Parte 1 1. Conceitos básicos
A principal função dos microsserviços é dividi-los em subserviços, um por um, de acordo com o negócio, para alcançar o desacoplamento funcional. Cada microsserviço fornece o serviço de uma única função de negócios e executa suas próprias funções. Do ponto de vista técnico, é um serviço flexível. e unidades independentes podem ser iniciadas e desligadas de forma independente. Geralmente, cada serviço possui seu próprio módulo de banco de dados.
Na indústria tradicional de TI, a maior parte do software é uma coleção de vários sistemas independentes. Em resumo, os problemas desses sistemas são baixa escalabilidade, baixa confiabilidade e altos custos de manutenção. Mais tarde, o serviço SOA foi introduzido, mas como a SOA usava o modelo de barramento nos primeiros dias, esse modelo de barramento estava fortemente vinculado a uma determinada pilha de tecnologia, como J2EE. Isto torna difícil para muitas empresas se conectarem aos seus sistemas legados. O tempo de mudança é muito longo e o custo é muito alto. Também leva algum tempo para a estabilidade do novo sistema convergir. Eventualmente, a SOA tornou-se muito complicada e inadequada em alguns cenários de pequenas e médias empresas.
11.1 A diferença entre microsserviços e arquitetura monolítica
Todos os módulos de uma arquitetura monolítica são acoplados entre si, resultando em uma grande quantidade de código e dificuldade de manutenção. Cada módulo de um microsserviço equivale a um projeto separado. A quantidade de código é significativamente reduzida e os problemas encontrados são relativamente fáceis de resolver. . Todos os módulos da arquitetura monolítica compartilham um banco de dados, e o método de armazenamento é relativamente simples. Cada módulo do microsserviço pode usar diferentes métodos de armazenamento (por exemplo, alguns usam redis, alguns usam mysql, etc.), e o banco de dados também é um módulo único correspondente ao seu próprio banco de dados. Na arquitetura monolítica, todos os módulos utilizam a mesma tecnologia de desenvolvimento, cada módulo de microsserviços pode utilizar diferentes tecnologias de desenvolvimento, tornando o modelo de desenvolvimento mais flexível.
21.2 A diferença entre microsserviços e SOA
Os microsserviços, em essência, ainda são arquitetura SOA. Mas a conotação é diferente. Os microsserviços não estão vinculados a nenhuma tecnologia especial. Em um sistema de microsserviços, pode haver serviços escritos em Java ou serviços escritos em Python. Eles são unificados em um só pelo estilo arquitetônico Restful. Sistemático. Portanto, os microsserviços em si não têm nada a ver com implementações técnicas específicas e são altamente escaláveis.
Parte 2 2. Características dos microsserviços
A principal função dos microsserviços é implementar um conjunto de sistemas de infraestrutura para que vários serviços sejam fracamente acoplados e apareçam funcionalmente como um todo unificado. Este chamado "todo unificado" se manifesta em uma interface de estilo unificado, gerenciamento de permissões, política de segurança, processo on-line, métodos de registro e auditoria, métodos de agendamento, entradas de acesso, etc.
32.1 Princípios de design de microsserviços
De acordo com o princípio da responsabilidade única, cada microsserviço só precisa implementar sua própria lógica de negócio, como o módulo de ensino, que só precisa processar a lógica de negócio relacionada ao ensino, e os demais conteúdos são divididos;
O princípio da autonomia de serviço significa que cada microsserviço é independente entre si em termos de desenvolvimento, teste, lançamento, operação e manutenção, etc., e suas bases de dados de armazenamento também são separadas umas das outras, reduzindo suas respectivas dependências;
O princípio da comunicação leve é que as linguagens usadas para comunicação entre si são muito leves e o método de comunicação precisa ser multilíngue e multiplataforma. Isso permite que cada microsserviço tenha independência suficiente e não seja restrito. pela tecnologia. A forma comum é comunicar-se através da API REST ou RPC;
Princípio da interface clara Geralmente, haverá uma relação de chamada entre microsserviços. Para evitar alterações na interface de um determinado microsserviço que afetem outros microsserviços, situações comuns devem ser levadas em consideração no início do projeto, para que o A interface pode ser usada tanto quanto possível. Seja versátil e flexível e tente evitar mudanças em grande escala.
42.2 Serviço de acesso de cliente
Para se comunicar com cada serviço, o cliente precisa se lembrar desses serviços, incluindo o offline/atualização/atualização do serviço, e o cliente deve ser reimplantado. Ao mesmo tempo, o cliente também está mantendo e publicando, etc., que requer gerenciamento unificado. Além disso, chamar cada serviço também requer uma certa sobrecarga de rede. E, de modo geral, os microsserviços geralmente não têm estado no sistema. É melhor manter e gerenciar as informações e permissões de login do usuário em um local unificado.
Portanto, geralmente há um proxy ou API Gateway entre o serviço em segundo plano e a IU. Suas funções são as seguintes:
Forneça uma entrada de serviço unificada, permitindo que os microsserviços agreguem de forma transparente serviços de back-end ao front-end, economizem tráfego, melhorem o desempenho e forneçam funções de gerenciamento de API, como segurança, filtragem e limitação de corrente.
52.3 Gateway de API
O gateway de API conecta todas as chamadas de API à camada de gateway de API de maneira unificada, e a camada de gateway fornece acesso e saída unificados. As funções básicas de um gateway incluem: acesso unificado, proteção de segurança, adaptação de protocolo, controle de tráfego, suporte a links longos e curtos e tolerância a falhas. Com o gateway, cada equipe do provedor de serviços de API pode se concentrar em seu próprio processamento de lógica de negócios, enquanto o gateway de API se concentra mais em segurança, tráfego, roteamento e outros problemas.
Chris Richardson divide os gateways de API nos dois tipos a seguir em seu blog: gateways de API de nó único e back-ends para gateways de front-end.
比较热门的开源API网关组件: Tyk:Tyk是一个开放源码的API网关,基于golang语言开发。Tyk提供了一个API管理平台,其中包括API网关、API分析、开发人员门户和API管理面板。 Kong:Kong是一个可扩展的开放源码API Layer(也称为API网关或API中间件)。Kong 可以在任何RESTful API运行,通过插件扩展,它提供了超越核心平台的额外功能和服务。 zuul:提供动态路由、监视、弹性、安全性等功能的边缘服务。Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。
过滤器filter是整个Zuul的核心,分为前置过滤器(pre filter)、路由过滤器(routing filter)、后置过滤器(post filter)以及 错误过滤器(error filter)。当一个请求过来时,会先执行所有的 pre filter,然后通过 routing filter 将请求转发给后端服务。后端服务进行结果响应之后,再执行 post filter,最后把响应给客户端。在不同的filter里面可以执行不同的逻辑,比如安全检查、日志记录等。
Part3三、服务调用
微服务的多个服务之间的通信一般分为两种方式,同步调用和异步调用。
63.1 同步
远程过程调用(Remote Procedure Invocation)直接通过远程过程调用来访问别的service。示例 REST、gRPC、Apache、Thrift、RPCX等。
一般同步调用比较简单,可以满足强一致性,但是在调用层次多的时候性能容易出现问题,性能体验上比较差。常见的RESTful和RPC的各有所长。一般REST基于HTTP,可以跨客户端更容易实现,服务端实现的技术也更灵活,各个语言都能支持,只要封装HTTP的SDK就能调用,使用的范围较为普遍;RPC的优点在于传输协议更高效,安全可控,尤其是公司内部有统一的开发规范和服务框架,开发效率优势更明显。
73.2 异步
使用异步消息来通信,服务间通过消息管道来交换消息,从而完成通信。支持很多通信机制比如通知、请求/异步响应、发布/订阅、发布/异步响应。常见的有Kafka、RabbitMQ、RocketMQ等。
异步消息的调用在分布式系统中也发挥了重要作用,它既减少了服务之间的耦合,又可以缓冲消息,降低积压带来的影响,同时能保证调用方的服务异步的体验,专注于自己的任务不受打扰。不过带来的问题是数据的最终一致性;再一个就是后台服务一般要实现幂等性,考虑到消息发送的性能一般会有重复(通常只被接收一次),需要制定对应的推送和消费策略。
Part4四、服务发现
Zookeeper作为服务注册中心保证了CP,即高可用和实时更新。当向注册中心查询服务列表时,一般可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题是选举leader的时间长达30~120s,且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是难以容忍的。
通过ZK(zookeeper)技术做服务注册信息的分布式管理。当 服务上线时,服务提供者将自己的服务信息注册到ZK,并通过心跳维持长链接,实时更新链接信息。服务调用者通过ZK寻址,根据可定制算法,找到一个服务,还可以将服务信息缓存在本地以提高性能。当服务下线时,ZK会发通知给服务客户端。 其他能够作为服务注册中心的有: etcd:高可用,分布式,强一致性的,key-value,Kubernetes和Cloud Foundry都使用了etcd; consul:用于discovering和configuring的工具。它提供了允许客户端注册和发现服务的API。Consul可以进行服务健康检查,以确定服务的可用性。
Part5五、服务容错
分布式服务的特点就是网络是不可靠的。通过微服务拆分能降低这个风险,如果没有特别的保障,可能引起很严重的后果。当系统是由一系列的服务调用链组成的时候,必须确保任一环节出问题都不至于影响整体链路。处理服务挂掉的相应手段有很多:
隔离 超时重试 限流 熔断机制 降级(本地缓存)
85.1 容错机制
1 隔离
它是指将系统按照一定的规则划分为若干个服务模块,各个模块之间相对独立,无强依赖。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不涉及其他模块,不影响整体的系统服务。常见的隔离方式有:线程池隔离和信号量隔离。
2 超时重试
超时与重试机制也是容错的一种方法,凡是发生RPC调用的地方,比如读取redis,db,mq等,因为网络故障或者是所依赖的服务故障,长时间不能返回结果,就会导致线程增加,加大cpu负载,甚至导致雪崩。在上游服务调用下游服务时,设置一个最大响应时间,如果超过这个时间,下游未作出反应,就断开请求,释放掉线程。
3 限流
限流就是限制系统的输入和输出流量已达到保护系统的目的,为了保证系统的稳定运行,一旦达到需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。 限流方式有:计数器、令牌桶、信号量(漏桶)等
4 熔断
在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全全体的措施叫做熔断。熔断一般有三种状态: 熔断关闭状态:服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。 熔断开启状态:后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。 半熔断状态:尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率,如果成功率达到预期,则说明服务已经恢复,进入熔断关闭状态。如果成功率很低,则重新进入熔断关闭状态。
5 降级
降级其实就是为服务提供一个托底方案,一旦服务无法正常调用,就是用托底方案。
95.2 常见的容错组件
Hystrix是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者是第三方库,防止级联失败,从而提升系统的可用性和容错性。 Resilience4J是一款轻量级、简单、文档清晰、丰富的熔断工具,这也是Hystrix官方推荐的替代产品,不仅如此,Resilience4J还原生支持SpringBoot,而且监控也支持和promettheus等多款主流产品进行整合。 Sentinel是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定。
Part6六、负载均衡
负载均衡的常见策略
106.1 随机
来自网络的请求被随机地分配给内部的多个服务器处理,理想情况下每个机器获得请求的次数是基本相同的。
116.2 轮询
每一个来自网络中的请求,轮流分配给内部的服务器,从1到N然后重新开始。此种负载均衡算法适合服务器组内部的服务器都具有相同的配置并且平均服务请求相对均衡的情况。
126.3 加权轮询
根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。例如服务器A、B、C的权值分别被设计成1、3、6,则服务器A、B、C将分别接受到10%、30%、60%的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
136.4 IP Hash
通过生成请求源IP的哈希值,并通过哈希值来找到正确的真实服务器。这意味着对于同一主机来说对应的服务器总是相同。使用这种方式不需要保存任何源IP,但是注意,这种方式可能导致服务器负载不平衡。
146.5 最少连接数
客户端的每一次请求在服务器停留的时间可能会有较大的差异,随着工作时间加长,如果采用轮循或随机均衡的算法,每一台服务器上的连接进程可能会产生很大的不同,并没有达到真正的负载均衡。最少连接数均衡法对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量。当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使负载更加均衡。
Part7七、监控
微服务的监控一般的做法是,让各个组件提供报告自己当前状态的接口(metrics接口),这个接口输出的数据格式应该是一致的。 然后部署一个指标采集器组件,定时从这些接口获取并保持组件状态,同时提供查询服务。最后还需要一个UI,从指标采集器查询各项指标,绘制监控界面或者根据阈值发出告警。 网络上有很多开源组件。RedisExporter和MySQLExporter分别提供了Redis缓存和MySQL数据库的指标接口,微服务则根据各个服务的业务逻辑实现自定义的指标接口,然后采用Prometheus作为指标采集器,Grafana配置监控界面和邮件告警。这样一套微服务监控系统就搭建起来了。
157.1 常见的监控组件
Prometheus Promethes是一款2012年开源的监控框架,其本质是时间序列数据库,由Google前员工所开发。 它采用拉的模式(Pull)从应用中拉取数据,并还支持 Alert 模块可以实现监控预警。性能非常强劲,单机可以消费百万级时间序列。 对于一些定时任务模块是周期性运行的,采用拉的方式无法获取数据,Prometheus 也提供了一种推数据的方式,但是并不是推送到Prometheus Server中,而是中间搭建一个 Pushgateway,定时任务模块将metrics信息推送到这个Pushgateway中,然后Prometheus Server再依然采用拉的方式从Pushgateway中获取数据。 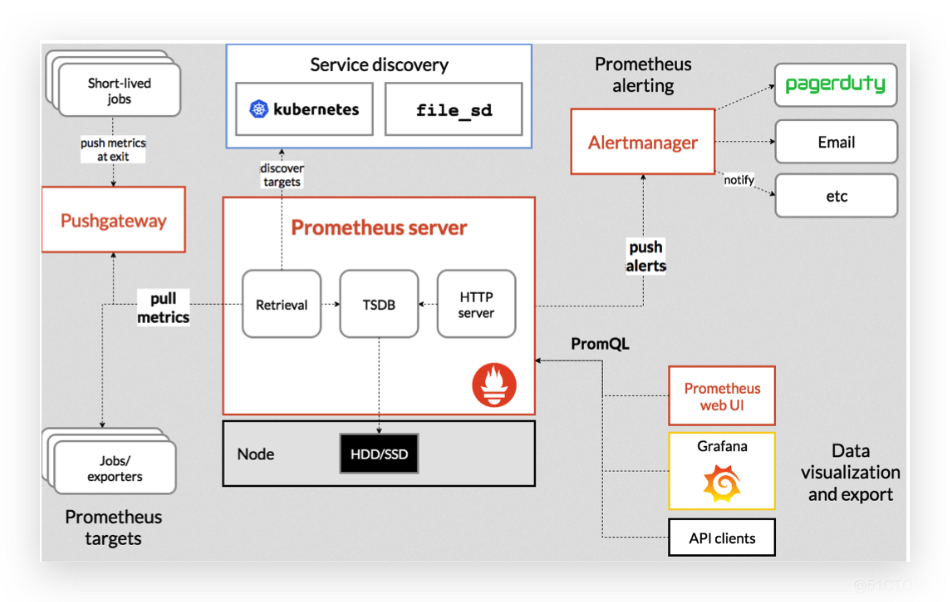
openTSDB OpenTSDB采用的是Hbase的分布式存储,它获取数据的模式与Prometheus不同,它采用的是推模式(Push)。 在展示层,OpenTSDB自带有WebUI视图,也可以与Grafana很好的集成,提供丰富的展示界面。 但OpenTSDB并没有自带预警模块,需要自己去开发或者与第三方组件结合使用。 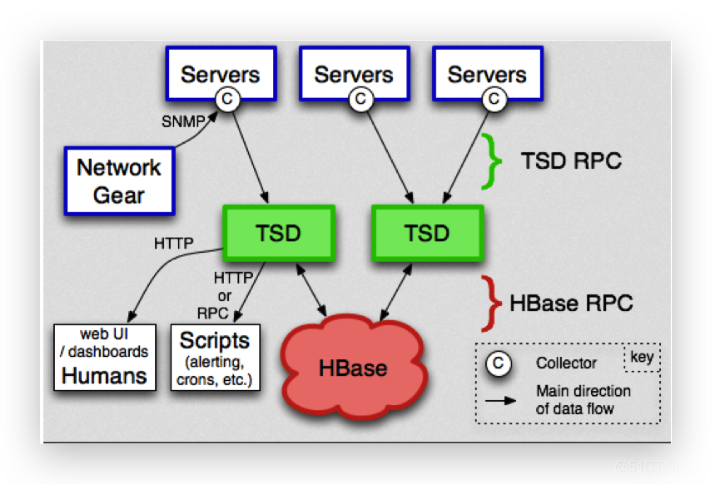
InfluxDB是在2013年开源的一款时序数据库,在这里我们主要还是用于做监控系统方案。它收集数据也是采用推模式(Push)。在展示层,InfluxDB也是自带WebUI,也可以与Grafana集成。 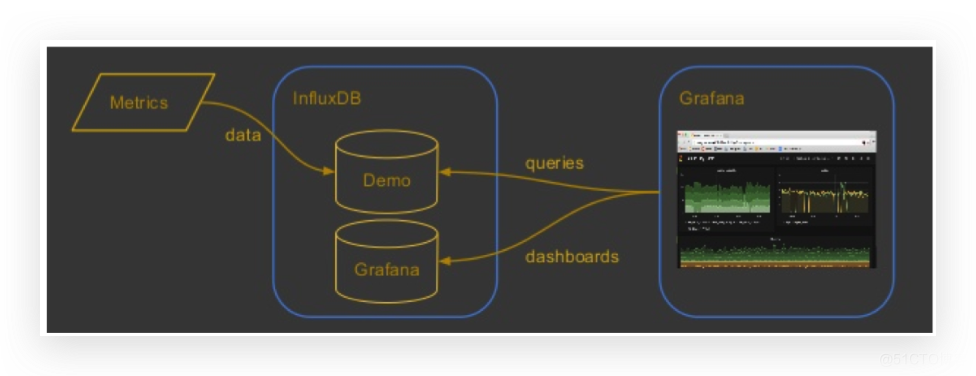
Part8八、链路追踪
微服务架构中,有很多的服务之间的调用关系,为了更好地定位问题,需要记录服务调用了哪些内部的接口,产生了多少调用,这也就是链路追踪。 链路追踪的记录就像一棵树,每次服务调用会在HTTP的HEADERS中记录至少记录四项数据:
traceId:traceId标识一个用户请求的调用链路,具有相同traceId的调用属于同一条链路; spanId:标识一次服务调用的ID,即链路跟踪的节点ID; parentId:父节点的spanId; requestTime 和 responseTime:请求时间和响应时间。 目前业界比较流行的链路追踪系统,例如Twitter的Zipkin,阿里的鹰眼,美团的Mtrace,大众点评的cat等,大部分都是基于google发表的Dapper。Dapper阐述了分布式系统,特别是微服务架构中链路追踪的概念、数据表示、埋点、传递、收集、存储与展示等技术细节。
本文由 mdnice 多平台发布