Artikelverzeichnis
-
- 一、Vision Transformer
- 二、Swin Transformer
- 三、Erkennungstransformator
- 四、Dateneffizienter Bildtransformator
- 五、Selbstdestillation ohne Etiketten
- 六、Verformbares DETR
- 七, Kompakte Faltungstransformatoren
- 8. Nest
- 九、Pyramid Vision Transformer
- 十、Dense Prediction Transformer
- 十一、Convolutional Vision Transformer
- 十二、Tokens-To-Token Vision Transformer
- 十三、Multiscale Vision Transformer
- 14. MoCo v3
- 15. LV-ViT
Vision Transformers sind Transformer-ähnliche Modelle, die auf Vision-Aufgaben angewendet werden. Sie stammen aus der Arbeit von ViT, die die Transformer-Architektur direkt auf nicht überlappende mittelgroße Bildfelder zur Bildklassifizierung anwendet. Nachfolgend finden Sie eine ständig aktualisierte Liste visueller Konverter.
Modelle vom Typ ViT können weiter unterteilt werden in ViT mit einheitlichem Maßstab, ViT mit mehreren Maßstäben, Hybrid-ViT mit Faltung und selbstüberwachtes ViT. Die unten aufgeführten Methoden bieten einen umfassenden Überblick über ViT-Modelle, die auf eine Reihe von Sehaufgaben angewendet werden.
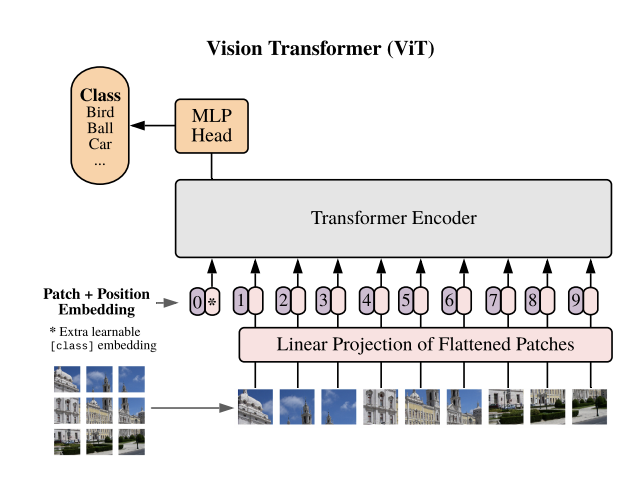
一、Vision Transformer
Vision Transformer (ViT) ist ein Bildklassifizierungsmodell, das eine Transformer-ähnliche Architektur auf Bildfelder anwendet. Teilen Sie das Bild in Blöcke fester Größe auf, betten Sie dann jeden Block linear ein, fügen Sie Positionseinbettungen hinzu und geben Sie die resultierende Vektorsequenz an einen Standard-Transformer-Encoder weiter. Um eine Klassifizierung durchzuführen, wird die Standardmethode des Hinzufügens zusätzlicher lernbarer „Klassifizierungsmarker“ zur Sequenz verwendet.
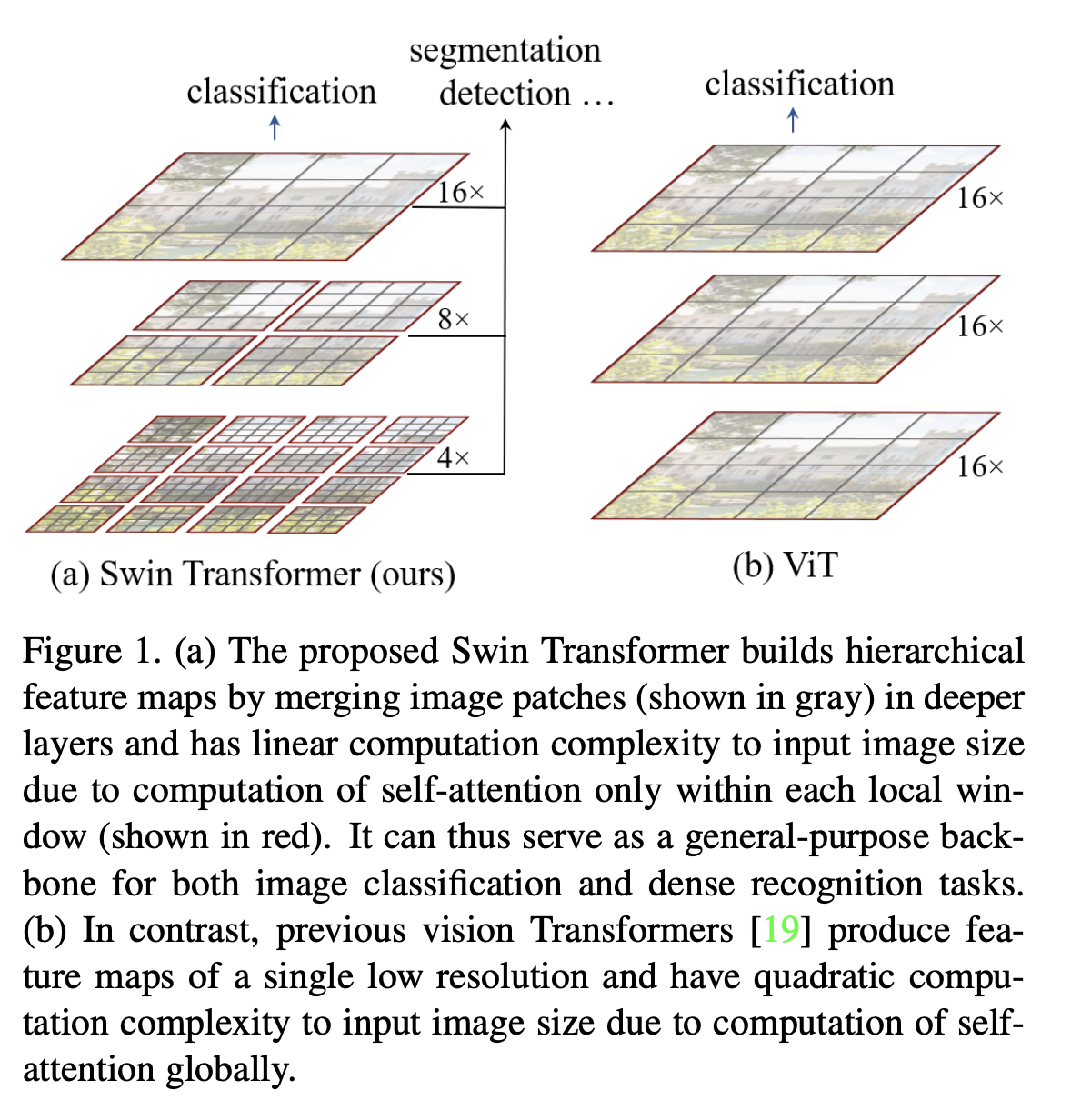
二、Swin Transformer
Swin Transformer ist eine Art visueller Transformator. Es erstellt hierarchische Feature-Maps durch Zusammenführen von Bildfeldern in tieferen Schichten (in Grau dargestellt) und weist eine lineare Rechenkomplexität in der Eingabebildgröße auf, da die Selbstaufmerksamkeit nur innerhalb jedes lokalen Fensters berechnet wird (in Rot dargestellt). Daher kann es als allgemeines Rückgrat für Bildklassifizierungs- und dichte Erkennungsaufgaben dienen. Im Gegensatz dazu generieren frühere visuelle Transformer eine einzelne Feature-Map mit niedriger Auflösung, und die Rechenkomplexität ist aufgrund der Berechnung der globalen Selbstaufmerksamkeit quadratisch in der Eingabebildgröße.
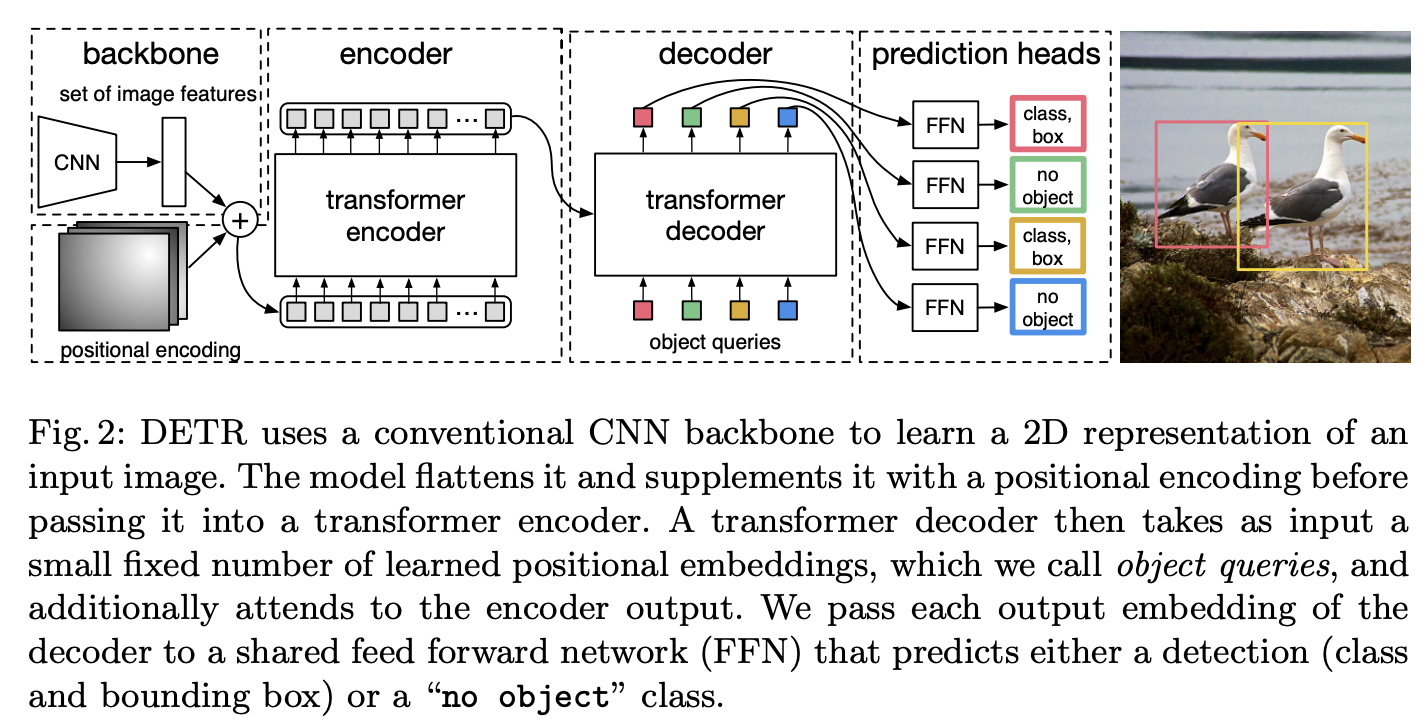
三、Erkennungstransformator
Detr oder Detection Transformer ist ein Ensemble-basierter Objektdetektor, der Transformatoren auf einem Faltungsrückgrat verwendet. Es nutzt ein traditionelles CNN-Backbone, um eine 2D-Darstellung des Eingabebildes zu lernen. Das Modell glättet es und ergänzt es mit einer Positionskodierung, die es dann an einen Transformator-Encoder weitergibt. Der Transformator-Decoder nimmt dann als Eingabe eine kleine feste Anzahl erlernter Positionseinbettungen (die wir Objektabfragen nennen) und konzentriert sich zusätzlich auf die Encoder-Ausgabe. Wir übergeben jede Ausgabeeinbettung des Decoders an ein gemeinsames Feedforward-Netzwerk (FFN), das Erkennungen (Klasse und Begrenzungsrahmen) oder die Klasse „Kein Objekt“ vorhersagt.
四、Dateneffizienter Bildtransformator
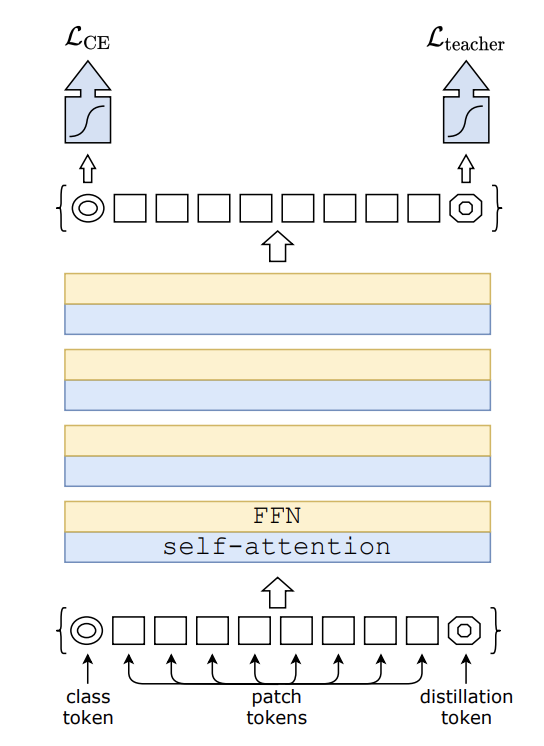
Data Efficient Image Transformer ist ein visueller Transformator für Bildklassifizierungsaufgaben. Das Modell wird mithilfe der einzigartigen Lehrer-Schüler-Strategie von Transformer trainiert. Es basiert auf destillierten Token und stellt sicher, dass Schüler durch Aufmerksamkeit von ihren Lehrern lernen.
五、Selbstdestillation ohne Etiketten
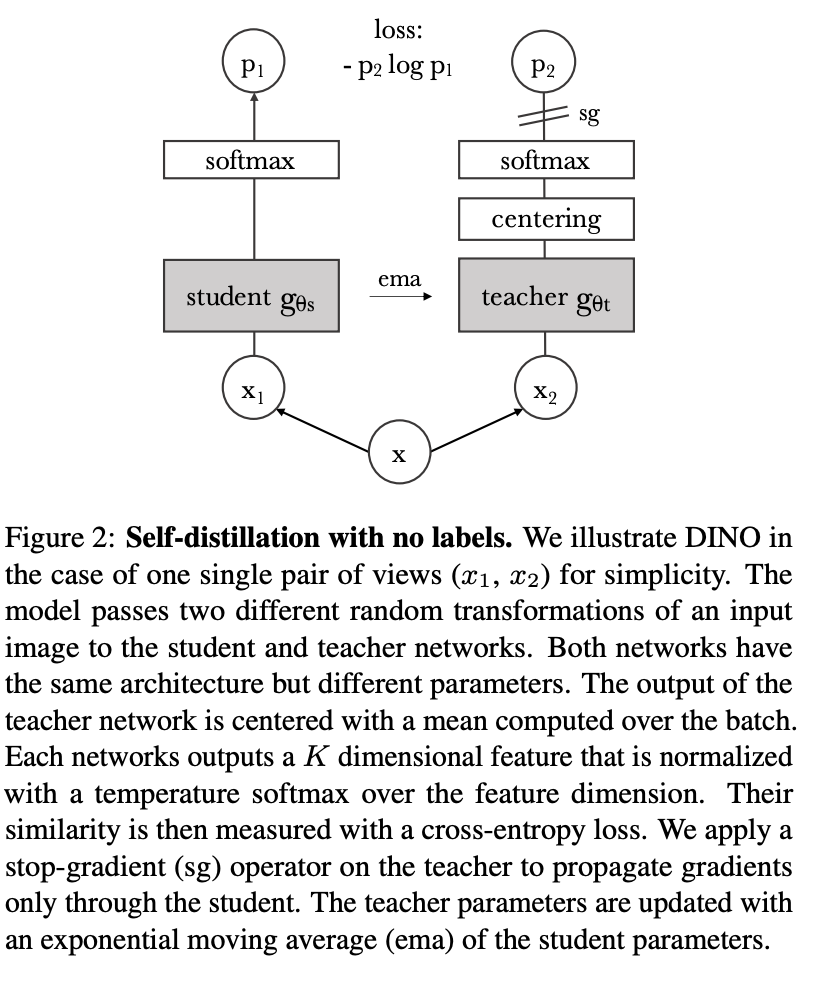
DINO (Destillation Without Labels) ist eine selbstüberwachte Lernmethode, die den Standard-Kreuzentropieverlust verwendet, um die Ausgabe eines Lehrernetzwerks, das aus einem Impulsgeber erstellt wurde, direkt vorherzusagen.

六、Verformbares DETR
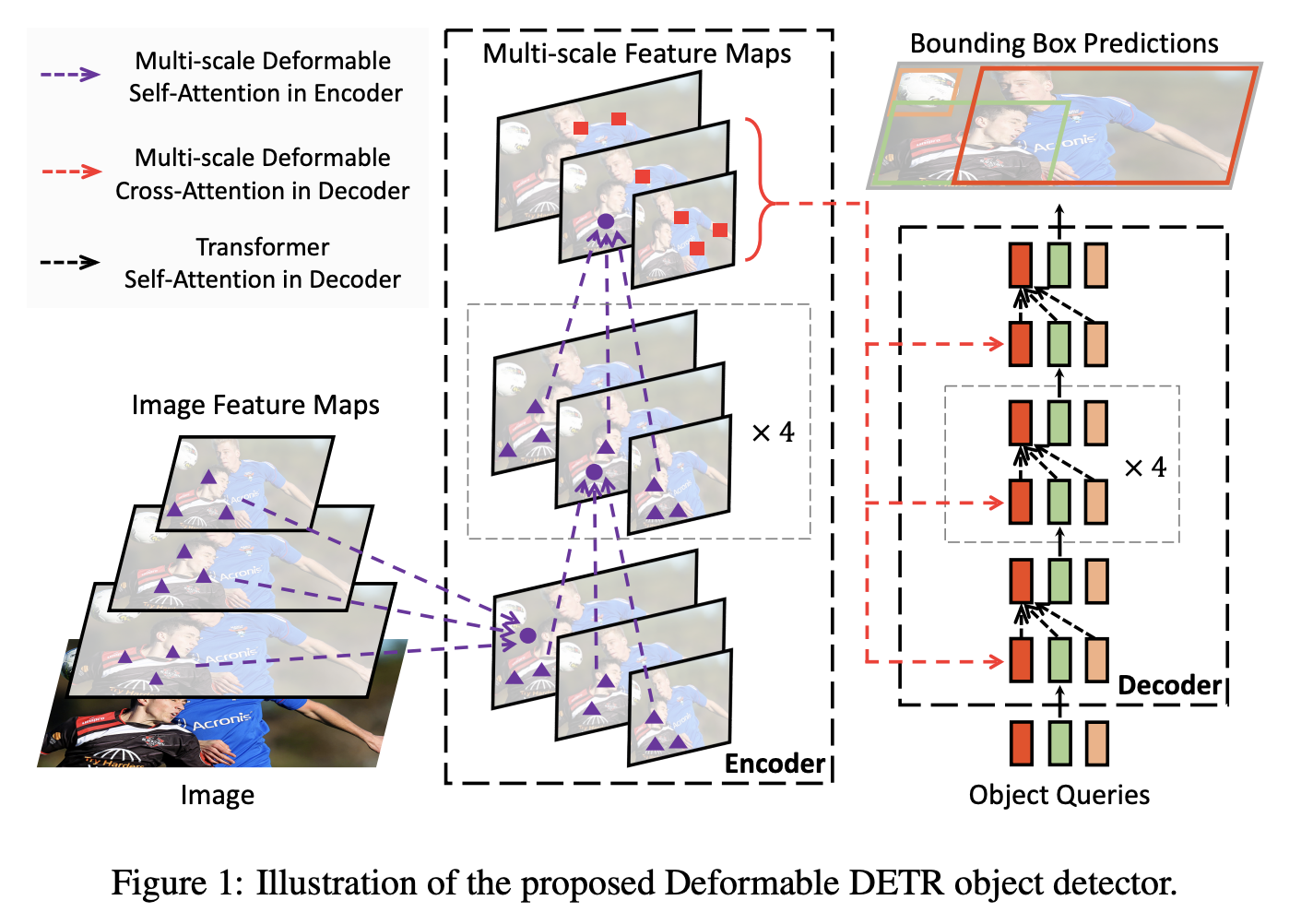
Deformable DETR ist eine Objekterkennungsmethode, die die Probleme der langsamen Konvergenz und der hohen Komplexität von DETR lindern soll. Es kombiniert die beste Leistung der spärlichen räumlichen Abtastung verformbarer Windungen mit den relationalen Modellierungsfunktionen von Transformers. Konkret wird ein verformbares Aufmerksamkeitsmodul eingeführt, das sich auf einen kleinen Satz von Abtastorten als Vorfilter konzentriert, um Schlüsselelemente unter allen Merkmalsbildpixeln hervorzuheben. Dieses Modul kann natürlich erweitert werden, um Multiskalenfunktionen zu aggregieren, ohne auf FPN zurückgreifen zu müssen.
七, Kompakte Faltungstransformatoren
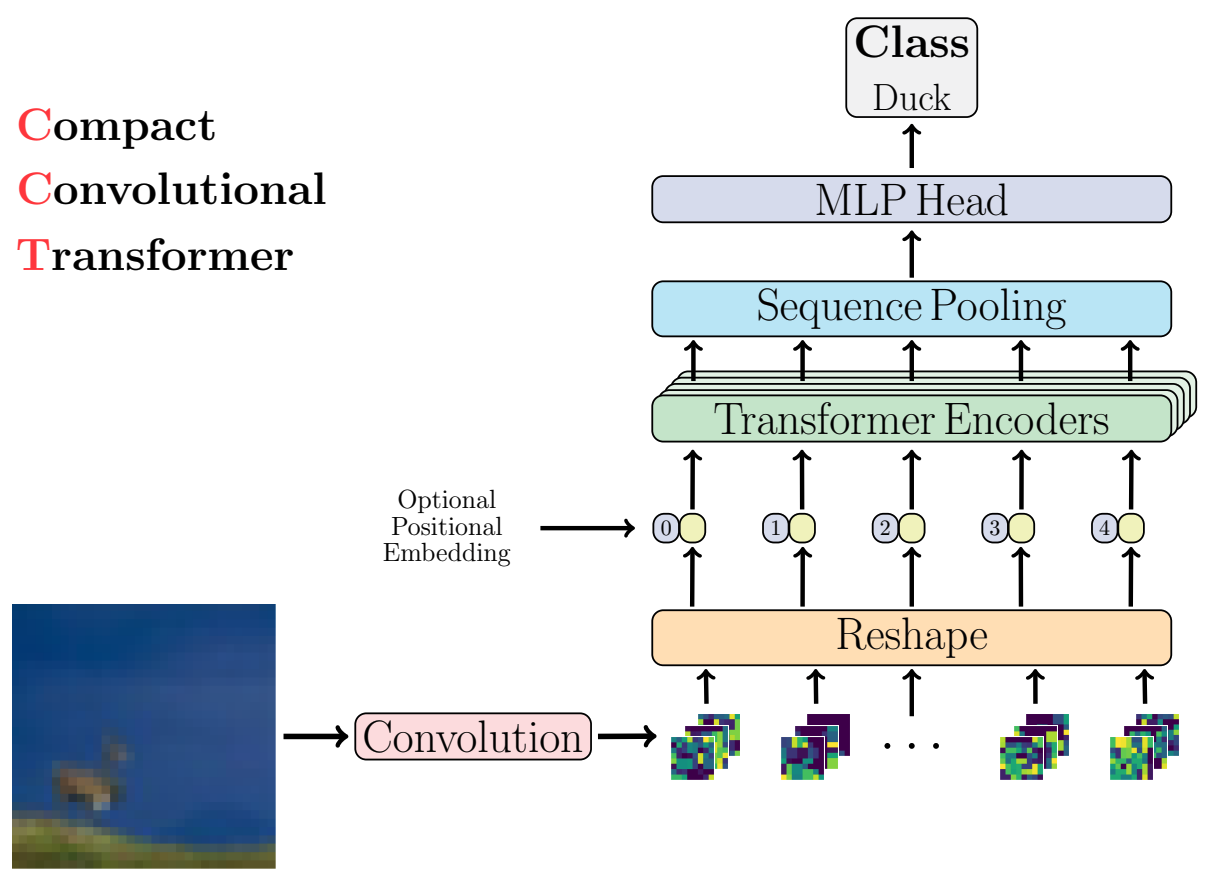
Kompakte Faltungstransformatoren nutzen Sequenz-Pooling und ersetzen Patch-Einbettungen durch Faltungs-Einbettungen, was eine bessere induktive Vorspannung ermöglicht und Positionseinbettungen optional macht. CCT erreicht eine bessere Genauigkeit als ViT-Lite (kleineres ViT) und erhöht die Flexibilität der Eingabeparameter.
8. Nest
NesT stapelt kanonische Transformer-Ebenen, führt für jeden Bild-Patch unabhängig eine lokale Selbstaufmerksamkeit durch und „verschachtelt“ sie dann hierarchisch. Die Kopplung von Verarbeitungsinformationen zwischen räumlich benachbarten Blöcken wird durch die vorgeschlagene Blockaggregation zwischen jeweils zwei Hierarchien erreicht. Die Gesamthierarchie kann durch zwei wichtige Hyperparameter bestimmt werden:

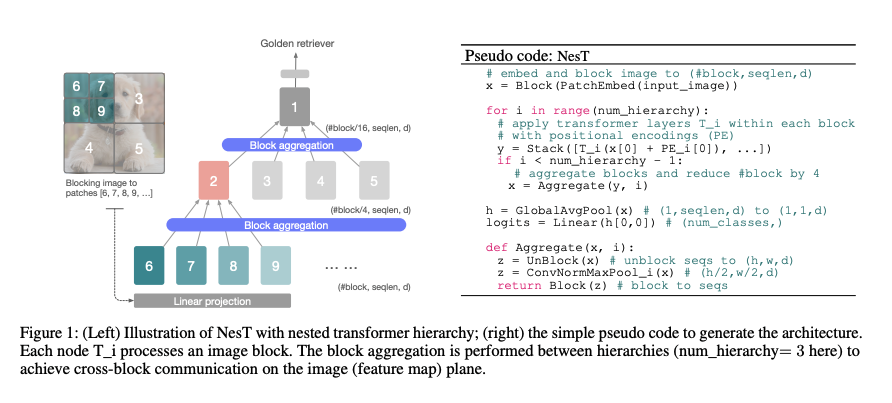
九、Pyramid Vision Transformer
PVT (Pyramid Vision Transformer) ist ein visueller Transformator, der eine Pyramidenstruktur nutzt und somit ein effektives Rückgrat für dichte Vorhersageaufgaben darstellt. Insbesondere ermöglicht es die Verwendung feinkörnigerer Eingaben (4 x 4 Pixel pro Patch) und reduziert gleichzeitig die Sequenzlänge des Transformers mit zunehmender Tiefe, wodurch die Rechenkosten gesenkt werden. Darüber hinaus wird eine SRA-Schicht (Spatial Reduced Attention) verwendet, um den Ressourcenverbrauch beim Erlernen hochauflösender Merkmale weiter zu reduzieren.

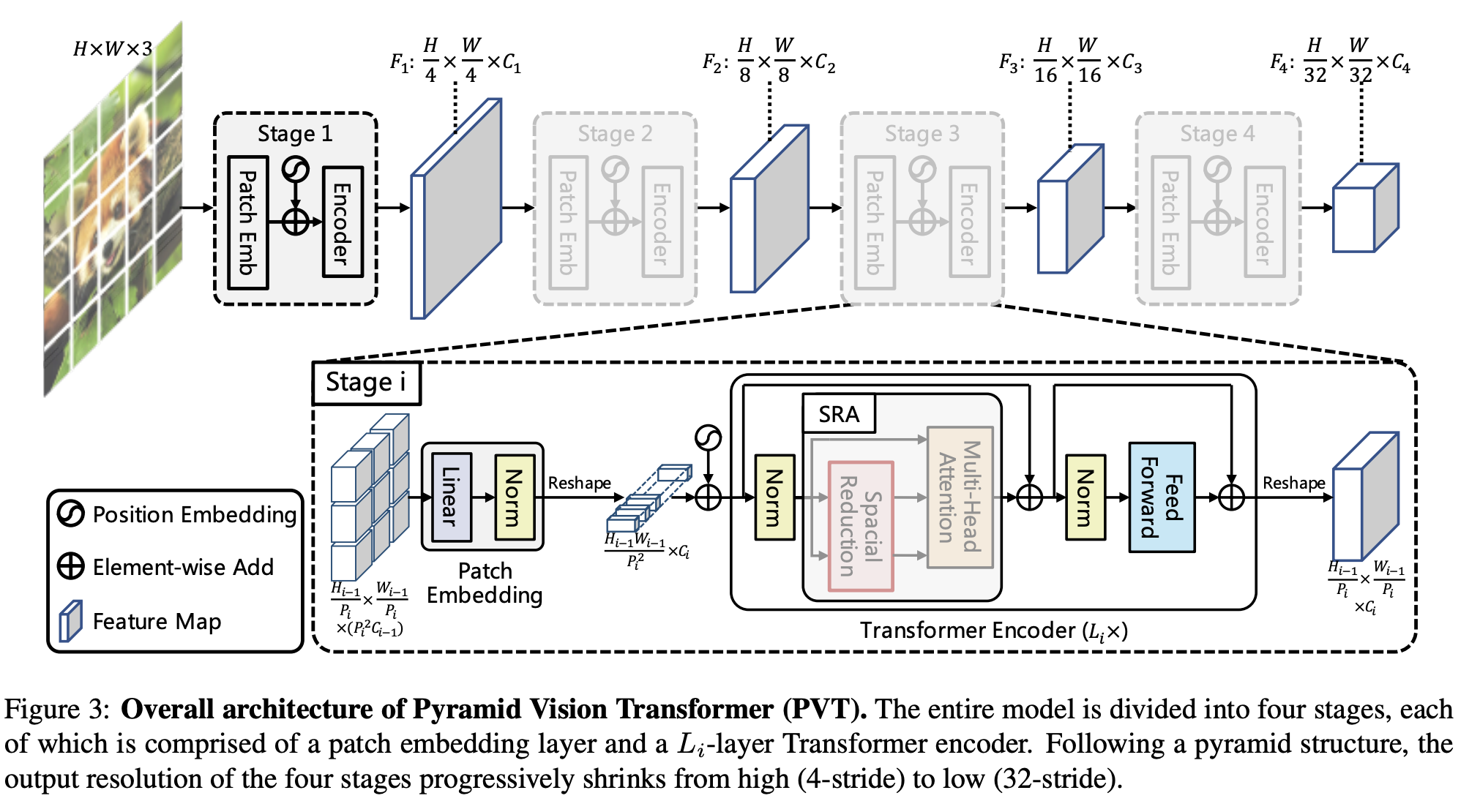
十、Dense Prediction Transformer
Der Dense Prediction Transformer (DPT) ist ein visueller Transformator für dichte Vorhersageaufgaben.
Das Eingabebild wird in Markierungen (orange) umgewandelt, indem nicht überlappende Patches extrahiert und dann ihre abgeflachten Darstellungen (DPT-Base und DPT-Large) linear projiziert werden, oder indem der ResNet-50-Feature-Extraktor (DPT-Hybrid) angewendet wird. Bildeinbettungen werden durch Positionseinbettungen verbessert und Patch-unabhängige Auslesemarkierungen (rot) werden hinzugefügt. Der Token durchläuft mehrere Transformationsstufen. Token werden aus verschiedenen Stadien in bildähnlichen Darstellungen (grün) mit mehreren Auflösungen wieder zusammengesetzt. Das Fusionsmodul (lila) fusioniert und hochsampelt Darstellungen nach und nach, um feinkörnige Vorhersagen zu generieren.
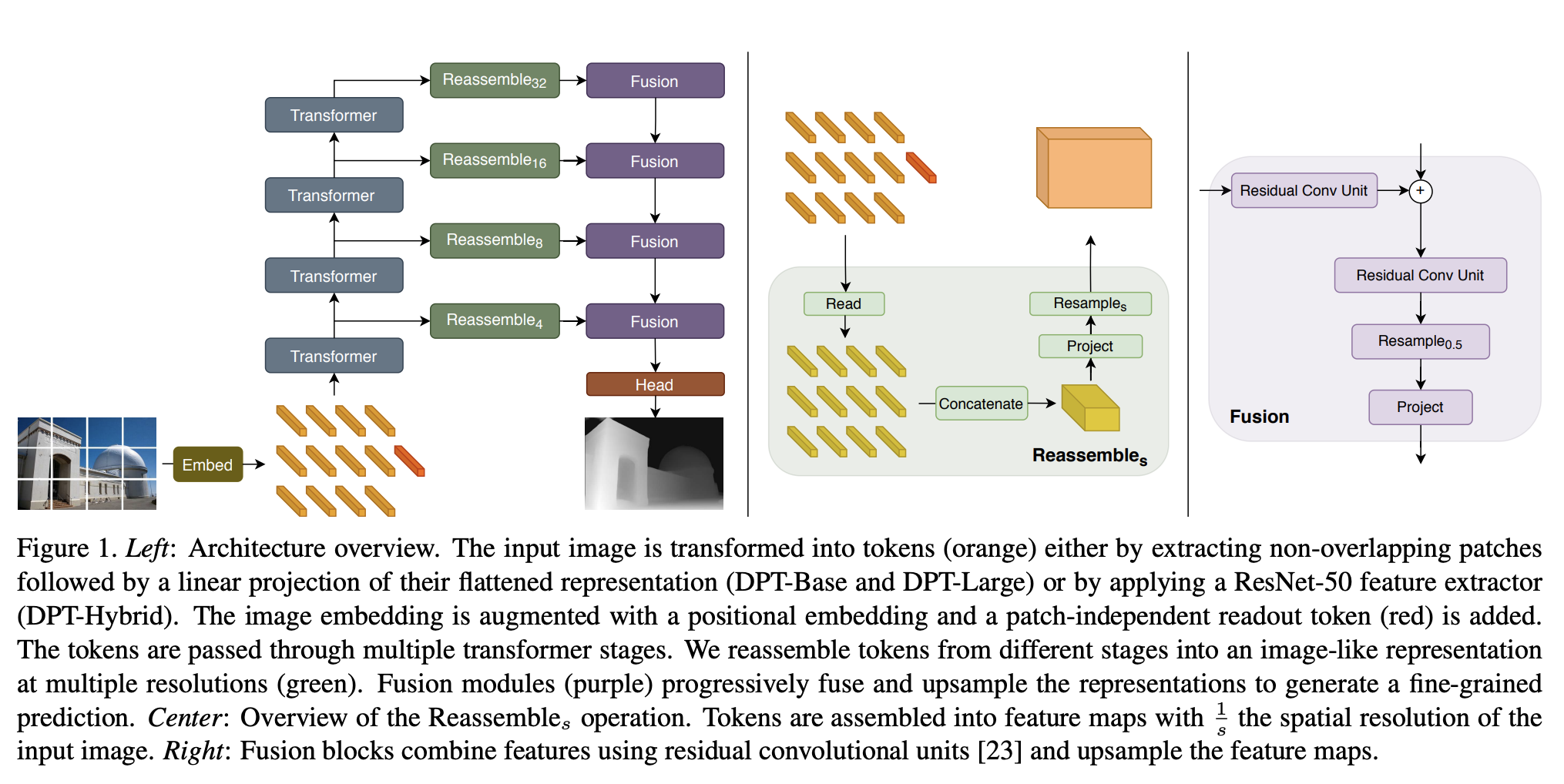
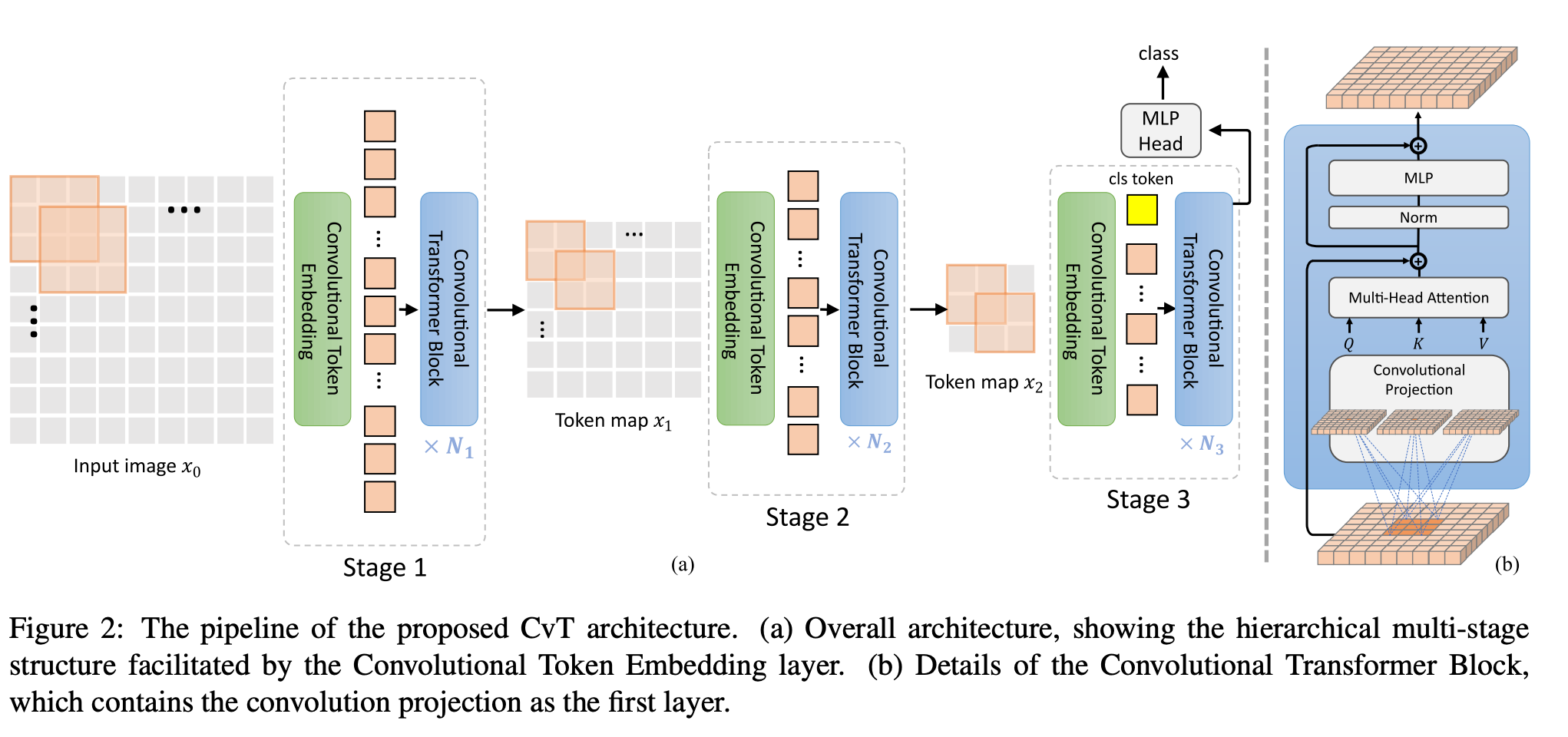
十一、Convolutional Vision Transformer
Convolutional Vision Transformer (CvT) ist eine Architektur, die Faltungen in Transformers integriert. Das CvT-Design führt die Faltung in zwei Kernteile der ViT-Architektur ein.
Erstens sind Transformer in mehrere Stufen unterteilt, die eine Hierarchie von Transformern bilden. Der Beginn jeder Stufe besteht aus einer Faltungs-Token-Einbettung, die überlappende Faltungsoperationen am umgestalteten 2D-Token-Graphen durchführt (d. h. die abgeflachte Token-Sequenz wieder in das räumliche Gitter umformt), gefolgt von einer Schichtnormalisierungsänderung. Dies ermöglicht es dem Modell, nicht nur lokale Informationen zu erfassen, sondern auch die Sequenzlänge schrittweise zu reduzieren und gleichzeitig die Dimensionalität stufenübergreifender gekennzeichneter Features zu erhöhen, wodurch räumliches Downsampling ermöglicht und gleichzeitig die Anzahl der Feature-Maps erhöht wird, genau wie dies bei CNNs der Fall ist.
Zweitens wird die lineare Projektion vor jedem Selbstaufmerksamkeitsblock im Transformer-Modul durch die vorgeschlagene Faltungsprojektion ersetzt, die s × s tiefentrennbare Faltungsoperationen auf dem umgestalteten 2D-Token-Graphen anwendet. Dadurch kann das Modell den lokalen räumlichen Kontext weiter erfassen und semantische Mehrdeutigkeiten im Aufmerksamkeitsmechanismus reduzieren. Es ermöglicht auch die Verwaltung der Rechenkomplexität, da der Schritt der Faltung zur Unterabtastung der Schlüssel- und Wertmatrizen genutzt werden kann, um die Effizienz um den Faktor 4 oder mehr zu steigern und gleichzeitig Leistungseinbußen zu minimieren.
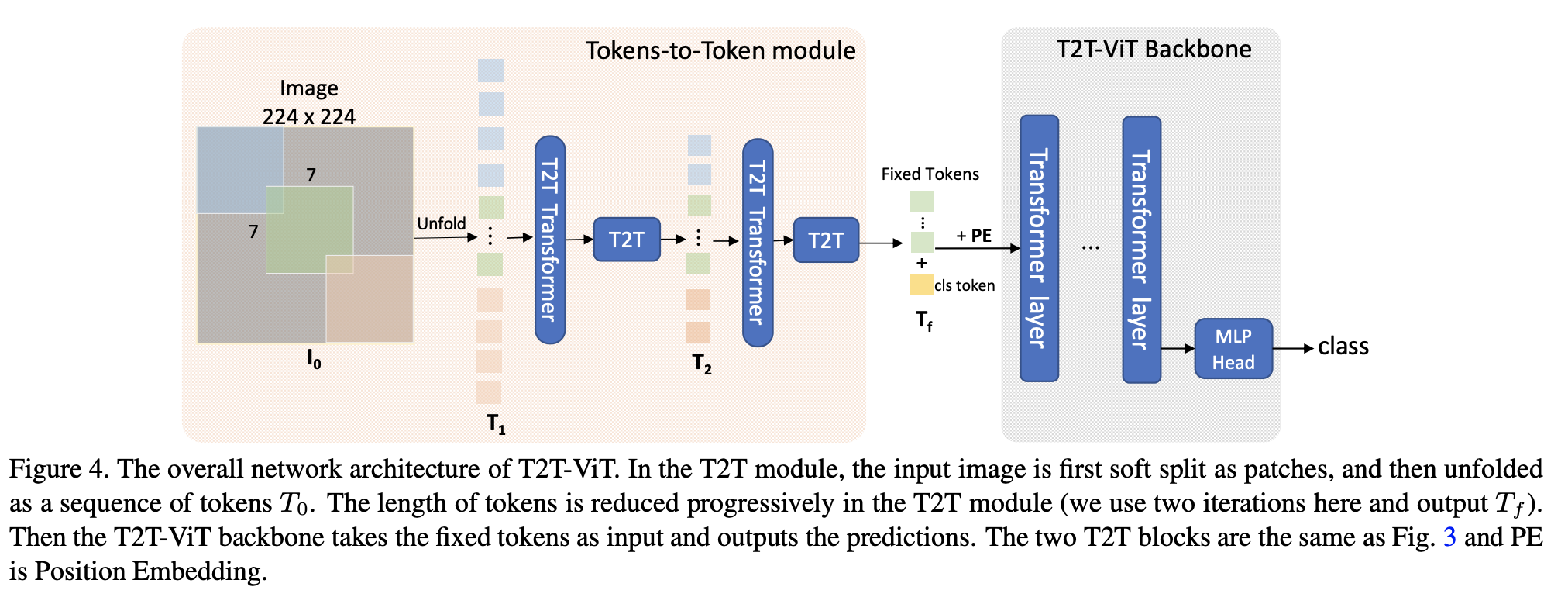
十二、Tokens-To-Token Vision Transformer
T2T-ViT (Tokens-To-Token Vision Transformer) ist ein Vision Transformer, der 1) die hierarchische Tokens-to-Token (T2T)-Transformation durch rekursive Zusammenfassung benachbarter Token zu einem Token (Tokens) kombiniert, um Bilder schrittweise in Token zu strukturieren. -to-Token), das die durch die umgebenden Token dargestellte lokale Struktur modellieren und die Token-Länge reduzieren kann; 2) Nach empirischer Forschung, inspiriert durch das CNN-Architekturdesign, wird der visuelle Transformator mit einer tiefen und schmalen Struktur versehen. Effizientes Rückgrat.
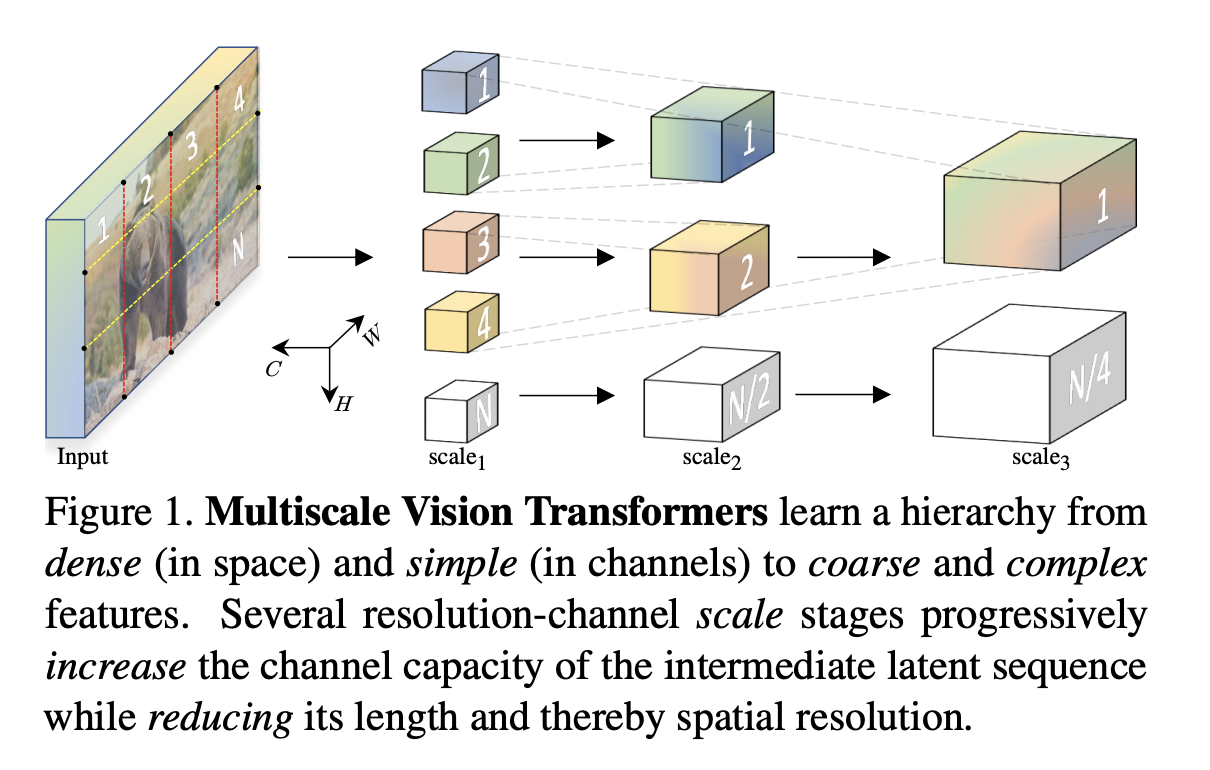
十三、Multiscale Vision Transformer
Multiscale Vision Transformer (MViT) ist eine Transformer-Architektur zur Modellierung visueller Daten wie Bilder und Videos. Im Gegensatz zu herkömmlichen Transformern, die im gesamten Netzwerk eine konstante Kanalkapazität und Auflösung aufrechterhalten, verfügen Multiscale-Transformer über mehrere Skalierungsstufen für die Kanalauflösung. Ausgehend von der Eingangsauflösung und der kleinen Kanalgröße erweitert jede Stufe hierarchisch die Kanalkapazität und verringert gleichzeitig die räumliche Auflösung. Dadurch entsteht eine Merkmalspyramide mit mehreren Maßstäben, wobei die ersten Schichten mit hoher räumlicher Auflösung arbeiten, um einfache visuelle Informationen auf niedriger Ebene zu modellieren, während tiefere Schichten mit räumlich groben, aber komplexen hochdimensionalen Merkmalen arbeiten.
14. MoCo v3


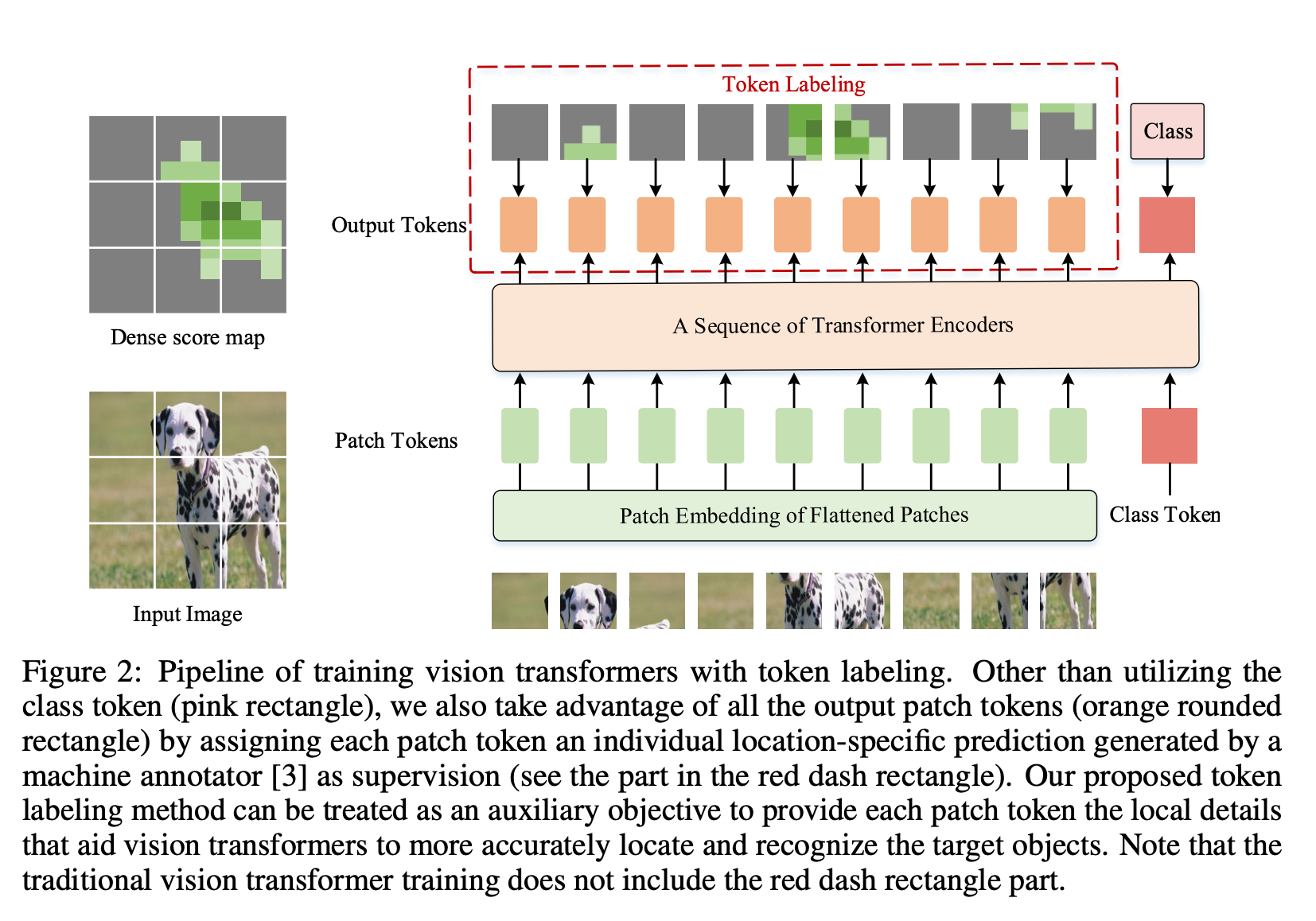
15. LV-ViT
LV-ViT ist ein visueller Transformator, der Markierungsetiketten als Trainingsziele verwendet. Im Gegensatz zum Standard-Trainingsziel von ViT, das darin besteht, den Klassifizierungsverlust für zusätzliche trainierbare Klassenlabels zu berechnen, nutzt das Label-Label alle Bild-Patch-Labels, um den Trainingsverlust auf dichte Weise zu berechnen. Konkret formuliert das Tag-Tagging das Bildklassifizierungsproblem in mehrere Erkennungsprobleme auf Tag-Ebene um und weist jedem Patch-Tag eine individuelle ortsspezifische Überwachung zu, die von einem maschinellen Annotator generiert wird.