1. Introdução ao JPA
1. Conceito JPA
JPA é a Java Persistence Specification proposta oficialmente pela Sun. É a abreviação de Java Persistence API. O nome chinês é 'Java Persistence Layer API'. É essencialmente uma especificação ORM.
JPA descreve o relacionamento de mapeamento de 'tabela relacional de objeto' por meio de anotações JDK 5.0 ou XML e persiste os objetos de entidade de tempo de execução no banco de dados.
2. O motivo do surgimento da JPA
A Sun introduziu a especificação JPA por dois motivos:
-
- Simplifique o desenvolvimento de Java EE e Java SE existentes;
-
- A Sun espera integrar a tecnologia ORM para realizar a unidade do mundo.
Em outras palavras, o propósito da especificação JPA proposta pela Sun é unificar as especificações de vários frameworks ORM em uma capacidade oficial, incluindo o famoso Hibernate, TopLink, etc. Desta forma, os desenvolvedores podem evitar a necessidade de aprender um framework ORM para usar o Hibernate, para usar o framework TopLink, eles precisam aprender outro framework ORM, eliminando a necessidade de repetir o processo de aprendizagem!
3. Tecnologias cobertas pelo JPA
A ideia geral do JPA é mais ou menos consistente com as estruturas ORM existentes, como Hibernate, TopLink, JDO e Mybatis.
Em geral, o JPA inclui as três tecnologias a seguir:
(1). Metadados de mapeamento ORM
O JPA oferece suporte a duas formas de anotações em XML e JDK 5.0. Os metadados descrevem o relacionamento de mapeamento entre objetos e tabelas, e a estrutura persiste objetos de entidade em tabelas de banco de dados de acordo.
(2).API JPA
Ele é usado para operar objetos de entidade e executar operações CRUD. A estrutura faz todo o trabalho para nós em segundo plano e os desenvolvedores ficam livres de códigos JDBC e SQL complicados.
(3). Linguagem de consulta
Consultar dados por meio de linguagem de consulta orientada a objetos em vez de orientada a banco de dados, evitando o acoplamento rígido de instruções SQL do programa.
4. A relação entre JPA e outros frameworks ORM
A essência do JPA é uma especificação ORM (não uma estrutura ORM, porque o JPA não fornece uma implementação ORM, mas apenas uma especificação), não uma implementação.
Ele fornece apenas algumas interfaces relacionadas, mas essas interfaces não podem ser usadas diretamente.A camada inferior do JPA precisa de algum tipo de implementação do JPA, e estruturas como o Hibernate são uma implementação específica do JPA.
也就是说JPA仅仅是一套规范,不是一套产品, Hibernate, TopLink等都是实现了JPA规范的一套产品。
O Hibernate é compatível com JPA desde 3.2. O Hibernate3.2 obteve a certificação compatível com JPA (Java Persistence API) da Sun TCK.
Portanto, o relacionamento entre JPA e Hibernate pode ser entendido simplesmente como JPA é a interface padrão e Hibernate é a implementação. Não há relacionamento de benchmarking entre eles. A figura a seguir pode mostrar o relacionamento entre eles.
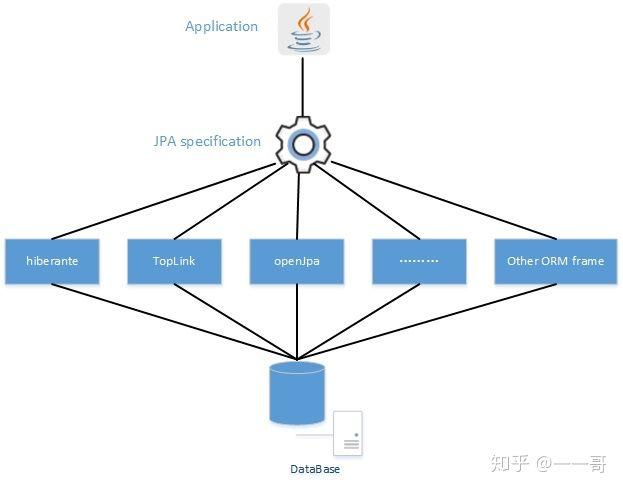
O Hibernate é uma implementação que segue a especificação JPA, mas o Hibernate possui outras especificações a serem implementadas. Portanto, o relacionamento deles é mais semelhante a: JPA é uma especificação padrão para fazer macarrão e Hibernate é uma sopa de macarrão específica que segue a especificação para fazer macarrão; não apenas segue a especificação para fazer macarrão, mas também segue as especificações para fazer sopa e temperos outras especificações.
5. Anotações em JPA

2. O Spring Boot integra o processo de implementação do JPA
1. Crie um aplicativo da web
De acordo com nossa experiência anterior, criamos um programa da Web e o transformamos em um projeto Spring Boot. O processo específico é omitido.

2. Adicione dependências
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
3. Adicione o arquivo de configuração
Criar arquivo de configuração application.yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/db4?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: syc
driver-class-name: com.mysql.jdbc.Driver #驱动
jpa:
hibernate:
ddl-auto: update #自动更新
show-sql: true #日志中显示sql语句
jpa.hibernate.ddl-auto é a propriedade de configuração do hibernate, cuja principal função é criar, atualizar e verificar automaticamente a estrutura da tabela do banco de dados.
Várias configurações deste parâmetro são as seguintes:
- Criar: Toda vez que o hibernate for carregado, a última tabela gerada será deletada, e então uma nova tabela será regenerada de acordo com sua classe de modelo, mesmo que não haja alteração duas vezes, esta é a que leva à perda da tabela do banco de dados razão importante de dados.
- Create-drop: Toda vez que o hibernate é carregado, uma tabela é gerada de acordo com a classe do modelo, mas quando a sessionFactory é fechada, a tabela é deletada automaticamente.
- update: O atributo mais comumente usado. Quando o hibernate é carregado pela primeira vez, a estrutura da tabela será automaticamente estabelecida de acordo com a classe do modelo (a premissa é que o banco de dados seja estabelecido primeiro). Quando o hibernate for carregado posteriormente, a estrutura da tabela será atualizado automaticamente de acordo com a classe do modelo, mesmo que a estrutura da tabela seja alterada, mas as linhas da tabela ainda existem sem excluir as linhas anteriores. Deve-se observar que, quando implantado no servidor, a estrutura da tabela não será estabelecida imediatamente, não será estabelecida até que o aplicativo seja executado pela primeira vez.
- Validate: Toda vez que o hibernate é carregado, a validação cria a estrutura das tabelas do banco de dados, que serão comparadas apenas com as tabelas do banco de dados. Nenhuma nova tabela será criada, mas novos valores serão inseridos.
4. Crie classes de entidade
package com.yyg.boot.domain;
import lombok.Data;
import lombok.ToString;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/30
* @Description Description
*/
@Data
@ToString
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
@Column
private String birthday;
@Column
private String sex;
@Column
private String address;
}
5. Crie uma classe de configuração DataSource
package com.yyg.boot.config;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/30
* @Description 第二种配置数据源的方式
*/
@Data
@ComponentScan
@Configuration
@ConfigurationProperties(prefix="spring.datasource")
public class DbConfig {
private String url;
private String username;
private String password;
@Bean
public DataSource getDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
return dataSource;
}
}
6. Crie um repositório de entidade JPA
package com.yyg.boot.repository;
import com.yyg.boot.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
public interface UserRepository extends JpaRepository<User, Long> {
}
7. Crie uma interface de teste do controlador
package com.yyg.boot.web;
import com.yyg.boot.domain.User;
import com.yyg.boot.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserRepository userRepository;
@GetMapping("")
public List<User> findUsers() {
return userRepository.findAll();
}
/**
* 注意:记得添加@RequestBody注解,否则前端传递来的json数据无法被封装到User中!
*/
@PostMapping("")
public User addUser(@RequestBody User user) {
return userRepository.save(user);
}
@DeleteMapping(path = "/{id}")
public String deleteById(@PathVariable("id") Long id) {
userRepository.deleteById(id);
return "success";
}
}
8. Crie uma classe de inicialização do aplicativo
package com.yyg.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @Author 一一哥Sun
* @Date Created in 2020/3/31
* @Description Description
*/
@SpringBootApplication
public class JpaApplication {
public static void main(String[] args) {
SpringApplication.run(JpaApplication.class, args);
}
}
Estrutura completa do projeto:

9. Interface de teste
Faça uma consulta get no navegador:

Execute a operação de adição no carteiro:

Execute operações de exclusão no carteiro:

10. Princípio de implementação do JPA
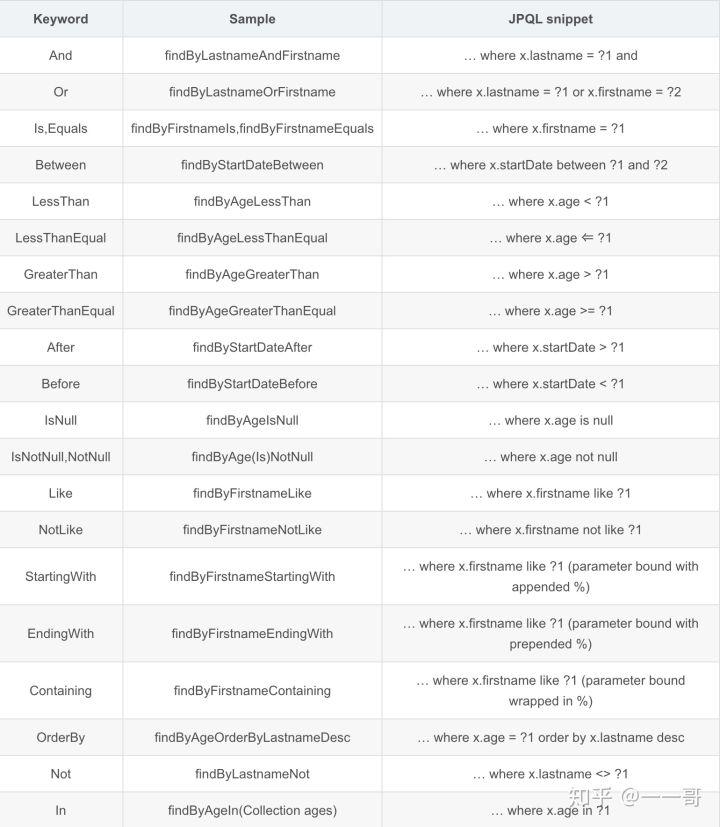
O JPA gerará instruções de consulta SQL com base no nome do método, que segue o princípio de Convenção sobre configuração (convenção sobre configuração) e segue a nomenclatura de método definida por Spring e JPQL. O Spring fornece um mecanismo para construção de consultas por meio de regras de nomenclatura.Esse mecanismo primeiro filtra o nome do método por algumas palavras-chave, como find...By, read...By, query...By, count...By e get. ..Por...
Em seguida, o sistema analisará o nome em duas subinstruções de acordo com as palavras-chave, e a primeira By é a palavra-chave para distinguir as duas subinstruções. A subinstrução antes deste By é uma subinstrução de consulta (indica que o objeto a ser consultado é retornado) e a parte seguinte é uma subinstrução condicional.
Se for diretamente findBy... o que é retornado é a coleção de objetos de domínio especificados ao definir o repositório. Ao mesmo tempo, JPQL também define palavras-chave ricas: and, or, Between, etc. JPQL: