https://github.com/graspnet/graspnet-baseline.git
cd graspnet-baselineInstalar pacotes via Pip
pip install -r requirements.txtCompilar e instalar pointnet2
cd pointnet2
python setup.py installCompilar e instalar knn
cd knn
python setup.py installInstale o grabnetAPI
git clone https://github.com/graspnet/graspnetAPI.git
cd graspnetAPI
pip install .Construir documentação manualmente
cd docs
pip install -r requirements.txt
bash build_doc.sh2. Construção ambiental
Instale os pacotes necessários
- Pitão 3
- PyTorch 1.6
- Abrir3d >=0,8
- TensorBoard 2.3
- NumPy
- SciPy
- Travesseiro
- tqdm
3. Gere rótulos
Baixe do Google Drive / Baidu Pan
A execução do programa gera:
mv tolerance.tar dataset/
cd dataset
tar -xvf tolerance.tar4. Baixe pré-pesos
Pesos pré-treinados podem ser baixados em:
checkpoint-rs.tar[ Google Drive ] [ Disco Baidu ]checkpoint-kn.tar[ Google Drive ] [ Disco Baidu ]
checkpoint-rs.tare checkpoint-kn.tarsão treinados usando dados RealSense e dados Kinect, respectivamente.
2. Recorrência de demonstração
1. Editar configuração
Abra demo.py, expanda-o no canto superior direito do pycharm e selecione Editar configuração
Insira os pesos pré-treinamento nos parâmetros formais
Insira os parâmetros formais de acordo com o peso baixado. Observe que o caminho subsequente deve ser modificado para o local onde você armazena o arquivo.
--checkpoint_path logs/log_kn/checkpoint.tar
--dump_dir logs/dump_rs --checkpoint_path logs/log_rs/checkpoint.tar --camera realsense --dataset_root /data/Benchmark/graspnet
--log_dir logs/log_rs --batch_size 2 Formato formal de entrada de parâmetros
--Parâmetro formal 1 caminho 1 --Parâmetro formal 2 caminho 2
2. Repita a demonstração
Você pode visualizar a imagem de entrada em grspnet-baseline/doc/example_data

Execute demo.py para obter uma exibição 3D e gerar uma pose de agarramento 6D.
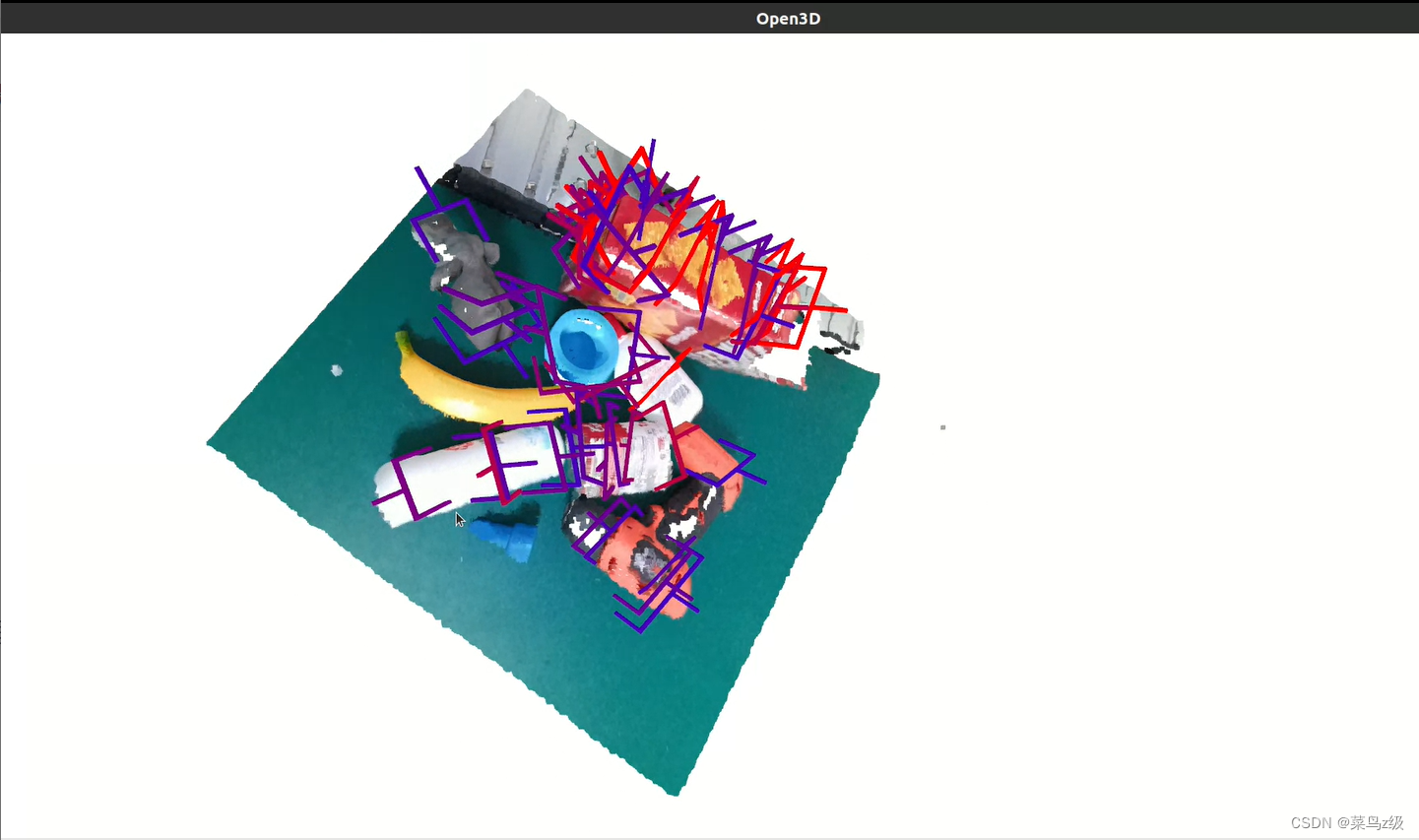
fim do show
3. Use seu próprio conjunto de dados para obter previsões de rastreamento
1. Introdução de dados
Use a câmera realsensel515 e conecte-a ao computador usando um cabo de dados
parâmetros da câmera realsense515
factor_profundidade valor de conversão de profundidade 4000
parâmetros internos da câmera internal_matrix
1351,72 0 979,26 0 1352,93 556.038 0 0 1
2. Entrada de dados
Configuração do pacote
pyrealsense2
cv2
Realize a entrada de cenas reais e converta-as com sucesso em formato de imagem para capturar a entrada
Alinhe profundidade_imagem com color_image
Modifique os parâmetros internos da câmera (distância focal, centro óptico) e valor de conversão de profundidade
Código completo
""" Demo to show prediction results.
Author: chenxi-wang
"""
import os
import sys
import numpy as np
import open3d as o3d
import argparse
import importlib
import scipy.io as scio
from PIL import Image
import torch
from graspnetAPI import GraspGroup
import pyrealsense2 as rs
import cv2
from matplotlib import pyplot as plt
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.join(ROOT_DIR, 'models'))
sys.path.append(os.path.join(ROOT_DIR, 'dataset'))
sys.path.append(os.path.join(ROOT_DIR, 'utils'))
from models.graspnet import GraspNet, pred_decode
from graspnet_dataset import GraspNetDataset
from collision_detector import ModelFreeCollisionDetector
from data_utils import CameraInfo, create_point_cloud_from_depth_image
parser = argparse.ArgumentParser()
parser.add_argument('--checkpoint_path', required=True, help='Model checkpoint path')
parser.add_argument('--num_point', type=int, default=20000, help='Point Number [default: 20000]')
parser.add_argument('--num_view', type=int, default=300, help='View Number [default: 300]')
parser.add_argument('--collision_thresh', type=float, default=0.01, help='Collision Threshold in collision detection [default: 0.01]')
parser.add_argument('--voxel_size', type=float, default=0.01, help='Voxel Size to process point clouds before collision detection [default: 0.01]')
cfgs = parser.parse_args()
def get_net():
# Init the model
net = GraspNet(input_feature_dim=0, num_view=cfgs.num_view, num_angle=12, num_depth=4,
cylinder_radius=0.05, hmin=-0.02, hmax_list=[0.01,0.02,0.03,0.04], is_training=False)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net.to(device)
# Load checkpoint
checkpoint = torch.load(cfgs.checkpoint_path)
net.load_state_dict(checkpoint['model_state_dict'])
start_epoch = checkpoint['epoch']
print("-> loaded checkpoint %s (epoch: %d)"%(cfgs.checkpoint_path, start_epoch))
# set model to eval mode
net.eval()
return net
def get_and_process_data(data_dir):
# load data
color = np.array(Image.open(os.path.join(data_dir, 'color.png')), dtype=np.float32) / 255.0
depth = np.array(Image.open(os.path.join(data_dir, 'depth.png')))
workspace_mask = np.array(Image.open(os.path.join(data_dir, 'workspace_mask.png')))
meta = scio.loadmat(os.path.join(data_dir, 'meta.mat'))# Resize depth to match color image resolution while preserving spatial alignment
color_height, color_width = color.shape[:2]
depth = cv2.resize(depth, (color_width, color_height), interpolation=cv2.INTER_NEAREST)
intrinsic = meta['intrinsic_matrix']
factor_depth =meta['factor_depth']
# generate cloud
camera = CameraInfo(1280.0, 720.0, intrinsic[0][0], intrinsic[1][1], intrinsic[0][2], intrinsic[1][2], factor_depth)
cloud = create_point_cloud_from_depth_image(depth, camera, organized=True)
# get valid points
mask = (workspace_mask & (depth > 0))
cloud_masked = cloud[mask]
color_masked = color[mask]
# sample points
if len(cloud_masked) >= cfgs.num_point:
idxs = np.random.choice(len(cloud_masked), cfgs.num_point, replace=False)
else:
idxs1 = np.arange(len(cloud_masked))
idxs2 = np.random.choice(len(cloud_masked), cfgs.num_point-len(cloud_masked), replace=True)
idxs = np.concatenate([idxs1, idxs2], axis=0)
cloud_sampled = cloud_masked[idxs]
color_sampled = color_masked[idxs]
# convert data
cloud = o3d.geometry.PointCloud()
cloud.points = o3d.utility.Vector3dVector(cloud_masked.astype(np.float32))
cloud.colors = o3d.utility.Vector3dVector(color_masked.astype(np.float32))
end_points = dict()
cloud_sampled = torch.from_numpy(cloud_sampled[np.newaxis].astype(np.float32))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cloud_sampled = cloud_sampled.to(device)
end_points['point_clouds'] = cloud_sampled
end_points['cloud_colors'] = color_sampled
return end_points, cloud
def get_grasps(net, end_points):
# Forward pass
with torch.no_grad():
end_points = net(end_points)
grasp_preds = pred_decode(end_points)
gg_array = grasp_preds[0].detach().cpu().numpy()
gg = GraspGroup(gg_array)
return gg
def collision_detection(gg, cloud):
mfcdetector = ModelFreeCollisionDetector(cloud, voxel_size=cfgs.voxel_size)
collision_mask = mfcdetector.detect(gg, approach_dist=0.05, collision_thresh=cfgs.collision_thresh)
gg = gg[~collision_mask]
return gg
def vis_grasps(gg, cloud):
gg.nms()
gg.sort_by_score()
gg = gg[:50]
grippers = gg.to_open3d_geometry_list()
o3d.visualization.draw_geometries([cloud, *grippers])
def demo(data_dir):
net = get_net()
end_points, cloud = get_and_process_data(data_dir)
gg = get_grasps(net, end_points)
if cfgs.collision_thresh > 0:
gg = collision_detection(gg, np.array(cloud.points))
vis_grasps(gg, cloud)
def input1():
# Create a pipeline
pipeline = rs.pipeline()
# Create a config object to configure the pipeline
config = rs.config()
config.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30)
# Start the pipeline
pipeline.start(config)
align = rs.align(rs.stream.color) # Create align object for depth-color alignment
try:
while True:
# Wait for a coherent pair of frames: color and depth
frames = pipeline.wait_for_frames()
aligned_frames = align.process(frames)
if not aligned_frames:
continue # If alignment fails, go back to the beginning of the loop
color_frame = aligned_frames.get_color_frame()
aligned_depth_frame = aligned_frames.get_depth_frame()
if not color_frame or not aligned_depth_frame:
continue
# Convert aligned_depth_frame and color_frame to numpy arrays
aligned_depth_image = np.asanyarray(aligned_depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
# Display the aligned depth image
aligned_depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(aligned_depth_image, alpha=0.03),
cv2.COLORMAP_JET)
cv2.imshow("Aligned Depth colormap", aligned_depth_colormap)
cv2.imshow("Aligned Depth Image", aligned_depth_image)
cv2.imwrite('./data1/depth.png', aligned_depth_image)
# Display the color image
cv2.imshow("Color Image", color_image)
cv2.imwrite('./data1/color.png', color_image)
# Press 'q' to quit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
# Stop the pipeline and close all windows
pipeline.stop()
cv2.destroyAllWindows()
if __name__=='__main__':
input1()
data_dir = 'data1'
demo(data_dir)Entre eles, dada1 é o seu próprio arquivo de dados, que contém
color.png Imagem colorida gerada por sua própria câmera
deep.png Mapa de profundidade alinhado com o mapa de cores
workspace.png é copiado diretamente do arquivo de dados de demonstração
meta.mat Copie o meta.mat do arquivo de dados de demonstração e modifique os parâmetros internos para os parâmetros de sua própria câmera
Lembre-se de que a atribuição de peso é consistente com demo.py
3. Exibição de resultados
Imagem coloridaRGB

Mapa de profundidade

Gere poses de captura 6D e imagens 3D

4. Mantenha apenas a postura ideal de agarrar
Modifique algum código
def vis_grasps(gg, cloud, num_top_grasps=10):
gg.nms()
gg.sort_by_score(reverse=True) # Sort the grasps in descending order of scores
gg = gg[:num_top_grasps] # Keep only the top num_top_grasps grasps
grippers = gg.to_open3d_geometry_list()
o3d.visualization.draw_geometries([cloud, *grippers])Rodar programa

A experiência termina