O que acontece se
- Se houver dezenas de milhões de registros na tabela, esse problema de desempenho, e se houver outro campo de texto que precise ser configurado vagamente nela, isso causará sérios problemas de desempenho
- Ainda não é possível separar os termos de pesquisa. Por exemplo, o acima só pode pesquisar funcionários cujos nomes comecem com "Zhang San". Se você quiser pesquisar por "Zhang Xiaosan", não será possível pesquisar.
De modo geral, o uso de bancos de dados para implementar pesquisas não é muito confiável e geralmente o desempenho será ruim
Elasticsearch é um mecanismo de pesquisa (sistema de análise) de código aberto (distribuído)
é um mecanismo de pesquisa e análise de código aberto distribuído desenvolvido com base no Apache Lucene.
- Um armazenamento de documentos distribuído em tempo real, cada campo pode ser indexado e pesquisado
- Um mecanismo de pesquisa analítico distribuído em tempo real
- É capaz de expandir centenas de nós de serviço e suporta dados estruturados ou não estruturados em nível de PB
Elasticsearch é um mecanismo de busca moderno que oferece múltiplas funções, como armazenamento persistente e estatísticas
É um mecanismo de busca e um banco de dados [banco de dados não relacional], e não suporta transações e relacionamentos complexos (pelo menos a versão 1.X não suporta, 2.X melhorou, mas o suporte ainda não é bom)
Pesquisa de texto completo : O banco de dados de texto completo é o principal componente do sistema de pesquisa de texto completo. O chamado banco de dados de texto completo é uma coleção de dados formada pela transformação de todo o conteúdo de uma fonte de informação completa em unidades de informação que podem ser reconhecidas e processadas por um computador. Os bancos de dados de texto completo não apenas armazenam informações, mas também têm as funções de edição e processamento adicional de palavras, caracteres, parágrafos, etc. em dados de texto completo, e todos os bancos de dados de texto completo são bancos de dados de informações massivos.
Por exemplo : quando inserimos "desintegração total", ela será dividida em duas palavras "completa" e "desintegração". Use 2 palavras para recuperar dados no índice invertido e retornar os dados recuperados. Todo o processo é chamado de pesquisa de texto completo
Índice invertido : Encontre registros com base no valor do atributo. Como o valor do atributo não é determinado pelo registro, mas a localização do registro é determinada pelo valor do atributo, ele é chamado de índice invertido.
Cada entrada em tal tabela de índice inclui um valor de atributo e os endereços dos registros que possuem o valor do atributo.
Um arquivo com um índice invertido é chamado de arquivo de índice invertido ou, abreviadamente, arquivo invertido.
Lucene é um kit de ferramentas de mecanismo de pesquisa de código aberto (um pacote jar, que contém códigos empacotados para construção de índices invertidos e pesquisa, incluindo vários algoritmos). Solr também é um mecanismo de pesquisa distribuído de código aberto baseado em Lucene. Existem muitas semelhanças com o
Elasticsearch .
O Elasticsearch começou com pesquisa de texto completo e transformou o kit de desenvolvimento do Lucene em um produto de dados, protegendo várias configurações complexas do Lucene e fornecendo aos desenvolvedores uma conveniência amigável. Muitos bancos de dados relacionais tradicionais também fornecem pesquisa de texto completo, alguns baseados em Lucene incorporado, alguns baseados em desenvolvimento próprio, em comparação com Elasticsearch, a função é única, o desempenho não é muito bom e a escalabilidade é quase inexistente.
ES resolve esses problemas
1. Manutenção automática da distribuição de dados para o estabelecimento de índices em múltiplos nós, bem como a execução de solicitações de pesquisa distribuídas para vários nós
2. Manutenção automática de cópias redundantes de dados para garantir que os dados não serão perdidos quando a máquina cair 3.
Encapsula funções mais avançadas, como a função de análise de agregação e pesquisa baseada em localização geográfica
- Pode ser usado como uma tecnologia de cluster distribuído em grande escala (centenas de servidores) para processar dados em nível de PB e atender grandes empresas; também pode ser executado em uma única máquina para atender pequenas empresas
- Elasticsearch não é uma tecnologia nova, mas combina principalmente recuperação de texto completo, análise de dados e tecnologia distribuída.
- Para os usuários, é pronto para uso, muito simples, como um aplicativo de pequeno e médio porte, implemente o ES diretamente em 3 minutos
- Elasticsearch é um complemento aos bancos de dados tradicionais, como pesquisa de texto completo, processamento de sinônimos, classificação de correlação, análise de dados complexos e processamento quase em tempo real de dados massivos;
cenas a serem usadas
Iniciar um novo projeto usando o Elasticsearch como único armazenamento de dados pode ajudar a manter seu design o mais simples possível. No entanto, este cenário não suporta operações que envolvam atualizações e transações frequentes.
Um exemplo é o seguinte : Crie um novo sistema de blog e use es como armazenamento.
1) Podemos enviar novas postagens de blog para o ES;
2) Usar o ES para recuperar, pesquisar e contar dados.
Cenário 2: Adicionar Elasticsearch ao sistema existente
Como o ES não pode fornecer todas as funções de armazenamento, em alguns cenários é necessário adicionar suporte ao ES com base no armazenamento de dados do sistema existente.

Se você usar um banco de dados SQL e armazenamento ES conforme mostrado, precisará encontrar uma maneira 使得两存储之间实时同步. Você precisa selecionar o plug-in de sincronização correspondente de acordo com a composição dos dados e do banco de dados. Os plug-ins disponíveis incluem:
1) mysql, logstash-input-jdbcplug-ins de seleção do Oracle. 【Canal também está OK】
2) mongo seleciona a ferramenta mongo-connector
Consulta de aplicativo
Elasticsearch é melhor em consultas.Com base no algoritmo central do índice invertido, o desempenho da consulta é mais forte do que todos os produtos de dados do tipo B-Tree, especialmente o banco de dados relacional. Quando a quantidade de dados excede dezenas de milhões ou centenas de milhões, a eficiência da recuperação de dados é muito óbvia.
O Elasticsearch é usado em cenários de aplicativos de consulta geral. Os bancos de dados relacionais são limitados pelo princípio do lado esquerdo do índice. A execução do índice deve ter uma ordem estrita. Se houver poucos campos de consulta, você pode melhorar o desempenho da consulta criando um pequeno número de índices . Se houver muitos campos de consulta e os campos estiverem fora de ordem, o índice perde o significado; pelo contrário, o Elasticsearch cria índices para todos os campos por padrão, e todas as consultas de campo não precisam garantir a ordem, então usamos Elasticsearch em vez de bancos de dados relacionais para consultas gerais em um grande número de sistemas de aplicativos de negócios. As consultas de banco de dados são muito exclusivas. Exceto para as consultas mais simples, o Elasticsearch é usado para outras consultas de condições complexas.
No campo do big data,
o Elasticserach tornou-se um dos componentes importantes da plataforma de big data para fornecer consultas externas. A plataforma de big data calcula iterativamente os dados originais e, em seguida, envia os resultados para um banco de dados para consulta, especialmente para grandes lotes de dados detalhados. O famoso conjunto de três peças para recuperação de
logs refere-se a um portfólio de produtos especialmente projetado para coleta, armazenamento e consulta de logs. 5) Campo de monitoramento 6) Aprendizado de máquinaELKElasticsearch,Logstash,Kibana
Introdução básica aos componentes ES
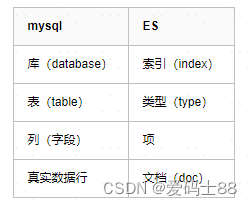
Metadados do Documento
Um documento contém não apenas seus dados, mas também metadados – informações sobre o documento. Os três elementos de metadados necessários são os seguintes:
_index Onde o documento está armazenado?
_type A categoria do objeto representada pelo documento
_id O identificador exclusivo do documento.
# ES é usado no springboot
- Introduzir dependências
em pom.xml, junte-sespring-boot-starter-data-elasticsearch
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- Escreva um arquivo de configuração
server:
port: 9001
es:
schema: http
address: 192.168.0.1:9200
connectTimeout: 10000
socketTimeout: 20000
connectionRequestTimeout : 50000
maxConnectNum: 16
maxConnectPerRoute: 20
- Classe de entidade:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "shen")
public class User {
@Id
private String id;
// 用在属性上 代表mapping中一个属性 一个字段 type:属性 用来指定字段类型 analyzer:指定分词器
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Text)
private Date bir;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String introduce;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String address;
}
- Insira um documento em es
/**
* ElasticSearch Rest client操作
*
* RestHighLevelClient 更强大,更灵活,但是不能友好的操作对象
* ElasticSearchRepository 对象操作友好
*
* 我们使用rest client 主要测试文档的操作
**/
// 复杂查询使用:比如高亮查询
@Autowired
RestHighLevelClient restHighLevelClient;
@Override
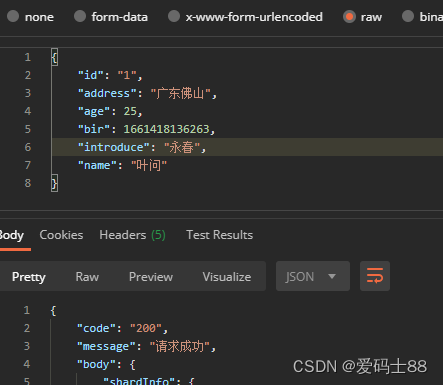
public ResponseInfo addUsers(User user) throws IOException {
IndexRequest indexRequest = new IndexRequest("shen");
indexRequest.source(JSONObject.toJSONString(user), XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
return ResponseInfo.ok(indexResponse);
}
- interface de chamada
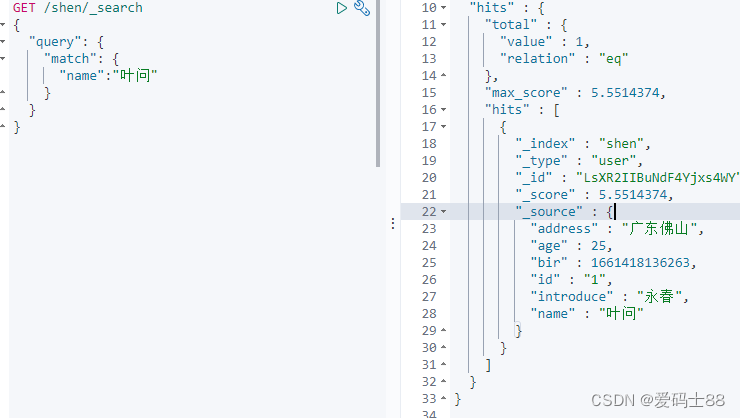
- Use kibana para visualizar os resultados em es:
/**
* 更新
*/
@Override
public ResponseInfo updateDoc(User user) throws IOException {
Document document = user.getClass().getAnnotation(Document.class);
UpdateRequest updateRequest = new UpdateRequest(document.indexName(), user.getId());
updateRequest.doc(JSONObject.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
return ResponseInfo.ok(updateResponse);
}
/**
* 删除
*/
@Override
public ResponseInfo deleteDoc(User user) throws IOException {
Document document = user.getClass().getAnnotation(Document.class);
DeleteRequest deleteRequest = new DeleteRequest(document.indexName(), user.getId());
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
return ResponseInfo.ok(deleteResponse);
}
/**
* 批量更新
*/
@Override
public void bulkUpdate() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
// 添加
IndexRequest indexRequest = new IndexRequest("shen");
indexRequest.source("{\"name\":\"张三\",\"age\":23,\"bir\":\"1991-01-01\",\"introduce\":\"西藏\",\"address\":\"拉萨\"}", XContentType.JSON);
bulkRequest.add(indexRequest);
// 删除
DeleteRequest deleteRequest01 = new DeleteRequest("shen","pYAtG3kBRz-Sn-2fMFjj");
DeleteRequest deleteRequest02 = new DeleteRequest("shen","uhTyGHkBExaVQsl4F9Lj");
DeleteRequest deleteRequest03 = new DeleteRequest("shen","C8zCGHkB5KgTrUTeLyE_");
bulkRequest.add(deleteRequest01);
bulkRequest.add(deleteRequest02);
bulkRequest.add(deleteRequest03);
// 修改
UpdateRequest updateRequest = new UpdateRequest("shen","pYAtG3kBRz-Sn-2fMFjj");
updateRequest.doc("{\"name\":\"曹操\"}",XContentType.JSON);
bulkRequest.add(updateRequest);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
BulkItemResponse[] items = bulkResponse.getItems();
for (BulkItemResponse item : items) {
System.out.println(item.status());
}
}
/**
* 查询
* @throws IOException
*/
@Test
public void testSearch() throws IOException {
//创建搜索对象
SearchRequest searchRequest = new SearchRequest("shen");
//搜索构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery())//执行查询条件
.from(0)//起始条数
.size(10)//每页展示记录
.postFilter(QueryBuilders.matchAllQuery()) //过滤条件
.sort("age", SortOrder.DESC);//排序
//创建搜索请求
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("符合条件的文档总数: "+searchResponse.getHits().getTotalHits());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
}