Inhaltsverzeichnis
3. Sieben Parameter von Threads
4. Welche Vor- und Nachteile haben Threads?
5. Was ist der Unterschied zwischen der Start- und der Ausführungsmethode?
6. Was ist der Unterschied zwischen Warten und Schlafen?
7. Der Unterschied zwischen Sperre und Synchronisierung
8. Ist das Schlüsselwort „Volatile“ threadsicher? Was ist das zugrunde liegende Prinzip?
9. Was sind die Funktionen und zugrunde liegenden Prinzipien der Synchronisierung?
12. Was ist der Unterschied zwischen HashMap und ConcurrentHashMap?
13. Was ist der Unterschied zwischen HashMap und HashTable?
1. Thread, Prozess, Programm
Prozess: Wir nennen ein laufendes Programm einen Prozess. Jeder Prozess belegt Speicher- und CPU-Ressourcen. Prozesse sind unabhängig voneinander.
Thread: Ein Thread ist eine Ausführungseinheit in einem Prozess und ist für die Ausführung von Programmen im aktuellen Prozess verantwortlich. Ein Prozess kann mehrere Threads enthalten. Multithreading kann die Parallellaufeffizienz von Programmen verbessern.
Programm: Es handelt sich um eine Datei mit Anweisungen und Daten, die auf einer Festplatte oder einem anderen Datenspeichergerät gespeichert ist. Das heißt, das Programm ist ein statischer Code.
2. Thread-Status
1. Neu: Beim Erstellen eines Thread-Objekts
2. Bereit (ausführbar): Der Thread ruft die Startmethode auf und verfügt über Ausführungsqualifikationen, aber keine Ausführungsrechte.
3. Ausführen: Nachdem die CPU im Bereitschaftszustand das Ausführungsrecht erhalten hat, wechselt sie in den Betriebszustand.
4. Blockiert: Wenn der Erwerb der Sperre fehlschlägt, wechselt sie in den blockierten Zustand
5. Warten: Warten darauf, von der notify()-Methode geweckt zu werden
6. Schlafen: Für einen bestimmten Zeitraum schlafen. Nach Ablauf der Zeit wechselt es in den Bereitschaftszustand.
7. Abgebrochen: Thread stirbt ab

3. Sieben Parameter von Threads
1. Anzahl der Kernthreads (corePoolSize): Gibt die Mindestanzahl der Threads an, die aktiv bleiben.
2. Maximale Anzahl von Threads (maximumPoolSize): Gibt die maximale Anzahl von Threads an, die erstellt werden dürfen.
3. Leerlaufzeit (keepAliveTime): Gibt die Zeit an, die überschüssige Leerlauf-Threads am Leben bleiben können, wenn die Anzahl der Threads die Anzahl der Kern-Threads überschreitet.
4. Blockierungswarteschlange (workQueue): Stellt eine Blockierungswarteschlange dar, in der Aufgaben gespeichert werden, die auf ihre Ausführung warten.
5. Einheit: Einheit, die die Leerlaufzeit angibt, z. B. Millisekunden, Sekunden usw.
6. Ablehnungsstrategie (rejectedExecutionHandler): Gibt die Strategie an, die angewendet wird, wenn die Aufgabe nicht zur Ausführung an den Thread-Pool übermittelt werden kann.
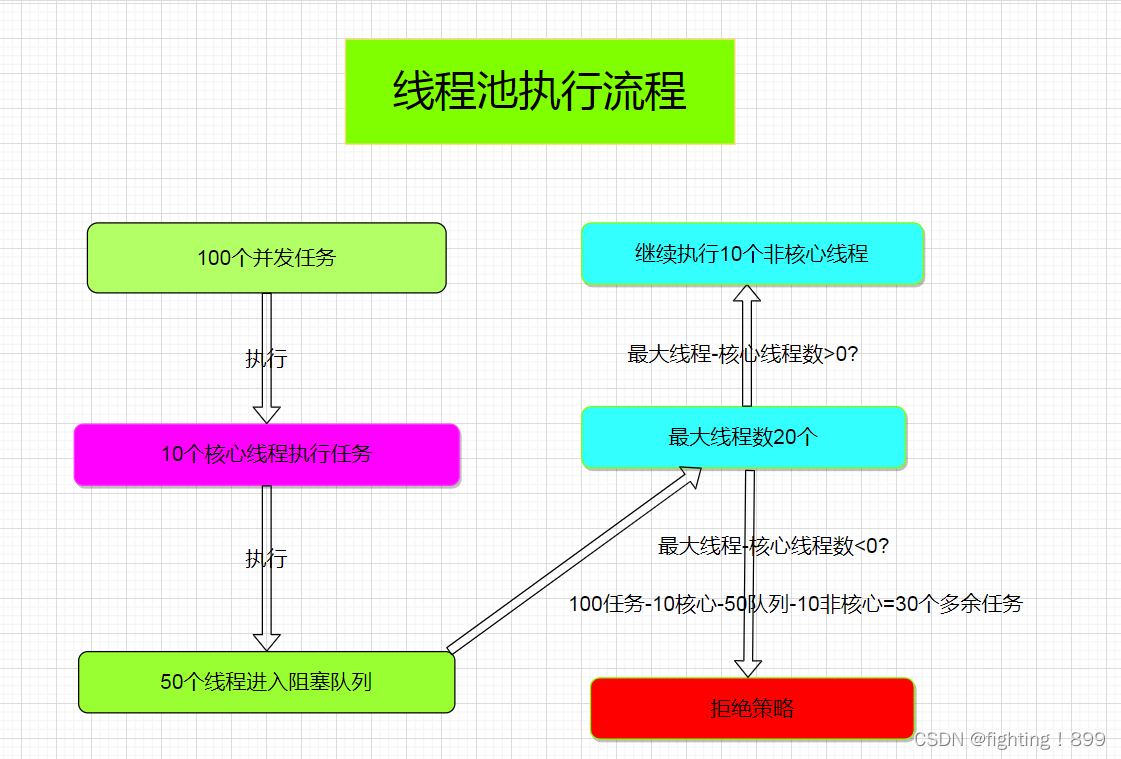
Wenn eine Thread-Aufgabe eingeht, versucht sie zunächst, einen Kern-Thread zur Ausführung zu erstellen. Wenn die Anzahl der Threads im Thread-Pool die Anzahl der Kern-Threads erreicht hat,
Und wenn die Blockierungswarteschlange ebenfalls voll ist, wird versucht, einen neuen Thread zur Ausführung zu erstellen.
Wenn die Anzahl der Threads im Thread-Pool die maximale Anzahl an Threads erreicht hat und die Blockierungswarteschlange voll ist, wird die Ablehnungsstrategie ausgeführt.
Beispiel: Angenommen, die Anzahl der Kernthreads im Thread-Pool beträgt 10, die maximale Anzahl der Threads beträgt 20 und die Kapazität der Blockierungswarteschlange beträgt 50.
Wenn dann 100 Aufgaben in den Thread-Pool gelangen, führen 10 Kernthreads die Aufgaben sofort aus und 50 Aufgaben gelangen in die Blockierungswarteschlange.
Weitere 10 Threads werden erstellt und führen sofort die restlichen Aufgaben aus. Am Ende verbleiben 30 Aufgaben, die nicht ausgeführt werden können und deren Ausführung abgelehnt wird.
4. Welche Vor- und Nachteile haben Threads?
Vorteil:
1. Verbessern Sie in Multi-Core-CPUs die Programmleistung durch paralleles Rechnen . Beispielsweise ist die Ausführung einer Methode zeitaufwändig. Jetzt ist die Logik dieser Methode zur gleichzeitigen Ausführung in mehrere Threads aufgeteilt, um die Programmeffizienz zu verbessern.
2. Es kann die zeitaufwändigen Probleme lösen , die durch Netzwerkwartezeiten und IO-Antworten verursacht werden .
3. Erhöhen Sie die Auslastungsrate der CPU . Verbessern Sie die Auslastungsrate der Netzwerkressourcen
Mangel:
1. Threads sind auch Programme, daher müssen Threads Speicher belegen. Je mehr Threads, desto mehr Speicher belegen sie.
2. Der Zugriff auf gemeinsam genutzte Ressourcen zwischen Threads führt zu Problemen mit der Ressourcensicherheit.
3. Beim Multithreading gibt es ein Kontextwechselproblem . Die CPU führt Aufgaben zyklisch über den Zeitscheibenzuweisungsalgorithmus aus, sodass sie CPU-Ressourcen belegt.
5. Was ist der Unterschied zwischen der Start- und der Ausführungsmethode?
Der Thread kann durch Aufrufen der Startmethode gestartet werden, und die Run-Methode ist nur ein normaler Methodenaufruf in der Thread-Klasse, der weiterhin im Hauptthread ausgeführt wird.
6. Was ist der Unterschied zwischen Warten und Schlafen?
Ähnliche Punkte: Die Wirkung von Warten (lang) und Schlafen (lang) besteht darin, dass der aktuelle Thread vorübergehend das Recht zur Nutzung der CPU aufgibt und in den Blockierungszustand wechselt .
Unterschied:
Sleep ist eine statische Methode von Thread und wait() ist eine Mitgliedsmethode von Object, und jedes Objekt hat sie.
Die Schlafmethode besteht darin , den aktuellen Thread anzuhalten , was einem Schlafen für einen bestimmten Zeitraum entspricht, und dann automatisch aufzuwachen, während wait () durch die Methode notify oder notifyall aufgeweckt werden muss , andernfalls wird er immer blockiert .
Der Aufruf der Wartemethode muss zuerst die Sperre des Warteobjekts erwerben, während im Ruhezustand keine solche Einschränkung besteht. Die Objektsperre wird freigegeben, nachdem die Wartemethode ausgeführt wurde.
Erlauben Sie anderen Threads, die Objektsperre zu erhalten ( ich gebe die CPU auf, aber Sie können sie trotzdem verwenden ); wenn sie in einem synchronisierten Codeblock ausgeführt wird, wird die Objektsperre nicht aufgehoben ( ich gebe die CPU auf, aber Sie können sie nicht verwenden). benutze es ).
7. Der Unterschied zwischen Sperre und Synchronisierung
Grammatische Ebene:
1.synchronized ist ein Schlüsselwort , der Quellcode ist in JVM und wird in der Sprache C++ implementiert
2..Lock ist eine Schnittstelle . Der Quellcode wird von jdk bereitgestellt und in der Java-Sprache implementiert.
3. Bei Verwendung von „Synchronisiert“ wird die Sperre automatisch vom JVM aufgehoben, wenn der synchronisierte Codeblock verlassen wird. Bei Verwendung von „Lock“ müssen Sie die Entsperrmethode manuell aufrufen, um die Sperre aufzuheben, da dies sonst zu Deadlocks und anderen Problemen führen kann.
Funktionsebene
1. Lock bietet mehr Optionen für Sperrmechanismen , wie z. B. faire Sperren, unfaire Sperren, wiedereintretende Sperren, Lese-/Schreibsperren usw., während synchronisiert nur einen Typ hat, nämlich exklusive Sperren (exklusive Sperren).
2. Lock sollte für eine bessere Leistung und Flexibilität zuerst in Szenarien mit hoher Parallelität verwendet werden , während das synchronisierte Schlüsselwort besser für einfache Thread-Synchronisationsszenarien geeignet ist und einfach zu verwenden und zu warten ist.
8. Ist das Schlüsselwort „Volatile“ threadsicher? Was ist das zugrunde liegende Prinzip?
Was ist Nachbestellung?
Wenn eine Variable geändert wird und der Wert der Variablen nicht in den Hauptspeicher geschrieben wurde , lesen andere Threads möglicherweise den alten Wert der Variablen , was zu einem Programmfehler führt.
Bei der gleichzeitigen Programmierung gibt es drei wichtige Funktionen:
Atomarität :
Eine oder mehrere Operationen werden entweder alle erfolgreich ausgeführt oder alle schlagen fehl. Operationen, die die Atomizität erfüllen, können nicht auf halbem Weg unterbrochen werden
Unterbrechen.
Sichtbarkeit :
Wenn mehrere Threads gemeinsam auf eine gemeinsam genutzte Variable zugreifen und ein Thread die Variable ändert, können andere Threads den geänderten Wert sofort sehen.
Ordnung :
Die Reihenfolge der Programmausführung richtet sich nach der Reihenfolge der Codeausführung . (Da das JMM-Modell es dem Compiler und dem Prozessor ermöglicht, die Neuordnung von Befehlen für mehr Effizienz zu optimieren. Die Neuordnung von Befehlen erscheint als serielle Semantik in einem einzelnen Thread und erscheint in Multi-Threads nicht in der richtigen Reihenfolge. Bei der gleichzeitigen Programmierung mit mehreren Threads müssen wir dies berücksichtigen wie man eine teilweise Neuordnung von Anweisungen in einer Multithread-Umgebung ermöglicht und gleichzeitig die Ordnung gewährleistet)
Wie sorgt das Schlüsselwort volatile für Sichtbarkeit und Ordnung ?
Sichtbarkeit sicherstellen: Wenn eine Variable flüchtig geändert wird, aktualisiert die JVM zwangsweise den neuesten Variablenwert im Arbeitsspeicher im Hauptspeicher , was dazu führt, dass der Cache in anderen Threads. Wenn andere Threads auf diese Weise den Cache verwenden und feststellen, dass diese Variable im lokalen Arbeitsspeicher ungültig ist, erhalten sie sie aus dem Hauptspeicher. Auf diese Weise ist der erhaltene Wert der neueste Wert, wodurch Thread-Sichtbarkeit erreicht wird .
Thema :
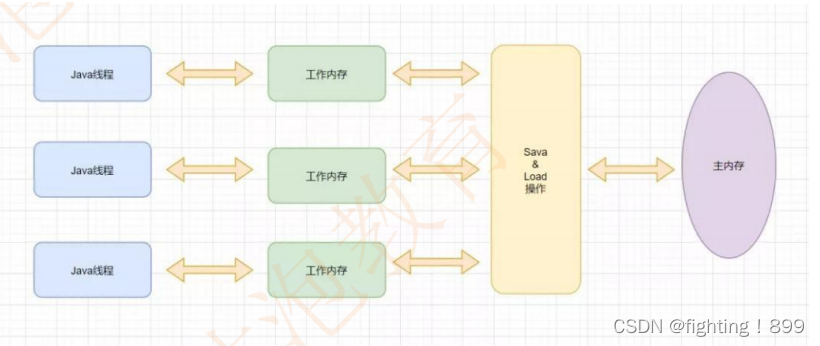
Thread ist die kleinste Einheit der Programmausführung, und mehrere Threads können gleichzeitig ausgeführt werden. In Java verfügt jeder Thread über einen eigenen Arbeitsspeicher
Arbeitsgedächtnis :
Jeder Thread verfügt über einen eigenen Arbeitsspeicher, der auch als Thread- lokaler Speicher bezeichnet wird . Der Arbeitsspeicher ist für den Thread privat und wird zum Speichern von Stapelrahmen, lokalen Variablen und anderen Informationen während der Thread-Ausführung verwendet.
Hauptspeicher :
Der Hauptspeicher ist ein Speicherbereich, der von allen Threads gemeinsam genutzt wird . Alle Variablen werden im Hauptspeicher gespeichert , einschließlich statischer Variablen, Instanzvariablen usw. Der Hauptspeicher ist der Speicherbereich für den Datenaustausch zwischen Threads .
Garantierte Ordnung: Wenn der Compiler Bytecode generiert, fügt erder Befehlssequenz eine „ Speicherbarriere “ hinzu, um eine Neuordnung der Befehle zu verhindern und so die Ordnung sicherzustellen. (Abschirmung der Neuordnung von CPU-Anweisungen in einer Multithread-Umgebung)
Kurz gesagt, das Schlüsselwort Volatile garantiert Sichtbarkeit und Reihenfolge, aber keine Atomizität, sodass volatile nicht threadsicher ist.
9. Was sind die Funktionen und zugrunde liegenden Prinzipien der Synchronisierung?
1. Das Java-Schlüsselwort synchronisiert ist ein Mechanismus zur Implementierung der Multithread-Synchronisation, der sicherstellt, dass mehrere Threads beim Zugriff auf gemeinsam genutzte Ressourcen keine Konkurrenz und Konflikte erzeugen, wodurch Dateninkonsistenzen vermieden werden. Sein Hauptprinzip basiert auf der internen Sperre des Java-Objekts, nämlich der Monitorsperre (Monitor Lock), die sicherstellt, dass nur ein Thread gleichzeitig auf den geschützten Codeblock oder die geschützte Methode zugreifen kann .
2. Wenn ein Thread versucht, eine durch das synchronisierte Schlüsselwort geschützte Ressource abzurufen und die Ressource bereits von anderen Threads belegt ist, wechselt der Thread in einen blockierten Wartezustand. Wenn der Thread, der die Ressource belegt, die Ressource freigibt, konkurrieren die Threads in der Warteschlange um die Ressource, und nur ein Thread erhält die Ressource erfolgreich, während andere Threads weiterhin warten.
3. Das synchronisierte Schlüsselwort garantiert Sichtbarkeit und Atomizität. Die Sichtbarkeit wird durch die zugrunde liegende Speicherbarriere der JVM erreicht , und die Atomizität wird durch den gegenseitigen Ausschluss der Monitorsperre erreicht .
Im synchronisierten Block erhält der Thread die Sperre und löscht den Arbeitsspeicher , sodass die vom Thread verwendeten Variablen erneut aus dem Hauptspeicher gelesen werden können . Gleichzeitig werden die Variablen im Arbeitsspeicher erneut gelesen in den Hauptspeicher zurückgeschrieben werden. Auf diese Weise können andere Threads den neuesten Wert lesen und so die Sichtbarkeit gewährleisten.
11. Ist ThreadLocal threadsicher? Was ist das zugrunde liegende Prinzip? Wird es einen Speicherverlust geben?
Schwache Referenz : Solange der Garbage-Collection-Mechanismus läuft, wird der vom Objekt belegte Speicher unabhängig davon, ob der JVM-Speicherplatz ausreicht, zurückgefordert.
ThreadLocal: Erstellen Sie in jedem Thread eine Kopie für die gemeinsam genutzte Variable, und jeder Thread kann auf seine eigene interne Kopiervariable zugreifen. Thread-Sicherheit wird durch threadlocal gewährleistet.
In der ThreadLocal-Klasse gibt es eine statische interne Klasse ThreadLocalMap (ähnlich Map), die die Variablenkopie jedes Threads in Form von Schlüssel-Wert-Paaren speichert. Der Schlüssel des Elements in ThreadLocalMap ist das aktuelle ThreadLocal-Objekt, und der Wert entspricht die Variable copy des Threads . ThreadLocal selbst speichert keine Werte. Es wird nur als Schlüssel in ThreadLocalMap gespeichert. Es ist jedoch zu beachten, dass es eine schwache Referenz als Schlüssel verwendet . Da es keine starke Referenzkette gibt, kann die schwache Referenz während der GC recycelt werden . Auf diese Weise gibt es in ThreadLocalMap einige Schlüssel-Wert-Paare (Eintrag) mit Nullschlüsseln. Da der Schlüssel null wird, können wir nicht auf diese Einträge zugreifen, aber diese Einträge selbst werden nicht gelöscht. Wenn der entsprechende Schlüssel nicht manuell gelöscht wird, wird der Speicher nicht recycelt und es kann nicht darauf zugegriffen werden, was einen Speicherverlust darstellt . Denken Sie nach der Verwendung von ThreadLocal daran, die Remove- Methode aufzurufen .
1. Jeder Thread verwaltet eine ThreadLocalMap. Der Schlüssel dieser ThreadLocalMap ist die ThreadLocal-Instanz selbst, und der Wert ist der tatsächliche Wert des zu speichernden Objekts.
2. Jeder Thread-Thread enthält eine ThreadLocalMap, und die Map speichert das ThreadLocal-Objekt (Schlüssel) und die Variablenkopie (Wert) des Threads.
3. Die Karte innerhalb des Threads wird von ThreadLocal verwaltet, das für das Abrufen und Festlegen der Variablenwerte des Threads aus der Karte verantwortlich ist.
4. Für verschiedene Threads können andere Threads jedes Mal, wenn der Kopierwert abgerufen wird, nicht den Kopierwert des aktuellen Threads abrufen, wodurch die Kopie isoliert wird und sich nicht gegenseitig stört.
Hinweis: Unter der Voraussetzung, dass der Thread-Pool nicht verwendet wird , wird die „Variablenkopie“ des Threads von gc recycelt, auch wenn die Methode zum Entfernen nicht aufgerufen wird, sodass ThreadLocal eine schwache Referenz ist. Das heißt, es entsteht kein Speicherverlust verursacht .
12. Was ist der Unterschied zwischen HashMap und ConcurrentHashMap?
Zunächst einmal sind sowohl HashMap als auch ConcurrentHashMap Implementierungsklassen der Map-Schnittstelle . Ihre Unterschiede können unter folgenden drei Aspekten analysiert werden:
Thread-Sicherheit : Da HashMap keinen Sperrmechanismus hat, ist es Thread-sicher . ConcurrentHashMap verfügt über eine segmentierte Sperre im Inneren , wodurch es Thread-sicher ist .
Gleichzeitige Leistung : Da ConcurrentHashMap einen segmentierten Sperrmechanismus verwendet, kann es mehrere Threads zum gleichzeitigen Lesen und Schreiben von Vorgängen unterstützen und weist in Szenarien mit hoher Parallelität eine bessere Leistung auf . HashMap ist standardmäßig nicht gesperrt und muss manuell gesperrt werden. Wenn mehrere Threads gleichzeitig dasselbe HashMap-Objekt ändern, können Sperrkonkurrenzbedingungen und Deadlock- Probleme auftreten .
Die zugrunde liegende Datenstruktur ist unterschiedlich : Die zugrunde liegende Schicht von HashMap verwendet ein Array + eine verknüpfte Liste + einen rot-schwarzen Baum , während die zugrunde liegende Schicht von ConcurrentHashMap mithilfe eines Segmentsperrmechanismus (Segmentmechanismus) implementiert wird.
Das zugrunde liegende Segmentierungssperrprinzip von ConcurrentHashMap :
Zum Zeitpunkt von JDK1.7 : Um die Thread-Sicherheit zu gewährleisten , verwendet ConcurrentHashMap einen segmentierten Sperrmechanismus ---> Teilen Sie die Daten zunächst zur Speicherung in Segmente auf und weisen Sie dann jedem Datensegment eine Sperre zu. Wenn der Thread die Daten belegt, wird darauf zugegriffen Durch die Sperre kann auch auf andere Segmentdaten zugegriffen werden. Allerdings weist diese Methode in Szenarien mit hoher Parallelität immer noch einen Leistungsengpass auf, da immer noch mehrere Threads um dieselbe Sperre konkurrieren müssen .
Nach JDK1.8 : Um die Effizienz zu verbessern , wurde das segmentierte Sperrdesign aufgegeben und durch Node+CAS+Synchronized ersetzt , um eine gleichzeitige Sicherheitsimplementierung sicherzustellen. ConcurrentHashMap unterteilt die zugrunde liegende Datenstruktur in mehrere kleine Buckets (Segmente), wobei jeder Bucket ein unabhängiger Hash ist Die Tabelle bleibt erhalten und verschiedene Threads können gleichzeitig auf verschiedene Buckets zugreifen. Dadurch wird vermieden, dass mehrere Threads um dieselbe Sperre konkurrieren , und die Leistung und Effizienz der Parallelität wird verbessert. syschronized sperrt nur den ersten Knoten der aktuellen verknüpften Liste oder des rot-schwarzen Baums. Solange der Hash nicht in Konflikt steht, wird die Effizienz verbessert.
13. Was ist der Unterschied zwischen HashMap und HashTable?
1. Thread-Sicherheit :
HashTable ist threadsicher und HashMap ist nicht threadsicher . Da die Kernmethoden von ashTable alle synchronisierte Synchronisationssperren sind , ist hashMap nicht gesperrt.
2. Umgang mit Nullwerten:
Mit HashMap können Schlüssel und Werte leer (null) sein . Es kann Nullwerte speichern und Null als Schlüssel-Wert-Paar verwenden. HashTable lässt nicht zu, dass Schlüssel oder Werte leer (null) sind. Wenn Sie versuchen, einen Nullwert zu speichern oder Null als Schlüssel zu verwenden, wird eine NullPointerException geworfen.
3. Traversal-Methode:
HashMap kann in beide Richtungen durchlaufen und gelöscht werden . HashTable kann nur in eine Richtung durchlaufen und nicht gelöscht werden.
4. Anfangskapazität und Erweiterungsmechanismus:
Die standardmäßige Anfangskapazität von Hashtable beträgt 11. Bei jeder Erweiterung der Kapazität wird die Kapazität doppelt so hoch wie die ursprüngliche Kapazität plus eins.
Die standardmäßige Anfangskapazität von HashMap beträgt 16 und die Kapazität verdoppelt sich bei jeder Erweiterung.