
o que é babel
- Babel é um compilador de javascript. Desde o nascimento do ECMAScript, ele atua como um tradutor de código e ambiente operacional, permitindo-nos usar a nova sintaxe de js para escrever o código que quisermos.
- babel é uma cadeia de ferramentas
- O que o babel pode fazer pelos desenvolvedores?
- conversão de sintaxe;
- conversão de código-fonte;
- Adicione recursos ausentes no ambiente de destino por meio de polyfill (transforme e polyfill introduzindo módulos polyfill de terceiros);
- O uso do Babel para operar no código-fonte pode ser usado para análise estática. As mais utilizadas em combate real são: internacionalização automática, geração automática de documentos, enterramento automático, interpretador js, etc.;
O processo de compilação de babel
Analisar
- implemento
- Chame o parser para percorrer todos os plugins
- Encontre o compilador parserOverride
- Um analisador que converte o código js em uma árvore de sintaxe abstrata (AST para abreviar)
Transformar
- pré (inicializar o objeto de operação ao entrar no AST)
- visitante (executar o método no visitante após inicializar o objeto de operação, usar traverse para percorrer os nós AST e executar o plug-in durante o processo de passagem)
- post (excluir objeto de operação ao sair do AST)
Gerar
- Após a conclusão da conversão AST, o código é regenerado por gerar
- Após a geração do código-alvo, o código relacionado ao sourceMap também será gerado ao mesmo tempo
A árvore de sintaxe abstrata do código-fonte Vue real
Para vue normal, todos nós escrevemos a sintaxe do modelo. Se queremos compilá-lo na sintaxe html normal, é muito difícil compilá-lo diretamente, então precisamos usar a árvore de sintaxe abstrata para inverter, ou seja, primeiro temos que altere _sintaxe do modelo_ para AST , após a conclusão, transforme o AST em sintaxe HTML normal e a árvore de sintaxe abstrata atuará como uma transição intermediária, facilitando o trabalho de compilação.
Esta é a sintaxe do modelo

Esta é a sintaxe HTML normal

Esta é a árvore de sintaxe abstrata que precisa ser analisada em

A camada inferior do Vue examina todos os modelos a partir da perspectiva de strings. Se você olhar dessa maneira, o AST analisado é como uma versão js de objetos HTML. A árvore de sintaxe abstrata é amplamente usada na compilação de modelos, ou seja, desde que como há um lugar para compilar modelos Uma árvore de sintaxe abstrata será definitivamente usada.
Qual é a relação entre árvores de sintaxe abstrata e nós virtuais?
Sintaxe do modelo => árvore de sintaxe abstrata => função de renderização (função h) => nó virtual => interface
Reserva de algoritmo necessária
ideia do ponteiro AST
【例1】试寻找字符串中,连续重复次数最多的字符‘aaaaaaaaaabbbbbbbbcccddd’
解:
var str = 'aaaaaaaaaaabbbccccccddd';
//指针
var i = 0;
var j = 1;
// 当前重复次数最多的次数
var maxRepeatCount = 0;
// 重复次数最多的字符串
var maxRepeatChar = '';
//当i还在范围内的时候,应该继续寻找
while (i <= str.length - 1) {
//看i指向的字符和j指向的字符是不是不相同
if (str[i] != str[j]) {
console.log(i + '和' + j + '之间文字连续相同' + '字母' + str[i] + '它重复了' + (j - i) + '次')
//和当前重复次数最多的进行比较
if (j - i > maxRepeatCount) {
// 如果当前文字重复次数(j - i)超过了此时的最大值
// 就让它成为最大值
maxRepeatCount = j - i;
// 将i指针只想的字符串存为maxRepeatChar
maxRepeatChar = str[i];
}
// 让指针i追上指针j
i = j;
}
//不管相不相同,j永远要后移
j++;
}
Idéias para solução de problemas:
A primeira coisa que vem à mente é tirar todas as substrings e comparar se o comprimento é o mesmo, mas, neste caso, o número de ciclos será maior e isso desperdiçará eficiência. Muitas strings que não são mais repetidos também serão calculados Vá para comparação, então apresentarei o método do ponteiro.
O ponteiro é o subscrito, não o ponteiro na linguagem c, o ponteiro na linguagem c pode operar a memória e o ponteiro no js é uma posição na tabela abaixo.
i: 0
j: 1
Se as palavras apontadas por i e j são as mesmas, então i não se move ej se move para trás
. Se as palavras apontadas por i e j são diferentes, significa que as palavras entre elas são consecutivamente o mesmo, deixe i seguir para cima j, j se move para trás.
resultado da operação:
Entre 0 e 11 a letra a se repete 11 vezes entre
11 e 14 b se repete 3 vezes
entre 14 e 20 se repete 6 vezes
entre 20 e 23 Texto com a mesma letra d seguida se repete 3 vezes
pensamento recursivo
【例1】斐波那契数列,求前N项的和
解:
function fib(n) {
return n == 0 || n == 1 ? 1 : fib(n - 1) + fib(n - 2)
}
这其实很容易,但是衍生出来一个思考,代码是否有大量重复计算?应该怎样解决重复计算的问题。
缓存思想用hasOwnProperty方法判断
这样的话总的递归次数减少了,只要命中了缓存,就直接读缓存,不会再引发下一次递归了
解:
var cache = {
}
function fib(n) {
if (cache.hasOwnProperty(n)) {
return cache[n]
}
var v = n == 0 || n == 1 ? 1 : fib(n - 1) + fib(n - 2)
cache[n] = v;
return v;
}
【例2】将高维数组 [1, 2, [3, [4, 5], 6], 7, [8], 9] 转换为以下这个对象
{
children: [
{
value: 1 },
{
value: 2 },
{
children: [
{
value: 3 },
{
children: [
{
value: 4 },
{
value: 5 }
]
},
{
value: 6 }
]
},
{
value: 7 },
{
children: [
{
value: 8 }
]
},
{
value: 9 }
]
}
解:
var arr = [1, 2, 3, [4, 5, 6]]
function convert(arr) {
var result = [];
for (let i = 0; i < arr.length; i++) {
if (typeof arr[i] === 'number') {
result.push({
value: arr[i]
})
} else if (Array.isArray(arr[i])) {
result.push({
children: convert(arr[i])
})
}
}
return result;
}
// 还有一种更秒的写法不用循环数组,大大减少了递归次数
function convert(item) {
var result = [];
if (typeof item === 'number') {
return {
value: item
}
} else if (Array.isArray(item)) {
return {
children: item.map(_item => convert(_item))
}
}
return result;
}
estrutura de pilha
Todos nós sabemos que uma matriz é uma estrutura linear e os dados podem ser inseridos e excluídos em qualquer posição. Mas, às vezes, para alcançar certas funções, devemos limitar essa arbitrariedade. Pilhas e filas são estruturas lineares restritas comuns.
Uma pilha é uma lista linear restrita, o último a entrar, o primeiro a sair. A restrição é que as operações de inserção e exclusão só são permitidas em uma extremidade da tabela, que é chamada de topo da pilha, e a outra extremidade é chamada de base da pilha. LIFO (último a entrar, primeiro a sair) significa que é o elemento que entra depois, e o espaço da pilha é retirado primeiro. Inserir um novo elemento em uma pilha também é chamado de push, push ou push.É colocar o novo elemento no topo do elemento superior da pilha para torná-lo um novo elemento superior da pilha. A exclusão de elementos de uma pilha também é conhecida como empilhamento ou desempilhamento.Ele exclui o elemento superior da pilha e torna seu elemento adjacente o novo elemento superior da pilha.
【例1】smartRepeat智能重复字符串问题
将 '3[abc]' 变为 'abcabcabc'
将 '3[2[a]2[b]]' 变成 'aabbaabbaabb'
将 '2[1[a]3[b]2[3[c]4[d]]]' 变成 'abbbcccddddcccddddabbbcccddddcccdddd'
function smartRepeat(templateStr) {
// 指针下标
let index = 0
// 栈一,存放数字
let stack1 = []
// 栈二,存放需要重复的字符串
let stack2 = []
let tailStr = templateStr
// 为啥遍历的次数为 length - 1 ? 因为要估计忽略最后的一个 ] 字符串
while (index < templateStr.length - 1) {
// 剩余没处理的字符串
tailStr = templateStr.substring(index)
if (/^\d+\[/.test(tailStr)) {
// 匹配 "[" 前的数字
let word = tailStr.match(/^(\d+)\[/)[1]
// 转为数字类型
let num = Number(word)
// 入栈
stack1.push(num)
stack2.push('')
index++
} else if (/^\w+\]/.test(tailStr)) {
// 匹配 "]" 前的需要重复的字符串
let word = tailStr.match(/^(\w+)\]/)[1]
// 修改栈二栈顶的字符串
stack2[stack2.length - 1] = word
// 让指针后移,word的长度,避免重复计算字符串
index += word.length
} else if (tailStr[0] === ']') {
// 遇到 [ 字符串就需要出栈了,栈一和栈二同时出栈,栈二出栈的字符串重复栈一出栈的 数字的次数,并赋值到栈二的新栈顶上
let times = stack1.pop()
let word = stack2.pop()
stack2[stack2.length - 1] += word.repeat(times)
index++
} else {
index++
}
// console.log('tailStr', tailStr)
// console.log('index', index)
// console.log('stack1', stack1)
// console.log('stack2', stack2)
}
// while结束之后, stack1 和 stack2 中肯定还剩余1项,若不是,则用户输入的格式错误
if (stack1.length !== 1 || stack2.length !== 1) {
throw new Error('输入的字符串有误,请检查')
} else {
return stack2[0].repeat(stack1[0])
}
}
Ideias para resolver problemas:
iterar através de cada caractere
- criar duas pilhas
- Se o caractere for um número, coloque o número na pilha 1 e uma string vazia na pilha 2
- Se este caractere for uma letra, mude o item do topo da pilha 2 para esta letra neste momento
- Se o caractere for ], então o número é retirado da pilha 1 e o elemento superior da pilha 2 é repetido o número de vezes que o número é retirado da pilha 1, a pilha 2 é retirada e unida ao novo topo da pilha 2
A preparação preliminar acabou, vamos usar "sonho para iluminar a realidade" para converter **string modelo** em estrutura de árvore AST
Implementação manuscrita da árvore de sintaxe abstrata AST
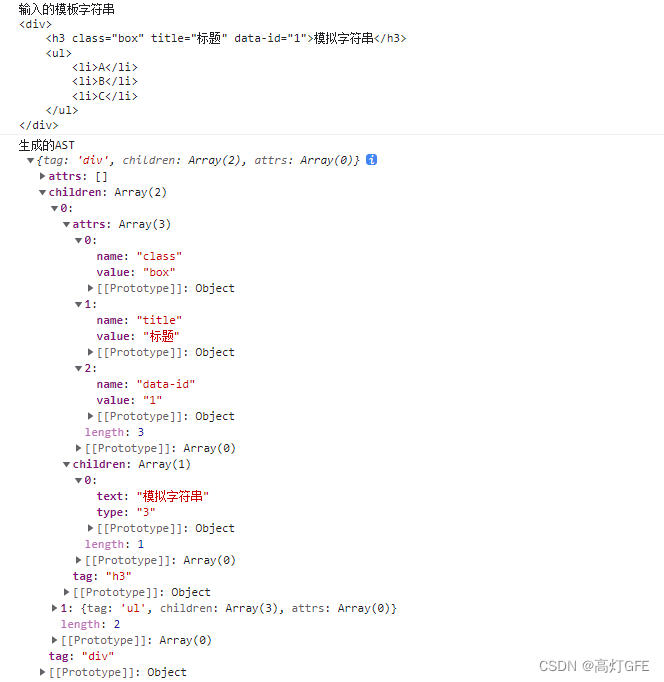
Precisamos analisar a string de modelo em
ideias de solução de problemas AST:
- Analisando o atributo attribute na tag html, o pensamento da pilha é muito útil ao analisar a string do modelo e pode analisar rapidamente o HTML aninhado
- Converta a string do modelo em uma estrutura de árvore AST. O algoritmo usado é a pilha e a ideia da pilha na reserva do algoritmo é usada.
Analisar o atributo de atributos na tag html
export default function (attrsString) {
let result = []
if (!attrsString) {
return result
} else {
// console.log('attrsString', attrsString)
// 案例 'class="box" title="标题" data-type="3"'
let isMatchQuot = false // 是否遇到引号
// 改变了一下写法,采用双指针来记录 "" 之间走过的字符串
let i = 0
let j = 0
while (j < attrsString.length) {
// 当前指针指向的这一项
const char = attrsString.charAt(j)
if (char === '"') {
// 匹配 " 字符
isMatchQuot = !isMatchQuot
} else if (!isMatchQuot && char === ' ') {
// 没匹配到 " 字符,而且当前项是空格
// 尝试拿到 i 和 j 指针之间的目标字符串
const target = attrsString.substring(i, j).trim()
// console.console.log(target);
if (target) {
result.push(target)
}
// 让指针i 追上 指针j
i = j
}
j++
}
// 循环结束,还剩下最后一项属性
result.push(attrsString.substring(i).trim())
// filter过滤空字符
return result.filter(item => item).map(item => {
const res = item.match(/^(.+)="(.+)"$/)
return {
name: res[1],
value: res[2]
}
})
}
}
Ideia:
Para o atributo attrs, remova os espaços em ambos os lados e, em seguida, use o ponteiro para julgar e interceptar o conteúdo de cada atributo por vez e retornar o valor da chave na forma de um objeto.
Converter string de modelo em estrutura de árvore AST
import parseAttribute from './parseAttribute'
export default function parse(templateString) {
let index = 0
// 未处理的字符串
let tailStr = templateString
// 匹配开始的html标签
const startTagRegExp = /^\<([a-z]+[1-6]?)(\s[^\<]+)?\>/
// 匹配结束的html标签
const endTagRegExp = /^\<\/([a-z]+[1-6]?)\>/
// 抓取结束标签前的文字
const wordRegExp = /^([^\<]+)\<\/[a-z]+[1-6]?\>/
// 准备两个栈
let stack1 = [] // 存储匹配到的开始html标签
let stack2 = []
let result = null
while (index < templateString.length - 1) {
tailStr = templateString.substring(index)
if (startTagRegExp.test(tailStr)) {
// 匹配开始标签
const res = tailStr.match(startTagRegExp)
const startTag = res[1]
const attrsString = res[2]
// 开始将标记放入到栈1中
stack1.push(startTag)
// 将对象推入数组
stack2.push({
tag: startTag, children: [], attrs: parseAttribute(attrsString)})
// 得到attrsString的长度
const attrsStringLength = attrsString ? attrsString.length : 0
// 指针移动标签的长度 + 2 + attrsString.length
// 为什么 +2,因为 <> 也占两个长度
index += startTag.length + 2 + attrsStringLength
} else if (endTagRegExp.test(tailStr)) {
// 匹配结束标签
const endTag = tailStr.match(endTagRegExp)[1]
// 栈1和栈2都需要弹栈
const pop_tag = stack1.pop()
const pop_obj = stack2.pop()
// 此时栈1的栈顶的元素肯定和endTag相同
if (endTag === pop_tag) {
if (stack2.length > 0) {
stack2[stack2.length - 1].children.push(pop_obj)
} else if (stack2.length === 0) {
// 匹配到结束标签,且stack2出栈完毕,证明已经遍历结束,那么结果就是stack2最后出栈的那一项
result = pop_obj
}
} else {
throw new Error(`${
pop_tag}便签没有封闭!!`)
}
// 指针移动标签的长度 + 3,为什么 +3,因为 </> 也占三个长度
index += endTag.length + 3
} else if (wordRegExp.test(tailStr)) {
// 识别遍历到的这个字符,是不是文字,并且不能全是空字符
const word = tailStr.match(wordRegExp)[1]
if (!/^\s+$/.test(word)) {
stack2[stack2.length - 1].children.push({
text: word,
type: '3'
})
}
index += word.length
} else {
index++
}
}
return result
}
Ideia:
Defina o ponteiro móvel para determinar se a string restante é um rótulo inicial ou final ou texto e armazene o nome do rótulo e o contêiner em duas pilhas. Quando o rótulo inicial é encontrado, o rótulo é colocado na pilha 1, o o contêiner gerado é colocado na pilha 2 e o texto é preenchido O conteúdo no topo da pilha 2, quando fechado, o conteúdo no topo da pilha 2 será movido para o contêiner anterior no topo da pilha.
import parse from './parse'
const templateString = `
<div>
<h3 class="box" title="标题" data-id="1">模拟字符串</h3>
<ul>
<li>A</li>
<li>B</li>
<li>C</li>
</ul>
</div>
`
console.log('输入的模板字符串', templateString);
const ast = parse(templateString)
console.log('生成的AST\n', ast)
Resumir
O artigo acima é a parte principal da árvore de sintaxe abstrata AST no Vue. A parte mais empolgante são as ideias de solução de problemas de pilha e ponteiro duplo. Espero que depois de ler este artigo, você tenha uma nova compreensão do algoritmo de pilha e ponteiro. .