
1. Beschreibung
Ich habe erklärt, was der Aufmerksamkeitsmechanismus ist und einige wichtige Schlüsselwörter und Blöcke im Zusammenhang mit Transformatoren erläutert, z. B. Selbstaufmerksamkeit, Abfrage, Schlüssel und Wert sowie Mehrkopfaufmerksamkeit. In diesem Teil erkläre ich, wie diese Aufmerksamkeitsblöcke dazu beitragen, Transformer-Netzwerke, Aufmerksamkeit, Selbstaufmerksamkeit, Multi-Head-Aufmerksamkeit, maskierte Multi-Head-Aufmerksamkeit, Transformers, BERT und GPT zu erstellen.
2. Inhalt:
- Herausforderungen von RNNs und wie Transformer-Modelle dabei helfen können, sie zu überwinden (vorgestellt in Teil 1)
- Aufmerksamkeitsmechanismen – Selbstaufmerksamkeit, Abfrage, Schlüssel, Wert, Mehrkopfaufmerksamkeit (eingeführt in Teil 1)
- Transformatorennetz
- Grundlagen von GPT (behandelt in Teil 3)
- Grundlagen von BERT (wird in Teil 3 behandelt)
3. Transformatornetzwerk
Papier – Aufmerksamkeit ist alles, was Sie brauchen (2017)
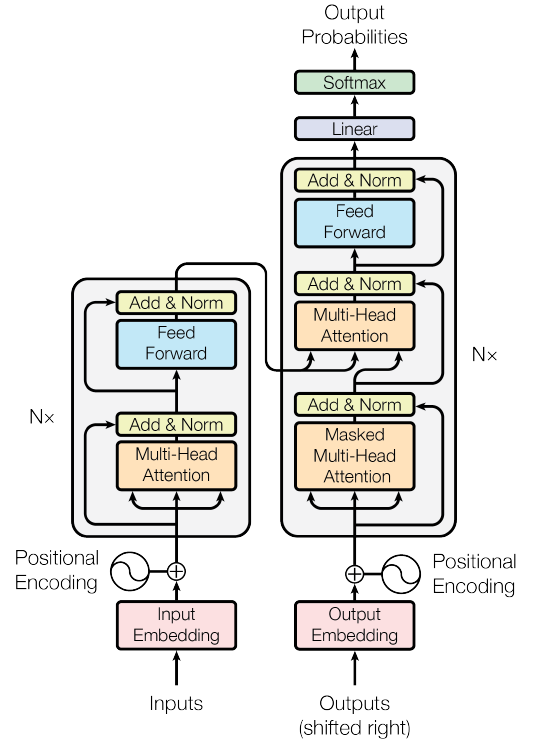
Abbildung 1. Das Transformer-Netzwerk (Quelle: Das Bild stammt aus dem Originaltext)
Abbildung 1 zeigt das Transformatornetzwerk. Dieses Netzwerk hat RNN als bestes Modell für NLP und sogar Computer Vision ( Vision Transformer ) abgelöst.
Das Netzwerk besteht aus zwei Teilen – Encoder und Decoder.
Bei der maschinellen Übersetzung wird ein Encoder zum Codieren des Originalsatzes und ein Decoder zum Generieren des übersetzten Satzes verwendet. Der Encoder des Transformers kann ganze Sätze parallel verarbeiten und ist damit schneller und besser als RNNs – RNNs verarbeiten Sätze Wort für Wort.
3.1 Encoderblock

Abbildung 2. Der Encoder-Teil des Transformatornetzwerks (Quelle: Das Bild stammt aus dem Originaltext)
Das Encoder-Netzwerk beginnt mit einem Eingang. Hier wird der gesamte Satz auf einmal eingespeist. Anschließend werden sie in den Block „ Einbettung der Eingabe “ eingebettet . Anschließend wird jedem Wort im Satz eine „ Positionskodierung “ hinzugefügt. Diese Kodierung ist entscheidend für das Verständnis der Position jedes Wortes in einem Satz. Ohne Positionseinbettungen sieht das Modell den gesamten Satz als eine Tüte voller Wörter ohne Reihenfolge oder Bedeutung.
Im Detail:
3.1.1 Eingabeeinbettung
— Das Wort „Hund“ in einem Satz kann den Einbettungsraum nutzen, um Vektoreinbettungen zu erhalten. Beim Einbetten wird einfach ein Wort in einer beliebigen Sprache in seine Vektordarstellung umgewandelt. Ein Beispiel ist in Abbildung 3 dargestellt. Im Einbettungsraum haben ähnliche Wörter ähnliche Einbettungen, zum Beispiel werden das Wort „Katze“ und das Wort „Kätzchen“ im Einbettungsraum sehr nahe beieinander liegen, während die Wörter „Katze“ und „Emotion“ weiter im Raum liegen .

Abbildung 3. Eingabeeinbettung (Quelle: Vom Autor erstelltes Bild)
3.1.2 Positionskodierung
Wörter in verschiedenen Sätzen können unterschiedliche Bedeutungen haben. Zum Beispiel das Wort Hund in a. Ich habe einen süßen Hund (Tier/Haustier – Position 5) und b. Was bist du doch für ein fauler Hund! (kein Wert - Position 4) hat eine andere Bedeutung. Um bei der Positionskodierung zu helfen. Es handelt sich um einen Vektor, der Informationen basierend auf dem Kontext und der Position eines Wortes in einem Satz bereitstellt.
In jedem Satz erscheinen Wörter nacheinander und haben eine Bedeutung. Wenn die Wörter in einem Satz durcheinander sind, ergibt der Satz keinen Sinn. Aber wenn der Konverter die Sätze lädt, lädt er sie nicht nacheinander, sondern parallel. Da die Transformer-Architektur beim parallelen Laden die Reihenfolge der Wörter nicht berücksichtigt, müssen wir die Position der Wörter in Sätzen explizit definieren. Dies hilft dem Konverter zu verstehen, dass in einem Satz ein Wort nach dem anderen kommt. Hier bieten sich Standorteinbettungen an. Dies ist eine Vektorkodierung, die Wortpositionen definiert. Diese Positionseinbettung wird der Eingabeeinbettung hinzugefügt, bevor sie in das Aufmerksamkeitsnetzwerk eintritt. Abbildung 4 vermittelt ein intuitives Verständnis der Eingabe- und Positionseinbettungen, bevor sie in das Aufmerksamkeitsnetzwerk eingespeist werden.

Abbildung 4. Intuitives Verständnis von Standorteinbettungen (Quelle: Vom Autor erstelltes Bild)
Es gibt verschiedene Möglichkeiten, diese Positionseinbettungen zu definieren. Beispielsweise definieren die Autoren in der Originalarbeit „Attention is All You Need“ Einbettungen mithilfe alternierender Sinus- und Kosinusfunktionen, wie in Abbildung 5 dargestellt.

Abbildung 5. Im Originalpapier verwendete Positionseinbettungen (Quelle: Bild aus dem Originalpapier)
Obwohl diese Einbettung für Textdaten funktioniert, funktioniert diese Einbettung nicht für Bilddaten. Somit gibt es mehrere Möglichkeiten, Objektpositionen (Text/Bilder) einzubetten, und diese können während des Trainings festgelegt oder gelernt werden. Die Grundidee besteht darin, dass diese Einbettung es der Transformatorarchitektur ermöglicht, zu verstehen, wo sich Wörter in einem Satz befinden, anstatt die Bedeutung durch Verwirrung von Wörtern zu verfälschen.
Nachdem die Wort-/Eingabeeinbettung und die Positionseinbettung abgeschlossen sind, fließt die Einbettung in den wichtigsten Teil des Encoders, der zwei wichtige Blöcke enthält – den „Multi-Head Attention“-Block und das „ Feed-Forward “-Netzwerk.
3.1.3 Mehrkopfaufmerksamkeit
Dies ist der Hauptblock, in dem die Magie geschieht. Um mehr über Multi-Head Attention zu erfahren, besuchen Sie bitte diesen Link – 2.4 Multi-Head Attention .
Als Eingabe erhält der Block einen Vektor (Satz), der Untervektoren (Wörter im Satz) enthält. Dann berechnet die Multi-Head-Aufmerksamkeit die Aufmerksamkeit zwischen jeder Position und den anderen Positionen des Vektors.

Abbildung 6. Skalierte Skalarproduktaufmerksamkeit (Quelle: Bild aus dem Originalpapier)
Die obige Abbildung zeigt die skalierte Punktproduktaufmerksamkeit. Dies ist genau das Gleiche wie Selbstaufmerksamkeit, mit der Hinzufügung von zwei Blöcken (Skala und Maske). Um mehr über Sef-Attention zu erfahren, besuchen Sie bitte diesen Link – 2.1 Selbstaufmerksamkeit .
Wie in Abbildung 6 dargestellt, ist die skalierte Aufmerksamkeit genau die gleiche, außer dass sie nach der ersten Matrixmultiplikation (Matmul) eine Skala hinzufügt.
Die Skalierungsverhältnisse sind wie folgt:

Die skalierte Ausgabe geht in eine Maskenebene. Dies ist eine optionale Ebene, die für die maschinelle Übersetzung nützlich ist.

Abbildung 7. Aufmerksamkeitsblock (Quelle: Vom Autor erstelltes Bild)
Abbildung 7 zeigt die neuronale Netzwerkdarstellung des Aufmerksamkeitsblocks. Worteinbettungen werden zunächst an einige lineare Ebenen übergeben. Diese linearen Schichten haben keinen „Bias“-Term und sind daher nichts anderes als Matrixmultiplikationen. Eine der Ebenen wird als „Schlüssel“ dargestellt, eine andere als „Abfragen“ und die letzte Ebene als „Werte“. Wenn wir eine Matrixmultiplikation zwischen dem Schlüssel und der Abfrage durchführen und dann normalisieren, erhalten wir die Gewichte. Diese Gewichte werden dann mit Werten multipliziert und summiert, um den endgültigen Aufmerksamkeitsvektor zu erhalten. Dieser Block ist mittlerweile in neuronalen Netzen verfügbar und wird Aufmerksamkeitsblock genannt. Es können mehrere solcher Aufmerksamkeitsblöcke hinzugefügt werden, um mehr Kontext bereitzustellen. Das Beste daran ist, dass wir eine Gradienten-Backpropagation erhalten können, um Aufmerksamkeitsblöcke (Gewichte für Schlüssel, Abfragen, Werte) zu aktualisieren.
Die Multi-Head-Aufmerksamkeit nimmt mehrere Schlüssel, Abfragen und Werte auf, leitet sie durch mehrere skalierte Punktprodukt-Aufmerksamkeitsblöcke und verkettet schließlich die Aufmerksamkeiten, um uns eine endgültige Ausgabe zu liefern. Wie in Abbildung 8 dargestellt.

Abbildung 8. Aufmerksamkeit mehrerer Köpfe (Quelle: Vom Autor erstelltes Bild)
Einfachere Erklärung: Der Hauptvektor (Satz) enthält Untervektoren (Wörter) – jedes Wort hat eine Positionseinbettung. Die Aufmerksamkeitsberechnung behandelt jedes Wort als „ Abfrage “ und findet einen „ Schlüssel “ , der einem anderen Wort im Satz entspricht , und nimmt dann eine konvexe Kombination der entsprechenden „ Werte “. Bei der Multi-Head-Aufmerksamkeit werden mehrere Werte, Abfragen und Schlüssel ausgewählt, um mehrere Aufmerksamkeiten bereitzustellen (bessere Worteinbettungen und besseren Kontext). Diese Mehrfachaufmerksamkeiten werden verkettet, um den endgültigen Aufmerksamkeitswert (Kontextkombination aller Wörter aus allen Mehrfachaufmerksamkeiten) zu ergeben, was viel besser ist als die Verwendung eines einzelnen Aufmerksamkeitsblocks.
Bei einfachen Wörtern besteht die Idee der Multi-Head-Aufmerksamkeit darin, eine Worteinbettung zu nehmen und sie mit einigen anderen Worteinbettungen (oder mehreren Wörtern) zu kombinieren, um Aufmerksamkeit (oder mehrere Aufmerksamkeiten) zu verwenden, um eine bessere Einbettung für dieses Wort zu erzeugen (Einbettung). mehr Kontext der umgebenden Wörter).
Die Idee besteht darin, mehrere Aufmerksamkeiten pro Abfrage mit unterschiedlichen Gewichtungen zu berechnen.
3.1.4 Addieren, Normieren und Feedforward
Der nächste Block ist „Add and Norm “, der die Restverbindungen der ursprünglichen Worteinbettungen nimmt, sie zu den Mehrkopf-Aufmerksamkeitseinbettungen hinzufügt und sie dann auf den Mittelwert Null und die Varianz Eins normalisiert.
Dies wird in einen „ Feedforward “-Block eingespeist , der an seinem Ausgang auch einen „Add and Normalize“-Block hat.
Der gesamte Multi-Head-Aufmerksamkeits- und Feed-Forward-Block wird im Encoderblock n-mal (Hyperparameter) wiederholt.
3.2 Decoderblock

Abbildung 9. Der Decoder-Teil des Transformatornetzwerks (Quelle: Bild aus dem Originalpapier)
Die Ausgabe des Encoders ist wiederum eine Reihe von Einbettungen, eine Einbettung für jede Position, wobei jede Positionseinbettung nicht nur die Einbettung des ursprünglichen Wortes an dieser Position enthält, sondern auch Informationen über andere Wörter, die er durch Aufmerksamkeit gelernt hat.
Dieses wird dann in den Decoder-Teil des Transformatornetzwerks eingespeist, wie in Abbildung 9 dargestellt. Der Zweck eines Decoders besteht darin, eine Ausgabe zu erzeugen. In der Arbeit „Attention is All You Need“ wird dieser Decoder zur Satzübersetzung (z. B. vom Englischen ins Französische) verwendet. Der Encoder erhält also einen englischen Satz und der Decoder übersetzt ihn ins Französische. In anderen Anwendungen ist der Decoder-Teil des Netzwerks nicht erforderlich, daher werde ich nicht näher darauf eingehen.
Schritte im Decoderblock –
1. Bei der Satzübersetzung empfängt der Decoderblock einen französischen Satz (für die Übersetzung vom Englischen ins Französische). Wie beim Encoder fügen wir hier eine Worteinbettung und eine Positionseinbettung hinzu und speisen sie in einen Aufmerksamkeitsblock mit mehreren Köpfen ein.
2. Der Selbstaufmerksamkeitsblock generiert einen Aufmerksamkeitsvektor für jedes Wort in einem französischen Satz, um die Relevanz eines Wortes für ein anderes im Satz anzuzeigen.
3. Anschließend werden die Aufmerksamkeitsvektoren in den französischen Sätzen mit denen in den englischen Sätzen verglichen. Dies ist der Teil, in dem die Wortzuordnung vom Englischen zum Französischen erfolgt.
4. In den letzten Schichten sagt der Decoder die Übersetzung des englischen Wortes in das bestmögliche französische Wort voraus.
5. Der gesamte Vorgang wird mehrmals wiederholt, um eine Übersetzung der gesamten Textdaten zu erhalten.
Die für jeden der oben genannten Schritte verwendeten Module sind in Abbildung 10 dargestellt.

Abbildung 10. Die Rolle verschiedener Decoderblöcke bei der Satzübersetzung (Quelle: Vom Autor erstelltes Bild)
Es gibt einen neuen Block im Decoder – maskierte Mehrkopf-Aufmerksamkeit. Alle anderen Blöcke haben wir bereits im Encoder gesehen.
3.2.1Maskieren Sie die Aufmerksamkeit mehrerer Köpfe
Dabei handelt es sich um einen Aufmerksamkeitsblock mit mehreren Köpfen, bei dem bestimmte Werte ausgeblendet werden. Die Wahrscheinlichkeit, dass ein maskierter Wert leer oder nicht aktiviert ist.
Beispielsweise sollte der Ausgabewert beim Dekodieren nur von vorherigen Ausgaben abhängen, nicht von zukünftigen Ausgaben. Dann maskieren wir die zukünftige Ausgabe.
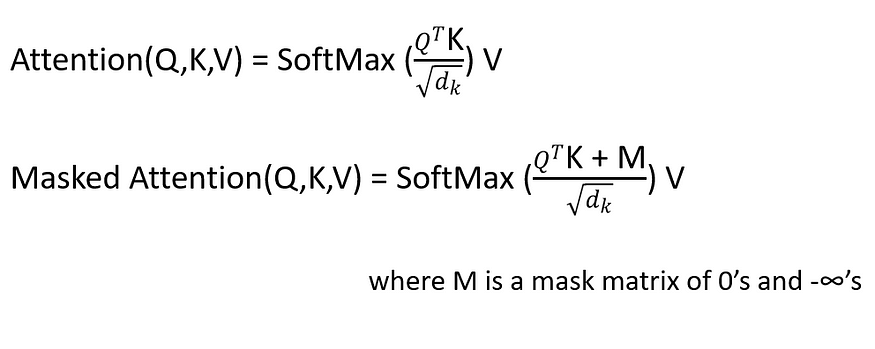
3.3 Ergebnisse und Schlussfolgerungen

Abbildung 11. Ergebnisse (Quelle: Originalpapierbild)
In der Arbeit wird die Sprachübersetzung vom Englischen ins Deutsche und vom Englischen ins Französische mit anderen modernen Sprachmodellen verglichen. BLEU ist eine Metrik, die bei Sprachübersetzungsvergleichen verwendet wird. Aus Abbildung 11 sehen wir, dass das große Transformatormodell bei beiden Übersetzungsaufgaben höhere BLEU-Werte erzielt. Sie haben auch die Schulungskosten erheblich gesenkt.
Zusammenfassend lässt sich sagen, dass das Transformer-Modell die Rechenkosten senken und gleichzeitig Ergebnisse auf dem neuesten Stand der Technik erzielen kann.
In diesem Teil erkläre ich die Encoder- und Decoderblöcke von Transformer Networks und wie jeder Block bei der Sprachübersetzung verwendet wird. Im nächsten und letzten Teil (Teil 3) werde ich einige wichtige Transformatornetzwerke besprechen, die in letzter Zeit sehr bekannt geworden sind, wie z. B. BERT (Bidirektionale Encoderdarstellung von Transformatoren) und GPT (General Transformer).
4. Zitat
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser und Illia Polosukhin. 2017. Aufmerksamkeit ist alles, was Sie brauchen. In Proceedings der 31. Internationalen Konferenz über neuronale Informationsverarbeitungssysteme (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010.