Introdução:
No trabalho e estudo diários, podemos precisar encontrar e extrair conteúdo específico em arquivos PDF. Este artigo apresentará como implementar uma ferramenta simples de pesquisa de conteúdo PDF usando a linguagem de programação Python e a biblioteca de interface gráfica do usuário wxPython. Usaremos o módulo PyMuPDF para processar arquivos PDF e combinar wxPython para construir uma interface amigável.
C:\pythoncode\new\pdffindcontent.py
Preparação
Antes de começar, certifique-se de ter instalado o Python e os módulos correspondentes. Você pode usar o pip para instalar os módulos wxPython e PyMuPDF. Para métodos de instalação específicos, consulte a documentação oficial.
Crie uma interface GUI
Primeiro, precisamos criar uma interface GUI para que os usuários selecionem arquivos PDF para pesquisar e inserir o que procuram. Usamos a biblioteca wxPython para criar a interface.
def __init__(self, parent, title):
super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
# 选择文件按钮
file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST)
file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected)
vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10)
# 输入框和按钮
hbox = wx.BoxSizer(wx.HORIZONTAL)
self.search_text = wx.TextCtrl(panel)
search_button = wx.Button(panel, label='搜索')
search_button.Bind(wx.EVT_BUTTON, self.on_search)
hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5)
hbox.Add(search_button, 0, wx.ALL, 5)
vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10)
# 显示框
self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY)
vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10)
panel.SetSizer(vbox)
self.Show()
No código acima, criamos uma PDFSearchFrameclasse de janela chamada, que herda da wx.Frameclasse wxPython. No construtor desta classe, criamos vários componentes da interface, incluindo o botão de seleção de arquivo, a caixa de entrada e o botão de pesquisa, e a caixa de exibição.
Pesquisa e extração de conteúdo PDF
Em seguida, precisamos adicionar a funcionalidade de pesquisa e extração de conteúdo PDF ao código. Usaremos o módulo PyMuPDF para processar arquivos PDF.
# 导入所需模块
import wx
import fitz
def on_search(self, event):
search_text = self.search_text.GetValue()
if not search_text or not self.pdf_path:
return
doc = fitz.open(self.pdf_path)
matches = []
for page in doc:
text = page.get_text().lower()
if search_text.lower() in text:
matches.append((page.number, text))
self.display_text.SetValue('')
if matches:
for page_num, text in matches:
self.display_text.AppendText(f"Page {
page_num}:\n{
text}\n\n")
else:
self.display_text.AppendText("未找到匹配的内容。")
doc.close()
No código acima, adicionamos on_searcho código de busca e extração de conteúdo PDF no método. Primeiro, usamos fitz.opena função para abrir o arquivo PDF selecionado e percorrer o conteúdo de texto de cada página. Em seguida, convertemos o conteúdo do texto para minúsculas e verificamos se o texto da pesquisa está lá. Se forem encontradas correspondências adequadas, nós as armazenamos em matchesuma lista. Finalmente, exibimos os resultados correspondentes na caixa de exibição e, se nenhum conteúdo correspondente for encontrado, as informações de prompt correspondentes serão exibidas.
todos os códigos
import wx
import fitz
class PDFSearchFrame(wx.Frame):
def __init__(self, parent, title):
super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
# 选择文件按钮
file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST)
file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected)
vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10)
# 输入框和按钮
hbox = wx.BoxSizer(wx.HORIZONTAL)
self.search_text = wx.TextCtrl(panel)
search_button = wx.Button(panel, label='搜索')
search_button.Bind(wx.EVT_BUTTON, self.on_search)
hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5)
hbox.Add(search_button, 0, wx.ALL, 5)
vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10)
# 显示框
self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY)
vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10)
panel.SetSizer(vbox)
self.Show()
def on_file_selected(self, event):
self.pdf_path = event.GetPath()
def on_search(self, event):
search_text = self.search_text.GetValue()
if not search_text or not self.pdf_path:
return
doc = fitz.open(self.pdf_path)
matches = []
for page in doc:
text = page.get_text().lower()
if search_text.lower() in text:
matches.append((page.number, text))
self.display_text.SetValue('')
if matches:
for page_num, text in matches:
self.display_text.AppendText(f"Page {
page_num}:\n{
text}\n\n")
else:
self.display_text.AppendText("未找到匹配的内容。")
doc.close()
if __name__ == '__main__':
app = wx.App()
PDFSearchFrame(None, title="PDF搜索")
app.MainLoop()
execute o programa
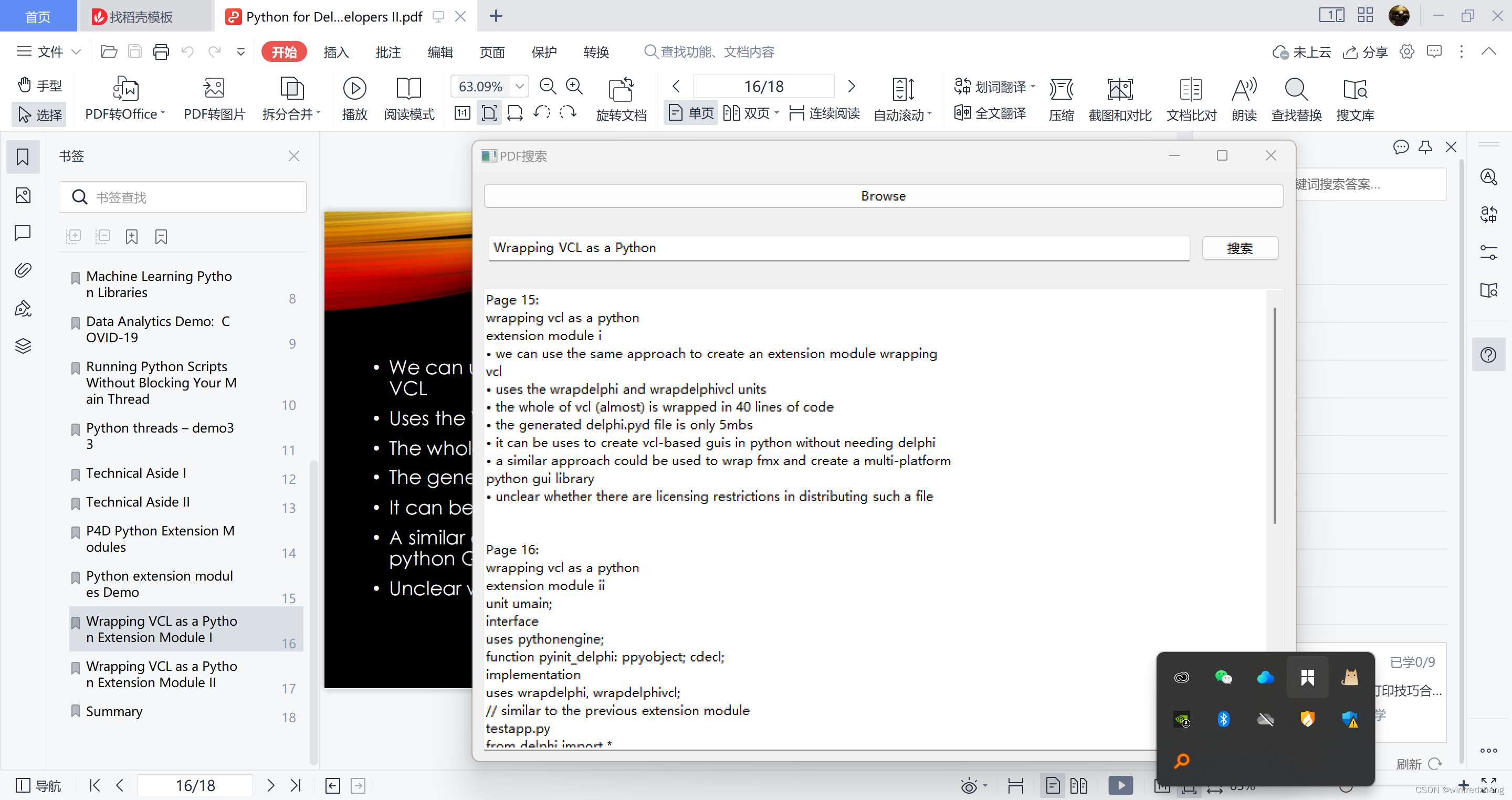
Após concluir as etapas acima, podemos salvar e executar o programa. Uma janela com uma ferramenta de pesquisa de conteúdo PDF com funcionalidade de pesquisa aparecerá. Podemos selecionar o arquivo PDF para pesquisar, inserir o conteúdo que queremos encontrar e clicar no botão de pesquisa. O programa exibirá os resultados correspondentes na caixa de exibição, incluindo o número da página encontrada e o conteúdo do texto correspondente.
Resumo:
Este artigo apresenta como usar a biblioteca Python e wxPython para implementar uma ferramenta simples de pesquisa de conteúdo PDF. Combinando o módulo PyMuPDF e a interface gráfica wxPython, podemos selecionar facilmente o arquivo PDF e inserir o conteúdo que queremos encontrar na caixa de entrada. O programa procurará o conteúdo correspondente e extrairá o conteúdo da página encontrado na caixa de exibição. Esta ferramenta pode nos ajudar a encontrar e extrair rapidamente conteúdo específico em arquivos PDF e melhorar a eficiência do trabalho.
Palavras-chave: Python, wxPython, PDF, pesquisa de conteúdo, PyMuPDF