Escreva o título do diretório aqui
- 1. Introdução ao XML
- 2. Sintaxe XML
-
- 2.1. Declaração do documento
- 2.2. Comentários XML
- 2.3. Elementos (rótulos)
- 2.4, atributos xml
- 3.5. Regras gramaticais:
-
- 3.5.1 Todos os elementos XML devem ter uma tag de fechamento (ou seja, um fechamento)
- 3.5.2 As tags XML diferenciam maiúsculas de minúsculas
- 3.5.3 XML deve estar devidamente aninhado
- 3.5.4 Documentos XML devem ter um elemento raiz
- 3.5.5 Valores de atributos XML devem ser citados
- 3.5.6 Caracteres especiais em XML
- 3.5.7 Área de texto (área CDATA)
- 4. Introdução à tecnologia de análise xml
1. Introdução ao XML
1.1 O que é XML?
xml é uma linguagem de marcação extensível.
1.2 Qual é o papel do xml?
As principais funções do xml são:
1. É usado para salvar dados, e esses dados são autodescritivos
. 2. Também pode ser usado como um arquivo de configuração de projeto ou módulo
. 3. Também pode ser usado como um formato para dados de transmissão de rede (agora JSON é o formato principal) .
2. Sintaxe XML
- Declaração de documentação.
- elemento (rótulo)
- atributo xml
- comentário xml
- Área de texto (área CDATA)
2.1. Declaração do documento
Vamos começar criando um arquivo XML simples para descrever as informações do livro.
- 1. Crie um arquivo xml
<?xml version="1.0" encoding="utf-8" ?>
<!-- xml声明 version是版本的意思 encoding是编码 -->
<books> <!-- 这是xml注释 -->
<book id="SN123123413241"> <!-- book标签描述一本图书 id属性描述 的是图书 的编号 -->
<name>java编程思想</name> <!-- name标签描述 的是图书 的信息 -->
<author>华仔</author> <!-- author单词是作者的意思 ,描述图书作者 -->
<price>9.9</price> <!-- price单词是价格,描述的是图书 的价格 -->
</book>
<book id="SN12341235123"> <!-- book标签描述一本图书 id属性描述 的是图书 的编号 -->
<name>葵花宝典</name> <!-- name标签描述 的是图书 的信息 -->
<author>班长</author> <!-- author单词是作者的意思 ,描述图书作者 -->
<price>5.5</price> <!-- price单词是价格,描述的是图书 的价格 -->
</book>
</books>
- 2. A
versão do atributo é a codificação do número da versão
é a codificação do arquivo xml
standalone="yes/no" indica se o arquivo xml é um arquivo xml independente - 3. O atributo id do livro indica a identificação única, título, autor e informações de preço
2.2. Comentários XML
Os comentários html e XML são os mesmos:<!-- html 注释-->
2.3. Elementos (rótulos)
Vamos relembrar primeiro:
tags html:
格式:<标签名>封装的数据</标签名>
单标签: <标签名/> <br /> 换行 <hr />水平线
双标签<标签名>封装的数据</标签名>
Os nomes das tags não diferenciam maiúsculas de minúsculas
. As tags têm atributos, incluindo atributos básicos e atributos de evento.
As tags devem ser fechadas (se não forem fechadas, nenhum erro será relatado no html. Mas devemos desenvolver bons hábitos de escrita. Fechado)
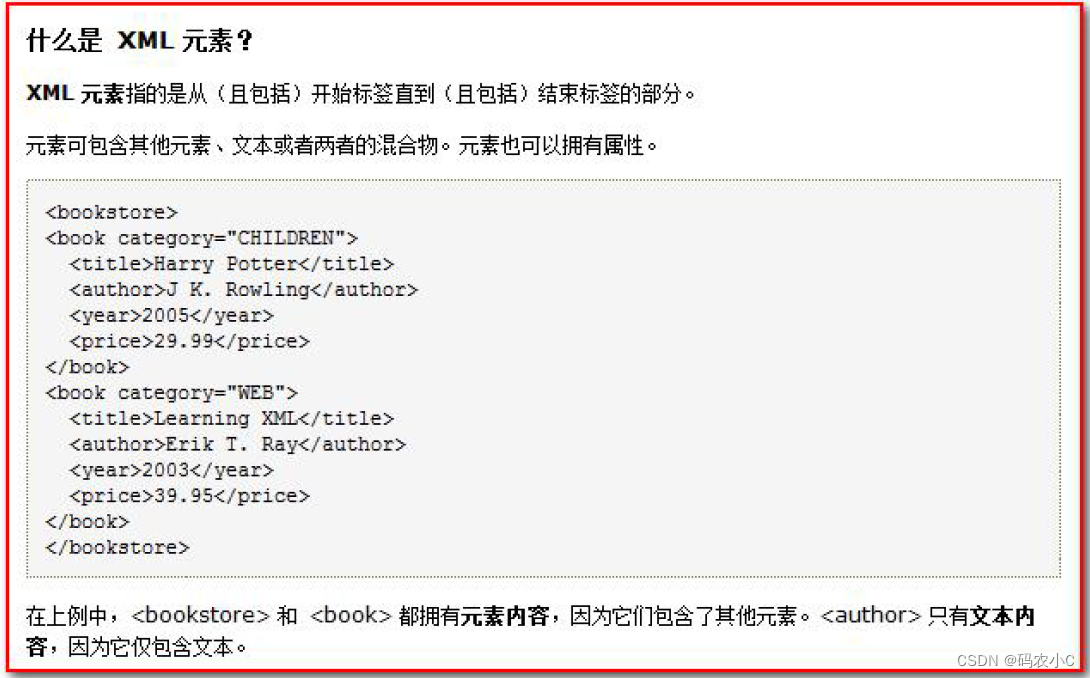
2.3.1. O que é um elemento xml
Um elemento é o conteúdo da tag de abertura até a tag de fechamento.
Por exemplo: <title>java 编程思想</title>
Os elementos podem ser simplesmente entendidos como rótulos.
Elemento de tradução do elemento
2.3.2, regras de nomenclatura XML
Os elementos XML devem seguir as seguintes convenções de nomenclatura:
- 1) O nome pode conter letras, números e outros caracteres
Por exemplo:
<book id="SN213412341"> <!-- 描述一本书-->
<author>班导</author> <!-- 描述书的作者信息-->
<name>java 编程思想</name> <!-- 书名-->
<price>9.9</price> <!-- 价格-->
</book>
-
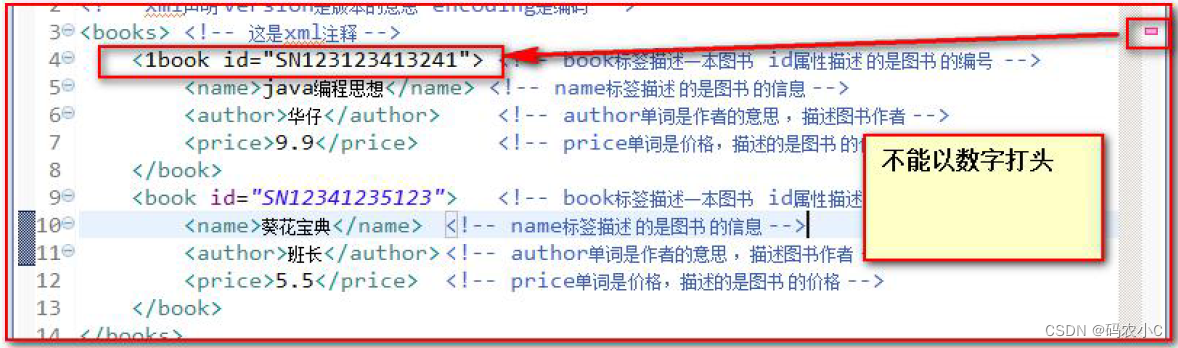
2) O nome não pode começar com um número ou pontuação
-
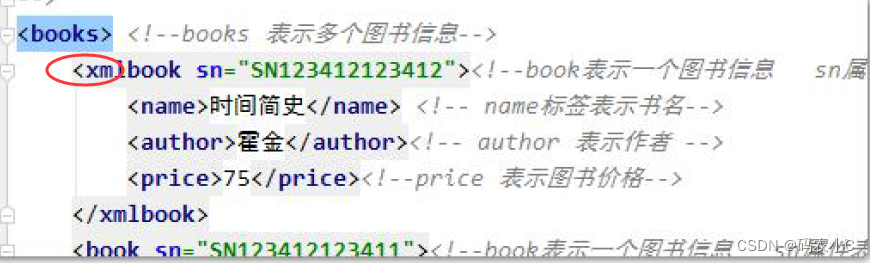
3) O nome não pode começar com os caracteres "xml" (ou XML, Xml) (mas funciona)
-
4) O nome não pode conter espaços
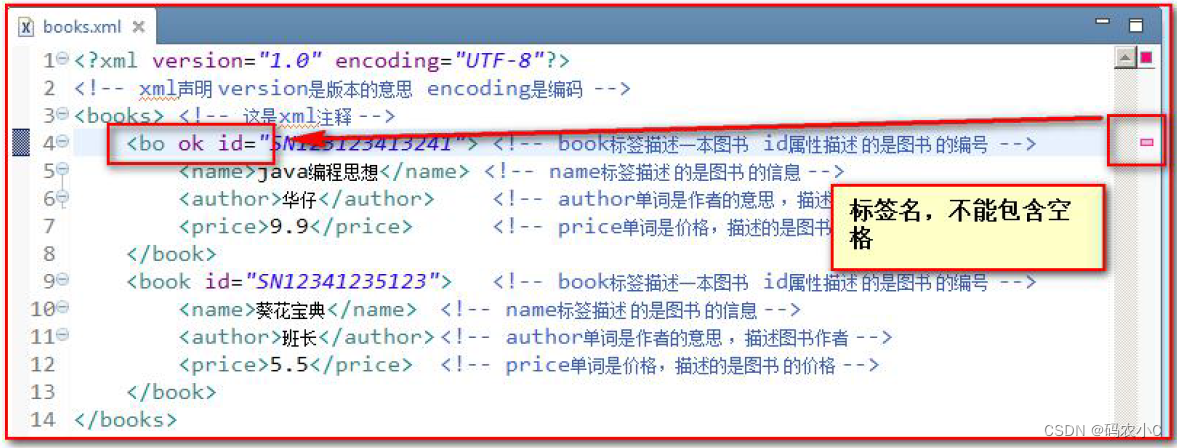
2.3.2. Os elementos (tags) no xml também são divididos em tags simples e duplas:
Formato de tag única
: <tag name attribute=”value” attribute=”value” … /> Formato
de tag dupla
: <tag name attribute=”value” attribute=”value”…>dados de texto ou subtag</nome da tag>
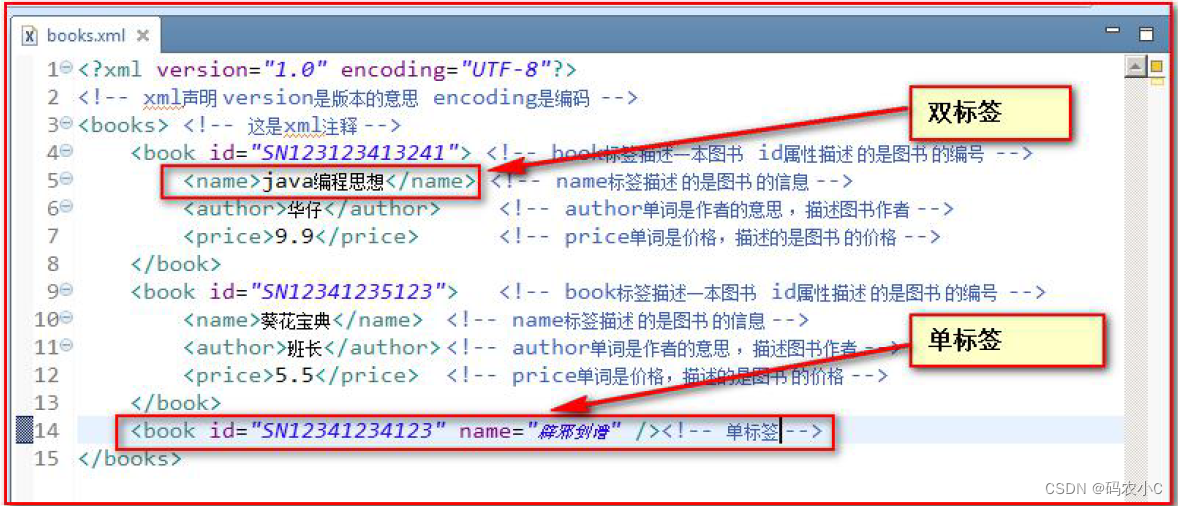
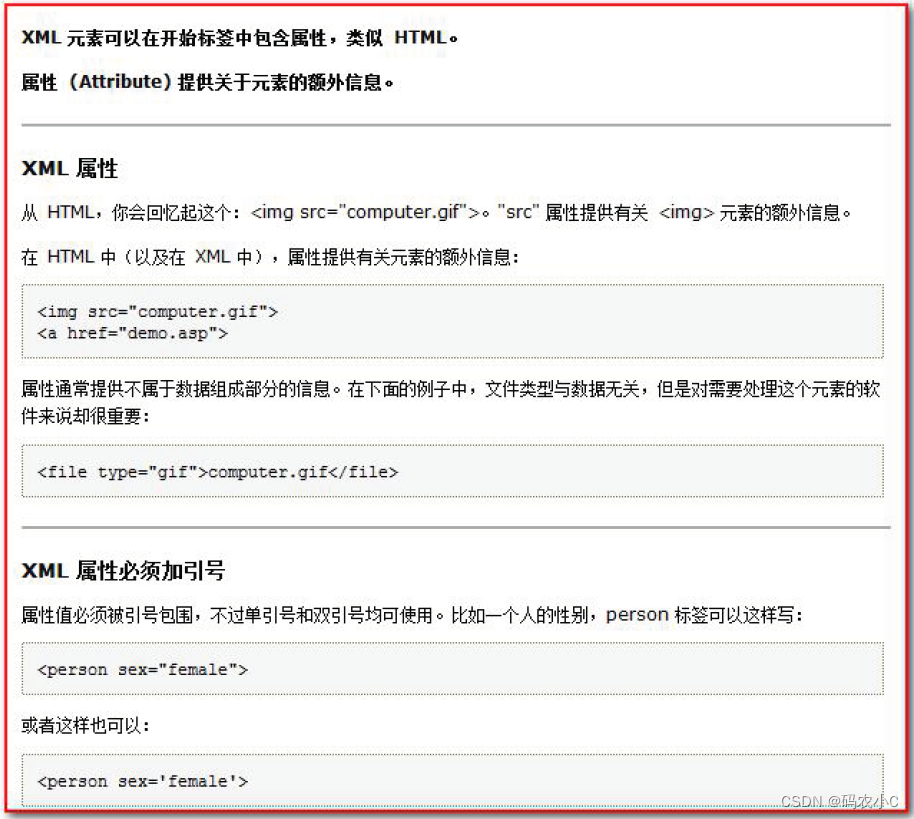
2.4, atributos xml
O atributo tag do xml é muito semelhante ao atributo tag do html. O atributo pode fornecer informações adicionais do elemento. Os atributos
podem ser escritos na tag:
vários atributos podem ser escritos em uma tag. O valor de cada atributo deve ser colocado entre aspas.
As regras são as mesmas que as regras de escrita para rótulos.
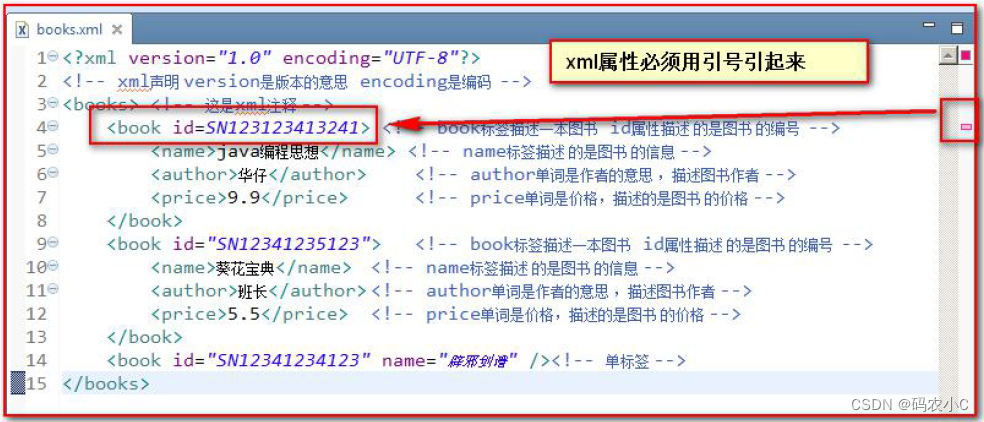
2.4.1. Os atributos devem ser colocados entre aspas. Se não forem citados, será reportado um erro. Exemplo de código
3.5. Regras gramaticais:
3.5.1 Todos os elementos XML devem ter uma tag de fechamento (ou seja, um fechamento)

3.5.2 As tags XML diferenciam maiúsculas de minúsculas

3.5.3 XML deve estar devidamente aninhado
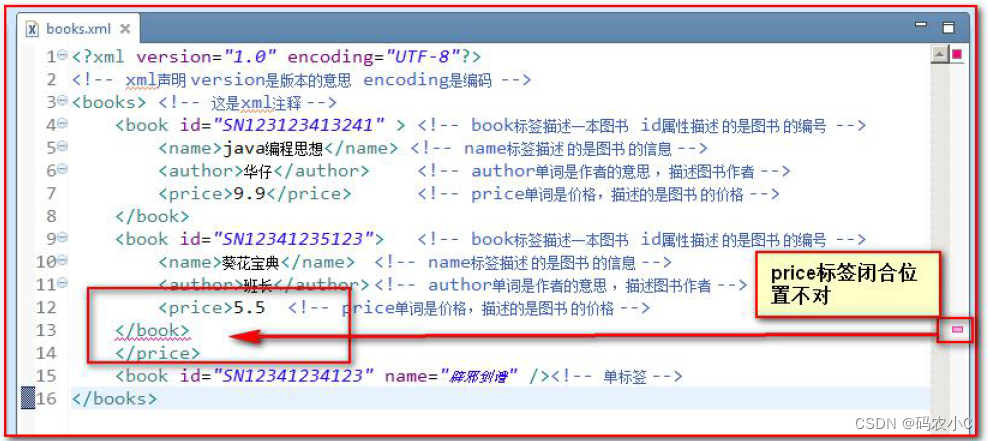
3.5.4 Documentos XML devem ter um elemento raiz
O elemento raiz é o elemento de nível superior e
o elemento sem uma marca pai é chamado de elemento de nível superior.
O elemento raiz é o elemento de nível superior que não possui tag pai e é o único.
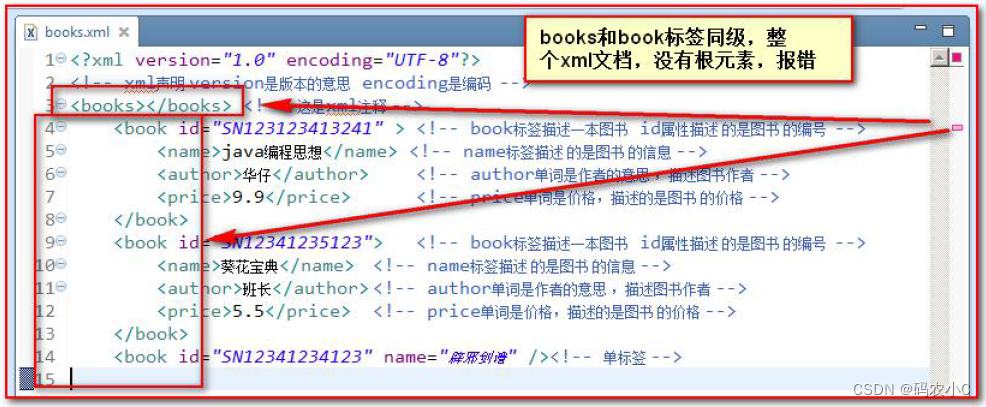
3.5.5 Valores de atributos XML devem ser citados
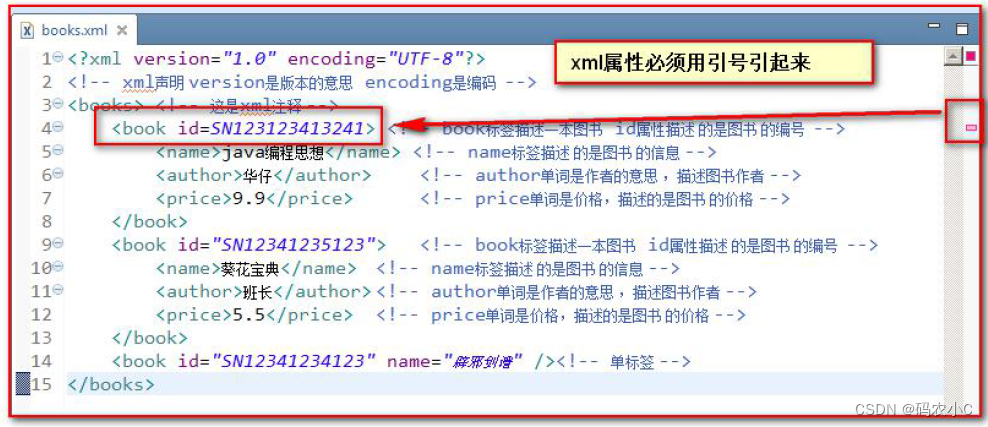
3.5.6 Caracteres especiais em XML
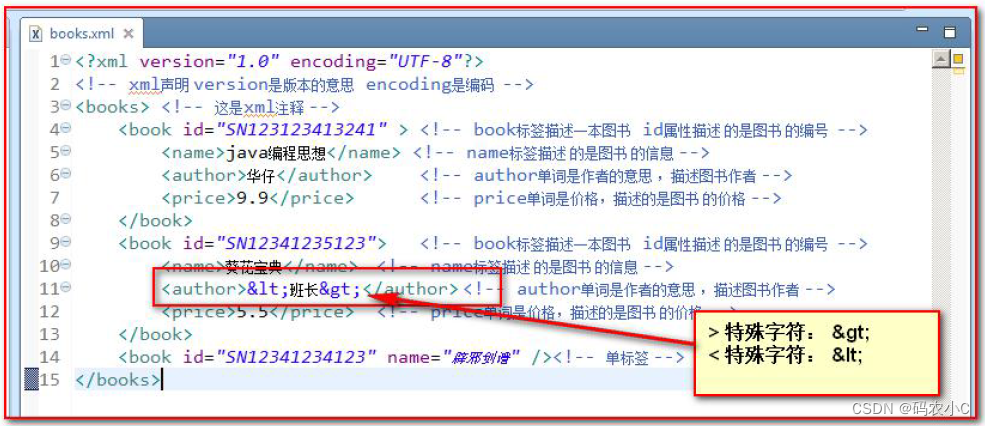
3.5.7 Área de texto (área CDATA)
A sintaxe CDATA pode informar ao analisador xml que o conteúdo de texto em meu CDATA é apenas texto simples e a sintaxe xml não é necessária para analisar o
formato CDATA:<![CDATA[ 这里可以把你输入的字符原样显示,不会解析xml ]]>

4. Introdução à tecnologia de análise xml
xml Linguagem de marcação extensível.
Tanto os arquivos html quanto os arquivos xml são documentos de marcação e podem ser analisados usando a tecnologia dom desenvolvida pela organização w3c.
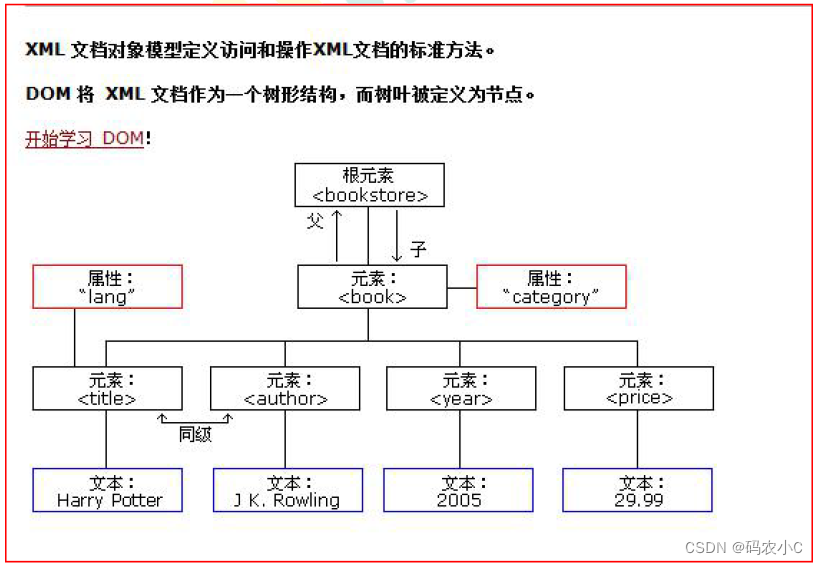
O objeto document representa o documento inteiro (pode ser um documento html ou um documento xml)
O JDK inicial nos forneceu uma introdução a duas tecnologias de análise xml DOM e Sax ( obsoleto, mas precisamos conhecer essas duas tecnologias )
a tecnologia de análise dom é formulada pela organização W3C e todas as linguagens de programação usam sua própria tecnologia de análise para isso. características da linguagem são implementadas.
Java também implementa tags de análise de tecnologia dom.
A empresa Sun atualizou a tecnologia de análise dom na versão JDK5: SAX (Simple API for XML)
SAX parsing, que é diferente da análise desenvolvida pelo W3C. Ele usa um mecanismo de evento semelhante para informar ao usuário o conteúdo que está sendo analisado no momento por meio de um retorno de chamada.
Ele lê o arquivo xml linha por linha para análise. Não cria um grande número de objetos dom.
Portanto, ele usa memória ao analisar xml. e desempenho. Ambos são superiores à análise Dom.
Análise de terceiros:
o jdom é encapsulado com base no dom e
o dom4j também é encapsulado no jdom.
O pull é usado principalmente no desenvolvimento de telefones celulares Android, é muito semelhante ao sax e usa um mecanismo de evento para analisar arquivos xml.
Este Dom4j é uma tecnologia de análise de terceiros. Precisamos usar um terceiro para nos fornecer uma boa biblioteca de classes antes de podermos analisar o arquivo xml .
4. tecnologia de análise dom4j (ênfase*****)
Como o dom4j não é uma tecnologia da empresa sun, mas uma tecnologia de uma empresa terceirizada, se precisarmos usar o dom4j, precisamos baixar o
pacote dom4j jar do site oficial do dom4j.
4.1, o uso da biblioteca de classes Dom4j
Após a descompressão:
4.2. Introdução ao diretório dom4j:
1) docs é o diretório de documentos
2) Como verificar a documentação do Dom4j
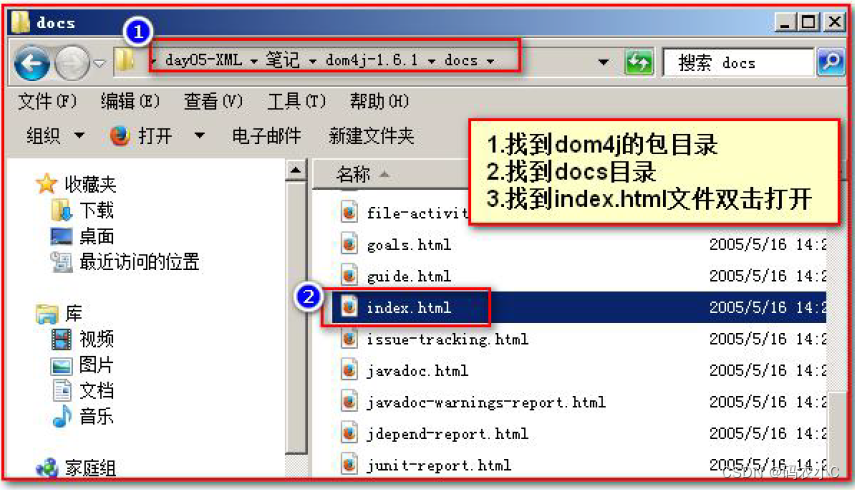
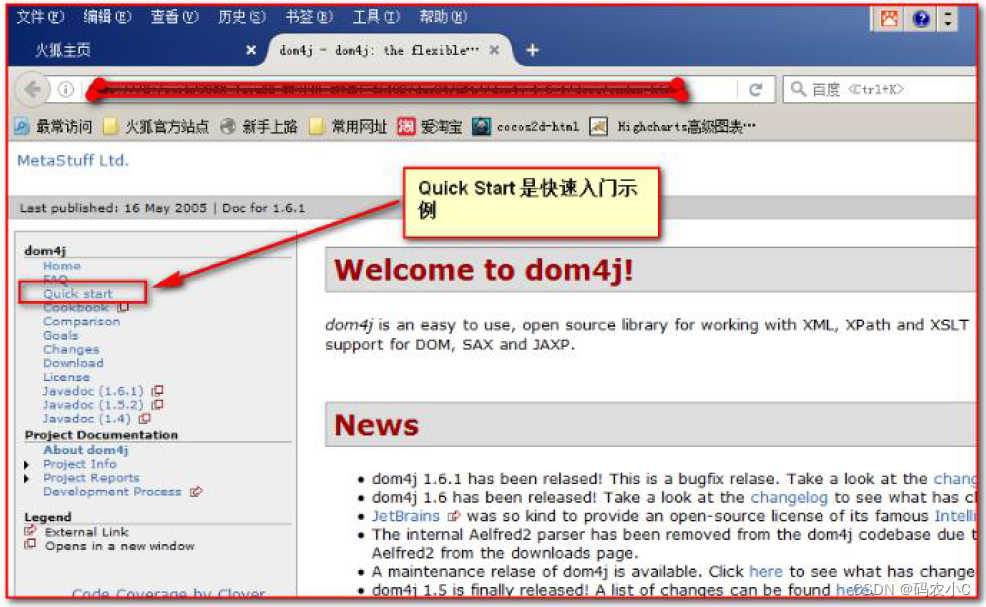
4.3. Início rápido do Dom4j
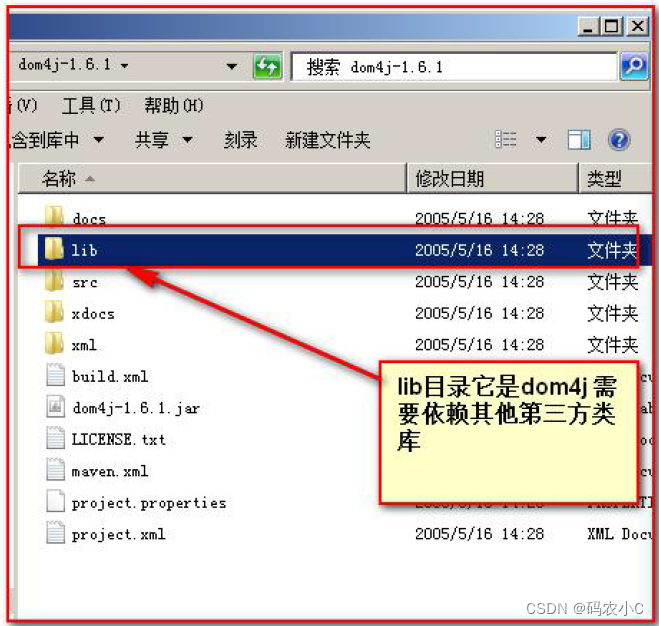
- 2) diretório lib
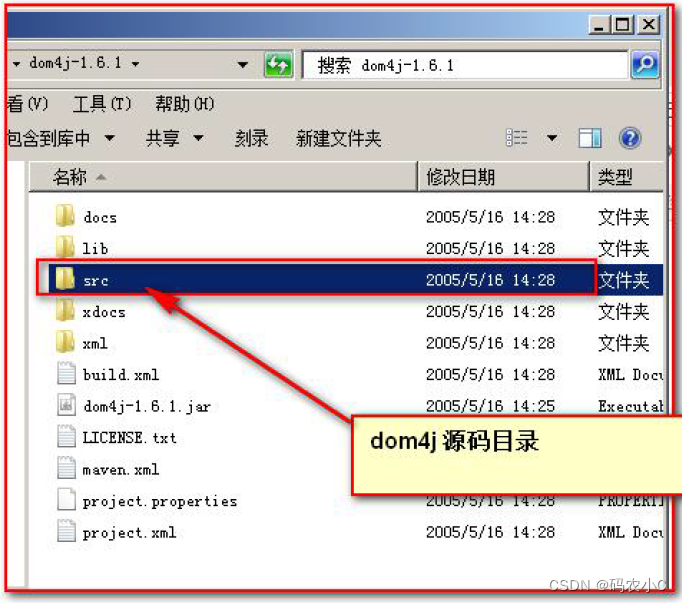
- 3) O diretório src é o diretório do código-fonte da biblioteca de classes de terceiros:
4.4, passos de programação dom4j:
Passo 1: Primeiro carregue o arquivo xml para criar um objeto Document
Passo 2: Obtenha o objeto elemento raiz através do objeto Document
Passo 3: Através do elemento raiz.elelemts(nome da tag); uma coleção pode ser retornada, que é colocada no coleção. Todos os objetos de elemento com o nome de marca que você especificou
Etapa 4: Encontre o elemento filho que deseja modificar ou excluir e execute a operação correspondente
Etapa 5: Salve-o no disco rígido
4.5. Obtenha o objeto do documento
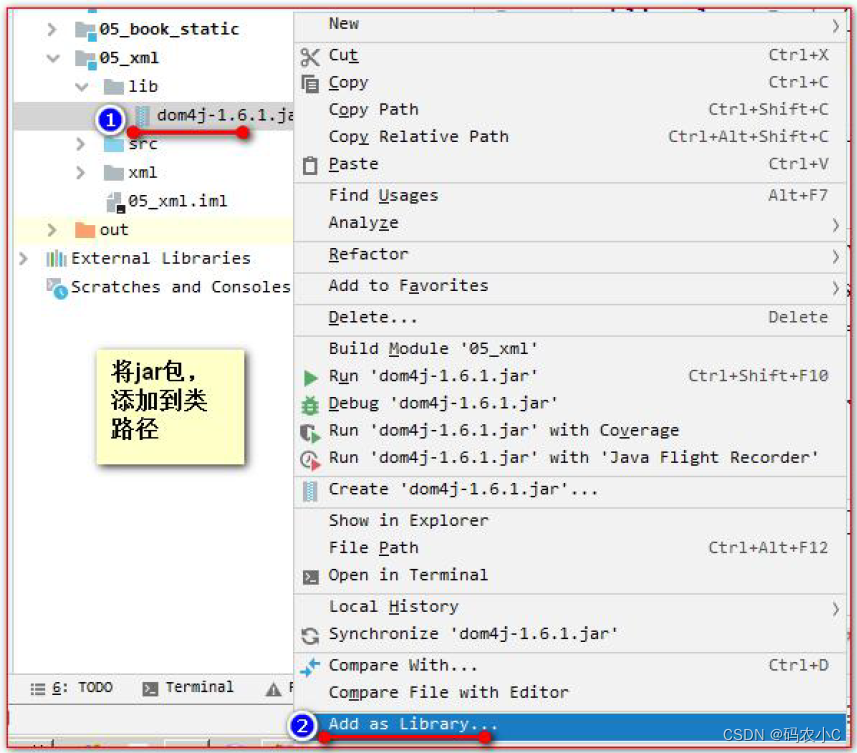
Crie um diretório lib e adicione o pacote jar dom4j. e adicionado ao classpath.
O conteúdo do arquivo books.xml que precisa ser analisado
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book sn="SN12341232">
<name>辟邪剑谱</name>
<price>9.9</price>
<author>班主任</author>
</book>
<book sn="SN12341231">
<name>葵花宝典</name>
<price>99.99</price>
<author>班长</author>
</book>
</books>
Analisando o código para obter o objeto Document
A primeira etapa é criar um objeto SaxReader. Este objeto é usado para ler arquivos xml e criar documentos
/*
* dom4j 获取Documet 对象
*/
@Test
public void getDocument() throws DocumentException {
// 要创建一个Document 对象,需要我们先创建一个SAXReader 对象
SAXReader reader = new SAXReader();
// 这个对象用于读取xml 文件,然后返回一个Document。
Document document = reader.read("src/books.xml");
// 打印到控制台,看看是否创建成功
System.out.println(document);
}
4.6. Percorra as tags para obter o conteúdo em todas as tags (tecla *****)
Ele precisa ser dividido em quatro etapas:
a primeira etapa é criar um objeto SAXReader. Para ler o arquivo xml e obter o objeto Document
O segundo passo é passar o objeto Document. Obter o objeto de elemento raiz do XML
A terceira etapa é passar o objeto de elemento raiz. Obtenha todos os objetos de marca de livro
Quarto, atravesse cada objeto de marca de livro. Em seguida, obtenha cada elemento no objeto da tag do livro e, em seguida, obtenha o conteúdo do texto entre a tag inicial e a tag final por meio do método getText()
Execute o código a seguir para lembrar de importar o pacote.
Código Dom4jTest:
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.jupiter.api.Test;
import java.util.List;
public class Dom4jTest {
@Test
public void test1() throws Exception {
// 创建一个SaxReader输入流,去读取 xml配置文件,生成Document对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read("src/books.xml");
System.out.println(document);
}
/*
* 读取xml 文件中的内容
*/
@Test
public void readXML() throws Exception {
// 需要分四步操作:
// 第一步,通过创建SAXReader 对象。来读取xml 文件,获取Document 对象
// 第二步,通过Document 对象。拿到XML 的根元素对象
// 第三步,通过根元素对象。获取所有的book 标签对象
// 第四小,遍历每个book 标签对象。然后获取到book 标签对象内的每一个元素,再通过getText() 方法拿到 起始标签和结束标签之间的文本内容
// 第一步,通过创建SAXReader 对象。来读取xml 文件,获取Document 对象
SAXReader reader = new SAXReader();
Document document = reader.read("src/books.xml");
// 第二步,通过Document 对象。拿到XML 的根元素对象
Element root = document.getRootElement();
// 打印测试
// Element.asXML() 它将当前元素转换成为String 对象
// System.out.println( root.asXML() );
// 第三步,通过根元素对象。获取所有的book 标签对象
// Element.elements(标签名)它可以拿到当前元素下的指定的子元素的集合
List<Element> books = root.elements("book");
// 第四小,遍历每个book 标签对象。然后获取到book 标签对象内的每一个元素,
for (Element book : books) {
// 测试
// System.out.println(book.asXML());
// 拿到book 下面的name 元素对象
Element nameElement = book.element("name");
// 拿到book 下面的price 元素对象
Element priceElement = book.element("price");
// 拿到book 下面的author 元素对象
Element authorElement = book.element("author");
// 再通过getText() 方法拿到起始标签和结束标签之间的文本内容
System.out.println("书名" + nameElement.getText() + " , 价格:"
+ priceElement.getText() + ", 作者:" + authorElement.getText());
}
}
}
Código da classe BOOK:
import java.math.BigDecimal;
public class Book {
private String sn;
private String name;
private BigDecimal price;
private String author;
public Book(String sn, String name, BigDecimal price, String author) {
this.sn = sn;
this.name = name;
this.price = price;
this.author = author;
}
public Book() {
}
public String getSn() {
return sn;
}
public void setSn(String sn) {
this.sn = sn;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {
return "Book{" +
"sn='" + sn + '\'' +
", name='" + name + '\'' +
", price=" + price +
", author='" + author + '\'' +
'}';
}
}