Índice
2. Kafka recebe dados da interface externa
3. Kafka encaminha os dados após recebê-los

1. O que é kafka
Kafka é uma plataforma de processamento de fluxo distribuído originalmente desenvolvida pelo LinkedIn. Ele é projetado para processamento de dados de alta taxa de transferência e baixa latência, capaz de lidar com fluxos de dados em tempo real em grande escala. O Kafka usa um modelo de publicação-assinatura para publicar dados em um ou mais tópicos (tópicos) e, em seguida, os assinantes podem consumir dados sobre esses tópicos de acordo com suas próprias necessidades.
O Kafka é um sistema distribuído que divide os dados horizontalmente por meio de partições, e cada partição pode armazenar e processar dados em diferentes servidores no cluster. Esse design torna o Kafka altamente escalável e tolerante a falhas, capaz de processar grandes quantidades de dados e garantir a disponibilidade de dados quando os nós do cluster falham.
O Kafka é amplamente usado em cenários como coleta de logs, arquitetura orientada a eventos e filas de mensagens. Ele pode ser usado para construir um sistema de processamento de fluxo de dados em tempo real, transferir dados rapidamente da fonte para o sistema de destino e suportar funções como armazenamento persistente de dados, replicação de dados e reprodução de dados.

2. Kafka recebe dados da interface externa
Kafka pode enviar dados de interfaces externas para o cluster Kafka escrevendo um programa produtor. A seguir está um código de exemplo simples de um produtor Kafka escrito em Java:
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 创建Producer的配置
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建Producer实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 待发送的数据
String topic = "my_topic";
String key = "my_key";
String value = "Hello, Kafka!";
// 创建ProducerRecord并发送数据
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record);
// 关闭Producer
producer.close();
}
}No código de amostra acima, criamos uma instância KafkaProducer, configuramos parâmetros relacionados (como endereço de cluster Kafka, serializador etc.), criamos um objeto ProducerRecord para representar os dados a serem enviados e, finalmente, enviamos os dados para o tópico especificado através do meio do método send.
Você pode modificar os parâmetros relevantes no código de acordo com suas próprias necessidades para se adaptar a seus cenários e formatos de dados específicos.
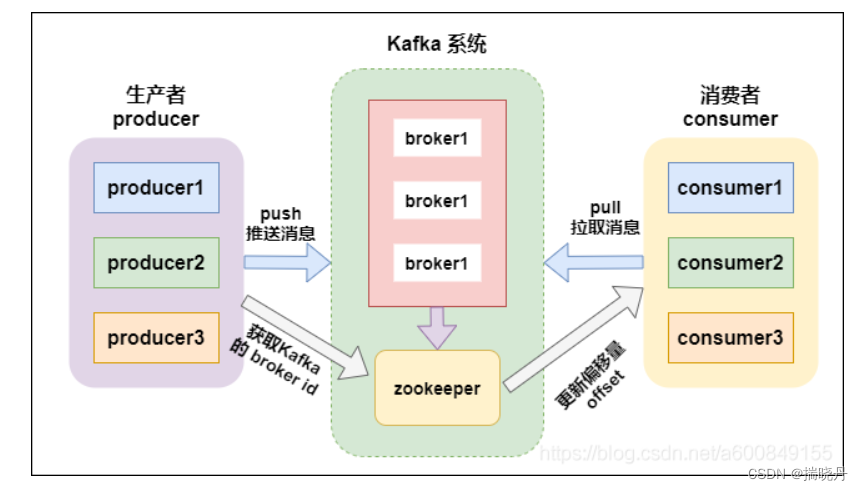
3. Kafka encaminha os dados após recebê-los
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Arrays;
import java.util.Properties;
public class KafkaForwarder {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 消费者配置
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", bootstrapServers);
consumerProps.put("group.id", "my_consumer_group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 订阅要消费的主题
consumer.subscribe(Arrays.asList("my_topic"));
// 生产者配置
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", bootstrapServers);
producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(producerProps);
// 循环消费数据并转发
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
// 获取消费的数据
String topic = record.topic();
String key = record.key();
String value = record.value();
// 转发数据给其他终端
// TODO: 编写转发逻辑,将数据发送到目标终端
// 示例:将数据发送到另一个Kafka主题中
String forwardTopic = "forward_topic";
ProducerRecord<String, String> forwardRecord = new ProducerRecord<>(forwardTopic, key, value);
producer.send(forwardRecord);
}
}
}
}No código de exemplo acima, criamos uma instância KafkaConsumer para consumir dados do cluster Kafka e criamos uma instância KafkaProducer para encaminhar dados. Primeiro, definimos a configuração do consumidor, incluindo endereço de cluster Kafka, grupo de consumidores, desserializador, etc. Em seguida, subscribe assinamos o tópico que queremos consumir por meio do método. poll Em seguida, use o método para extrair dados do cluster Kafka em um loop infinito , percorrer os dados de consumo e encaminhá-los. No exemplo, enviamos os dados encaminhados para outro tópico Kafka, você pode modificar a lógica de encaminhamento de acordo com sua necessidade. Lembre-se de substituir os parâmetros de configuração relevantes no código para se adequar ao seu cenário específico.
Quatro, resumo de kafka
Kafka é uma plataforma de processamento de fluxo distribuído com alta taxa de transferência e baixa latência. No Kafka, os dados são publicados e assinados por meio de tópicos. O produtor (Producer) envia dados para o tópico especificado e o consumidor (Consumer) consome dados do tópico.
Para enviar e receber dados no Kafka, primeiro você precisa criar uma instância de produtor. O produtor pode configurar parâmetros como endereço e serializador do cluster Kafka. Então, ao criar um objeto ProducerRecord, os dados a serem enviados são encapsulados em um registro. Ao chamar o método send, o produtor envia o registro para o tópico especificado.
Para consumidores, uma instância de consumidor precisa ser criada. Os consumidores podem configurar parâmetros como endereços de cluster Kafka, grupos de consumidores e desserializadores. Ao chamar o método de assinatura, o consumidor se inscreve no tópico a ser consumido. Em seguida, use o método de votação para extrair dados do cluster Kafka em determinados intervalos. Os consumidores percorrem e consomem os dados extraídos e podem processar os dados de acordo com suas necessidades, como encaminhamento e armazenamento.
Em resumo, as etapas básicas para enviar e receber dados usando o Kafka são as seguintes:
-
Crie uma instância do produtor e configure os parâmetros relacionados.
-
Crie um objeto ProducerRecord para encapsular os dados a serem enviados.
-
Chame o método send para enviar o registro para o tópico especificado.
-
Crie uma instância de consumidor e configure os parâmetros relacionados.
-
Chame o método de assinatura para assinar o tópico a ser consumido.
-
Use o método de votação para extrair dados do cluster Kafka.
-
Percorra os dados de consumo e processe de acordo.
Deve-se notar que o Kafka fornece uma grande variedade de opções de configuração e funções flexíveis, que podem ser ajustadas e expandidas de acordo com as necessidades específicas do negócio. Ao mesmo tempo, configurar razoavelmente os parâmetros do cluster Kafka e monitorar o status de execução do cluster Kafka também são aspectos importantes para garantir a eficiência e a confiabilidade do envio e recebimento de dados.