paper:CrossKD: Destilação de Conhecimento Cross-Head para Detecção de Objetos Densos
implementação oficial: https://github.com/jbwang1997/CrossKD
prefácio
A destilação pode ser dividida em dois tipos: imitação de previsão de destilação preditiva e imitação de característica de destilação de recursos. Em 2015, Geoffrey Hinton propôs o trabalho pioneiro da destilação de conhecimento KD KD: Destilando o conhecimento em uma rede neural O princípio e a análise de código pertencem à simulação preditiva, e FitNets: dicas para princípios de Thin Deep Nets e análise de código são simulações de recursos típicos. No entanto, por muito tempo, descobriu-se que a simulação preditiva é menos eficiente do que a simulação de recursos. O princípio e a análise de código do LD para Detecção de Objetos Densos (CVPR 2022) mostram que a simulação preditiva tem a capacidade de transferir conhecimento específico da tarefa, o que é benéfico para os alunos realizarem simulação preditiva ao mesmo tempo. e simulação de recursos. Isso levou os autores a explorar e melhorar as simulações preditivas.
A inovação deste artigo
Na simulação preditiva, a previsão do modelo do aluno precisa simular a previsão do GT e do modelo do professor ao mesmo tempo, mas a previsão do modelo do professor geralmente é muito diferente do GT, e o modelo do aluno experimentou uma situação contraditória processo de aprendizagem durante o processo de destilação.O autor acredita que este é o principal motivo que impede que os modelos preditivos atinjam um desempenho superior.
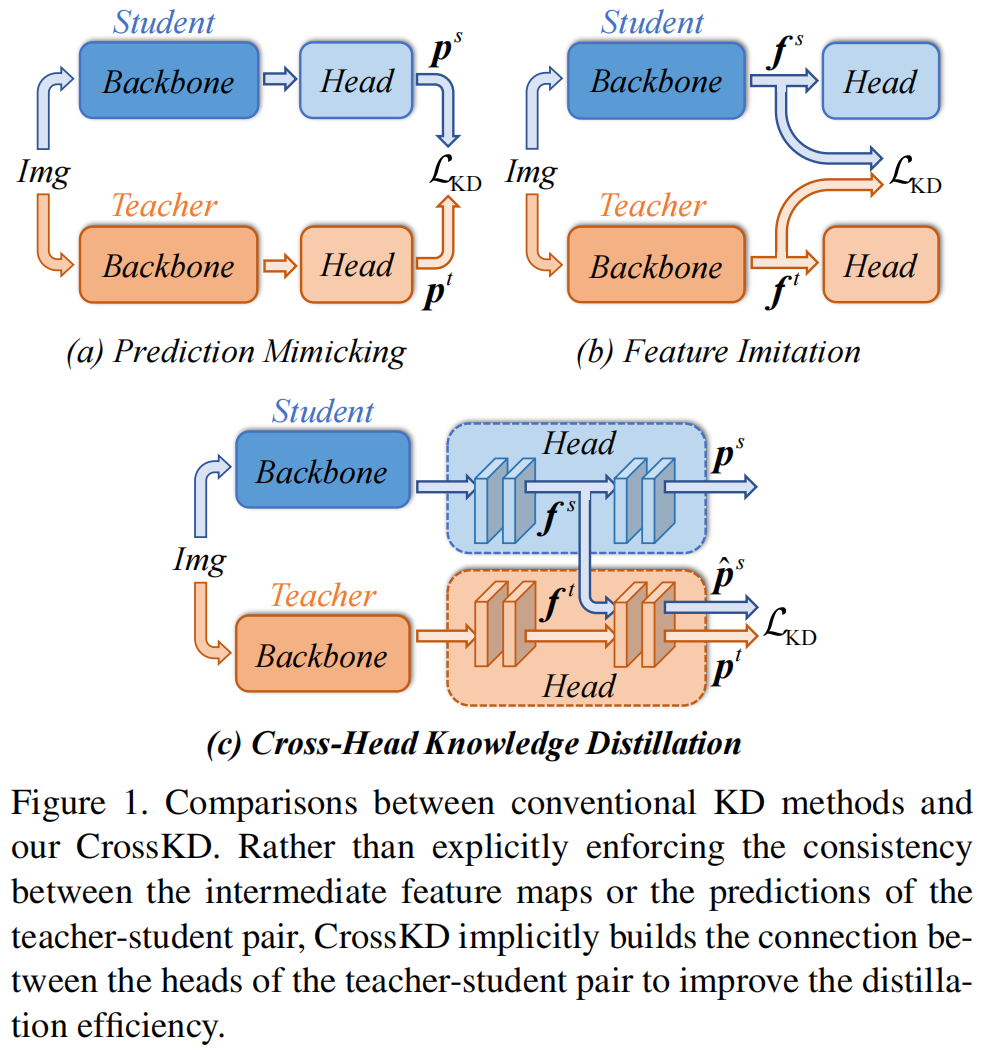
A fim de aliviar o problema do conflito de alvos de aprendizagem, este artigo propõe um novo método de destilação CrossKD, que envia as características intermediárias da cabeça de detecção do aluno para a cabeça de detecção do professor e destila os resultados de previsão obtidos com os resultados de previsão originais do professor. O método tem dois benefícios: a primeira perda de KD não afeta a atualização de peso da cabeça de detecção do aluno, evitando o conflito entre a perda de detecção original e a perda de KD. Além disso, como a previsão da cabeça de interseção e a previsão do professor compartilham algumas das cabeças de detecção do professor, as previsões das duas são relativamente consistentes, o que alivia a diferença de previsão entre o aluno-professor e melhora a estabilidade do treinamento da simulação de previsão.
A simulação de predição, a simulação de recursos e o kd cruzado proposto neste artigo são mostrados em (a)(b)(c) da Figura 1
introdução do método
A arquitetura geral do CrossKD é mostrada na Figura 3
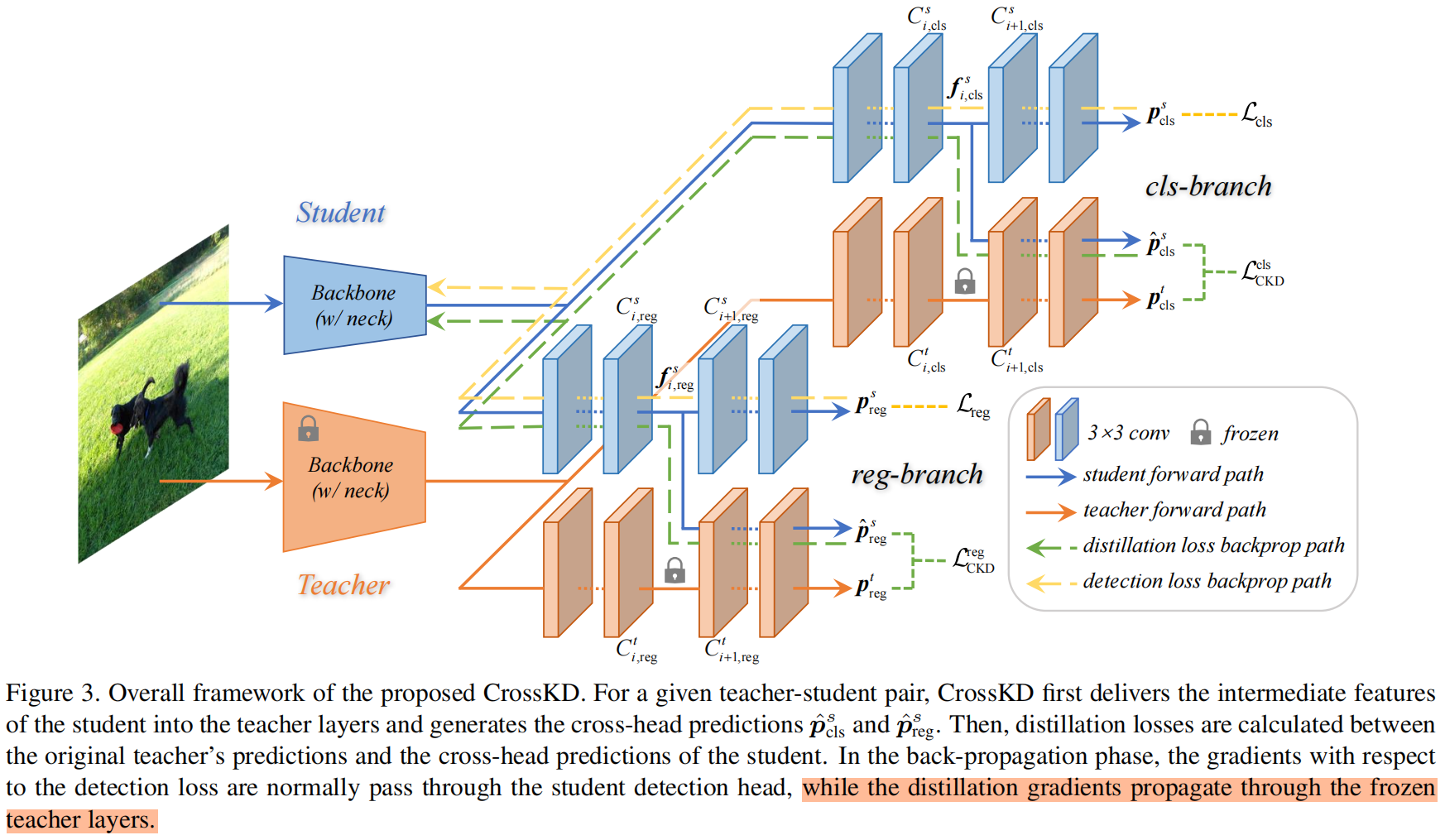
Dado um detector denso como o RetinaNet, cada cabeçote de detecção geralmente consiste em uma série de convoluções, denotadas como \(\esquerda \{ C_{i} \direita \} \). Para simplificar, assumimos que cada cabeçote de detecção tem um total de \(n\) camadas convolucionais (como n=5 em RetinaNet, incluindo 4 camadas ocultas e 1 camada de previsão). Usamos \(f_{i},i\in\left \{ 1,2,...,n-1 \right \} \) para representar o mapa de recursos de saída de \(C_{i}\),\ (f_{0}\) representa o mapa de recursos de saída de \(C_{1}\). A previsão\(p\) é a saída da última camada convolucional\(C_{n}\), os resultados finais da previsão de professores e alunos podem ser expressos como\(p^{t},p^{s}\) .
O CrossKD envia os recursos intermediários\(f_{i}^{s},i\in\left \{ 1,2,...,n-1 \right \} \) da cabeça de detecção de alunos para\(C^ { t}_{i+1}\), ou seja, a \((i+1)\)ª camada convolucional da cabeça de detecção do professor, e obtenha a previsão \(\hat{p}^{s}\) de a cabeça cruzada. Ao contrário do método anterior, não calculamos a perda KD entre \(p^{s}\) e \(p^{t}\), mas calculamos \(\hat{p}^{s}\) e \ (p^{t}\) Perda de KD entre, como segue

Onde \(\mathcal{S}(\cdot)\) e \(|\mathcal{S}|\) são o princípio de seleção de região e o fator de normalização, respectivamente. O autor deste artigo não envolveu o complexo \(\mathcal{S}(\cdot)\), o ramo de classificação\(\mathcal{S}(\cdot)\) é um valor constante 1, o primeiro plano do ramo de regressão área\(\mathcal{S }(\cdot)\) é 1 e área de fundo\(\mathcal{S}(\cdot)\) é 0.
Resultados experimentais
O primeiro são alguns experimentos de ablação, a rede do professor usa ResNet-50+GFL e a rede do aluno é ResNet-18.
Posições para aplicar CrossKD.
Conforme mencionado acima, a saída da \(i\)ª camada convolucional da cabeça de detecção do aluno é enviada para a rede do professor. Aqui, o autor compara o impacto de diferentes valores de \(i\) no resultado final. Quando \(i=0\ ) significa que os recursos de saída do FPN são enviados diretamente para o chefe da rede do professor e os resultados específicos são os seguintes
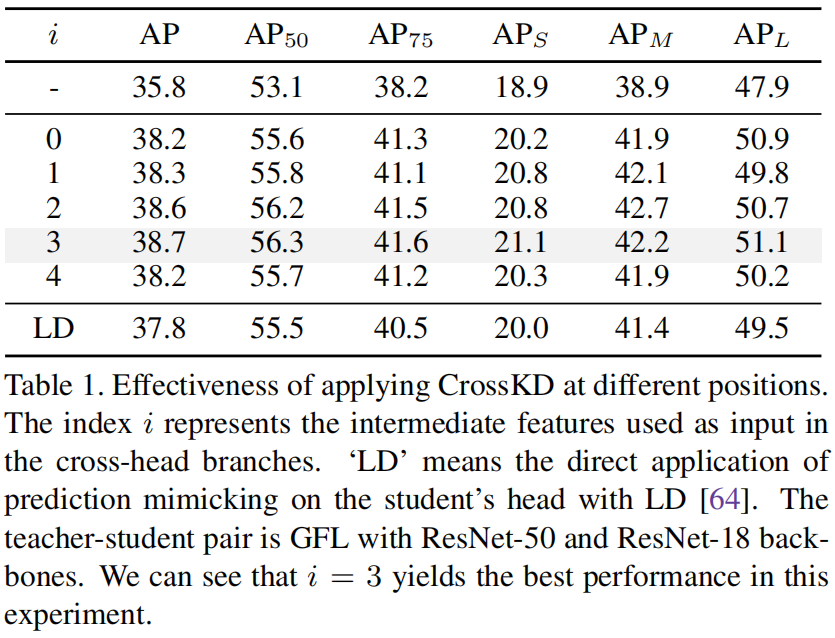
Pode-se ver que quando \(i=3\), a precisão final do modelo é a mais alta, então a configuração padrão \(i=3\) é usada nos experimentos subsequentes.
CrossKD vs Imitação de recursos.
O autor comparou CrossKD e o método SOTA PKD de destilação de características. Por uma questão de justiça, PKD é realizado na mesma posição que CrossKD, incluindo o pescoço de \(i=0\) e a cabeça de \(i=3\ ). Os resultados são os seguintes
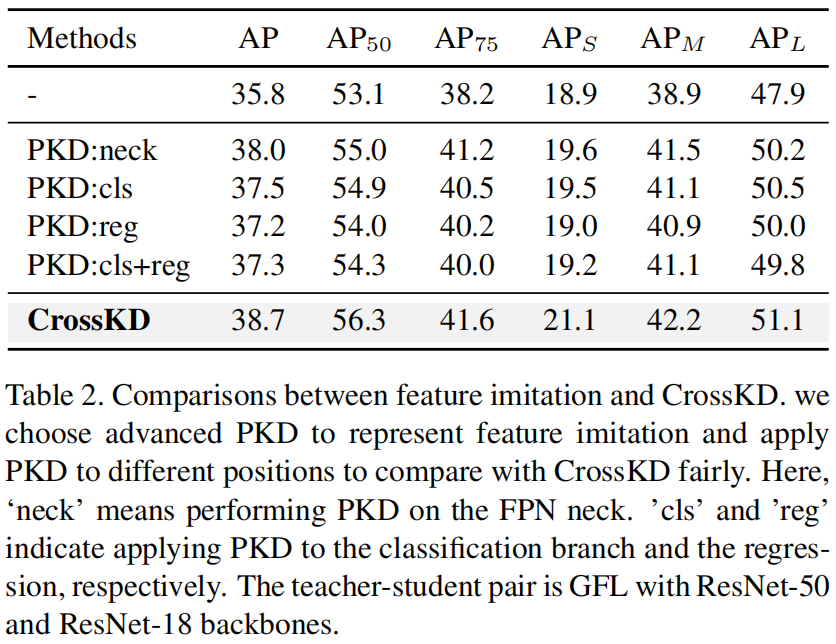
Pode-se ver que não importa onde o PKD esteja, o efeito não é tão bom quanto o CrossKD.
CrossKD para detectores leves.
O autor coloca os resultados no detector leve CrossKD da seguinte forma
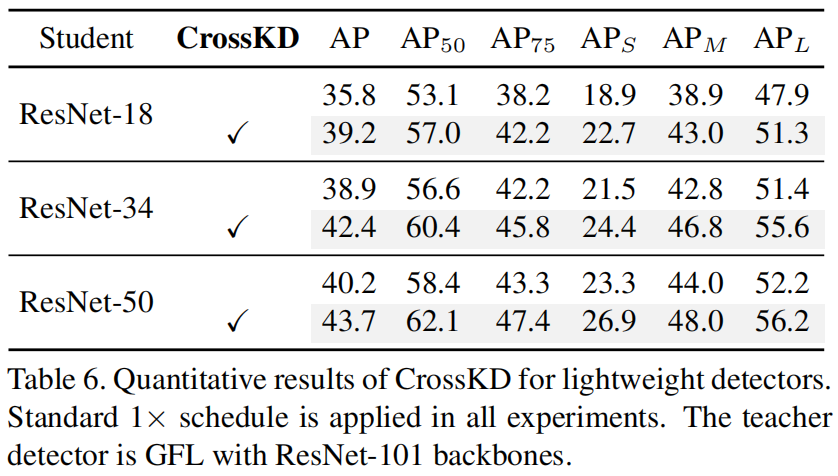
Pode-se ver que a rede do professor é ResNet-101+GFL, a rede do aluno é ResNet-50, ResNet-34, ResNet-18 e CrossKD podem melhorar significativamente a precisão.
Comparação com métodos SOTA KD
A comparação com outros métodos de destilação SOTA para detecção de alvos é mostrada na tabela abaixo.Pode-se ver que o CrossKD é superior a todos os métodos existentes.

análise de código
A implementação oficial é baseada em mmdetection, e crosskd é usado em atss, fcos, gfl, retinanet. Tomando atss como exemplo, o código está em mmdet/models/detectors/crosskd_atss.py, e o código da peça perdida é o seguinte. Primeiro, a entrada original batch_inputs passa pelo backbone e pelo pescoço do professor e pelo aluno, respectivamente, self.teacher_extract_feat é o backbone e o pescoço da rede do professor e self.extract_feat é o backbone e o pescoço da rede do aluno.
def loss(self, batch_inputs: Tensor,
batch_data_samples: SampleList) -> Union[dict, list]:
"""Calculate losses from a batch of inputs and data samples.
Args:
batch_inputs (Tensor): Input images of shape (N, C, H, W).
These should usually be mean centered and std scaled.
batch_data_samples (list[:obj:`DetDataSample`]): The batch
data samples. It usually includes information such
as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
Returns:
dict: A dictionary of loss components.
"""
tea_x = self.teacher.extract_feat(batch_inputs)
tea_cls_scores, tea_bbox_preds, tea_centernesses, tea_cls_hold, tea_reg_hold = \
multi_apply(self.forward_hkd_single,
tea_x,
self.teacher.bbox_head.scales,
module=self.teacher)
stu_x = self.extract_feat(batch_inputs)
stu_cls_scores, stu_bbox_preds, stu_centernesses, stu_cls_hold, stu_reg_hold = \
multi_apply(self.forward_hkd_single,
stu_x,
self.bbox_head.scales,
module=self)
reused_cls_scores, reused_bbox_preds, reused_centernesses = multi_apply(
self.reuse_teacher_head,
tea_cls_hold,
tea_reg_hold,
stu_cls_hold,
stu_reg_hold,
self.teacher.bbox_head.scales)
outputs = unpack_gt_instances(batch_data_samples)
(batch_gt_instances, batch_gt_instances_ignore,
batch_img_metas) = outputs
losses = self.loss_by_feat(tea_cls_scores,
tea_bbox_preds,
tea_centernesses,
tea_x,
stu_cls_scores,
stu_bbox_preds,
stu_centernesses,
stu_x,
reused_cls_scores,
reused_bbox_preds,
reused_centernesses,
batch_gt_instances,
batch_img_metas,
batch_gt_instances_ignore)
return lossesA saída do pescoço obtida apresenta tea_x e stu_x e, em seguida, insere a função self.forward_hkd_single respectivamente , da seguinte maneira
def forward_hkd_single(self, x, scale, module):
cls_feat, reg_feat = x, x
cls_feat_hold, reg_feat_hold = x, x
for i, cls_conv in enumerate(module.bbox_head.cls_convs):
cls_feat = cls_conv(cls_feat, activate=False)
if i + 1 == self.reused_teacher_head_idx:
cls_feat_hold = cls_feat
cls_feat = cls_conv.activate(cls_feat)
for i, reg_conv in enumerate(module.bbox_head.reg_convs):
reg_feat = reg_conv(reg_feat, activate=False)
if i + 1 == self.reused_teacher_head_idx:
reg_feat_hold = reg_feat
reg_feat = reg_conv.activate(reg_feat)
cls_score = module.bbox_head.atss_cls(cls_feat)
bbox_pred = scale(module.bbox_head.atss_reg(reg_feat)).float()
centerness = module.bbox_head.atss_centerness(reg_feat)
return cls_score, bbox_pred, centerness, cls_feat_hold, reg_feat_holdEntre eles, através do head do professor e do aluno respectivamente, incluindo o branch cls e o branch reg, self.reused_teacher_head_idx é o índice do recurso no head do aluno a ser enviado para o head de detecção do professor, e o recurso deste A posição é salva e enviada para a cabeça do professor, ou seja, a função reuse_teacher_head .
def reuse_teacher_head(self, tea_cls_feat, tea_reg_feat, stu_cls_feat,
stu_reg_feat, scale):
reused_cls_feat = self.align_scale(stu_cls_feat, tea_cls_feat)
reused_reg_feat = self.align_scale(stu_reg_feat, tea_reg_feat)
if self.reused_teacher_head_idx != 0:
reused_cls_feat = F.relu(reused_cls_feat)
reused_reg_feat = F.relu(reused_reg_feat)
module = self.teacher.bbox_head
for i in range(self.reused_teacher_head_idx, module.stacked_convs):
reused_cls_feat = module.cls_convs[i](reused_cls_feat)
reused_reg_feat = module.reg_convs[i](reused_reg_feat)
reused_cls_score = module.atss_cls(reused_cls_feat)
reused_bbox_pred = scale(module.atss_reg(reused_reg_feat)).float()
reused_centerness = module.atss_centerness(reused_reg_feat)
return reused_cls_score, reused_bbox_pred, reused_centernessObserve que há uma etapa align_scale aqui, que não é mencionada no artigo, ou seja, após subtrair a média das características da cabeça do aluno e dividi-la pela variância, multiplicá-la pela variância do recurso de posição correspondente do cabeça do professor e, em seguida, adicione a média das características do professor, como segue
def align_scale(self, stu_feat, tea_feat):
N, C, H, W = stu_feat.size()
# normalize student feature
stu_feat = stu_feat.permute(1, 0, 2, 3).reshape(C, -1)
stu_mean = stu_feat.mean(dim=-1, keepdim=True)
stu_std = stu_feat.std(dim=-1, keepdim=True)
stu_feat = (stu_feat - stu_mean) / (stu_std + 1e-6)
#
tea_feat = tea_feat.permute(1, 0, 2, 3).reshape(C, -1)
tea_mean = tea_feat.mean(dim=-1, keepdim=True)
tea_std = tea_feat.std(dim=-1, keepdim=True)
stu_feat = stu_feat * tea_std + tea_mean
return stu_feat.reshape(C, N, H, W).permute(1, 0, 2, 3)