prefácio
Ao processar dados no trabalho, muitas vezes é necessário usar pandas e registrar alguns hábitos de uso de pandas no trabalho.
1. Mesclar dados
#读取原始数据
data1 = pd.read_excel('/home/zhenhengdong/WORk/Classfier/Dates/Original/1.xlsx')
data2 = pd.read_excel('/home/zhenhengdong/WORk/Classfier/Dates/Original/2.xlsx')
data3 = pd.read_excel('/home/zhenhengdong/WORk/Classfier/Dates/Original/3.xlsx')
data4 = pd.read_excel('/home/zhenhengdong/WORk/Classfier/Dates/Original/20230712.xlsx')
#新建data
data = pd.DataFrame()
#有选择的将原始数据进行合并
data['序号'] = pd.concat([data4['序号'],data3['序号'],data1['序号'],data2['序号']], ignore_index=False)
data['内容'] = pd.concat([data4['内容'],data3['内容'],data1['内容'],data2['内容']], ignore_index=False)
data['一级分类'] = pd.concat([data4['一级分类'],data3['一级分类'],data1['一级分类'],data2['一级分类']], ignore_index=False)
data['二级分类'] = pd.concat([data4['二级分类'],data3['二级分类'],data1['二级分类'],data2['二级分类']], ignore_index=False)
data['反馈类型'] = pd.concat([data4['反馈类型'],data3['反馈类型'],data1['反馈类型'],data2['反馈类型']], ignore_index=False)2. Exclua dados
2.1 Excluir linha
O parâmetro index especifica a linha a ser excluída e o parâmetro inplace indica se deve operar no conjunto de dados original.
#根据行索引删除行
data.drop(index=[0, 4], inplace=True)2.2 Excluir coluna
O parâmetro columns especifica as colunas a serem excluídas e o parâmetro inplace indica se deve operar no conjunto de dados original.
#根据列名称删除列
data.drop(columns=['class'], inplace=True)Você também pode usar del para excluir.
del data['class']2.3 Excluir linhas duplicadas
O parâmetro subset especifica as colunas que precisam ser verificadas quanto a duplicatas e o valor padrão é todas as colunas. O parâmetro inplace indica se deve operar no conjunto de dados original. keep=last significa manter a última linha duplicada e keep=first significa manter a primeira linha duplicada.
data.drop_duplicates(subset="gender", inplace=True,keep='last')2.4 Excluir linhas ausentes
eixo: eixo. 0 ou 'índice' significa exclusão por linha; 1 ou 'colunas' significa exclusão por coluna.
como: método de filtro. 'qualquer' significa que, desde que a linha/coluna tenha mais de um valor nulo, a linha/coluna será excluída; 'todos' significa que a linha/coluna contém todos valores nulos e a linha/coluna será excluída.
thresh: Número mínimo de elementos não vazios. tipo int, o padrão é Nenhum. Se o número de elementos não vazios na linha/coluna for menor que esse valor, exclua a linha/coluna.
subconjunto: subconjunto. Uma lista cujos elementos são índices de linha ou coluna. Se eixo=0 ou 'índice', os elementos do subconjunto são o índice da coluna; se eixo=1 ou 'coluna', os elementos do subconjunto são o índice da linha. A subárea restrita por subconjunto é uma área de julgamento de condições para julgar se a linha/coluna deve ser excluída.
inplace: Se deve ser substituído no local. Valor booleano, o padrão é False. Se True, opere no DataFrame original e retorne None.
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# 删除包含缺失值的行
data.dropna()
# 删除全部为缺失值的行
data.dropna(how='all')
# 删除至少有2个缺失值的行
data.dropna(thresh=2)
# 根据指定的列删除包含缺失的行
data.dropna(subset=['列名'])
2.5 Excluir linhas por condição
2.5.1 Exclusão aleatória elegível
Exclua as linhas cujo tipo de feedback seja BUG e exclua aleatoriamente 44 linhas.
from random import sample
drop_index_1 = data[(data.反馈类型 == 'BUG问题')].index.tolist()
drop_index_2 = sample(drop_index_1, k = 44)
data = data.drop(index = drop_index_2)
#重新设置索引
data.reset_index(drop=True, inplace=True)2.5.2 Exclua todos os itens que atendam às condições
data = data.drop(index = data[(data.反馈类型 == '其他')].index.tolist())3. Redefina o índice
data.reset_index(drop=True, inplace=True)4. Veja o número de categorias
for index,key_values in enumerate(data.联合分类.value_counts().items()):
print(index,key_values)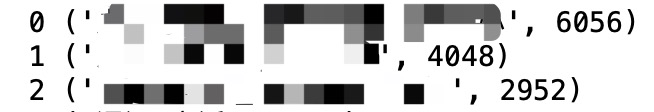
data['标注类型'].value_counts()![]()
5. atravessar dados
Obtenha os dados da linha especificada por meio de data.iloc[index].
content_list = []
label_list = []
for index in range(len(data)):
content = data.iloc[index]['内容']
label = data.iloc[index]['标注类型']
content_list.append(content)
label_list.append(label)6. Novos dados
new_data = pd.DataFrame()
new_data['content'] = content_list
new_data['label'] = label_list7. Estatísticas e rótulos definidos
Feedback_type = {}
for index,item in enumerate(list(new_data['label'].value_counts().keys())):
Feedback_type[item] = index
def add_Feedback_type_index(Feed_type):
index = Feedback_type.get(Feed_type)
return index
new_data['feedback_type_label'] = new_data['label'].apply(add_Feedback_type_index)8. Salve o arquivo de mapeamento
with open("Feedback_type.json", "w") as outfile:
json.dump(Feedback_type, outfile,ensure_ascii=False)9. Excel de geração de dados estatísticos
def Statistics(data):
keys = []
values = []
for key_values in (data):
keys.append(key_values[0])
values.append(key_values[1])
pkg_name_index_xlsx=pd.DataFrame()
pkg_name_index_xlsx['类目'] = keys
pkg_name_index_xlsx['数量'] = values
pkg_name_index_xlsx.to_excel(excel_writer= r"联合分类.xlsx")
Statistics(data.联合分类.value_counts().items())10. Armazene dados
#将合并的data存储
data.to_csv('./Total_data.csv',index = False,encoding='utf8')11. Amostragem negativa de dados
#统计联合分类中数量大于4000的类目
drop_element_list = []
for index,key_values in enumerate(data.联合分类.value_counts().items()):
if key_values[1] > 4000:
drop_element_list.append(key_values[0])
#对其删除1200条
from random import sample
def drop_element(data,drop_element_list):
for index in range(len(drop_element_list)):
element = drop_element_list[index]
result = 1200
drop_index_1 = data[(data.联合分类 == element)].index.tolist()
drop_index_2 = sample(drop_index_1, k=result)
data = data.drop(index = drop_index_2)
data.reset_index(drop=True, inplace=True)
return data
data = drop_element(data,drop_element_list)