1. Fundo
Sem mais delongas, vamos para a foto primeiro
A imagem acima é do site oficial (https://github.com/alibaba/canal), que cobre basicamente os cenários atuais de uso do ambiente de produção.Como todos sabemos, a sincronização de dados do Canal já é uma referência na indústria. Nosso ambiente de produção também usa o Canal para monitorar as alterações de dados do binlog e, em seguida, analisa os dados correspondentes e os envia para o MQ (RocketMQ). Para alguns negócios de processo não principal, cenários assíncronos podem consumir MQ para processamento.
Mas neste artigo, quero falar principalmente sobre os cenários de uso do Canal quando os dados dos sistemas antigo e novo são sincronizados em duas direções durante a refatoração do sistema.
Nota: Não vou descrever a introdução da refatoração do sistema aqui. Você pode ler a série de artigos que escrevi antes: Falando sobre refatoração do sistema
2. Sobre a sincronização bidirecional
O que é sincronização bidirecional?
A chamada sincronização bidirecional significa que os dados do banco de dados do sistema antigo são sincronizados com o novo banco de dados do sistema, e o novo banco de dados do sistema também é sincronizado com o banco de dados do sistema antigo. Para garantir que o novo sistema e os dados do banco de dados do sistema antigo sejam completamente consistentes. Se houver um problema quando o sistema for reestruturado, ele poderá ser revertido para o sistema antigo original a qualquer momento, o que também fornece a garantia subjacente para a solução em tons de cinza.
Como fazer a sincronização geral? Quais são as vantagens e desvantagens de cada um?
Solução 1: Solução de interceptação da camada Dao
Descrição da solução: Faça furos na camada Dao para interceptar todas as solicitações de gravação (inserir, atualizar, excluir), depois grave na fila MQ e depois grave no banco de dados correspondente consumindo a fila MQ.
Vantagens: Esta solução é relativamente simples de implementar.
Desvantagens: Para o banco de dados do sistema antigo, pode haver muitos serviços de gravação.Se for interceptado da camada Dao, muitos locais podem precisar ser modificados e as alterações serão relativamente grandes.
Solução 2: Use a assinatura do Canal para analisar o Binlog
Descrição da solução: Use o Canal para assinar o Binlog, analisá-lo em dados e, em seguida, gravá-lo no banco de dados correspondente (aqui você pode gravar diretamente ou gravar no MQ primeiro e depois consumir o MQ para gravar, o último é recomendado) .
Vantagens: Pode resolver o problema de várias gravações no sistema.
Desvantagens: A introdução de um novo componente, Canal, aumenta a complexidade.
A seguir, vamos dar uma olhada na segunda opção na prática.
3. Preparação do ambiente (sistema Centos como exemplo)
1. Instale o MySQL
wget https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm
yum install mysql80-community-release-el8-1.noarch.rpm
#禁用centos自带的mysql
yum module disable mysql -y
#安装
yum install mysql-community-server -y
#启动
systemctl start mysqld
#查看启动状态 提升 Active: active (running) 表示成功
systemctl status mysqld
#查看初始密码
grep 'temporary password' /var/log/mysqld.log
#初始密码登录
mysql -uroot -p'AXXXXX' -hlocalhost -P3306
#修改ROOT密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'BXXXXX';2. Implantação do ambiente
1) Verifique se o modo binlog está habilitado no mysql.Se o valor de log_bin for OFF, ele não está habilitado, e se estiver ON, está habilitado.
SHOW VARIABLES LIKE '%log_bin%'2), se não estiver habilitado, você precisa modificar /ect/my.cnf para habilitar o modo binlog
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1Reinicie o serviço mysql após a modificação
3), crie um usuário e autorize
create user canal@'%' IDENTIFIED by 'XXXX';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;3. Instalação do servidor de canal
1), endereço de download do canal
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz2), descompacte no diretório especificado
mkdir canal-server-1.1.4
tar -zxf canal.deployer-1.1.4.tar.gz -C canal-server-1.1.4/3), modifique o arquivo de configuração para visualizar a posição binlog da biblioteca principal
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000002 | 4526 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)Modifique o arquivo de configuração conf/example/instance.properties
# position info
canal.instance.master.address={IP}:3306
# 这里对应上面的File
canal.instance.master.journal.name=binlog.000002
# 这里对应上面的Position
canal.instance.master.position=4526
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=XXXX4), inicie o canal-servidor
./bin/startup.sh
# 查看日志
tail -f logs/example/example.logO acima conclui a implementação da versão de instância única do Canal-Server. O ambiente de cluster do ambiente de produção é geralmente construído para operação e manutenção. Usamos a versão de instância única para teste.
A seguir, uma breve introdução ao design do mecanismo HA do Canal, que é recomendado para ambientes de produção.
O HA do canal é dividido em duas partes, o servidor do canal e o cliente do canal têm implementações de HA correspondentes, respectivamente
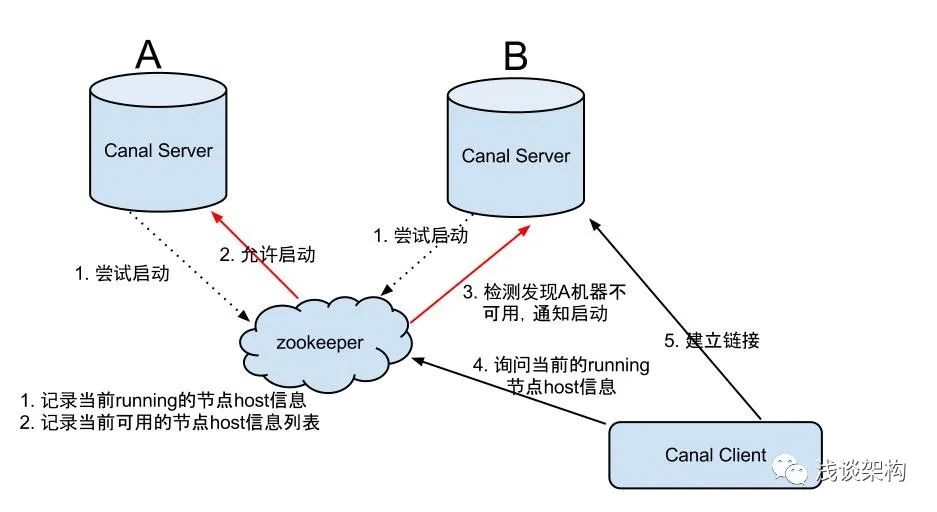
servidor de canais:
Para reduzir as solicitações de despejo do mysql, as instâncias em servidores diferentes exigem que apenas uma esteja em execução ao mesmo tempo e as outras estejam em estado de espera.
cliente do canal:
Para garantir o pedido, uma instância só pode ser executada por um cliente de canal por vez para operações get/ack/rollback, caso contrário, o pedido não pode ser garantido para o cliente receber. O controle de todo o mecanismo HA depende principalmente de vários recursos de zookeeper, watcher e nós EPHEMERAL (ligados ao ciclo de vida da sessão), portanto não os apresentarei aqui. Alunos interessados podem ler o wiki oficial.
4. Demonstração
Como o componente do canal encapsula muito código, passei algumas noites escrevendo no meu tempo livre (por favor, goste), o código foi aberto para gitee e os alunos que precisam podem cloná-lo para vê-lo.
endereço gitee: https://gitee.com/bytearch/fast-cloud
Atualmente suporta modo de conexão direta simples e modo de cluster zookeeper
O seguinte demonstra o canal-client-demo
Crie uma nova biblioteca order_center e crie uma tabela order_info
CREATE TABLE `order_info` ( `order_id` bigint(20) unsigned NOT NULL, `user_id` int(11) DEFAULT '0' COMMENT '用户id', `status` int(11) DEFAULT '0' COMMENT '订单状态', `booking_date` datetime DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`order_id`), KEY `idx_user_id` (`user_id`), KEY `idx_bdate` (`booking_date`), KEY `idx_ctime` (`create_time`), KEY `idx_utime` (`update_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;Adicionar manipulador de processador
@CanalHandler(value = "orderInfoHandler", destination = "example", schema = {"order_center"}, table = {"order_info"}, eventType = {CanalEntry.EventType.UPDATE, CanalEntry.EventType.INSERT,CanalEntry.EventType.DELETE}) public class OrderHandler implements Handler<CanalEntryBO> { @Override public boolean beforeHandle(CanalEntryBO canalEntryBO) { if (canalEntryBO == null) { return false; } return true; } @Override public void handle(CanalEntryBO canalEntryBO) { //1. 更新后数据解析 OrderInfoDTO orderInfoDTO = CanalAnalysisUti.analysis(OrderInfoDTO.class, canalEntryBO.getRowData().getAfterColumnsList()); System.out.println("event:" + canalEntryBO.getEventType()); System.out.println(orderInfoDTO); //2. 后续操作 TODO } }adicionar configuração
canal: clients: simpleInstance: enable: true mode: simple servers: XXXXX:11111 batchSize: 1000 destination: example getMessageTimeOutMS: 500 #zkInstance: # enable: true # mode: zookeeper # servers: 172.30.1.6:2181,172.30.1.7:2181,172.30.1.8:2181 # batchSize: 1000 # #filter: order_center.order_info # destination: example # getMessageTimeOutMS: 500Instruções de configuração:
public class CanalProperties { /** * 是否开启 默认不开启 */ private boolean enable = false; /** * 模式 * zookeeper: zk集群模式 * simple: 简单直连模式 */ private String mode = "simple"; /** * canal-server地址 多个地址逗号隔开 */ private String servers; /** * canal-server 的destination */ private String destination; private String username = ""; private String password = ""; private int batchSize = 5 * 1024; private String filter = StringUtils.EMPTY; /** * getMessage & handleMessage 的重试次数, 最后一次重试会ack, 之前的重试会rollback */ private int retries = 3; /** * getMessage & handleMessage 的重试间隔ms * canal-client内部代码 的重试间隔ms */ private int retryInterval = 3000; private long getMessageTimeOutMS = 1000;
Testar operações de inserção e atualização
mysql> insert into order_info(order_id,user_id,status,booking_date,create_time,update_time) values(6666666,6,10,"2022-02-19 00:00:00","2022-02-19 00:00:00", "2022-02-19 00:00:00"); Query OK, 1 row affected (0.00 sec) mysql> update order_info set status=20 where order_id=66666; Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 mysql>Resultado dos testes
2022-02-18 19:29:52.399 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle : **************************************************** * Batch Id: [11] ,count : [3] , memsize : [189] , Time : 2022-02-18 19:29:52.399 * Start : [binlog.000003:18893:1645183792000(2022-02-18 19:29:52.000)] * End : [binlog.000003:19123:1645183792000(2022-02-18 19:29:52.000)] **************************************************** 2022-02-18 19:29:52.405 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle : ----------------> binlog[binlog.000003:19056] , name[order_center,order_info] , eventType : INSERT ,tableName : order_info, executeTime : 1645183792000 , delay : 400ms event:INSERT OrderInfoDTO{orderId=6666666, userId=6, status=10, bookingDate=2022-02-19 00:00:00, createTime=2022-02-19 00:00:00, updateTime=2022-02-19 00:00:00}Pronto. Neste ponto, você concluiu com sucesso as etapas de assinatura do Canal e binlog de análise.
5. Precauções para sincronização de dados
Deixando de lado duas questões, você pode pensar sobre isso
Como resolver o problema de loopback de dados quando os dados são sincronizados em duas direções?
Por exemplo, se os dados gerados pelo novo sistema estiverem sincronizados com o sistema antigo, eles não poderão fluir de volta para o novo sistema. Como resolver isso?
O problema da ordem dos dados, se for escrito no MQ, é necessário garantir o consumo sequencial? Como conseguir?
Quando a simultaneidade de sincronização é relativamente grande, como melhorar a velocidade de sincronização.
Lembrete: Este tópico não está finalizado.Irei implementar as questões acima no próximo artigo "Ferramenta de Sincronização de Dados de Refatoração do Sistema: Canal Prático de Combate-Continuação" Você pode pensar nisso com antecedência.
Sexto, extra
Sejam todos bem-vindos a prestar atenção à conta pública de "Falando sobre Arquitetura" e compartilhar artigos originais de vez em quando
Se você tiver alguma dúvida, sinta-se à vontade para me enviar uma mensagem privada.
