A linguagem dos computadores: o conjunto de instruções de montagem
Esse é o conjunto de instruções. Este livro apresenta principalmente o conjunto de instruções MIPS.
instruções de montagem
Operaçoes aritimeticas:
add a,b,c # a=b+c
sub a,b,c # a=b-c
Os comentários para montagem do MIPS são # sinais.
Como o tamanho do registrador no MIPS é de 32 bits, que é a unidade básica de acesso, ele também é chamado de word. O assembly MIPS tem 32 registradores. O número de registradores está relacionado à viabilidade do conjunto de instruções, não quer dizer que quanto mais Lei de Moore, melhor.
Em seguida, substitua as letras abstratas acima por representações de registro:
# f=(g+h)-(i+j)
# f,g,h,i,j in s0,s1,s2,s3,s4
add $t0,$s1,$s2
add $t1,$s3,$s4
sub $s0,$t0,$t1
Os registradores no assembly MIPS são representados por $+ dois caracteres.
Depois, há instruções para buscar dados da memória.
# g=h+A[8]
# g,h in s1,s2
# A address in s3
lw $t0,8($s3) # 用这种方式拿出来
add $s1,$s2,$t0
O MIPS usa endereçamento big-endian, ou seja, o byte alto é armazenado no endereço baixo.
Bit menos significativo: o bit mais à direita, que é o bit 0 do MIPS[31:0].
Bit mais significativo: 31 bits.
Se endereçar por byte, o offset correto é offset*4.
Por exemplo: calcule A[12]=h+A[8], h está em s2 e A está em s3.
lw $t0,32($s3)
add $t0,$s2,$t0
sw $t0,48($s3) # 写回
Operação constante: Por exemplo, a constante 4 é armazenada em s1+AddrConstant4, podemos lw $t0,AddConstant4($s1)retirar a constante.
Como alternativa, use o valor imediato diretamente.
addi $s3,$s3,4 #加立即数需要用 addi
A velocidade de operação imediata é rápida e o consumo de energia é baixo.
O registrador $zero armazena uma constante 0, porque, por exemplo, uma instrução de transferência de dados pode ser considerada como uma instrução add 0, o que simplifica a combinação de instruções de transferência de dados e instruções de adição.
Definir algumas constantes de acordo com a frequência de uso é uma das formas de acelerar eventos de alta probabilidade.
O armazenamento digital é dividido em números não assinados e números assinados representados por códigos complementares, e o algoritmo específico não será expandido em detalhes~
composição de comando
t0-t7 são registradores 8-15, s0-s7 são registradores 16-23.
Por exemplo, a add $t0,$s1,$s2representação em linguagem de máquina de instrução (decimal) é:

O campo 0 no início e o campo 32 no final representam o comando add.
17 18 são dois operandos fonte s1 s2.
8 é o operando de destino t0.
O quinto campo não é usado e definido como 0.
Claro que a representação subjacente é um número binário de 32 bits. As instruções MIPS são todas de 32 bits.

op: Código da operação.
rs rt: Dois registradores de operando fonte.
rd: registrador do operando destino.
shamt: deslocamento.
funct: código de função, uma variante de op como addi.
Mas o defeito deste formato de instrução é que o comprimento às vezes não é suficiente, por exemplo, o endereço ou valor imediato que queremos processar não pode ser representado por 5 bits (5 bits podem representar apenas 32 números na análise final).
Daí a introdução de instruções do tipo I (instruções usadas para valores imediatos. As instruções acima são instruções do tipo R, usadas para registradores)

O último campo grande é usado para representar um deslocamento de endereço ou um valor imediato.
Ambas são instruções de 32 bits, então a complexidade não aumenta muito. Mas como o computador julga qual é o comando R e qual é o comando I? O formato de instrução específico é julgado por diferentes operações.
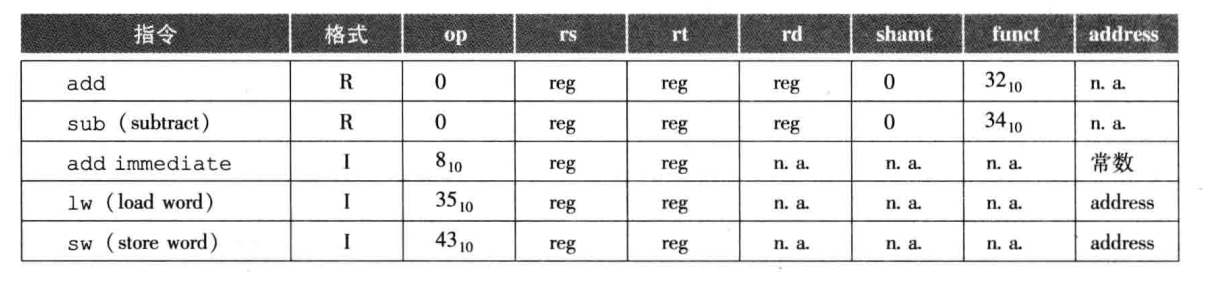
Por exemplo, lw significa que rs e rt são registradores e todos os bits seguintes são valores addr.
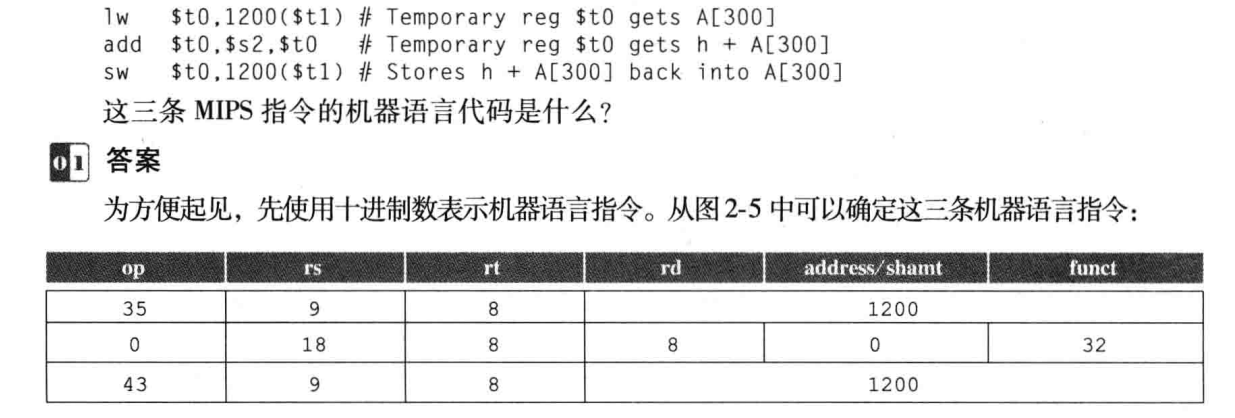
O exemplo acima mostra o código de máquina para duas instruções diferentes. Se não houver rd, o segundo registrador de operando de origem rt é usado em seu lugar.
Mova para a esquerda:
sll $t2,$s0,4 # t2=s0<<4
and $t0,$t1,$t2 #t0=t1 & t2
or $t0,$t1,$t2 #t0=t1 | t2
nor $t0,$t1,$t2 #t0=~(t1 | t2), 其中一个是0的话相当于 not

Salto condicional:
beq $s1,$s2,L1 #两者相等则跳转到L1处
bne $s1,$s2,L1
por exemplo:if(i==j)f=g+h;else f=g-h;
bne $s3,$s4,Else
add $s0,$s1,$s2
j Exit
Else:sub $s0,$s1,$s2
Exit:
Loop Jump: Um método de comparação de salto semelhante.
Loop: #循环体
bne $s0,$s1,Exit #如果两者不等,跳出循环
j Loop
Exit:
menos que diretiva:
slt $t0,$s3,$s4 #t0=1 if s3<s4
sltu $t0,$s3,$s4 #无符号数
slti $t0,$s3,10 #带立即数的比较
Devido ao princípio da simplicidade, não há instrução "pule se for menor que". Claro, podemos usar slt primeiro e depois usar beq para julgar o valor de t0, para que as duas instruções simples sejam mais eficientes.
processo (função)
Um conceito abstrato, uma parte do processo de execução do programa, semelhante a uma função. O processo não precisa saber todas as informações sobre o chamador, mas apenas a parte necessária para concluir o processo.
Envolve: passar parâmetros, entregar o controle ao processo e obter a área de armazenamento especificada para obter o valor de retorno do processo após o retorno do processo.
a0~a3 são os parâmetros de entrada, v0 e v1 são o valor de retorno da função e ra é o registrador de endereço de retorno do ponto inicial de retorno.
jal: pula e vincula, pula e armazena o valor de retorno em ra. Em seguida, use a instrução jr para voltar. jr é um salto incondicional para o endereço armazenado no registrador subseqüente.
jr ra
A parte que chama a função é o chamador. A função que está sendo chamada é callee.
jal realmente armazena o valor de pc+4 em ra.
a pilha
Por exemplo, precisamos usar mais registradores na função, não apenas esses 5.
Podemos primeiro colocar o valor do registrador original na pilha e, em seguida, fornecer esses registradores à pilha.
O sp da pilha ainda cresce do endereço alto para o endereço baixo.
Por exemplo, a função calcula a soma de f=(g+h)-(i+j). Os quatro parâmetros passados são a0-a3, f é armazenado em s0 e as duas operações de adição no processo precisam usar duas variáveis temporárias t0 e t1. Portanto, os valores desses três registradores precisam ser salvos na pilha.
Código de envio:
addi $sp,$sp,-12
sw t0,8($sp)
sw t1,4($sp)
sw s0,0($sp)
Após a operação, o valor no registrador s0 deve ser transferido para um registrador de valor de retorno
add $v0,$s0,$zero
Código da pilha:
lw t0,8($sp)
lw t1,4($sp)
lw s0,0($sp)
addi $sp,$sp,+12
Mas, na verdade, o MIPS estipula que os registradores da série s0-s7 devem ser salvos e o receptor deve ser salvo e restaurado. As séries t0-t9 não são usadas.
procedimento aninhado
Um processo que não chama outros processos é chamado de processo folha. No entanto, sabemos que existem muito poucos programas que consistem apenas em procedimentos folha.
O processo não-folha deve enviar todos os registradores que devem ser reservados, o chamador salva os registradores de parâmetro a0-a3 e os registradores temporários t0-t9, o callee salva os registradores de salvamento s0-s7 e o endereço de retorno ra. O registrador salvo pelo callee pode garantir o mesmo valor na chamada e no retorno, enquanto o valor do registrador temporário e do registrador de parâmetros é variável no retorno. Portanto, se o chamador salvar a série t para utilidade, você mesmo deve salvá-la e não esperar que o receptor a salve; se não for útil, você não precisa salvá-la.
Por exemplo, um código recursivo, expresso em linguagem C da seguinte forma:
int fact(int n)
{
if(n<1)return 1;
else return n*fact(n-1);
}
Código de montagem do MIPS:
Primeiro, faça um inventário dos registradores usados pelos processos não-folha.
-
As etapas de cálculo são relativamente simples e não precisam salvar registros temporários.
-
n é o parâmetro a0 que precisa ser salvo.
-
ra precisa ser salvo.
-
s0-s7 não são usados.
Ou seja, apenas a0 ra precisa ser salvo. Então julgue onde salvá-lo? chamador ou chamado?
Toda vez que a função de fato é chamada, a função de fato é chamada, o que salva ra por si só. Se o fato chama recursivamente o próximo eu, então ele mesmo se torna o chamador e precisa salvar a0 (ou outra lógica: salve ra e a0 toda vez, se chamar a si mesmo recursivamente, restaure ra a0, caso contrário, não é usado restaurar ra a0 porque o valor não mudou)
fact:
addi $sp,$sp,-8
sw $ra,4($sp)
sw $a0,0($sp)
slti $t0,$a0,1 # 判断是否 <1
beq $t0,$zero,L1 # >=1 则准备进入下一层循环
addi $v0,$zero,1
addi $sp,$sp,8
jr $ra # ra a0 值没变,这里把栈指针恢复一下,返回值赋值一下就结束函数了
L1:
addi $a0,$a0,-1
jal fact # 递归调用非叶过程
lw $ra,4($sp)
lw $a0,0($sp)
addi $sp,$sp,8 # 恢复寄存器原值
mul $v0,$a0,$v0 # 乘上本轮递归的 n
jal $ra
Suplemento: As variáveis globais e estáticas são estáticas.As variáveis estáticas são armazenadas na área de dados estáticos e também existem durante a entrada e saída do processo, enquanto as variáveis dinâmicas só existem durante a entrada e saída do processo. O MIPS tem um ponteiro global $gp apontando para a área de dados estáticos.
A sobrecarga do processo recursivo ainda é relativamente grande. Seria melhor usar a iteração?
quadro de processo
Em alguns processos, uma parte dos registradores também é colocada na pilha, essa parte dos registradores e fragmentos de variáveis locais são chamados de frames de processo ou registros ativos.
Alguns softwares MIPS usarão o ponteiro do quadro $fp e $sp para identificar qual parte é o quadro do processo, e alguns softwares usarão registradores para salvar o ponteiro do quadro do processo.
O ponteiro do quadro também pode salvar mais de 4 parâmetros, e a parte em excesso pode encontrar sua localização na memória de acordo com o ponteiro do quadro.
Claro, um princípio muito importante é: antes que o processo retorne, esta parte deve ser restaurada para esvaziar.
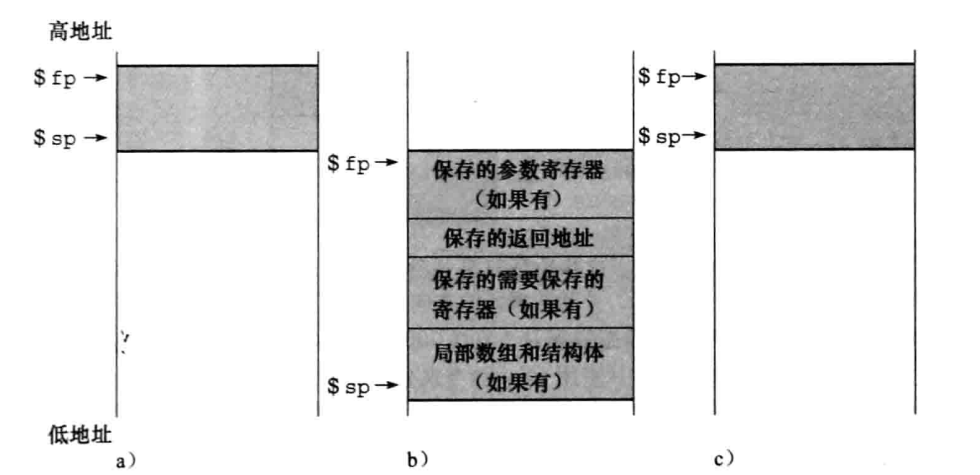
fragmento de código
Forneça espaço para variáveis estáticas e dados dinâmicos no heap.
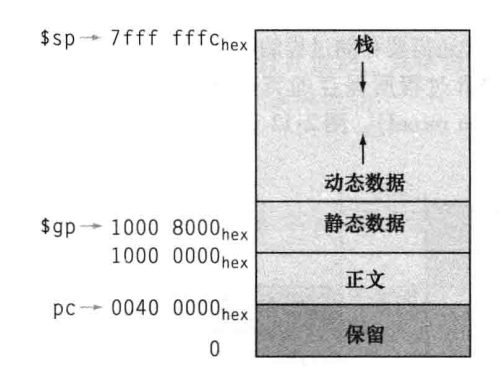
Corpo: trecho de código.
Dados estáticos: variáveis globais e estáticas.
Dinâmico: Variáveis dinâmicas.
A linguagem C aloca e libera espaço de heap por meio de funções malloc e free explícitas. A desvantagem é que esquecer de liberar manualmente pode facilmente levar a vazamentos de memória e, se a liberação for antecipada, um ponteiro pendente será gerado e o programa apontará para um local para o qual não deseja apontar. E o java alocará memória automaticamente e recuperará unidades inúteis XD
Esta é uma convenção de registro salva pelo MIPS. Isso conta como um evento acelerado de alta probabilidade, porque as estatísticas provam que salvar 8 registradores e 10 rascunhos é suficiente na maioria das vezes.
interação humano-computador
A maioria dos computadores hoje usa bytes de 8 bits para representar caracteres, também conhecidos como códigos ASCII.
lb sb: lê e escreve apenas um byte, para os oito bits mais à direita do registrador de destino.
Os caracteres geralmente são combinados em strings. Existem três esquemas para marcar o comprimento de uma string: 1. O primeiro caractere da string é seu comprimento; 2. Use uma variável separada para armazenar o comprimento da string; 3. Use um terminador especial para marcar o final da string. string. A linguagem c usa o esquema 3, usando o sinalizador \0.
Por exemplo, para a implementação de uma cópia de string, a lógica da linguagem c é: percorrer um bit dos caracteres de cópia até que \0 seja encontrado.
Suponha que as matrizes de origem e destino sejam baseadas em $a0 $a1 e i seja armazenado em $s0.
strcpy:
addi $sp,$sp,-4
sw $s0,0($sp)
add $s0,$zero,$zero # i置0
L1:
add $t1,$a1,$s0 # t1存放源数组的当前指针
lbu $t2,0($t1) # 无符号字节读取
add $t3,$a0,$s0 # t1存放目标数组的当前指针
sbu $t2,0($t3)
beq $t2,$zero,L2 # 跳出结束复制
addi $s0,$s0,1 # 这里和之前以字为单位做处理不同,我们是以字节为单位做处理,因此i++而不是i+4
L2:
lw $s0,0($sp)
addi $sp,$sp,4
jr $ra
Java usa o Unicode mais geral (o esquema usado pela maioria das páginas da Web atualmente) para salvar caracteres, e a unidade é de 16 bits. O MIPS pode usar diretamente lh sh lhu shu para ler e escrever meia palavra com exatamente um caractere. Portanto, as strings java ocupam o dobro da memória que c, mas as operações de string são mais rápidas.
Java usa uma palavra para armazenar o comprimento total da string.
Como o endereço da pilha do MIPS deve ser alinhado por palavra, um caractere em c tem 8 bits, mesmo que haja 5 caracteres, o comprimento de 8 caracteres será alocado para alinhar 2 palavras. As meias-palavras de Java também requerem um mecanismo de alinhamento semelhante.
imediato de 32 bits
O número imediato normal é de 16 bits, mas às vezes precisamos que seja maior, para 32 bits.
A instrução lui load upper imediato pode copiar o valor imediato de 16 bits para os 16 bits superiores do registrador.

Dessa forma, por exemplo, para um número de 32 dígitos, podemos primeiro lui os primeiros 16 bits em um registrador e depois inserir os 16 bits inferiores ori.
Há um registrador $at especial no MIPS para armazenar temporariamente valores imediatos de 32 bits.
No entanto, você precisa prestar atenção ao uso de imediato de 32 bits e imediato de 16 bits. Por exemplo, os 16 bits superiores de addi e operações lógicas estão envolvidos na operação (a operação lógica superior de 16 bits do 16-bit bit imediato é considerado como 0).
endereçamento
As instruções de salto da série J são opcode de 6 bits + endereço de salto de 26 bits e o intervalo de salto é 2 ^ 26.
Como as instruções condicionais da série B também precisam de bits para armazenar os registradores a serem comparados, elas são estruturadas como opcode de 6 bits + registrador 1 de 5 bits + registrador 2 de 5 bits + endereço de 16 bits.
Se esse endereço de 16 bits representar o endereço de destino, o intervalo de endereços que pode ser saltado é limitado a 2 ^ 16 palavras e o comprimento total do programa não pode exceder esse intervalo, o que é muito chato.
Para tanto, a solução adotada é: o endereço de 16 bits é um endereço de deslocamento, e o método de salto é o endereço base atual + endereço de deslocamento de 16 bits (um bit de sinal, ou seja, ±2^15). Como a maioria das instruções de loop e instruções condicionais são menores que 2 ^ 15 (que também é um evento de alta probabilidade para aumento de velocidade), essa abordagem é suficiente. Este método é chamado de endereçamento relativo ao PC.
Além disso, os endereços MIPS são alinhados por palavra, portanto, em comparação com os endereços de byte, o intervalo endereçável é expandido em 4 vezes. Por exemplo, o intervalo de endereçamento da série j é de 2 ^ 28 endereços de byte.
Mas os endereços de PC não são de 32 bits? Na verdade, apenas os 28 bits mais baixos podem ser modificados por instruções de salto. Se o tamanho do programa exceder 2 ^ 28, ele precisará pular por salto de registro.

A série b é de endereçamento relativo, e é relativo à próxima instrução, ou seja, o salto em 80016 addi $s3,$s3,1para a Saída em 80032, ou seja, 8+80016.
A série j é endereçamento direto, 20000*4=80000 saltos.

Essa também é uma ideia interessante.Eu sempre sinto que a desmontagem condicional é diferente do pensamento normal.
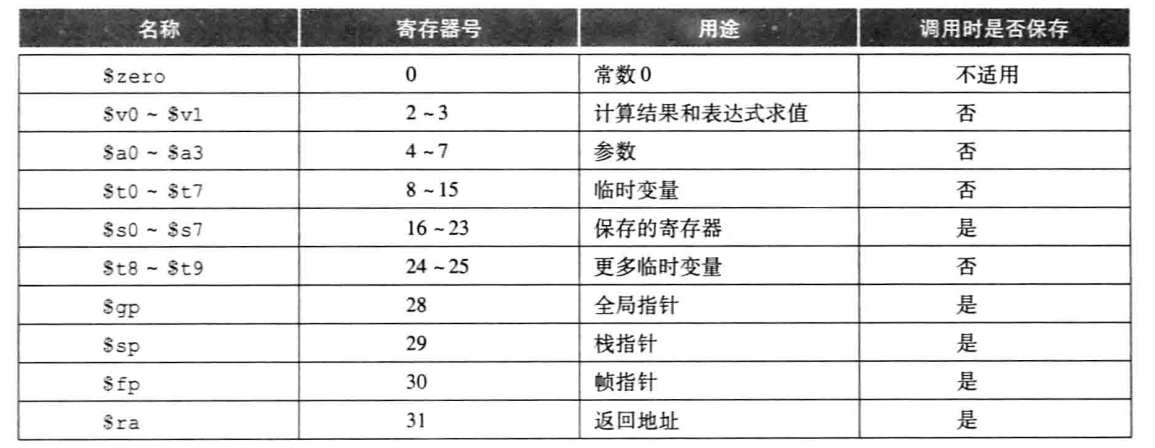
Os modos de endereçamento do MIPS geralmente têm os seguintes tipos:
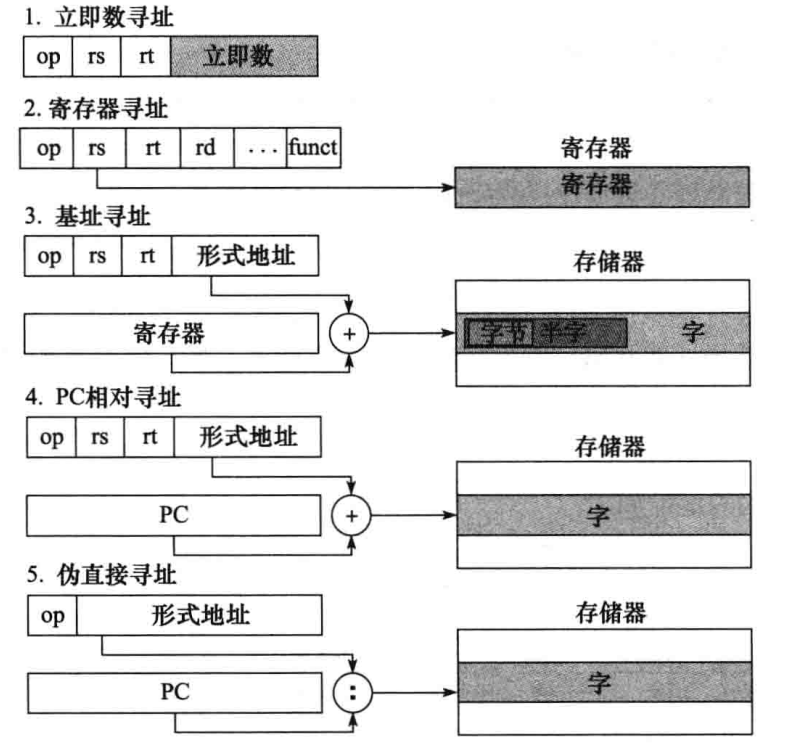
Endereçamento base: endereço + endereço de deslocamento em um determinado registrador.
Endereçamento pseudodireto: os endereços de ordem superior e de forma de 26 bits do PC são concatenados.
Embora o MIPS neste livro seja de endereçamento de 32 bits, quase todos os microprocessadores podem ser estendidos para endereçamento de 64 bits, que é compatível com versões anteriores.
Instruções paralelas e síncronas
O mecanismo de sincronização é mais importante ao executar tarefas em paralelo para evitar a competição de dados.
É muito semelhante a aprender o sistema operacional aqui. Execute operações atômicas de leitura e gravação em um conjunto de dados por meio de um mutex.
Usamos o par de instruções: acesso ao link + armazenamento condicional ll+sc para alcançar.
again: addi $t0,$zero,1 ; 尝试上锁=1
ll $t1,0($s1) ; 获取 s1 初始值
sc $t0,0($s1) ; 保存 s1 值。如果发现 ll 获取值和 sc 保存值不同,t0 置零
beq $t0,$zero,again ; 如果 t0 又变成0了,执行失败,重新执行
add $s4,$zero,$t1 ; 做操作
Os capítulos posteriores irão expandir ainda mais.
executivo de tradução
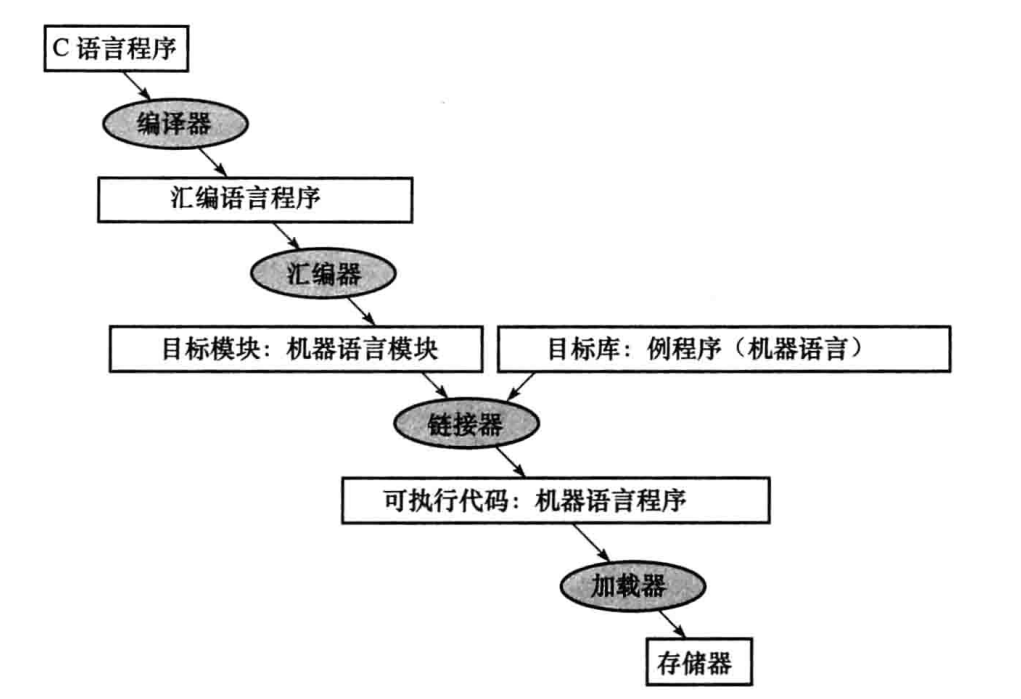
Antigamente, a capacidade de armazenamento do hardware era pequena e a eficiência do compilador não era alta, e todos eram escritos em assembly.
O montador suporta algumas variantes da linguagem de máquina, como a instrução de movimento. Na verdade add $t0,$zero,$t0, o montador também pode traduzir, mas não há instrução de movimento. Esse tipo de instrução é chamado de pseudo-instrução.
O montador chamará a tabela de símbolos.
O arquivo de objeto gerado pelo arquivo de montagem contém:
- Cabeçalho do arquivo de destino: descreve a composição, tamanho, localização e outras informações do arquivo de destino.
- fragmento de código
- segmento de dados estáticos
- Informações de realocação: algumas instruções e dados que dependem de endereços absolutos.
- Tabela de símbolos: Tags restantes indefinidos (como rótulos em ramificação e instruções de transferência de dados são colocados em uma tabela para serem consultados, e os dados da tabela consistem em rótulos e endereços em pares), como referências externas.
- informações de depuração.
O vinculador combina os arquivos de objeto de linguagem de máquina individuais em um executável. As principais etapas envolvidas são as seguintes:
- De acordo com as informações de realocação e a tabela de símbolos no arquivo, o endereço antigo em cada arquivo é combinado para criar um novo endereço. Por que não gerar o arquivo executável e definir o novo endereço desde o início, em vez de compilar cada arquivo em um arquivo de objeto separado e modificá-lo novamente? Porque esta modificação é mais eficiente.
- Depois de analisar os links externos, o vinculador determina a localização de todos os módulos na memória e os representa com endereços absolutos realocados. Os endereços absolutos são processados primeiro e, em seguida, os endereços relativos restantes são dispostos.
Em geral, os arquivos executáveis e de objeto têm o mesmo formato, mas não contêm referências não resolvidas (exceto alguns links externos, como links para funções de biblioteca).
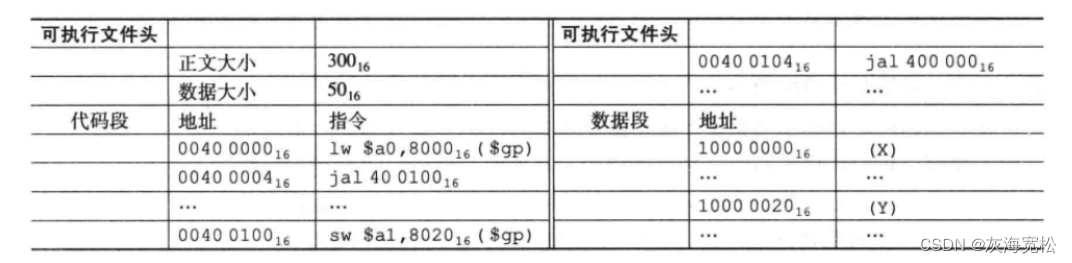
Exemplo: A seguir estão os dois arquivos de destino de AB, vincule e forneça o endereço atualizado.
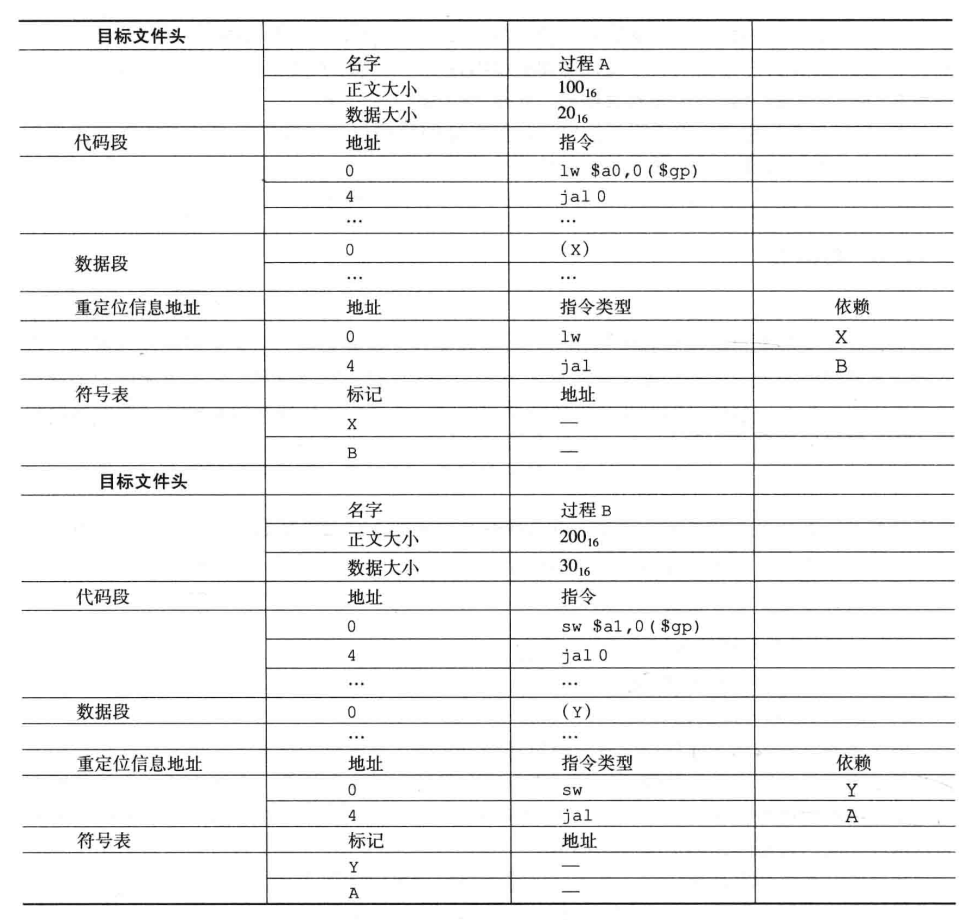
- Lidar com referências externas. A faz referência a XB e B faz referência a YA.
- O segmento de código começa em 0x400000 e o segmento de dados começa em 0x10000000, então o segmento de código de A é 0x400000-0x400100 (o cabeçalho do arquivo do processo A identifica o tamanho de seu texto e 0x400100 não é usado), o segmento de dados é 0x10000000-0x10000020, seguido por B Depois disso, o segmento de código é 0x400100-0x400300 e o segmento de dados é 0x10000020-0x10000050.
- A primeira instrução de salto das duas é pular para a primeira posição de instrução da outra parte. jal: Endereçamento pseudo-direto, o endereço de salto jal é o endereço da primeira instrução da outra parte, a é pular para 400100, b é pular para 400000. Além disso, a regra de salto jal é descartar as duas mais à esquerda dígitos (salto real é o endereço base + 4* jal), os endereços de salto reais dos dois são 100040 e 100000. As instruções são aumentadas de forma incremental
- O endereço inicial de gp é 0x10008000, e os dados de acesso dependem do registrador de endereço base. Se o endereço de busca real quiser buscar 0x10000000, o deslocamento deve ser 0x8000. Os dados big-endian estão aumentando de forma decrescente .
Depois que o arquivo executável é criado, o carregador vem para colocar as instruções de dados na memória.
- Leia o cabeçalho do arquivo para saber o segmento de código e o tamanho dos dados;
- Crie um corpo suficientemente grande e espaço de dados;
- comando copiar dados;
- Os parâmetros da função principal são copiados para o topo da pilha e o ponteiro da pilha aponta para NULL;
- Pule para a rotina de inicialização, copie os parâmetros e chame a função principal do programa; quando a função principal retornar, chame exit para encerrar o programa.
O método de vinculação mencionado acima é a vinculação estática.A desvantagem é que, se a função de biblioteca for atualizada, a função de biblioteca vinculada anteriormente não será alterada. E também fará com que a biblioteca seja totalmente carregada, mesmo que nem todo o conteúdo da biblioteca seja usado, e o programa será muito grande.
A DLL de link dinâmico deve vincular a biblioteca quando estiver em execução. O link dinâmico no início também adicionará o conteúdo em todas as bibliotecas, e a DLL vinculada no processo final vinculará apenas as rotinas chamadas.
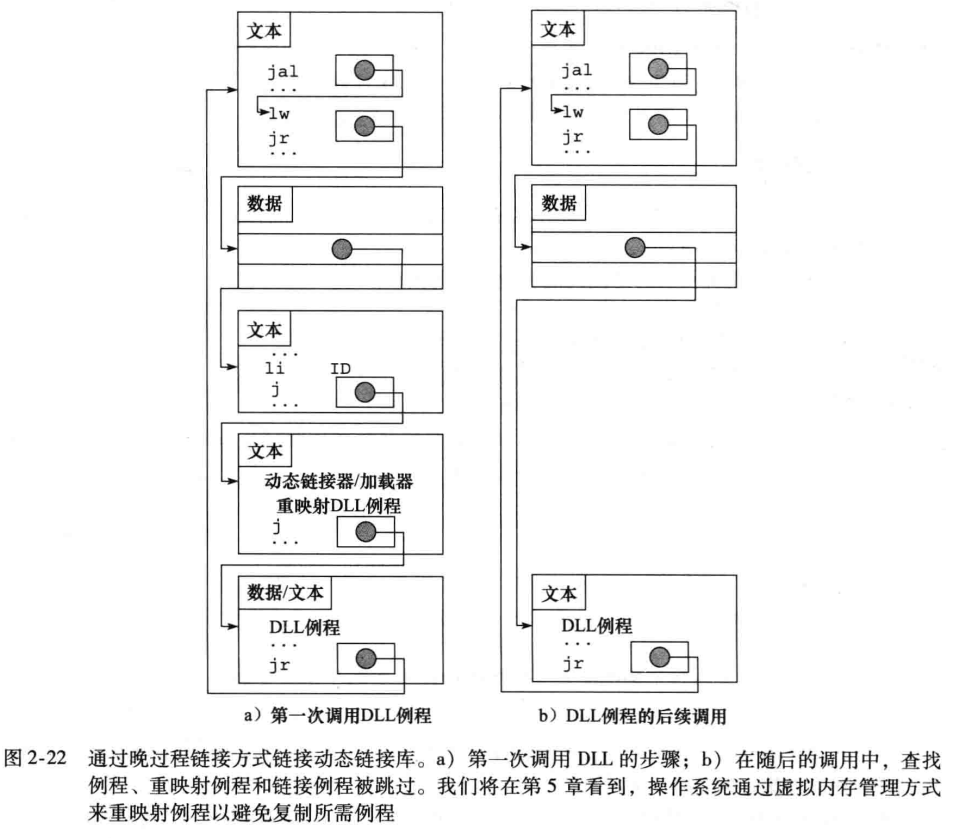
A segunda vez evita alguns saltos indiretos.
A execução de um programa java passa por duas etapas.
- javac compila a linguagem java em arquivos de bytes binários de classe.
- jvm interpreta e traduz arquivos bytecode item por item.
A eficiência do jvm é muito baixa e a assistência do compilador instantâneo JIT apareceu posteriormente, que identificará os blocos de código de execução frequente como "códigos quentes", os compilará em códigos de máquina relacionados à plataforma local e os otimizará para melhorar a eficiência.
Exemplo de projeto: classificar

sll $t0,$a1,2
add $t1,$a0,$t0
lw $t2,0($t1)
lw $t0,4($t1)
sw $t0,4($t1)
sw $t2,0($t1)
jr ra

Circuito 1:
move $s0,$zero
for1tst:
slt $t0,$s0,$a1
beq $t0,$zero,$exit1
...
for loop 2
...
addi $s0,$s0,1
j for1tst
exit1:
Ciclo 2: Não toque no registrador s no ciclo 1, você pode alterar o registrador t à vontade.
addi $s1,$s0,-1
for2snd:
slti $t0,$s1,0
bne $t0,$zero,$exit2
sll $t1,$s1,2
add $t2,$t1,$a0
lw $t3,0($t2)
lw $t4,4($t2)
slt $t0,$t4,$t3
beq $t0,$zero,$exit2
...
swap
...
addi $s1,$s1,-1
j for2snd
exit2:
chamada de troca: salve primeiro o registro de parâmetro original e, em seguida, modifique o registro de parâmetro.
# 传参
move $s2,$a0
move $s3,$a1
move $a0,$s2
move $a1,$s1
jal swap
Finalmente, antes de mesclar, também precisamos adicionar a operação de salvar e alterar o registro de origem no início e no final. Usamos s0-s3, então salve s0-s3 e ra.
sort:
addi $sp,$sp,-20
sw $ra,16($sp)
sw $s3,12($sp)
sw $s2,8($sp)
sw $s1,4($sp)
sw $s0,0($sp)
move $s2,$a0
move $s3,$a1 # 不管是否要调用,先存一下参数
move $s0,$zero
for1tst:
slt $t0,$s0,$a1
beq $t0,$zero,$exit1
addi $s1,$s0,-1
for2snd:
slti $t0,$s1,0
bne $t0,$zero,$exit2
sll $t1,$s1,2
add $t2,$t1,$a0
lw $t3,0($t2)
lw $t4,4($t2)
slt $t0,$t4,$t3
beq $t0,$zero,$exit2
move $a0,$s2
move $a1,$s1
jal swap
addi $s1,$s1,-1
j for2snd
exit2:
addi $s0,$s0,1
j for1tst
exit1:
lw $ra,16($sp)
lw $s3,12($sp)
lw $s2,8($sp)
lw $s1,4($sp)
lw $s0,0($sp)
addi $sp,$sp,20
jr $ra
A parte que chama a função de troca pode ser otimizada por inlining, ou seja, a operação de troca é expandida diretamente em vez de chamar a função para reduzir a sobrecarga de salto. Porém, devido ao aumento na quantidade de código, se a taxa de falta de cache aumentar, a perda será maior do que o ganho.
Além disso, na verdade $sp sempre contém 4 registradores de parâmetro -16. Porque c terá uma opção vararg de parâmetro variável, permitindo um parâmetro de ponteiro.
Matrizes e ponteiros
O array é subscrito *4 adicionado ao endereço base do array, e o ponteiro é o endereço base do array +=4.
Os exemplos de programa a seguir são duas implementações de limpeza de array:

Em comparação com outros conjuntos de instruções
- Arquitetura ARM:
- ARM (Advanced RISC Machines) é uma arquitetura de computador com conjunto reduzido de instruções (RISC) amplamente utilizada em dispositivos móveis, sistemas embarcados, chips embarcados e microcontroladores.
- Os projetos ARM se concentram na eficiência energética e no baixo consumo de energia, por isso se destacam em dispositivos móveis.
- A arquitetura ARM tem várias versões e variantes, incluindo ARMv7, ARMv8, etc., onde ARMv8 introduziu um modo de execução de 64 bits (AArch64).
- arquitetura x86:
- A arquitetura x86 é uma arquitetura CISC (Complex Instruction Set Computer) usada principalmente em computadores pessoais, servidores e sistemas de desktop.
- Processadores representativos da arquitetura x86 incluem Pentium da Intel, série Core i e série Ryzen da AMD.
- A arquitetura x86 oferece alta flexibilidade em desempenho e funcionalidade para uma ampla gama de tarefas de computação.
- Arquitetura MIPS:
- MIPS (Microprocessor without Interlocked Pipeline Stages) é uma arquitetura de computador com conjunto de instruções reduzido (RISC) que foi amplamente usada em estações de trabalho e sistemas embarcados nos primeiros dias.
- O design do MIPS se concentra na simplificação do conjunto de instruções para melhorar a eficiência da execução.
- Embora seu uso tenha diminuído gradualmente em algumas áreas, a arquitetura MIPS ainda é usada em alguns equipamentos de rede embarcados e controladores embarcados.
por gpt
Por exemplo, comparação de braço e ramificação condicional: o MIPS armazena o resultado da comparação em um registro e o ARM define o resultado da comparação como um código de condição, incluindo: número negativo, zero, transporte, estouro. Por exemplo, uma comparação CMP subtrai dois valores de registro e o resultado define o código de condição.
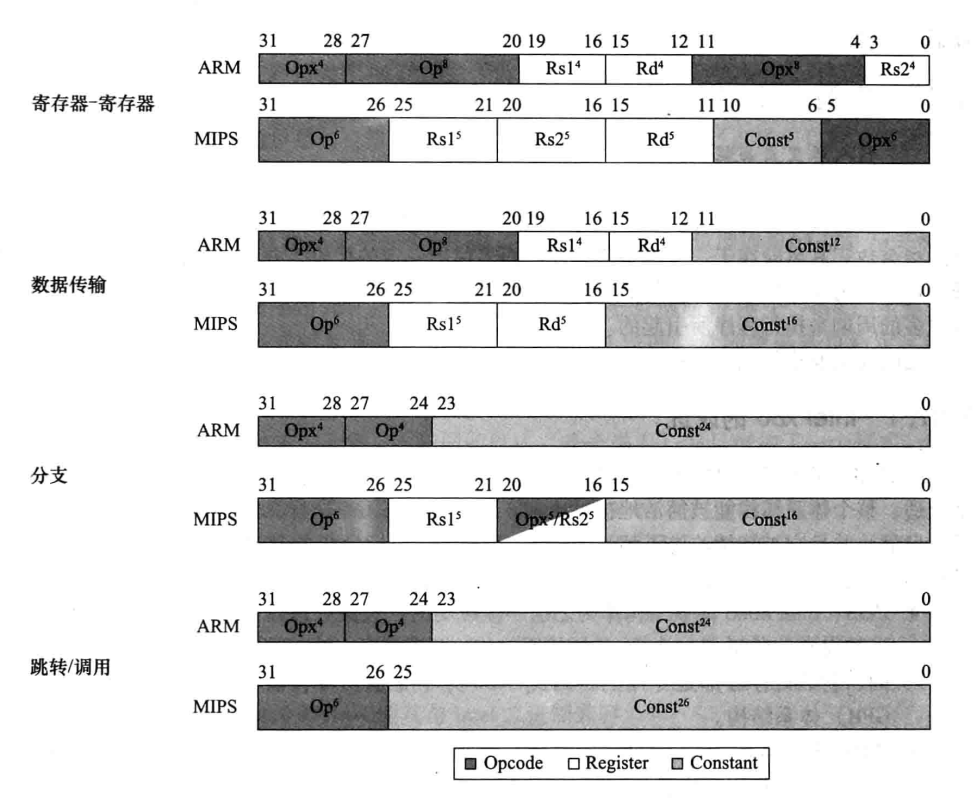
Desta forma, o braço tem o dobro de registros (16), mas ainda pode concluir a tarefa e, em alguns casos, de acordo com o código de condição, pulará diretamente as instruções que não precisam ser executadas, economizando espaço no código e executando tempo.
O valor imediato de arm: a forma estendida de 4+8.

Ele também suporta operações de deslocamento no segundo parâmetro de registro e o mesmo número de bits pode representar mais dados.
arm também suporta a operação do grupo de registradores e decide quais registradores nos registradores de 16 bits carregar/copiar através de uma máscara de 16 bits.
A desvantagem do x86 é principalmente que a faixa de endereçamento é limitada e o cisc diminui a eficiência.
Em geral, as instruções do MIPS são regulares e de comprimento uniforme, apenas 32 registradores são usados para garantir os requisitos de velocidade e a composição das instruções é otimizada pela aceleração de eventos de alta probabilidade e outras ideias.