
1. Visão Geral
Este artigo analisa principalmente o sistema de recomendação, introduz principalmente a definição do sistema de recomendação, a estrutura básica do sistema de recomendação e apresenta brevemente os métodos e arquitetura relacionados da recomendação de design. É adequado para alguns alunos interessados no sistema de recomendação e para aqueles que possuem fundamentos relevantes.Meu nível é limitado e todos podem me corrigir.
2.Sistema de recomendação de mercadorias
2.1 Definição de sistema de recomendação
O sistema de recomendação resolve essencialmente o problema da sobrecarga de informações, ajuda os usuários a encontrar itens nos quais estão interessados e explora profundamente os interesses potenciais dos usuários.
2.2 Arquitetura Recomendada
Na verdade, o processo central do sistema de recomendação consiste apenas em recordar, classificar e reorganizar.
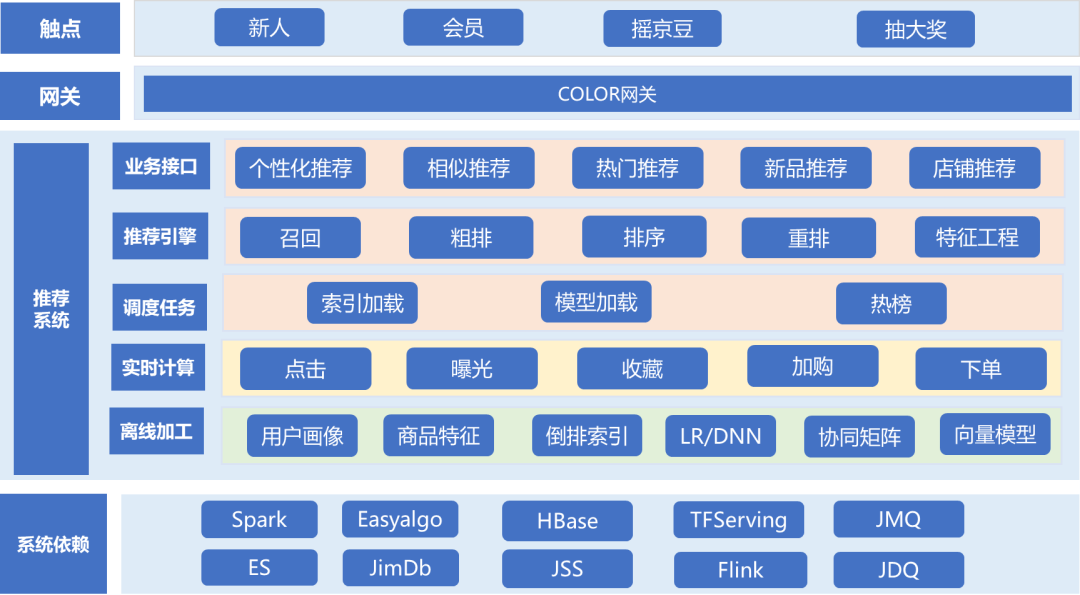
Processo de solicitação
Quando um usuário abre uma página, o front-end carrega as informações do usuário (pin ou uuid, etc.) para solicitar a interface de back-end (chamada indiretamente por meio de cor), e quando o back-end recebe a solicitação, ele irá geralmente primeiro divida e obtenha configurações de política relevantes de acordo com o ID do usuário (estratégia ab), essas estratégias determinam qual interface do módulo de recall, módulo de classificação e módulo de rearranjo será chamada a seguir. O módulo de recall geral é dividido em múltiplos recalls, sendo que cada recall é responsável por recall de múltiplos produtos, e a classificação e reorganização são responsáveis por ajustar a ordem desses produtos. Finalmente, o produto apropriado é selecionado e informações relevantes como preço e imagem são complementadas e exibidas ao usuário. Os usuários escolherão clicar ou não, dependendo de estarem interessados ou não.Esses comportamentos relacionados ao usuário serão relatados à plataforma de dados por meio de logs, estabelecendo a base para posterior análise de efeitos e recomendação de produtos usando o comportamento do usuário.
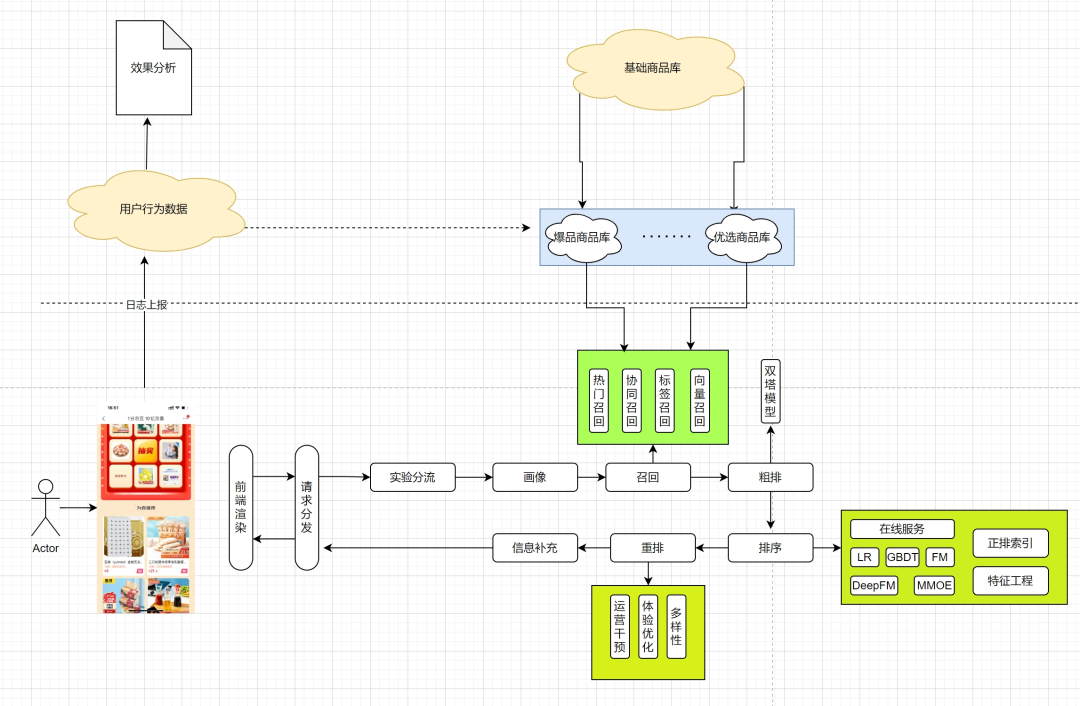
Na verdade, há algumas questões sobre as quais quero falar:
Por que adotar a hierarquia de funil de recall, classificação e reorganização?
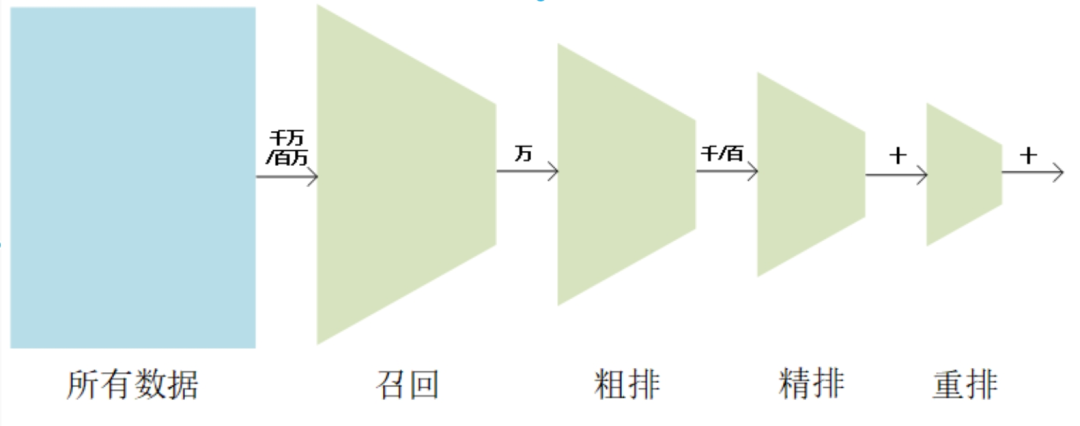
(1) Em termos de desempenho
Nível final: Na biblioteca de mercadorias de nível de milhão, selecione as mercadorias de nível de um dígito nas quais os usuários estão interessados.
A inferência online de modelos de classificação complexos é demorada e é necessário controlar rigorosamente o número de produtos que entram no modelo de classificação. precisa ser desmontado
(2) Do ponto de vista do alvo
Módulo de recall : A tarefa do módulo de recall é selecionar rapidamente alguns itens candidatos de um grande número de itens, com o objetivo de não perder itens que os usuários possam gostar. O módulo de recall geralmente adota recall multidirecional, usando alguns recursos ou modelos simplificados.
Módulo de classificação : A tarefa do módulo de classificação é classificar com precisão e classificar os itens candidatos selecionados pelo módulo de recall de acordo com o comportamento histórico, interesses, preferências e outras informações do usuário. Os módulos de classificação geralmente usam alguns modelos complexos.
Módulo de reclassificação : A tarefa do módulo de reclassificação é reclassificar ou ajustar os resultados do módulo de classificação para melhorar ainda mais a precisão e personalização das recomendações. Os módulos de rearranjo geralmente usam alguns algoritmos simples, mas eficazes.
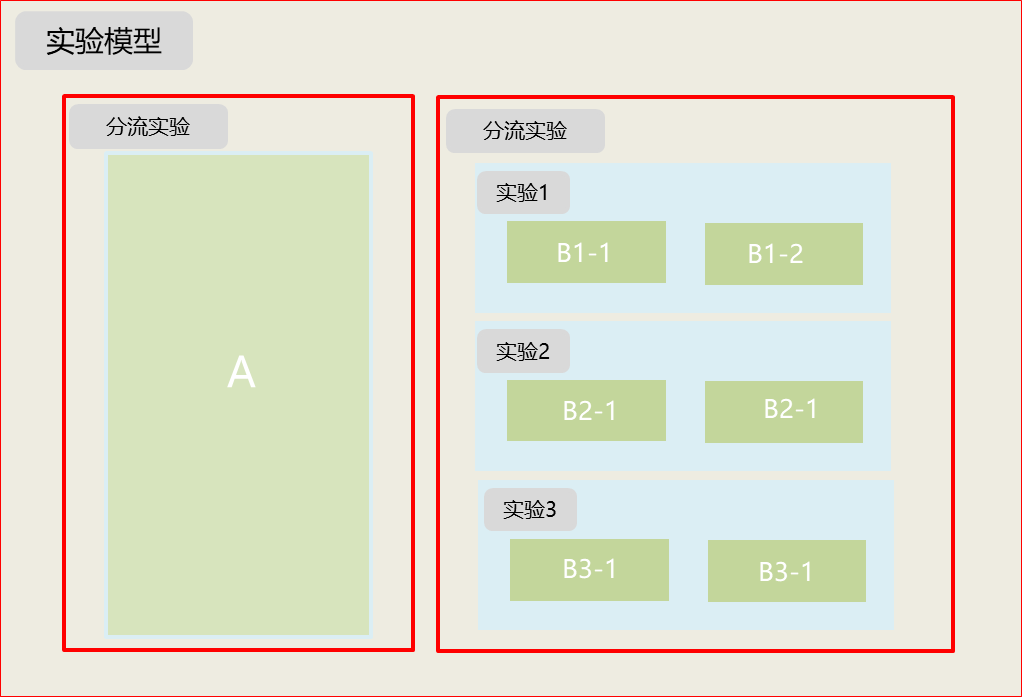
O que é um experimento abdominal?
Referência: Infraestrutura experimental sobreposta: experimentação mais, melhor e mais rápida (google2010)
Somente o experimento online pode realmente avaliar os prós e os contras do modelo, e o experimento ab pode verificar rapidamente o efeito do experimento e iterar rapidamente o modelo. Reduza o risco de lançar novos recursos.
algoritmo ab: Hash (uuid + id do experimento + carimbo de data / hora de criação)% 100
Características: Shunt + Ortogonal

2.3 Recuperação
A existência da camada de recall serve apenas para os usuários selecionarem inicialmente um lote de bons produtos do vasto conjunto de produtos. Para equilibrar a contradição entre a velocidade de cálculo e a taxa de recuperação (a proporção de amostras positivas para todas as amostras positivas), é adotada uma estratégia de recuperação de múltiplos caminhos, e cada estratégia de recuperação considera apenas uma única característica ou estratégia.
2.3.1 Vantagens e desvantagens da recuperação multicanal
Recuperação multidirecional: Use diferentes estratégias, recursos ou modelos simples para recuperar uma parte dos conjuntos de candidatos e, em seguida, misture os conjuntos de candidatos para classificação. A taxa de recuperação é alta, a velocidade é rápida e a recuperação multidirecional se complementa.
Na recuperação multicanal, o número K truncado de cada recuperação é um hiperparâmetro, que requer ajuste manual dos parâmetros e alto custo; há problemas de sobreposição e redundância nos canais de recuperação.
Se existe um tipo de recall que pode substituir o recall multicanal, o recall vetorial surgiu. Por enquanto, ainda é baseado no recall vetorial e outros recalls são complementados.
2.3.2 Classificação de recall
É dividido principalmente em duas categorias: recall não personalizado e recall personalizado. Os recalls não personalizados são principalmente para hot pushes, e o efeito Matthew no campo de recomendação é sério, com 20% dos produtos contribuindo com 80% dos cliques. O recall personalizado visa principalmente descobrir produtos nos quais os usuários estão interessados, focar em lidar com as diferenças de cada usuário, aumentar a diversidade de produtos e manter a aderência do usuário.
recall não personalizado
(1) Recalls populares: recall de produtos com muitos cliques, muitas curtidas e muitas vendas nos últimos 7 dias
(2) Recall de novos produtos: recall dos produtos mais recentes nas prateleiras
recall personalizado
(1) recall de rótulo, recall regional
Recall de rótulo: a categoria, marca, recall de loja, etc. em que o usuário está interessado
Recall regional: Faça recall de produtos de alta qualidade da região de acordo com a região do usuário.
(2) cf recordação
O algoritmo de filtragem colaborativa é baseado em dados de comportamento do usuário para extrair a preferência de comportamento do usuário, de modo a recomendar itens de acordo com a preferência de comportamento do usuário, que se baseia na matriz de comportamento (matriz de co-ocorrência) de usuários e itens. O comportamento do usuário geralmente inclui navegação, curtidas, compras adicionais, cliques, atenção, compartilhamento, etc.
A filtragem colaborativa é dividida em três categorias: filtragem colaborativa baseada no usuário (UCF), filtragem colaborativa baseada em itens (ICF) e filtragem colaborativa baseada em modelo (modelo semântico oculto). Para recomendar um item para um usuário, o usuário e o item devem primeiro ser associados, e se o ponto de associação é outro item ou outro usuário determina a qual tipo de filtragem colaborativa ele pertence. O modelo semântico oculto é baseado nos dados de comportamento do usuário para agrupar e explorar automaticamente as características de interesse potencial do usuário. Assim, usuários e itens são associados por meio de características de interesse latentes.
Filtragem Colaborativa Baseada em Item (ICF): Para determinar se deve recomendar um item a um usuário, primeiro infira o interesse do usuário no item com base na semelhança entre o item registrado no comportamento histórico do usuário e o item, de modo a determinar se recomendamos o item. Todo o processo de filtragem colaborativa é dividido principalmente nas seguintes etapas: cálculo da similaridade entre os itens, cálculo do interesse do usuário pelos itens, classificação e interceptação dos resultados.
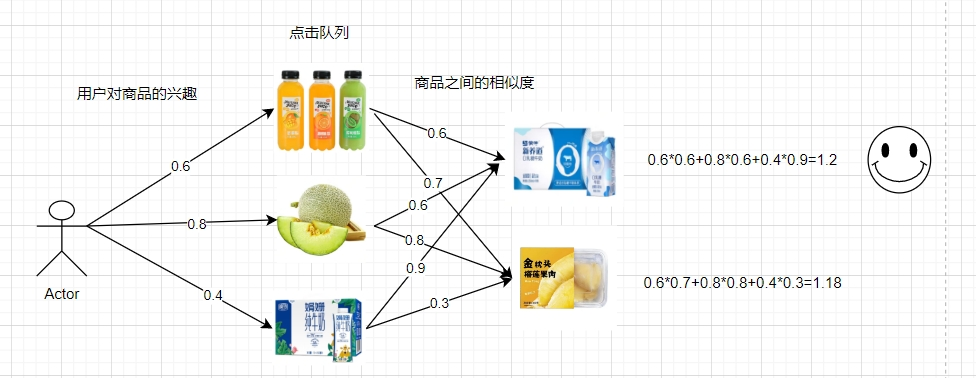
Cálculo de similaridade de commodities:
Existem principalmente as seguintes maneiras de medir a similaridade: distância do ângulo cosseno, fórmula de Jaccard. Devido à diversidade de representações de usuários ou itens, o cálculo destas semelhanças é muito flexível. Podemos usar a matriz de comportamento de usuários e itens para calcular a similaridade, e também podemos construir representações vetoriais de usuários e itens com base no comportamento do usuário, atributos do item e relações contextuais para calcular a similaridade.
Fórmula da distância do cosseno do ângulo:
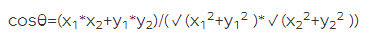
Fórmula de Jaccard J(A,B)=(|A⋂B|)/(|A⋃B|)
| Mercadoria um |
Mercadoria b | Mercadoria c | Mercadoria d | |
| Usuário A |
1 |
0 |
0 | 1 |
| Usuário B | 0 |
1 | 1 |
0 |
| Usuário C | 1 |
0 | 1 |
1 |
| Usuário D | 1 |
1 | 0 |
0 |
A fórmula da distância do cosseno do ângulo incluído calcula a semelhança entre as mercadorias a e b:
Wab=(1*0+0*1+1*0+1*1)/(√(1^2+0^2+1^2+1^2 )*√(0^2+1^2+ 0^2+1^2 ))=1/√6
Spark implementa ICF: https://zhuanlan.zhihu.com/p/413159725
Problema: problema de partida a frio, efeito de cauda longa.
(3) Recuperação de vetores
Recuperação vetorizada: ao aprender a representação vetorizada de baixa dimensão de usuários e itens, a recordação é modelada como um problema de busca vizinha no espaço vetorial, o que efetivamente melhora a capacidade de generalização e a diversidade da recordação, e é o principal canal de recordação do mecanismo de recomendação.
Vetor: tudo pode ser vetorizado. Incorporar é usar um vetor denso de baixa dimensão para representar um objeto (palavra ou mercadoria). A principal função é converter um vetor esparso em um vetor denso (o efeito da redução da dimensionalidade). A representação aqui contém certo significado profundo, de modo que pode expressar uma parte das características do objeto, e a distância entre os vetores reflete a semelhança entre os objetos.
Etapa de recuperação de vetores: treinamento offline para geração de vetores, recuperação de vetores online.
1. Treinamento offline para geração de vetores
word2vec: O originador do vetor de palavras consiste em três camadas de rede neural: camada de entrada, camada oculta, camada de saída, camada oculta não tem função de ativação e a camada de saída usa softmax para calcular a probabilidade.
função objetiva
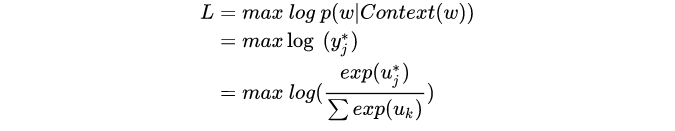
Estrutura da rede:
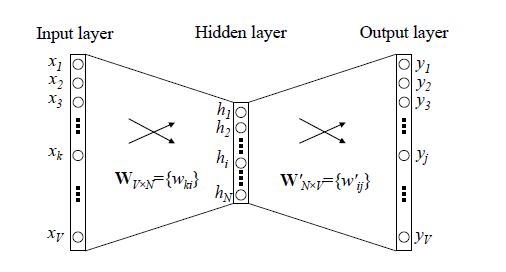
Em geral: a entrada é uma sequência de palavras, e o vetor correspondente a cada palavra pode ser obtido após o treinamento do modelo. A aplicação no campo de recomendação é inserir a sequência de cliques do usuário, e obter o vetor de cada produto através do treinamento do modelo.
Prós e contras: Simples e eficiente, mas apenas sequências de comportamento são consideradas e outros recursos não são considerados.
Modelo Torres Gêmeas:
Estrutura de rede: respectivamente chamada de User Tower e Item Tower; a User Tower recebe recursos do lado do usuário como entrada, como ID do usuário, sexo, idade, categorias de interesse de terceiro nível, sequência de cliques do usuário, endereço do usuário, etc.; a Item Tower aceita recursos do lado do produto, como ID do produto, ID da categoria, preço, volume de pedidos nos últimos três dias, etc. Treinamento de dados: (dados de amostra positivos, 1) (amostra negativa, 0) amostra positiva: o produto clicado, amostra negativa: amostra aleatória global do produto (ou outras amostras de clique do usuário no mesmo lote)
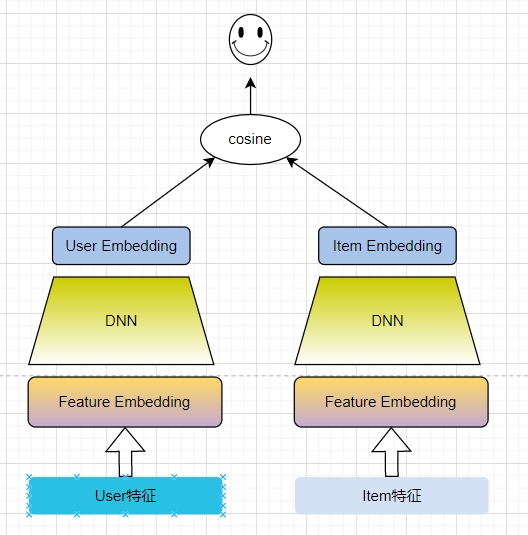
Prós e Contras: Eficiente, ajuste perfeito ao recurso de recall, solicitação on-line para obter o vetor do usuário, recuperar e recuperar o vetor do item, alta generalização; a torre do usuário e a torre do item são separadas e só interagem no final.
2. Recuperação de vetores on-line
Recuperação vetorial: É um método de recuperação de informações baseado no Modelo de Espaço Vetorial, que é usado para encontrar rapidamente o vetor de documento mais semelhante ao vetor de consulta em uma coleção de texto em grande escala. É amplamente utilizado na recuperação de informações, sistema de recomendação e classificação de textos.
O processo de recuperação de vetores consiste em calcular a similaridade entre os vetores e, finalmente, retornar o vetor TopK com maior similaridade, e há muitas maneiras de calcular a similaridade de vetores. Os métodos para calcular a similaridade vetorial incluem distância euclidiana, produto interno e distância do cosseno. Após a normalização, o produto interno é equivalente à fórmula de cálculo de similaridade de cosseno.
A essência da recuperação de vetores é a Pesquisa Aproximada de Vizinhos (ANNS), que reduz ao máximo o intervalo de pesquisa do vetor de consulta, melhorando assim a velocidade da consulta.
Os algoritmos de recuperação de vetores usados atualmente em larga escala na indústria podem ser basicamente divididos nas três categorias a seguir:
Hashing sensível à localidade (LSH)
Baseado em gráfico (HNSW)
Quantização baseada em produto
Uma breve introdução ao LSH
A ideia central do algoritmo LSH é: depois de transformar dois pontos de dados adjacentes no espaço de dados original por meio do mesmo mapeamento ou projeção, a probabilidade de que esses dois pontos de dados ainda sejam adjacentes no novo espaço de dados é muito alta, e eles não estão relacionados. A probabilidade de pontos de dados adjacentes serem mapeados para o mesmo intervalo é muito pequena.
Em comparação com a pesquisa de força bruta para percorrer todos os pontos no conjunto de dados e usando hash, primeiro descobrimos em qual intervalo a amostra de consulta se enquadra. Se a divisão do espaço for dividida pela medida de similaridade que desejamos, a amostra de consulta O vizinho mais próximo de provavelmente cairá no intervalo da amostra de consulta, portanto, só precisamos percorrer e comparar no intervalo atual, em vez de percorrer todos os conjuntos de dados. Quando o número de funções hash H é muito grande, a possibilidade de a amostra de consulta e seu vizinho mais próximo correspondente cairem no mesmo balde se tornará muito fraca. Para resolver este problema, podemos repetir este processo L vezes (cada vez é um hash diferente função), aumentando assim a taxa de recuperação do vizinho mais próximo.
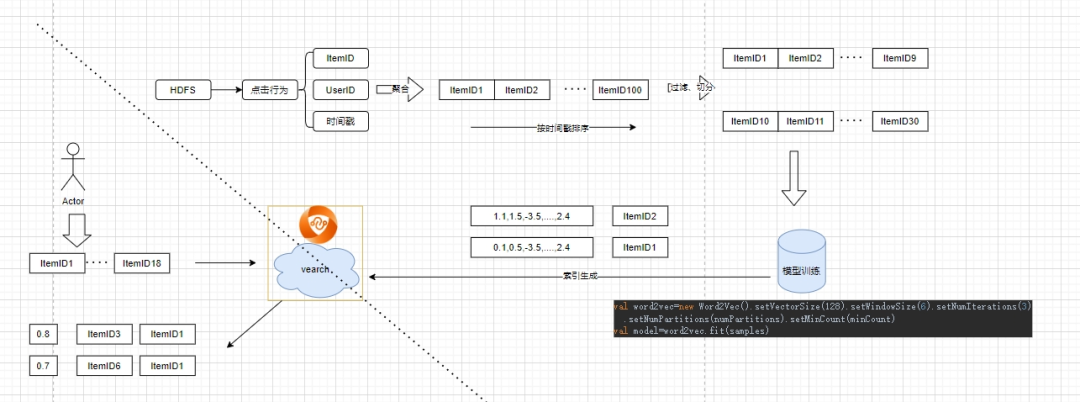
Caso: recuperação de vetor com base em word2vec
2.4 Classificação
A menina dos olhos para sistemas de recomendação
O estágio de classificação é dividido em classificação aproximada e classificação fina. A classificação aproximada geralmente ocorre quando a magnitude dos dados dos resultados da recuperação é relativamente grande.
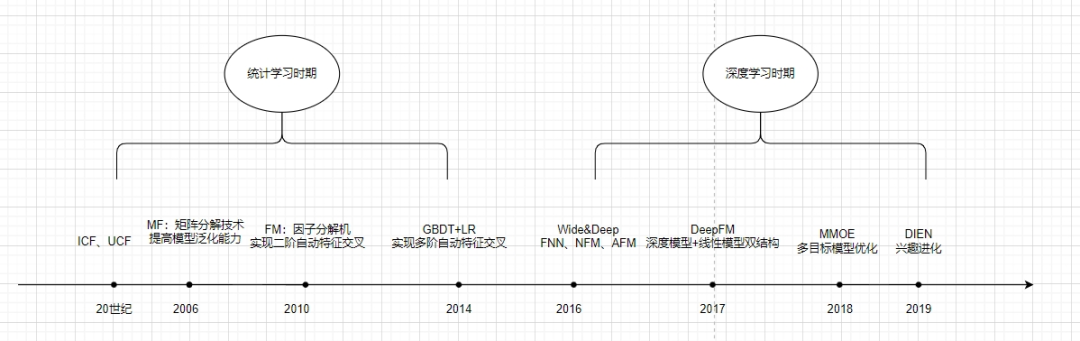
Evolução
Uma breve introdução ao Wide&Deep
Antecedentes : O efeito de memória da combinação manual de recursos é bom, mas a engenharia de recursos é muito trabalhosa e as combinações de recursos que não apareceram antes não podem ser memorizadas e não podem ser generalizadas.
Objetivo : Fazer com que o modelo leve em consideração tanto a generalização quanto a capacidade de memória (uso eficaz de informações históricas e forte capacidade expressiva)
(1) O modelo de capacidade de memória aprende diretamente e usa a capacidade da frequência de co-ocorrência de itens ou recursos em dados históricos para memorizar as características de distribuição dos dados históricos. O modelo simples pode facilmente encontrar os recursos ou recursos combinados nos dados que tem um impacto maior nos resultados e ajusta seu peso para obter memória para recursos fortes
(2) A capacidade de generalização do modelo transfere a correlação de recursos e a capacidade de explorar a correlação entre recursos esparsos ou raros e o rótulo final.Mesmo uma entrada de vetor de recursos muito esparsa pode obter uma probabilidade de recomendação estável e suave. Exemplos de generalização melhorada: fatoração de matrizes, redes neurais
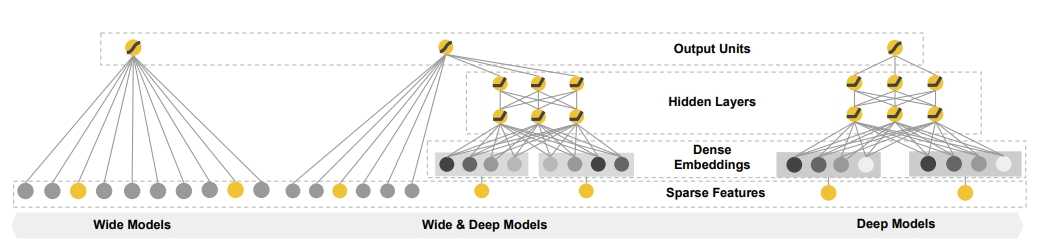
Com base nos recursos de memória e generalização (precisão e escalabilidade dos resultados), a parte ampla concentra-se na memória do modelo, processando rapidamente um grande número de características de comportamento histórico, a parte profunda concentra-se na generalização do modelo, explorando novos mundos, a correlação de transferência de modelo recursos e escassez de mineração A capacidade de correlacionar até mesmo recursos raros e remotos com o rótulo final é poderosamente expressiva. Finalmente, a parte larga e a parte profunda são combinadas para formar um modelo unificado.
A parte larga é o modelo linear básico, expresso como y=W^T X+b A parte do recurso X inclui recursos básicos e recursos cruzados. O recurso cruzado é muito importante na parte ampla, que pode capturar a interação entre os recursos e desempenhar o papel de adicionar não linearidade.
A parte profunda é a incorporação de camada + rede neural de três camadas (relu), fórmula feed-forward
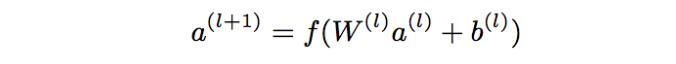
treinamento conjunto
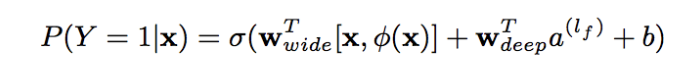
Prós e contras: lançou uma base importante para o desenvolvimento de algoritmos de recomendação/publicidade/classificação de pesquisa e saltou dos algoritmos tradicionais para algoritmos de aprendizagem profunda, o que é um marco. Levando em consideração os recursos de memória e generalização, o lado amplo ainda precisa combinar recursos manualmente.
Artigo de referência: Aprendizado amplo e profundo para sistemas de recomendação
2.5 Reorganização
Definição: Ajustar a ordem dos resultados após o ajuste fino, por um lado para alcançar a otimização global, por outro lado para atender às demandas de negócios e melhorar a experiência do usuário. Por exemplo, estratégia dispersa, estratégia de inserção forte, aumento de exposição, filtragem sensível
Algoritmo MMR
Alcançando a diversidade de produtos
Objetivo: Garantir a diversidade dos resultados das recomendações e, ao mesmo tempo, garantir a precisão dos resultados das recomendações, a fim de equilibrar a diversidade e a relevância dos resultados das recomendações
Princípios de algoritmo, como fórmulas
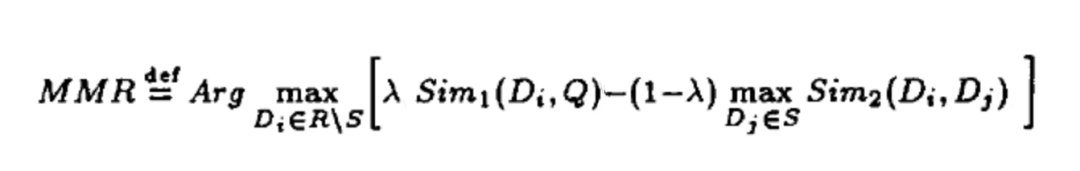
D: coleção de produtos, Q: usuário, S: coleção de produtos selecionados, R\S: coleção de produtos não selecionados em R
def MMR(itemScoreDict, similarityMatrix, lambdaConstant=0.5, topN=20):
#s 排序后列表 r 候选项
s, r = [], list(itemScoreDict.keys())
while len(r) > 0:
score = 0
selectOne = None
# 遍历所有剩余项
for i in r:
firstPart = itemScoreDict[i]
# 计算候选项与"已选项目"集合的最大相似度
secondPart = 0
for j in s:
sim2 = similarityMatrix[i][j]
if sim2 > second_part:
secondPart = sim2
equationScore = lambdaConstant * (firstPart - (1 - lambdaConstant) * secondPart)
if equationScore > score:
score = equationScore
selectOne = i
if selectOne == None:
selectOne = i
# 添加新的候选项到结果集r,同时从s中删除
r.remove(selectOne)
s.append(selectOne)
return (s, s[:topN])[topN > len(s)]O significado é selecionar um item que seja mais relevante para o usuário e menos relevante para o item selecionado. A complexidade do tempo O(n2) pode reduzir a complexidade do tempo, limitando o número de escolhas
Implementação de engenharia: A correlação entre usuários e itens e a similaridade entre itens são necessárias como entrada. A correlação entre usuários e itens pode ser substituída pelos resultados do modelo de classificação, e a similaridade entre itens pode ser obtida por meio de algoritmos como filtragem colaborativa .Vetor de mercadorias, para calcular a distância do cosseno. Também pode ser tão simples quanto ser representado pela mesma categoria de terceiro nível ou pela mesma loja.
3. Resumo
Isso é tudo para uma breve conversa. Quero que todos entendam o sistema de recomendação e apresentem toda a arquitetura de recomendação e os módulos de toda a recomendação. Devido ao meu nível limitado, não expliquei detalhadamente cada módulo, espero poder continuar a estudar esta área em meu trabalho, aprofundar-me nos detalhes e produzir coisas melhores para todos.
-fim-