Índice
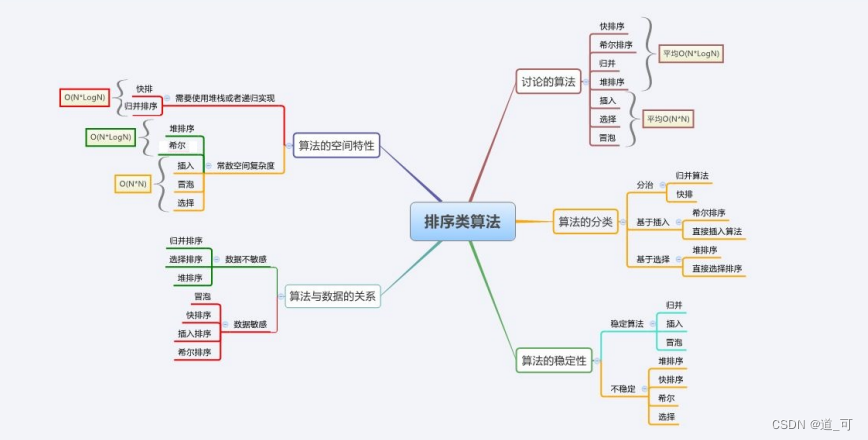
Destaques de classificação comuns
1. Classificação por inserção direta
método de ponteiro para frente e para trás
Classificando a interface de implementação
Complexidade do algoritmo e análise de estabilidade

Aqui está uma estrutura de dados de site recomendada e visualização dinâmica de algoritmo (chinês) - VisuAlgo
Isso nos permite ver o processo de classificação com mais clareza.
Classificando a interface de implementação
classificar.h
#include<stdlib.h>
#include<stdio.h>
#include<assert.h>
#include<time.h>
// 插入排序
void InsertSort(int* a, int n);
// 希尔排序
void ShellSort(int* a, int n);
// 选择排序
void SelectSort(int* a, int n);
// 堆排序
void AdjustDwon(int* a, int n, int root);
void HeapSort(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n)
// 快速排序递归实现
// 1.快速排序hoare版本
int PartSort1(int* a, int left, int right);
// 2.快速排序挖坑法
int PartSort2(int* a, int left, int right);
// 3.快速排序前后指针法
int PartSort3(int* a, int left, int right);
void QuickSort(int* a, int left, int right);
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
// 归并排序递归实现
void MergeSort(int* a, int n)
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
1. Classificação por inserção
Ideia: Inserir os registros a serem ordenados em uma sequência ordenada já ordenada, um por um, de acordo com o tamanho de seus valores-chave, até que todos os registros sejam inseridos e uma nova sequência ordenada seja obtida .

void InsertSort(int* arr, int n)
{
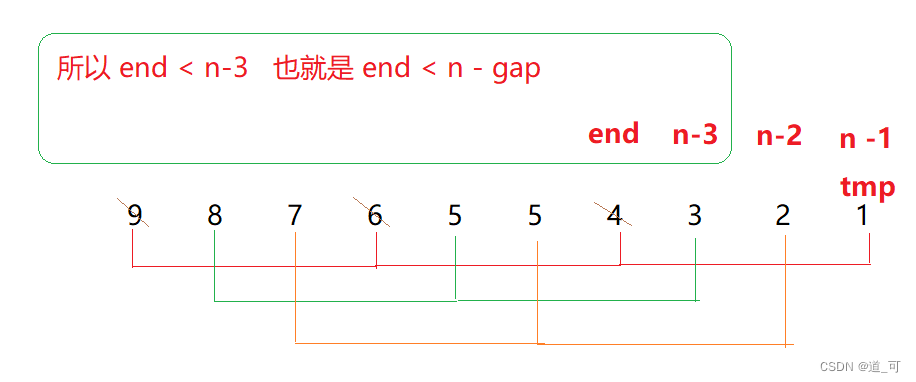
// i< n-1 最后一个位置就是 n-2
for (int i = 0; i < n - 1; i++)
{
//[0,end]的值有序,把end+1位置的值插入,保持有序
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
arr[end + 1] = tmp;
// why? end+1
//break 跳出 插入 因为上面end--;
//为什么不在else那里插入?因为极端环境下,假设val = 0,那么end-- 是-1,不进入while ,
//所以要在外面插入
}
}Por que o loop for i <n-1 está aqui?Como mostrado na figura:

2. Classificação de colinas
A classificação Hill também é chamada de método de redução de incremento. A ideia é: o algoritmo primeiro divide um conjunto de números a serem classificados em vários grupos de acordo com uma certa lacuna de incremento. Os subscritos registrados em cada grupo diferem por lacuna. Classifique todos os elementos em cada grupo e, em seguida, agrupe-o em um incremento menor e classifique-o dentro de cada grupo. Quando o incremento é reduzido para 1 (== classificação por inserção direta), todo o número a ser classificado é dividido em um grupo e a classificação é concluída.
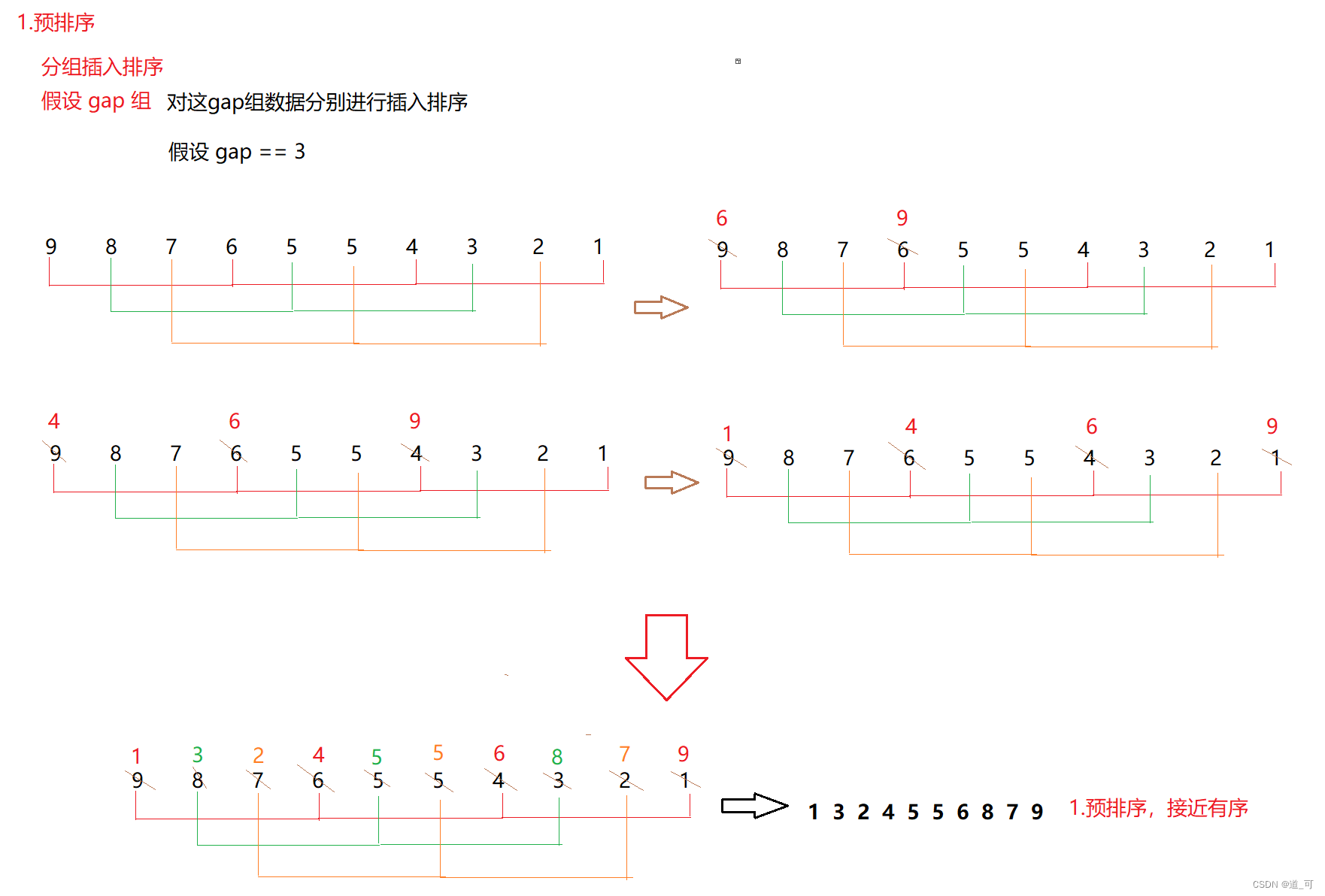
Como mostrado abaixo:
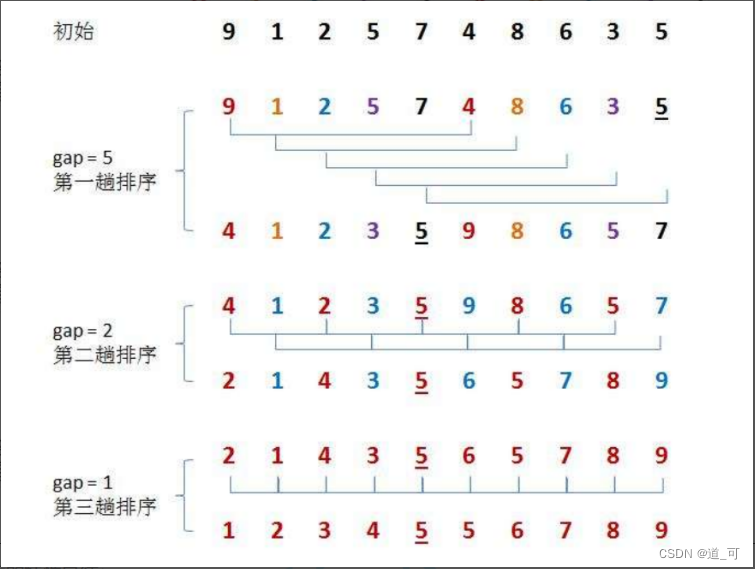
Implementação: ①
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
//gap = gap / 2;
for (int j = 0; j < gap; j++)
{
for (int i = j; i < n - gap; i = i + gap)
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end = end - gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}②: Otimização simples baseada em ①
void ShellSort(int* arr, int n)
{
//gap > 1 时 ,预排序
//gap = 1 时,直接插入排序
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1; //加1意味着最后一次一定是1 ,当gap = 1 时,就是直接排序
//gap = gap / 2;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end = end - gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
Qual é o valor da lacuna?
Aqui depende de hábitos pessoais. Acima, o intervalo é n no início e sempre após entrar no loop é /3. A razão pela qual +1 é para garantir que o intervalo seja 1 no último loop . Claro, /2 também é possível, e /2 significa que você não precisa de +1 no final.
Resumo dos recursos da classificação Hill:
3.Selecione a classificação
Idéia: Cada vez, o menor (ou maior) elemento é selecionado dos elementos de dados a serem classificados e armazenado no início da sequência até que todos os elementos de dados a serem classificados estejam organizados.
Implementação: Uma otimização simples é feita aqui: cada travessia não apenas seleciona o menor, mas também seleciona o maior.
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void SelectSort(int* arr, int n)
{
assert(arr);
int left = 0; //开始位置
int right = n - 1; //结束位置
while (left < right)
{
int min = left;
int max = left;
for (int i = left + 1; i <= right; i++)
{
if (arr[i] < arr[min])
min = i;
if (arr[i] > arr[max])
max = i;
}
Swap(&arr[left], &arr[min]);
//如果 left 和 max 重叠 ,那么要修正 max 的位置
if (left == max)
{
max = min;
}
Swap(&arr[right], &arr[max]);
left++;
right--;
}
}4. Classificação de pilha
Ideia: Heapsort refere-se a um algoritmo de classificação projetado usando uma estrutura de dados como uma árvore empilhada (heap).É um tipo de classificação por seleção. Ele seleciona dados por meio do heap. Deve-se observar que um heap grande deve ser construído em ordem crescente, e um heap pequeno deve ser construído em ordem decrescente.

Implementação: Existem duas maneiras de construir um heap: aqui usamos o método de ajuste descendente para construir um heap.
typedef int HPDataType;
void Swap(HPDataType* p1, HPDataType* p2)
{
HPDataType tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(HPDataType* arr, int size, int parent)//向下调整
{
int child = parent * 2 + 1;
while (child < size)
{
if (arr[child + 1] > arr[child] && child + 1 < size)
{
child++;
}
if (arr[child] > arr[parent])
{
Swap(&(arr[child]), &(arr[parent]));
parent = child;
child = (parent * 2) + 1;
}
else
{
break;
}
}
}
void HeapSort(int* arr, int n)
{
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
//排序
int end = n - 1;
while (end > 0)
{
Swap(&(arr[0]), &(arr[end]));
AdjustDown(arr, end, 0);
end--;
}
}5. Classificação por bolha
Ideia: Troque as posições dos dois registros na sequência com base nos resultados da comparação dos valores-chave dos dois registros na sequência. A característica da classificação por bolha é: mover o registro com um valor-chave maior para o final de a sequência e move o registro com um valor de chave menor para o final da sequência. Os registros são movidos para o início da sequência.
Consulte: borbulhando
concluir:
void BubbleSort(int* arr, int n)
{
assert(arr);
for (int i = 0; i < n; i++)
{
int flag = 1;
for (int j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
Swap(&arr[j], &arr[j + 1]);
flag = 0;
}
}
//如果没有发生交换,说明有序,直接跳出
if (flag == 1)
break;
}
}6. Classificação rápida
Idéia: pegue qualquer elemento na sequência de elementos a ser classificado como valor de referência e divida o conjunto a ser classificado em duas subsequências de acordo com o código de classificação. Todos os elementos na subsequência esquerda são menores que o valor de referência e todos os elementos na subsequência direita são maiores que o valor de referência .valor e, em seguida, repita o processo para as subsequências esquerda e direita até que todos os elementos estejam organizados nas posições correspondentes .
versão hoare


Métodos como abaixo:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
int PartSort1(int* arr, int begin, int end)
{
int left = begin;
int right = end;
//keyi 意味着保存的是 key 的位置
int keyi = left;
while (left < right)
{
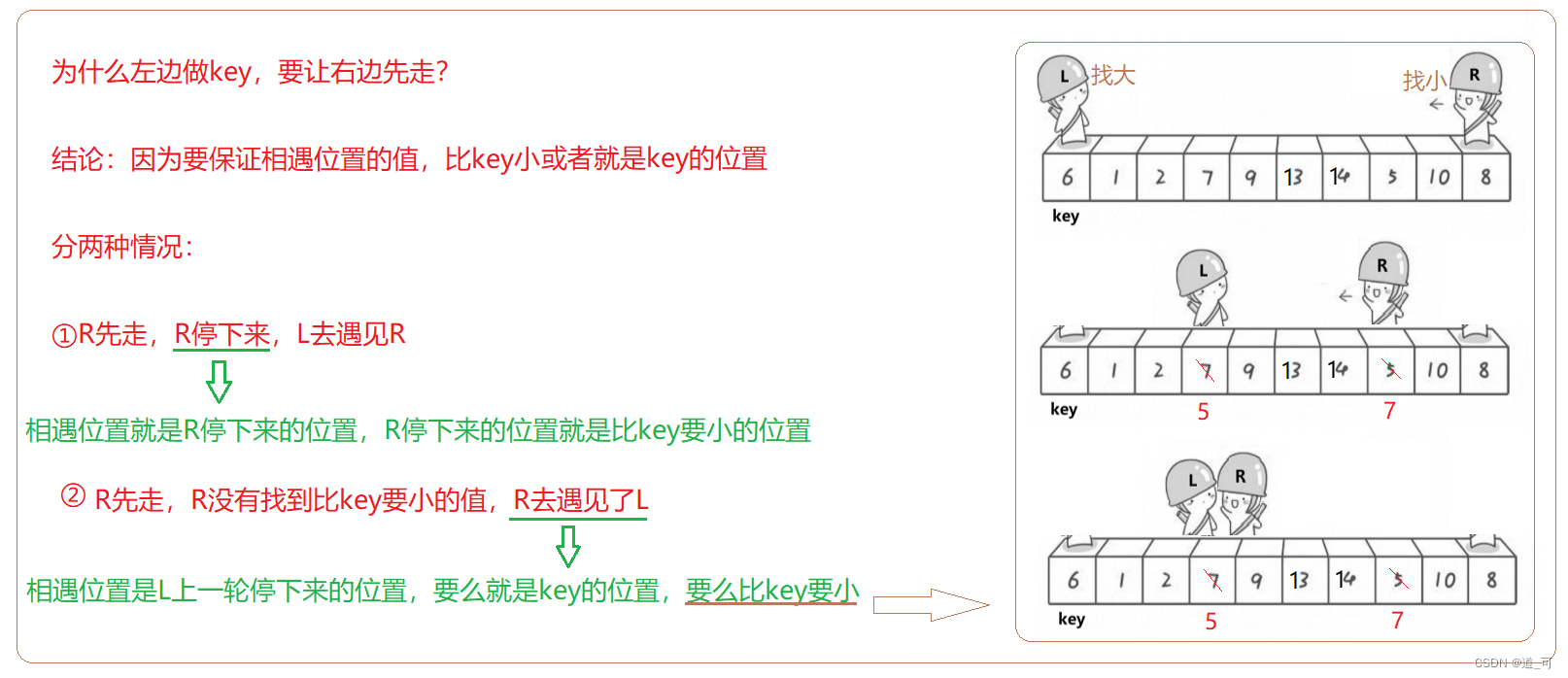
//右边先走,找小
while (left < right && arr[right] >= arr[keyi])
{
right--;
}
//左边再走,找大
while (left < right && arr[left] <= arr[keyi])
{
left++;
}
//走到这里意味着,右边的值比 key 小,左边的值比 key 大
Swap(&arr[left], &arr[right]);
}
//走到这里 left 和 right 相遇
Swap(&arr[keyi], &arr[left]);
keyi = left; //需要改变keyi的位置
return keyi;
}Método de escavação


Métodos como abaixo:
int PartSort2(int* arr, int begin, int end)
{
int key = arr[begin];
int piti = begin;
while (begin < end)
{
//右边先走,找小,填到左边的坑里去,这个位置形成新的坑
while (begin < end && arr[end] >= key)
{
end--;
}
arr[piti] = arr[end];
piti = end;
//左边再走,找大
while (begin < end && arr[begin] <= key)
{
begin++;
}
arr[piti] = arr[begin];
piti = begin;
}
//相遇一定是在坑位
arr[piti] = key;
return piti;
}método de ponteiro para frente e para trás

Métodos como abaixo:
int PartSort3(int* arr, int begin, int end)
{
int key = begin;
int prev = begin;
int cur = begin + 1;
//优化-三数取中
int midi = GetMidIndex(arr, begin, end);
Swap(&arr[key], &arr[midi]);
while (cur <= end)
{
if (arr[cur] < arr[key] && prev != cur )
{
prev++;
Swap(&arr[prev], &arr[cur]);
}
cur++;
}
Swap(&arr[key], &arr[prev]);
key = prev;
return key;
}Realização: Os três métodos acima são todos implementados na forma de funções, que são convenientes de chamar. Além disso, os métodos acima são todos de classificação de passagem única . Se você deseja obter uma classificação completa, ainda precisa usar um método recursivo, semelhante à travessia de pré-ordem de uma árvore binária
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void QuickSort(int* arr, int begin,int end)
{
//当区间不存在或者区间只要一个值,递归返回条件
if (begin >= end)
{
return;
}
if (end - begin > 20) //小区间优化一般在十几
{
//int keyi = PartSort1(arr, begin, end);
//int keyi = PartSort2(arr, begin, end);
int keyi = PartSort3(arr, begin, end);
//[begin , keyi - 1] keyi [keyi + 1 , end]
//如果 keyi 的左区间有序 ,右区间有序,那么整体就有序
QuickSort(arr, begin, keyi - 1);
QuickSort(arr, keyi + 1, end);
}
else
{
InsertSort(arr + begin, end - begin + 1);//为什么+begin,因为排序不仅仅排序左子树,还有右子树
//为什么+1 ,因为这个区间是左闭右闭的区间.例:0-9 是10个数 所以+1
}
}otimização:
int GetMidIndex(int* arr, int begin, int end)
{
//begin mid end
int mid = (begin + end) / 2;
if (arr[begin] < arr[mid])
{
if (arr[mid] < arr[end])
{
return mid;
}
else if(arr[begin] < arr[end]) //走到这里说明 mid 是最大的
{
return end;
}
else
{
return begin;
}
}
else // arr[begin] > arr[mid]
{
if (arr[mid] > arr[end])
{
return mid;
}
else if (arr[begin] < arr[end]) // 走到这里就是 begin end 都大于 mid
{
return begin;
}
else
{
return end;
}
}
}Versão não recursiva :
A versão não recursiva precisa usar uma pilha, que é implementada em linguagem c, então você precisa implementar manualmente uma pilha
Se você usar C++, poderá fazer referência direta à pilha.
A implementação da pilha aqui é temporariamente omitida e um link será fornecido posteriormente. Apenas saiba disso por enquanto.
Diagrama simplificado:

//非递归
//递归问题:极端场景下,深度太深,会出现栈溢出
//1.直接改成循环--例:斐波那契数列、归并排序
//2.用数据结构栈模拟递归过程
void QuickSortNonR(int* arr, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, end);
StackPush(&st, begin);
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(arr, left, right);
//[left , keyi - 1] keyi [keyi + 1 , right]
if (keyi + 1 < right)
{
StackPush(&st, right);
StackPush(&st, keyi + 1);
}
if (left < keyi - 1)
{
StackPush(&st, keyi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}7. Mesclar classificação
Idéia: Merge sort (MERGE-SORT ) é um algoritmo de classificação eficaz baseado na operação de mesclagem.Este algoritmo é uma aplicação muito típica do método de divisão e conquista ( Divide and Conquer). Mesclar as subsequências já ordenadas para obter uma sequência completamente ordenada; isto é, primeiro torne cada subsequência ordenada e depois ordene os segmentos da subsequência. Se duas listas ordenadas são mescladas em uma lista ordenada, isso é chamado de mesclagem bidirecional. Etapas principais da classificação por mesclagem:

concluir:
void _MergeSort(int* arr, int begin, int end, int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
//[begin mid] [mid+1,end]
//递归
_MergeSort(arr, begin, mid, tmp);
_MergeSort(arr, mid + 1, end, tmp);
//归并[begin mid] [mid+1,end]
int left1 = begin;
int right1 = mid;
int left2 = mid + 1;
int right2 = end;
int i = begin;//这里之所以等于begin 而不是等于0 是因为可能是右子树而不是左子树 i为tmp数组下标
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[i++] = arr[left1++];
}
else
{
tmp[i++] = arr[left2++];
}
}
//假如一个区间已经结束,另一个区间直接拿下来
while (left1 <= right1)
{
tmp[i++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[i++] = arr[left2++];
}
//把归并的数据拷贝回原数组 [begin mid] [mid+1,end]
// +begin 是因为可能是右子树 例:[2,3][4,5]
//+1 是因为是左闭右闭的区间 0-9 是10个数据
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
_MergeSort(arr, 0, n - 1, tmp);
free(tmp);
}
Versão não recursiva:
Pensamento: Pilhas ou filas não podem ser usadas aqui, porque pilhas ou filas são adequadas para substituir a travessia de pré-pedido, mas a ideia de classificação de mesclagem pertence à travessia de pós-pedido. As características das pilhas e filas significam que o o espaço anterior não pode ser usado posteriormente.
Como aqui é um loop, você pode projetar um intervalo variável. Quando intervalo = 1, mescle-os um por um. Quando intervalo = 2, mescle-os em pares, intervalo *2 de cada vez.
Como mostrado na imagem:

código mostrado abaixo:
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
}
memcpy(arr, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}Porém, o código acima envolve um problema, pois se os dados a serem classificados não forem uma potência de 2, ocorrerão problemas (não tem nada a ver com a paridade dos dados) e ultrapassarão o limite .
exemplo:

Então precisamos otimizar o código, a otimização pode ser feita a partir de dois aspectos:
//1. Após a fusão, copie todos os dados de volta para a matriz original
//Adote o método de correção de limite
//Exemplo: Se forem 9 dados, os últimos dados continuarão a ser mesclados
//Porque se não forem mesclados, todos serão copiados de volta para o array original pela última vez. Array, o que significa 9 dados, os primeiros 8 são mesclados e os últimos dados copiados de volta geram valores aleatórios porque não são mesclados.
//Se cruzar o limite, corrija o limite e continue a mesclar
código mostrado abaixo:
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
//printf("gap=%d->", gap);
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
//监测是否出现越界
//printf("[%d,%d][%d,%d]---", left1, right1, left2, right2);
//修正边界
if (right1 >= n)
{
right1 = n - 1;
//[left2 , right2] 修正为一个不存在的区间
left2 = n;
right2 = n - 1;
}
else if (left2 >= n)
{
left2 = n;
right2 = n - 1;
}
else if (right2 >= n)
{
right2 = n - 1;
}
//printf("[%d,%d][%d,%d]---", left1, right1, left2, right2);
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
}
//printf("\n");
memcpy(arr, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}2. Para mesclar um conjunto de dados, copie um conjunto de dados de volta para a matriz original
Dessa forma, se ultrapassar os limites, ele sairá diretamente do loop e os dados subsequentes não serão mesclados.
void MergeSortNonR_2(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i , i + gap-1] [i + gap , i + 2*gap-1]
int left1 = i;
int right1 = i + gap - 1;
int left2 = i + gap;
int right2 = i + 2 * gap - 1;
//right1 越界 或者 left2 越界,则不进行归并
if (right1 >= n || left2 > n)
{
break;
}
else if (right2 >= n)
{
right2 = n - 1;
}
int m = right2 - left1 + 1;//实际归并个数
int j = left1;
while (left1 <= right1 && left2 <= right2)
{
if (arr[left1] < arr[left2])
{
tmp[j++] = arr[left1++];
}
else
{
tmp[j++] = arr[left2++];
}
}
while (left1 <= right1)
{
tmp[j++] = arr[left1++];
}
while (left2 <= right2)
{
tmp[j++] = arr[left2++];
}
memcpy(arr+i, tmp+i, sizeof(int) * m);
}
gap *= 2;
}
free(tmp);
}Os dois métodos de código acima estão todos disponíveis, o importante específico é a ideia.
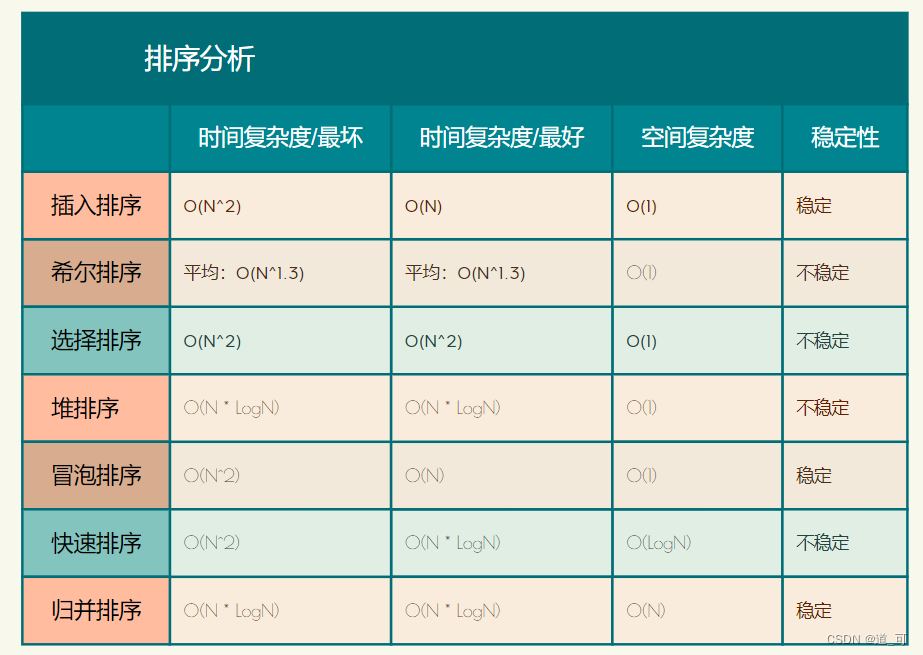
Complexidade do algoritmo e análise de estabilidade
Estabilidade : Suponha que existam vários registros com a mesma palavra-chave na sequência de registros a serem classificados. Se classificados, a ordem relativa desses registros permanece inalterada, ou seja, na sequência original, r[i]=r[j] , e r[i] é antes de r[j] , e na sequência classificada, r[i] ainda é antes de r[j] , então esse algoritmo de classificação é chamado de estável; caso contrário, é chamado de instável.