5자 4행시로 시작해서 그 뒤에 무엇이 있는지 아십니까?
두 개의 칼을 들고
뜨거운 비명을 지르는 입
수천 송이의 꽃을 밟고
미소로 모든 것을 봐
� 무엇입니까?
얼마 전 Shitou 형제의 이 기사에서 - 당신도 이 단순한 문자열의 구덩이에 빠질 수 있습니다.
사실, 이 "�"는 유명한 WeChat과 같이 정말 어디에나 있습니다.
위챗에서
또 다른 예를 들어, 표지 사진에서 22위안의 단가는 "Kun jin kao kun jin kao"이고 다음은 Baidu입니다.

어디에나 있는
이 문제를 명확히 하려면 코딩부터 시작해야 합니다.
컴퓨터의 눈에는 모두 이진수이기 때문에 이진수는 어떤 기호를 나타내는 데 사용되며 이것이 인코딩입니다. 코딩이 너무 복잡하다고 생각하지 마십시오. 실제로는 매우 간단한 매핑입니다.
예를 들어, 잘 알려진 ASCII 코드는 대문자 A를 의미하는 10진수로 65인 이진수 0100 0001을 지정합니다.
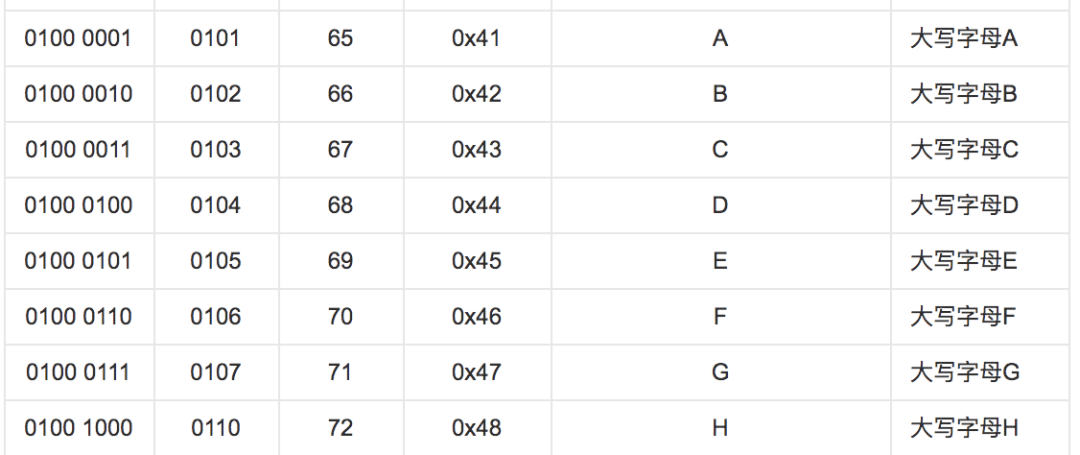
ASCII 인코딩
� 역시 코딩된 문자로, 위의 A와 마찬가지로 UNICODE 인코딩 방법의 특수 문자, 즉 0xFFFD(65533), 의미론은 이 인코딩 시스템을 표현하는 데 사용되는 자리 표시자입니다. 몰라.
예를 들어 이전 기사의 실험 스크린샷에서 빨간색 원으로 표시된 해당 문자는 UTF-8 인코딩을 알지 못하므로 UNICODE의 정의에 따라 통일된 자리 표시자 - 0xFFFD(65533)를 사용하여 표현하다.
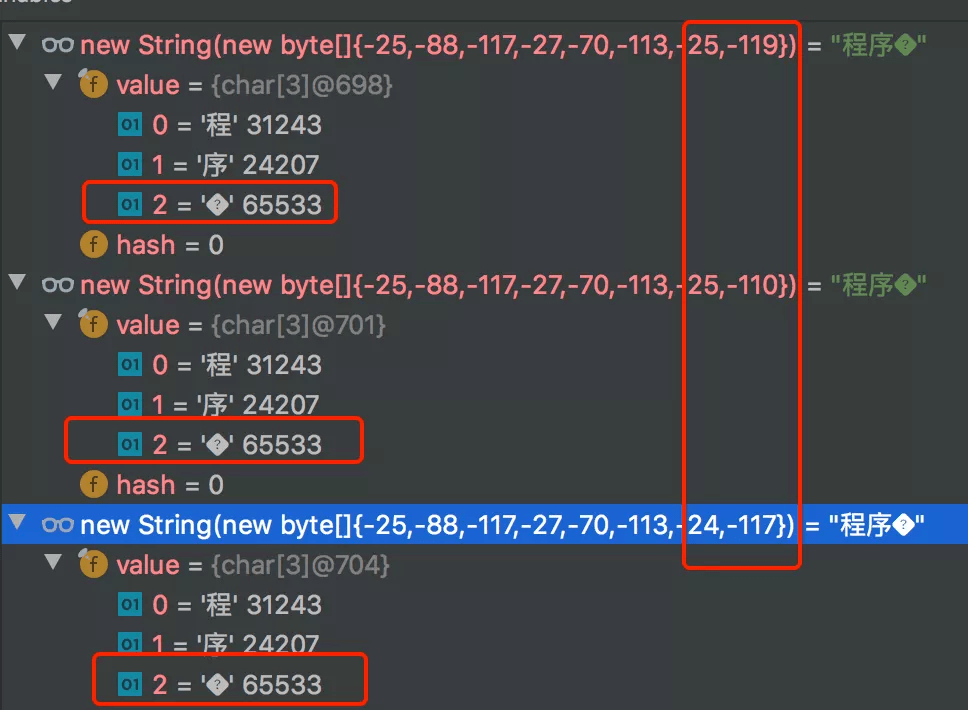
왜 "군진 카피"가 있습니까?
아래 그림과 같이 "프로그래머 스톤"의 바이너리 코드에 해당하는 부분을 가로채는 이전 예제를 계속 진행해 보겠습니다.

위의 그림과 같이 18행의 바이트 배열 new byte[] {-25, -119, -25, -116}, UTF-8은 단지 그것을 알지 못하므로 자리 표시자로 대체할 수 밖에 없습니다. .
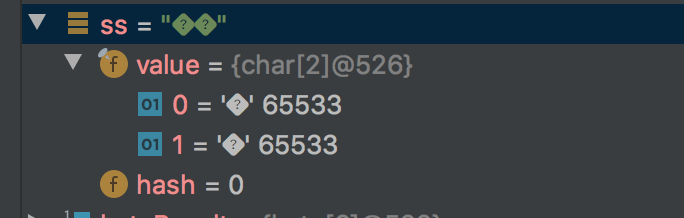
��
이러한 상황은 코드 변환 과정에서 실제로 비교적 일반적이며, 두 당사자가 명확하게 의사 소통하지 않으면 서로를 알지 못하기 쉽습니다.
중국 시스템에서 일반적인 문자 인코딩은 GBK입니다.이 시점에서 모든 사람들이 사전에 명확하게 논의하지 않았기 때문에 기본적으로 GBK에 따라 인코딩을 제공합니다.

"곤진카피"는 여기
놀랬나 안놀랬나 안놀랐나...
사실 UTF-8로 인코딩한 후에는 0xEFBFBD(즉, 위의 바이트 배열 [-17, -65, -67])가 되고, 그 둘이 0xEFBFBDEFBFBD로 연결되어 있기 때문이다. 위의 바이트 배열 [- 17, -65, -67, -17, -65, -67].
GBK 코드는 여전히 2바이트 코드 체계를 채택하므로 위의 6바이트 0xEFBFBDEFBFBD는 3개의 2바이트 문자, 즉 0xEFBF, 0xBDEF, 0xBFBD로 분할됩니다. ), 복사(0xBFBD).


