DDPM: Modelo Probabilístico de Difusão de Denoising, modelo de probabilidade de difusão de denoising
Referência neste artigo: Um vídeo para entender a derivação principal do modelo de difusão DDPM | Modelo subjacente de pintura de IA_哔哩哔哩_bilibili
1. Princípio geral
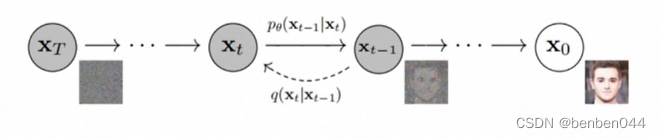
Da direita para a esquerda está o processo de adição de ruído direto e da esquerda para a direita
está o processo reverso de redução de ruído.
Adicionando continuamente ruído no processo de avanço, após T vezes , esperamos
Desta forma, durante a inferência, podemos retirar do aleatório
(adicionar 'para indicar que este é um novo valor).
Se pudermos aprender o método de redução de ruído, poderemos finalmente passar
a nova imagem.
2. O que prevê o método de redução de ruído do modelo de difusão
Agora é o método de redução de ruído que precisa ser aprendido . O algoritmo DDPM não é um método para aprender diretamente o valor previsto , mas a
distribuição de probabilidade condicional
prevista e, em seguida, o valor obtido tomando o valor da distribuição
. Este método é semelhante ao método de previsão profunda, pois as distribuições são previstas em vez de valores.
Então, por que prever distribuições em vez de valores exatos?
Como a distribuição pode ser amostrada , o modelo possui aleatoriedade.
Além disso, se você conseguir , poderá obtê-lo por amostragem , para que possa obtê-lo passo a passo . Portanto, o que queremos aprender é a distribuição de p, e não um gráfico exato.
Conclusão: Todo o processo de aprendizagem está prevendo a distribuição p .
Mais tarde veremos que o modelo está prevendo ruído, que não é o ruído entre e , mas o ruído envolvido no cálculo
da distribuição normal p .
Então, obtemos isso por previsão
e, em seguida, obtemos p. Também verificou a nossa conclusão, ou seja, todo o processo de aprendizagem está prevendo a distribuição p .
3. Desmontagem da distribuição de probabilidade condicional
Fórmula 1 :, a distribuição de probabilidade condicional original é transformada de acordo com a fórmula bayesiana e a nova fórmula contém 3 distribuições de probabilidade.
(1) Cálculo do primeiro p
O primeiro p é:
Da distribuição de probabilidade no processo de adição de ruído, porque o processo de adição de ruído é definido antecipadamente, a distribuição de probabilidade p também pode ser definida .
Agora definimos o processo de rampa da seguinte forma:
Equação 2 :,onde
o ruído
,.
Porque , então
. (ps: a variância precisa ser elevada ao quadrado)
Pode ser vista como a variância do ruído, ela precisa ser muito pequena perto de 0. Somente quando o ruído adicionado é pequeno, as direções para frente e para trás obedecem à distribuição normal.
Derivação adicional, , a saber:
Fórmula 3: .
(2) Cálculo do terceiro p
O terceiro p é: , que é semelhante ao segundo p. Se você encontrar um método de cálculo para um, o outro poderá ser obtido de forma semelhante.
Na etapa anterior, obtivemos a fórmula 2 de cada etapa do processo de adição de ruído, e a fórmula 3 da distribuição de probabilidade condicional de cada etapa de adição de ruído.
Para o processo de adição de ruído, portanto, pode
ser usado
.
Para modificar a fórmula 1:
Fórmula 4:
Como o processo de aquecimento é um processo de Markov, ele está relacionado apenas à etapa anterior, e não tem nada a ver com a etapa anterior, ou seja, a soma
não tem nada a ver, então
É obtido passo a
passo
, portanto nenhuma simplificação adicional é possível. Além disso, a Equação 4 simplifica para:
Fórmula 5 :
Agora comece a calcular o valor do novo terceiro p novamente e deduza-o da fórmula 2 da seguinte forma (ps: colchetes indicam que alguns parâmetros estão incluídos, mas não escritos, e informações sem importância são omitidas):
Finalmente, após uma derivação imprecisa, damos o resultado oficial:
Equação 6 :, que
representa a multiplicação contínua.
(3) Solução de fórmula de difusão
Se obtido na etapa anterior , também pode ser obtido de forma semelhante
.
O resultado oficial da fórmula 4 é dado diretamente:
Fórmula 7 :
Entre eles está o hiperparâmetro,
a fórmula é a seguinte:
Fórmula 8 :
Por ser fixa,
a tarefa de buscar torna-se busca
.
Se sim , então o valor de inferência previsto pode ser obtido de acordo com a seguinte fórmula:
Fórmula 9 :,
Se você retirar
, o processo não é derivável (inserindo diretamente o valor médio e o valor da variância por meio do pacote python), então há um problema com o processo reverso, então ele pode ser convertido para a fórmula 9 através da técnica de parâmetros pesados. Fórmula guiada para expressar
.
Na fase de inferência está o valor que queremos, que é desconhecido, portanto é necessária uma fórmula para converter em um fator conhecido.
A Equação 6 é transformada pela técnica de parâmetros pesados da seguinte forma:
Fórmula 10 :e, em seguida, obtenha:
Fórmula 11 :, onde t é o número atual de estágios de adição de ruído, que mudará. Ao mesmo tempo, este
é o valor do parâmetro do processo intermediário e não pode ser usado como o valor final previsto, porque o processo p de raciocínio precisa seguir o processo de Markov, portanto deve ser derivado passo a passo
.
Na Fórmula 7, o valor desconhecido é , e o valor desconhecido no valor é
, e
o valor desconhecido em é
, que não pode ser calculado e derivado por fórmulas existentes .
Então usamos a rede UNet, input , output
.
Substituindo a Equação 11 na Equação 8, obtemos:
Equação 12 : , onde entre
outras coisas são conhecidas.
É previsto pela rede UNet, que pode ser expresso como
um
parâmetro do modelo UNet.
*************O processo do modelo de difusão obtendo a imagem prevista através da rede UNet**************** :
O acima é a lógica mais importante do modelo de difusão DDPM .
4. Treinamento de modelo
De acordo com a Equação 12, pode-se observar que a rede UNet é treinada com ruído normalmente distribuído .
Pergunta 1: Qual é a entrada e a saída durante o treinamento do modelo?
Resposta: entrada , saída
.
Questão 2: Então qual processo realiza o treinamento dos parâmetros da rede UNet?
Resposta: o processo de adição de ruído. O processo de remoção de ruído é a fase de treinamento, e o processo de remoção de ruído é a fase de inferência.
De acordo com a fórmula 2, o ruído do processo de adição de ruído é definido pela implementação, para que possamos comparar o ruído previsto e a
divergência KL real para calcular o valor da perda.Na descrição oficial, a fórmula da divergência KL pode ser simplificada para calcular os dois O valor mse de um valor.
Pergunta 3: É deduzido passo a passo durante o treinamento?
Resposta: Não há necessidade. Durante o processo de treinamento , conforme fórmula 10 ,
pode ser calculado por
,,,, esses quatro valores.
Ele pode ser calculado antecipadamente e armazenado na memória,
que é o conjunto de imagens de entrada,
o ruído de entrada
e o número de estágios de adição de ruído.
Portanto, cada passo na direção direta pode obter o valor diretamente.
5. Implementação de pseudocódigo de treinamento e inferência
(1) Estágio de treinamento

Interpretação:
Representa tirar fotos do conjunto de dados
Indica que um número de estágios de adição de ruído é selecionado aleatoriamente. Como mencionado anteriormente, o processo de adição de ruído não precisa ser feito passo a passo.
para
(2) Estágio de raciocínio

Interpretação:
Isso significa que o processo inverso precisa ser feito passo a passo.
O cálculo complexo na etapa 4 corresponde à Equação 9, e a primeira fórmula do cálculo corresponde à Equação 12.