Recentemente descobri um projeto, seu antecessor é ChatGLM. Discuti o processo de implantação do ChatGLM em meu blog anterior. Este projeto foi otimizado com base no primeiro e pode implementar implementação local com base no atual modelo LLM convencional e grande conhecimento base. Implante seu próprio ChatGPT e ajuste o modelo com base em seu próprio conhecimento para que as perguntas e respostas incluam o conhecimento que você carregou. Contando com os modelos LLM e Embedding de código aberto suportados por este projeto, este projeto pode alcançar implantação privada offline usando todos os modelos de código aberto . Ao mesmo tempo, este projeto também apoia a chamada da API OpenAI GPT e continuará a expandir o acesso a vários modelos e APIs de modelo no futuro. A seguir é explicado em detalhes como implementar a implantação local. O processo é muito simples e muito conveniente de usar.
Índice
2.2 Incorporando suporte ao modelo
3. Desenvolvimento e implantação
3.2 Preparação do ambiente de desenvolvimento
3.4 Definir itens de configuração
3.5 Inicialização e migração da base de conhecimento
3.6 Inicie o serviço API ou UI da Web com um clique
4. Adicione base de conhecimento pessoal
4.1 Adicione base de conhecimento localmente
4.2 Adicionar base de conhecimento por meio da página da web
1. Download de código
Link do projeto GitHub - chatchat-space/Langchain-Chachat
Baixe o código localmente.
2. Suporte ao modelo
O modelo LLM padrão usado neste projeto é THUDM/chatglm2-6b , e o modelo de incorporação padrão usado é moka-ai/m3e-base como exemplo.
2.1 Suporte ao modelo LLM
Na versão mais recente deste projeto, o acesso ao modelo LLM local é baseado em FastChat . Os modelos suportados são os seguintes:
- metal-lhama/Llama-2-7b-chat-hf
- Vicuna, Alpaca, LLaMA, Coala
- BlinkDL/RWKV-4-Raven
- camel-ai/CAMEL-13B-Combined-Data
- blocos de dados/dolly-v2-12b
- FreedomIntelligence/phoenix-inst-chat-7b
- h2oai/h2ogpt-gm-oasst1-pt-2048-open-llama-7b
- lcw99/polyglot-ko-12.8b-chang-instruct-chat
- lmsys/fastchat-t5-3b-v1.0
- mosaicoml/mpt-7b-chat
- Neutrozz/BiLLa-7B-SFT
- nomic-ai/gpt4all-13b-snoozy
- NousResearch/Nous-Hermes-13b
- openaccess-ai-collective/manticore-13b-chat-pyg
- OpenAssistant/oast-sft-4-pythia-12b-epoch-3.5
- projeto-baize/baize-v2-7b
- Salesforce/codet5p-6b
- EstabilidadeAI/stablelm-tuned-alpha-7b
- THUDM/chatglm-6b
- THUDM/chatglm2-6b
- tiiuae/falcon-40b
- timdettmers/guanaco-33b mesclado
- juntoscomputador/RedPajama-INCITE-7B-Chat
- WizardLM/WizardLM-13B-V1.0
- WizardLM/WizardCoder-15B-V1.0
- baichuan-inc/baichuan-7B
- internlm/internlm-chat-7b
- Qwen/Qwen-7B-Chat
- AbraçandoFaceH4/starchat-beta
- Qualquer modelo python EleutherAI , como python-6.9b
- Qualquer adaptador Peft treinado no modelo acima . Para ativar, ele deve estar presente no caminho do modelo
peft.PEFT_SHARE_BASE_WEIGHTS=trueNOTA: Se vários modelos PEFT forem carregados, você poderá fazer com que eles compartilhem os pesos do modelo base definindo variáveis de ambiente em qualquer modelo de trabalho .
A lista de modelos suportados acima pode ser atualizada continuamente à medida que o FastChat é atualizado. Consulte a lista de modelos suportados pelo FastChat .
Além dos modelos locais, este projeto também suporta acesso direto à API OpenAI. Para configurações específicas, consulte as informações de configuração configs/model_configs.py.example em .llm_model_dictopenai-chatgpt-3.5
2.2 Incorporando suporte ao modelo
Este projeto oferece suporte à chamada do modelo de incorporação em HuggingFace . Os modelos de incorporação suportados são os seguintes:
- moka-ai/m3e-pequeno
- moka-ai/m3e-base
- moka-ai/m3e-grande
- BAAI/bge-small-zh
- BAAI/bge-base-zh
- BAAI/bge-grande-zh
- BAAI/bge-large-zh-noinstruct
- sensenova/base pequena-zh
- sensenova/pequeno-grande-zh
- shibing624/text2vec-base-chinese-sentence
- shibing624/text2vec-base-chinese-paráfrase
- shibing624/text2vec-base-multilíngue
- shibing624/text2vec-base-chinês
- shibing624/text2vec-bge-grande-chinês
- GanimedesNil/text2vec-large-chinese
- nghuyong/ernie-3.0-nano-zh
- Ernie-3.0-base-zh/ernie-3.0-base-zh
- OpenAI/text-embedding-ada-002
3. Desenvolvimento e implantação
3.1 Requisitos de software
Este projeto foi testado no ambiente Python 3.8.1 - 3.10, CUDA 11.7. Os testes foram concluídos em sistemas Windows, macOS baseados em ARM e Linux.
3.2 Preparação do ambiente de desenvolvimento
Consulte Preparação do Ambiente de Desenvolvimento .
Observação: 0.2.3 e versões mais recentes de pacotes de dependência 0.1.x podem entrar em conflito com pacotes de dependência de versão. É altamente recomendável reinstalar os pacotes de dependência após criar um novo ambiente.
Primeiro crie um ambiente virtual e depois mude para o diretório do arquivo de código no ambiente virtual:
cd /d E:\Demo\Langchain-Chatchat-master # 切换到代码所在位置Crie um ambiente virtual:
conda create -n Chat_GLM python=3.9 # 虚拟环境名称为ChatGLMHabilite o ambiente virtual:
conda activate ChatGLMDependências do ambiente de instalação:
pip install requirements.txtInstale o pacote de idiomas zh_core_web_sm:
spacy/zh_core_web_sm em principal (huggingface.co)
Basta baixar o arquivo whl no diretório de imagem abaixo, mudar para o diretório zh_core_web_sm-any-none-any.whl e instalá-lo usando pip
pip install zh_core_web_sm-any-none-any.whl
3.3 Baixe o modelo para local
Se você deseja executar este projeto em um ambiente local ou offline, primeiro você precisa baixar os modelos necessários para o projeto em seu computador local.Normalmente, os modelos LLM e Embedding de código aberto podem ser baixados do HuggingFace .
Pegue o modelo LLM THUDM/chatglm2-6b e o modelo de incorporação moka-ai/m3e-base usados por padrão neste projeto como exemplos. Clique diretamente para baixar.
Download do disco de rede:
Link: https://pan.baidu.com/s/14vm-yc8EDQ3DqrRAliFWXw?pwd=eaxqCódigo
de extração: eaxqLink: https://pan.baidu.com/s/1OAqm5sQOUHYyg-YzZu7eCw?pwd=0arh
Código de extração: 0arh
3.4 Definir itens de configuração
Copie o arquivo de modelo de configuração de parâmetros relacionados ao modelo configs/model_config.py.example, armazene-o no caminho do projeto ./configs e renomeie-o model_config.py.
Copie o arquivo de modelo de configuração de parâmetros relacionados ao serviço configs/server_config.py.example, armazene-o no caminho do projeto ./configs e renomeie-o server_config.py.
Antes de iniciar a interface da Web ou a interação da linha de comando, primeiro verifique se o parâmetro do modelo está projetado e atende aos requisitos configs/model_config.py : configs/server_config.py
- Por favor, confirme se o caminho de armazenamento local do modelo LLM que foi baixado para o local está escrito nas propriedades
llm_model_dictdo modelo correspondentelocal_model_path, como:
llm_model_dict={
"chatglm2-6b": {
"local_model_path": "E:\Demo\chatglm2-6b", # 只需该这里
"api_base_url": "http://localhost:8888/v1", # "name"修改为 FastChat 服务中的"api_base_url"
"api_key": "EMPTY"
},
}- Confirme se o caminho de armazenamento local do modelo de incorporação que foi baixado para o local está escrito no
embedding_model_dictlocal do modelo correspondente, como:
embedding_model_dict = {
"m3e-base": "E:\Demo\m3e-base", # 只需改这里
}Se você optar por usar o modelo de incorporação da OpenAI, keyescreva o modelo embedding_model_dict. Para usar este modelo, você precisa acessar a API oficial da OpenAI ou configurar um proxy.
3.5 Inicialização e migração da base de conhecimento
As informações da base de conhecimento do projeto atual são armazenadas no banco de dados. Inicialize o banco de dados antes de executar oficialmente o projeto (recomendamos fortemente que você faça backup de seus arquivos de conhecimento antes de executar a operação).
-
Se você for
0.1.xum usuário que atualizou da versão anterior, para a base de conhecimento estabelecida, confirme se o tipo de base vetorial e o modelo de incorporação da base de conhecimento sãoconfigs/model_config.pyconsistentes com as configurações padrão em . Se não houver alterações, basta adicionar o informações existentes da base de conhecimento para o banco de dados com o seguinte comando É isso: -
python init_database.py -
Se você estiver executando este projeto pela primeira vez e a base de conhecimento não tiver sido estabelecida, ou o tipo de base de conhecimento e o modelo incorporado no arquivo de configuração tiverem sido alterados, ou a biblioteca de vetores anterior não tiver sido aberta, será necessário inicializar ou reconstruir a base de conhecimento com o seguinte comando
normalize_L2: -
python init_database.py --recreate-vs
3.6 Inicie o serviço API ou UI da Web com um clique
1. Habilite o modelo padrão com um clique
Script de inicialização com um clique startup.py, um clique para iniciar todos os serviços Fastchat, serviços API e serviços WebUI, código de exemplo:
python startup.py -aIr automaticamente para a página da Web. Se não conseguir pular, lembre-se de pressionar a tecla Enter no final do código para iniciar a página da Web com um clique.

E você pode usá-lo para Ctrl + C desligar diretamente todos os serviços em execução. Se não conseguir terminar uma vez, você pode pressioná-lo várias vezes.
Os parâmetros opcionais incluem -a (或--all-webui), --all-api, --llm-api, -c (或--controller), --openai-api, -m (或--model-worker), --api, --webui, onde:
--all-webui 为一键启动 WebUI 所有依赖服务;
--all-api 为一键启动 API 所有依赖服务;
--llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
--openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务;
其他为单独服务启动选项。2. Habilite modelos não padrão
Se quiser especificar um modelo não padrão, você precisará usar --model-name opções, por exemplo:
python startup.py --all-webui --model-name Qwen-7B-ChatMais informações podem ser python startup.py -hencontradas em .
4. Adicione base de conhecimento pessoal
Se os resultados da resposta atual não forem ideais, conforme mostrado na figura abaixo, você poderá adicionar uma base de conhecimento para otimizar o conhecimento.

4.1 Adicione base de conhecimento localmente
Adicione o documento ao diretório Knowledge_base——samples——content:
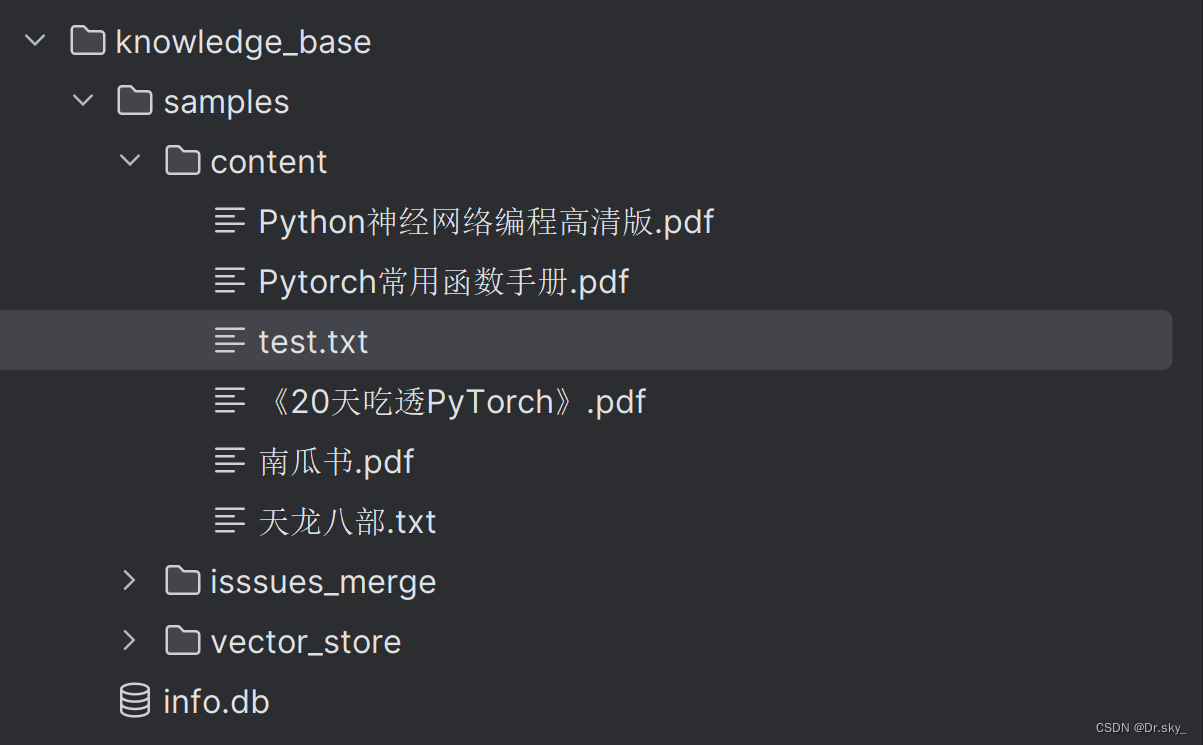
4.2 Adicionar base de conhecimento por meio da página da web
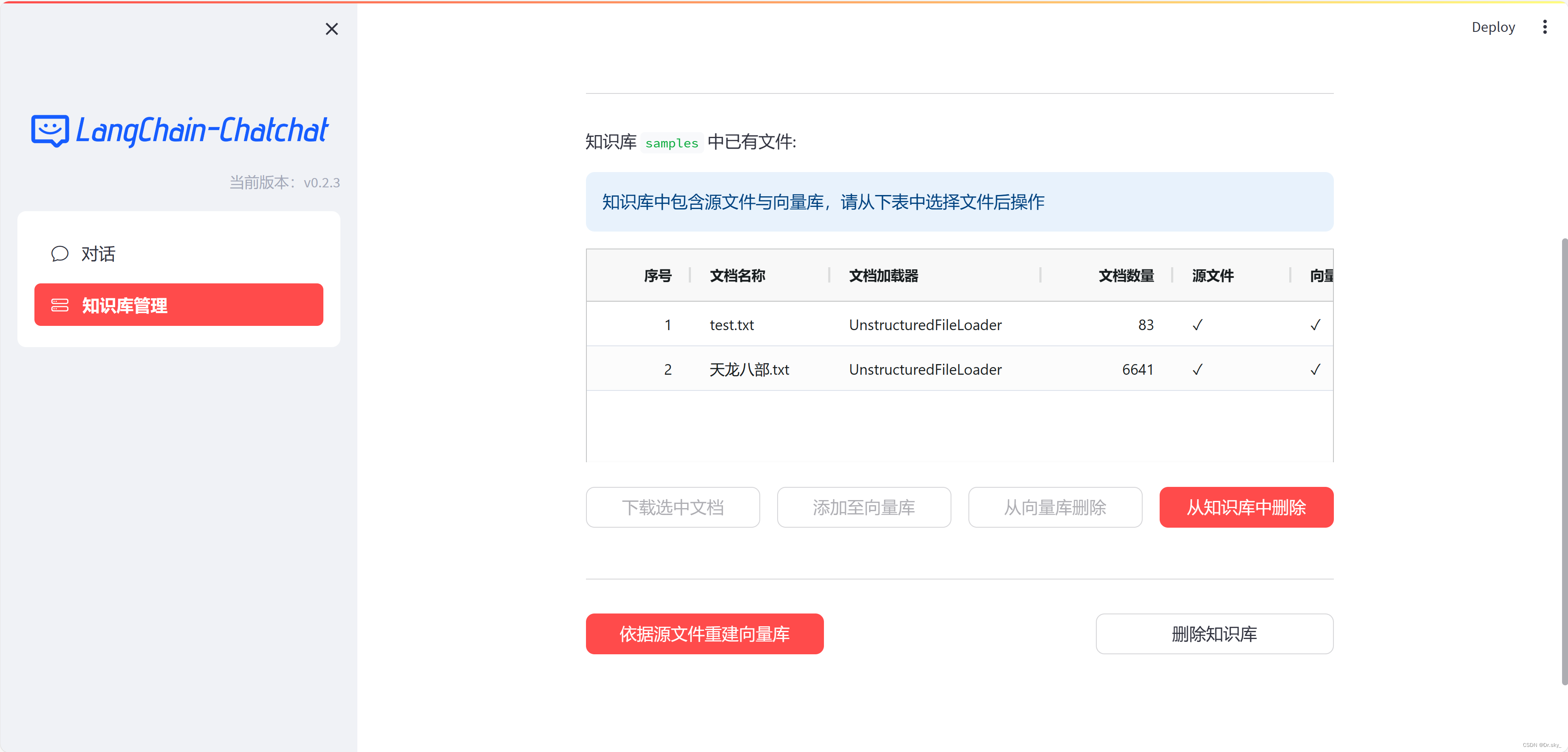
4.3 Reajustando o modelo
Após a adição da base de conhecimento, execute novamente o programa de acordo com 3.5-3.6 para atualizar a base de conhecimento local. Conforme mostrado na figura abaixo, após adicionar o e-book “Dragão e as Oito Partes”, os resultados das respostas tornam-se mais precisos.

Para melhorar a velocidade de resposta, mude a CPU para GPU:
No arquivo model_config.py, modifique
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "auto"para:
# Embedding 模型运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
EMBEDDING_DEVICE = "cuda"Rever
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "auto"para:
# LLM 运行设备。设为"auto"会自动检测,也可手动设定为"cuda","mps","cpu"其中之一。
LLM_DEVICE = "cuda"dica:
Se você encontrar problemas durante a implantação acima, siga-me: dyga9uraeovh