Hoje vou apresentar os tipos de dados combinados do Python.
Não é fácil resolver. Espero obter seu apoio. Os leitores são bem-vindos para comentar, curtir e coletar.
Obrigado!
Índice
pontos de conhecimento
- Conceitos básicos de tipos de dados compostos
- Tipos de lista: definição, índice, fatia
- Listar operações de tipo: funções de operação de lista, métodos de operação de lista
- Tipos de dicionário: definição, índice
- Operação do tipo de dicionário: função de operação de dicionário, método de operação de dicionário
mapa do conhecimento
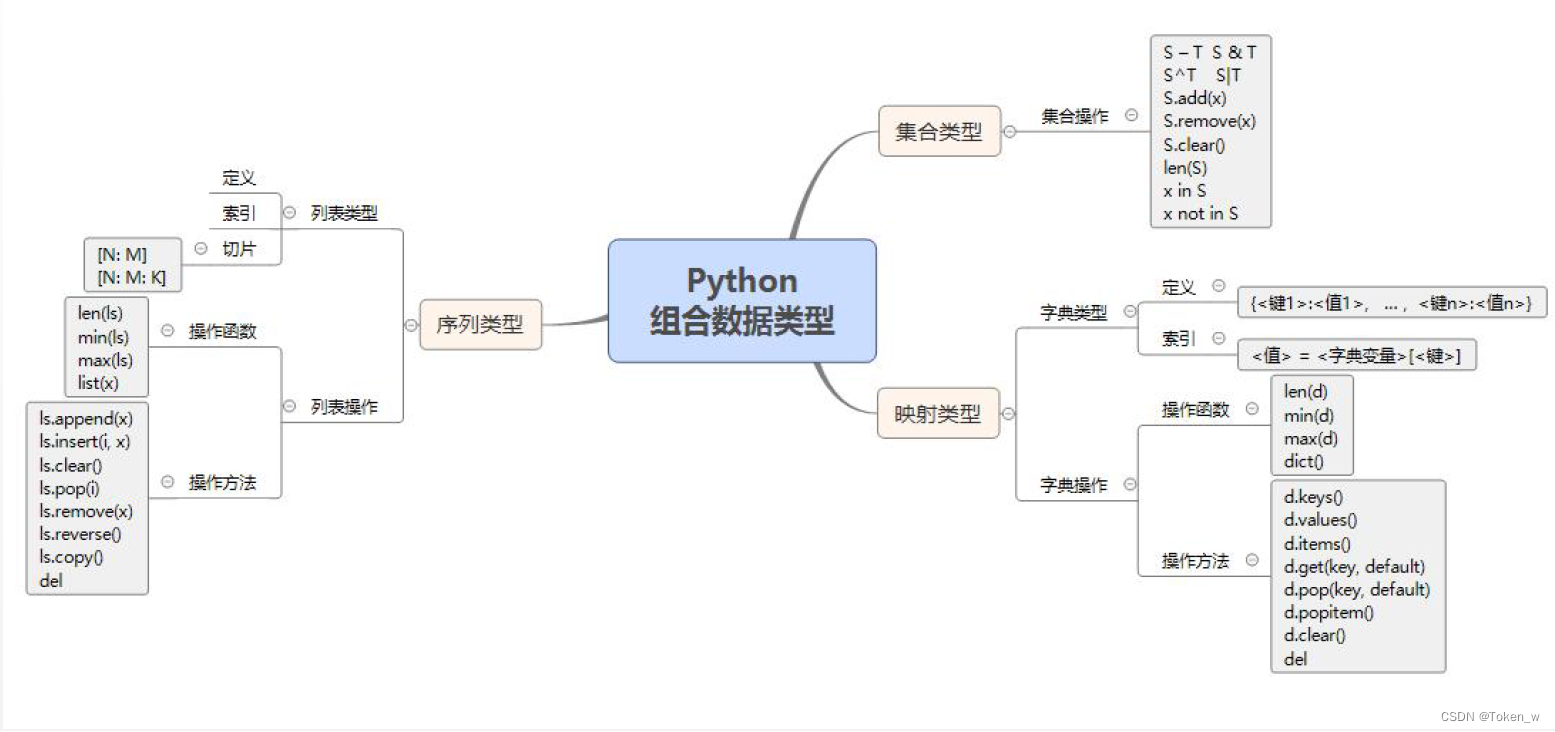
1. O conceito básico de tipos de dados combinados
1.1 Tipos de dados compostos
- Existem três tipos de tipos de dados combinados mais comumente usados na linguagem Python, ou seja, tipos de coleção, tipos de sequência e tipos de mapeamento.
- O tipo de coleção é um nome de tipo de dados específico, enquanto o tipo de sequência e o tipo de mapeamento são termos gerais para uma classe de tipos de dados.
- O tipo de coleção é uma coleção de elementos, os elementos não são ordenados e o mesmo elemento existe apenas na coleção.
- O tipo sequência é um vetor de elementos, e existe uma relação de sequência entre os elementos, que são acessados através de números de série, sendo que os elementos não são exclusivos. Representantes típicos de tipos de sequência são o tipo string e o tipo lista.
- O tipo de mapa é uma combinação de itens de dados de "valor-chave" e cada elemento é um par de valor-chave, expresso como (chave, valor). Um representante típico do tipo de mapeamento é o tipo de dicionário.
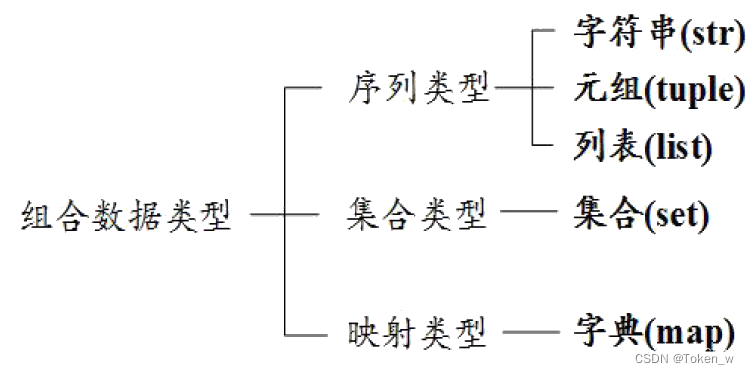
1.2 Visão geral dos tipos de coleção
- O tipo de coleção na linguagem Python é consistente com o conceito de coleção em matemática, ou seja, uma combinação não ordenada de 0 ou mais itens de dados.
- Um conjunto é uma combinação não ordenada, representada por colchetes ({}), não possui conceito de índice e posição e os elementos do conjunto podem ser adicionados ou excluídos dinamicamente.
- Os elementos na coleção não podem ser repetidos e os tipos de elemento podem ser apenas tipos de dados fixos, como: números inteiros, números de ponto flutuante, strings, tuplas, etc. Listas, dicionários e tipos de coleção em si são tipos de dados variáveis e não podem aparecer como elementos da coleção.
S = {
1010, "1010", 78.9}
print(type(S))
# <class 'set'>
print(len(S))
# 3
print(S)
# {78.9, 1010, '1010'}
- Deve-se observar que, como os elementos da coleção não estão ordenados, o efeito de impressão da coleção pode não ser consistente com a ordem de definição. Como os elementos da coleção são exclusivos, usar o tipo de coleção pode filtrar elementos duplicados.
T = {
1010, "1010", 12.3, 1010, 1010}
print(T)
# {1010, '1010', 12.3}
- O tipo set possui 4 operadores, interseção (&), união (|), diferença (-), complemento (^), e a lógica de operação é a mesma da definição matemática.
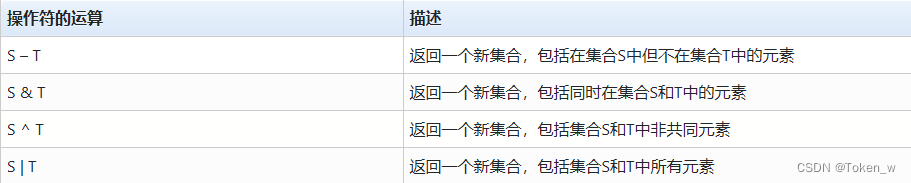

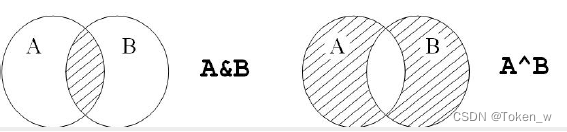
S = {
1010, "1010", 78.9}
T = {
1010, "1010", 12.3, 1010, 1010}
print(S - T)
# {78.9}
print(T – S)
# {12.3}
print(S & T)
# {1010, '1010'}
print(T & S)
# {1010, '1010'}
print(S ^ T)
# {78.9, 12.3}
print(T ^ S)
# {78.9, 12.3}
print(S | T)
# {78.9, 1010, 12.3, '1010'}
print(T | S)
# {1010, 12.3, 78.9, '1010'}
- Os tipos de coleção têm algumas funções ou métodos de operação comuns
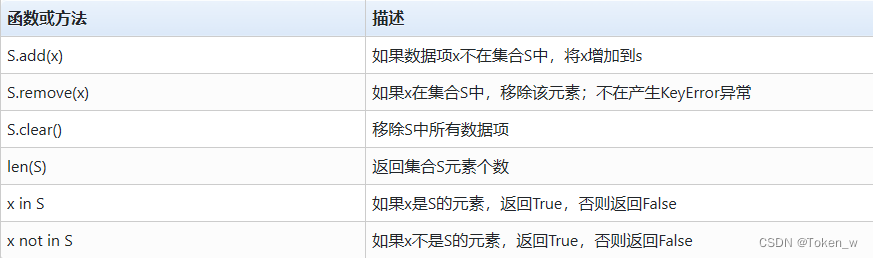
- O tipo de coleta é usado principalmente para desduplicação de elementos e é adequado para qualquer tipo de dados combinados.
S = set('知之为知之不知为不知')
print(S)
# {'不', '为', '之', '知'}
for i in S:
print(i, end="")
# 不为之知
1.3 Visão geral dos tipos de sequência
- O tipo sequência é um vetor de elemento unidimensional, e existe uma relação de sequência entre os elementos, que são acessados por meio de números de série.
- Como existe uma relação de ordem entre os elementos, podem existir elementos com o mesmo valor, mas posições diferentes na sequência. Muitos tipos de dados na linguagem Python são tipos de sequência, entre os quais os mais importantes são: tipo string e tipo lista, e também inclui tipo tupla.
- O tipo string pode ser considerado como uma combinação ordenada de caracteres únicos, que pertence ao tipo sequência. Uma lista é um tipo de sequência que pode usar vários tipos de elementos. Os tipos de sequência usam o mesmo sistema de indexação, ou seja, números ascendentes e descendentes.

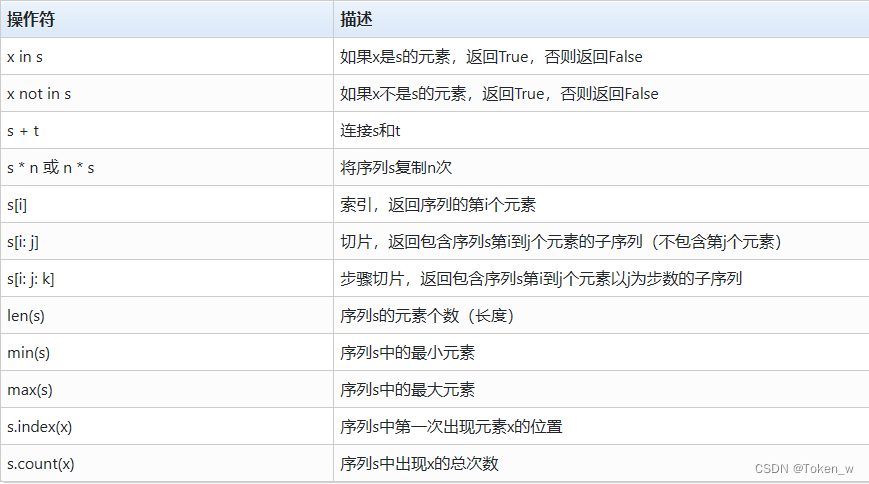
- Os tipos de sequência têm alguns operadores e funções comuns
1.4 Visão geral dos tipos de mapeamento
-
O tipo de mapeamento é uma combinação de itens de dados de "valor-chave", cada elemento é um par de valor-chave, ou seja, o elemento é (chave, valor) e os elementos não estão ordenados. Um par chave-valor é um relacionamento binário, derivado do relacionamento de mapeamento entre atributos e valores
-
Os tipos de mapeamento são uma extensão dos tipos de sequência. No tipo de sequência, o índice do valor do elemento específico é indexado pelo número de sequência de incremento positivo começando em 0. Para o tipo de mapeamento, o usuário define o número de série, ou seja, a chave, que é utilizada para indexar o valor específico.
-
A chave (chave) representa um atributo, podendo também ser entendida como uma categoria ou item, o valor (valor) é o conteúdo do atributo, e o par chave-valor descreve um atributo e seu valor. Os pares chave-valor estruturam o relacionamento de mapeamento para armazenamento e expressão.
2. Tipo de lista
2.1 Definição de lista
- Uma lista é uma sequência ordenada composta por 0 ou mais tuplas, que pertence ao tipo sequência. As listas podem ser adicionadas, excluídas, substituídas, pesquisadas e assim por diante. A lista não tem limite de comprimento, os tipos de elementos podem ser diferentes, nenhum comprimento predefinido é necessário.
- O tipo de lista é representado por colchetes ([]) e o tipo de coleção ou string também pode ser convertido em um tipo de lista por meio da função list(x).
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls)
# [1010, '1010', [1010, '1010'], 1010]
print(list('列表可以由字符串生成'))
# ['列', '表', '可', '以', '由', '字', '符', '串', '生', '成']
print(list())
# []
- A lista pertence ao tipo de sequência, portanto, o tipo de lista suporta as operações correspondentes ao tipo de sequência
2.2 Índice de lista
- A indexação é a operação básica das listas, usada para obter um elemento da lista. Use colchetes como o operador de indexação.
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls[3])
# 1010
print(ls[-2])
# [1010, '1010']
print(ls[5])
'''
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
ls[5]
IndexError: list index out of range'''
- Você pode usar o loop de passagem para percorrer os elementos do tipo de lista. O uso básico é o seguinte:
for <循环变量> in <列表变量>:
<语句块>
ls = [1010, "1010", [1010, "1010"], 1010]
for i in ls:
print(i*2)
'''
2020
10101010
[1010, '1010', 1010, '1010']
2020'''
2.3 Divisão de listas
- O fatiamento é a operação básica das listas, que é utilizada para obter um fragmento da lista, ou seja, obter um ou mais elementos. O resultado do fatiamento também é um tipo de lista. As fatias podem ser usadas de duas maneiras:
<列表或列表变量>[N: M]
或
<列表或列表变量>[N: M: K]
- O fatiamento leva elementos do tipo de lista de N a M (não incluindo M) para formar uma nova lista. Quando K existe, a fatia obtém uma lista composta de elementos correspondentes ao tipo de lista de N a M (não incluindo M) com K como tamanho do passo.
ls = [1010, "1010", [1010, "1010"], 1010]
print(ls[1:4])
# ['1010', [1010, '1010'], 1010]
print(ls[-1:-3])
# []
print(ls[-3:-1])
# ['1010', [1010, '1010']]
print(ls[0:4:2])
# [1010, [1010, '1010']]
3. Listar operações do tipo
3.1 Listar funções de operação
- O tipo de lista herda as características do tipo de sequência e possui algumas funções gerais de operação
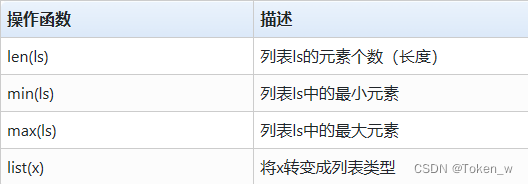
ls = [1010, "1010", [1010, "1010"], 1010]
print(len(ls))
# 4
lt =["Python", ["1010", 1010, [
1010, "
Python"]]]
print(len(lt))
# 2
- min(ls) e max(ls) retornam o menor ou maior elemento de uma lista, respectivamente.A premissa de usar essas duas funções é que os tipos de elementos na lista podem ser comparados.
ls = [1010, 10.10, 0x1010]
print(min(ls))
# 10.1
lt = ["1010", "10.10", "Python"]
print(max(lt))
# 'Python'
ls = ls + lt
print(ls)
# [1010, 10.1, 4112, '1010', '10.10', 'Python']
print(min(ls))
'''
Traceback (most recent call last):
File "<pyshell#15>", line 1, in <module>
min(ls)
TypeError: '<' not supported between instances of 'str' and 'float''''
- list(x) converte a variável x em um tipo de lista, onde x pode ser um tipo de string ou um tipo de dicionário.
print(list("Python"))
# ['P', 'y', 't', 'h', 'o', 'n']
print(list({
"小明", "小红", "小白", "小新"}))
# ['小红', '小明', '小新', '小白']
print(list({
"201801":"小明", "201802":"小红", "201803":"小白"}))
# ['201801', '201802', '201803']
3.2 Como operar a lista
- Existem alguns métodos de operação para o tipo de lista e a sintaxe de uso é:
<列表变量>.<方法名称>(<方法参数>)
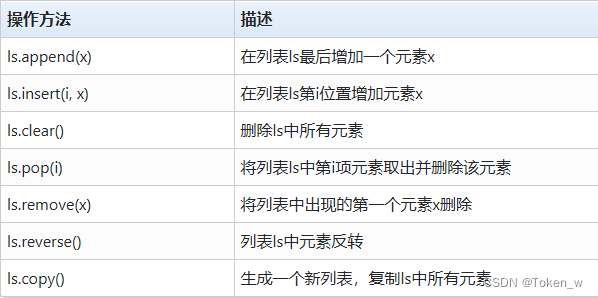
- ls.append(x) adiciona um elemento x ao final da lista ls.
lt = ["1010", "10.10", "Python"]
lt.append(1010)
print(lt)
# ['1010', '10.10', 'Python', 1010]
lt.append([1010, 0x1010])
print(lt)
# ['1010', '10.10', 'Python', 1010, [1010, 4112]]
- ls.append(x) é usado apenas para adicionar um elemento à lista. Se quiser adicionar vários elementos, você pode usar o sinal de mais para mesclar as duas listas.
lt = ["1010", "10.10", "Python"]
ls = [1010, [1010, 0x1010]]
ls += lt
print(lt)
['1010', '10.10', 'Python', 1010, [1010, 4112]]
- ls.insert(i, x) adiciona o elemento x na posição do número de sequência i na lista ls, e os números de sequência dos elementos após o número de sequência i aumentam sucessivamente.
lt = ["1010", "10.10", "Python"]
lt.insert(1, 1010)
print(lt)
# ['1010', 1010, '10.10', 'Python']
- ls.clear() exclui todos os elementos da lista ls e limpa a lista.
lt = ["1010", "10.10", "Python"]
lt.clear()
print(lt)
# []
- ls.pop(i) retornará o i-ésimo elemento na lista ls e excluirá o elemento da lista.
lt = ["1010", "10.10", "Python"]
print(lt.pop(1))
# 10.10
print(lt)
# ["1010", "Python"]
- ls.remove(x) removerá a primeira ocorrência de x na lista ls.
lt = ["1010", "10.10", "Python"]
lt.remove("10.10")
print(lt)
# ["1010", "Python"]
- Além dos métodos acima, você também pode usar a palavra reservada do Python del para excluir elementos ou fragmentos da lista, como segue:
del <列表变量>[<索引序号>] 或
del <列表变量>[<索引起始>: <索引结束>]
lt = ["1010", "10.10", "Python"]
del lt[1]
print(lt)
# ["1010", "Python"]
lt = ["1010", "10.10", "Python"]
del lt[1:]
print(lt)
# ["1010"]
- ls.reverse() inverte os elementos na lista ls na ordem inversa.
lt = ["1010", "10.10", "Python"]
print(lt.reverse())
# ['Python', '10.10', '1010']
- ls.copy() Copia todos os elementos em ls para gerar uma nova lista.
lt = ["1010", "10.10", "Python"]
ls = lt.copy()
lt.clear() # 清空lt
print(ls)
# ["1010", "10.10", "Python"]
- Como pode ser visto no exemplo acima, uma lista lt é copiada usando o método .copy() e atribuída à variável ls, e limpar o elemento lt não afeta a variável ls recém-gerada.
- Deve-se observar que para tipos de dados básicos, como inteiros ou strings, a atribuição de elemento pode ser obtida por meio do sinal de igual. Mas para o tipo de lista, a atribuição real não pode ser obtida usando o sinal de igual. Dentre elas, a instrução ls = lt não copia os elementos de lt para a variável ls, mas associa uma nova referência, ou seja, ls e lt apontam para o mesmo conjunto de conteúdo.
lt = ["1010", "10.10", "Python"]
ls = lt # 仅使用等号
lt.clear()
print(ls)
# []
- Os elementos da lista podem ser modificados usando um índice com o sinal de igual (=).
lt = ["1010", "10.10", "Python"]
lt[1] = 1010
print(lt)
# ["1010", 1010, "Python"]
- List é uma estrutura de dados muito flexível, que tem a capacidade de lidar com comprimento arbitrário e tipos mistos e fornece uma grande variedade de operadores e métodos básicos. Quando o programa precisar usar tipos de dados combinados para gerenciar dados em lote, use o tipo de lista o máximo possível.
4. Tipo de dicionário
4.1 Definição do dicionário
- Os "pares chave-valor" são uma forma importante de organizar dados e são amplamente utilizados em sistemas Web. A ideia básica de um par chave-valor é associar as informações de "valor" a uma informação de "chave" e, em seguida, usar as informações de chave para encontrar as informações de valor correspondentes. Esse processo é chamado de mapeamento. O mapeamento é implementado através do tipo de dicionário na linguagem Python.
- Os dicionários na linguagem Python são criados usando colchetes {} e cada elemento é um par chave-valor, que é usado da seguinte maneira:
{
<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
- Entre eles, chaves e valores são conectados por dois pontos e diferentes pares de valores-chave são separados por vírgulas. O tipo dicionário também possui propriedades semelhantes às coleções, ou seja, não há ordem entre os pares chave-valor e eles não podem ser repetidos.
- A variável d pode ser considerada como a relação de mapeamento entre "número do aluno" e "nome". Deve-se notar que os elementos do dicionário não possuem uma ordem.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d)
# {'201801': '小明', '201802': '小红', '201803': '小白'}
4.2 Indexação de dicionários
- Os tipos de lista são indexados por posição na ordem dos elementos. Como a chave no elemento do dicionário "par chave-valor" é o índice do valor, o relacionamento do par chave-valor pode ser usado diretamente para indexar o elemento.
- O padrão de índice para pares chave-valor em um dicionário é o seguinte, no formato de colchetes:
<值> = <字典变量>[<键>]
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d["201802"])
# 小红
- Cada elemento no dicionário pode ser modificado usando índice e atribuição (=).
d["201802"] = '新小红'
print(d)
# {'201801': '小明', '201803': '小白', '201802': '新小红'}
- Dicionários podem ser criados usando chaves. Elementos podem ser adicionados ao dicionário por meio da cooperação de indexação e atribuição.
t = {
}
t["201804"] = "小新"
print(d)
# {'201804': '小新'}
- Um dicionário é uma estrutura de dados que armazena um número variável de pares chave-valor. Chaves e valores podem ser de qualquer tipo de dados. Valores são indexados por chaves e valores podem ser modificados por chaves.
5. Operações do tipo dicionário
5.1 Funções de operação dos dicionários
- O tipo de dicionário tem algumas funções de operação comuns
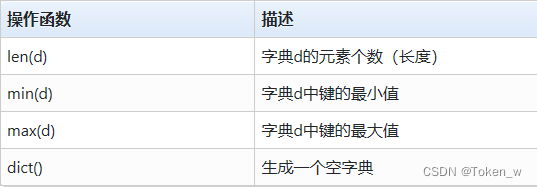
- len(d) fornece o número de elementos no dicionário d, também conhecido como comprimento.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(len(d))
# 3
- min(d) e max(d) retornam o menor ou maior valor de índice no dicionário d, respectivamente.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(min(d))
# '201801'
print(max(d))
# '201803'
- A função dict() é usada para gerar um dicionário vazio, consistente com {}.
d = dict()
print(d)
# {}
5.2 Método de operação do dicionário
- Existem alguns métodos de operação para o tipo de dicionário e a sintaxe de uso é:
<字典变量>.<方法名称>(<方法参数>)

- d.keys() retorna todas as informações de chave no dicionário, e o resultado de retorno é um tipo de dado interno do Python, dict_keys, que é dedicado a representar as chaves do dicionário. Se quiser fazer melhor uso do resultado retornado, você pode convertê-lo em um tipo de lista.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.keys())
# dict_keys(['201801', '201802', '201803'])
print(type(d.keys()))
# <class 'dict_keys'>
print(list(d.keys()))
# ['201801', '201802', '201803']
- d.values() retorna todas as informações de valor no dicionário, e o resultado de retorno é um tipo de dados interno dict_values do Python. Se quiser fazer melhor uso do resultado retornado, você pode convertê-lo em um tipo de lista.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.values())
# dict_values(['小明', '小红', '小白'])
print(type(d.values()))
# <class 'dict_values'>
print(list(d.values()))
# ['小明', '小红', '小白']
- d.items() retorna todas as informações de pares chave-valor no dicionário, e o resultado de retorno é um tipo de dados interno dict_items do Python.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.items())
# dict_items([('201801', '小明'), ('201802', '小红'),('201803', '小白')])
print(type(d.items()))
# <class 'dict_items'>
print(list(d.items()))
# [('201801', '小明'), ('201802', '小红'), ('201803', '小白')]
- d.get(key, default) busca e retorna a informação do valor de acordo com a informação da chave. Se a chave existir, retorna o valor correspondente, caso contrário retorna o valor padrão. O segundo elemento default pode ser omitido. Se for omitido , o valor padrão é vazio.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.get('201802'))
'小红'
print(d.get('201804'))
print(d.get('201804', '不存在'))
'不存在'
- d.pop(key, default) procura e busca as informações do valor de acordo com as informações da chave, retorna o valor correspondente se a chave existir, caso contrário retorna o valor padrão, o segundo elemento default pode ser omitido, se omitido, o valor padrão é vazio. Comparado com o método d.get(), d.pop() irá deletar o par chave-valor correspondente do dicionário depois de retirar o valor correspondente.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.pop('201802'))
# '小红'
print(d)
# {'201801': '小明', '201803': '小白'}
print(d.pop('201804', '不存在'))
# '不存在'
- d.popitem() pega aleatoriamente um par chave-valor do dicionário e o retorna na forma de uma tupla (chave, valor). Remova este par chave-valor do dicionário depois de retirá-lo.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print(d.popitem())
# ('201803', '小白')
print(d)
# {'201801': '小明', '201802': '小红'}
- d.clear() exclui todos os pares chave-valor no dicionário.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
d.clear()
print(d)
# {}
- Além disso, se você deseja excluir um elemento no dicionário, pode usar a palavra reservada do Python del.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
del d["201801"]
print(d)
# {'201802': '小红', '201803': '小白'}
- O tipo de dicionário também suporta a palavra reservada in, que é usada para determinar se uma chave está no dicionário. Retorna True se presente, False caso contrário.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
print("201801" in d)
# True
print("201804" in d)
# False
- Como outros tipos de combinação, os dicionários podem ser percorridos por meio de loops para percorrer seus elementos. A estrutura básica da sintaxe é a seguinte:
for <变量名> in <字典名>
<语句块>
- O nome da variável retornado pelo loop for é o valor do índice do dicionário. Se você precisar obter o valor correspondente à chave, poderá obtê-lo por meio do método get() no bloco de instruções.
d = {
"201801":"小明", "201802":"小红", "201803":"小白"}
for k in d:
print("字典的键和值分别是:{}和{}".format(k, d.get(k)))
'''
字典的键和值分别是:201801和小明
字典的键和值分别是:201802和小红
字典的键和值分别是:201803和小白'''
6. Exemplo de Análise: Estatísticas de Frequência de Palavras de Texto
-
Em muitos casos, você encontrará esse problema: para um determinado artigo, você deseja contar as palavras que aparecem várias vezes nele e, em seguida, analisar o conteúdo do artigo. A solução para este problema pode ser usada para recuperação automática e arquivamento de informações de rede.
-
Na era da explosão de informações, esse tipo de arquivamento ou classificação é muito necessário. Este é o problema das "estatísticas de frequência de palavras".
Contando a frequência de palavras em inglês em "Hamlet" -
Passo 1: Decomponha e extraia as palavras do artigo em inglês
Use a função txt.lower() para transformar as letras em minúsculas para eliminar a interferência da diferença de maiúsculas e minúsculas do texto original nas estatísticas de frequência da palavra. Para unificar o método de separação, você pode usar o método txt.replace() para substituir vários caracteres especiais e sinais de pontuação por espaços e, em seguida, extrair palavras. -
Passo 2: Conte cada palavra
if word in counts:
else:
counts[word] = 1
Alternativamente, esta lógica de processamento pode ser expressa de forma mais concisa como o seguinte código:
counts[word] = counts.get(word,0) + 1
- Passo 3: Classifique os valores estatísticos das palavras de alto a baixo
Como o tipo de dicionário não tem ordem, ele precisa ser convertido em um tipo de lista ordenada e, em seguida, use o método sort() e a função lambda para classificar os elementos de acordo com o número de palavras.
items = list(counts.items())#将字典转换为记录列表
items.sort(key=lambda x:x[1], reverse=True) #以第2列排序
# CalHamlet.py
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {
}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
>>>
the 1138
and 965
to 754
of 669
you 550
a 542
i 542
my 514
hamlet 462
in 436
resumo
Destinado principalmente a leitores iniciantes em programação, explica especificamente os conceitos básicos de linguagens de programação, compreende o método de escrita IPO de desenvolvimento de programas, as etapas específicas de configuração do ambiente de desenvolvimento Python e as características da linguagem Python e dos programas Python, etc. ., além de fornecer 5 códigos de exemplo do Simple Python para ajudar os leitores a testar o ambiente de desenvolvimento do Python e ter uma compreensão intuitiva da linguagem.
O drama do Python está prestes a ser encenado, vamos acompanhar o drama juntos.